OCR之身份证识别
前言
OCR身份证识别是光学字符识别技术在身份证领域的应用。通过扫描或拍照获取身份证图像,利用图像处理、深度学习等技术,自动提取姓名、性别、民族、出生日期、地址、身份证号等信息,可大幅提升信息录入效率,广泛应用于政务、金融、酒店等场景,保障身份核验的准确性与便捷性。
一、环境
语言:Pytnon
开发工具:PyCharm
二、在线测试
秒级识别,准确率高达99%,测试地址:http://47.108.177.251:9000。(由于当前租用的云服务性能存在局限性,导致识别速度稍显迟缓,在普通办公电脑部署测试验证,识别结果可在 3 秒内输出。)
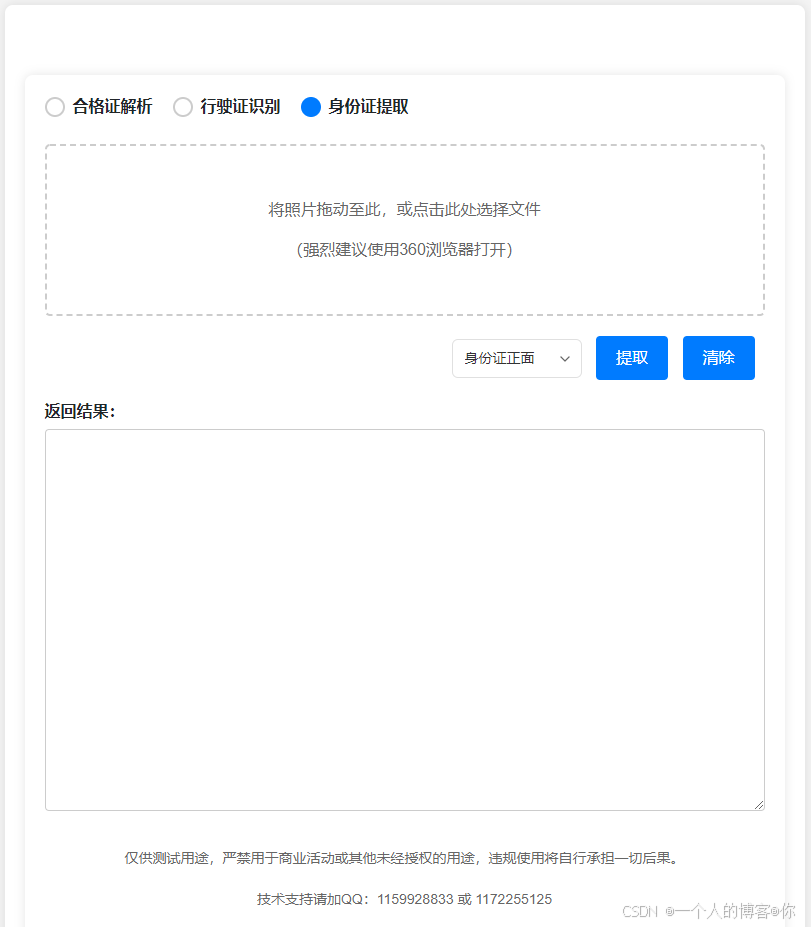
三、核心技术
其技术也是介于上一行驶证识别的基础上,重新训练而成。可参考下面的链接:OCR之行驶证识别-CSDN博客文章浏览阅读554次,点赞6次,收藏6次。使用OCR(光学字符识别)提取行驶证上的文字,OCR技术在行驶证识别中的应用已经非常广泛,基于深度学习算法,通过训练大量样本数据,使模型具备图像分类、目标检测和文字识别能力,在行驶证识别中,首先对行驶证图像进行预处理,包括灰度化、二值化、去噪等操作,以提高图像清晰度和识别率,然后对图像中的文字进行定位、分割和识别。https://blog.csdn.net/weixin_42148410/article/details/146560403?fromshare=blogdetail&sharetype=blogdetail&sharerId=146560403&sharerefer=PC&sharesource=weixin_42148410&sharefrom=from_link
import cv2
import pytesseractdef ocr_local(image_path):# 读取图像img = cv2.imread(image_path)# 预处理(按需调整)gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]# 设置中文识别(需要下载chi_sim训练数据)custom_config = r'--oem 3 --psm 6 -l chi_sim'text = pytesseract.image_to_string(thresh, config=custom_config)return text# 使用示例
print(ocr_local('身份证照片.jpg'))from aip import AipOcr# 配置百度OCR应用信息
APP_ID = '你的APP_ID'
API_KEY = '你的API_KEY'
SECRET_KEY = '你的SECRET_KEY'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)def ocr_vehicle_license(image_path):# 读取图片with open(image_path, 'rb') as f:image = f.read()# 调用行驶证识别接口result = client.vehicleLicense(image)# 解析结果if 'words_result' in result:data = {}for key, value in result['words_result'].items():data[key] = value['words']return dataelse:return None# 使用示例
if __name__ == '__main__':image_path = '身份证照片.jpg'result = ocr_vehicle_license(image_path)if result:print(f"姓名:{result.get('name', '')}")print(f"性别: {result.get('sex', '')}")print(f"民族: {result.get('ethnicity', '')}")print(f"住址: {result.get('address', '')}")print(f"身份证号: {result.get('IDCardNum', '')}")else:print("识别失败")注意:
-
百度API版本需要网络
-
本地版需要安装Tesseract并下载中文语言包(应用场景更广泛)
-
实际应用中需要根据行驶证版式添加图像预处理和结果解析逻辑