Stack和Queue和deque的讲解(底层实现 手撕版)
一.底层的基本思路
我们cpp中实现的栈和队列不同于我们数据结构c语言实现的栈和队列,c语言中实现的栈和队列都是通过一个数组指针的形式来完成,每个函数都需要写大量的代码,但是我们的cpp,就是通过函数模板 适配器来完成的。

我们先来看一下库中的stack的函数模板,有两个参数,第一个是我们需要存入的类型,第二个就是适配器。
1.1 什么是适配器呢?
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
听着很抽象,我们直接来写吧。

就是这个样子的。
这个适配器就是我们需要传入的一个类型,我们传入来演示一下。
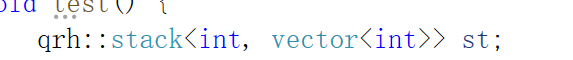
我们写了这样的一个代码,我们把第二个参数传入了一个vector容器,当然我们也可以传入list容器,接下来我们先来看一下好处。
1.2 实现栈中的各种方法
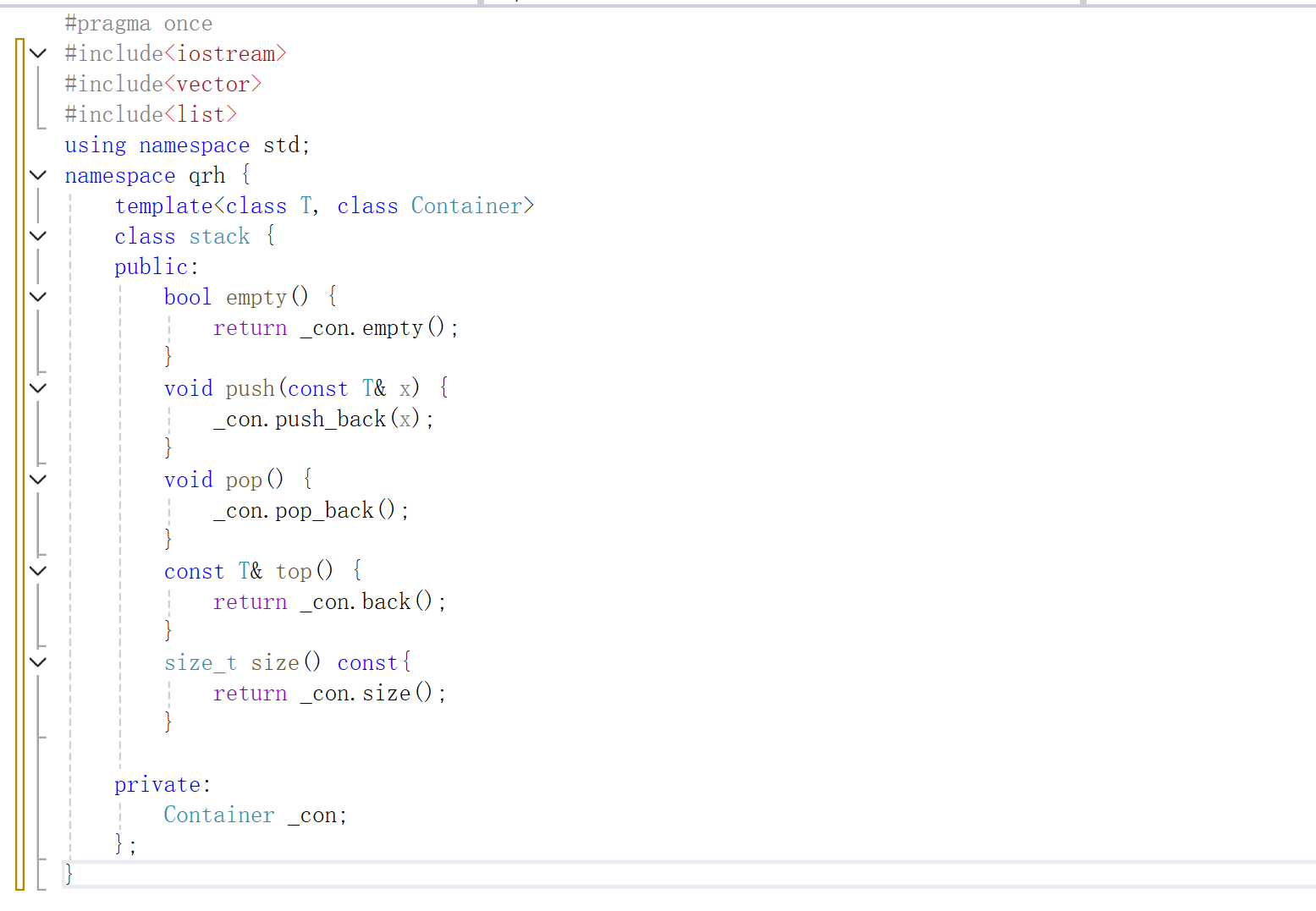
我们直接调用了vector容器中的方法了,使得我们的栈实现起来非常的简单。
我们要是想给stack<int>这样的形式的怎么办呢?只需要给第二个参数一个缺省值即可。
我们下面给一下。
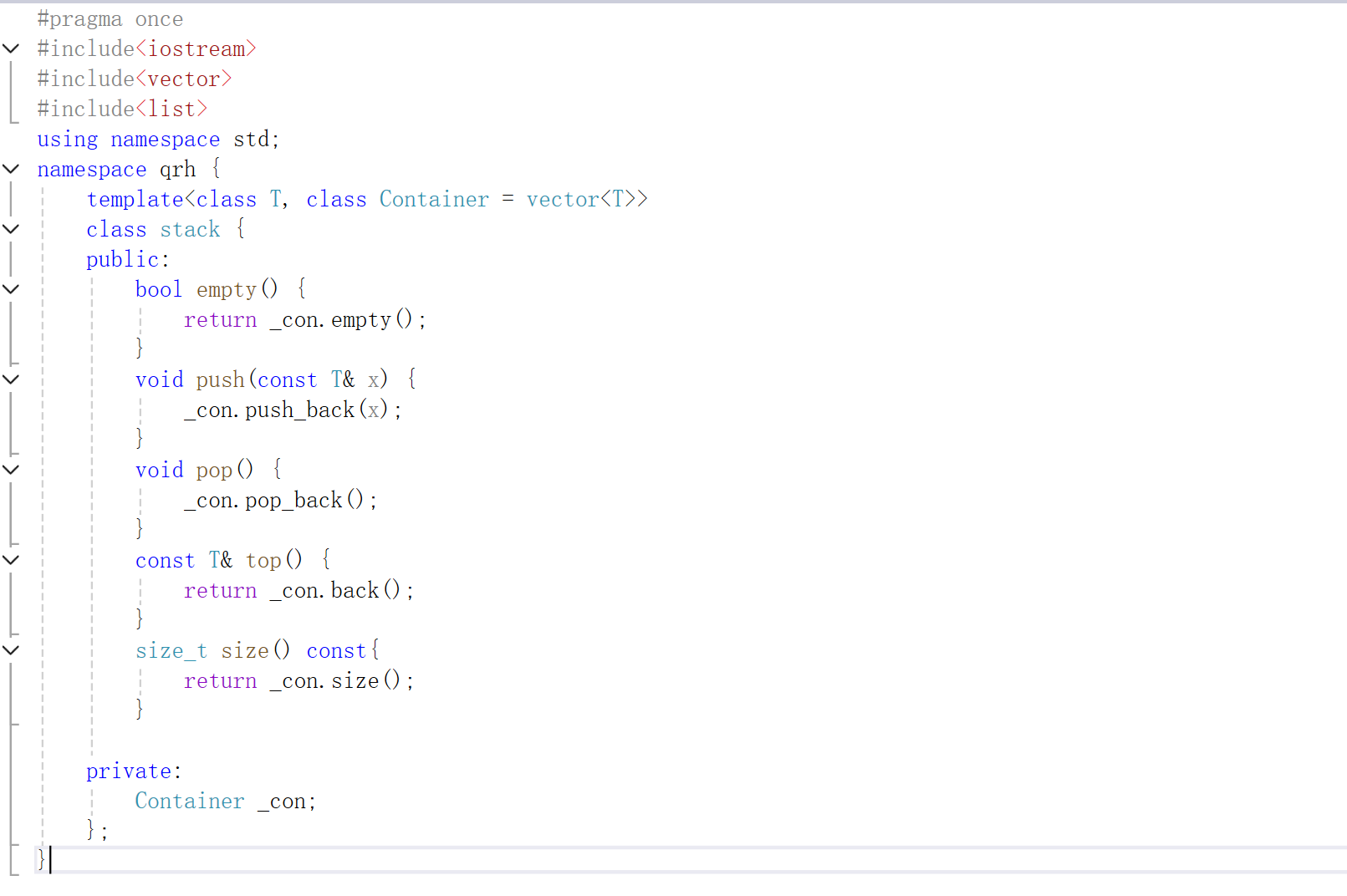
这样就ok了。
1.3 队列
队列和上面也是同理,我们就直接写了。
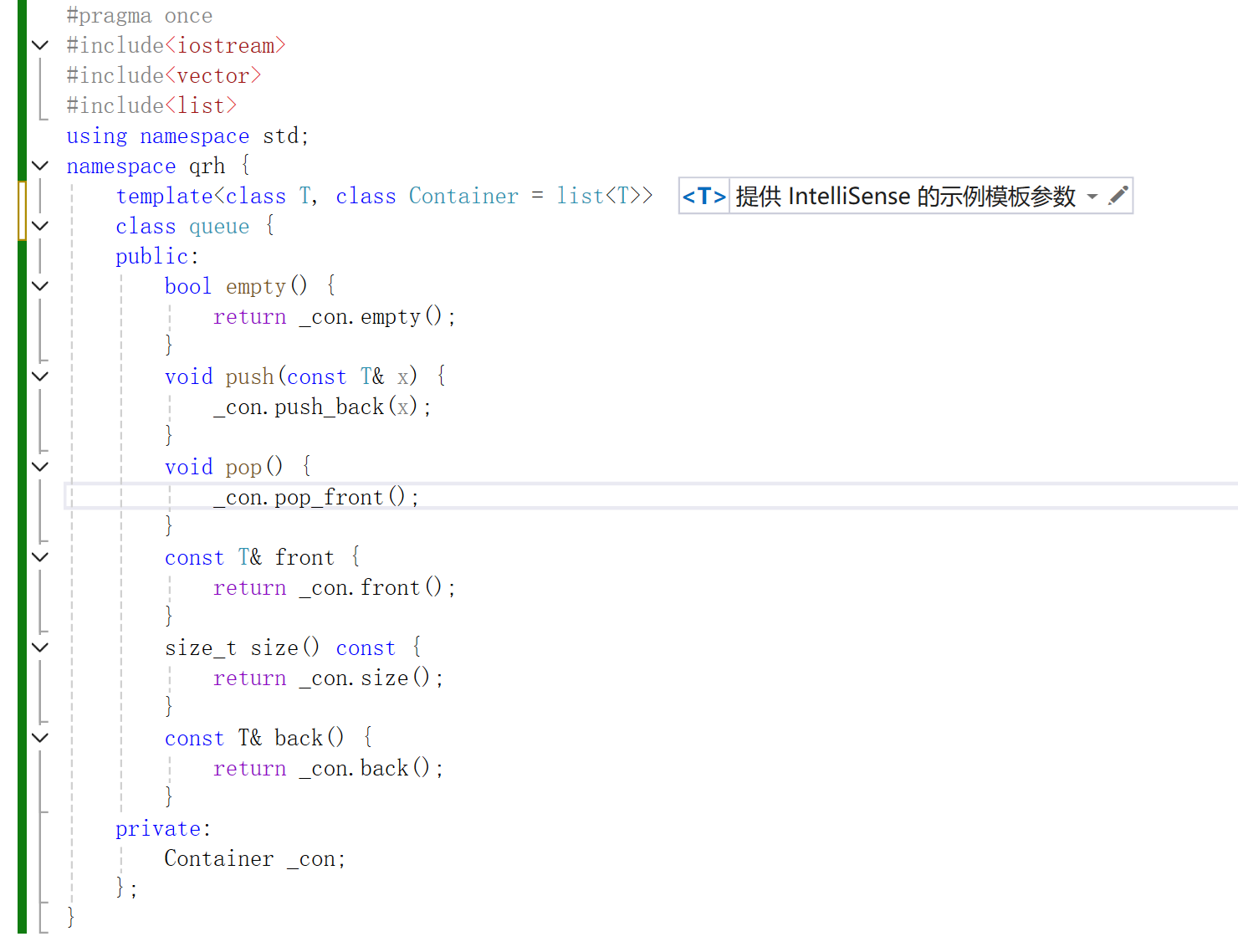
我们这个队列的缺省值只能给list,因为vector是没有pop_front()这个方法的,所以不能传入vector,否则将会报错。
我们上面传入vector和list只是让我们了解适配器的作用,我们看cpp库中的实现,发现它是通过传入deque<T>实现的,那么这个deque是什么呢?
1.4 deque<T>
因为这个是不太常用的,所以我们不会讲的太详细,会让你明白为什么传入这个作为参数。
这个叫做双向队列,虽然是队列,但是它和我们数据结构中的队列完全不同,接下来我们就来看一下。
我们要想弄明白这个,首先我们就要分析一下vector和list的优缺点。

这个是我大致总结的优缺点,可能不全,我们发现vector和list都是有缺点的,我们都知道,vector的下标随机访问虽然用着很爽,但是它的insert和删除数据却效率很低,我们的list虽然插入删除的效率高,但是无法通过下标直接访问,所以,有些大佬看看能不能将vector和list的优点给结合一下,这时这个deque就诞生了。
我们下面来看一个图。
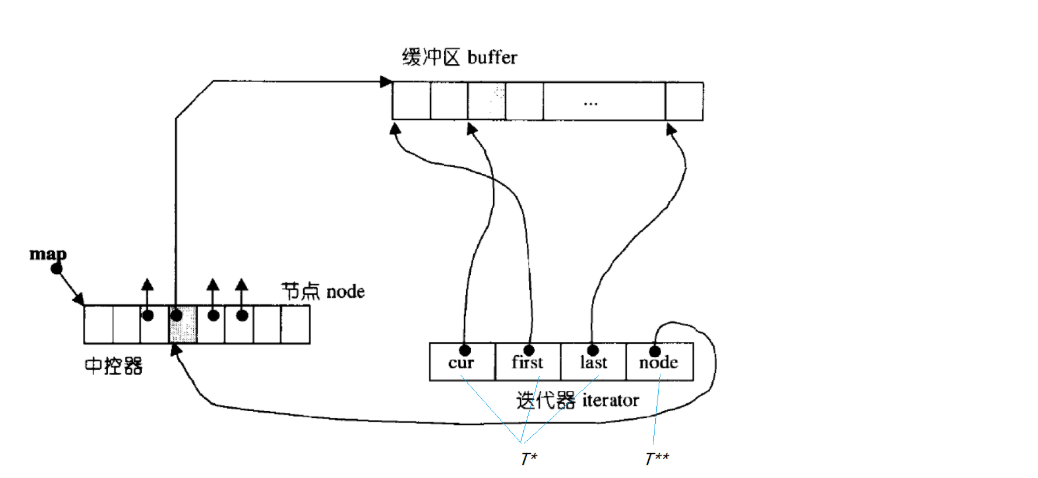
这些就是实现的基本组件。
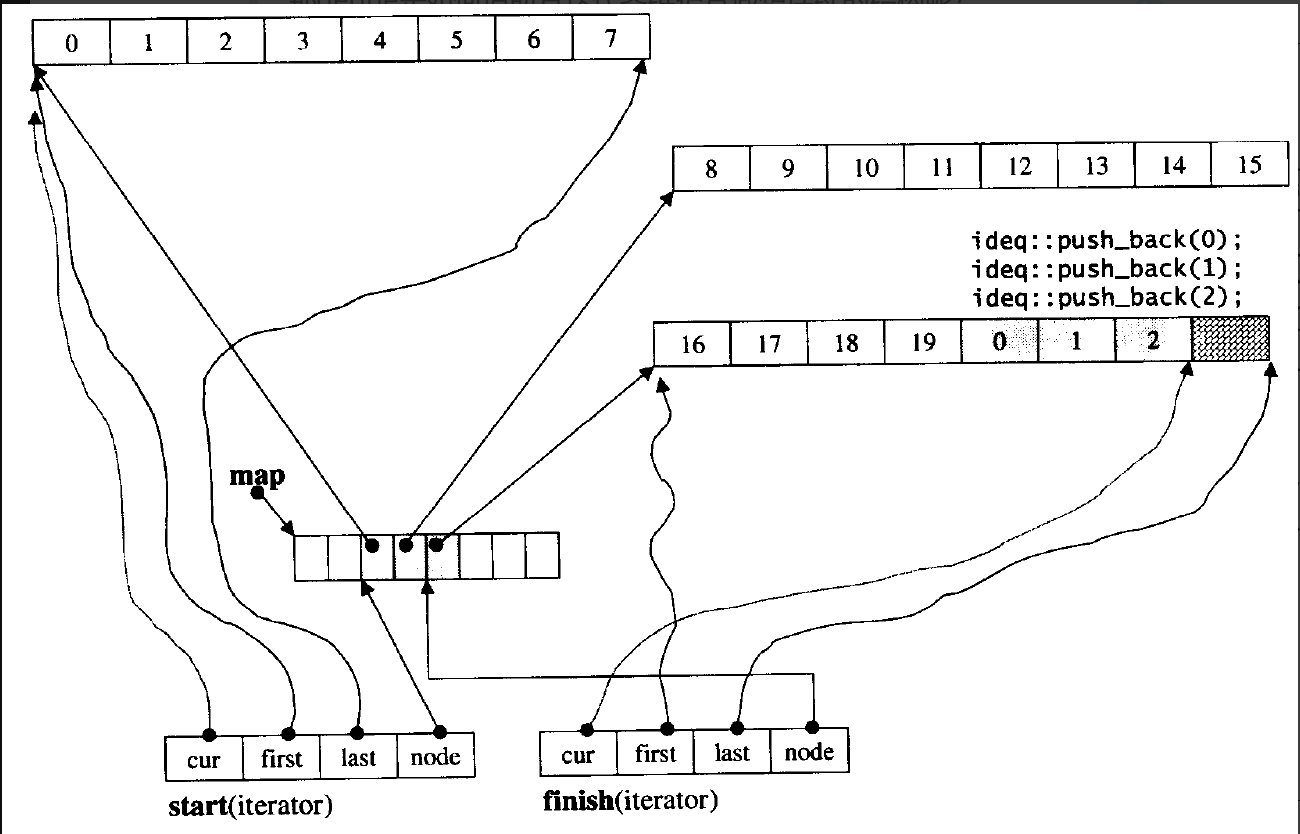
这个就是我们的底层实现原理了,相信大家可能看着有点懵,接下来我来大概讲一下吧,它的原理就是开辟buff数组来存储数据。
我们看最上面的那个就是一个buff数组,他存放了八个数据,当我们存满的时候,它会再开一个buff数组,大小和前面的相同,然后通过一个中控数组来控制,这个中控数组就是一个数组指针,就是数组里面存放的是指针,指针都是这些buff数组的第一个位置的地址,可以通过这个中控数组来控制我们访问的是哪个buff数组,然后就是两个迭代器,一个是start和finish迭代器,迭代器中有四个变量,前三个是T* 类型的,初始状态,cur,first都指向第一个buff数组的头位置,last执行第一个buff数组的尾,finish顾名思义就是指向最后一个buff数组了,最后一个node是T** 类型的,start迭代器的node的初始状态是指向我们的中控数组的第一个位置的,指向指针的地址的指针我们要用二级指针,finish则是指向中控数组的最后一个元素的,这个中控数组满了是要扩容的。
我们了解完这些工具之后我们来看一下它是怎么操作的吧。
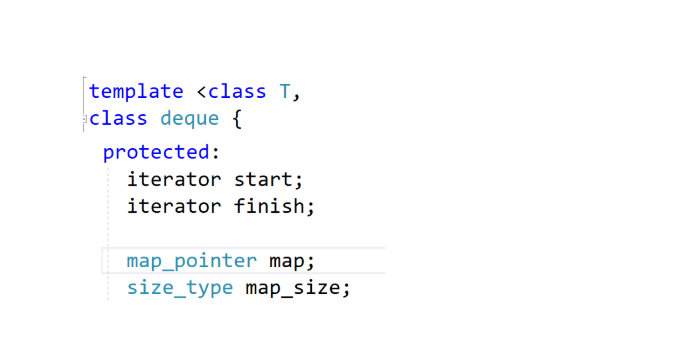
这就是这个类,这个map_pointer是T** ,我们再来看一些方法。

我们先看一下第一个*操作,就是返回*cur,cur指针就是指向我们当前访问的数据的,迭代器是通过移动cur指针来完成遍历的。
我们再来看看++操作,这些方法都是封装在我们start迭代器的结构体中的,每次都是移动cur指针,当cur==last的时候,也就是我们的这个buff数组遍历完了,此时就要去往下一个buff数组了,它的做法就是通过set_node方法,我们来看一下,通过传入了node+1,此时就把下一个buff数组的头位置的地址的地址给了形参new_node,然后让node=new_node,此时node就指向下一个buff数组头位置的地址的地址了,此时让first=*new_node,此时我们的start的frist就指向下一个buff数组的头位置的地址了,然后再改变last的指向,再返回到上面的if语句中再让cur=first即可完成变到下个buff数组。
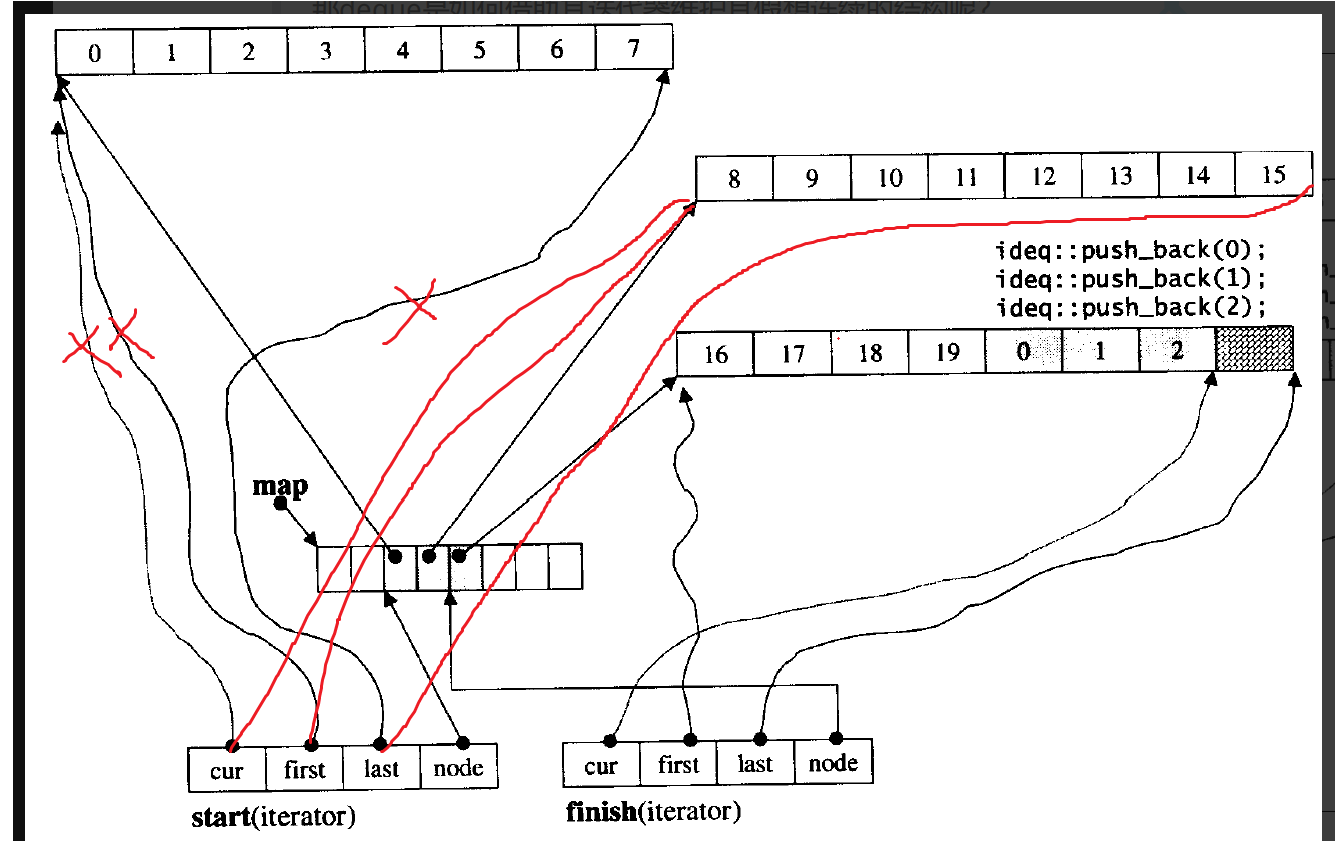
就是这个操作了,此时我们的push_back操作就是直接让*last=x(我们要插入的数据),last++即可了,满了就再开buff数组,改变finish迭代器的指向即可,和上面的改变操作一样。
那么我们头插怎么办呢?
比如我们push_front(2).
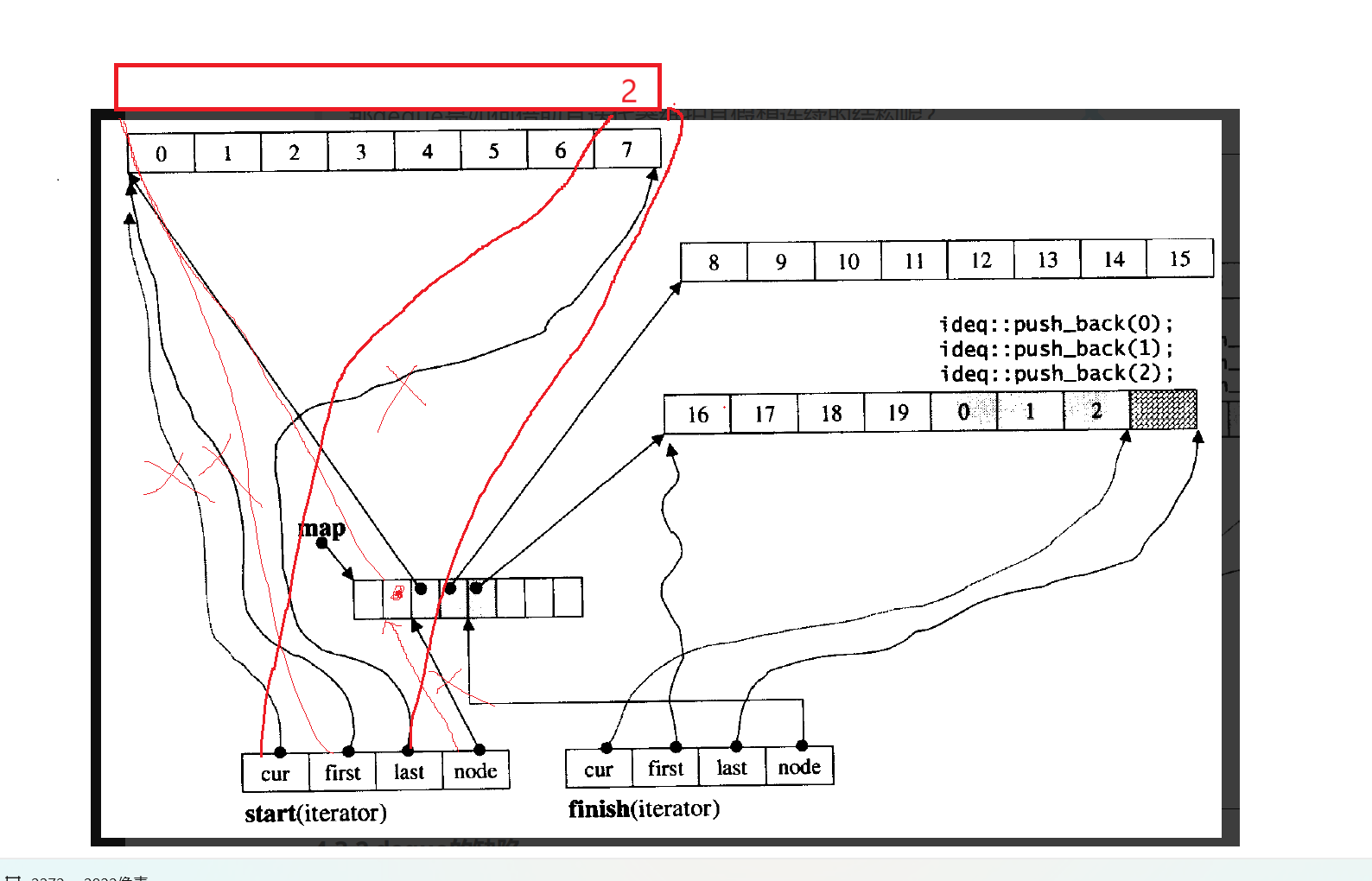
就是上图的这个操作了,就是在中控数组的前面再加入我们新开的buff数组的头位置的地址,我们初始的中控数组,我们的第一个buff数组的地址存放的是中控数组的中间位置,而不是第一个位置,这个要注意一下,中控数组前面或者后面满了都是要扩容的。
上图就是开一个buff数组,把它的头位置的地址存放在原来中控数组的第一个有数据位置的前一个位置即可,然后再改变finish迭代器中指针的指向即可,为什么2要放在buff数组的最后一个位置呢?因为我们++之后就能直接跳到下一个buff数组了,如若放在第一个位置,++之后就是空了。
综上我们就讲清楚了基本使用,接下来我们来讲一下它是如何通过[]来访问数据的。

就是这个规则了,通过第一个算式来找到在第几个buff数组中,通过取余再找到在这个buff数组的第几个位置就可以访问得到了。
但是它的insert和erase操作在中间插入或者删除数据的时候还是要大量挪动数据的和vector一样,有人在想能不能直接在这个buff数组中通过扩容插入数据呢?
答案是不行的如果这样做的话,我们buff数组的大小不一样,此时我们的[]操作符就失效了。
下面来总结一下。

就是这个优点和缺点了,我们也可以测试一下第二个特点。
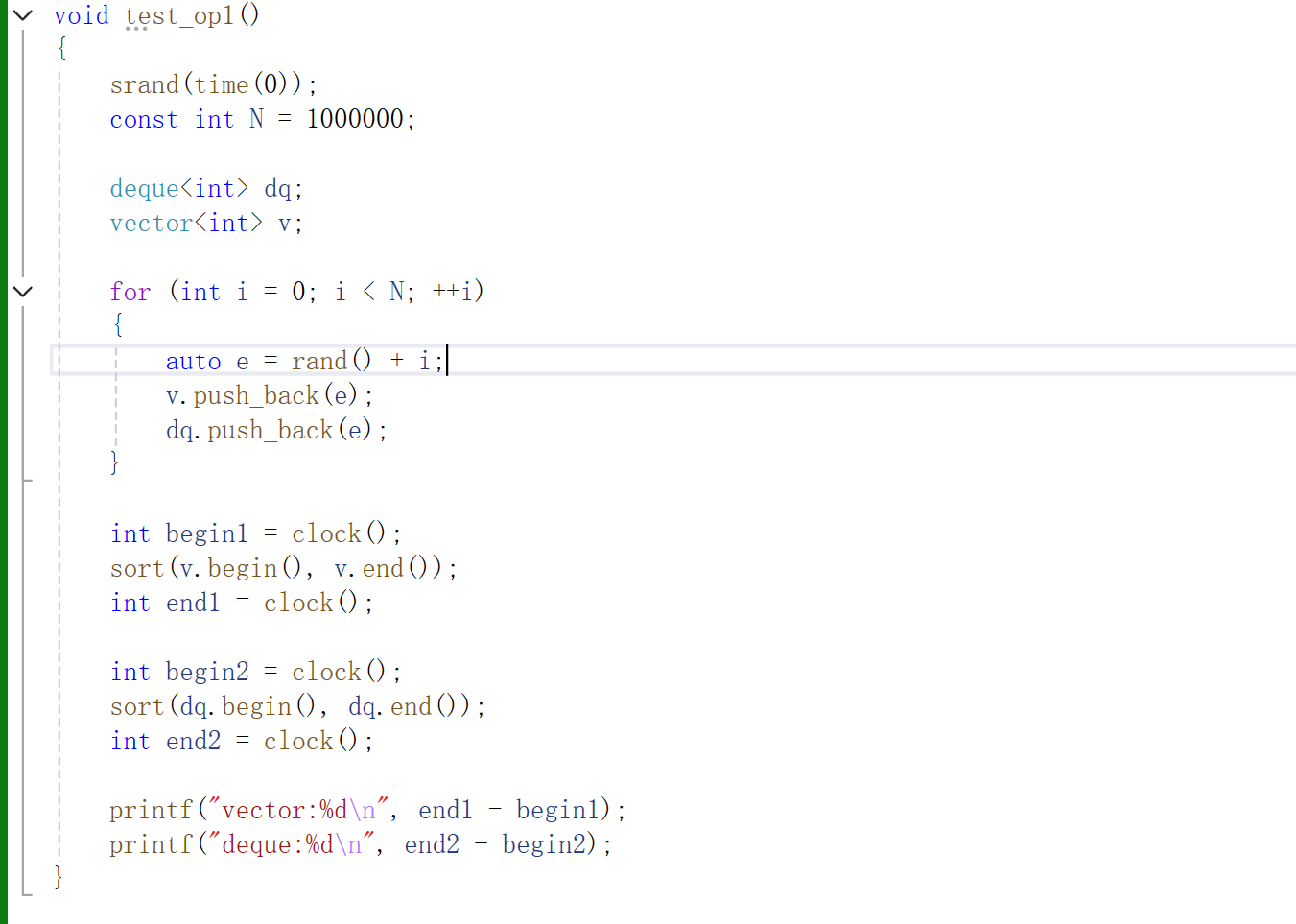
我们来测试一下效率。
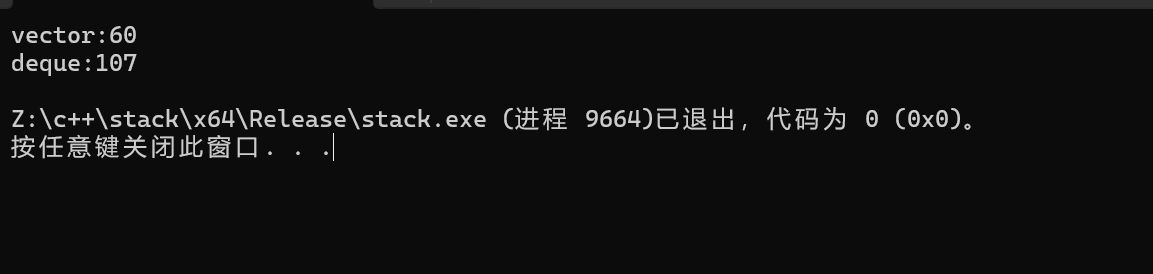
我们看这个deque的[]操作符所用时间是vector的二倍,我们要是想排deque中的数据,我们可以像下面一样。
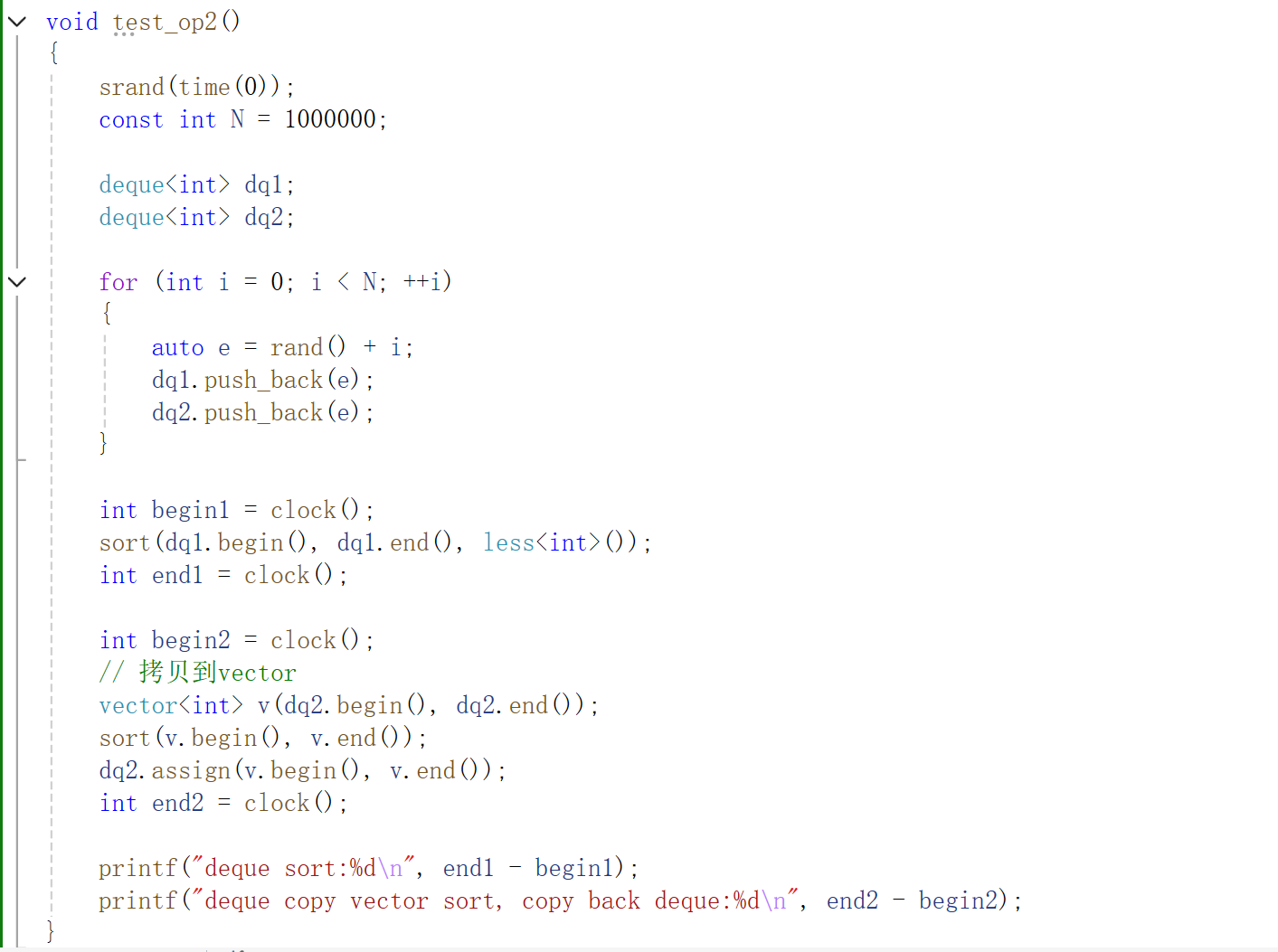

此时还是vector快,我们要想排序可以这样实现。
这样我们就大概可以了解deque了。
二.结束语
感谢大家的查看,希望可以帮助到大家,做的不是太好还请见谅,其中有什么不懂的可以留言询问,我都会一一回答。 感谢大家的一键三连。
