机器学习--线性回归模型
阅读本文之前,可以读一读下面这篇文章:终于有人把线性回归讲明白了
0、引言
线性回归作为统计学与机器学习的入门算法,以其简洁优雅的数学表达和直观的可解释性,在数据分析领域占据重要地位。这个诞生于19世纪的经典算法,至今仍在金融预测、市场营销、医学研究等场景中焕发着蓬勃生机。
我们先看一个例子。
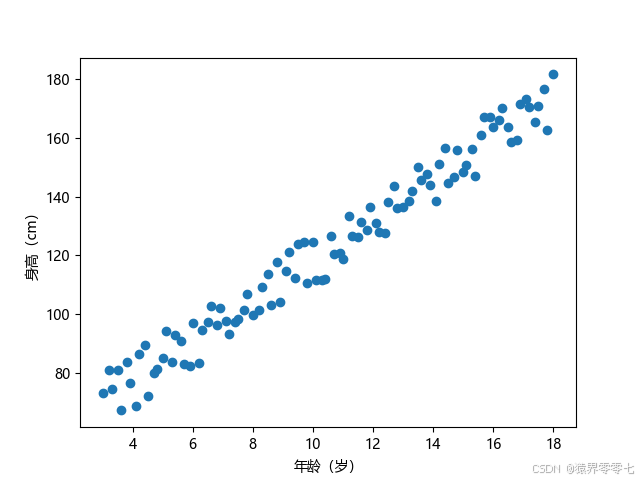
上图中展示了100名青少年男孩年龄与身高之间的关系,其中横坐标是年龄,纵坐标是身高,蓝色原点是青少年身高和年龄的坐标点。从图中可以直观的看出,年龄越大,身高越高,而且增长趋势接近一条直线,我们怎样去表示这种情况呢?中小学时,我们学过,可以用一元一次函数表示一条直线。我们假设有一条直线可以表示身高和年龄的关系。
用x表示年龄,y表示身高。现在x、y都是已知数据(图中点的坐标),那么怎样确定这条直线呢,我们可以尝试在图中画几条直线,看一看哪条更符合实际情况。
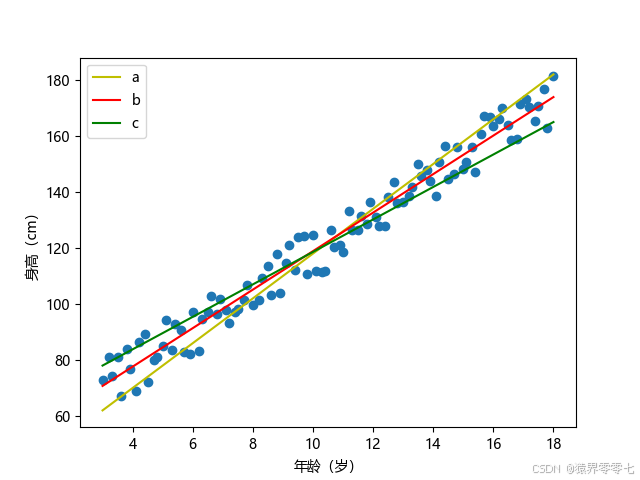
我们在图中画了三条直线a、b、c,这三条直线都经过了一些点,也避开了一些点,貌似这三条直线都可以说明身高与年龄的关系,究竟哪一个更好呢?我们怎样选择最好的呢?
无论我们怎么画都不能将所有的点画到同一条直线上。因为我们画的这些直线,并不能完美表示年龄和身高的关系,所有称之为预测函数。
图中坐标点中x坐标在直线上的值叫做预测值f(x),预测值f(x)与真实值y的差值,称为误差。
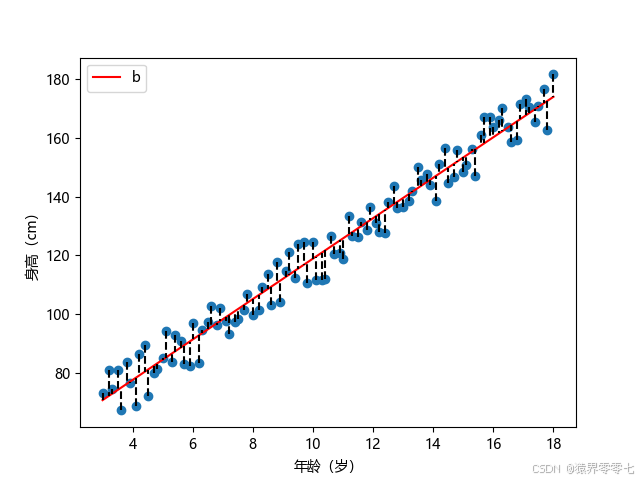
取其中一条直线,画出每个坐标点与预测函数的误差,可以直观的看出,有些点的误差小,有些点的误差大,我们是否可以用误差找到一条合适的直线呢?带着这些问题,让我们一起走进线性回归的世界。
1、定义
上面的例子中,提到影响青少年身高因素只有年龄,像这种寻找只有一个自变量(特征)x,与因变量(标签)y之间的线性关系的模型,叫做一元线性回归。
现实生活中,影响青少年的身高因素,不只是年龄,还有饮食、睡眠、遗传和运动等因素,像这种寻找多个自变量(特征)x,与因变量(标签)y之间的线性关系的模型,叫做多元线性回归。
多元线性回归几何图形很抽象,我们可以简化理解为,二维平面中的一条直线,三维立体空间中的一个平面。总之,它在空间内是直的、平的。
线性回归(Linear Regression)是一种用于建模和分析变量间线性关系的统计学方法,其核心目标是建立自变量(特征)与因变量(目标)之间的最佳线性拟合模型。通过最小化预测值与真实值的误差,量化变量间的关联程度,并用于预测或解释数据规律。
上面一段统计学中线性回归的定义,看着不像人话,看不懂也没关系。
使用数学公式可以表示为:
公式①
其中:
- Y是因变量(真实值);
是自变量(特征或解释变量);
是截距(模型的偏置),有些书籍和文章中使用的是
、
或b;
是自变量的系数(模型的斜率),有些书籍和文章中使用的是
、
;
是误差项,表示模型无法解释的随机误差;
一元线性回归的公式可以简化为:
2、前提条件
- 自变量和因变量在理论上有因果关系;
- 因变量为连续型变量;
- 各自变量与因变量之间存有线性关系;
- 残差
- 多个自变量不存在多重共线性。
其中,线性(Linear)、正态性(Normal)、独立性(Independence)、方差齐性(Equal Variance),俗称LINE,是线性回归分析的四大基本前提条件。
这里稍微解释它们概念:
Q1 线性:解释自变量X和因变量Y必须要有线性关系吗?
---不是!只有当X是连续型数据或者等级数据(不设哑变量)时,才要求X与Y有线性的关系。当X是二分类或无序多分类,没有线性条件的要求。
Q2独立性:要求因变量Y各观察值相互独立吗?
---不是,是要求残差是独立的。
Q3正态性:要求因变量Y各观察值正态分布吗?
---不是,是要求残差正态分布。
Q4方差齐性:要求不同的解释变量X时,因变量Y方差相等吗?
---没错,但是对于多元线性回归分析,更加合理的理解是在不同Y预测值情况下,残差的方差变化不大。
Q5:一定要严格满足LINK吗?
---如果回归分析只是建立自变量与因变量之间关系,无须根据自变量预测因变量的容许区间和可信度等,则方差齐性和正态性可以适当放宽。
3、预测函数
线性回归模型的基本原理是寻找一条直线(或者在多维情况下是一个超平面),以最佳地拟合训练数据,使得模型的预测与真实观测值之间的误差最小化。寻找过程中使用的函数称为预测函数,可以写作、
、
、
等形式,此处我们使用
公式②
初次接触线性回归模型的小伙伴,可能理解上面两个公式比较困难。仔细观察公式② ,其实就和我们小学时就无比熟悉的一元一次方程式: 是同样的性质。只不过,在实际场景中,特征只有一个的情况几乎不存在,通常样例数据中会包含多个特征(
),因此我们常说线性回归模型,也就是多元线性回归模型。
在训练模型过程中,通常使用拥有m个样本,n个特征X的训练集。为了保持样式统一,让截距乘以一个人为构造的特征值都是1的特征
。训练集特征X是一个(m,n+1)的矩阵,特征参数w是一个(n,1)的列向量。
公式②可以写成矩阵的形式
简写为:
公式③
在线性代数中,字母的大小写通常用于区分不同类型的数学对象(如标量、向量、矩阵等),这种区分有助于快速识别变量类型。以下是常见的规则和惯例:
1. 标量(Scalar)
- 表示方法:小写斜体字母(如 a,b,c)。
- 特点:标量是单个数值,无方向性。
示例:a=5, x∈R
2. 向量(Vector)
- 表示方法:
- 小写粗体字母(如 v,w)。
- 手写时可用箭头(如
)。
- 特点:向量是一维数组,有方向和大小。
示例:,
=(3,4)
3. 矩阵(Matrix)
- 表示方法:大写粗体字母(如 A,B)。
- 特点:矩阵是二维数组,表示线性变换或方程组系数。
示例:,
4、模型的目标
线性回归模型的目标是通过优化算法找到一组模型参数(权重),使得模型的预测值尽可能接近真实值,其核心是最小化预测值与真实值之间的误差。常用的最小二乘法和梯度下降法求解
5、最小二乘法
最小二乘法的目标是最小化误差平方和(Sum of Sqaured Error简称:SSE,又叫残差平方和 Residual Sum of Squares简称:RSS),指的是所有训练样本的真实值减与预测值差值的平方的总和,公式如下:
通过转换我们得到了关于自变量w的一元二次的损失函数,一阶导数为0的点是它的极值点。
下面求导过程中涉及线性代数矩阵求导的知识,如果看不懂,可以忽略求导过程,直接看求导结果就可以了,因为python库中已经封装好了对应的方法,不需要自己一步步实现。
矩阵求导简画公式,其中a是常数:
函数为凸函数,一阶导数等于0求最小值点,得到:
公式④
看完参数的整个求导过程,是不是很纳闷,为什么叫“最小二乘法”。一些书籍和文章中是这样解释的,大概意思是:误差平方和中的平方也叫二乘,最小化误差平方和的过程,就叫做最小二乘法。
最小二乘法得到的是解析解,并且是全局最优解。但要求比较严格,多个自变量间不能存在多重共线性,并且随着特征、样本量的增多,会变得越来越耗时。
6、梯度下降法
很多文章中在讲梯度下降时,都会用下山举例说明,我们也从下山的例子开始说起。
假设有一座像下图一样有坡度的山,我们站在山中的某一处,周围可见度有限,我们想要到达山谷,应该怎么做呢?一般我们会观察所在位置的周边,找到最陡峭的方向,并朝着这个方向往下走去,当走了一段距离后,我们会再次观察周边情况,找到最陡峭的方向,然后走下去,就这样我们走一会观察一下,一步步走到了山下。
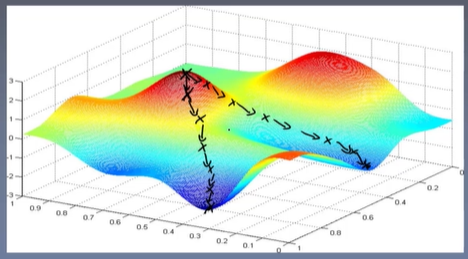
梯度下降法可以类比下山法,也是走一步看一步,每一步都找一个下降最快的方向向下走。下山的过程中会经过很多点,每经过一个点就会得到一组模型参数w,每组模型参数w可以都可以组成一个预测函数,经过的每个点代表所有样本在当前点对应预测函数的预测值与真实值的误差平方和(梯度下降法使用的损失函数也是均方误差)。
什么是梯度?
梯度是微积分中的一个概念,表示一个函数在某个点的变化率或斜率的向量值,因此它是一个向量,梯度的方向是函数增加最快的方向,梯度的大小表示函数在某个点处的变化率的大小。(关于梯度更多的知识,有兴趣的小伙伴可以自学微积分)
可以简单理解为梯度是函数某点上的切线的斜率,其方向是使得函数值上升的方向。
多元线性回归的损失函数画图太复杂,下面我们使用一元线性回归的损失函数画图说明梯度下降的求解过程。
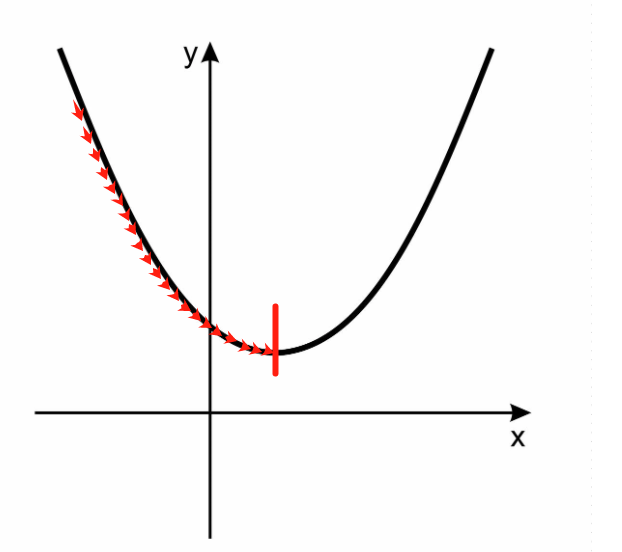
梯度下降法使用的损失函数是均方误差,均方误差是在误差平方和公式的基础上,再除以样本总量m
可以看到损失函数的公式中,多成了一个1/2,其目的只是为了简化后面的求导结果,没有实际意义。并且我们要求解的是极值点,乘以1/2不会改变极值点的位置(不会改变模型参数w),只会影响极值的大小(不需要关系极值大小)。
模型参数个数共n+1个,需要分别求出每一个方向上的梯度,因此需要对每一个求导
公式⑤
此处先埋下一个问题,梯度下降法使用的损失函数为什么是均方误差,而不是误差平方和?
对上面求导结果取负值(梯度是上升方向,取负值后是下降方向),得到梯度下降方向。现在有了方向知道往那走了,接下来就是一次走多远的问题了。
每次走的距离叫做步长,也称为学习率(Learning Rate),是决定每次迭代中参数更新幅度的关键超参数。它直接影响算法的收敛速度、稳定性以及最终能否找到最优解。
有了方向和步长,就可以得到每次迭代(走一步)后的参数,公式如下:
公式⑥
上面是模型参数公式推导的过程,下面说一下梯度下降算法的实现步骤:
- 初始化参数:选择一个初始点(参数值)。
- 计算梯度:计算目标函数在当前参数值处的梯度。
- 更新参数:沿着梯度的反方向更新参数,步长由学习率(learning rate)控制。
- 重复迭代:重复步骤2和3,直到满足停止条件。
第4步中提到了迭代的停止条件,这个条件是人为设定的,比如梯度接近零、达到最大迭代次数等。
梯度下降法有三种常见方式:
- 批量梯度下降(Batch Gradient Descent) :每次迭代使用全部训练数据计算梯度。
- 随机梯度下降(Stochastic Gradient Descent, SGD) :每次迭代随机选择一个样本计算梯度。
- 小批量梯度下降(Mini-batch Gradient Descent) :每次迭代使用一小部分样本计算梯度。
步长大小的影响
适中的步长:可以在收敛速度和稳定性之间平衡,逐步逼近最优解。
步长过小:参数更新缓慢,需要大量迭代才能收敛,计算效率低。
步长过大:可能导致参数更新时 “跳过” 最小值,甚至在梯度方向震荡或发散。
步长的类型与策略
1. 固定步长(Constant Step Size)
-
特点:整个训练过程中步长保持不变(如 α=0.01)。
-
适用场景:简单问题或初始调试,但需手动调优,否则易陷入震荡或收敛过慢。
2. 自适应步长(Adaptive Step Size)
基于梯度历史信息动态调整步长,避免手动调参:
-
AdaGrad:对每个参数使用不同步长,初始步长较大,随迭代递减(适合稀疏数据)。
-
RMSprop:引入滑动平均缓解 AdaGrad 的过度衰减问题。
-
Adam:结合动量(Momentum)和 RMSprop,自适应调整步长并加速收敛,是最常用的策略之一。
3. 学习率衰减(Learning Rate Scheduling)
在训练初期使用较大步长快速收敛,后期逐步减小以精细调整:
-
指数衰减:
(
为衰减因子,如 0.99)。
-
分段常数衰减:在固定迭代次数后手动降低步长(如每 1000 次迭代除以 2)。
-
余弦退火:根据余弦函数周期性调整步长,兼顾全局搜索和局部优化。
如何选择合适的步长?
-
初始调试
-
从较小的初始值开始(如 10−3),逐步增大(如 10−2,10−1),观察损失函数变化:
-
若损失下降后震荡,说明步长偏大;
-
若损失长时间不变,说明步长过小。
-
-
使用学习率预热(Warm-Up):在训练初期用极小步长更新,逐步增加到预设值,避免参数初始化时梯度过大导致发散。
-
-
可视化与监控
-
绘制损失函数随迭代的变化曲线,判断是否收敛或震荡。
-
检查梯度范数(如
),若持续增大,说明步长过大需调小。
-
-
经验与最佳实践
-
深度学习中,常用初始步长范围:
,具体依赖优化器(如 Adam 通常比 SGD 的步长可设更大)。
-
对于非凸问题(如神经网络),动态调整步长(如 Adam)通常比固定步长更鲁棒。
-
7、损失函数
线性回归中常用的损失函数(目标函数)主要用于衡量预测值与真实值之间的差异,以下是几种常见的损失函数:
1、均方误差(Mean Squared Error, MSE)
- 公式:
其中,是真实值,
是预测值,N 是样本数量。
- 特点:
- 对异常值敏感(平方项会放大误差)。
- 数学性质良好,易于求导,适合梯度下降优化。
- 是线性回归中最常用的损失函数。
2、平均绝对误差(Mean Absolute Error, MAE)
- 公式:
- 特点:
- 对异常值不敏感(绝对值项限制误差放大)。
- 但在数学上不可导(在 0 点处导数不连续),可能影响优化稳定性。
- 适合数据存在较多噪声或异常值的场景。
3、均方根误差(Root Mean Squared Error, RMSE)
- 公式:
- 特点:
- 是 MSE 的平方根,结果与真实值单位一致,便于解释。
- 其他特性与 MSE 类似。
4、Huber 损失(Huber Loss)
- 公式:
其中,,δ 是超参数,用于平衡 MSE 和 MAE 的影响。
- 特点:
- 结合 MSE 和 MAE 的优点:误差较小时类似 MSE(可导),误差较大时类似 MAE(鲁棒性强)。
- 适合数据中存在部分异常值的场景。
5、Log-Cosh 损失(Log-Cosh Loss)
- 公式:
- 特点:
- 对误差的平方项和绝对值项都有折中效果,且在所有点都可导。
- 近似于 MSE,但对异常值的惩罚比 MSE 轻,比 MAE 重。
选择建议
- MSE/RMSE:默认选择,适合数据分布稳定、无明显异常值的场景。
- MAE:数据含较多异常值时更鲁棒。
- Huber/Log-Cosh:折中方案,兼顾可导性和鲁棒性。
7、模型评估
线性回归模型的评估方法可分为误差指标评估、统计检验评估和模型诊断三个维度,具体方法如下:
7.1、误差指标评估
-
决定系数(R²)
- 衡量模型对因变量变异的解释比例,取值在[0,1]之间,越接近1拟合效果越好。
- 调整R²:适用于多元回归,通过惩罚变量数量避免过拟合,更客观反映模型解释力。
-
平均绝对误差(MAE)
- 计算预测值与真实值的绝对误差均值,反映平均误差大小,对异常值不敏感。
-
均方误差(MSE)
- 误差平方的平均值,对较大误差更敏感,数学性质优良但单位与原始数据不一致。
-
均方根误差(RMSE)
- MSE的平方根,与原始数据单位一致,直观反映误差水平。
-
平均绝对百分比误差(MAPE)
- 误差百分比化,适用于标准化评估,但对零值敏感。
7.2、统计检验评估
-
模型整体显著性检验(F检验)
- 检验所有自变量联合对因变量的影响是否显著,若p值<0.05则模型有效。
-
回归系数显著性检验(t检验)
- 判断单个自变量对因变量的影响是否显著,p值<0.05表示该变量有统计学意义。
7.3、模型诊断与假设验证
-
残差分析
- 正态性:通过QQ图或Shapiro-Wilk检验残差是否符合正态分布。
- 独立性:Durbin-Watson(DW)检验残差是否存在自相关(理想值接近2)。
- 同方差性:Breusch-Pagan(BP)检验残差方差是否恒定。
-
多重共线性检验
- 计算方差膨胀因子(VIF),若VIF≥10需处理(如删除变量或正则化)。
-
异常值与强影响点检测
- 使用Cook's Distance识别异常值,若值>1需进一步分析。
参考资料:
第二十一讲 | 多元线性回归分析(超级详细)
最强总结!8个线性回归核心点!!
机器学习算法入门之(一) 梯度下降法实现线性回归_使用梯度下降方法实现线性回归算法-CSDN博客
https://zhuanlan.zhihu.com/p/706039687
https://zhuanlan.zhihu.com/p/361449903
线性回归 (Linear Regression) | 菜鸟教程