EFL格式|动态库加载 | 重谈地址空间(2)
ELF格式(简单了解)
1. ELF Header
- 描述:ELF文件的起始部分,包含文件的基本信息。
- 内容:
- 文件类型(可执行文件、目标文件、共享目标文件等)。
- 目标机架构(如x86、x86-64、ARM等)。
- 入口点地址(程序开始执行的地址)。
- 程序头表(Program Header Table)和节头表(Section Header Table)的偏移和大小。
- 其他元数据,如ELF版本、ABI版本等。
2. Program Header Table(程序头表)
- 描述:描述如何创建进程映像,主要用于可执行文件和共享库。
- 内容:
- 每个程序头描述一个段(segment),如可加载的代码段、数据段等。
- 包含段的类型、偏移、虚拟地址、物理地址、文件大小、内存大小、标志(可读、可写、可执行)等信息。
3. Section Header Table(节头表)
- 描述:描述文件中的各个节(section),用于链接器和调试器。
- 内容:
- 每个节头描述一个节,如
.text(代码段)、.data(已初始化数据段)、.bss(未初始化数据段)等。- 包含节的名称、类型、地址、偏移、大小、标志等信息。
4. Sections(节)
- 描述:ELF文件中的实际数据部分,每个节包含特定类型的数据。
- 常见节:
.text:包含程序的可执行指令(代码段)。.data:包含已初始化的全局变量。.bss:包含未初始化的全局变量,在程序加载时由操作系统初始化为零。.rodata:包含只读数据,如字符串常量。.symtab:符号表,包含函数和变量的名称、类型、地址等信息。.strtab:字符串表,包含符号表中使用的字符串。.rel.text/.rela.text:重定位信息,用于动态链接。.dynamic:动态链接信息。.init和.fini:程序初始化和终止时执行的代码。.got和.plt:全局偏移表(GOT)和过程链接表(PLT),用于动态链接。
我们知道平时写的cpp的源文件分为代码和数据,经过编译链接形成可执行程序。可执行程序是二进制组成的。但是不单单只是简单的二进制,还有文件的属性以及格式等等。一个可执行程序也有自己的格式。
dpj@iZ2zee7b26b1g3ujcquk70Z:~/linux_code/daily_code/dir1/other$ size a.out text data bss dec hex filename //文件名3219 664 8 3891 f33 a.out
- text:代码段的大小(即程序的可执行指令)。
- data:已初始化的全局变量的大小。
- bss:未初始化的全局变量的大小(这些变量在运行时会被初始化为零)。
- dec:上述三段的十进制总和(
text + data + bss)。- hex:上述三段的十六进制总和。
- filename:目标文件的名称。
如上文所示,可执行程序其实由 text(代码),{data,bss} (数据) 等部分组成,并不是由二进制随意组成的,这种形成就是ELF( E x e c u t a b l e a n d L i n k a b l e F o r m a t ( 可执行与可链接格式 ) Executable and Linkable Format(可执行与可链接格式) ExecutableandLinkableFormat(可执行与可链接格式))。
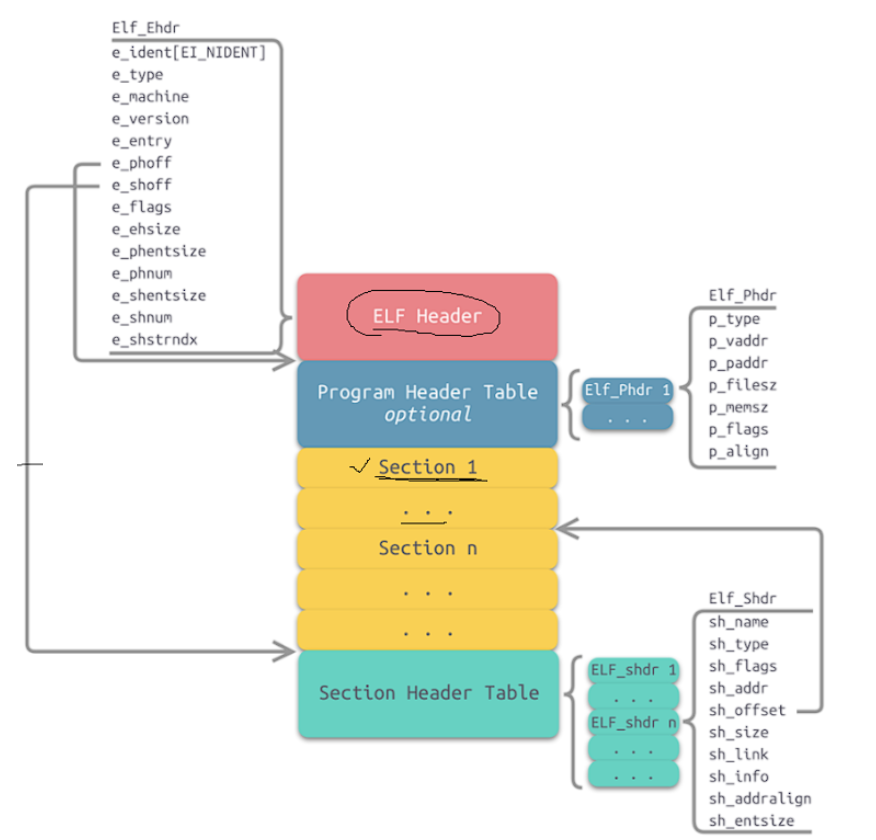
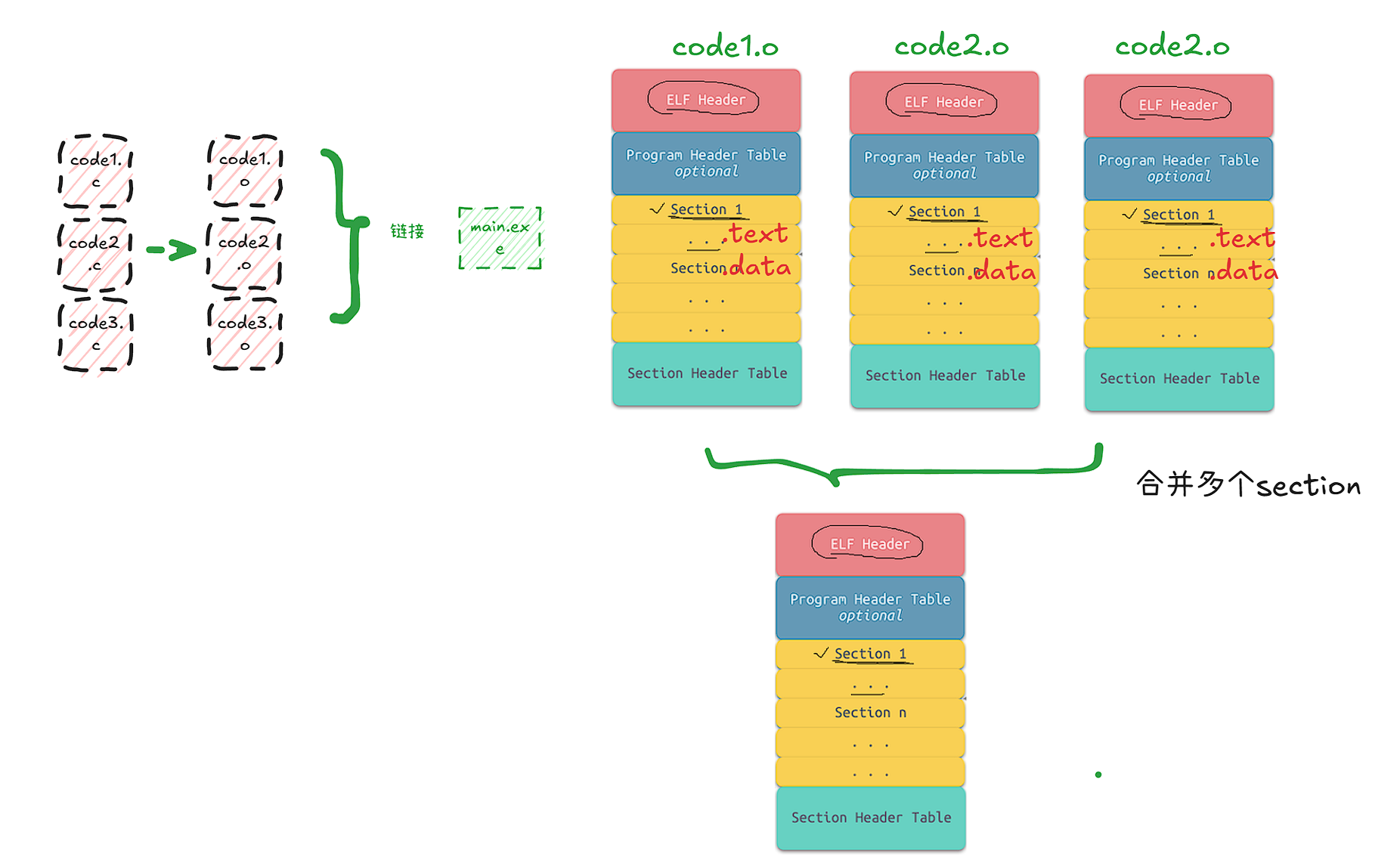
我们ELF格式的组成如上,这里其他我们先不管,上文提到的text(代码),{data,bss} (数据) ,经过编译形成一个一个的节(section)或者段(segment),例如: .text, .data, .bss。一般的除了可执行程序是这样的,我们的动态库和目标文件(.o)也是这种格式的。而对于多个源文件来说,有多个.o文件就有很多种不同的节,每一种ELF都会有 .text, .data等等的节,**所以链接的本质也就是不同的文件把相同属性的节融合在一起形成一个新的节,然后形成一个新的ELF格式的文件(.exe)。**显然这个合并方式在ELF形成的过程中就已经确定了,具体的合并规则存放在程序头表当中,可执行程序的每一个section合并之后会以一个segment的形成存在。
.symtab节 : Symbol Table 符号表,就是源码那些函数名、变量名和里面代码的对应关系
Elf file type is DYN (Position-Independent Executable file)
Entry point 0x1160
There are 13 program headers, starting at offset 64Program Headers:Type Offset VirtAddr PhysAddrFileSiz MemSiz Flags AlignPHDR 0x0000000000000040 0x0000000000000040 0x00000000000000400x00000000000002d8 0x00000000000002d8 R 0x8INTERP 0x0000000000000318 0x0000000000000318 0x00000000000003180x000000000000001c 0x000000000000001c R 0x1[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]LOAD 0x0000000000000000 0x0000000000000000 0x00000000000000000x0000000000000828 0x0000000000000828 R 0x1000LOAD 0x0000000000001000 0x0000000000001000 0x00000000000010000x00000000000005d1 0x00000000000005d1 R E 0x1000LOAD 0x0000000000002000 0x0000000000002000 0x00000000000020000x00000000000001cc 0x00000000000001cc R 0x1000LOAD 0x0000000000002d78 0x0000000000003d78 0x0000000000003d780x0000000000000298 0x00000000000002a0 RW 0x1000DYNAMIC 0x0000000000002d88 0x0000000000003d88 0x0000000000003d880x00000000000001f0 0x00000000000001f0 RW 0x8NOTE 0x0000000000000338 0x0000000000000338 0x00000000000003380x0000000000000030 0x0000000000000030 R 0x8NOTE 0x0000000000000368 0x0000000000000368 0x00000000000003680x0000000000000044 0x0000000000000044 R 0x4GNU_PROPERTY 0x0000000000000338 0x0000000000000338 0x00000000000003380x0000000000000030 0x0000000000000030 R 0x8GNU_EH_FRAME 0x0000000000002020 0x0000000000002020 0x00000000000020200x000000000000005c 0x000000000000005c R 0x4GNU_STACK 0x0000000000000000 0x0000000000000000 0x00000000000000000x0000000000000000 0x0000000000000000 RW 0x10GNU_RELRO 0x0000000000002d78 0x0000000000003d78 0x0000000000003d780x0000000000000288 0x0000000000000288 R 0x1Section to Segment mapping:Segment Sections...00 01 .interp 02 .interp .note.gnu.property .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt 03 .init .plt .plt.got .plt.sec .text .fini 04 .rodata .eh_frame_hdr .eh_frame 05 .init_array .fini_array .dynamic .got .data .bss 06 .dynamic 07 .note.gnu.property 08 .note.gnu.build-id .note.ABI-tag 09 .note.gnu.property 10 .eh_frame_hdr 11 12 .init_array .fini_array .dynamic .got
那么为什么要把多个section合并为一个segment呢?
- section合并的主要原因是减少页面碎片化,操作系统文件一般加载的块大小都是4kb(4096byte),现在加入一个.text大小为4097,而.init的大小为512字节,那么如果不合并为segment的话就需要3个节,而如果合并之后只需要两个页面。
- 此外操作系统加载程序的时候,会将相同属性的段合并在一起,这样可以实现不同的访问权限,从而优化内存管理和权限访问控制(一个segment统一权限)。
流程图如下:
而对于每一种节来说,我们有可修改的代码和不可修改,可读数据,节的范围从哪开始到哪结束?这些也需要知道,所以section需要被管理起来,所以就有了剩余的三个部分。
ELF Header 称之为ELF表头,它用来存储整个ELF格式的信息的,内容如下:
dpj@iZ2zee7b26b1g3ujcquk70Z:~/linux_code/daily_code/dir1/other$ readelf -h a.out //readelf -h 读取ELF表头
ELF Header:Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64Data: 2's complement, little endianVersion: 1 (current)OS/ABI: UNIX - System VABI Version: 0Type: DYN (Position-Independent Executable file) //ELF格式类型Machine: Advanced Micro Devices X86-64 //需要的机器架构Version: 0x1Entry point address: 0x1160Start of program headers: 64 (bytes into file)Start of section headers: 14592 (bytes into file)Flags: 0x0Size of this header: 64 (bytes)Size of program headers: 56 (bytes)Number of program headers: 13Size of section headers: 64 (bytes)Number of section headers: 31 //多少个节头Section header string table index: 30
上面内容做了解就行,那么对于可执行程序而言我们需要加载到内存,加载多少,从那开始加载呢?这些信息就在我们的 Program Header Table optional (程序头表) ,内容如下:
dpj@iZ2zee7b26b1g3ujcquk70Z:~/linux_code/daily_code/dir1/other$ readelf -l a.out //readelf -l 获取程序头表信息
Elf file type is DYN (Position-Independent Executable file)
Entry point 0x1160
There are 13 program headers, starting at offset 64
Program Headers:Type Offset VirtAddr PhysAddrFileSiz MemSiz Flags AlignPHDR 0x0000000000000040 0x0000000000000040 0x00000000000000400x00000000000002d8 0x00000000000002d8 R 0x8INTERP 0x0000000000000318 0x0000000000000318 0x00000000000003180x000000000000001c 0x000000000000001c R 0x1[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000 //段的加载地址与偏移量0x0000000000000828 0x0000000000000828 R 0x1000LOAD 0x0000000000001000 0x0000000000001000 0x00000000000010000x00000000000005d1 0x00000000000005d1 R E 0x1000LOAD 0x0000000000002000 0x0000000000002000 0x00000000000020000x00000000000001cc 0x00000000000001cc R 0x1000LOAD 0x0000000000002d78 0x0000000000003d78 0x0000000000003d780x0000000000000298 0x00000000000002a0 RW 0x1000DYNAMIC 0x0000000000002d88 0x0000000000003d88 0x0000000000003d880x00000000000001f0 0x00000000000001f0 RW 0x8NOTE 0x0000000000000338 0x0000000000000338 0x00000000000003380x0000000000000030 0x0000000000000030 R 0x8NOTE 0x0000000000000368 0x0000000000000368 0x00000000000003680x0000000000000044 0x0000000000000044 R 0x4GNU_PROPERTY 0x0000000000000338 0x0000000000000338 0x00000000000003380x0000000000000030 0x0000000000000030 R 0x8GNU_EH_FRAME 0x0000000000002020 0x0000000000002020 0x00000000000020200x000000000000005c 0x000000000000005c R 0x4GNU_STACK 0x0000000000000000 0x0000000000000000 0x00000000000000000x0000000000000000 0x0000000000000000 RW 0x10GNU_RELRO 0x0000000000002d78 0x0000000000003d78 0x0000000000003d780x0000000000000288 0x0000000000000288 R 0x1
这里先说一个结论:对于任何文件我们都可以看作是一个巨大的一维数组,我们可以通过 偏移量 + 大小的方式 来表示文件的任何一个区域。(至于我们看到的文件是因为屏幕大小不够才换行的)
如上段代码黄色标识区域,Offset 代表我们的偏移量,从0开始,这里可以看作是section的开头,紧接着下一行就是FileSize 标识我们加载的大小。同时右边有一列为FlagsR代表读,W代表写,E代表可执行。所以程序头表记录着我们可执行程序加载内容的区域范围。
如果我们想要更细致的观看每一个节的范围就需要看Section Header Table表了,内容如下:
dpj@iZ2zee7b26b1g3ujcquk70Z:~/linux_code/daily_code/dir1/other$ readelf -S a.out
There are 31 section headers, starting at offset 0x3900:Section Headers:[Nr] Name Type Address OffsetSize EntSize Flags Link Info Align[ 0] NULL 0000000000000000 000000000000000000000000 0000000000000000 0 0 0[ 1] .interp PROGBITS 0000000000000318 00000318000000000000001c 0000000000000000 A 0 0 1[ 2] .note.gnu.pr[...] NOTE 0000000000000338 000003380000000000000030 0000000000000000 A 0 0 8[ 3] .note.gnu.bu[...] NOTE 0000000000000368 000003680000000000000024 0000000000000000 A 0 0 4[ 4] .note.ABI-tag NOTE 000000000000038c 0000038c0000000000000020 0000000000000000 A 0 0 4[ 5] .gnu.hash GNU_HASH 00000000000003b0 000003b00000000000000024 0000000000000000 A 6 0 8[ 6] .dynsym DYNSYM 00000000000003d8 000003d80000000000000168 0000000000000018 A 7 1 8[ 7] .dynstr STRTAB 0000000000000540 0000054000000000000000e2 0000000000000000 A 0 0 1[ 8] .gnu.version VERSYM 0000000000000622 00000622000000000000001e 0000000000000002 A 6 0 2[ 9] .gnu.version_r VERNEED 0000000000000640 000006400000000000000050 0000000000000000 A 7 1 8[10] .rela.dyn RELA 0000000000000690 0000069000000000000000c0 0000000000000018 A 6 0 8[11] .rela.plt RELA 0000000000000750 0000075000000000000000d8 0000000000000018 AI 6 24 8[12] .init PROGBITS 0000000000001000 00001000000000000000001b 0000000000000000 AX 0 0 4[13] .plt PROGBITS 0000000000001020 0000102000000000000000a0 0000000000000010 AX 0 0 16[14] .plt.got PROGBITS 00000000000010c0 000010c00000000000000010 0000000000000010 AX 0 0 16[15] .plt.sec PROGBITS 00000000000010d0 000010d00000000000000090 0000000000000010 AX 0 0 16[16] .text PROGBITS 0000000000001160 000011600000000000000461 0000000000000000 AX 0 0 16[17] .fini PROGBITS 00000000000015c4 000015c4000000000000000d 0000000000000000 AX 0 0 4[18] .rodata PROGBITS 0000000000002000 00002000000000000000001e 0000000000000000 A 0 0 4[19] .eh_frame_hdr PROGBITS 0000000000002020 00002020000000000000005c 0000000000000000 A 0 0 4[20] .eh_frame PROGBITS 0000000000002080 00002080000000000000014c 0000000000000000 A 0 0 8[21] .init_array INIT_ARRAY 0000000000003d78 00002d780000000000000008 0000000000000008 WA 0 0 8[22] .fini_array FINI_ARRAY 0000000000003d80 00002d800000000000000008 0000000000000008 WA 0 0 8[23] .dynamic DYNAMIC 0000000000003d88 00002d8800000000000001f0 0000000000000010 WA 7 0 8[24] .got PROGBITS 0000000000003f78 00002f780000000000000088 0000000000000008 WA 0 0 8[25] .data PROGBITS 0000000000004000 000030000000000000000010 0000000000000000 WA 0 0 8[26] .bss NOBITS 0000000000004010 000030100000000000000008 0000000000000000 WA 0 0 1[27] .comment PROGBITS 0000000000000000 00003010000000000000002b 0000000000000001 MS 0 0 1[28] .symtab SYMTAB 0000000000000000 0000304000000000000004e0 0000000000000018 29 20 8[29] .strtab STRTAB 0000000000000000 0000352000000000000002c0 0000000000000000 0 0 1[30] .shstrtab STRTAB 0000000000000000 000037e0000000000000011a 0000000000000000 0 0 1
如上端代码,我们找我们熟悉的,.text,.data,.bss 这里记录的就是我们每一个节的大小,权限,以及偏移量。
重谈地址空间 (第二次)
在进程章节我们加到了进程地址空间分为正文代码,初始化全局变量,未初始化全局变量,堆区,共享区以及栈区,后三者都是加载进来后动态创建的,但是前面的呢?
所以进程地址空间是由谁初始化的呢? , 回答这个问题之前我们先来想一下,对于一个可执行程序而言,我们还没有链接加载到内存的时候,只是编译完成,那么可执行程序的代码有地址吗? ➡️ 有地址的!!!
我们把查看可执行程序的反汇编,内容如下:
Objdump -S + 可执行程序可以生成反汇编,我们放入test.s文件当中观看
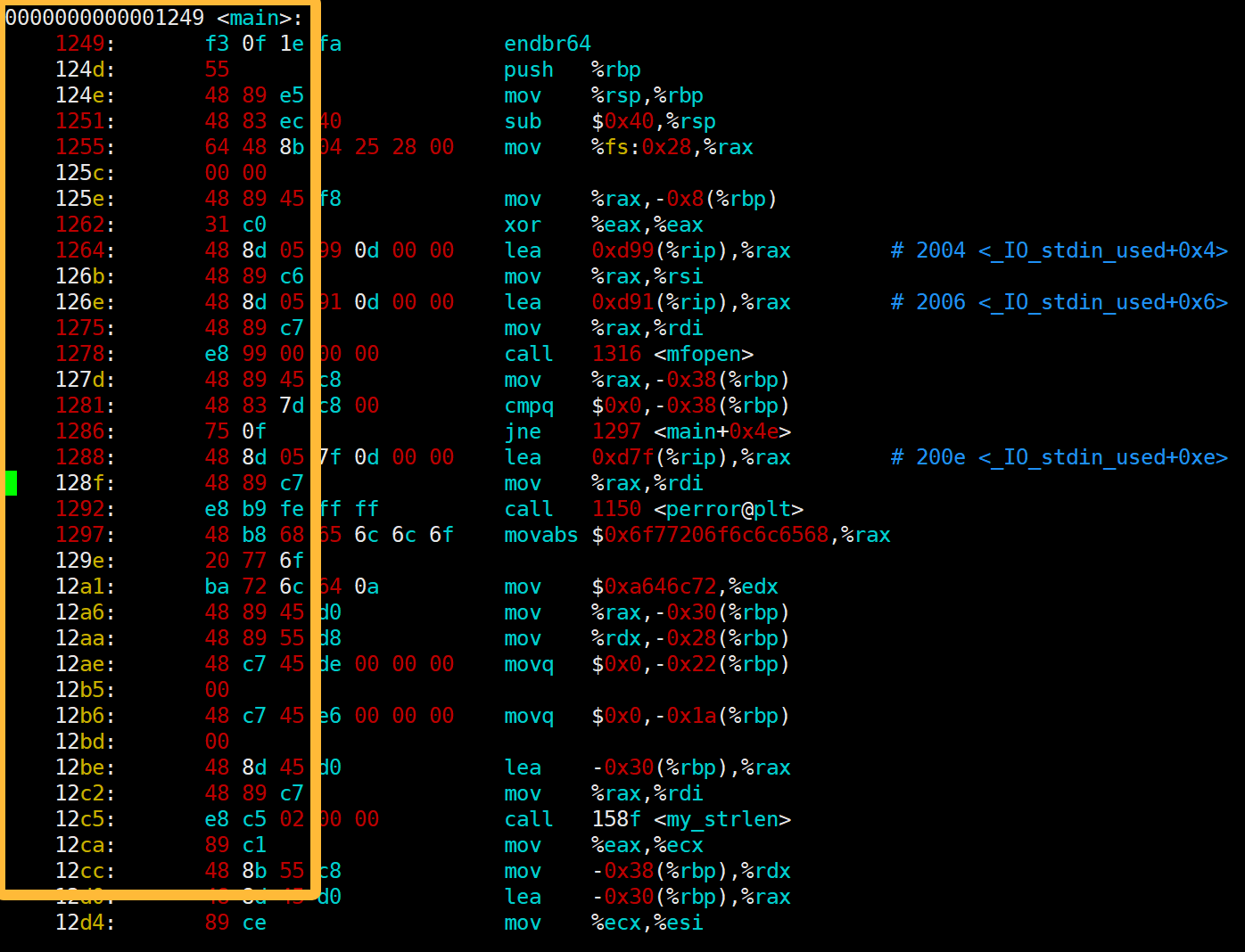
如上图,我们可以看到在我们圈出来的地方是有地址的,并且我们呢可以看到,**地址是连续的。**上述地址我们称为逻辑地址。
这里在说一个结论,现代中我们编译器编译形成可执行程序过程中,会对代码进行编址,同时这个编址采用**平坦模式,就是基地址 + 偏移量。这里的基地址我们可以看作是0就可以了。所以其实我们可以直接把这个地址看作是偏移量,因为起始地址从0开始。也就是说我们编址的过程无非就是 [0000 0000,FFFF FFFF] 进行编址,这个我们也称为虚拟地址。**所以现代中我们 逻辑地址 == 虚拟地址,只不过逻辑地址我们在磁盘当中这么称呼而已,而虚拟地址一般是在内存当中这么称呼。
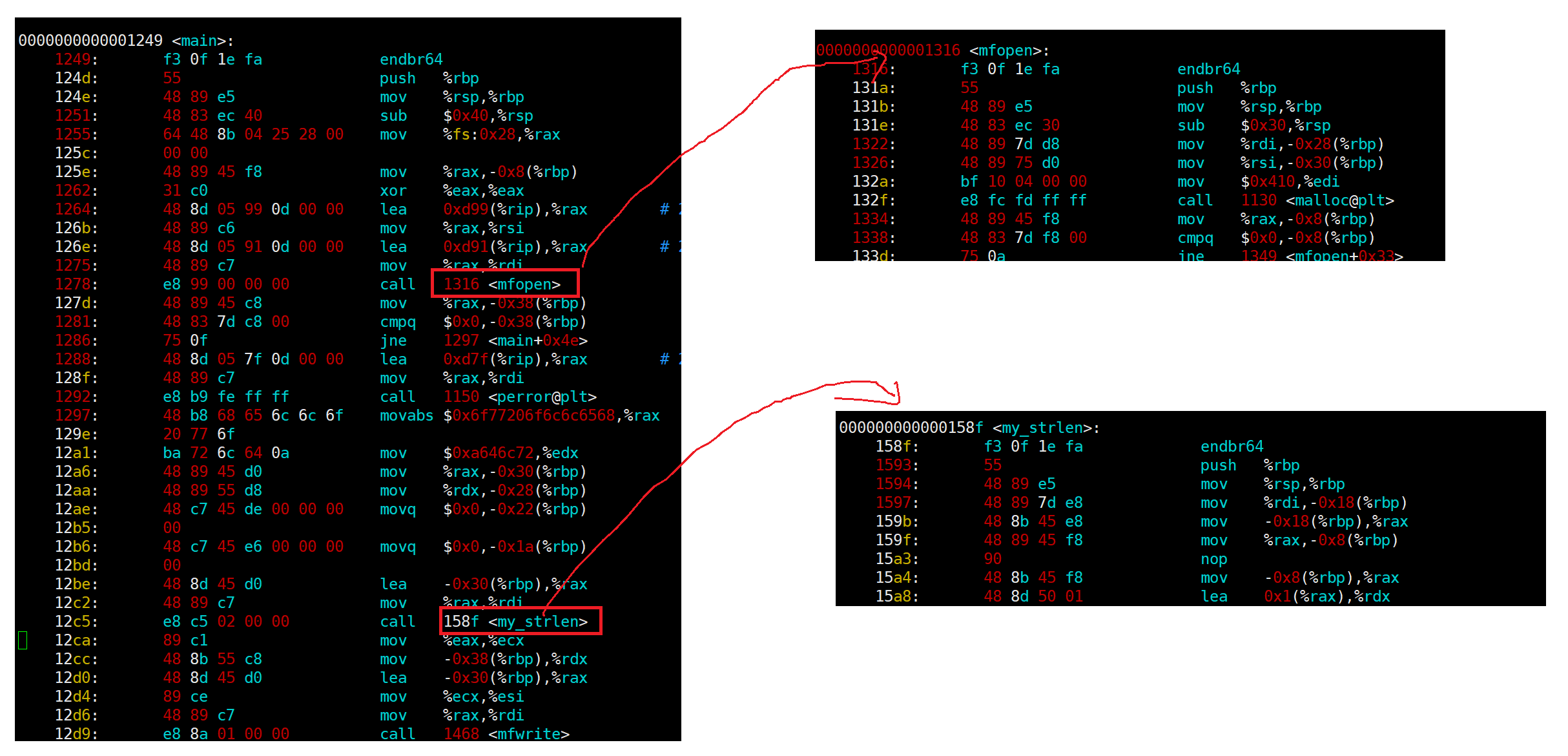
如上图,我们也可以看到在可执行程序内部当中,可以直接使用虚拟地址进行跳转。
所以进程地址空间的区域划分不就是有我们可执行程序编址的来的吗 !! ,我们的代码段不就是 .text吗 !!
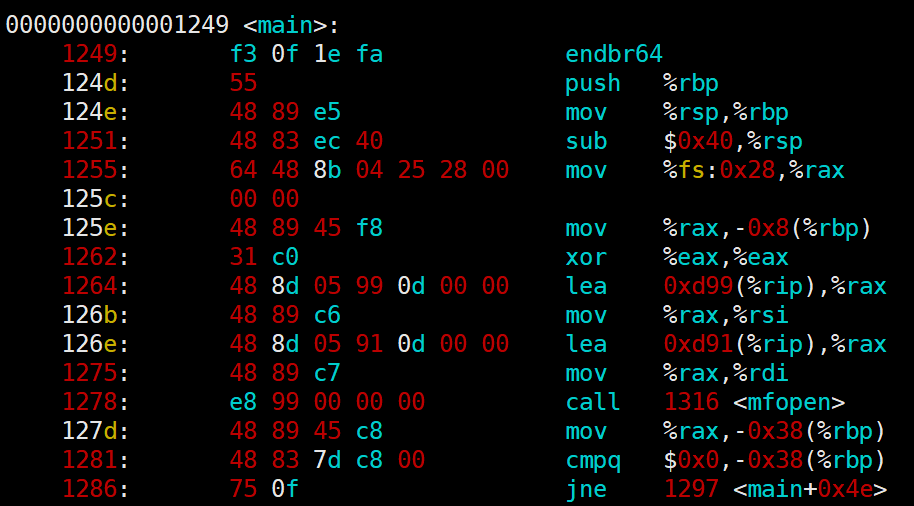
我们知道CPU运行可执行程序的时候会有PC寄存器拿到程序的入口地址,然后自动更新下一条指令的地址,从上图可以看出,其实我们指令也是有长度的。以前两个地址为例子:124d-1249 不就是我们第一条指令的长度了吗?所以指令本身也是有长度的。本质我们只需要知道一个地址,就能不断的往下去运行了?但是CPU如何知道我们第一条运行的指令地址呢?
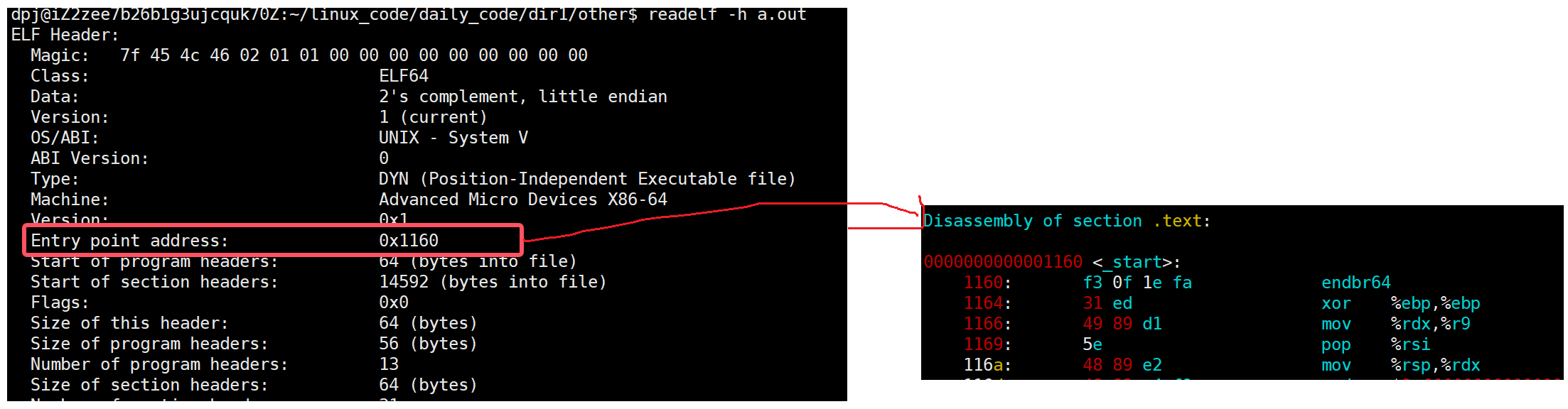
如上图,我们第一条地址在我们的ELF头表当中存储着呢!他就是我们的入口函数的地址,当我们的CPU拿到这个
地址的时候通过PC指针就可以往下运行了。
接下来让我从一张图,来展示CPU是如何读取指令并且能够一直的往下运行:
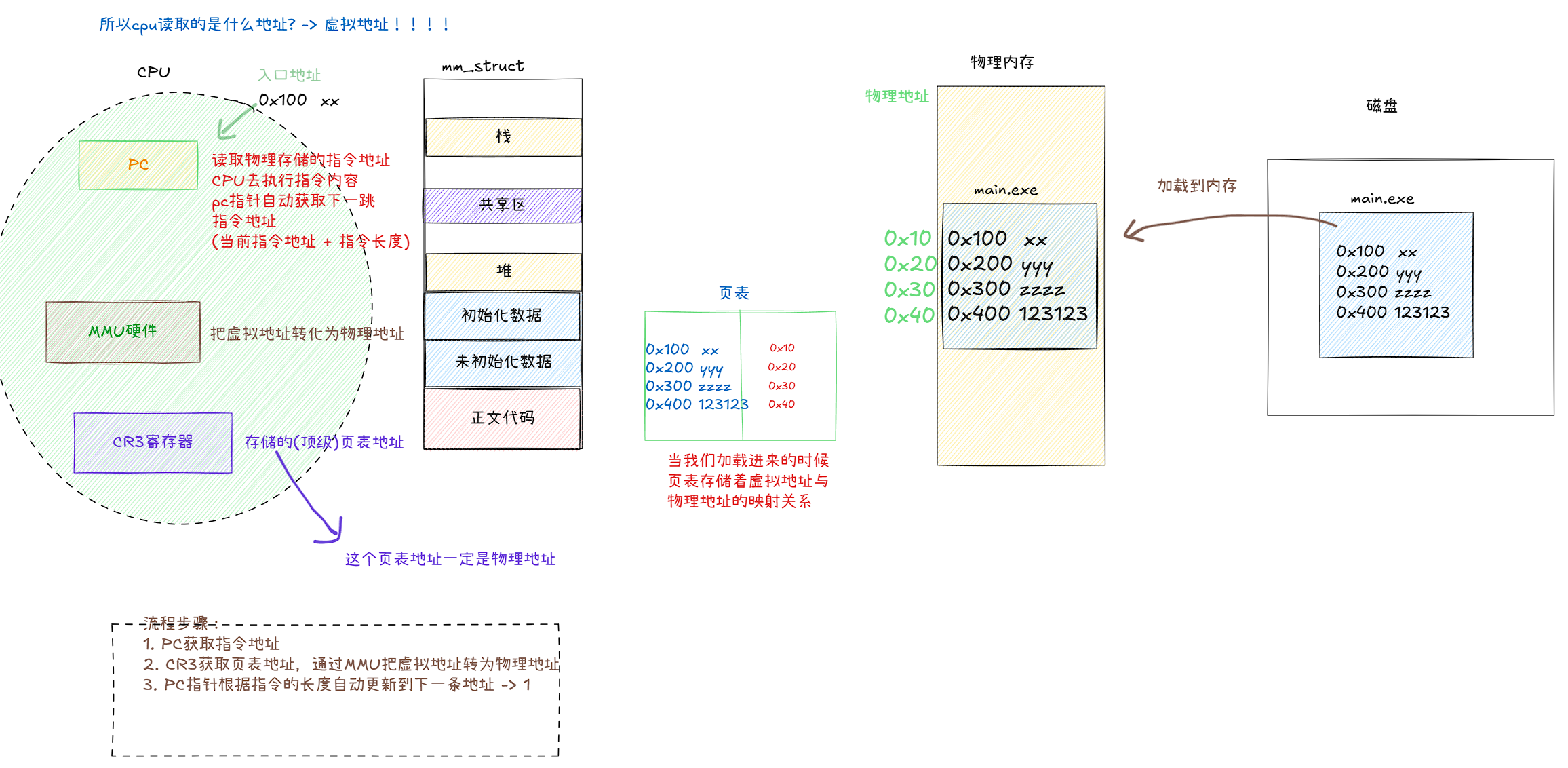
概念梳理(pc寄存器 VS EIP寄存器):
- PC 是通用术语,所有CPU架构都有类似设计(比如ARM的R15寄存器、MIPS的PC寄存器)。
- EIP(32位)/RIP(64位) 是x86架构对PC的具体实现,功能完全一致,只是名称不同
如上图,我们只是简单分析了一下CPU循环读取指令的过程,中途可能还会中断处理等等内容。
对于上面所说的都是对于我们进程地址空间可以通过可执行程序编址来进行划分的区域,但是对于堆栈和共享区,他们动态开辟是如何进行划分的呢?这里我们就需要补充一个数据结构 vm_area_struct 他是在mm_struct中的结构体。
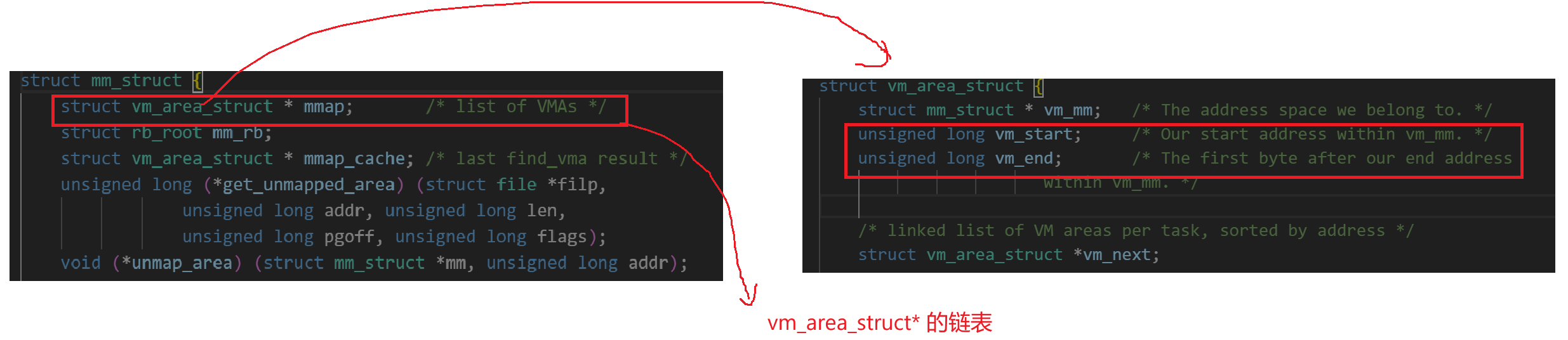
如上图,所以对于进程地址空间每个区域的具体划分其实都是由vm_area_struct中的 [start,end]来进行划分的,而mm_struct只是一个宏观上的划分。当我们加载动态库的时候会创建vm_area_struct节点,把动态库的虚拟起始和结束地址加入 [start,end ]然后在进程地址空间映射一个新的动态库起始和结束地址。当我们来了一个地址时,本质是去vm_area_struct链表中查表,查找在哪一个节点的区间当中。然后根据页表找到对应的物理地址执行指令。
所以其实进程地址空间中的区域划分就是我们的vm_area_struct节点,而我们的代码段等的划分其实在可执行程序文件中就被编址了。这里我们可以看做当我们从可执行程序中加载一个节(Section比如: .text,.data等等),就会创建一vm_area_struct节点来划分进程地址空间。这样可以让我们更加细粒度的对进程地址空间进行划分,但是一般我们加载文件都是按块(4kb)进行加载的。
对于一个大文件来说,有很多的节,我们需要把所有的节都全部加载进来吗?不需要,我们可以进行分批加载**(懒加载**),可能只是把节的入口函数地址加载进来,只有当我们真正要用的时候,再进行加载。对于一个加载过之后长期不用的,OS会标记为可释放,把物理内存释放了,但是elf表头等信息不释放,这样需要再加载的时候直接加载就好了。但是这样还是需要存储elf表头等信息,其实对于文件而言,可执行程序编址无非就是偏移量吗,我们只需要记录文件地址和偏移量即可 需要使用的时候,直接使用地址找到文件,然后根据偏移量加载对应的文件内容。
动态库的加载
这里我们要弱化一下页表的概念,当我们动态库加载进来的时候,虚拟地址默认就编址了,加载进来的时候物理地址也就有了,虚拟地址和物理地址有了那么页表中也就有虚拟地址和物理地址的映射关系了,我们认为动态库一家在页表就映射好了。
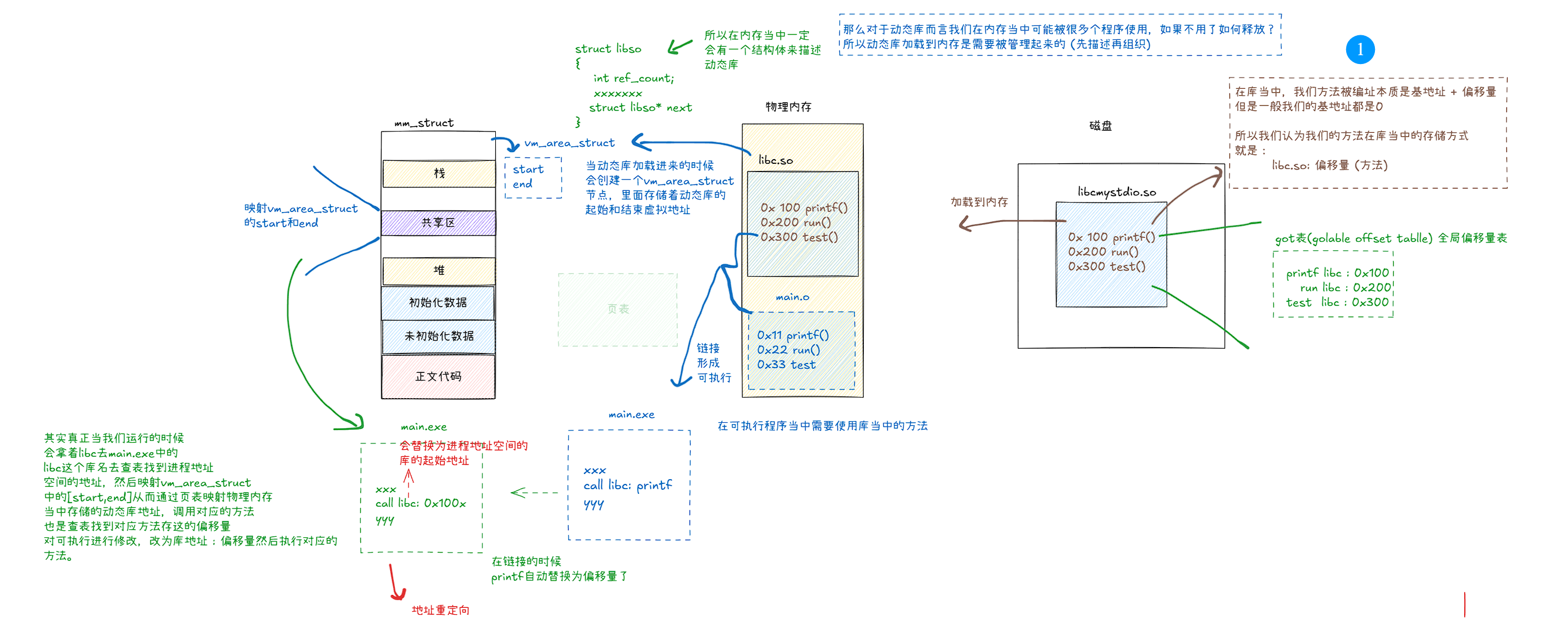
在我们动态库加载到内存的时候进程地址空间创建vm_area_struct节点,[start,end]映射动态库的虚拟地址,同时在进程地址空间当中对 [start,end]映射产生动态库的起始地址,当我们 call libc:printf() 在链接的时候库方法会被替换为库中的偏移量,然后 libc这个库名会被替换为进程地址空间的库起始地址,这样我们就通过库起始地址 + 偏移量,最后经过地址重定向,定位到动态库的真正地址,完成调用(简单理解😂)。所以其实动态库被加载到进程地址空间的什么位置重要吗?不重要,最后会经过地址重定向定位库地址,这就叫做与位置无关 (fPIC)。
可是对于可执行程序而言代码段不是只读的吗?我们如何进行替换操作的呢?
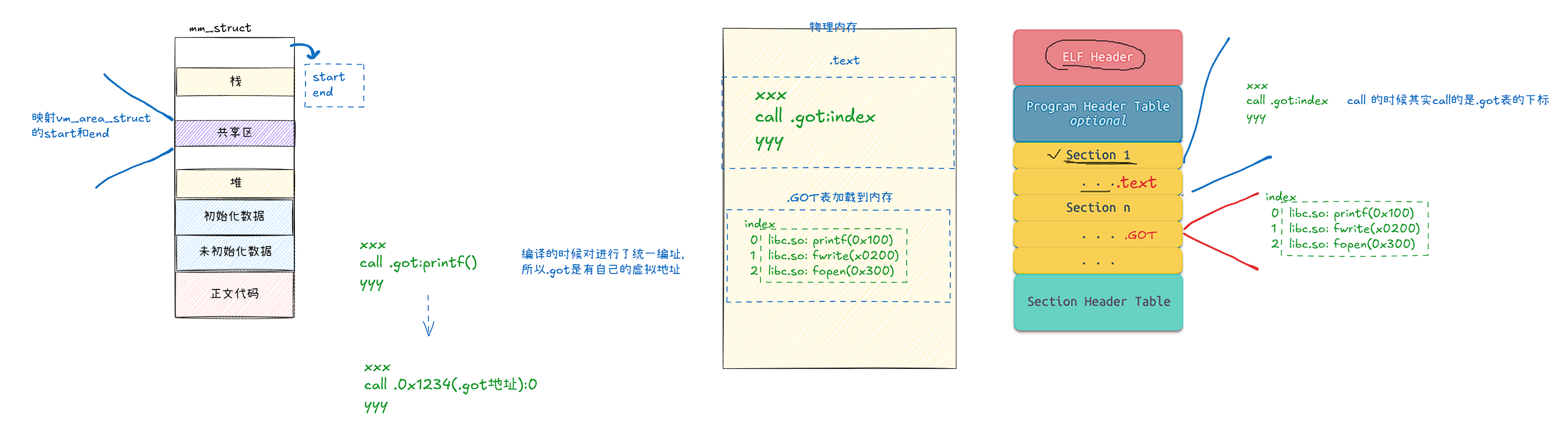
如上图,每一个ELF格式的文件都有一个节, .GOT(golable offset table) 全局偏移量表,里面存储的是库中方法的偏移量(地址),在我们程序运行的时候,当我们想要执行库中的方法时,链接的时候会转换为 .got:index 的形式,而由于编译的时候会对ELF文件进行统一的编址,所以CPU是知道 .got的地址的,所以 .text中的代码最后会转换为 0x1234:0 (假设这里.got虚拟地址为0x1234)。所以我们可执行程序会去查 .got表,而.got表是可读写的。
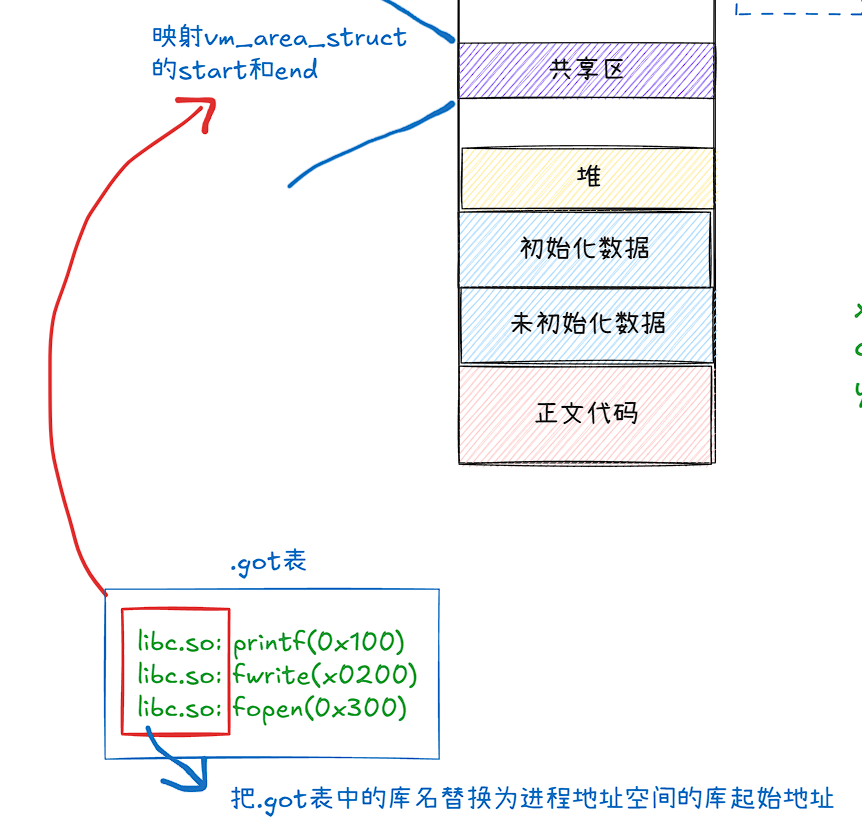
如上图,我们可执行程序运行的时候会把 .got中的表替换为进程地址空间的库起始地址,这样经过地址重定向就可以执行库中的方法了。而每一个可执行程序都是ELF格式都有自己的.got表,所以即使不同进程地址空间中的库起始地址不一样也互不影响。所以动态库映射进程地址空间中的任意位置都可以 ,什么是与地址无关?,本质就是 .got 表 + 方法偏移量。
而对于静态库而言并没有我们上述讲的过程,我们动态库构建完毕,起始都不知道函数应该跳转到哪一个地址,只有当链接形成可执行程序的时候,才会知道跳转到哪里。而对于静态库而言,直接一股脑把每一个section都合并了进来,把函数方法和定义结合到了一起,所以只要静态库一出来,我们就知道函数的跳转位置,动态库还需要动态的重定向,这也是为什么静态库的文件内存消耗大。
dpj@iZ2zee7b26b1g3ujcquk70Z:~/linux_code/daily_code/dir1$ readelf -S libmystdio.aFile: libmystdio.a(my_stdio.o)
There are 14 section headers, starting at offset 0x7a8:Section Headers:[Nr] Name Type Address OffsetSize EntSize Flags Link Info Align[ 0] NULL 0000000000000000 000000000000000000000000 0000000000000000 0 0 0[ 1] .text PROGBITS 0000000000000000 000000400000000000000279 0000000000000000 AX 0 0 1[ 2] .rela.text RELA 0000000000000000 000005680000000000000168 0000000000000018 I 11 1 8[ 3] .data PROGBITS 0000000000000000 000002b90000000000000000 0000000000000000 WA 0 0 1[ 4] .bss NOBITS 0000000000000000 000002b90000000000000000 0000000000000000 WA 0 0 1[ 5] .rodata PROGBITS 0000000000000000 000002bc000000000000000a 0000000000000000 A 0 0 4[ 6] .comment PROGBITS 0000000000000000 000002c6000000000000002c 0000000000000001 MS 0 0 1[ 7] .note.GNU-stack PROGBITS 0000000000000000 000002f20000000000000000 0000000000000000 0 0 1[ 8] .note.gnu.pr[...] NOTE 0000000000000000 000002f80000000000000020 0000000000000000 A 0 0 8[ 9] .eh_frame PROGBITS 0000000000000000 000003180000000000000098 0000000000000000 A 0 0 8[10] .rela.eh_frame RELA 0000000000000000 000006d00000000000000060 0000000000000018 I 11 9 8[11] .symtab SYMTAB 0000000000000000 000003b00000000000000168 0000000000000018 12 4 8[12] .strtab STRTAB 0000000000000000 000005180000000000000049 0000000000000000 0 0 1[13] .shstrtab STRTAB 0000000000000000 000007300000000000000074 0000000000000000 0 0
如上端代码,当我们查静态库中的节细节的时候,都没有我们的 .got表,所以也就不存在我们上述谈的问题了。
总结
通过这篇学习我们需要知道,我们可执行程序的形成之后就已经有了虚拟地址,也就是说在编译期间就已经把地址按照平坦模式编制了。
不过如果是多个.o文件的话,需要跳转函数的地址是在链接的时候统一初始化的。
elf是一种可执行程序文件。
地址空间中堆栈以及共享区域的地址划分是动态创建的,通过vm_area_struct创建节点来维护的。
动态库加载的时候进程地址空间拿到的地址其实是.got表的地址,这样多个进程使用同一个动态库就是与地址无关,因为每一个进程中的地址可能都不一样,但是都可以访问同一个动态库。
同时一般一开始都会使用延迟绑定,就是.got表地址一开始是通过plt获取的,然后第二次访问的时候才是直接访问.got表中的函数地址。(了解)