大语言模型的“模型量化”详解 - 02:量化参数 主流量化参数全面解读与实战-Q/K/IQ/TQ 到 GGUF 的完整流程
上一节的进度
在大语言模型落地部署的过程中,模型量化已成为不可或缺的一环。它能在不显著损失模型效果的前提下,大幅压缩模型体积、降低推理资源消耗,尤其适用于显存受限的场景。
在上一篇中,我们已经完成了环境搭建与基础命令的解读,本节将深入探索常见的量化参数体系、实际的转换流程,并使用 Ollama 加载本地量化模型,完成一次完整的轻量部署过程。
无论你是部署在 GPU、CPU,还是低配设备上,相信这篇文章都能帮你找到合适的量化方案。
量化参数
在当前大模型走向轻量化部署的浪潮中,模型量化成为不可回避的环节。它不仅能降低显存需求,还能加快推理速度,并在边缘设备(如低配服务器、个人电脑)中实现高效推理。本篇将围绕 GGUF 量化方案展开,从原始模型格式到 Ollama 端到端部署,涵盖理论理解与工程实践。
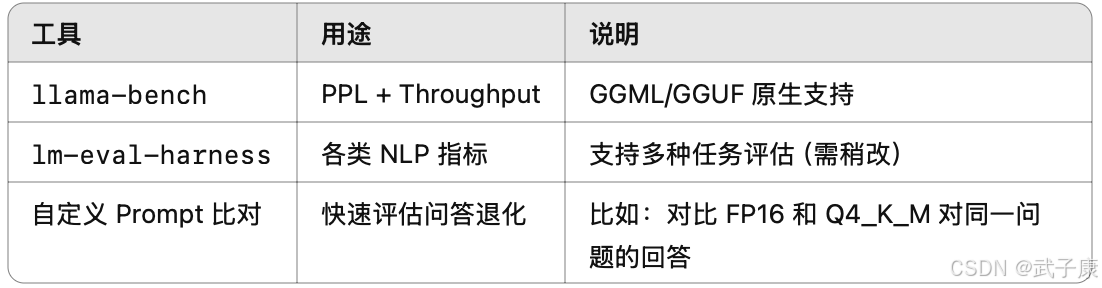
常见参数
整理了一下常见的量化配置参数如下:
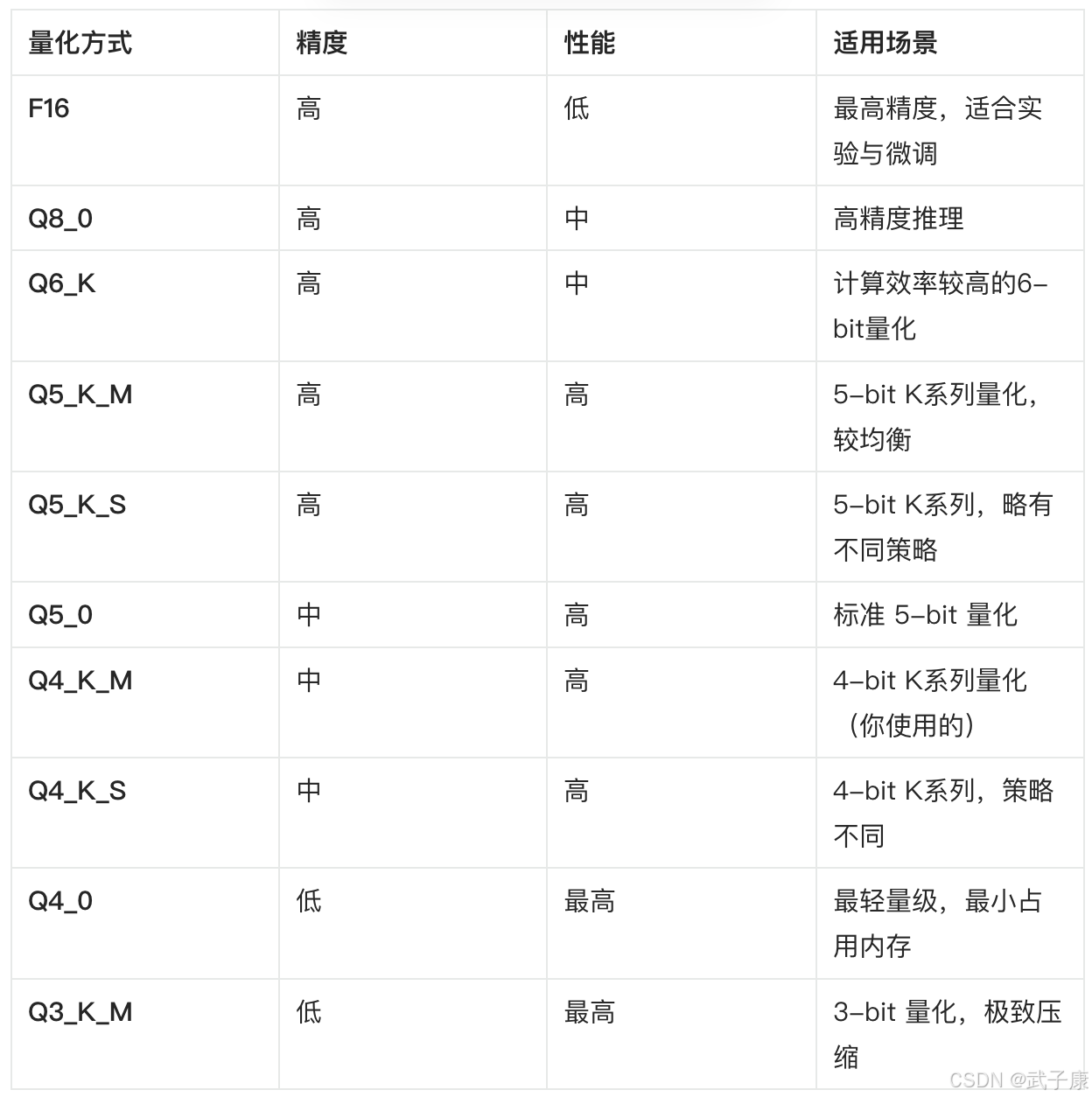
所有参数
如果你有更具体的需要,可以使用如下查看:
./build/bin/llama-quantize --help
可以看到的配置:
参数解读
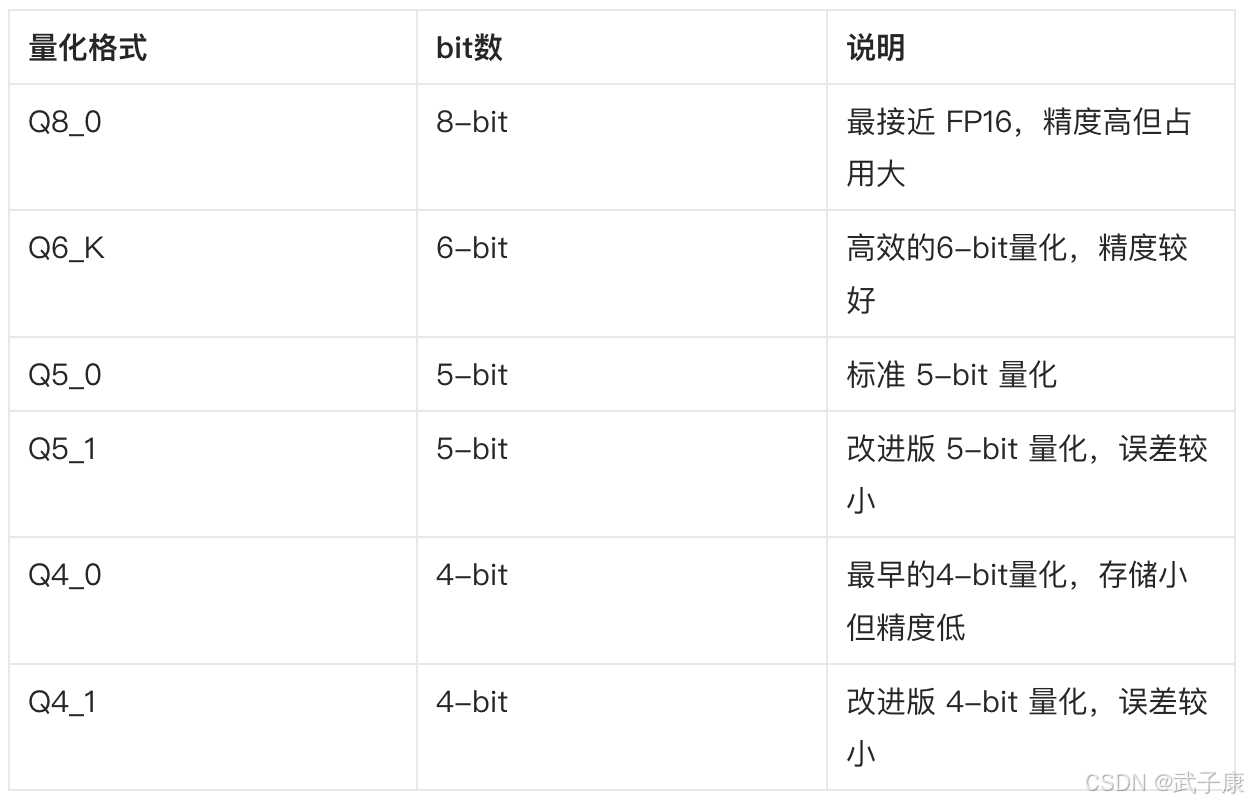
Q系列
比较传统和经典的方式:
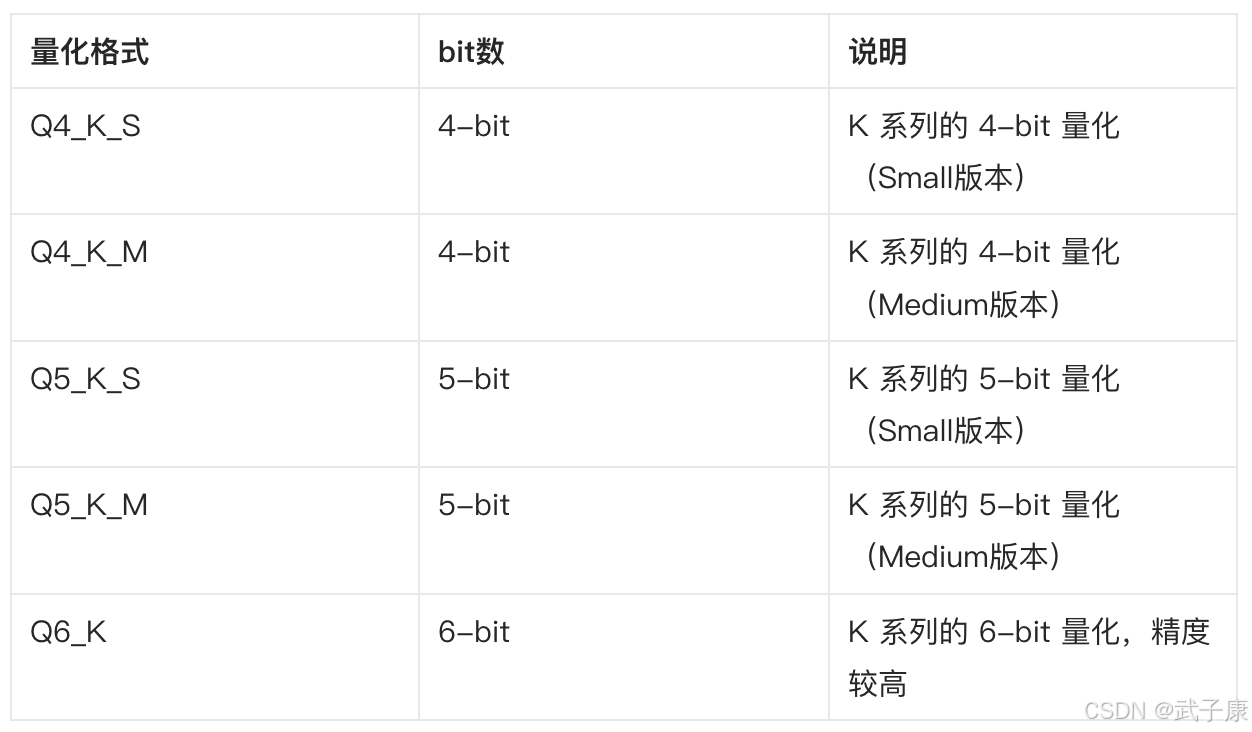
K系列
现代优化的量化方式,减少精度损失,适合用于推理。
IQ
IQ 系列是 整数量化(Integer Quantization),例如 IQ2, IQ3, IQ4 采用不同的比特存储策略。
IQ2_XS、IQ3_M、IQ4_NL 等都是更极端的量化策略,适用于极低显存情况。
TQ
TQ1_0 / TQ2_0 是 三值量化(Ternary Quantization),每个权重只能取 -1, 0, 1 的值,非常节省存储但精度低。
对比系列
- Q4_0 和 Q4_1 是早期量化方式,精度相对较低。
- Q4_K_M 和 Q5_K_M 是更现代的 K-Block 量化,能在 保持计算效率的同时减少精度损失。
- K 系列的 S(Small) 和 M(Medium) 版本指的是不同的权重块大小,M通常比S精度更高。
查看参数
./build/bin/llama-print-metadata xxx.gguf
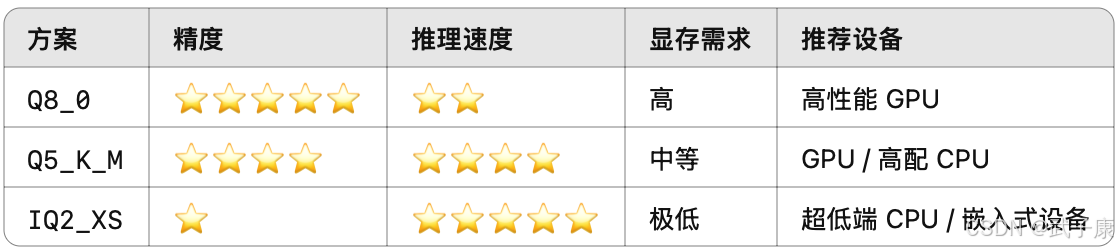
如何选择
- 高精度(接近原始 FP16):Q8_0, Q6_K
- 平衡方案(精度+推理速度):Q5_K_M, Q4_K_M
- 极致优化(低显存占用):Q4_0, Q3_K_M, IQ2_XS, IQ1_S
GPT的推荐意见:
- 如果你是 GPU 显存足够,可以用 Q6_K 或 Q5_K_M;
- 如果你是 CPU 推理,建议 Q4_K_M 或 Q5_K_M;
- 如果你是 极端低显存设备,可以尝试 Q3_K_M 或 IQ2_XS。
GGUF
我们需要先将原模型的格式转换为 GGUF,目前我的模型是 huggingface 的格式。
我们需要使用的脚本是,huggingface to gguf:
convert_hf_to_gguf.py
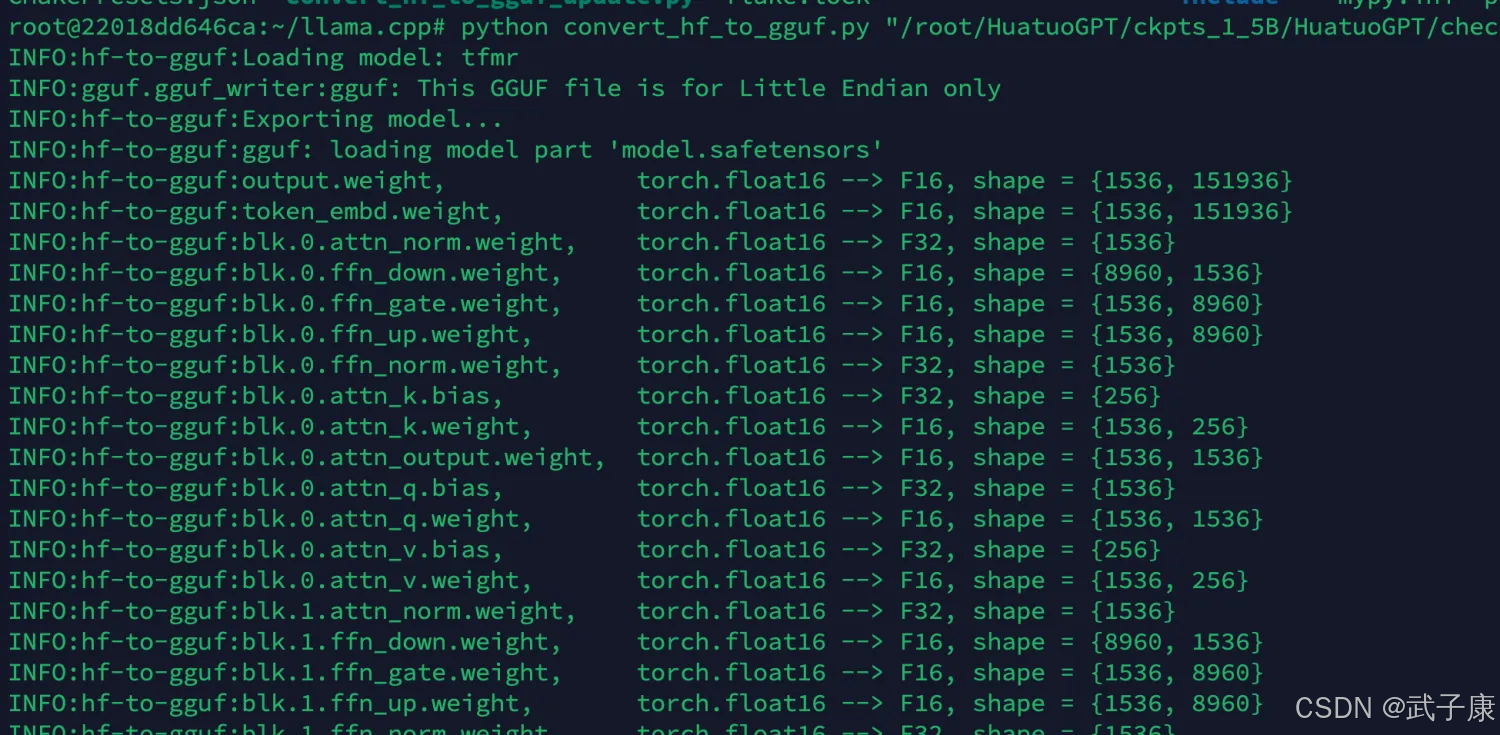
我们需要输入一些参数来保证,FP16 GGUF,还要指定是 FP16:
python convert_hf_to_gguf.py "/root/HuatuoGPT/ckpts_1_5B/HuatuoGPT/checkpoint-0-22604/tfmr" --outtype f16
转换过程如下所示:
转换完毕可以看到转换的存储目录:
目录在这里:
/root/HuatuoGPT/ckpts_1_5B/HuatuoGPT/checkpoint-0-22604/tfmr/Tfmr-1.8B-F16.gguf
我们查看目录
量化处理
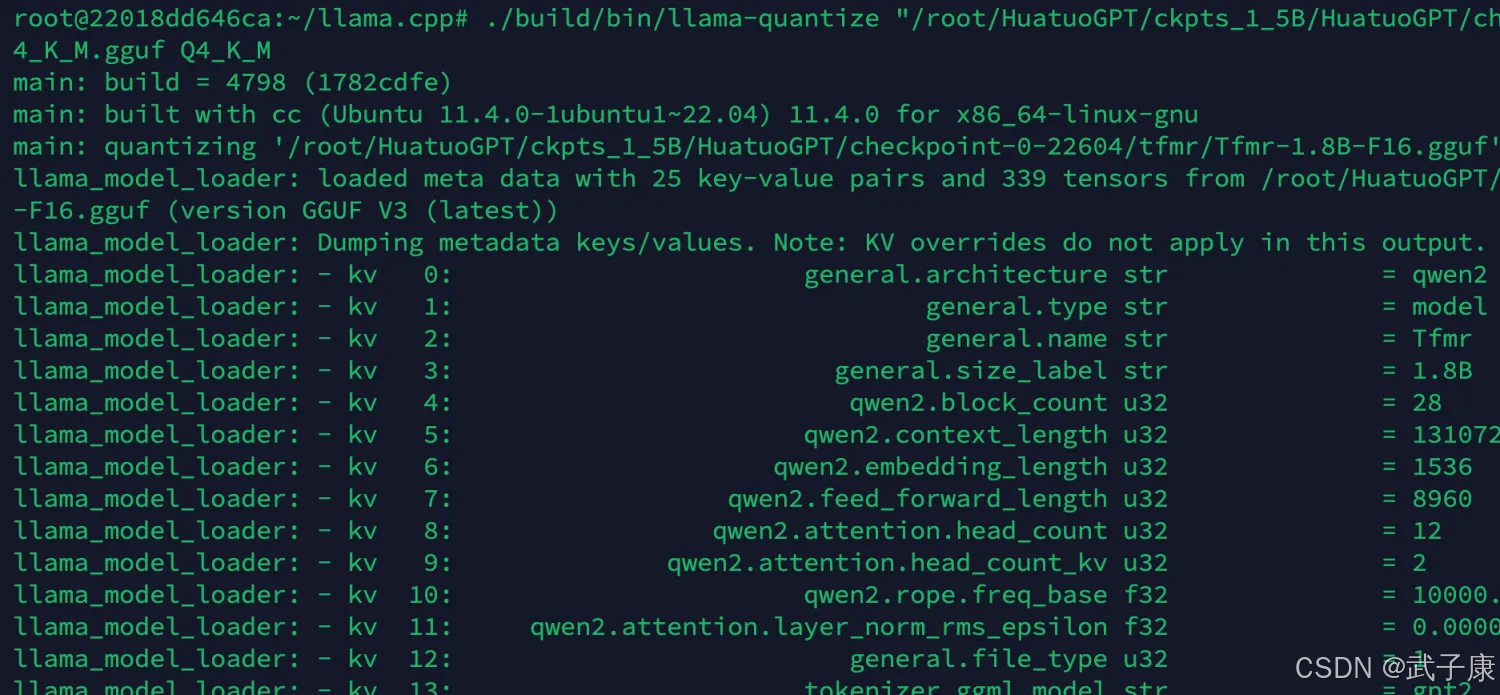
我们要将刚才转换好的 GGUF 量化为 Q4_K_M:
./build/bin/llama-quantize "/root/HuatuoGPT/ckpts_1_5B/HuatuoGPT/checkpoint-0-22604/tfmr/Tfmr-1.8B-F16.gguf" deepseek-d-qwen1_5B_q4_K_M.gguf Q4_K_M
如果顺利的话,可以看到如下的效果:
最终大小:
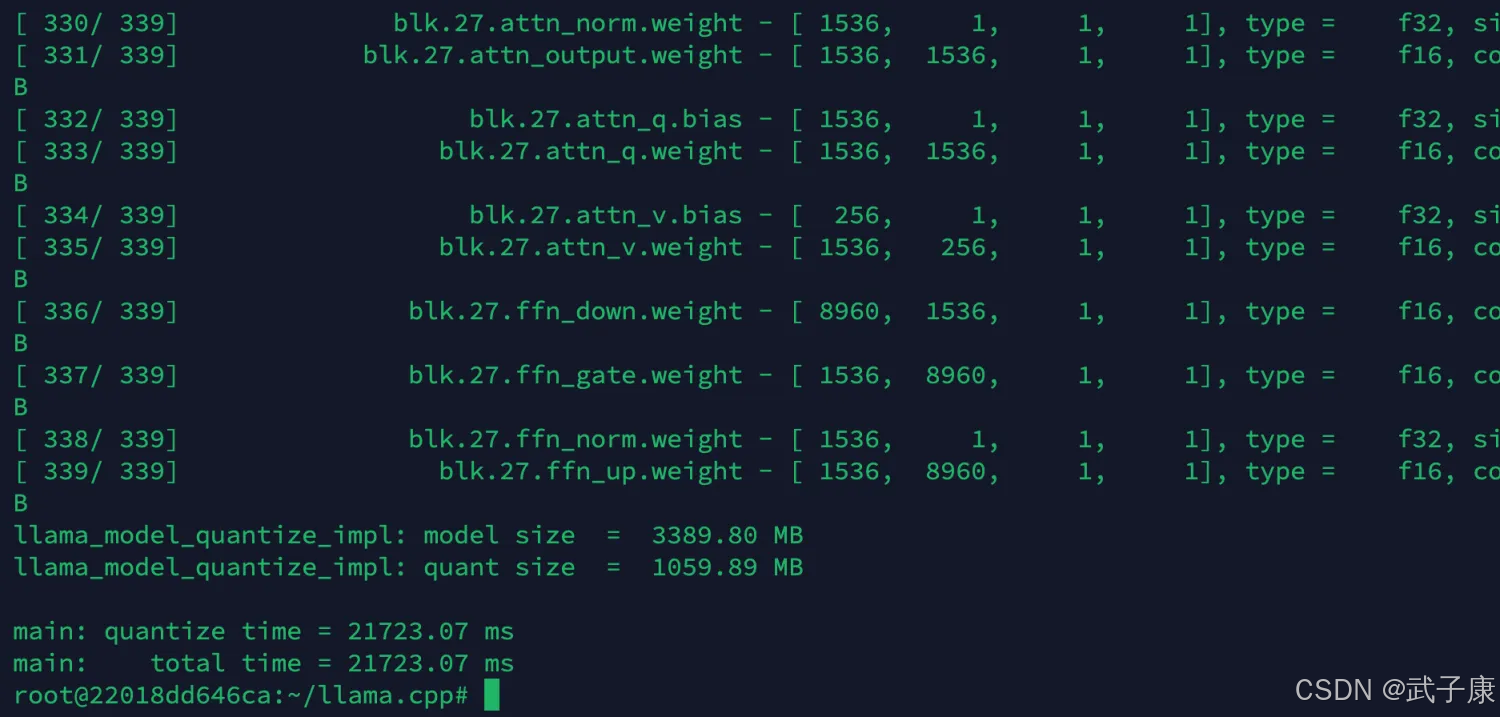
加载模型
我们将量化后的模型,加载进 Ollama:
ollama create deepseel-d-qwen1-5B-sft --path /Users/wuzikang/Desktop/deepseek-d-qwen1_5B_q4_K_M.gguf
这里是 MacMini 16GB(其他操作系统也一样),我们将模型拷贝过来:
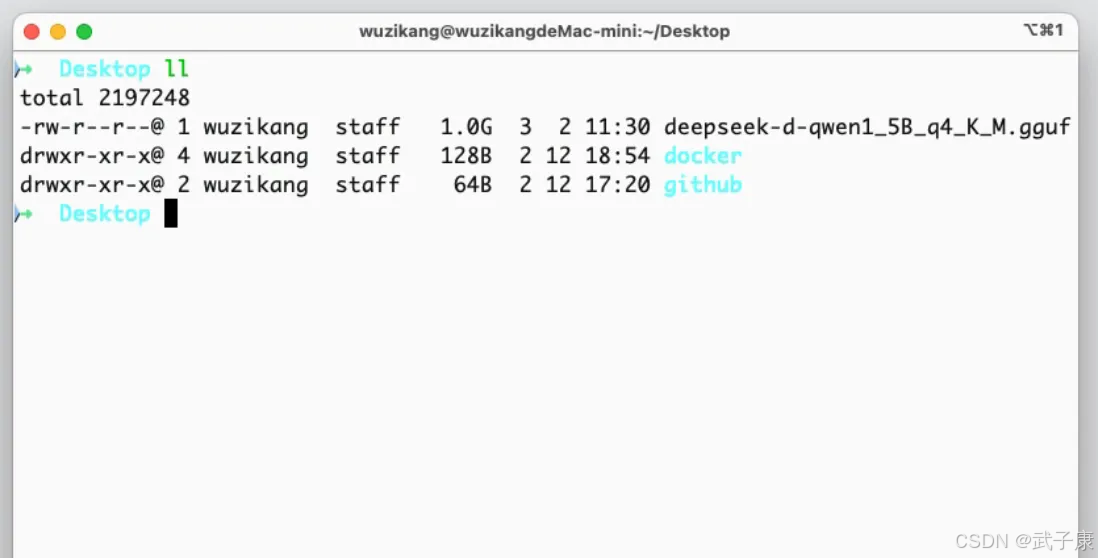
ollama create 模型的名字
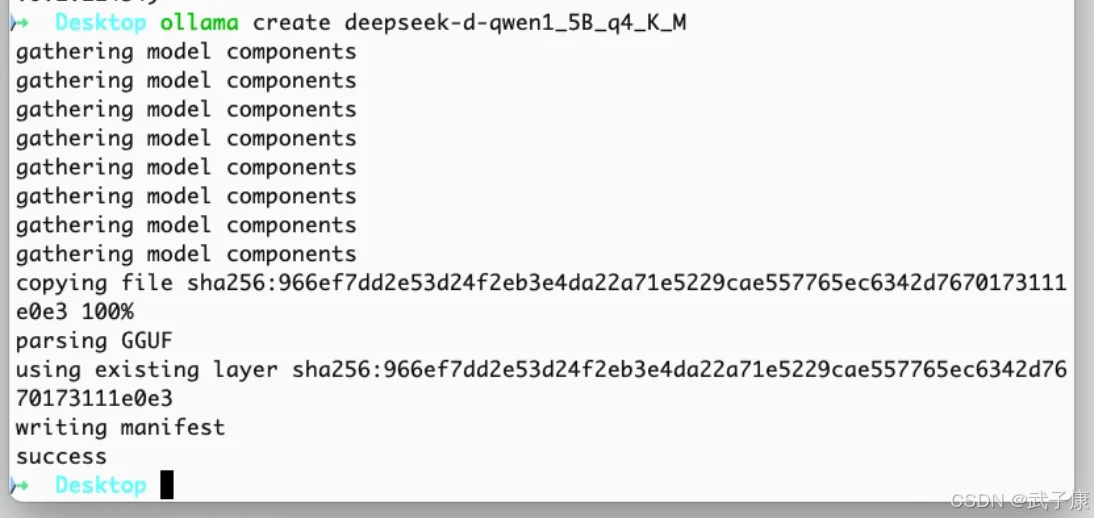
可以看到 Ollama 已经识别并且导入:
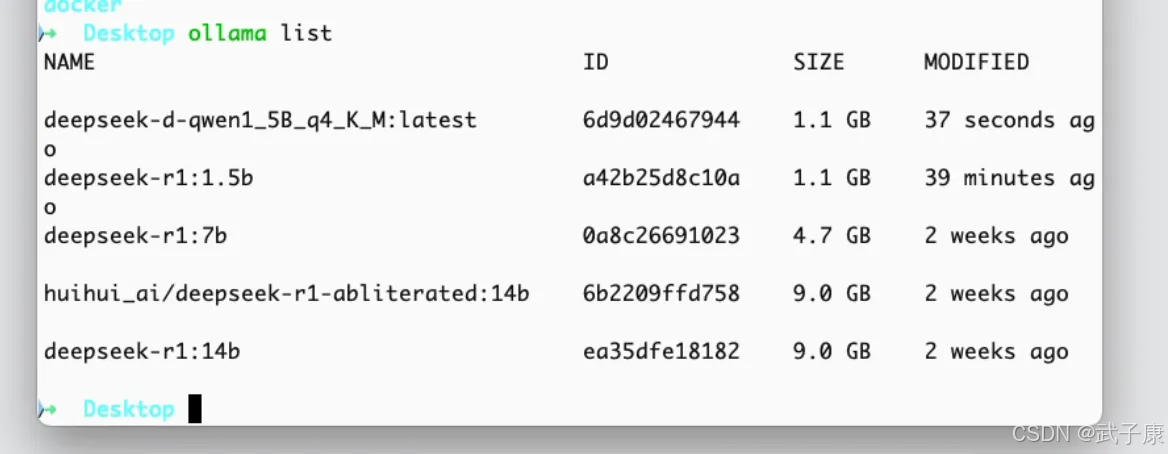
此时我们查看 Ollama 的模型,就可以看到我们导入的内容了,后续使用按照自己的方式即可:
如何衡量量化效果?
推理精度(Accuracy / Perplexity)
- 对于分类/问答/多轮对话模型,可以比较:
- 原始 FP16 与量化后的结果是否一致
- ROUGE、BLEU、F1-score、Exact Match 等评估指标
- 对于生成类模型,可计算 PPL(perplexity),越低越好
推理速度(Throughput)
- 单条输入的平均响应时间
- 批量输入下的 tokens/sec
- 实测 Q4_K_M 通常是 Q8_0 的 1.5~2倍速度提升
显存占用(Memory Footprint)
- 使用 nvidia-smi 或 Ollama 查看模型载入时占用
- 同一模型:Q8_0 约为 FP16 的 50%,Q4_K_M 约为 FP16 的 25~30%
加载耗时与稳定性
- GGUF 是否能被加载
- 是否会在推理中 crash 或出现乱码
人工验证质量
- 让模型回答几个基准问题(你可自定义 prompt),观察是否逻辑混乱、回答缺失或明显退化