Linux:进程的创建进程的终止
进程的创建
fork
fork是c语言中的一个函数,用于创建新的子进程,它存放在<unistd.h>的头文件中
当我们运行程序时,如果使用了fork函数那么就会为这个进程创建一个它的子进程,这个子进程会继承父进程的所有数据和代码,但其实子进程是和父进程共用一套数据和代码。还有一个重点是:
内存指针:子进程会继承父进程的内存指针,内存指针用于指向程序执行到了哪里。
我们来测试一下fork是否真的会创建一个新的进程。我们来看以下代码
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<string.h>
#include<errno.h>
#include<stdlib.h>
int main()
{printf("hello world!!!\n");fork();printf("ganchuhao!!!!!\n");printf("gansimiao!!!!!\n");sleep(1);
}运行结果
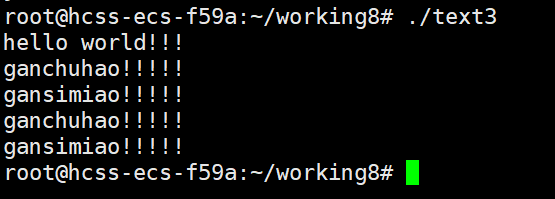
我们可以看到,在fork之前的程序只运行了一次,但是在fork之后的语句运行了两次,

从这张图中我们就可以看出fork函数会创建一个子进程,而子进程会继承父进程的代码和数据,并且在父进程运行下一行的位置开始运行
fork会返回两个值,子进程返回0,父进程返回子进程PID
其实这也就解释了为什么我们会看到fork有两个返回值,我们先来看一段代码
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<string.h>
#include<errno.h>
#include<stdlib.h>
int main()
{pid_t id=fork();if(id==0){printf("我是父进程\n");}else{printf("我是子进程\n");}}

我们会发现为什么呢?为什么id这个变量能同时满足两个条件语句,我们会以为id有两个值 ,其实真正的原因是在运行fork时父进程会创建一个子进程,而子进程会继承父进程的数据和代码,所以子进程也有了自己的id而父进程有一个id,那么父进程的id就是非零的而子进程的id是零,所以不是fork有两个返回值,而是fork返回了两个分别对应两个id,然后这两个id进入了两个条件语句
写时拷贝
当父进程创建子进程的时候,系统为了节省内存开支,就让子进程和父进程共用一份数据和一份代码,但是当子进程需要对数据修改时,系统便会重新为要修改的数据开创一份空间,将数据内容拷贝下来,然后修改。
我们先来判断父子进程是否共用一套数据和代码
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<string.h>
#include<errno.h>
#include<stdlib.h>
int main()
{printf("hello,world!!!\n");pid_t id=fork();printf("Ganchuaho!!!!!\n");printf("Gansimiao!!!!!\n");printf("Ganchujian!!!!\n");
}
运行结果
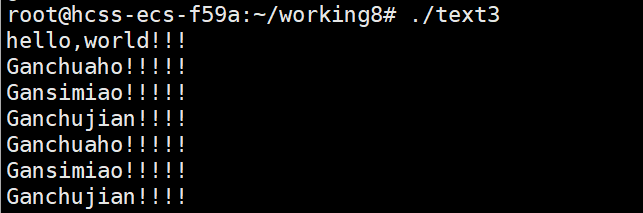
这里 hello,world!!!运行了一次,而其它的语句运行了两次,说明子进程和父进程是共用同一套代码和数据的
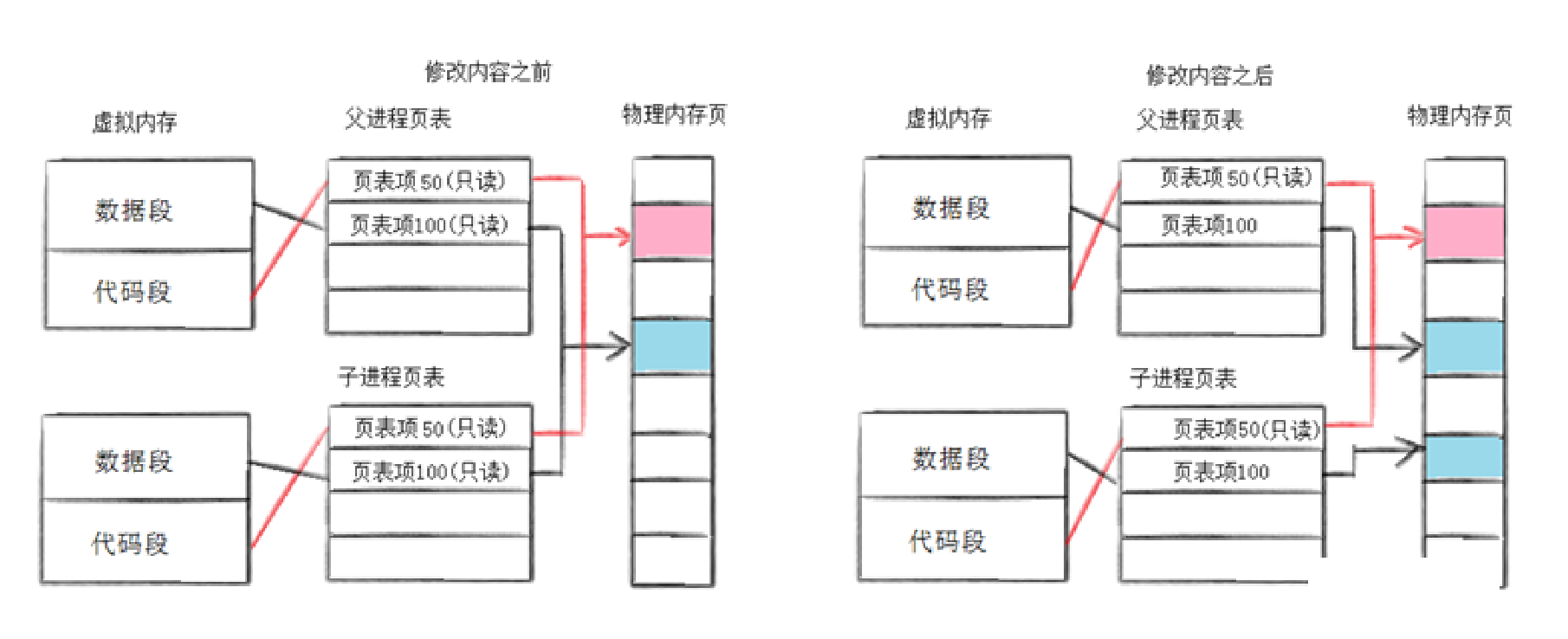
这里不管是父进程还是子进程页表都是只读的,但是当子进程需要修改数据时,那么页表就可以写入,并且操作系统开辟一块空间与页表项映射
进程终止
退出码
退出码:在main程序正常退出时会返回一个值,这个值称为退出码
当我们在写程序时,我们的main函数总是返回0,表示程序正常退出
echo $?这个指令可以查看上一个程序的退出码是什么
我们来用代码测试一下
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<string.h>
#include<errno.h>
#include<stdlib.h>
int main()
{return 123;
}
运行结果
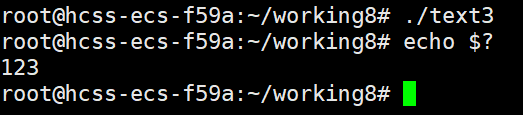
这里main函数返回123,所以输出123
strerror
strerror可以用来查看系统有多少错误信息,这些错误信息都对应一个错误码,它包含在<string.h>头文件中,我们来用代码测试一下
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<string.h>
#include<errno.h>
#include<stdlib.h>
int main()
{for(int i=0;i<20;i++){printf("[%d]:%s\n",i,strerror(i));}}
输出结果
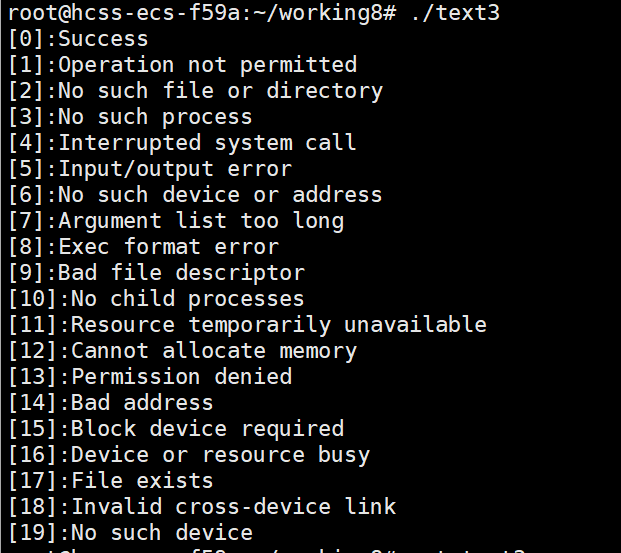
这里我们就输出前20个错误码对应的错误信息就可以了
我们会发现这里有些错误信息是我们经常遇到的
比如
[2]:No such file or directory
这里我们可以测试一下

当前工作目录下没有text.txt文件,但是我们仍然让ls去读取这个文件,那么系统就会报出这个错误,说明当前工作目录没有text.txt文件
我们再来用echo $?检测一下错误信息

错误信息是2,这也就更加说明了我们提出的结论
errno
errno是用于存储上一次函数错误的错误返回码,其存储在<errno.h>头文件中
我们用代码测试一下
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<string.h>
#include<errno.h>
#include<stdlib.h>
int main()
{fopen("text.txt","r");printf("[%d]:%s\n",errno,strerror(errno));
}
运行结果如下

fopen无法打开当前工作路径下没有的文件,所以errno会记录fopen的错误码
异常
当程序发生错误时,程序仍然可以运行,但是当程序发生异常时,程序便会退出,在上文中fopen无法打开文件,便发生错误,但是程序仍然还是可以运行printf还是可以打印结果
我们来测试一下如果程序发生异常还会不会运行
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<string.h>
#include<errno.h>
#include<stdlib.h>
int main()
{printf("hello,world\n");double a=5/0;printf("hello school\n");
}
这段代码发生了除零错误,让我们来运行一下看看结果时什么
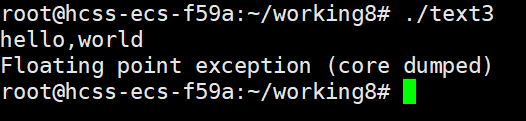
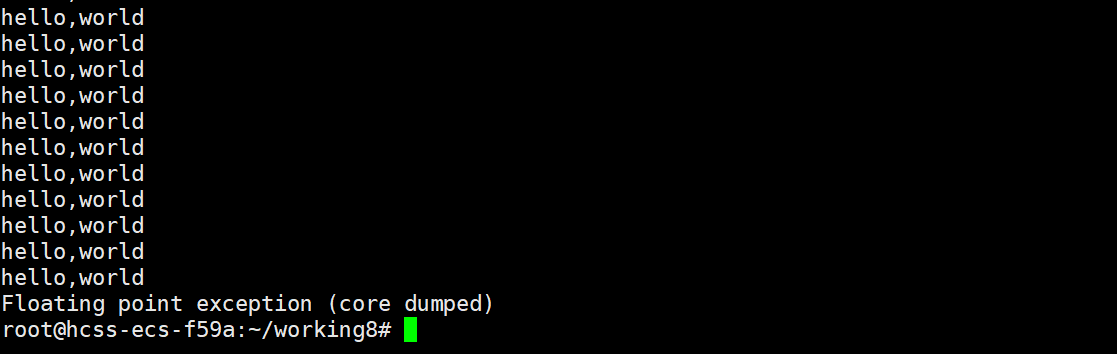
这里代码执行到hello,world就结束了,说明程序遇到异常时,便会停止执行程序
kill -l此命令可以查看所有的异常信号
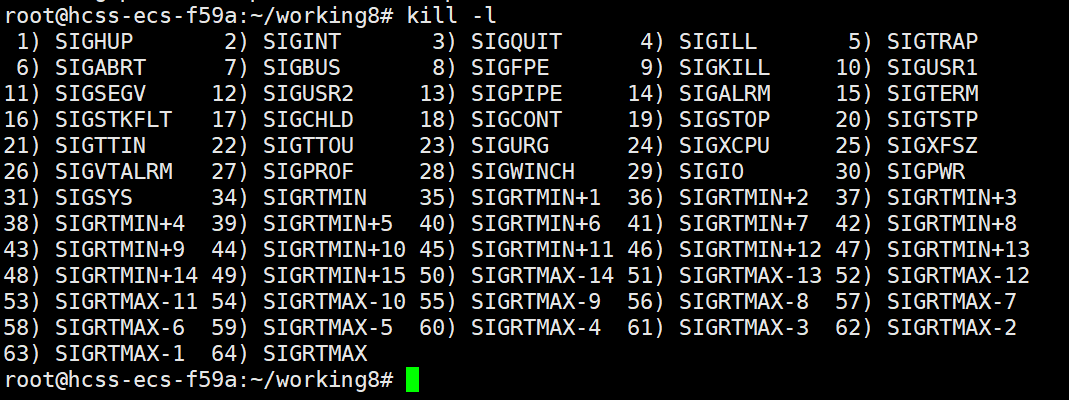 其实不只程序自己会发生异常信号,我们也可以想程序传递一个异常信号,这种方式会导致进程停止
其实不只程序自己会发生异常信号,我们也可以想程序传递一个异常信号,这种方式会导致进程停止
kill -X PID其中X是我们需要传递那种异常信号
我们来写个死循环程序来检测一下
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<string.h>
#include<errno.h>
#include<stdlib.h>
int main()
{while(1)printf("hello,world\n");
}
运行结果
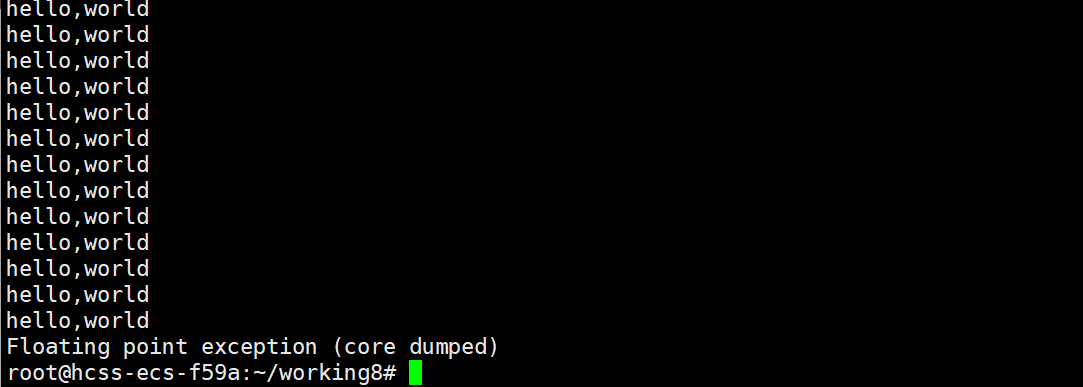
输入指令

我们再看另外一个Xshell的结果
当我们输入上面那个指令时便输出了这个结果,我们先要进程爆出上面异常,我们就输入哪个指令对应的数字就可以了
kill 不仅可以杀死进程,还能给进程抛异常
exit
exit可以直接结束进程,无论进程执行到了哪里,只要执行到了exit
我们来用一段代码来测试一下
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<string.h>
#include<errno.h>
#include<stdlib.h>
void func()
{exit(5);
}
int main()
{func();return 0;
}
检查错误码

程序运行完后检查错误码和exit的值是一样的
注意:无论exit在进程的哪一个部分时,只要执行到了exit就会退出进程
exit有两个版本,还有一个时_exit,这个_exit是系统提供给我们的,就算是exit也是由_exit放在exit进行实现的,_exit存在于<unistd.h>
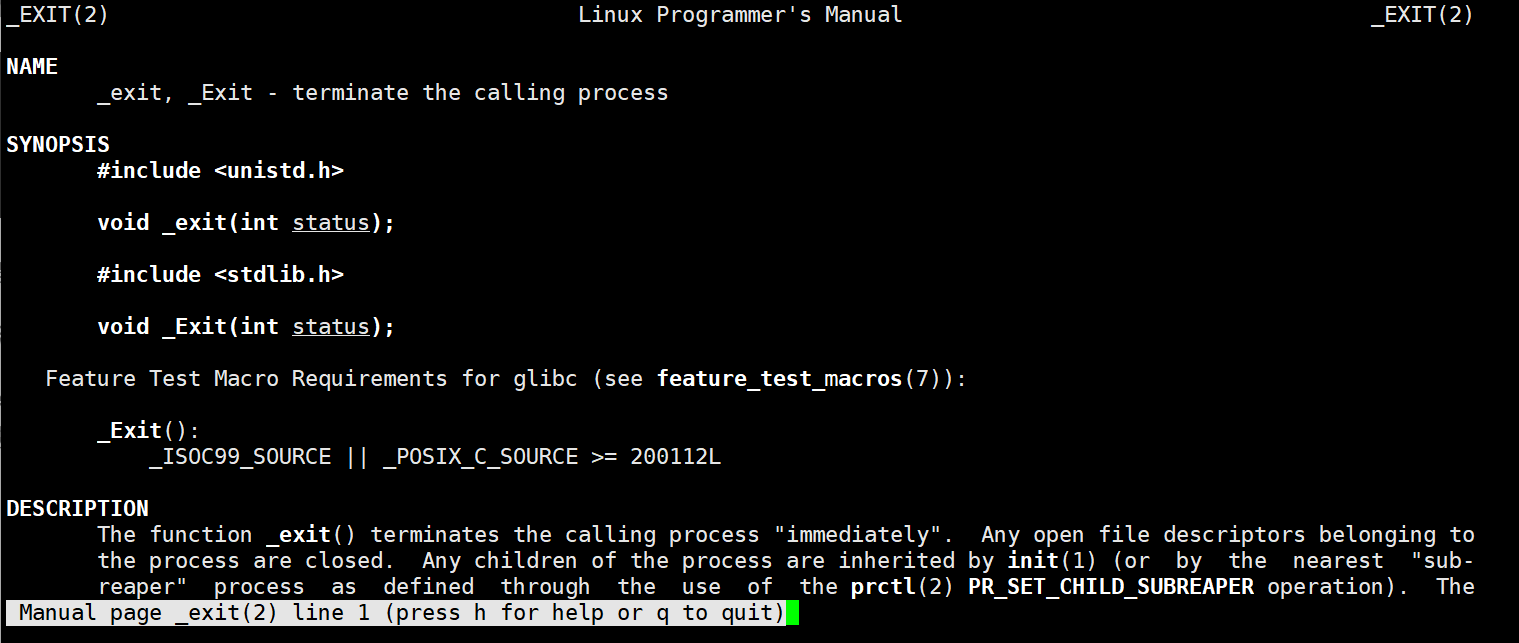
这个是系统的_exit,我们man一下是可以查出来的
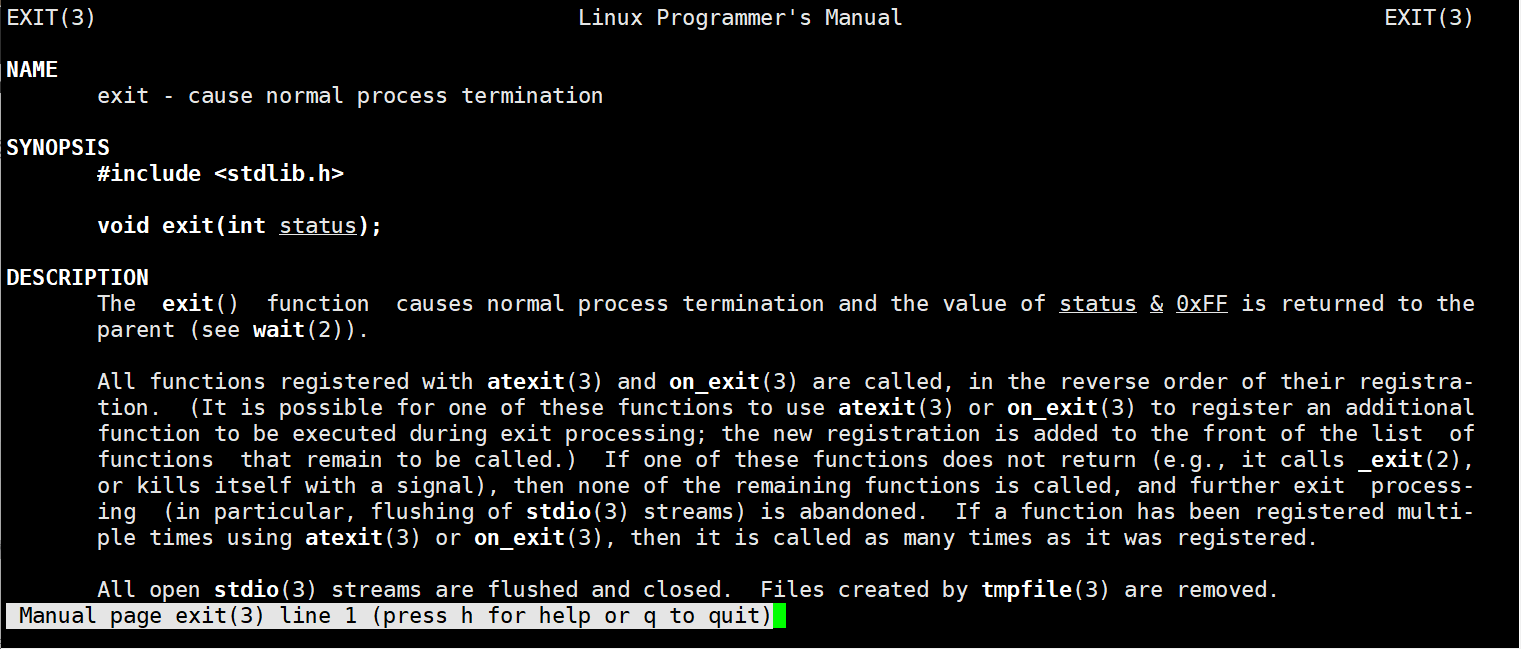
我们可以看到这个函数是存在于<stdlib.h>中的
这两个都能直接结束进程
但是_exit不会刷新缓冲区,exit会刷新缓冲区
exit的底层是由_exit实现的