【SAM2代码解析】training部分代码详解-训练流程
2.1 初始化

- initialize_config_module(“sam2”, version_base=“1.2”) ----> 初始化Hydra配置模块,并指定配置根目录为sam2(sam2目录应包含配置文件来定义模型、训练参数等),声明配置兼容Hydra1.2版本
- 参数列表

2.2 训练流程(main函数)
- 1、读取
sam2.1_hiera_b+_MOSE_finetune.yaml的内容,compose用于加载配置文件
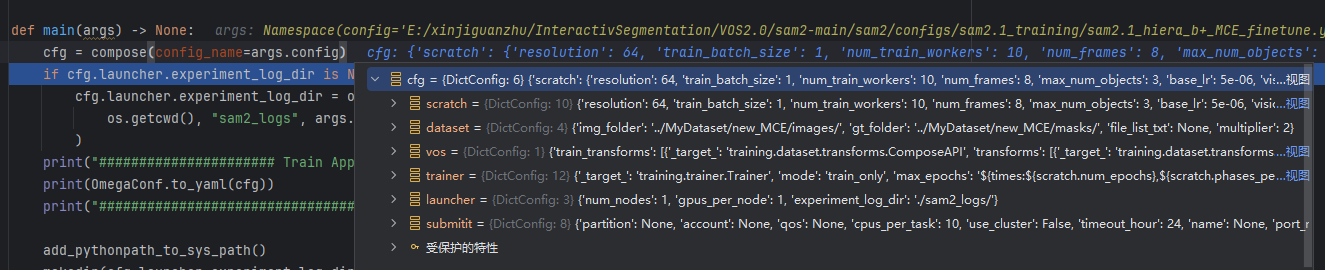
- 2、创建日志文件夹,如果在配置文件中,experiment_log_dir为None则自动创建
sam2_logs的文件夹,否则则按你设置的文件夹名创建。(注:这里自带的配置文件里,experiment_log_dir设置的null,如果你不改,那么就会报错,具体请看我主页的报错记录)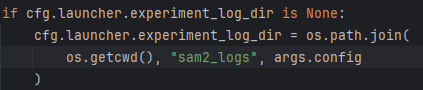
- 2.1、创建日志文件
config.yaml并保存当前配置信息

- 3、输出配置细节,注意
OmegaConf.to_yaml(cfg)的作用是将配置对象的内容转换成字符串

- 4、处理配置的解析版本
- 将 OmegaConf 配置对象cfg转换为一个普通的 Python 容器(如字典或列表)。这使得配置可以被其他不支持 OmegaConf 的代码使用。然后又立马转换成配置对象,这样就得到了一个复制的cfg配置对象—cfg_resolved
 、
、 - 将解析后的配置保存为 config_resolved.yaml 文件,(解析指的是将动态变量变为确定值)


- 将 OmegaConf 配置对象cfg转换为一个普通的 Python 容器(如字典或列表)。这使得配置可以被其他不支持 OmegaConf 的代码使用。然后又立马转换成配置对象,这样就得到了一个复制的cfg配置对象—cfg_resolved
- 5、submitit日志记录设置,
Submitit 日志是使用 Submitit 库提交集群任务时自动生成的记录文件,主要用于跟踪作业状态、调试错误和管理任务。 - 6、优先使用命令行参数,如果命令行参数中指定了 num_gpus、num_nodes 或 use_cluster,则优先使用这些值,否则使用配置文件中的默认值。
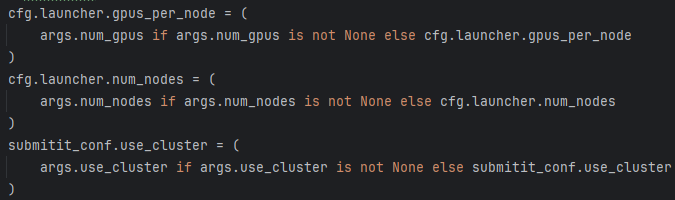
- 7、判断是否使用集群,若是使用则要设置SLURM参数,并打印相关配置,提交任务等
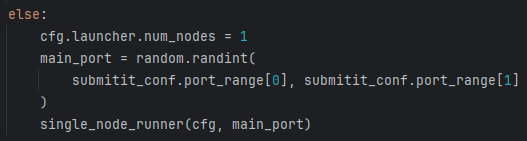
- 8、判断是否使用集群,若不使用则设置节点数量为1,随机生成一个主节点端口号,调用
single_node_runner函数在本地运行任务
总结:
- 加载配置文件并设置实验日志目录。
- 打印和保存配置文件。
- 检查是否使用集群。
- 如果使用集群,配置 SLURM 参数并提交任务。
- 如果不使用集群,则在本地运行任务。
2.3 single_node_runner
- 确保配置中指定的节点数量为 1。这是因为这个函数是为单节点训练设计的,如果节点数量不为 1,则会抛出断言错误。
assert cfg.launcher.num_nodes == 1
- 获取GPU数量,这个值将决定需要启动多少个进程
num_proc = cfg.launcher.gpus_per_node
- 设置多进程启动方法,设置pytorch多进程的启动方法为spawn
torch.multiprocessing.set_start_method(
“spawn”
) # CUDA runtime does not support fork
spawn 方法会重新启动一个 Python 解释器来运行子进程,这可以避免 CUDA 运行时的兼容性问题。
- 单GPU情况下启动程序:single_proc_run(local_rank=0, main_port=main_port, cfg=cfg, world_size=num_proc)
2.4 single_proc_run
def single_proc_run(local_rank, main_port, cfg, world_size):# 单GOU进程的入口点,用于初始化分布式训练环境并运行训练任务# local_rank--当前进程的本地排名,表示当前GPU的索引(从0开始)# main_port--主节点端口号,用于进程间通信# cfg--配置对象,包含训练任务的配置信息# world_size--全局进程总数,表示所有节点上的GPU数量"""Single GPU process,PyTorch分布式训练所必需的,用于初始化分布式通信的后端"""os.environ["MASTER_ADDR"] = "localhost" #主节点的地址,用于分布式训练的通信os.environ["MASTER_PORT"] = str(main_port) #主节点的端口号,用于分布式训练的通信os.environ["RANK"] = str(local_rank) #当前进程的全局排名,表示当前进程在整个分布式环境中的索引。os.environ["LOCAL_RANK"] = str(local_rank) #当前进程的本地排名,表示当前GPU在当前节点上的索引os.environ["WORLD_SIZE"] = str(world_size) #全局进程总数,表示所有节点上的GPU数量try:register_omegaconf_resolvers()# 扩展 OmegaConf 的功能,使其能够处理更复杂的动态表达式。# 这些解析器允许在配置文件中直接进行数学运算、类型转换、类和方法的动态引用等操作,从而使配置文件更加灵活和强大except Exception as e:logging.info(e) #将异常对象 e 的信息记录到日志中,通常在发生异常时使用,以便于后续的问题排查和调试#instantiate用于根据配置实例化对象。参数 _recursive_=False 表示不递归实例化配置中的嵌套对象。trainer = instantiate(cfg.trainer, _recursive_=False)trainer.run()#调用训练器的 run 方法,启动训练任务