R-CNN,Fast-R-CNN-Faster-R-CNN个人笔记
注:此博客主要为了方便笔者快速复习,只讲大致框架,只讲推理,不讲训练,因此内容不会很详实。
1.R-CNN
R-CNN系列的开山之作。
本文将该框架划分为3个模块:
1.region proposal generator
2.CNN(选取VGG16作为backbone)
3.SVM
第一个模块。第一个模块负责生成region proposal,也就是许多候选框(后续从这些框中选取某些框作为目标检测的输出框)。这里生成候选框采用了一种叫做selective search的方法。
请注意,这里的候选框是与类别无关(category-independent)的,后续步骤才会确定框的类别。
第二个模块。众所周知CNN可以用于提取图片特征,而此处的CNN就是为了分别提取region proposal对应图像的特征的。也就是说,每一个候选框都会经由CNN生成对应特征。这里就引出一个小问题:后续的SVM要求输入的特征维度是确定的,要达到这个目的,CNN的输入图像维度也要是确定的。但候选框的大小是五花八门的,怎么把每个候选框映射到固定维度大小呢?作者采用了一种叫warp的方法,具体请查阅论文。
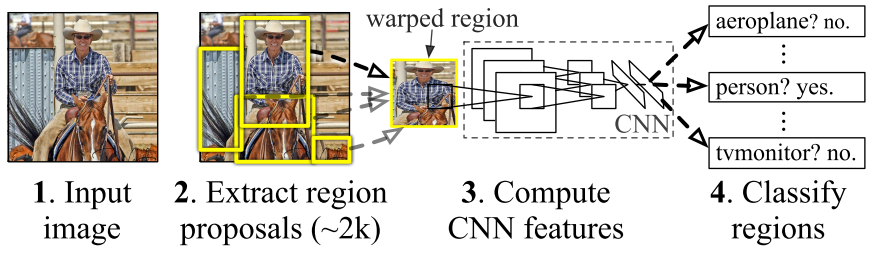
第三个模块怎么使用?若总共有20个类别,就训练出20个SVM。这样,一开始selective search会生成2000个候选框,然后经由CNN得到一个2000 * 4096的矩阵(每个候选框的特征向量维度是4096),再分别对每个特征向量使用20个SVM,得到2000*20的矩阵(每个候选框对应于某一个类别的概率)。
到这一步,理论上已经结束。只是我们可以看出,候选框明显过多。于是,对于每一个类别分别使用非极大值抑制(NMS),削减候选框的数量,可以得到更合理的结果。
此外,selective search的候选框位置不一定就那么刚好对得上真实框。在上一步结束后,这里还用了20个回归器来矫正每一类边界框的位置与大小,使得最后的生成框与真实框的IOU更高。
2.Fast-R-CNN
依然使用selective search,得到许多proposal。
CNN(依然选取VGG16):将原图像映射为一个feature map
关于ROI:
这部分是这篇论文的主要创新点。R-CNN中,CNN直接对proposal进行操作,那么就要经历2000次CNN的前馈过程。但在此论文中,我们只进行一次CNN操作:将原图像映射为一个feature map。那怎么提取proposal的相关信息呢?直接通过ROI projection(见图)将proposal映射到feature map的一小块区域,将这一小块区域作为proposal的特征图(也就是说,每个proposal都会对应feature map上的一个“小feature map”)。
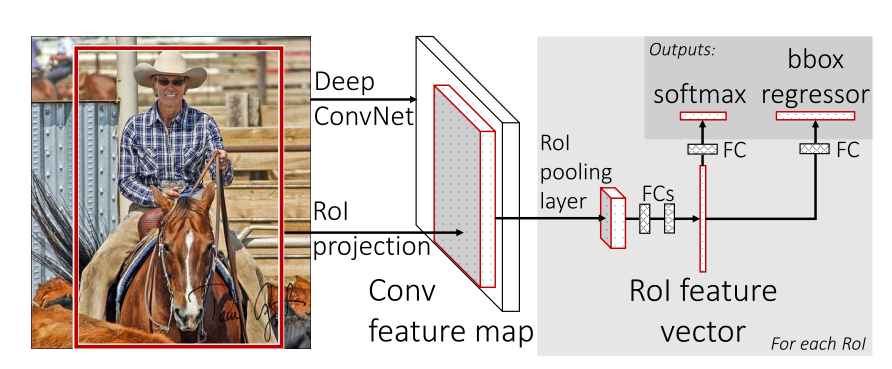
现在有了小feature map,就可以使用一个叫做ROI pooling的操作,将每个小feature map切割为7×7的小块,在每个小块上分别使用max pooling,就得到了7×7的最终特征。这里需要强调,ROI pooling 和SPP-net一样,是对每个channel分别进行操作的。也就是说,如果原图的feature mapchannel为c,那么每个小feature map的最终特征大小为7×7×c。
为什么要这样做?因为和之前一样,送入分类模块之前,要保证得到的表征(representation)大小维度是固定的。
最后是分类
分类的SVM变成了线性层。每个7×7×c的输出都会被分类为N个类别中的一个或是背景类。另外,依然有回归器对边界框的位置、大小进行矫正。
Faster R-CNN
上一篇工作提速已经比较明显了,但selective search依然比较耗时。这篇针对这个痛点,提出了RPN,进一步进行提速。
RPN和Faster R-CNN 共享了最开始的卷积层。本文架构与Fast R-CNN的的不同之处就是:将selective search替换为RPN。
按文中的意思,RPN是若干个卷积层构成的,只是除了最后一层(图中左侧),之前的卷积层与Fast R-CNN detector共用了(也就是图中的conv layers部分)。
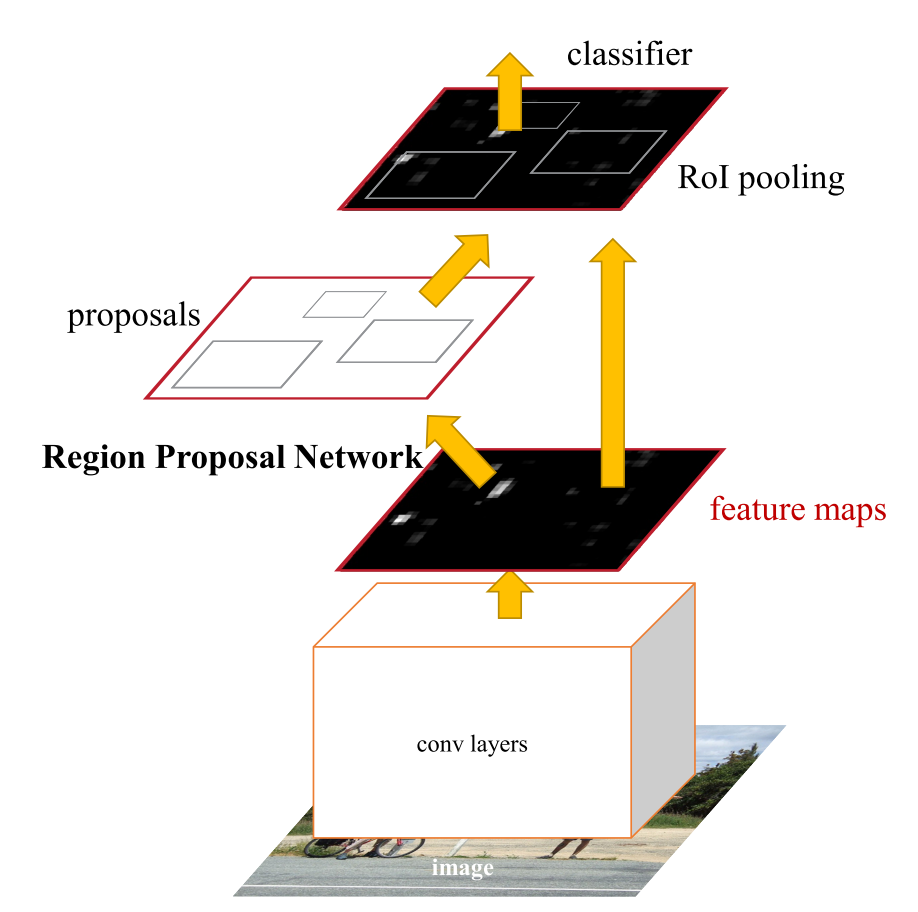
RPN如何操作(专指最后一层卷积,也就是图片左侧)?首先要知道,在feature map上每一点会根据长宽比、面积生成k个anchor(这里k为3×3=9)。
先将feature map进行padding,然后以3×3的卷积核依次在feature map的每个位置进行滑动。这里若backbone使用的是ZF-net,则feature map的channel为256,即,在feature map的每个位置上,RPN的输出维度是256。之后再将这个256维的向量分别接入两个全连接层,分别产生4k和2k个输出(前者用于调整框的大小和位置,后者用于判断每个框是不是背景)。
RPN生成的框会很多,会通过去除超过图片边界的anchor去除大部分框。去除以后剩下的框的数目大致和selective search相同。之后就和Fast R-CNN一样,正常检测,最后做一个NMS就行了。