AI工程pytorch小白TorchServe部署模型服务
注意:该博客仅是介绍整体流程和环境部署,不能直接拿来即用(避免公司代码外泄)请理解。并且当前流程是公司notebook运行&本机windows,后面可以使用docker 部署镜像到k8s,敬请期待~
前提提要:工程要放弃采购的AI平台,打算自建进行模型部署流程
需求:算法想要工程将模型文件+模型推理 部署为模型服务
技术栈:python pytorch
解决方案:torch serve 又称PyTorch Serving
TorchServe is a performant, flexible and easy to use tool for serving PyTorch models in production.
TorchServe 是一种高性能、灵活且易于使用的工具,用于在生产环境中为 PyTorch 模型提供服务。
示例代码
from ts.torch_handler.base_handler import BaseHandler
import torch
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfgclass DetectronHandler(BaseHandler):def initialize(self, context):self.manifest = context.manifestself.cfg = get_cfg()self.cfg.merge_from_file("path/to/config/file.yaml")self.cfg.MODEL.WEIGHTS = "path/to/model/weights.pth"self.predictor = DefaultPredictor(self.cfg)def preprocess(self, data):return torch.tensor(data)def inference(self, data):return self.predictor(data)def postprocess(self, data):return data
这段代码定义了一个名为 DetectronHandler 的类,它继承自 BaseHandler 类(通常用于在模型服务中处理请求)。这个类的目的是为了封装使用 Detectron2 模型进行推理的过程。以下是对各个部分的详细解析:
类和方法
init 方法:这里没有显示__init__方法,但因为 DetectronHandler 继承了 BaseHandler,所以会调用父类的构造函数。
initialize(self, context) 方法:
此方法在处理器初始化时被调用,接收一个包含环境信息的 context 参数。
加载模型配置文件(通过路径 “path/to/config/file.yaml”)到 self.cfg 中。
设置模型权重的路径为 “path/to/model/weights.pth”。
使用上述配置创建一个 DefaultPredictor 实例 self.predictor,用于后续的推理操作。
preprocess(self, data) 方法:
接收输入数据 data 并将其转换为 PyTorch 张量格式。这一步骤是为了确保输入数据符合模型的要求。
inference(self, data) 方法:
利用 self.predictor 对预处理后的数据进行推理,并返回结果。DefaultPredictor 是 Detectron2 提供的一个便捷类,简化了模型加载和推理过程。
postprocess(self, data) 方法:
这个方法目前只是简单地返回了推理的结果数据。在实际应用中,你可能会在这里添加一些额外的逻辑来处理或格式化输出结果,以便于客户端理解和使用。
注意事项
在 initialize 方法中,配置文件路径和模型权重路径是硬编码的。在实际部署中,这些路径可能需要根据具体环境进行调整。
preprocess 方法中的实现假设输入数据可以直接转换为张量。对于复杂的输入(如图像),你可能需要更复杂的预处理步骤。
当前的 postprocess 方法没有对输出做任何处理。根据你的应用场景,可能需要对模型的输出进行解码或其他处理,以生成用户友好的输出。
整体来看,DetectronHandler 类提供了一种将 Detectron2 模型集成到基于 TorchServe的服务中的方式,使得可以通过简单的接口调用来执行对象检测等任务。
部署流程:
一丶接受算法代码
好了,理解的差不多了,算法那边给了一个.ipynb notebook文件,使用vscode 打开需要下载 jupyter 插件进行执行
二丶理解算法代码逻辑
1.读取.pth 模型文件
2.读取测试参数字段
3.处理数据
4.处理数据集
5.执行模型推理
6.处理推理结果
三丶将.ipynb 转换为.py文件(有工具,但是我这边搞半天没成功,用简单的代码代替)
import nbformat# 读取 .ipynb 文件
with open('predict_main.ipynb', 'r', encoding='utf-8') as f:notebook_content = nbformat.read(f, as_version=4)# 提取代码单元
code_cells = [cell['source'] for cell in notebook_content['cells'] if cell['cell_type'] == 'code']# 写入 .py 文件
with open('predict_main.py', 'w', encoding='utf-8') as f:for code in code_cells:f.write(code + '\n\n')
四丶将算法的代码嵌入到TorchServe 框架内
initialize(初始化) preprocess(预处理) inference(推理) postprocess(推理结果)
1.initialize 接受请求把return 结果作为preprocess 的入参
2.preprocess return的结果作为inference 的入参
3.postprocess 拿到入参,return 作为返回结果
五丶安装TorchServe 环境
pip install torchserve torch-model-archiver torch-workflow-archiver
五丶脚本执行
# 创建MAR文件
torch-model-archiver --model-name dsn_model \--version 1.0 \--model-file best_model_8.pth \--handler service/handler.py \--extra-files "config.properties,service,log4j2.xml" \--export-path model-store \--force# 启动TorchServe
torchserve --start \--model-store model-store \--models dsn_model.mar \--ts-config config.properties \--disable-token-auth \--log-config log4j2.xml# 停止TorchServe
torchserve --stop
解决报错
1.
torch server 的底层是java , 且java的版本是>=jdk11
linux 暂时改java环境变量(后面请改)
export JAVA_HOME=/net_disk/tools/jdk-11.0.2
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
2.文件路径:所有的推理的代码尽量打包到相同路径
通过unzip 可以观看是不是已经把目标的文件打进去,如果没有打进去,会报错的。
3.log日志优化
由于torch server底层是java ,使用了Log4j2 作为日志框架,运行的代码日志非常乱,所以建议重写log4j2.xml,同时注意,python error 日志被torch server 都处理为了info日志(感觉很奇怪)
<?xml version="1.0" encoding="UTF-8"?>
<Configuration><Appenders><RollingFilename="access_log"fileName="${env:LOG_LOCATION:-logs}/access_log.log"filePattern="${env:LOG_LOCATION:-logs}/access_log.%d{dd-MMM}.log.gz"><PatternLayout pattern="%d{ISO8601} - %m%n"/><Policies><SizeBasedTriggeringPolicy size="100 MB"/><TimeBasedTriggeringPolicy/></Policies><DefaultRolloverStrategy max="5"/></RollingFile><Console name="STDOUT" target="SYSTEM_OUT"><PatternLayout pattern="%d{ISO8601} [%-5p] %t %c - %m%n"/></Console><RollingFilename="model_log"fileName="${env:LOG_LOCATION:-logs}/model_log.log"filePattern="${env:LOG_LOCATION:-logs}/model_log.%d{dd-MMM}.log.gz"><PatternLayout pattern="%d{ISO8601} [%-5p] %t %c - %m%n"/><Policies><SizeBasedTriggeringPolicy size="100 MB"/><TimeBasedTriggeringPolicy/></Policies><DefaultRolloverStrategy max="5"/></RollingFile><RollingFile name="model_metrics"fileName="${env:METRICS_LOCATION:-logs}/model_metrics.log"filePattern="${env:METRICS_LOCATION:-logs}/model_metrics.%d{dd-MMM}.log.gz"><PatternLayout pattern="%d{ISO8601} - %m%n"/><Policies><SizeBasedTriggeringPolicy size="100 MB"/><TimeBasedTriggeringPolicy/></Policies><DefaultRolloverStrategy max="5"/></RollingFile><RollingFilename="ts_log"fileName="${env:LOG_LOCATION:-logs}/ts_log.log"filePattern="${env:LOG_LOCATION:-logs}/ts_log.%d{dd-MMM}.log.gz"><PatternLayout pattern="%d{ISO8601} [%-5p] %t %c - %m%n"/><Policies><SizeBasedTriggeringPolicy size="100 MB"/><TimeBasedTriggeringPolicy/></Policies><DefaultRolloverStrategy max="5"/></RollingFile><RollingFilename="ts_metrics"fileName="${env:METRICS_LOCATION:-logs}/ts_metrics.log"filePattern="${env:METRICS_LOCATION:-logs}/ts_metrics.%d{dd-MMM}.log.gz"><PatternLayout pattern="%d{ISO8601} - %m%n"/><Policies><SizeBasedTriggeringPolicy size="100 MB"/><TimeBasedTriggeringPolicy/></Policies><DefaultRolloverStrategy max="5"/></RollingFile></Appenders><Loggers><Logger name="ACCESS_LOG" level="info"><AppenderRef ref="access_log"/></Logger><Logger name="io.netty" level="error" /><Logger name="MODEL_LOG" level="info"><AppenderRef ref="model_log"/></Logger><Logger name="MODEL_METRICS" level="error"><AppenderRef ref="model_metrics"/></Logger><Logger name="org.apache" level="off" /><Logger name="org.pytorch.serve" level="error"><AppenderRef ref="ts_log"/></Logger><Logger name="TS_METRICS" level="error"><AppenderRef ref="ts_metrics"/></Logger><Root level="info"><AppenderRef ref="STDOUT"/><AppenderRef ref="ts_log"/></Root></Loggers>
</Configuration>
4.config.properties 文件如下,把端口改成9080是为了避免8080端口被占用哦
inference_address=http://127.0.0.1:9080
management_address=http://127.0.0.1:9081
metrics_address=http://127.0.0.1:9082
- 启动TorchServe时要把认证取消,暂时没打算开启验证,如果有感兴趣的小伙伴去官网查下
--disable-token-auth
6.把环境变量改为
export LANG=C.UTF-8
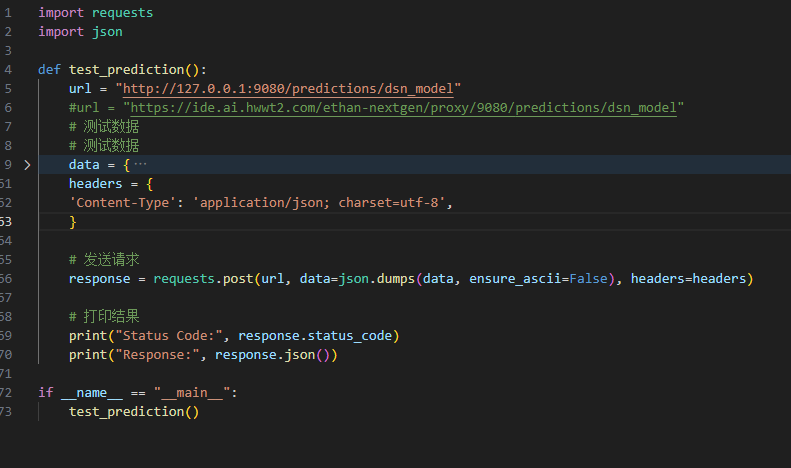
六丶HTTP 请求测试
七丶结果


windows 由于vscode一直报没有C++组件,所有用AI生成了一个bat文件,亲测可用,但是由于日志文件还没解决,所以只当本地测试版本
@echo off
REM ======================================================
REM Windows CMD 批处理脚本:生成 .mar 并启动 TorchServe
REM ======================================================
REM 切换到 UTF-8 显示
chcp 65001 >nulREM ======================================================
REM 项目专用 JDK11:只对本脚本生效,不改系统变量
REM ======================================================
REM 1. 指定 JDK11 安装目录
set "JAVA_HOME=D:\java11"
set "PATH=%JAVA_HOME%\bin;%PATH%"
REM 2. 验证当前使用的 java 版本(应是 11.x)
java -versionSET ModelName=xxx
set ModelFile=xxxx.pth
SET Version=1.0
SET Handler=service/handler.py
SET ExtraFiles=config.properties,service,log4j2.xml
SET ExportPath=model-store
SET TSConfig=config.properties
SET logConfig=log4j2.xmlecho === Windows 批处理 部署脚本 ===REM 1. 创建模型存储目录
if not exist %ExportPath% (echo 创建目录:%ExportPath%mkdir %ExportPath%
) else (echo 目录已存在:%ExportPath%
)REM 2. 生成 .mar 文件
echo 生成 .mar 文件:%ModelName%.mar
torch-model-archiver --model-name %ModelName% ^--version %Version% ^--model-file %ModelFile% ^--handler %Handler% ^--extra-files %ExtraFiles% --export-path %ExportPath% --force
if errorlevel 1 (echo ▶ 打包失败 (错误码:%ERRORLEVEL%),脚本终止。exit /b %ERRORLEVEL%
)REM 3. 启动 TorchServe
echo 启动 TorchServe ...
torchserve --start --model-store %ExportPath% ^--models %ModelName%.mar ^--ts-config %TSConfig% ^--disable-token-auth if errorlevel 1 (echo ▶ TorchServe 启动失败 (error code: %ERRORLEVEL%)。exit /b %ERRORLEVEL%
)echo 部署完成 🎉 ```