Whisper微调及制作方言数据集
本文不生产技术,只做技术的搬运工!!!
前言
最近在进行whisper微调实验,这个网上有很多成功案例,作者随机找了一个进行了复现,但是由于微调目的是适配本地方言,数据集的采集成为了一个重点难题,既要录制音频,又要打好标签,费时费力,作者开发了一个小软件,可以在录制音频时,将文本写入到标注文件中,进行快速音频采集标注(其实是多次一举,因为本来文本就是预先设定好的,直接录制完音频把念的稿子复制到标注文件里即可,作者这么做主要是想方便音频采集,因为作者不想手动改音频文件的名称,又想采集出来的音频以开始时间-结束时间.wav的形式保存)。
微调框架
https://github.com/yeyupiaoling/Whisper-Finetune![]() https://github.com/yeyupiaoling/Whisper-Finetune大家自行配置即可,这个作者应该是中国人,写了中文版的ReadMe,整体很清晰明了
https://github.com/yeyupiaoling/Whisper-Finetune大家自行配置即可,这个作者应该是中国人,写了中文版的ReadMe,整体很清晰明了
原始数据采集
作者使用前言中提到的软件进行数据采集,采集完成后的原始数据如下图所示

每个wav文件都是一段录音,txt中包含了该段文本,如下图所示

数据处理脚本
import os
import json
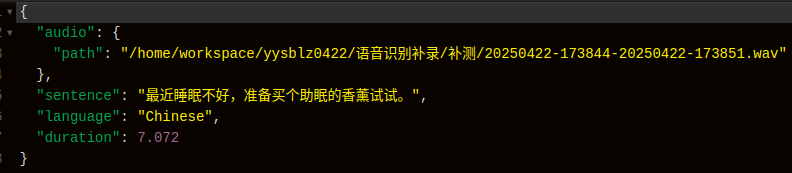
import wavedef get_wav_duration(wav_path):"""获取WAV文件的时长(秒)。参数:wav_path (str): WAV文件的路径。返回:float: WAV文件的时长(秒)。"""with wave.open(wav_path, 'rb') as wav_file:frames = wav_file.getnframes()rate = wav_file.getframerate()duration = frames / float(rate)return durationdef getFileList(dir, Filelist, ext=None):"""获取文件夹及其子文件夹中文件列表输入 dir:文件夹根目录输入 ext: 扩展名返回: 文件路径列表"""newDir = dirif os.path.isfile(dir):if ext is None:Filelist.append(dir)else:if ext in dir:Filelist.append(dir)elif os.path.isdir(dir):for s in os.listdir(dir):newDir = os.path.join(dir, s)getFileList(newDir, Filelist, ext)return Filelistif __name__ == '__main__':path = "/home/workspace/yysblz0422/语音识别补录/补验"file_path = "val.jsonl"wav_path_list = []wav_path_list = getFileList(path,wav_path_list , ".wav")data = []for wav_path in wav_path_list:template = {"audio": {"path": "dataset/0.wav"}, "sentence": "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。","language": "Chinese", "duration": 7.37}txt_path = wav_path.replace(".wav",".txt")with open(txt_path,"r") as f:template["sentence"] = f.read()template["audio"]["path"] = wav_pathtemplate["duration"] = get_wav_duration(wav_path)data.append(template)# 打开文件,使用写入模式with open(file_path, "w", encoding="utf-8") as jsonl_file:# 遍历数据列表,逐行写入 JSON 对象for item in data:# 将字典转换为 JSON 格式的字符串json_str = json.dumps(item, ensure_ascii=False)# 写入 JSON 字符串,换行分隔jsonl_file.write(json_str + "\n")print(f"数据已成功写入 {file_path}")
处理完成后,数据格式如下
采集软件展示
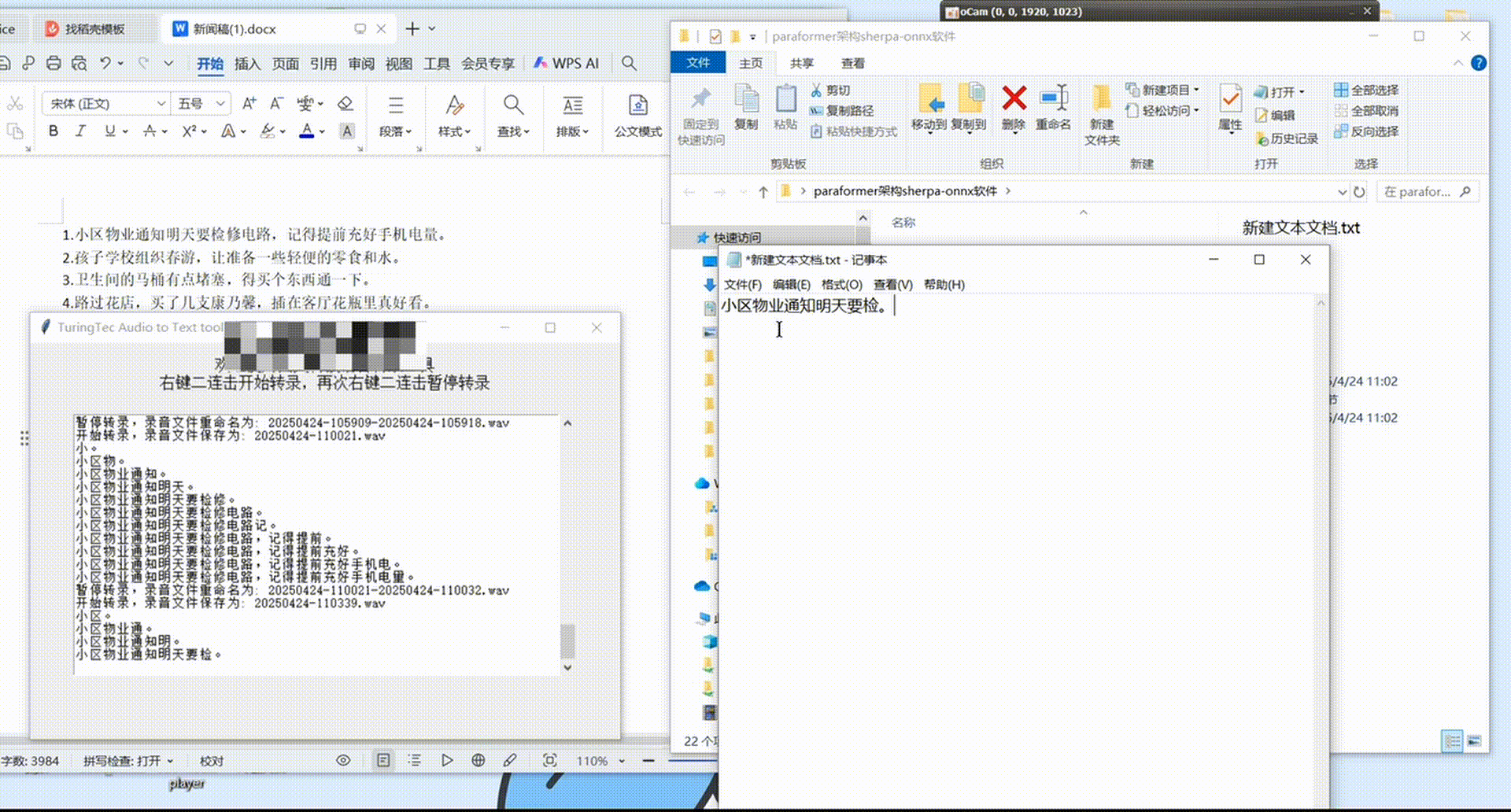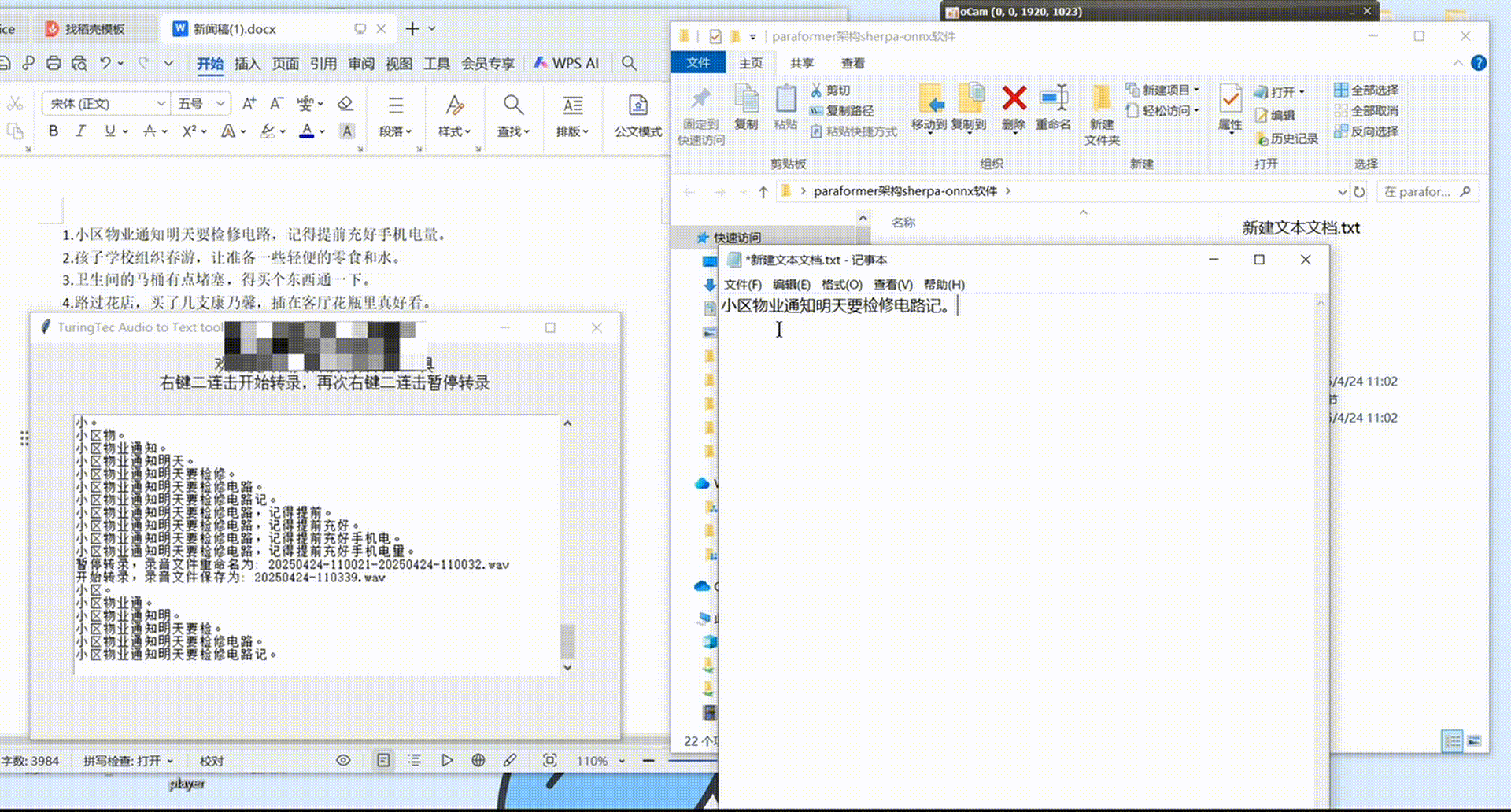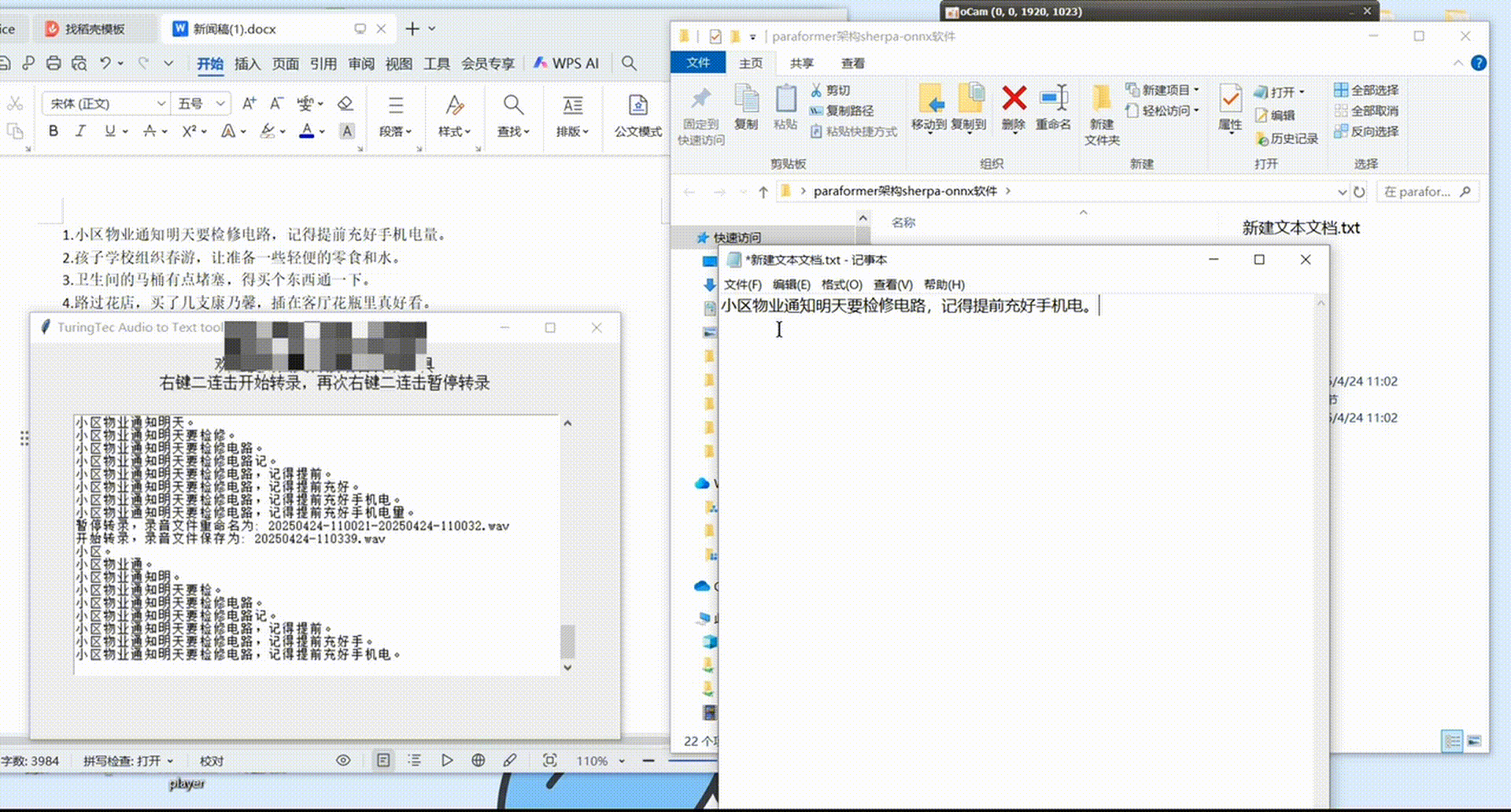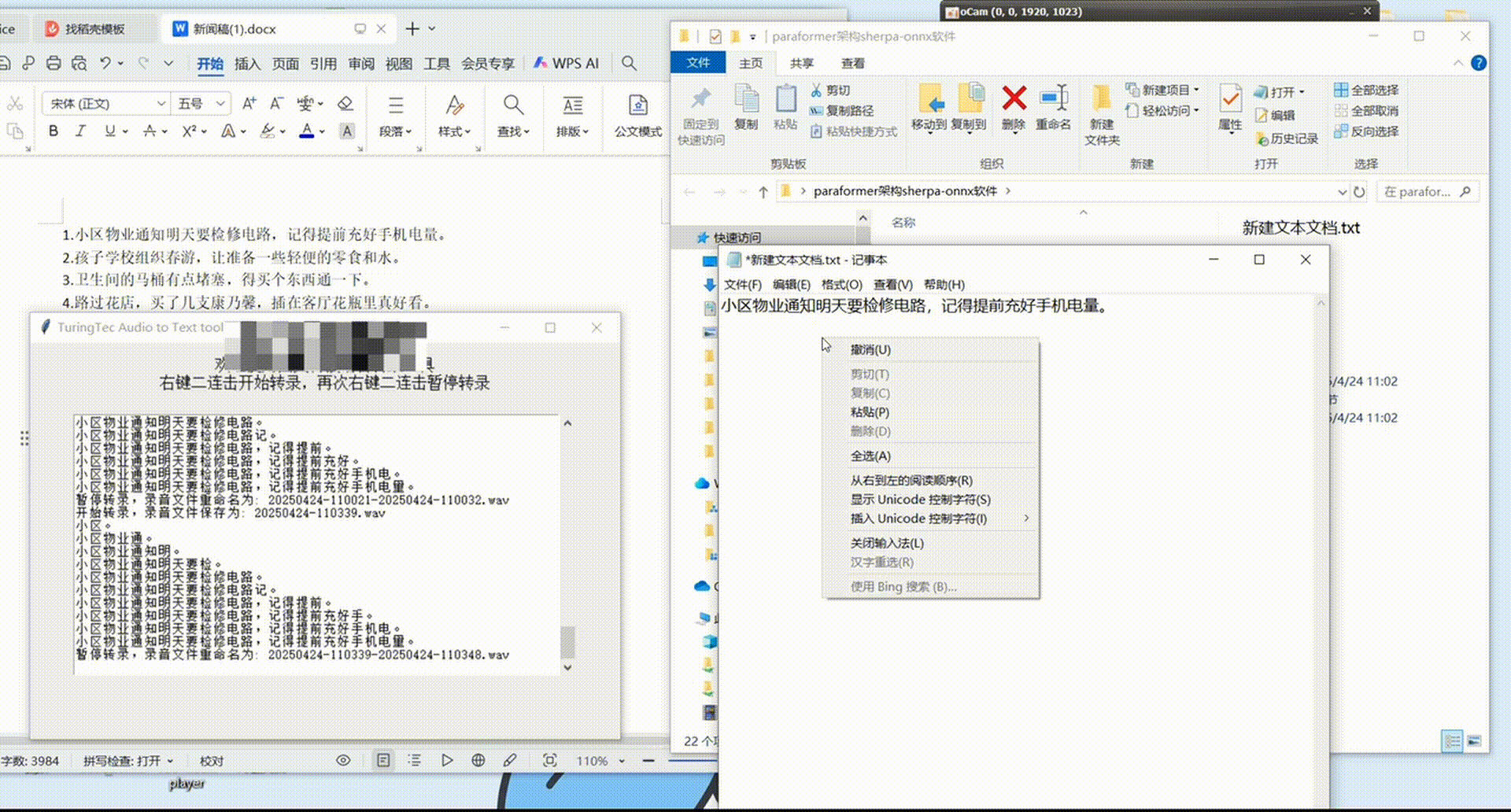
该软件可实现快速数据标注,同时也是一个非常好用的离线实时麦克风语音转文本工具,有软件需求或软件源代码需求的朋友可私聊作者。