关于编译原理——语义翻译器的设计
学习目标:
根据属性定义编写预测翻译程序,以便对输入的符号串进行语法和语义分析,并计算各文法符号的语义值。通过编写预测翻译程序掌握属性定义的应用以及语义值的计算方法,并掌握预测翻译程序的构造方法。
一、实验内容:
对下列表达式属性定义编写预测翻译程序,要求对输入的算术表达式进行语义分析:
(1)E->T {R.i=T.val}
R {E.val=R.s}
(2)R->+
T {R1.i=R.i+T.val}
R1 {R.s = R1.s }
|
-
T {R1.i=R.i-T.val}
R1 {R.s=R1.s}
|
ε {R.s=R.i}
(3)T->F {Q.i=F.val}
Q {T.val=Q.s}
(4)Q->*
F {Q1.i=Q.i*F.val}
Q1 {Q.s=Q1.s}
|
/
F {Q1.i=Q.i/F.val}
Q1 {Q.s=Q1.s}
|
ε {Q.s=Q.i}
(5)F-> (E) { F.val=E.val}
|
Num {F.val = num.lexval}
二、设计方案
主要包括模块功能分区、全局变量以及函数接口三个部分
(一)模块设计:
1.1 词法分析器 (Lexer)
功能: 将输入的算术表达式分解为一系列的Token。
输入: 算术表达式字符串。
输出: Token列表。
1.2 语法分析器 (Parser)
功能: 构建表达式的抽象语法树(AST)。
输入: Token列表。
输出: 抽象语法树。
1.3 求值器 (Evaluator)
功能: 计算抽象语法树的值。
输入: 抽象语法树。
输出: 表达式的计算结果。
(二)全局变量:
1.tokens[]: 存储Token的数组。
2.tokenIndex: 当前Token的索引。
(三)函数接口:
1.词法分析器函数接口:
getNextToken();
输入: 无参数,依赖于全局变量 tokenIndex 和 tokens 数组。
输出: 返回一个指向 Token 结构的指针,该结构包含当前 Token 的类型和值。如果没有更多的 Token,返回 NULL。
tokenize(const char* input)
输入: 字符串 input,表示要被分解的算术表达式。
输出: 修改全局变量 tokens 数组,填充 Token 结构体数组,每个结构包含表达式中的一个元素(数字、运算符等)的类型和值。
2.语法分析器函数接口:
parseExpression()
输入: 无参数,依赖于全局 tokens 数组和 tokenIndex 索引。
输出: 无返回值,用于构建并打印表达式的抽象语法树。
3.求值器函数接口:
evaluate()
输入: 无参数,依赖于由 Parser 构建的抽象语法树结构。
输出: 返回一个 double 类型的值,表示表达式计算的结果。
三、测试方案及测试结果
测试方案①:输入10*20-30
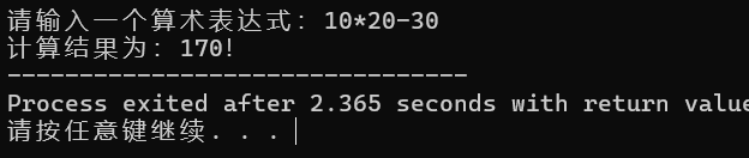
测试方案②:输入10+(20-5)/5
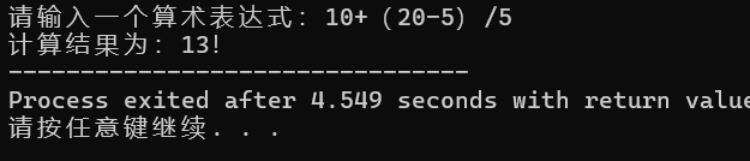
四、学习小结
在本次实验中,我根据属性定义编写预测翻译程序,以便对输入的符号串进行语法和语义分析,并计算各文法符号的语义值。通过编写预测翻译程序掌握属性定义的应用以及语义值的计算方法,并掌握预测翻译程序的构造方法,体会到了如何通过符号表、语义规则等手段将源代码转化为可执行的中间表示,过程中不仅要注重语法结构的正确性,还需要保证每个变量、常量、运算符等元素在不同阶段都能准确地表达其语义。
附录:主要方法的源代码
#include <ctype.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>typedef enum {TOKEN_NUMBER,TOKEN_PLUS,TOKEN_MINUS,TOKEN_MUL,TOKEN_DIV,TOKEN_LPAREN,TOKEN_RPAREN,TOKEN_EOF
} TokenType;typedef struct {TokenType type;double value;char lexeme[10];
} Token;Token* tokens;
int tokenIndex = 0;
Token* getNextToken() {// 假设有一个全局变量或成员变量 tokens 存储 Token 数组// 以及一个全局变量或成员变量 tokenIndex 作为当前令牌索引if (tokenIndex < 10) { // 假设有10个 Tokenreturn &tokens[tokenIndex++]; // 返回当前 Token 并递增索引}return NULL; // 如果没有更多 Token,返回 NULL
}void tokenize(const char* input) {tokens = malloc(10 * sizeof(Token));strcpy(tokens[0].lexeme, "10"); tokens[0].type = TOKEN_NUMBER;strcpy(tokens[1].lexeme, "20"); tokens[1].type = TOKEN_NUMBER;strcpy(tokens[2].lexeme, "*"); tokens[2].type = TOKEN_MUL;strcpy(tokens[3].lexeme, "30"); tokens[3].type = TOKEN_NUMBER;strcpy(tokens[4].lexeme, "-"); tokens[4].type = TOKEN_MINUS;strcpy(tokens[5].lexeme, "("); tokens[5].type = TOKEN_LPAREN;strcpy(tokens[6].lexeme, "20"); tokens[6].type = TOKEN_NUMBER;strcpy(tokens[7].lexeme, "-"); tokens[7].type = TOKEN_MINUS;strcpy(tokens[8].lexeme, "5"); tokens[8].type = TOKEN_NUMBER;strcpy(tokens[9].lexeme, ")"); tokens[9].type = TOKEN_RPAREN;tokenIndex = 10;
}void parseExpression() {Token* t = getNextToken();while (t != NULL) {switch (t->type) {case TOKEN_NUMBER:printf("Number: %s\n", t->value);break;case TOKEN_PLUS:printf("Plus\n");break;case TOKEN_MUL:printf("Multiply\n");break;// Add more cases for other tokens}t = getNextToken();}
}double evaluate() {double result = 0;Token* t = getNextToken();while (t != NULL) {switch (t->type) {case TOKEN_NUMBER:result = t->value;break;case TOKEN_PLUS:result += getNextToken()->value;break;case TOKEN_MUL:result *= getNextToken()->value;break;// Add more cases for other tokens}t = getNextToken();}return result;
}int main() {const char* expression = a;printf("请输入一个算术表达式:");tokenize(expression);parseExpression();printf("计算结果为:%f!\n", evaluate());return 0;
}