FFCV性能优化——快速加载大规模图像数据训练
官方地址:https://github.com/libffcv/ffcv
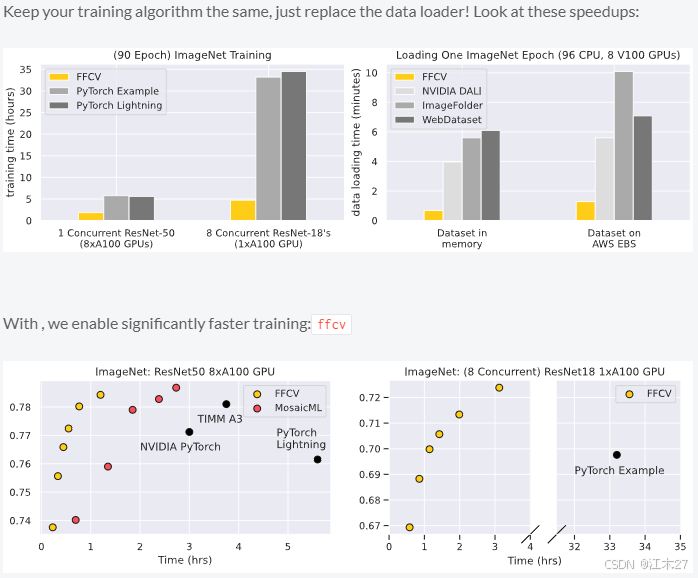
ffcv是一种直接数据加载系统,可显著提高模型训练中的数据吞吐量:
在 35 分钟内在一个 GPU 上训练一个 ImageNet 模型(AWS 上每个模型 98 美分)
在 36 秒内在一个 GPU 上训练一个 CIFAR-10 模型(在 AWS 上为每个模型 2 美分)
环境搭建
参考官方文档:https://docs.ffcv.io/
- conda-forge
conda create -n ffcv python=3.10 pkg-config opencv -c conda-forge --override-channels
conda activate ffcv
- 作用:pkg-config 能正确找到 opencv4.pc,否则无法编译ffcv
- torch
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidia
- ffcv
pip install ffcv
具体流程
这里就不以官方例子举例了,可以在官方文档看到,下面是我自己整理的一些过程
1将数据保存成ffcv格式
from ffcv.writer import DatasetWriter
from ffcv.fields import RGBImageField
from torchvision import transforms
from PIL import Image
from torch.utils.data import Dataset
import osclass ImagePairDataset(Dataset):def __init__(self, input_dir, target_dir, transform=None):self.input_dir = input_dirself.target_dir = target_dirself.transform = transformself.filenames = sorted(os.listdir(input_dir))def __len__(self):return len(self.filenames)def __getitem__(self, idx):input_path = os.path.join(self.input_dir, self.filenames[idx])target_path = os.path.join(self.target_dir, self.filenames[idx])input_img = Image.open(input_path).convert('RGB')target_img = Image.open(target_path).convert('RGB')if self.transform:input_img = self.transform(input_img)target_img = self.transform(target_img)# Return PIL images directlyreturn input_img, target_img# 数据集路径
input_dir = 'xx/input/'
target_dir = 'xx/target/'dataset = ImagePairDataset(input_dir, target_dir, transform=None)
writer = DatasetWriter('dataset.beton', {'input': RGBImageField(write_mode='smart'),'target': RGBImageField(write_mode='smart')
})
writer.from_indexed_dataset(dataset)2测试是否转换成功
from ffcv.loader import Loader, OrderOptionloader = Loader('dataset.beton', batch_size=32, num_workers=4, order=OrderOption.RANDOM)for batch in loader:print(type(batch)) input_images, target_images = batch[0], batch[1] print(input_images.shape, target_images.shape)break3替换pytorch的dataload
train_loader = Loader(dataset_setting["beton_path"],batch_size=args.batch_size,num_workers=4,order=OrderOption.RANDOM,pipelines={'input': [SimpleRGBImageDecoder(), ToTensor(), # tensorToTorchImage(), # chwToTensor(), # tensorConvert(torch.float32), # floattorchvision.transforms.Normalize(CIFAR_MEAN, CIFAR_STD),ToDevice(torch.device('cuda:0'))],#, ToDevice('cuda:0')],'target': [SimpleRGBImageDecoder(), ToTensor(),ToTorchImage(),Convert(torch.float32),torchvision.transforms.Normalize(CIFAR_MEAN, CIFAR_STD),ToDevice(torch.device('cuda:0'))],#, ToDevice('cuda:0')],},drop_last=True,# os_cache=False)
4自定义pipelines算子
- 在3中,大部分常用的tensor操作官方是实现了的,同时还有很多基于不同类型数据集对应的保存格式,这里不详细展开。
- 在使用过程中我难免会遇到一些需要自己实现的前处理和数据增强等,官方的实现还是有限的。
- 在实现过程中我们只要记住以下几点就可以添加自己的处理操作
- 必须在方法后面添加
declare_state_and_memory方法否则无法编译
def declare_state_and_memory(self, previous_state: State):
# 声明当前 transform 的输出状态(比如 shape, dtype 是否改变)
# 声明需要多少额外内存空间(比如预先开辟 buffer,就要开内存)
- 方法继承
from ffcv.pipeline.operation import Operation - 简单的例子,一个normlize操作
class NormalizeFirstChannel(Operation):def __init__(self, mean, std):super().__init__()self.mean = meanself.std = stddef generate_code(self):mean = self.meanstd = self.stddef process(images, *_):B, C, H, W = images.shapefor i in range(B):images[i, 0, :, :] = (images[i, 0, :, :] - mean) / stdreturn imagesreturn processdef declare_state_and_memory(self, previous_state: State):return previous_state, 0
总结
本文在流程上相比与官方文档感觉更加清晰一些,当然并不是使用ffcv就一定提速,在大规模数据可能效果更显著。