【KWDB 创作者计划】_深度学习篇---归一化反归一化
文章目录
- 前言
- 一、归一化(Normalization)
- 1. 定义
- 2. 常用方法
- Min-Max归一化
- Z-Score标准化(虽常称“标准化”,但广义属归一化)
- 小数缩放(Decimal Scaling)
- 3. 作用
- 4. 注意事项
- 二、反归一化(Denormalization)
- 1. 定义
- 2.方法
- 3. 应用场景
- 三、Python示例演示
- 四、归一化 vs. 标准化
- 五、常见问题
- 是否需要对所有特征归一化?
- 类别特征如何归一化?
- 时序数据如何归一化?
前言
本文简单介绍了归一化和反归一化。归一化和反归一化是数据预处理中的关键技术,尤其在机器学习和数据挖掘领域广泛应用。通过合理应用归一化和反归一化,能显著提升模型性能并确保结果可解释性。实际应用中需根据数据分布和模型需求选择方法。
一、归一化(Normalization)
1. 定义
归一化是将数据按比例缩放至特定范围(如[0, 1]或[-1, 1]),消除量纲差异,提升模型收敛速度和精度。
2. 常用方法
Min-Max归一化
范围:[0, 1]
适用场景:数据分布无明显边界(如图像像素值)。
Z-Score标准化(虽常称“标准化”,但广义属归一化)
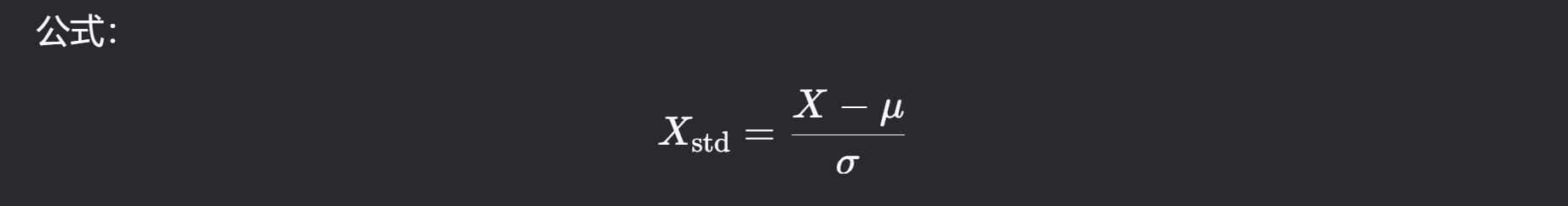 μ为均值,𝜎为标准差
μ为均值,𝜎为标准差
范围:无固定范围,数据均值为0,标准差为1
适用场景:数据存在高斯分布特征。
小数缩放(Decimal Scaling)
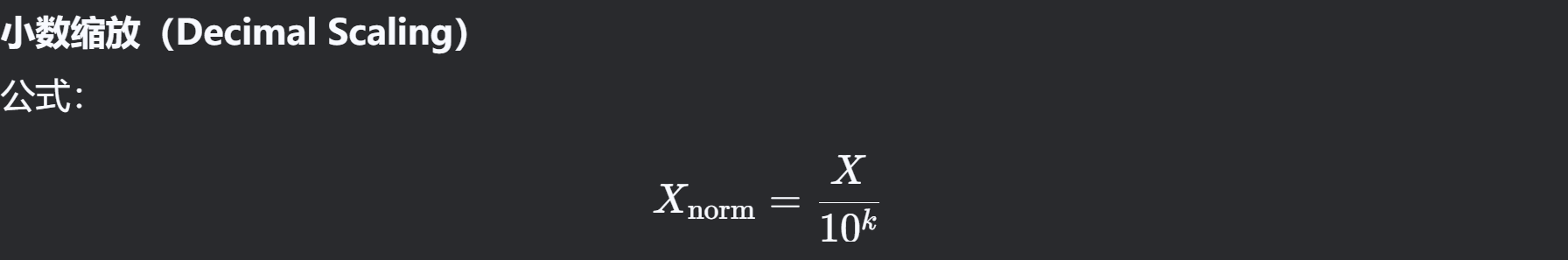
k为使最大值绝对值<1的最小整数
适用场景:数据跨度极大时。
3. 作用
- 加速梯度下降收敛
- 防止数值溢出
- 提升模型对特征的敏感性平衡(如SVM、KNN、神经网络)
4. 注意事项
测试数据需使用训练集的
𝑋min 、𝑋max或𝜇、𝜎,避