大语言模型的“模型量化”详解 - 01:原理、方法、依赖配置
基本介绍
随着大语言模型(LLM, Large Language Models)的广泛应用,从推理加速到边缘部署,模型量化(Quantization) 已成为模型压缩和加速的核心技术之一。本文将从基础原理、常用方法、工程落地和注意事项等多个方面,系统介绍大语言模型中的模型量化技术。
什么是模型量化?
模型量化是一种**将高精度浮点数(如 FP32)转换为较低位数表示(如 INT8、INT4、BF16 等)**的技术,目的是减小模型体积、加快推理速度、降低内存/显存使用,同时尽量保持模型精度。
简单来说,就是用更“紧凑”的方式来表示模型中的权重和激活值。
为什么需要量化?
- 📉 减少显存/内存使用:如 INT8 相比 FP32 可减少约 75% 的存储开销;
- 🚀 加速推理速度:低位计算指令可以被更快执行,尤其在 GPU / CPU / NPU 上;
- 🧳 便于部署:适合部署在边缘设备、手机、浏览器等低资源场景;
- 💰 降低成本:节省云计算资源,提升模型服务的吞吐能力。
量化的类型分类
PS:只介绍一部分

按数值精度分类
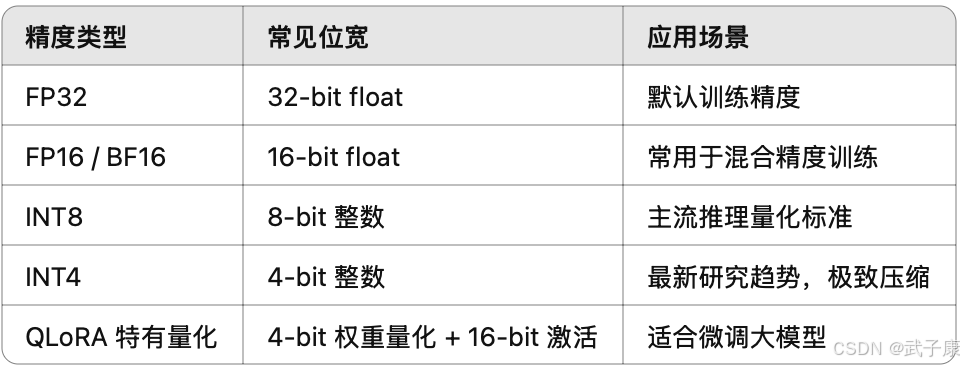
常见量化方法详解
逐层 vs 逐通道(Per-layer vs Per-channel)
- Per-layer:整个权重矩阵使用一个 scale,简单但可能失真较多。
- Per-channel:每个通道单独 scale,精度更高。
对称 vs 非对称量化
- 对称量化:正负值以相同尺度映射,适合分布中心在0附近的数据;
- 非对称量化:独立定义零点和 scale,适合偏移分布的数据。
动态 vs 静态量化
- 动态量化:推理时动态计算激活范围(如 transformer 的 Linear 层);
- 静态量化:提前统计激活的分布,适合固定输入场景。
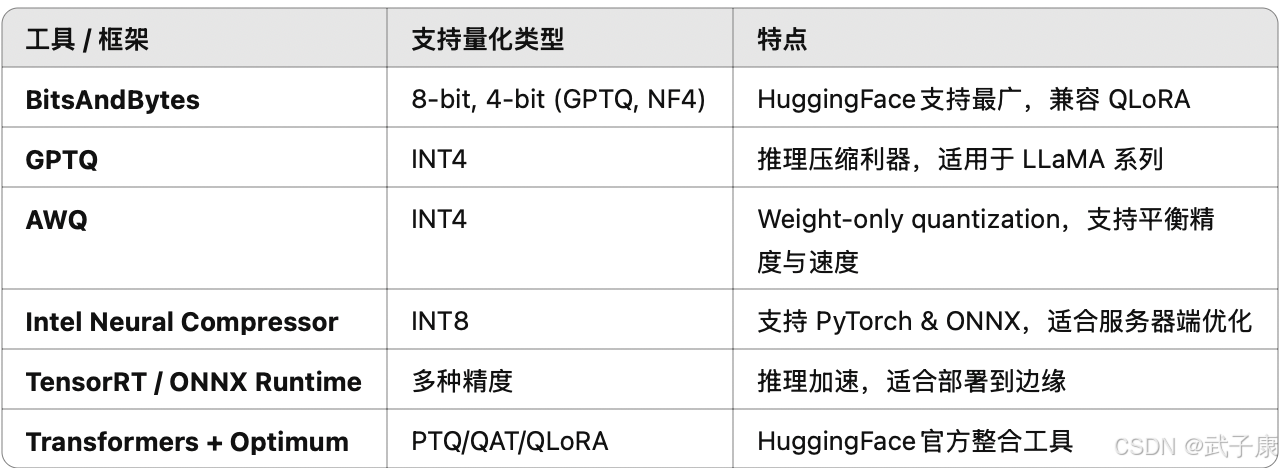
工程实践:量化 LLM 的工具链
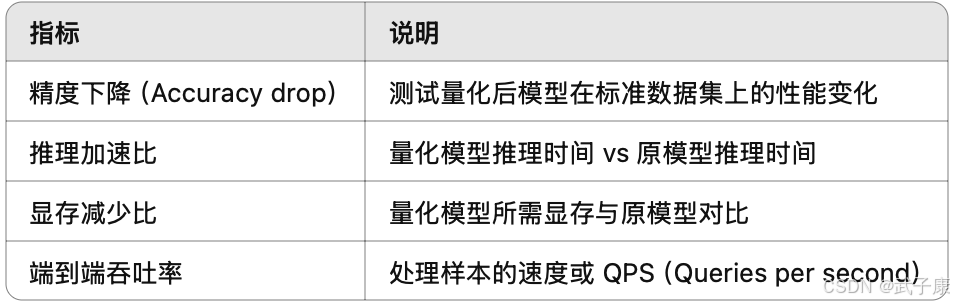
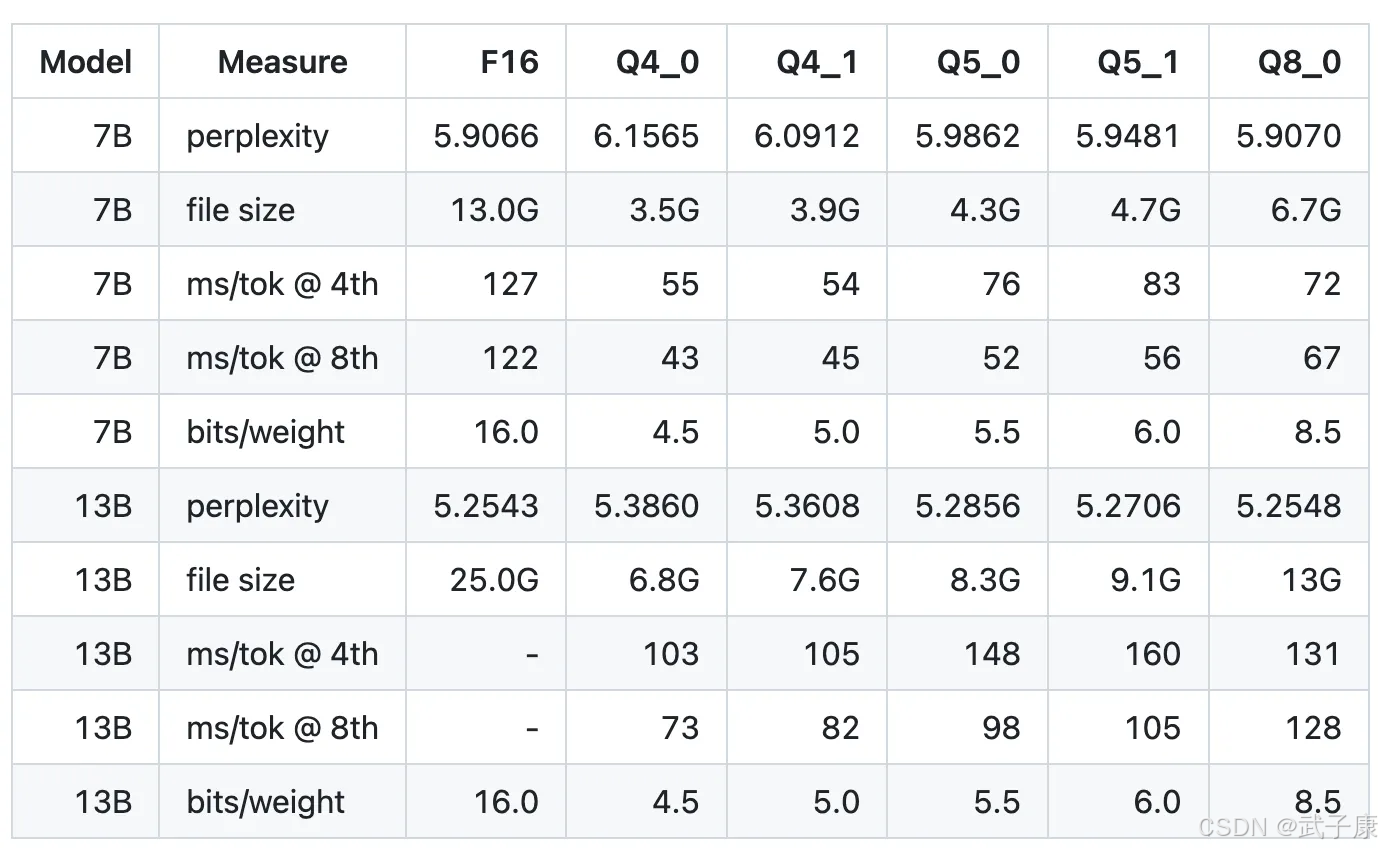
量化效果评估指标
实践中的挑战与建议
- 不要直接量化 LayerNorm、Embedding、Softmax 层;
- INT4/INT2 精度损失明显,推荐配合重排(reorder)或微调(LoRA/QLoRA);
- 激活量化容易导致退化,建议逐层检验;
- 量化策略需根据业务目标选择:精度优先 or 性能优先;
- 注意目标硬件支持情况(如 GPU、ARM、NPU)
参考资料
- 官方资料:https://github.com/ggml-org/llama.cpp/tree/master/examples/main
- llama.cpp
- 量化部署资料:https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/llama.cpp%E9%87%8F%E5%8C%96%E9%83%A8%E7%BD%B2
- 量化效果:https://github.com/ggml-org/llama.cpp/blob/master/examples/quantize/README.md
克隆项目
需要借助 llama.cpp 进行量化
git clone https://github.com/ggerganov/llama.cpp.git
cd llama
拉取项目:
安装依赖
确保下面的依赖都是有的:
pip install torch transformers sentencepiece
编译工具
我们需要编译llama.cpp的工具,才可以进行量化处理:
下面是官方的编译文档,需要的话可查看:
https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md
这里我们执行进行操作:
# 此时在 llama.cpp 目录下 进行编译
mkdir build
cd build
cmake ..
cmake --build . --config Release
开始编译:
过程是比较漫长的: