CONDA:用于 Co-Salient 目标检测的压缩深度关联学习(总结)
摘要
一 介绍
二 有关工作
三 提出的方法
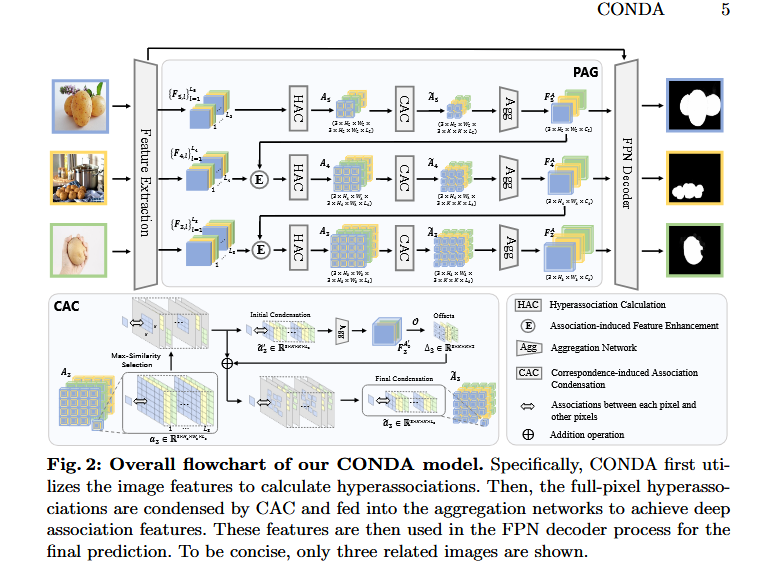
图2:我们的凝聚式深度关联(CONDA)模型的整体流程图。具体来说,凝聚式深度关联(CONDA)模型首先利用图像特征来计算超关联。然后,全像素超关联由对应诱导关联凝聚(CAC)模块进行凝聚,并输入到聚合网络中,以获得深度关联特征。这些特征随后在特征金字塔网络(FPN)解码器过程中用于最终的预测。为简洁起见,图中仅展示了三张相关图像。
问题一:这张图的流程是什么?
这张图展示的是 CONDA模型(Correspondence-induced Association Network for Dense Prediction) 的完整工作流程,其核心是通过 超关联计算(HAC)→ 对应诱导关联凝聚(C
AC)→ 聚合网络(Agg) 的三阶段处理,实现多图像间的深度关联特征提取与预测。
1. 输入与特征提取
-
输入图像:三张不同场景的图像(如水果、室内、手部),尺寸统一为 H×W×3。
-
特征提取:
-
通过共享权重的 骨干网络(如ResNet)提取多尺度特征:
-
输出特征图
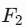 (浅层细节)和
(浅层细节)和 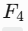 (高层语义),尺寸分别为
(高层语义),尺寸分别为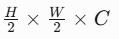 和
和 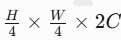 。
。
-
-
2. 超关联计算(HAC: Hyperassociation Calculation)
-
功能:计算图像内所有像素间的全局关联矩阵,捕捉长程依赖关系。
-
操作流程:
-
对特征图
和 分别展开为像素向量 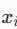 (尺寸 N×C,N=HW/4 或 HW/16)。
(尺寸 N×C,N=HW/4 或 HW/16)。 -
通过矩阵乘法生成关联矩阵 A(图中标注 A5 和 A4):
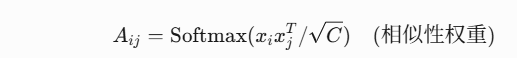
-
输出多尺度超关联图 A5(来自
)和 A4(来自 )。
-
3. 对应诱导关联凝聚(CAC: Correspondence-induced Association Condensation)
-
功能:对超关联矩阵进行稀疏化凝聚,保留强关联区域。
-
子步骤(对应下半部分详解):
-
初始凝聚(Initial Condensation):对关联矩阵 A 按行取Top-k值,生成稀疏矩阵 A′。
-
最大相似性选择(Max-Similarity Selection):筛选每行最大关联值对应的像素对,形成初始关联对集合 P。
-
关联诱导特征增强(Association-induced Feature Enhancement):对关联对 P 的特征进行加权融合(图中 ⊕ 表示逐元素加):
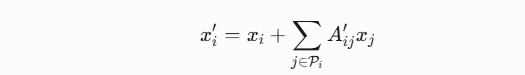
-
最终凝聚(Final Condensation):输出优化后的稀疏关联特征 F3 和 F4′。
-
4. 聚合网络(Agg: Aggregation Network)
-
功能:融合多尺度关联特征,生成深度关联表示。
-
操作:
-
将 F3、F4′ 和原始特征 F2、F4 通过跨尺度连接(图中灰色箭头)输入聚合网络。
-
输出统一的高维特征 Fagg(尺寸 4H×4W×4C)。
-
5. 预测生成(FPN Decoder & PAG)
-
FPN Decoder:基于特征金字塔结构上采样 Fagg,逐步恢复空间分辨率至 H×W。
-
PAG(聚合生成):通过跳跃连接融合浅层特征 F2,生成最终预测图(如云朵状概率图或白色轮廓掩码)。
6. 输出与监督
-
输出形式:
-
三张预测图(与输入对应),形式可能为:
-
云朵状概率图(低置信度区域模糊化)。
-
二值化轮廓掩码(高置信度区域锐化)。
-
-
-
损失函数:结合交叉熵损失(CE)和Dice损失优化边界精度。
7. 关键设计亮点
-
跨图像关联建模:HAC和CAC模块显式建模像素级长程依赖,适用于多图像协同分析。
-
动态稀疏化:CAC通过Top-k选择保留强关联,提升计算效率。
-
多尺度融合:Agg网络整合不同层级特征,兼顾细节与语义。
8. 图示符号对照表