2. Linux开发工具
目录
1.vim
1. vim的基本概念
2. vim的基本操作
3. vim命令模式命令集
2. Linux编译器-gcc/g++使用
3. Linux项目自动化构建工具-make/makefile
makefile:
make:
项目清理:
4.Linux小程序-进度条
5. git命令行
6. Linux调试器-gdb
1.vim
- IDE-vscode,jetbrains等编写,编译,输出结果为一体的
- vim只是写代码的工具
1. vim的基本概念
目前我们掌握三种即可,分别是命令模式、插入模式、底行模式,各模式的功能区分如下:
- 正常/普通/命令模式(Normal mode)
控制屏幕光标的移动,字符,字或行的删除,移动复制某区段及进入Insert mode、Last lint mode
- 插入模式(Insert mode)
只有在Insert mode下,才可以做文字输入,按[ESC]回到命令行模式。
- 末行模式(Last lint mode)
文件保存或退出,也可以进行文件替换,找字符串,列出行号等操作。在命令模式下,shift+;(其实就是:)即可进入该模式。

2. vim的基本操作
- 进入vim,在系统提示符号输入vim及文件名称后,就进入vim全屏幕编辑画面:
vim test.c进入vim以后是命令模式,要切换到插入模式才能输入文字。
- 命令模式切换到插入模式
- 输入a:从目前光标所在位置的下一个位置开始输入
- 输入i:从光标所在位置输入
- 输入o:插入新的一行,从行首开始输入文字
- 退出vim及保存文件
- w保存当前文件
- wq+回车:保存并退出
- q!:不存盘强制退出vim
3. vim命令模式命令集
进入插入模式和末行模式上面讲了,这里主要看其他的:
移动光标:
- vim可以使用小键盘的上下左右进行移动,但正规的vim是用小写英文字母h、j、k、l分别控制左、下、上、右的
- G:移动到最后
- $:所在行行尾
- ^:所在行行首
- w:下个字开头
- b:回到上个字开头
- gg:跳到文本开头
行号G:定位光标到任意行
删除:
- dd:删除光标所在行(剪切),dd+p就是剪切加复制,不p就是删除
复制:
- yy:复制光标所在行到缓冲区
- p:将缓冲区内字符粘贴到光标所在位置的下一行
- yy+10p:复制10行
替换:
- r:替换光标所在字符(不需要删除再打新的)
- R:替换光标所在字符,按下ESC为止
- shift+~
撤销:
- u:撤回,例如Windows的ctrl+z
- ctrl+r:撤销的恢复
多行注释和取消注释:
- 多行注释:在命令模式下,ctrl+v,hjkl上下左右移动选中多行代码(不能用箭头),大写i,//,ESC
- 取消注释:在命令模式下,ctrl+v,hjkl上下左右移动选中多行代码,d
2. Linux编译器-gcc/g++使用
gcc专用于编译C程序,g++是C和C++的都可以。
预处理:
- 功能包括:宏定义、文件包含、条件编译、去注释等(所以宏没机会进行语法检查,还没到检查的那个阶段就被替换了,不存在宏了)
- gcc -E hello.c -o hello.i
- -E:让gcc在预处理结束后停止编译过程
- -o:是指目标文件,意思是处理后的文件命名为xxx
- .i文件:为已预处理过的C源程序
编译:
- 检查语法,检查无误后,gcc把代码翻译成汇编语言
- gcc -S hello.i -o hello.s
- -S:让gcc在编译完后停下来,生成汇编代码
汇编:
- 把编译阶段生成的汇编代码转化为二进制机器码
- gcc -c hello.s -o hello.o(.o文件不能独立执行,需经过连接)
连接:
- 生成可执行文件
- gcc hello.o -o hello
连接中涉及到一个关键概念:函数库:
举个例子:我们的程序中没有定义pritf,只是包含了stdio.h,而这个文件中也只有printf的声明,并没有它的实现,那printf在哪里实现的呢?
系统把这些函数的实现都放到C标准库(如libc.a或libc.so)中,这个库本身是一个文件,gcc会默认到这个lib路径下进行查找,也就是连接到那个函数库中去,这样就能调用printf了。
函数库一般分为静态库和动态库,linux中.so是动态库、.a是静态库。
- 静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也不需要库文件了,它的优点是不依赖库,可独立运行
- 动态库相反,是程序执行时,才连接库,节省系统的开销
- gcc在编译时默认使用动态库,是动态链接的,若要按静态链接方式,要添加-static选项
-static的本质:改变优先级。一个文件(可执行程序或库)不一定是纯动态链接或纯静态链接,实际应用中往往是混合链接的。
3. Linux项目自动化构建工具-make/makefile
一个工程中的源文件非常多,makefile指定了一系列依赖来指定,哪些文件先编译,哪些文件后编译,用gcc不方便,makefile的好处就是自动化编译,一旦写好,只需要一个make命令,就可以完成整个工程的自动编译,极大提高效率。
make是一条命令,makefile是一个文件,两者搭配使用。
makefile:
makefile中包含依赖关系和依赖方法,举个例子
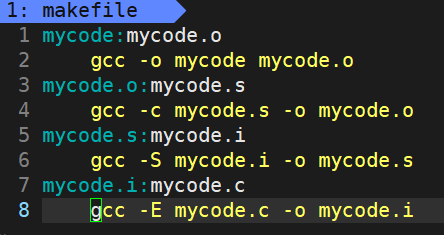
1,3,5,7即为依赖关系,2,4,6,8为依赖方法。
那什么是依赖关系呢?依赖关系指定了目标(target)所依赖的文件或其他目标。
比如第一行中,mycode就依赖mycode.o,前面的依赖后面的,这一行是声明这一种关系,就好比我和我爸,我依赖我爸,我不能依赖别人爸,我没生活费了需要我爸给我打钱,而不是别人爸给我打钱。先得产生关系,才能有具体的行为。也就是先得有依赖关系,才会调用对应的依赖方法。
在上面的makefile中体现出的就是,想要mycode,就得有mycode.o,想要mycode.o就得有mycode.s,想要mycode.s就得有mycode.i,想要mycode.i就得有mycode.c。他会一层一层向下找,最后返回,这是一个有点像递归的执行方式。
make:
make会在当前目录下找到名为makefile或Makefile的文件,找到之后,他会找文件中的第一个文件,也就是第一个依赖关系中前面的那个文件,作为目标文件。在上面的例子中,他会找到mycode 这个文件作为目标文件。
如果没有mycode,那他就会找mycode依赖的文件,层层递推,直到最终编译出第一个目标文件。
make完以后,再make就不会再编译
[zzy@iZuf626dg02ts3xac27i6sZ processBar]$ make
gcc -o processbar processBar.c main.c
[zzy@iZuf626dg02ts3xac27i6sZ processBar]$ make
make: `processbar' is up to date.
为什么只能make一次呢?
文件没改变过再make也没用,还是一样的结果,所以为了提高编译效率,make过就不能再make了。
那这是怎么判断一个工程能否再make的呢?它怎么直到文件是否被更改过呢?
在make时,一定是源文件形成可执行文件,先有源文件,才有可执行文件,所以一般情况下,源文件的修改时间一定比可执行文件的修改时间要更早。如果我们修改了源文件,曾经还有可执行,那么源文件的修改时间肯定是更新的。
所以只需要比较:可执行程序的最近修改时间 和 源文件的最近修改时间
如果 .exe 新于 .c,即.c源文件是老的,那么就不需要重新编译;
如果 .exe 老于 .c,即.c源文件是新的,那么就需要重新编译。
make 会根据源文件和目标文件的新旧,判定是否需要重新执行依赖关系进行编译。
[zzy@iZuf626dg02ts3xac27i6sZ processBar]$ stat makefileFile: ‘makefile’Size: 84 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 1057038 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ zzy) Gid: ( 1000/ zzy)
Access: 2025-04-13 13:59:54.742513605 +0800
Modify: 2025-04-13 13:59:51.491393878 +0800
Change: 2025-04-13 13:59:51.491393878 +0800Birth: -
调用stat可以显示出一个文件的各种信息,可以发现下面有3个时间:
Access time (atime): 表示文件的 最后访问时间,即文件内容最后一次被读取的时间。
Modify time (mtime):这是文件内容最后一次被修改的时间(比如用编辑器修改并保存了 makefile)。
Change time (ctime): 这是文件元数据(如权限、所有者等)最后一次被修改的时间。
上一章文件包括文件内容和文件属性,修改文件内容就会修改mtime,修改文件属性就会修改ctime。一般修改文件内容,文件的大小变了,那么文件的属性也变了,即mtime变了,ctime也会变。若只修改文件属性,比如权限,则只有ctime变了。
再有一点:如果我们想把一个已存在文件的时间更新为最新,可以使用touch:
[zzy@iZuf626dg02ts3xac27i6sZ ~]$ touch makefile[zzy@iZuf626dg02ts3xac27i6sZ ~]$ stat makefileFile: ‘makefile’Size: 76 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 921073 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ zzy) Gid: ( 1000/ zzy)
Access: 2025-04-13 15:59:52.086643597 +0800
Modify: 2025-04-13 15:59:52.086643597 +0800
Change: 2025-04-13 15:59:52.086643597 +0800Birth: -
那如果我就是想不管新旧都能make呢?可以这样写makefile:
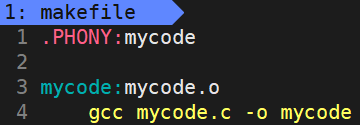
我们用.PHONY修饰目标文件,成为伪目标,伪目标的特性:总是被执行的。不过我们不建议这么搞,但是清理是希望总被执行的。
项目清理:
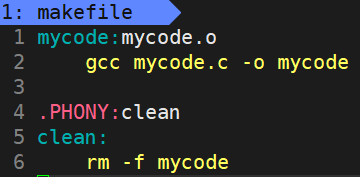
工程是需要被清理的,clean没有依赖文件,调用时直接make clean就可以了,清除所有目标文件,方便重新编译。
注意clean一般要写到最后,如果写到最开头的话,make这个命令就会把clean当作目标文件,调用make等于调用make clean了。
4.Linux小程序-进度条
先理解一下回车和换行:
回车:回到一行的最开始
换行:换到下一行
现代电脑键盘都把这两个操作合并成回车键了,老式的打印机:

纸向上移动的过程就是换行的过程,左边这个拨片在打字时会向右走,走到头需要手动的拨回最左边,这就是回车的过程。
再理解一下行缓冲区:
运行如下代码会发现:先休眠了2s,才打印出的hello world,但是程序的执行顺序一定是先执行打印,为什么没能在屏幕上输出来呢?
[zzy@iZuf626dg02ts3xac27i6sZ ~]$ cat test.c
#include <stdio.h>int main()
{printf("hello world");sleep(2);return 0;
}
sleep时,printf一定执行完了,hello world此时就存放在缓冲区stdout,默认只有程序结束时才会刷新缓冲区,将其中的内容输出。
int main()
{printf("hello world");fflush(stdout);sleep(2);return 0;
}我们可以使用fflush提前将缓冲区中的内容刷新出去就实现了先打印,再休眠。
进度条代码:
processBar.h:
#pragma once#include <stdio.h>#define NUM 102
#define STYLE '-'extern void processbar();
processBar.c:
#include "processBar.h"
#include <string.h>
#include <unistd.h>void processbar()
{int cnt = 0;char bar[NUM];memset(bar, '\0', sizeof(bar));const char* lable = "|/-\\";int len = strlen(lable);while(cnt <= 100){printf("[%-100s][%d%%][%c]\r", bar, cnt, lable[cnt%len]);fflush(stdout);bar[cnt++] = STYLE;if(cnt < 100)bar[cnt] = '>';usleep(100000);}printf("\n");return;
}
label是在进度条末尾显示一个 | / - \ 的循环,其实就是一条线在转的效果,表示进度条在动。
![]()
main.c
#include "processBar.h"int main()
{processbar();return 0;
}
5. git命令行
准备工作:创建gitee账号,创建仓库,linux中安装好git
把创建好的仓库克隆到本地:
git clone https://gitee.com/want-to-become-a-coding-expert/linux.git后面的地址复制的是下面这个按钮里的https

这时候ll就可以发现有了这个库为名称的目录
那怎么把刚刚写的进度条上传到gitee中呢?
1. 首先把 processBar 拷贝到仓库中,进到linux中,然后:
cp ../processBar . -rf2. 把仓库中不存在的存入到暂存区:
git add .3. 把暂存区中的内容放到版本库中:
git commit -m "提交日志:不能乱写,要写干了什么"4. 推送到远端-gitee创建的仓库中
git push然后输一下登陆gitee时的账号和密码就行了。
其他问题:
查看提交仓库历史记录:
git log检查是否有新文件没有推送,需要更新,即检查工作目录状态:
git status首次使用时需要配置邮箱和用户名,这个邮箱最好和gitee绑定的一样。这主要是为了代码溯源,如果提交上去的代码有问题,或者别人用的时候发现了问题方便找到是谁提交的。
其他还有很多命令,使用方法,可自行了解,后期可能也会单独写git企业级系列吧。
6. Linux调试器-gdb
程序的发布方式有两种,debug和release版本。
linux gcc/g++出来的可执行程序,默认是release模式,不能使用gdb调试,要使用gdb调试,必须在makefile中,加上-g选项,debug发布。
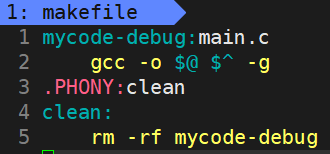
在实际调试中:
首先得先看到程序:
- l 行号 : 显示行号附近的代码,每次列10行
一般使用时 l 0,然后一直回车就可每次列10行直到全部列出
- r:运行程序
- c:从当前位置开始运行到下一个断点
- b 行号:在某一行设置断点
- info break:查看断点信息,其中含有一个断点序号
- d 序号:可以删除某序号的断点
- d b : 删除所有断点
- disable b 序号:可以禁用某个断点,就是不删但是暂时不想用
- enable b 序号:启用断点
- s:进入函数体内部,逐语句进行调试
- finish:执行到当前函数返回,然后停下来,其实就是某个函数直接跑完
- until 行号:快速运行代码到指定行
- p 变量:打印变量值
- display 变量:可以跟踪查看一个变量,每次停下来都会显示它的值(可以跟踪多个)
- undisplay 变量序号:取消追踪变量,注意后面跟的是变量序号不是变量名
- n:单步执行
- q:退出调试