Python常用的第三方模块之【jieba库】支持三种分词模式:精确模式、全模式和搜索引擎模式(提高召回率)
Jieba 是一个流行的中文分词Python库,它提供了三种分词模式:精确模式、全模式和搜索引擎模式。精确模式尝试将句子最精确地切分,适合文本分析;全模式则扫描文本中所有可能的词语,速度快但存在冗余;搜索引擎模式在精确模式的基础上,对长词进行再次切分,提高召回率。
分词功能
Jieba的核心功能是分词,它依据词库确定汉字间的关联概率。用户可以通过以下函数进行分词操作:
-
jieba.cut(s, cut_all=False): 精确模式,默认模式,返回一个可迭代的generator对象。
-
jieba.cut(s, cut_all=True): 全模式,返回一个可迭代的generator对象,可能包含冗余。
-
jieba.cut_for_search(s): 搜索引擎模式,返回一个可迭代的generator对象,对长词进行再次切分。
返回列表的分词
Jieba还提供了返回列表形式的分词结果的函数:
-
jieba.lcut(s): 精确模式,返回一个列表类型的分词结果。
-
jieba.lcut(s, cut_all=True): 全模式,返回一个列表类型的分词结果,存在冗余。
-
jieba.lcut_for_search(s): 搜索引擎模式,返回一个列表类型的分词结果,存在冗余。
自定义词典
用户可以通过jieba.add_word(w)向分词词典中增加新词,以提高分词的准确性。例如,如果有一个不常见的词语“就这”,可以添加到词典中,使得Jieba在未来的分词操作中能够识别它。
import jieba# 精确模式
words = jieba.cut("我爱自然语言处理", cut_all=False)
for word in words:print('精确模式:',word)# 全模式
words = jieba.cut("我爱自然语言处理", cut_all=True)
for word in words:print('全模式:',word)# 搜索引擎模式
words = jieba.cut_for_search("我爱自然语言处理")
for word in words:print('搜索引擎模式:',word)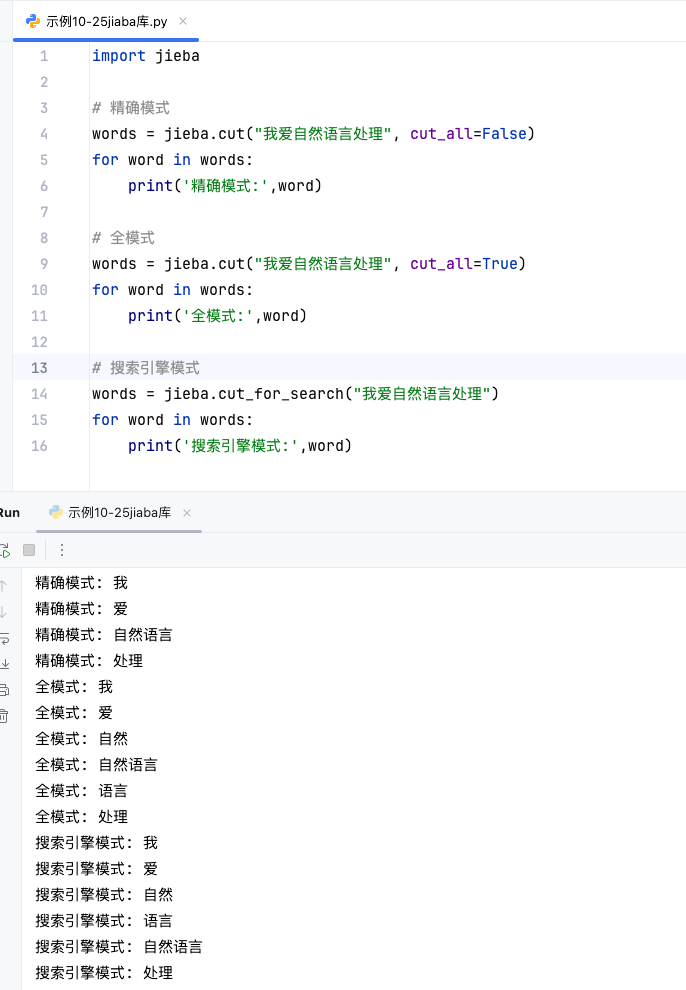
示例:
import jieba
import chardet
from chardet import UniversalDetectorfileName='AI工具集.txt'
# #读取进来,with open只能打开txt这样的纯文本,请勿打开非文本文档(比如Office系列excel),尝试使用UTF-8编码打开文件
with open(fileName, 'r', encoding='utf-8') as file:content = file.read()# print(content)#分词
lst=jieba.lcut(content)
print(lst)#去重操作
set1=set(lst) #使用集合实现去重
#
d={} #key:词,value:出现的次数
for item in set1:if len(item)>2:print(item)d[item]=0#统计出现次数
for item in lst:if item in d:d[item]=d.get(item)+1
print(d)new_lst=[]
for item in d:new_lst.append([item,d[item]])
print(new_lst)#排序
new_lst.sort(key=lambda x:x[1],reverse=True)
print(new_lst[0:11]) #显示的是前10项