windows编程字符串处理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、windows常用字符出处理函数?
- 二、测试代码
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
Windows编程中主要使用两种字符串类型:ANSI字符串(char)和Unicode字符串(wchar_t)。ANSI字符串使用单字节编码,而Unicode字符串使用双字节编码(UTF-16)。为了编写跨平台的代码,Windows提供了TCHAR类型,它可以根据编译设置自动转换为char或wchar_t。CRT库中提供了对应的处理函数,如strlen和wcslen分别用于处理ANSI和Unicode字符串。
提示:以下是本篇文章正文内容,下面案例可供参考
一、windows常用字符出处理函数?
Windows提供了丰富的字符串处理函数,包括安全字符串函数(如RtlStringCbPrintfW)和通用函数宏(如_tcslen)。这些函数可以处理不同编码的字符串,并确保操作的安全性。TCHAR.H头文件中定义了一系列宏,如__T宏用于字符串字面量的编码转换,_tcslen会根据_UNICODE定义自动选择strlen或wcslen。
常用:
_T() //自动转换为char或wchar_t
strlen
wsclen
_tsclen
WideCharToMultiByte //宽转窄
MultiByteToWideChar//窄转宽
WideCharToMultiByte
功能:将宽字符字符串(UTF-16)转换为多字节字符串(ANSI/UTF-8等)。
函数原型:
int WideCharToMultiByte(
UINT CodePage, // 目标代码页(如 CP_ACP、CP_UTF8)
DWORD dwFlags, // 转换标志(通常设为 0)
LPCWSTR lpWideCharStr, // 输入的宽字符字符串
int cchWideChar, // 输入字符串的字符数(-1 表示自动计算)
LPSTR lpMultiByteStr, // 输出的多字节缓冲区
int cbMultiByte, // 输出缓冲区的字节数(若为 0,则返回所需缓冲区大小)
LPCSTR lpDefaultChar, // 无法转换时的替代字符(通常设为 NULL)
LPBOOL lpUsedDefaultChar // 是否使用了替代字符(可设为 NULL)
);
典型用途:
将 wchar_t* 转换为 char*,例如保存为 UTF-8 文件或兼容旧版 ANSI API。
处理需要兼容非 Unicode 环境的场景。
MultiByteToWideChar
功能:将多字节字符串(ANSI/UTF-8等)转换为宽字符字符串(UTF-16)。
函数原型:
int MultiByteToWideChar(
UINT CodePage, // 代码页(如 CP_ACP 表示当前 ANSI 代码页,CP_UTF8 表示 UTF-8)
DWORD dwFlags, // 转换标志(通常设为 0)
LPCSTR lpMultiByteStr,// 输入的多字节字符串
int cbMultiByte, // 输入字符串的字节长度(-1 表示自动计算到 NULL 终止符)
LPWSTR lpWideCharStr, // 输出的宽字符缓冲区
int cchWideChar // 输出缓冲区的字符数(若为 0,则返回所需缓冲区大小)
);
典型用途:
将 char*(ANSI 或 UTF-8)转换为 wchar_t*(UTF-16)。
处理来自文件或网络的 UTF-8 数据时转换为 Windows 原生 Unicode 格式。
二、测试代码
打印中文8位和16位字符串
#include <Windows.h>
#include <iostream>
#include <tchar.h>
#include <stdio.h>void print_bin(void* p, int len)
{int i = 0;for (i = 0; i < len; i++){if (i % 16 == 0){printf("\n");}printf("%2x ", ((unsigned char*)p)[i]);}
}int main()
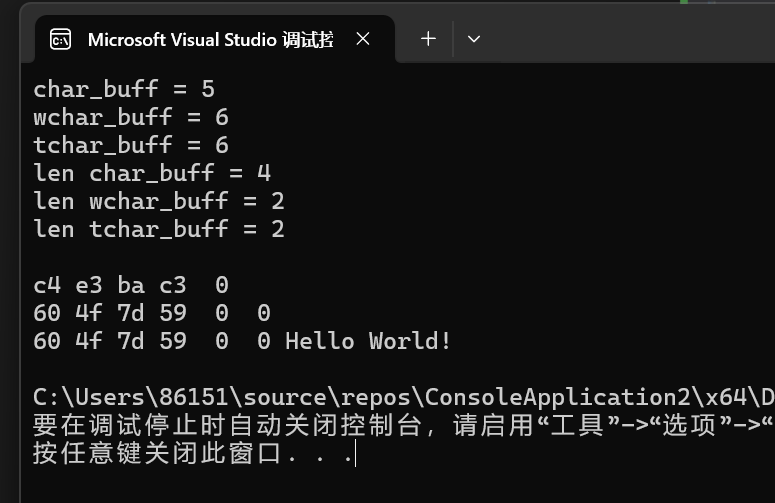
{CHAR char_buff[] = "你好";WCHAR wchar_buff[] = L"你好";TCHAR tchar_buff[] = _T("你好");printf("char_buff = %lld\n", sizeof(char_buff));printf("wchar_buff = %lld\n", sizeof(wchar_buff));printf("tchar_buff = %lld\n", sizeof(tchar_buff));printf("len char_buff = %lld\n", strlen(char_buff));printf("len wchar_buff = %lld\n", wcslen(wchar_buff));printf("len tchar_buff = %lld\n", _tcslen(tchar_buff));print_bin(&char_buff, sizeof(char_buff));print_bin(&wchar_buff, sizeof(wchar_buff));print_bin(&tchar_buff, sizeof(tchar_buff));std::cout << "Hello World!\n";
}调用堆栈
ConsoleApplication2.exe!main() 行 40 C++
ConsoleApplication2.exe!invoke_main() 行 79 C++
ConsoleApplication2.exe!__scrt_common_main_seh() 行 288 C++
ConsoleApplication2.exe!__scrt_common_main() 行 331 C++
ConsoleApplication2.exe!mainCRTStartup(void * __formal) 行 17 C++
kernel32.dll!00007ff8ce03e8d7() 未知
ntdll.dll!00007ff8cf8914fc() 未知
1,GBK编码(char_buff) c4 e3 ba c3 0 表示:
c4 e3 = "你"的GBK编码
ba c3 = "好"的GBK编码
0 = 字符串结束符 GBK编码中每个中文字符占用2个字节,所以"你好"共4字节,加上结束符共5字节。
2,UTF-16LE编码(wchar_buff) 60 4f 7d 59 0 0 表示:
60 4f = "你"的Unicode码点U+4F60的小端表示
7d 59 = "好"的Unicode码点U+597D的小端表示
0 0 = 宽字符串结束符 UTF-16LE中每个字符占2字节,所以"你好"共4字节,加上结束符共6字节。
GBK是传统的ANSI编码扩展,而UTF-16LE则是现代Unicode编码的标准实现。
GBK编码详解
GBK编码是中国国家标准GB 2312-80的扩展,全称为《汉字内码扩展规范》。它具有以下特点:
双字节编码:每个中文字符占用2个字节,英文字符保持1个字节
兼容性:完全兼容GB 2312标准,同时支持繁体中文和日韩汉字
编码范围:高字节在0x81-0xFE,低字节在0x40-0xFE
典型应用:传统Windows应用程序、简体中文版操作系统默认ANSI编码
GBK编码的优势在于存储效率高,对简体中文支持完善,但缺点是不支持国际化多语言环境。
UTF-16LE编码详解
UTF-16LE是Unicode标准的实现方式之一,特点包括:
固定长度:大多数字符(包括中文)使用2个字节表示
完整支持:可表示Unicode标准中的所有字符(包括补充字符使用4字节)
小端序:低字节在前,高字节在后
Windows原生支持:Windows API内部使用UTF-16LE作为原生字符串格式
UTF-16LE的优势在于完美支持多语言环境,且是Windows系统内核的本地编码格式。
总结
介绍了windows下字符串存储方式,8位和16位,以及常用的中文编码方式GBK和utf16le