【C++指南】告别C字符串陷阱:如何实现封装string?
🌟 各位看官好,我是egoist2023!
🌍 种一棵树最好是十年前,其次是现在!
💬 注意:本章节只详讲string中常用接口及实现,有其他需求查阅文档介绍。
🚀 今天通过了解string接口,从而实现封装自己的string类达到类似功能。
👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更多人哦!

引入
string类的文档介绍 --> 如有需要自行查阅文档中接口实现。
auto和范围for
auto关键字(自动推导类型):
- 在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,后来这个不重要了。C++11中,标准委员会变废为宝赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
- 用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&。
- 当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
- auto不能作为函数的参数,可以做返回值,但谨慎使用。
- auto不能直接用来声明数组。
范围for(底层就是迭代器):
- 对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围,自动迭代,自动取数据,自动判断结束。
- 范围for可以作用到数组和容器对象上进行遍历
- 范围for的底层很简单,容器遍历实际就是替换为迭代器,这个从汇编层也可以看到。
了解string常用接口
1.常见构造
| (constructor) 函数名称 | 功能说明 |
| string() (重点) | 构造空的 string 类对象,即空字符串 |
| string(const char* s) (重点) | 用 C-string 来构造 string 类对象 |
| string(size_t n, char c) | string 类对象中包含 n 个字符c |
| string(const string&s) (重点) | 拷贝构造函数 |
2.容量操作
| 函数名称 | 功能说明 |
| size(重点) | 返回字符串有效字符长度 |
| length | 返回字符串有效字符长度 |
| capacity | 返回空间总大小 |
| empty | 检测字符串释放为空串,是返回 true ,否则返回 false |
| clear | 清空有效字符(不改变底层空间大小) |
| reserve | 为字符串预留空间 |
| resize | 将有效字符的个数该成 n 个,多出的空间用字符 c 填充 |
注意:1. size() 与 length() 方法底层实现原理完全相同,引入 size() 的原因是保持与其他接口容器一致,而length函数是由于历史原因遗留的。2. resize(size_t n) 与 resize(size_t n, char c) 都是将字符串中有效字符个数改变到 n 个,不同的是当字符个数增多时: resize(n) 用 0 来填充多出的元素空间, resize(size_t n, charc) 用字符 c 来填充多出的元素空间。注意: resize 在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。3. reserve(size_t res_arg=0) :为 string 预留空间,不改变有效元素个数,当 reserve 的参数小于 string 的底层空间总大小时, reserver 不会改变容量大小。
3.迭代器访问
| 函数名称 | 功能说明 |
| operator[] (重点) | 返回 pos 位置的字符, const string 类对象调用 |
| begin + end | begin 获取一个字符的迭代器 + end 获取最后一个字符下一个位 置的迭代器 |
| rbegin + rend | begin 获取一个字符的迭代器 + end 获取最后一个字符下一个位 置的迭代器 |
| 范围 for | \ |
4.修改操作
| 函数名称 | 功能说明 |
| push_back | 在字符串后尾插字符 c |
| append | 在字符串后追加一个字符串 |
| operator+= ( 重点 ) | 在字符串后追加字符串 str |
| c_str ( 重点 ) | 返回 C 格式字符串 |
| find + npos ( 重 点 ) | 从字符串 pos 位置开始往后找字符 c ,返回该字符在字符串中的 位置 |
| rfind | 从字符串 pos 位置开始往后找字符c,返回该字符在字符串中的位置 |
| substr | 在 str 中从 pos 位置开始,截取 n 个字符,然后将其返回 |
5.非成员函数
| 函数 | 功能说明 |
| operator+ | 尽量少用,因为传值返回,导致深拷贝效率低 |
| operator>> (重点) | 输入运算符重载 |
| operator<< (重点) | 输出运算符重载 |
| getline (重点) | 获取一行字符串 |
| relational operators (重点) | 大小比较 |
string类模拟实现
底层结构
class string
{
public://...private:char* _str = nullptr;int _size = 0;int _capacity = 0;const static size_t npos;
};在上面定义的结构当中,其常量npos表示字符串末尾之前的所有字符,在substr接口中有使用。
const size_t string::npos = -1; //-1的无符号整数即表示最大值

1.常见构造
我们知道无论如何字符串当中末尾总会存' \0 ' ,作为标记。因此在构造字符串string时,一定要多开一个空间存 ' \0 ' 。那如果new空间失败呢?采用抛异常的方式,在外进行捕获异常(之后会讲)。
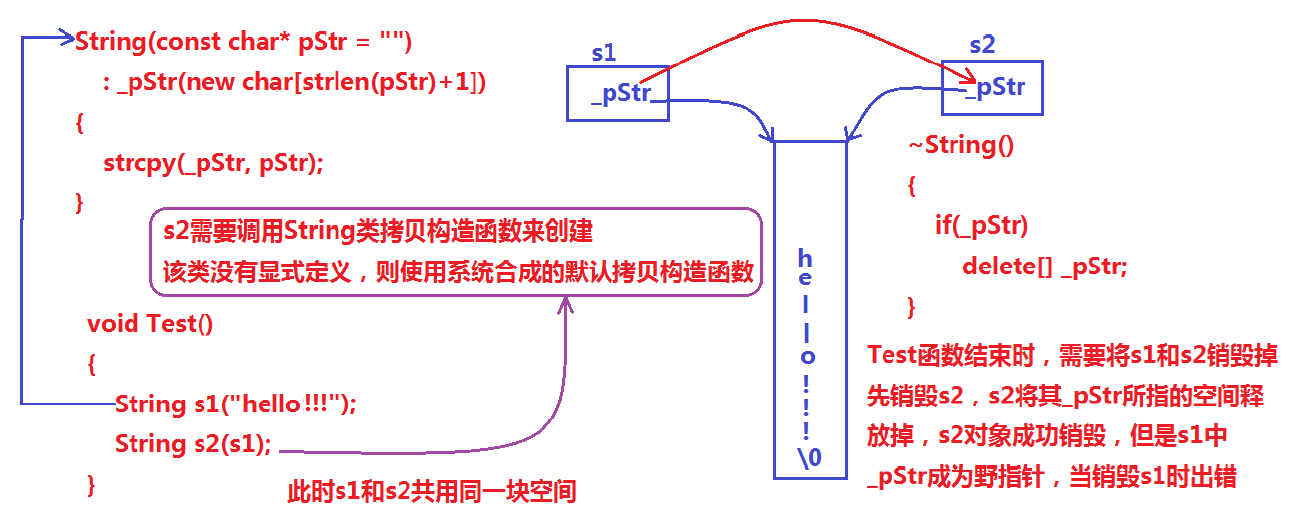
在如下一段程序中,将字符串str拷贝到string当中,但是这样会导致多次析构一块空间导致程序崩溃的问题。
string::string(const char* str):_str(new char[strlen(str)+1]){strcpy(_str, str);}浅/深拷贝
浅拷贝:也称位拷贝,编译器只是将对象中的值拷贝过来 。如果 对象中管理资源 ,最后就会 导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该资源已经被释放,以为还有效,所以当继续对资源进项操作时,就会发生发生了访问违规 。如下图当中, s1 、 s2 共用同一块内 存空间,在释放时同一块空间被释放多次而引起程序崩溃 ,这种拷贝方式,称为浅拷贝。
深拷贝:不单单是把数据拷贝过去,还需要开一块内存空间,防止指向同一块空间。

string::string(const char* str):_size(strlen(str)){_str = new char[_size + 1];//如果失败需要捕获异常_capacity = _size;strcpy(_str, str);}string::string(size_t n, char ch):_str(new char[n + 1]), _size(n), _capacity(n){for (size_t i = 0;i < n;i++){_str[i] = ch;}_str[_size] = '\0';}//析构string::~string(){delete[] _str;_str = nullptr;_size = _capacity = 0;}拷贝构造、赋值运算法重载(重点)
拷贝构造:
目标是将s中的数据拷贝到_str中,那我们直接调用strcpy函数将s数据拷过来即可?
string::string(const string& s){strcpy(_str, s._str);}但是这样会导致析构时多次析构一块空间,从而报错(依然是浅拷贝的问题)。
string::string(const string& s){_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}赋值运算符重载:
特殊情况下可能自己给自己赋值,为了不再拷贝一次做判断。
string& string::operator=(const string& s){if (this != &s){delete _str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}return *this;}现代写法
实际上,上面的两段代码显得过于笨拙且冗杂,都是老老实实自己手写申请空间。而在如下一段程序当中,借用构造函数来完成拷贝及其赋值。而这种方法,也是实践当中最常用到的现代写法。
void string::swap(string& s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}//拷贝构造简洁化 --> 现代写法string::string(const string& s){string tmp(s._str);swap(tmp);}在如上一段程序当中,通过构造函数构造tmp。s这里是引用传参,即出了作用域不会销毁 ;而tmp是属于这个栈内的空间,出了作用域就会销毁。此时我们借助swap的特性,将_str指向的指针进行交换,此时就是*this指向了新申请的空间,再将个数和空间交换即可。
这样看,和平日写的拷贝构造是差不多的。别着急,我们再来看看赋值运算符重载的简化实现。
- 方法一:仍然采用上面思想写赋值重载;
- 方法二:实际上,当我们写完了拷贝构造后,我们甚至还能再借助拷贝构造的特性来完成赋值重载。此时,我们不再使用引用传参,而是借助拷贝构造出s,而s出了作用域就会销毁,此时我们再借助swap来进行交换。这样来看,这种现代写法是不是既简洁又充满着妙处。
string& string::operator=(string s){//s即是拷贝构造过来的swap(s); //出了作用域就会析构return *this;}2.容量操作
//增容
void string::reserve(size_t n)
{char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;
}3. 迭代器访问
什么是迭代器?
迭代器的作用是用来访问容器(用来保存元素的数据结构)中的元素,所以使用迭代器,我们就可以访问容器中里面的元素。那迭代器不就相当于指针一个一个访问容器中的元素吗?并不是,迭代器是像指针一样的行为,但是并不等同于指针,且功能更加丰富,这点需在之后慢慢体会。(本章节体现并不是很明显)
typedef char* iterator;
typedef const char* const_iterator;iterator begin()
{return _str;
}iterator end()
{return _str + _size;
}const_iterator begin() const
{return _str;
}const_iterator end() const
{return _str + _size;
}4. 修改操作
push_back插入逻辑:
- 当插入元素大于容器容量时,需进行扩容操作;
- _size的位置是' \0 ',但直接将插入元素覆盖即可,_size++,重新加上' \0 ' 。
void string::push_back(char x)
{if (_size + 1 > _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}_str[_size++] = x;_str[_size] = '\0';
}
append插入逻辑:
- 计算需要插入字符串的长度len,若string的个数+len大于容量则需扩容;
- 若个数+len长度大于2倍扩容时,则应扩容到个数+len容量;
- 往string末尾插入字符串。
void string::append(const char* str)
{size_t len = strlen(str);if (len + _size > _capacity){int NewCapacity = 2 * _capacity;if (len + _size > 2 * _capacity){NewCapacity = len + _size;}reserve(NewCapacity);}strcpy(_str + _size, str);_size += len;
}+=运算符重载逻辑:
- 如果插入的是字符串,则采用append函数的逻辑;
- 如果插入的是字符,则采用push_back函数的逻辑;
- 无论哪种情况,实现方式都和以上两种代码实现方式是相同的,因此我们可以以复用的方式,更容易维护我们的代码。
string& string::operator+=(const char* str)
{append(str);return *this;
}
string& string::operator+=(char x)
{push_back(x);return *this;
}insert函数实现逻辑:
- 扩容逻辑与其上是类似的,区别在于插入元素后的数据是从后往前还是从前往后挪动;
- 如果是从前往后挪动,那么会发生覆盖数据的现象,而从后往前就不会,这点在之前也有强调过;
void string::insert(size_t pos, size_t n, char ch){assert(pos <= _size);//扩容if (_size + n > _capacity){// size_t newCapacity = 2 * _capacity;if (_size + n > 2 * _capacity){newCapacity = _size + n;}reserve(newCapacity);}//int end = _size;//while (end >= (int)pos)//这里不强转会有err//{// _str[end + n] = _str[end];// --end;//}size_t end = _size + n;while (end > pos + n - 1){_str[end] = _str[end - n];--end;}for (size_t i = 0;i < n;i++){_str[pos + i] = ch;}_size += n;}
- 扩容逻辑与其上对应重载函数是一样的;
- 一样是需要将pos后的位置进行挪动后,思路是类似的,那能否复用上面的实现函数呢?
如果复用上面的函数,那么该往这位置插入的字符串都是相同的一个字符,这样想似乎不能复用。
但是没关系,这些位置刚好是为要插入字符串预留的,那么我们只要将这些位置覆盖一遍即可。

void string::insert(size_t pos, const char* str){size_t n = strlen(str);insert(pos, n, 'x');for (size_t i = 0;i < n;i++){_str[i + pos] = str[i];}}复用 :通过牺牲空间方法。
string tmp(n, ch);insert(pos, tmp.c_str());5. 非成员函数
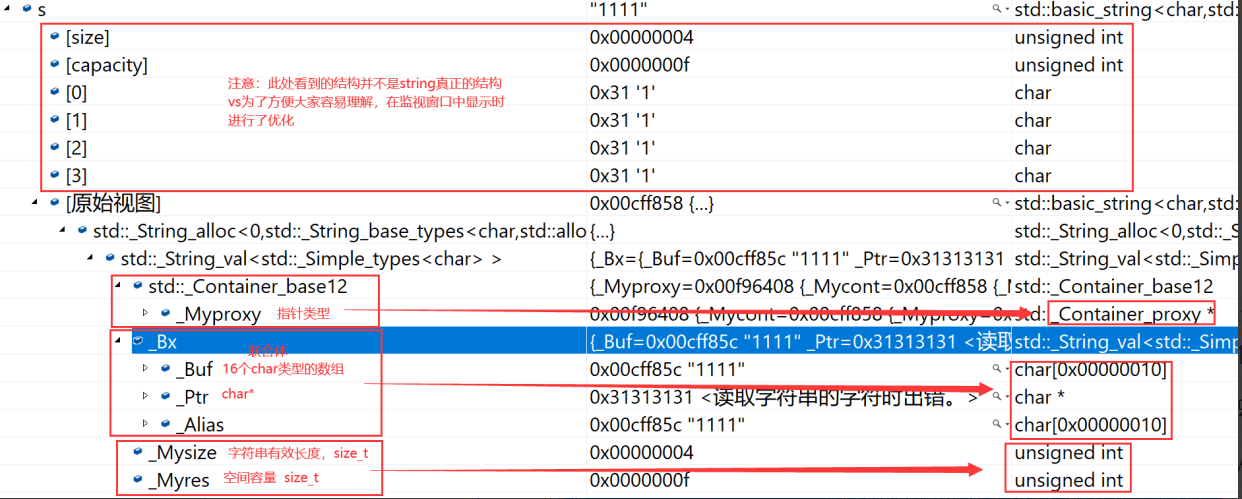
- 当字符串长度小于16时,使用内部固定的字符数组来存放
- 当字符串长度大于等于16时,从堆上开辟空间
union _Bxty{ // storage for small buffer or pointer to larger onevalue_type _Buf [ _BUF_SIZE ];pointer _Ptr ;char _Alias [ _BUF_SIZE ]; // to permit aliasing} _Bx ;
流提取
vs下额外定义了个buff数组以减少扩容,提高效率。我们同样采用这种思想造类似的轮子。
//cin>>s
istream& operator>>(istream& in, string& s)
{s.clear();//char ch = in.get();//while (ch != ' ' && ch != '\n')//{// s += ch;// ch = in.get();//}//为了减少频繁的扩容,定义一个数组char buff[1024];char ch = in.get();size_t i = 0;while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == 1023){buff[i] = '\0';s += buff;i = 0;}ch = in.get();}if (i > 0){buff[i] = '\0';s += buff;}return in;
}流插入
//cout<<s
ostream& operator<<(ostream& out, const string& s)
{for (auto ch : s){out << ch;}return out;
}getline函数(难点)
实现逻辑:
- 每次输入都往buff数组中填入数据;
- 当数据超过buff数组容量时,将数组里的数据加到string当中,buff数组从0开始继续填入数据;
- 如果ch==delim时,不再填入数据,将buff数组里剩下的数据加到string当中。
istream& getline(istream& is, string& s, char delim)
{char buff[1024];char ch = is.get();size_t i = 0;while (ch != delim){buff[i++] = ch;if (i == 1023){buff[i] = '\0';s += buff;i = 0;}ch = is.get();}if (i > 0){buff[i] = '\0';s += buff;}return is;
}代码实现
string.h
#pragma once
#include<iostream>
#include<string.h>
#include<assert.h>
using namespace std;namespace egoist
{class string{public://迭代器typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}//计算串的size和capacitysize_t size() const{return _size;}size_t capacity() const{return _capacity;}//构造函数string(const char* str = "");string(size_t n, char ch);//交换void swap(string& s);//拷贝构造string(const string& s);const char* c_str() const{return _str;}void reserve(size_t n);void push_back(char x);void append(const char* str);=重载运算符//string& operator=(const string& s);//现代简洁化string& operator=(string s);string& operator+=(const char* str);string& operator+=(char x);//比较大小bool operator==(const string& s) const;bool operator!=(const string& s) const;bool operator<(const string& s) const;bool operator<=(const string& s) const;bool operator>(const string& s) const;bool operator>=(const string& s) const;//[]运算符重载char& operator[](size_t pos){assert(pos < _size);assert(pos >= 0);return _str[pos];}const char& operator[](size_t pos) const{assert(pos < _size);assert(pos >= 0);return _str[pos];}void insert(size_t pos, size_t n, char ch);void insert(size_t pos, const char* str);void erase(size_t pos = 0, size_t len = npos);size_t find(char ch, size_t pos = 0);size_t find(const char* str, size_t pos = 0);void clear(){_str[0] = '\0';_size = 0;}string substr(size_t pos, size_t len = npos);//析构~string();private:char* _str = nullptr;int _size = 0;int _capacity = 0;const static size_t npos;};//cout<<sostream& operator<<(ostream& out, const string& s);//cin>>sistream& operator>>(istream& in, string& s);istream& getline(istream& is, string& s, char delim = '\n');}string.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"string.h"namespace egoist
{const size_t string::npos = -1;string::string(const char* str):_size(strlen(str)){_str = new char[_size + 1];//如果失败需要捕获异常_capacity = _size;strcpy(_str, str);}string::string(size_t n, char ch):_str(new char[n + 1]), _size(n), _capacity(n){for (size_t i = 0;i < n;i++){_str[i] = ch;}_str[_size] = '\0';}拷贝构造//string::string(const string& s)//{// _str = new char[s._capacity + 1];// strcpy(_str, s._str);// _size = s._size;// _capacity = s._capacity;//}void string::swap(string& s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}//拷贝构造简洁化 --> 现代写法string::string(const string& s){string tmp(s._str);swap(tmp);}void string::reserve(size_t n){//需要增容 --> 为了和new配套使用,不用reallocchar* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}void string::push_back(char x){if (_size + 1 > _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}_str[_size++] = x;_str[_size] = '\0';}void string::append(const char* str){size_t len = strlen(str);if (len + _size > _capacity){int NewCapacity = 2 * _capacity;if (len + _size > 2 * _capacity){NewCapacity = len + _size;}reserve(NewCapacity);}strcpy(_str + _size, str);_size += len;}//=运算符重载//string& string::operator=(const string& s)//{// if (this != &s)// {// delete _str;// _str = new char[s._capacity + 1];// strcpy(_str, s._str);// _size = s._size;// _capacity = s._capacity;// }// return *this;//}//现代简洁化 --> 通过调用拷贝构造string& string::operator=(string s){//s即是拷贝构造过来的swap(s); //出了作用域就会析构return *this;}string& string::operator+=(const char* str){append(str);return *this;}string& string::operator+=(char x){push_back(x);return *this;}//比较大小bool string::operator==(const string& s) const{return strcmp(_str, s._str) == 0;}bool string::operator!=(const string& s) const{return !(*this == s);}bool string::operator<(const string& s) const{return strcmp(_str, s._str) < 0;}bool string::operator<=(const string& s) const{return (*this < s) || (*this == s);}bool string::operator>(const string& s) const{return !(*this <= s);}bool string::operator>=(const string& s) const{return !(*this < s);}void string::insert(size_t pos, size_t n, char ch){assert(pos <= _size);//扩容if (_size + n > _capacity){// size_t newCapacity = 2 * _capacity;if (_size + n > 2 * _capacity){newCapacity = _size + n;}reserve(newCapacity);}//int end = _size;//while (end >= (int)pos)//这里不强转会有err//{// _str[end + n] = _str[end];// --end;//}size_t end = _size + n;while (end > pos + n - 1){_str[end] = _str[end - n];--end;}for (size_t i = 0;i < n;i++){_str[pos + i] = ch;}_size += n;}void string::insert(size_t pos, const char* str){由于高度相似,可采用复用//assert(pos <= _size);//size_t n = strlen(str);扩容//if (_size + n > _capacity)//{// // // size_t newCapacity = 2 * _capacity;// if (_size + n > 2 * _capacity)// {// newCapacity = _size + n;// }// reserve(newCapacity);//}//size_t end = _size + n;//while (end > pos + n - 1)//{// _str[end] = _str[end - n];// --end;//}size_t n = strlen(str);insert(pos, n, 'x');for (size_t i = 0;i < n;i++){_str[i + pos] = str[i];}//通过牺牲空间方法复用/*string tmp(n, ch);insert(pos, tmp.c_str());*/}void string::erase(size_t pos, size_t len){assert(pos >= 0);if (len > _size - pos){_str[pos] = '\0';_size = pos;}else {for (size_t i = pos;i <= _size;i++){_str[i] = _str[i + len];}_size -= len;}}size_t string::find(char ch, size_t pos){for (size_t i = pos;i < _size;i++){if (_str[i] == ch)return i;}return npos;}size_t string::find(const char* str, size_t pos){const char* p = strstr(_str + pos, str);if (p == nullptr){return npos;}else{return p - _str;}}string string::substr(size_t pos, size_t len){size_t leftlen = _size - pos;if (len > leftlen)len = leftlen;string tmp;tmp.reserve(len);for (size_t i = 0; i < len; i++){tmp += _str[pos + i];}return tmp;}string::~string(){delete[] _str;_str = nullptr;_size = _capacity = 0;}//cout<<sostream& operator<<(ostream& out, const string& s){for (auto ch : s){out << ch;}return out;}//cin>>sistream& operator>>(istream& in, string& s){s.clear();//char ch = in.get();//while (ch != ' ' && ch != '\n')//{// s += ch;// ch = in.get();//}//为了减少频繁的扩容,定义一个数组char buff[1024];char ch = in.get();size_t i = 0;while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == 1023){buff[i] = '\0';s += buff;i = 0;}ch = in.get();}if (i > 0){buff[i] = '\0';s += buff;}return in;}istream& getline(istream& is, string& s, char delim){char buff[1024];char ch = is.get();size_t i = 0;while (ch != delim){buff[i++] = ch;if (i == 1023){buff[i] = '\0';s += buff;i = 0;}ch = is.get();}if (i > 0){buff[i] = '\0';s += buff;}return is;}
}
扩展 --> 引用计数的写时拷贝

