IPv6 技术细节 | 源 IP 地址选择 / Anycast / 地址自动配置 / 地址聚类分配
注:本文为 “IPv6 技术细节” 相关文章合集。
部分文章中提到的其他文章,一并引入。
略作重排,未整理去重。
如有内容异常,请看原文。
闲谈 IPv6 - 典型特征的一些技术细节
iteye_21199 于 2012-11-10 20:54:00 发布
0. 巨大的地址空间
这个已经不用再说了。除了空间巨大,固定长度的前缀分配也使得地址分配更加均衡。
1. ICMPv6 真正的有了用武之地:地址 / 路由配置的自动化
IPv6 使得联网设备真的成了即插即用,一切都是通过自动生成的链路本地地址开始的,如果没有这个开始,将不会存在后续的自动化。任何支持 IPv6 的设备都会为接口生成一个链路本地地址,所有的链路本地地址都是 FE80 开头的,巧妙的是最后的 64 位,是通过链路层地址生成的,典型的是 EUI-64 映射,将 48 位的以太网 MAC 地址映射成 64 位的链路本地地址的接口标识,生成这个链路本地地址后,即使没有路由器,同一链路的设备也能通过这个地址进行 IP 层的通信。IPv6 中,链路层和 IP 层就这样巧妙的结合在一起,链路层提供信息,IP 层使用之,使通信成为可能。
但是 IPv6 协议规定,使用这个自动生成的链路本地地址不能跨越路由器,我们知道,所谓的互联网就是由路由器连接而成的,互联网数据通信必须跨越路由器,也就是说必须有一个非链路本地地址的 IPv6 地址。既然有了同一链路可用的链路本地地址,那就意味着使用链路本地地址可以和同一链路的路由器通信了 (一个路由器的每一个接口表示一个链路),IPv6 定义了很多的邻居发现报文,可以让路由器告诉终端设备接口信息应该配置成什么,这就是所谓的自动配置,从开始到最后,不需要人工干预,普通用户再也不需要为配置地址这种技术型的工作犯愁了。下面就是自动配置的流程图:
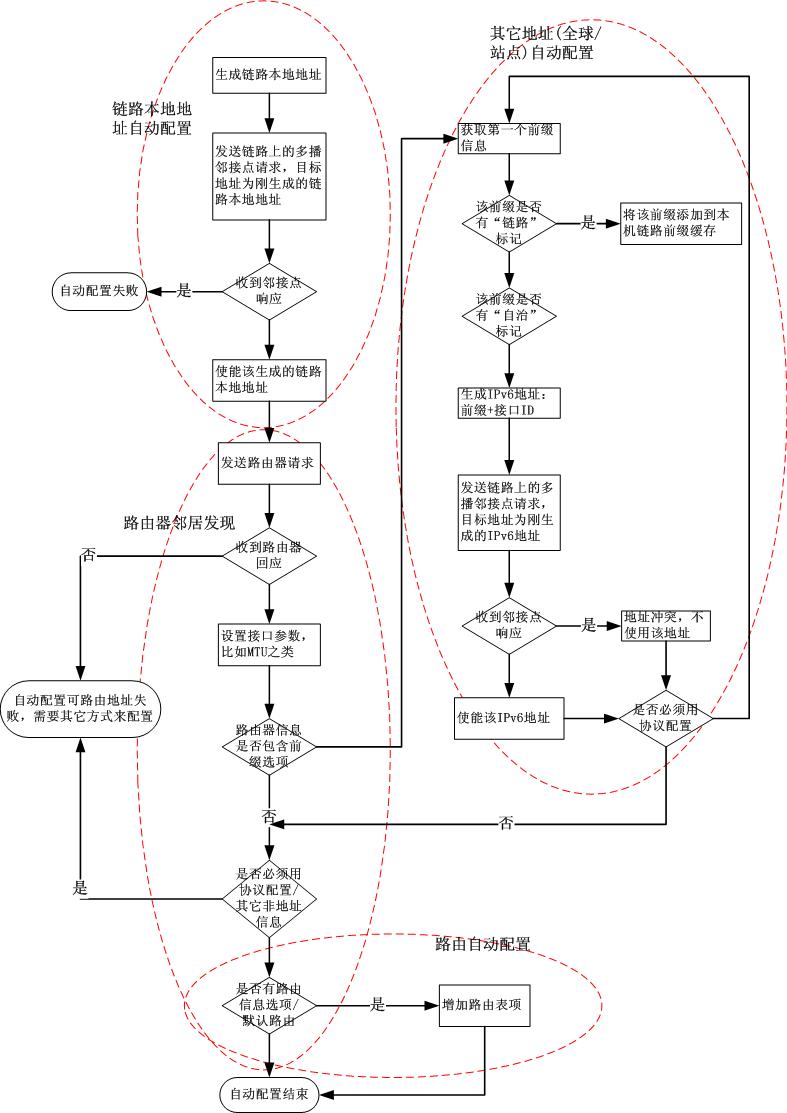
OpenVPN 的路由自动推送和自动地址配置和 IPv6 及其相似。
2. Linux 的 ARP 与 IPv6 的地址解析:状态图竟然如此类似
IPv6 以太网的地址解析使用组播进行,不再使用广播。这个过程十分简单,如果知道节点的 IPv6 地址,其组播地址可以自动算出来,然后就往这个组播地址发送解析报文请求即可,其实就是个邻居发现,得到回应后将 MAC-IP 对缓存起来,这个 MAC-IP 对的缓存有一个状态图,这个状态图猛一看好像是 Linux 的 ARP 缓存状态图,它们太像了,简直就是一个:
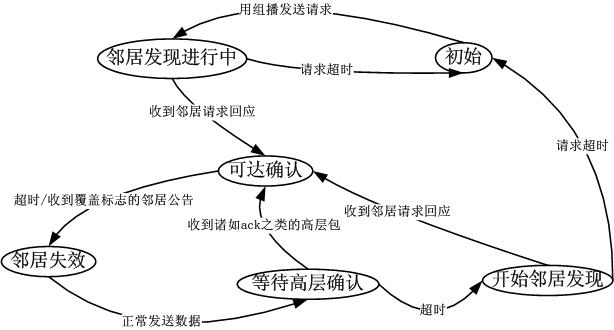
对比《Linux 实现的 ARP 缓存老化时间原理解析》里面的那幅图。(见后文)
然而和 Liunx 维护的 ARP 状态图不同的是,IPv6 的邻接点缓存不再通过复杂的计算以及协议外的原则来维护,而是通过报文本身来维护,比如 ARP 缓存的更新机制是 “收到来自同一 IP 的设备的 arp 包” 即覆盖,IPv6 则是使用邻接点公告报文中的 “覆盖标志” 来决定是否更新的。二者的差别仅仅是一个是实现,一个是协议标准自带的。
3. IPv6 的各种发现机制:自动化配置的根基
IPv6 之所以可以自动配置,正是由于存在诸多的发现报文,典型的就是:
a. 邻接点请求 / 公告
b. 路由器请求 / 公告
这些发现报文全部由 ICMPv6 来承载,路由器发现机制在 IPv4 实现中是可选的,然而 IPv6 实现中却是必须的。地址和路由的自动配置信息正是从这些发现报文中得到的。
诸多的自动化配置也需要对应的自动化失效机制,这就是引入了 IPv6 的一个针对地址的概念,也算是一个地址的属性,那就是地址的状态,一个地址使用下面的状态中的一种:试探,有效 (选用 / 丢弃),无效,无疑,具体属于哪个状态和超时时间以及接收到的消息有关。
路由器配置非自动化,因为它需要表示人的策略,主机配置自动化,因为它仅仅被使用。IPv6 路由器是不能使用自动配置机制的,配置路由器的人基本都是专业人士,IPv4 的配置困难恰恰在于把路由配置,IP 地址配置这种技术性的工作交给了使用者而不是管理员,要知道管理员不能去配置每一个终端,DHCP 虽然可以,但它毕竟是一个外围的协议,并非 IPv4 本身的性质。IPv6 彻底解放了广大用户,使用 IPv6,所有人的终端就成了即插即用的了,类似传统家用电器那样子。
因此,IPv6 的主干是配置而成,而叶子则是自己长出来的。主干嫁接容易,叶子却只能长出来,IPv4 的叶子就是嫁接的,很不成功。这也符合我们的常识,一般都是在既有的树木上嫁接一系列光秃秃的枝干,然后等待叶子自己长出来…
4. IPv4 中的几个跃跃欲试的思想
在配置 Linux 地址或者路由时,你可能会注意到一个 scope 参数,虽然你几乎不会用到它,然而到了 IPv6,这个 scope 竟然集成进了 IPv6 地址本身,不同的前缀代表不同的 scope。
在使用 Windows 的时候,当你使用多块网卡配置了多个默认网关或者 DHCP 得到了多个默认网关的时候,你可能会注意到注册表中有一个 DeadGWDetectDefault,它根据 TCP 连接的有效率来判断使用哪个默认网关,然而到了 IPv6,周期性的路由器通告竟然成了标准,协议本身就做好了 DeadGWDetect 的工作,并且减少了误判,做的更好。
在第 2 节,我解释了 Linux 的 arp 实现与 IPv6 的地址解析,同样的,这也是一个最终成为标准的跃跃欲试的想法。也许,很多不开源的协议栈也是这么实现的。因此 IPv6 可以说是集个大家协议栈于大成,解决了很多问题。
5. 强弱主机支持的遗憾
6. IPv6 将带来应用模式的根本转变
目前大量的应用都是 C/S 模式 (B/S 也是 CS 的一种) 的,数据流特征基本是单向的,并且广域网的接入层也迎合了这种态势,ADSL 正是其体现,不对称性正是 IPv4 的缺陷以及 NAT 修补造成的。
IPv6 风靡之后,全球所有的节点在理论上将互联互通,CS 模式的应用保持现状,大量的 P2P 应用将会涌现,整个互联网的交互性将大大增强。并且 IPv6 会影响到广域网接入技术,ADSL 这种技术将不再流行,宁可对开也不要三七分。
除了应用,路由器等硬件设备也会发生大的转变,NAT 不再是必须的功能,路由器真的就成了路由器。我们现在使用的家用路由器比如 TP-LINK,D-LINK,甚至 syslink 等其实不是什么路由器,而只是一个互联网接入设备,也不知道当初为何为这种东西取名子为路由器。路由器的一对端口应该是双向互通的。IPv6 使得 NAT 不再流行,诸多家用路由器厂商估计也要对自己的软件进行大的升级改造了。
闲谈 IPv6 - 源 IP 地址的选择(RFC3484 读后感)
dog250 于 2019-02-21 21:33:56 发布
杭州数月的连续淅淅沥沥的雨,让我感到舒适,…
回想起 2014 年的一个周末从上海来杭州,我在思考一个关于 IPv6 的问题,但一切却不是因为 IPv6 而起。
缘起
在多年以前,我被一个看似很简单的问题困扰了很久很久。问题是这样的。
在 Windows 机器上,创建一条基于 Tap 虚拟网卡的隧道,并且为该虚拟网卡配置一个 IP 地址,比方说是 10.0.1.20/24,同时将感兴趣的流量全部通过路由的方式导入到该 Tap 虚拟网卡,此外该 Windows 机器上安装的物理网卡的 IP 地址为 192.168.1.20/24。
现在有一个 App 发起一条感兴趣连接,所谓感兴趣连接就是走隧道的连接。那么请问该连接上的数据包的源 IP 地址是什么?是虚拟网卡上的 10.0.1.20 还是物理网卡上的 192.168.1.20?
答案是简单且明确的,是虚拟网卡上的 10.0.1.20!
为什么?因为数据包的源 IP 地址是基于路由来选择的,除非你显式 bind 一个特定的 IP 地址,否则 Windows 内置的 TCP/IP 协议栈将会基于最长前缀匹配算法为你选择一个路由结果指示的出口网卡上配置的 IP 地址!
在大多数情况下,选择虚拟网卡上的 IP 作为数据包的源 IP 地址并不影响正常的通信,只要各个路径的路由是连通可达的,但是…
但是,我们知道,虚拟网卡上的 IP 地址 10.0.1.20 可能就是为了建立隧道而被配置的,它并不是专门用于通信的,10.0.1.X/24(或者更加普遍的用法,用 / 30 前缀)的地址仅仅在隧道的两个端点可见。这意味着,如果目标地址不是隧道的另一端,那么便需要在数据包走出另一端隧道的时候,做源地址转换,将其转换成专门的通信地址。
而 NAT 是会带来很多问题的,为了解决这些问题,我不得不在炎热的夏日夜晚或者寒冷的冬夜写一个无状态的 NAT 转换器,解决了一个又一个关于 NAT,nf_conntrack 的问题… 幸好隧道的另一端是 Linux 系统,能让我尽情折腾…
那是 2012 年到 2014 年的那段时间,简直是受够了!!
------
IPv6 带来了福音!
RFC3484 简介
IPv6 制定了非常严格的 源地址 / 目标地址选择的机制和策略,并且这个过程还是可以从外部控制的!这简直太棒了!
参见 RFC3484:https://www.ietf.org/rfc/rfc3484.txt
------
具体来讲,在尚未确定源 IPv6 地址的时候,给出一台机器上不同网卡上配置的所有 IPv6 地址,作为一个集合,遵循 RFC3484 给出的 8 条 Rule 最终将会确定一个唯一的一个最优 IP 地址作为通信的源 IP 地址。
这 8 条 Rule 依次顺序匹配, 每一条 Rule 简单来讲都是一个比较排序规则,它将一些候选的 IPv6 地址排在另一些候选 IPv6 地址之前或者之后,排在后面的地址将再没有机会被选中而被淘汰。
换句话说,只有在一条 Rule 没有确定唯一的优胜者时,后面的 Rule 才会起作用。很显然,这是一个逐步细化的不同维度的排序过程,如果前一条 Rule 选择了多个优胜者,将会进行下一条 Rule 规定的竞选。
这 8 条 Rule 分别是:
-
Rule 1: 优选与目标地址相同的地址
-
Rule 2: 优选其 scope 与目标地址 scope 相比更接近且 scope 更大的地址
-
Rule 3: 优选 “preferred” 地址
-
Rule 4: 优选 home 地址
-
Rule 5: 优选和路由出口在同一块网卡上配置的地址
-
Rule 6: 优选 Label 匹配的地址
-
Rule 7: 优选非临时 / 临时地址(可配置)
-
Rule 8: 优选和目标地址最长前缀匹配的地址
这里主要说说 Rule 2,Rule 6 以及 Rule7。
我们先看什么是 scope。
感谢 IPv6 在设计时就对地址按照其作用域范围 (scope)进行了分类,比如:
| 地址类型 | 地址前缀/地址 | 特点 | 补充说明/应用场景 |
|---|---|---|---|
| 未指定地址 | ::/128 | 不能分配给接口,不能作为目标地址 | 主机获取地址前的源地址(如 DAD 过程)。 |
| 环回地址 | ::1/128 | 节点用于向自身发送数据包 | 本地测试、进程间通信。 |
| 链路本地地址 | fe80::/10 | 不能出三层设备,仅用于本二层链路 | 同一链路节点通信、邻居发现 (NDP)、路由协议邻居、SLAAC。 |
| IPv4 映射地址 | ::ffff:0:0/96(例如 ::ffff:192.0.2.1) | 在双栈节点内部表示 IPv4 地址,未废弃 | 允许 IPv6 应用处理 IPv4 连接,系统内部使用。 |
| IPv4 兼容地址 | ::/96(例如 ::192.0.2.1) | 早期过渡技术,将 IPv4 地址嵌入,已废弃 (RFC 4291) | 不推荐使用,安全性差,已被更好技术取代。 |
| 站点本地地址 | fec0::/10 | 已废弃 (RFC 3879) | 被 ULA 地址取代。 |
| ULA 地址 | fc00::/7(包括 fc00::/8 和 fd00::/8) | 不能在公网路由,但可用于私有网络(内部路由) | 企业内部稳定通信,类似 IPv4 私有地址。fd00::/8 推荐使用随机全局 ID。 |
| 组播地址 | ff00::/8 | 用于将数据包发送到网络中一组特定的节点(一对多) | 用于多媒体流分发、路由协议更新(如 OSPFv3, RIPng)、邻居发现等。 地址结构包含 Flags 和 Scope 字段,定义组播类型和范围(如 ff02:: 为链路本地范围)。 |
| 全球单播地址 (GUA) | 2000::/3 | 可在全球范围路由和访问,互联网上的公共地址 | 公网通信,由 ISP/RIR 分配。 |
| Teredo 地址 | 2001::/32 | IPv6 过渡技术,用于 IPv4 NAT 后的主机访问 IPv6 网络(封装) | 允许 NAT 后主机通过 IPv4 访问 IPv6。 |
| 6to4 地址 | 2002::/16 | IPv6 过渡技术,将公网 IPv4 地址嵌入,通过 IPv4 公网连接 IPv6 站点 | 早期用于连接 IPv6 孤岛。 状态:历史/不推荐 (RFC 7526)。 |
| 文档前缀 | 2001:db8::/32 | 仅用于文档 | 用于技术文档、示例等,避免与实际地址冲突。 |
这些作用域,比如说链路本地,站点本地,全局等等,在标准上就限制了这些地址能被路由的范围,如果一台公网路由器的协议栈是严格按照标准实现的,那么当它发现类似 fc00::/7 这种地址的时候,就应该将其丢弃,另外,路由器也不能转发 fe80::/10 这种链路本地地址,这相比 IPv4只要有路由就能通,一切靠路由要严格太多了,这种严格大大减轻了配置管理员的负担!
所以说,scope 其实就是一个硬约束,两个地址如果要通信,其 socpe 越接近,其在物理上就越接近,与此相对,还有一个软约束, 即最长前缀匹配度,两个地址的最长前缀越匹配,表明二者在拓扑上越接近。
Rule 2 有两层意思:
1.优选更大 scope
越大的 scope,其可达性范围越广。这保证了源和目标通信节点的连通性。
2.优选与目标地址的 scope 更接近的 scope
如果源和目标在 scope 约束下能通信,那么 scope 越接近,它们在物理上就越接近!
注意,二者是相与的关系。在 Rule 2 之上,依然存在着 scope 作用范围的硬约束。
IPv4 没有这个 scope 的概念,但是在很多操作系统协议栈中,它依然被模拟了出来,比如对于 Linux 内核而言,它就将 127.0/8 以及 169.254 这种 DHCP 失败的地址视为了本机 scope 地址,本地链路 scope 地址,意思是说它们已经被限制住了范围,此外,关于路由 scope 也是一样,Linux 内核将链路层自己发现的路由,其 scope 定为 link 范围,而非自动发现的路由,其 scope 则是 global。
接下来我们看看 Rule 6。
IPv6 允许为每一个 IPv6 地址配置一个元组映射: M : { 地址前缀,优先级, L a b e l } M:\{地址前缀,优先级,Label\} M:{地址前缀,优先级,Label} 该元组映射作为系统的一张策略表存在,用于选择源 IP 地址或者目标 IP 地址。
如果 Rule 1~Rule 5 均没有选择出优选 IP 地址,也就是说多个幸存者 IP 无法决胜负,成了平局,那么在从剩余的幸存者候选 IP 地址中选择的时候,执行以下序列:
如果 Rule 1~Rule 5 均没有选择出优选 IP 地址,也就是说多个幸存者 IP 无法决胜负,成了平局,那么在从剩余的幸存者候选 IP 地址中选择的时候,执行以下序列:
-
用目标 IP 在 M 中的 “地址前缀” 字段执行最长前缀匹配算法;
-
根据 1 的结果,获取一个元组 m 1 : ( P 1 , P r i o r 1 , L 1 ) m_1:(P_1,Prior_1,L1) m1:(P1,Prior1,L1)
-
针对每一个候选的源 IPv6 地址 A n A_n An 执行 1,获取元组 m n : ( P n , P r i o r n , L n ) mn:(P_n,Prior_n,L_n) mn:(Pn,Priorn,Ln)
-
如果 L n = L 1 L_n= L_1 Ln=L1,那么就优选 A n A_n An
-
对于多条 L n = L 1 L_n= L_1 Ln=L1,选择优先级 P r i o r n Prior_n Priorn 最高的 A n A_n An
很有意思,是的。
我们在 Linux 上可以直接通过 iproute2 导出系统默认的这个 M M M 映射:
# ip addrl show
prefix ::1/128 label 0
prefix ::/96 label 3
prefix ::ffff:0.0.0.0/96 label 4
prefix 2001::/32 label 6
prefix 2001:10::/28 label 7
prefix 3ffe::/16 label 12
prefix 2002::/16 label 2
prefix fec0::/10 label 11
prefix fc00::/7 label 5
prefix ::/0 label 1
如果我们 man 一下 ip-addrlabel,就知道,这个表其实是可以配置的。
再简单说下 Rule 7。
在 IPv6 中,有一种生命周期有限的地址,称作临时地址。 临时地址一般用于私密通信,用完即丢。
从底层协议角度来讲,临时地址并不稳定存在,基于此,它作为次优选择会更妥当,但是另一方面,从业务的角度来讲,之所以配置这种临时地址,那么它本来就是要被使用,不然呢?要它干嘛!所以说,临时地址又是一个优选地址。
到底谁对谁错呢?没有对错!由用户自己来决定好了,所以可以从外部来配置说临时地址到底是优选的,还是不建议的次优选择。
解题
回到本文开头的那个让我恶心了好几年的故事,如果现在让我用 IPv6 跑同样的程序,问题迎刃而解!
且慢,即便是在当时,我如果使用 Linux 的话,不是还是可以用 ip route add 命令加上 src 参数来明确源 IP 地址的吗?出问题的是 Windows 啊!
是的,出问题的是 Windows,但是和 IPv4 的标准路由不同,由于 ip label 是 IPv6 的 RFC 标准建议,所以大多数操作系统均支持了它,Windows 也不例外!
在 netsh 上下文中,可以看到类似的东西:
至于说怎么配置,简单了!一路 help 即可:
好了,现在回到那个悲哀的故事,如果用 IPv6,我应该怎么配置感兴趣流量的源 IP 地址不选择虚拟网卡 IP,而选择物理网卡呢?
假设目标 IPv6 地址是一个全球全局地址,而虚拟网卡上是一个本地链路地址,那么根据 Rule 2 就可以淘汰掉虚拟网卡上的地址,但是如果虚拟网卡上的地址也是一个全球全局地址呢?
我们知道在 Rule 6 之前先要执行 Rule 5,而 Rule 将会选择虚拟网卡上的全局地址,根本没有机会执行 Rule 6 让你折腾这个 Label 表,那怎么办?
别忘了还有 Rule 3 呢!哈哈!
问题是,我们在 Linux 上废弃一个地址非常容易,执行下面的语句就可以了:
ip addr change $IPv6_addr_to_deprecated dev tun preferred_lft 0
但是,Windows 上怎么办呢?不会又是一个 Linux 上很容易,而 Windows 上完全做不到的事情。
我就不信 Windows 不按标准实现 IPv6。仔细看看 netsh,还真有类似的配置,且看:
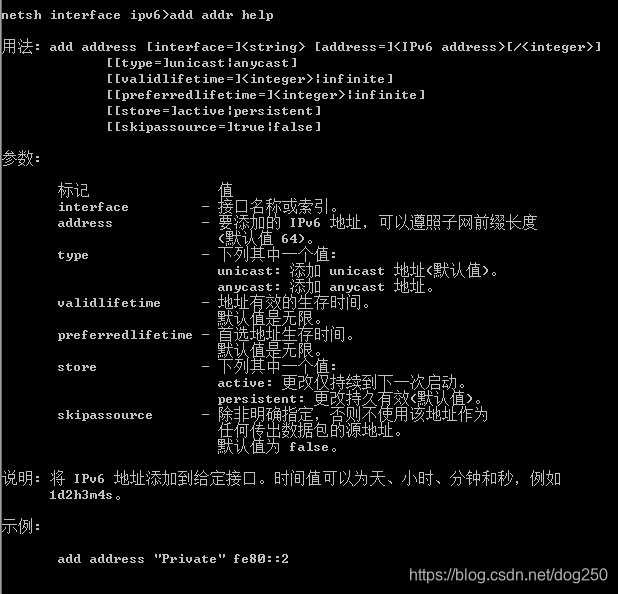
这样,将虚拟网卡上的 IP 地址给废弃掉,接下来我们就可以常规化使用 Rule 6 来把玩 Lable table 了!
具体怎么玩呢?很简单。配置如下一条规则即可:
ip addrlabel add prefix $ 目标地址 label 123
ip addrlabel add prefix $ 物理网卡地址 label 123
翻译至 Windows 上等价配置即可!
------
RFC3484 可以说是用一种常规的方法,去除了我的一块心病,为了解决这个问题,我想了无数个 Trick,但事后看来都是奇技淫巧,同时我也要感谢这个问题,让我学了很多东西。
------
说点形而上的
看完了具体的描述,我总是要写两句形而上的东西。
我们想象一下,为什么 IPv6 要有如此复杂且具体的源 IP 地址 / 目标 IP 地址选择机制,为什么 IPv4 没有这样的机制?这是为什么?
似乎我们从 IPv4 说起问题会变得简单。IPv4 太平(so flat!)太自由太没约束了!
我在 2010 年和 2017 年分别写了两篇文章:
关于 IP 网段间互访的问题 — 路由是根本
dog250 于 2010-02-09 20:37:00 发布
IP 网段间可以互相访问,完全依赖于路由。因此,路由是 IP 通信的核心。IP 是机器通信的资格证书,而路由决定了该机器的数据可以到达何处以及如何到达。没有路由,就不可能有 IP 网络。IP 实际上是一个标号,而 IP 路由是基于这种标号的寻址机制。这种逻辑解决方案使整个世界连接在一起,成为一个整体。
IP 提供了一个逻辑的物理层,传输层则是逻辑上的链路层。整个 IP 网络是一个逻辑网络,它并不在意底层的物理网络,即链路层和物理层。当逻辑网络与物理网络建立关系时,就是给网卡分配 IP 地址的时候。因为 IP 网络只是一个逻辑网络,实际传输数据还需要依靠物理网络承载。将 IP 地址分配给网卡,意味着该网卡作为 IP 数据传输的载体,负责传输到达该 IP 地址的数据或从该 IP 地址发出的数据。网卡只是一个承载层,可以承载多个 IP 地址的数据,就像一辆卡车可以装载多种货物一样。人也可以身兼数职,其中人是物理概念,而职位是逻辑概念。职位给了一个人,这个人只是该职位行为的执行者,具体如何执行还要看职位本身的指示。因此,将 IP 地址分配给网卡后,网卡并不知道如何传输 IP 数据。网卡的作用再次重申,它只是一个承载方,只提供物理连接的两点之间的传输机制。记住,这是物理相连的两点。如果想让一切工作起来,就要依靠路由。路由是 IP 逻辑网络这个“职位”的规则,它指示如何传输数据。
原则上,你可以给一块网卡分配任意数量的 IP 地址,然后为这些 IP 地址指定路由。在这块网卡上,你只能指示往哪个目的 IP 地址的数据从哪个网口走。给一块网卡分配多个 IP 地址意味着这些 IP 地址可以被寻到,即有数据是以这些 IP 地址为目的的。因此,你必须保证在其他机器或路由器上配置指向这些 IP 地址的路由,只有这样,数据才能有去有回,畅通无阻。每个路由记录会指示数据如何走,而数据在传输过程中还是要一步一步走,这一步一步走就是通过底层的物理承载网络实现的。只要你指定了路由,数据就可以通信。逻辑 IP 网络和物理链路层网络的关系除了承载与被承载之外其实并不大,也就是说,并不是一个物理网络的 IP 地址也必须是一个网段的,只要有路由就可以。
例如,将一台单网卡的 Linux 机器 M1 的 eth0 配置如下两个 IP 地址(使用ip addr add命令):eth0: inet 192.168.0.152/24 brd 192.168.0.255 scope global eth0 inet 172.16.0.5/32 scope global eth0然后将另一台单网卡的 Linux 机器 M2 的 eth0 配置如下一个 IP 地址:
eth0: inet 10.2.2.5/24 brd 10.2.2.255 scope global eth0只要保证两台机器在一个物理以太网内即可。然后在 M2 上 ping 192.168.0.152 不通,ping 172.16.0.5 也不通。难道是因为一个物理网络的 IP 地址也必须在一个逻辑网段吗?根本不是这样。记住,IP 逻辑网络中最重要的就是路由,只要有路由就能通,和物理网络没有关系。
于是为 M2 配置如下路由:172.16.0.5/32 dev eth0 scope link这条路由的意义是:往 IP 地址
172.16.0.5的数据请走eth0。现在再试试ping 172.16.0.5,还是不行。是不是有问题了呢?一点问题也没有。先说说物理网络的行为。IP 逻辑网络与物理网络还有一个相联系的地方就是 ARP 机制。如果路由配置好了,那么在路由的指导下进行实际传输,但实际传输是在物理网络进行的,因此必须要有物理地址,这就是 ARP 的作用。以太物理网络是广播网络,因此肯定可以随意传输数据。我们不是已经有了去往目的地址172.16.0.5的路由了吗?那么在访问172.16.0.5之前,首先需要172.16.0.5的 MAC 物理地址。因为我们是在一个物理网络内,所以 M2 的网卡就开始了询问:“谁的 IP 地址是172.16.0.5,请把你的 MAC 地址告诉我,我的地址是10.2.2.5。” 然后把这条 ARP 询问广播出去。因为是广播,所以所有的机器都接收到这个询问。M1 拥有172.16.0.5,因此 M1 做出回答,然后将它的 MAC 地址打包发给10.2.2.5。可是出事了,它并不知道怎么到10.2.2.5啊,于是 MAC 地址便送不到10.2.2.5,直接阻碍了物理传输,于是就 ping 不通了。
现在已经找到问题了,解决问题的方法很简单,给 M1 配置上到10.2.2.5的路由:10.2.2.5/32 dev eth0 scope link做完以后,再在 M2 上试试
ping 172.16.0.5,肯定通了。
因此可以看出,逻辑网络是否连通和物理网络的结构没有关系,只和路由有关。即使刚才那个 ARP 引起的逻辑网络不通的问题也和路由有关。只要有路由,一切自由连通。如果物理网络是不同的网络,比如不同的以太网,那么道理一样,只不过情况更复杂罢了,但本质还是创建路由。
既然可以为网卡指定 IP 地址,那么可不可以说 IP 地址属于网卡呢?不能。网卡只是传输媒介罢了,IP 地址是属于主机的,IP 地址是提供给应用的一个逻辑概念,并不是网卡的固有属性。还是以卡车为例,车上的货物是物主的而不是卡车的。以人的职位为例,职位是属于国家机器的而不是属于人的,人只是它的执行代理。这个人不干了还可以换人,但该职位永远属于国家机器。
一个古老的问题就是路由器和交换机的区别。按照这种逻辑网络和物理网络的理解,路由器就是指示 IP 数据如何走的机器,交换机指导物理数据帧怎么走,它只提供物理连接的两点之间的物理传输机制。其实路由器就是一个逻辑上的交换机,它的层次更高罢了。如果把路由当作寻址来理解的话,物理网络也有一个路由机制。交换机中也有一个“路由表”,那就是交换机学习到的 MAC 地址和端口的映射关系。
虽然路由需要人为指定,但是有一种路由确实在为网卡指定 IP 地址时自动生成,这就是链路层发现的路由。该路由指导了和指定 IP 地址为一个网段的数据包该怎么走。规范将这个“显然”的事实作为一条自动路由生成了。规范将 IP 地址存在相同部分的主机作为一个 IP 网段。一般来说,导线直接相连的两个网口是一个网段的,这已经成了约定。于是协议就会认为这个网口的那一端一定和本网口指定的 IP 地址是一个网段的,于是就有了链路层自动发现的路由一说。含义就是:到和本网口同一 IP 网段的数据一定从本网口出去!
这初看起来就是事实,难道不是吗?我们不都是这么配置网络的吗?很不幸,这不是事实。看看刚才举的那个例子吧,那么混乱的配置,几乎没有在同一网段的地址,竟然 ping 通了!这就印证了另一个真正的事实,即 IP 网络的连通在于路由而不是别的。协议自动生成的那条链路层路由其实是为了方便而不是真的必要。比如把上述混乱配置的例子中的链路层自动路由删除,照样可以 ping 通。其实那种混乱的配置下,我们根本就不用自动的链路层路由,那条路由是为常规配置准备的。
仔细看看链路层路由,它实际上是借用了物理网络的方便。因为常规上尽量把一个 IP 逻辑网段映射到一个物理网段,所以可以借用这个常规的假设,因此叫做链路层路由。真正纯粹意义的 IP 逻辑网和物理网是没有关系的,不应该有上述的网段一致映射,但是规范中建议了那种映射。上面的混乱配置的例子才是真正的理论上的 IP 逻辑网络,虽然很不实用,但对于理解概念十分有用。
两台不同网段的 PC 直连是否可以相互 ping 通
dog250 于 2017-04-02 12:42:34 发布
关于 rp_filter 的作用,本文的内容会有些容易引起误解的地方。如果你亲自试过配置,就会发现即便不配置 rp_filter,也不妨碍两者互通。所以我加了一个 配置说明 来消除这个误解,请留意。
本文描述的是一道抬杠题,但我希望不屑于配路由的程序员看了题目后先不要抬杠,先看看自己是不是能用不到 5 分钟的时间解答这个问题,期间不许查阅资源。
问题我就不详述了,请参见《两台不同网段的 PC 直连是否可以 ping 通》,但为了防止这篇文章的链接失效,我还是简单表述如下:
主机一配置:eth0:1.1.1.1/32主机二配置:
eth0:2.2.2.2/32主机一和主机二的 eth0 用一根网线直连,不必在意是交叉线还是直连线,它们是自协商的,这不是较真儿点。
问题是:在两台主机都不添加任何新的 IP 地址的前提下,主机一和主机二可以相互 ping 通吗?
常规的答案肯定是不能 ping 通,理由无非就是“两个地址不在同一个网段”之类云云。但我的答案却是,完全可以 ping 通,只要有路由即可!
我以 Linux 为例来使其相互 ping 通,配置如下:
主机 2.2.2.2 上的配置:ip route add 1.1.1.1/32 via 1.1.1.1 dev eth0 onlink sysctl -w net.ipv4.conf.eth0.rp_filter=0主机 1.1.1.1 上的配置:
ip route add 2.2.2.2/32 via 2.2.2.2 dev eth0 onlink sysctl -w net.ipv4.conf.eth0.rp_filter=0至于 Windows 怎么配置,王姐姐告诉我不需要任何配置,直接配了路由就可以通。我没有亲自试,所以不深入讨论。以下的讨论全部针对 Linux。
配置说明:
其实net.ipv4.conf.eth0.rp_filter是不需要配置的,仅仅配置路由即可。我之所以列举出net.ipv4.conf.eth0.rp_filter配置为 0,是因为本文的问题其实包含两个方面。首先是要想启动传输,必须要有路由,且仅仅有路由即可。其次,要想完成传输,必须要进行下一跳解析,逐级向下解析下层的地址,本例中就是 ARP 解析 MAC 地址。这两个方面从下往上看是递归进行的,缺一不可。然而从下往上看,只要配置了路由,ARP 也会自然而然完成。然而问题就出在这里,很多人都觉得这是自然而然完成的一个过程,但其实如果分开讲的话,你会学到更多的东西。
以从1.1.1.1来ping 2.2.2.2为例,如果2.2.2.2上没有配置到1.1.1.1的 onlink 路由,显然是不通的,但这并不意味着 ARP 无法完成。事实上,ARP 是可以完成的,即便没有路由也是可以完成的。详见下面 rp_filter 的作用解析。
这就是答案,即便直连的两台机器配置的 IP 地址不属于同一网段,也可以相互 ping 通,关键是要有路由!TCP/IP 协议族虽然不像 OSI/RM 那么和谐融洽,至少也是一套分层体系架构模型,层与层之间要做到尽可能互不牵涉,本题中可见一斑。三层互通,关直不直连什么事啊?直连不直连,那是链路的事情,与 IP 层无关。
要成功秒解这个问题,需要的知识点并不多,但很深入,包括以下几点:
1. onlink 路由是干什么的?
onlink 路由是可以直接 ARP 目标地址的,而不是 ARP 下一跳地址。意思就是说,目标地址是属于跟本地直连的二层链路上,不跨三层。既然是不跨三层的链路,ARP 就可以畅行无阻。而标准中又没有规定 ARP 协议包的请求源和请求目标必须是同一个网段的地址(甚至都没有掩码约束),所以说,以下的 ARP 请求是有效的:
源地址1.1.1.1请问,地址为2.2.2.2的网卡的 MAC 地址是多少?
好了,ARP 已经可以发出了,问题是当2.2.2.2网卡收到 ARP 之后,该如何反应呢?
2. rp_filter 如何起作用?
为了解释 rp_filter 的作用,我先假设删除主机2.2.2.2上到达1.1.1.1的路由。此时虽然2.2.2.2的 eth0 能收到来自1.1.1.1的 ARP 请求,问题是它会回应吗?
地址为2.2.2.2的网卡收到 ARP 请求之后,会执行 ARP 处理。由于 ARP 是广播发送,因此只要不跨三层的链路上所有的主机都能收到这个 ARP 请求。所以每一个主机首先会检查这个 ARP 是不是发给自己的,检查的办法很简单,就是执行一次路由查找。注意,就是路由查找而已。
路由查找的目标 IP 地址就是 ARP 的目标 IP 地址。如果路由查找结果的路由项属性是本地地址,那么就说明请求的目标 IP 地址就是本机,这个 ARP 请求就是发给自己的。到此为止,好像问题没有了,收到的 ARP 请求的是本机 IP 地址,照理说本机理应回应一个 ARP reply 了。是这样吗?**
如果使用的是 Linux,在默认情况下,这次路由查找将失败。原因在于 Linux 针对每个网卡默认启用了rp_filter选项。这个选项的作用是进行反向路径查找,即针对收到数据包的源 IP 地址做路由查找。如果查找结果的出口网卡不是收到数据包的网卡,那么查找将失败。在本例中,主机2.2.2.2在 eth0 上收到了来自1.1.1.1的 ARP 请求,那么针对1.1.1.1做路由查找,结果是没有找到路由,因此rp_filter验证将失败。于是,ARP reply 将不会被发出。
在本例中,由于主机2.2.2.2已经配置了到达1.1.1.1的 onlink 路由,所以查找是成功的。问题是,你要知道这是如何成功的。
要想让 ARP reply 被发出,需要禁用rp_filter,让路由查找通过,随后 ARP reply 就可以发出。ARP 既然已打通,onlink 路由也配置了,那么自然路就通了。现在可以尽情地ping了!
3. arp_ignore/arp_filter 又如何?
稍微了解一点 Linux 网络疑难杂症的人可能会往arp_ignore和arp_filter的方向去想,其实这个思路是对的,只是本例没有把事情搞得那么复杂。我来换个实例。假设主机一配备两块网卡,分别为 eth0 和 eth1,分别插有网线。主机一的 eth1 配置 IP 地址为1.1.1.1/32,而不再是 eth0 配置该地址,然而依然是 eth0 与主机二的 eth0 直连,主机二的 eth0 依然配置地址2.2.2.2/32。在这种情况下,事情会怎样呢?这个时候你就不得不考虑arp_ignore和arp_filter了……具体详情如何,我想有经验的读者可以自己搞定。
如果我要来面试的话,我绝对会问这种问题。当然,我会给出 5 分钟时间让面试者思考,理清知识点,但也仅仅有 5 分钟时间,且期间不许查阅资料。
能把这个问题回答正确的人,肯定是对 Linux 协议栈的实现理解非常透彻的人。这个问题的完美回答(如果不是提前准备的话)不仅仅意味着答题者是一个好的运维、好的技术支持,而是可以表明答题者可以秒杀 80% 以上的研发人员。很多人会把这种配路由的操作看作是十分低等的外围操作,认为没法跟那些精读 TCP 协议实现的人比。其实真实情况恰恰反过来。声称自己精通 Linux 内核 TCP 实现的人并不一定真的懂网络,他可能只是能看懂代码而已。有很多写过书的人,其实基本原理都不懂。恰恰那些配路由的人,常常被认为是运维、配网络、搬机器上架、扭螺丝的人,懂得可能反而更多。
程序员被惯坏了。作为一种职业,跟学生时代没有任何区别,甚至连学生们的怀疑精神、动手能力都没啦。往往书上怎么讲,就怎么记,书上写的就一定对吗?写书的人就一定懂吗?
如今太多的程序员非常浮躁,懂的名词特别多,但实际上也就是懂一些名词。成功搭建起一个环境就觉得了不得,就觉得精通了,其实还差得很远。有一篇文章写得比较好,我比较赞同,我就直接引用了,也省了我自己的笔墨:《“全栈”工程师 请不要随意去做》。虽然这篇文章也有吐槽之嫌,但看得出是真情实感。跟我之前那些类似的文章一样,踩的人比顶的人多。这说明什么?这说明当今程序员被别人说不得不好,只能夸,不能损。自以为自己高大上,其实自己心里明明有压力就是不说,顶着压力自己还不努力,然后还倔强,还抬杠,时不时抖机灵。如果鲁迅活着,我就歇息了。
我从 2007 年开始到现在,在地铁上看了两大书架的书。这里一个书架是 5×5 的方格书架,宜家毕利的那种。书目包括但不限于世界历史、网络技术、编程、互联网行业、机械工程、社会评论等,我唯独不看的三类书是时政、英语、小说。我看书有个习惯,一书未毕,不读新书,完全串行的。而且为了便于批注,我只读纸质的书(显得非常老土)。我已经把路上的时间当成了我的读书时间,同时把长春、上海、深圳三座城市的主干交通线当成了自己的图书馆,坚持了 10 年,我很自豪,很有成就感,比那些在一线城市买了房子独居一处的自豪多了(其实我在上海也买了房子,只是暂时在深圳工作而已)。在我这几年的学习生涯里,我偶尔会注视与我同行的人,不管在长春、上海还是在深圳,我每天总是在地铁上(家里有车,但我没有驾照,也永远不会考那个。我家的车我老婆开,开那玩意儿太耽误时间,没有意义)。遇到几乎相同的人,也有看书的人,但是说实话,我没有看到过一个能把一本书看完的,往往都是看完第一章前几页就换了:
- 2010 年,上海 2 号线,有人看《算法导论》,看了一周之后换了《设计模式》,此后细节不知……
- 2012 年,上海 2 号线,有人看《Java 编程思想》,看了大概一周多,换成了手机……
- 2013 年,上海地铁 11 号线,有个女的看《全球通史》,看了两周,改成了手机……
- 2013 年,上海地铁 11 号线,有人看《罗马人的故事》,第二天就改成了手机……
- 2016 年,深圳蛇口线,有人看《设计模式》,不到一周换成了手机……
- 2017 年,深圳罗宝线,几乎没有人看书,有同事说有人看《史记》被鄙视……
……
如果乔布斯可以改变世界,那么他为什么不能改变自己的基因?所有搞 IT 的人,至少目前无能为力。那么,如果程序员得了癌症,他必须求助于医生,而无法靠编程解决!
上文提到的引文两台不同网段的 PC 直连是否可以 ping 通
zhangdaisylove 于 2015-07-15 14:30:54 发布
如题,两台 PC 相连,假设 PC1 的 IP 地址为1.1.1.1,PC2 的 IP 地址为2.2.2.2。
当 PC1 ping PC2 时,会首先查看自己的 ARP 缓存,看是否有2.2.2.2对应的 MAC 地址。第一次显然没有,那么就需要发送 ARP 包来询问谁的 IP 地址为2.2.2.2。
PC2 收到来自 PC1 的 ARP 包之后,会回答说我就是2.2.2.2,将 MAC 地址发送给 PC1。
如果按照这个思路,显然是可以 ping 通的。
但是,问题的根源就在这里了,ARP 包是在什么情况下发送的呢?
ARP 协议是解决同一个局域网上的主机或路由器的 IP 地址和硬件地址的映射问题的。也就是说,当 PC1 想 ping PC2 之前,要先看 PC2 是否与自己在同一个网段上。如果在一个网段上,可以直接广播 ARP;如果不在,那么需要向网关发送 ARP 包,网关查询自己的 ARP 缓存。也就是说,如果两台直连的机器不在同一网段,是无法 ping 通的。
下面《CentOS6环境下实现路由器功能》解释了如何实现不同网段之间的电脑进行互 ping:
配置:
- 如图所示先配置所有的 IP 地址。
- Aubin-CentOS1
route add default gw 10.0.1.1- CentOS-R1
route add -net 10.0.3.0/24 gw 10.0.2.2 route add -net 10.0.4.0/24 gw 10.0.2.2 echo 1 > /proc/sys/net/ipv4/ip_forward # 启用转发功能(可以理解为启用路由功能) iptables -F # 关闭防火墙- CentOS-R2
route add -net 10.0.1.0/24 gw 10.0.2.1 route add -net 10.0.4.0/21 gw 10.0.3.1 echo 1 > /proc/sys/net/ipv4/ip_forward iptables -F- CentOS-R3
route add -net 10.0.2.0/24 gw 10.0.3.2 route add -net 10.0.1.0/24 gw 10.0.3.2 echo 1 > /proc/sys/net/ipv4/ip_forward iptables -F- Aubin-CentOS1
route add default gw 10.0.4.1以上就是全部配置。然后用 CentOS1 去测试,ping CentOS2 的 IP 地址
10.0.4.100。如果 ping 通则所有配置均没问题。如果没有通,请参考以下几点做检查:
- 使用
route -n查看路由是否生效。cat /proc/sys/net/ipv4/ip_forward查看输出是否为 1。如果为 0,说明没有开启转发功能。检查echo 1 > /proc/sys/net/ipv4/ip_forward是否执行成功。- 检查 IP 地址与掩码是否配置正确,因为有多个 IP 地址容易搞混,所以好好检查。
- 检查是否关闭防火墙,执行
iptables -F。- 如果在虚拟机环境下做实验,检查 MAC 地址是否冲突。

都是在说一个意思,即只有有路由,就能互通!
是的,IPv4 就是这么运作的!在 IPv4 中,任意地址都可以通往世界的任何地方。确实如此,即便是 127.0.0.1 这样的地址,在高版本的内核中,也可以被 NAT 了!就更别提什么 192.168 这种地址了。只要没有外部 ACL 把这种地址挡在内部,没有什么内部机制阻止其漂洋过海。
IPv4 完全是基于最长前缀匹配来选择使用哪个 IP 地址作为源,具体目标 IP 地址在拓扑上距离更近。IPv4 在默认“路由是聚合的”这个前提的基础上得到了最长前缀匹配出来的结果拓扑上距离更近的结果。
基于此一厢情愿,一开始并没有什么私有地址,没有什么规定 10.0.0.1,192.168 这种不能被公网路由,10.0/8 就是一个普通的 A 类段。
但事实上,并非如此。IPv4 的地址分配非常混乱!
于是才有了这种所谓私有地址的划分。私有属性并不是 IPv4 的内在属性。
IPv6 整洁了地址规划的过程,让路由内在地就是可汇聚的,正如 IPv4 最初的五类分类地址时代一样,天生就是路由强制汇聚的。但是为了达到这种效果,就必须将地址的用途进行强制化,比如说为了防止地址 a 被从一个大的汇聚块 A 里抠出来而被用于链路层通信,就需要规定类似 “链路层通信必须用 xxx 等地址” 等约束。
你不让人家乱用 IP 地址,你就得告诉人家什么时候用什么。
IPv6 也和 IPv4 最初一样,对地址进行了分类划分,只不过分类更加复杂和精细化。IPv4 最初的分类只是为了地址的分配(A 类地址数量巨多,B 类中等,C 类偏少…),IPv6 的分类则是根据地址的 scope 等属性进行分类的,这是本质的不同。
于是乎比方说 fe80::/10 就出来了,专门用于链路层通信,这是 IPv6 一开始就这么规定的。对比 IPv4,169.254 这种地址是后来才被规定的,而且还不是强制规定,感觉像是随便拍脑袋拍了一个地址。
IPv6 地址被分类了,也就不再被管理员完全掌控和解释了。对比 IPv4 地址,那可是管理员想怎么配置就怎么配置,想怎么解释就怎么解释的。只要你有路由,169.254 照样可以出去。
管理员不再可以控制地址用法的解释权,内在机制就要把某些以前管理员做的事情,帮其完成。比如如何选择通信时的源 IP 地址,比如如何选择 DNS 返回来的多个 IPv4,IPv6 混杂在一起的地址作为目标 IP 地址。这就有了这个 RFC3484,专门来指示在通信的时候,如何来选择用哪个 IP 地址。注意,这个是 RFC,不是让配置管理员看着做的,而是让操作系统协议栈实现时照着实现的。
嗯,这是最简单的为人处事的方法,省去了管理员学习很多东西。确实,机器在某些方面更不容易犯错,它们会做得更好,要让人学会理智,真的太难。
如果让管理员自己配置而不加以协议栈层面的约束,那么不专业的管理员很有可能会配置一个 fe80 的地址,期望它做全局通信,岂不乱套…
形而上地总结一下 IPv4 和 IPv6:
-
IPv4:无法一眼从地址上看出其 scope,地址的解释权在配置管理员那里。
-
IPv6:特定地址块有着严格的 scope,地址的解释权在协议栈。
我们实际地看一个例子。
对于 IPv4,当我为我的网卡 enp0s3 和 enp0s8 配置好并激活时,iproute2 的地址展示结果如下:
[root@localhost ~]# ip addr ls
1: lo: <LOOPBACK> mtu 65536 qdisc noqueue state DOWN group defaultlink/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 08:00:27:c8:4a:ad brd ff:ff:ff:ff:ff:ffinet 10.0.2.15/24 brd 10.0.2.255 scope global noprefixroute dynamic enp0s3valid_lft 84416sec preferred_lft 84416secinet6 fe80::647a:59b:f3ac:82e4/64 scope link noprefixroutevalid_lft forever preferred_lft forever
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 08:00:27:ff:26:e6 brd ff:ff:ff:ff:ff:ffinet 192.168.56.101/24 brd 192.168.56.255 scope global noprefixroute dynamic enp0s8valid_lft 1023sec preferred_lft 1023secinet6 fe80::fbb2:a1e:e59:15eb/64 scope link noprefixroutevalid_lft forever preferred_lft forever
这时,我们可以看到两块网卡都自动生成了一个 fe80 的地址,这个时候看看 IPv4 的路由:
[root@localhost ~]# ip route ls
default via 10.0.2.2 dev enp0s3 proto dhcp metric 101
10.0.2.0/24 dev enp0s3 proto kernel scope link src 10.0.2.15 metric 101
192.168.56.0/24 dev enp0s8 proto kernel scope link src 192.168.56.101 metric 100
可以看到协议栈自动生成了两条链路层路由,很显然,这些路由所关联的 IP 地址就是你配置在网卡上的 IP 地址。
我们再看看 IPv6 的路由:
[root@localhost ~]# ip -6 route ls
fe80::/64 dev enp0s8 proto kernel metric 256
fe80::/64 dev enp0s3 proto kernel metric 256
懵了… 按照 IPv4 的理解方式,这明显是路由冲突了!但是对于 IPv6 而言,却不是这样。IPv6 明确规定 fe80 的地址仅仅针对链路有效,不能跨网卡,不能跨路由器通信,所以说,如果你想用上述两条路由中的任意一条,你就必须指定网卡:
ping6 fe80::xxyy% 网卡 ID
还记得我之前总扯的那些关于 IPv4 的 Trick 吗?其实内核协议栈本身关于 IPv4 就有 Trick,比如和直连主机的非直连网卡通信,这就涉及到了 ARP 如何去获取一个IP 地址没有配置在本网卡上的网卡 MAC 地址,还记得怎么解吗?
答案就是配置系统参数:
net.ipv4.conf.all.arp_ignore
net.ipv4.conf.all.arp_filter...
多年来,我帮助无数人解决过无数个类似的问题…
IPv6 来了,这些 Trick 都不复存在,甚至 ARP 也被统一到 ICMPv6 里面了,如何连通主机,看懂 RFC3484 即可!
------
关于实现
看 Linux 内核的源码,以选择源地址为例,整个地址选择浓缩在了ipv6_dev_get_saddr函数中,简单看了一下,该函数其实就是对机器上所有的地址进行了一个冒泡排序而已。排序的规则就是从 Rule 1 到 Rule 8,遍历两层嵌套,外层是遍历设备,内层是遍历每一个设备的所有 IPv6 地址。
为了说明上面形而上的一个细节,注意一个代码段:
for_each_netdev_rcu(net, dev){struct inet6_dev *idev;/* Candidate Source Address(section 4)* - multicast and link-local destination address,* the set of candidate source address MUST only* include addresses assigned to interfaces* belonging to the same link as the outgoing* interface.*(- For site-local destination addresses, the* set of candidate source addresses MUST only* include addresses assigned to interfaces* belonging to the same site as the outgoing* interface.)*/if(((dst_type & IPV6_ADDR_MULTICAST)||// 如果是链路本地地址,不允许跨网卡!dst.scope <= IPV6_ADDR_SCOPE_LINKLOCAL)&&dst.ifindex && dev->ifindex != dst.ifindex)continue;...}
这段代码说明了,内核协议栈的实现,直接限制了地址不能乱用,完全遵循 scope 的规定!
------
例子
理解 RFC3484 最好的方法不是使劲读文档,也不是思考,最好的方式就是直接去读 RFC3484 后面的实例,这些实例非常好。
这里摘录几个:
10.1. Default Source Address Selection
The source address selection rules, in conjunction with the default policy table, produce the following behavior:
Destination:
2001::1Candidate Source Addresses:
3ffe::1orfe80::1Result:
3ffe::1(prefer appropriate scope)Destination:
2001::1Candidate Source Addresses:
fe80::1orfec0::1Result:
fec0::1(prefer appropriate scope)Destination:
fec0::1Candidate Source Addresses:
fe80::1or2001::1Result:
2001::1(prefer appropriate scope)Destination:
ff05::1Candidate Source Addresses:
fe80::1orfec0::1or2001::1Result:
fec0::1(prefer appropriate scope)Destination:
2001::1Candidate Source Addresses:
2001::1(deprecated) or2002::1Result:
2001::1(prefer same address)Destination:
fec0::1Candidate Source Addresses:
fec0::2(deprecated) or2001::1Result:
fec0::2(prefer appropriate scope)Destination:
2001::1Candidate Source Addresses:
2001::2or3ffe::2Result:
2001::2(longest-matching-prefix)…
10.2. Default Destination Address Selection
The destination address selection rules, in conjunction with the default policy table and the source address selection rules, produce the following behavior:
Candidate Source Addresses:
2001::2orfe80::1or169.254.13.78Destination Address List:
2001::1or131.107.65.121Result:
2001::1(src2001::2) then131.107.65.121(src169.254.13.78) (prefer matching scope)Candidate Source Addresses:
fe80::1or131.107.65.117Destination Address List:
2001::1or131.107.65.121Result:
131.107.65.121(src131.107.65.117) then2001::1(srcfe80::1) (prefer matching scope)Candidate Source Addresses:
2001::2orfe80::1or10.1.2.4Destination Address List:
2001::1or10.1.2.3Result:
2001::1(src2001::2) then10.1.2.3(src10.1.2.4) (prefer higher precedence)
特别妙的是最后一个完整实例,它告诉我们,原来 IPv6 可以仅仅捣鼓地址就能实现 IPv4 必须用 ACL,NAT,Policy Routing 等配置出来的效果:
10.5. Configuring a Multi-Homed Site
Consider a site A that has a business-critical relationship with another site B. To support their business needs, the two sites have contracted for service with a special high-performance ISP. This is in addition to the normal Internet connection that both sites have with different ISPs. The high-performance ISP is expensive and the two sites wish to use it only for their business-critical traffic with each other.
Each site has two global prefixes, one from the high-performance ISP and one from their normal ISP. Site A has prefix2001:aaaa:aaaa::/48from the high-performance ISP and prefix2007:0:aaaa::/48from its normal ISP. Site B has prefix2001:bbbb:bbbb::/48from the high-performance ISP and prefix2007:0:bbbb::/48from its normal ISP. All hosts in both sites register two addresses in the DNS.
The routing within both sites directs most traffic to the egress to the normal ISP, but the routing directs traffic sent to the other site’s2001prefix to the egress to the high-performance ISP. To prevent unintended use of their high-performance ISP connection, the two sites implement ingress filtering to discard traffic entering from the high-performance ISP that is not from the other site.
The default policy table and address selection rules produce the following behavior:
Candidate Source Addresses:
2001:aaaa:aaaa::aor2007:0:aaaa::aorfe80::aDestination Address List:
2001:bbbb:bbbb::bor2007:0:bbbb::bResult:
2007:0:bbbb::b(src2007:0:aaaa::a) then2001:bbbb:bbbb::b(src2001:aaaa:aaaa::a) (longest matching prefix)
In other words, when a host in site A initiates a connection to a host in site B, the traffic does not take advantage of their connections to the high-performance ISP. This is not their desired behavior.Candidate Source Addresses:
2001:aaaa:aaaa::aor2007:0:aaaa::aorfe80::aDestination Address List:
2001:cccc:cccc::cor2006:cccc:cccc::cResult:
2001:cccc:cccc::c(src2001:aaaa:aaaa::a) then2006:cccc:cccc::c(src2007:0:aaaa::a) (longest matching prefix)
In other words, when a host in site A initiates a connection to a host in some other site C, the reverse traffic may come back through the high-performance ISP. Again, this is not their desired behavior.
This predicament demonstrates the limitations of the longest-matching-prefix heuristic in multi-homed situations.
However, the administrators of sites A and B can achieve their desired behavior via policy table configuration. For example, they can use the following policy table:
Prefix Precedence Label ::150 0 2001:aaaa:aaaa::/4845 5 2001:bbbb:bbbb::/4845 5 ::/040 1 2002::/1630 2 ::/9620 3 ::ffff:0:0/9610 4 …
后面过程执行的解释,不再摘录,请自行思考,非常好玩。
后记
世界上迄今为止最大的飞机,A380 停产了,貌似印证了一个道理,**枢纽到枢纽的战略行不通,**庇护制的 NAT 终将失败!那么怎么办?
当然是点对点咯!
相对 A380 较小的飞机可以完美胜任点对点的运输任务,这意味着去枢纽化进程势在必得!
嗯,IPv6 也旨在点对点传输,在我看来,IPv4 的 NAT 节点就是枢纽,扫掉它们!世界正在微型化…
领主的领主,毕竟,不是我的领主。
闲谈 IPv6 - 一起玩转 IPv6 地址自动配置
dog250 于 2019-03-06 00:15:57 发布
早在 2012 年,我就开始扯 IPv6 的自动配置,光说不练假把式,于是本文将给大家带来一种不一样的感觉,本文是一个夹杂着形而上说辞的 Howto,不伦不类,但可以看透是非。
我喜欢将所有理论摆平,但是本文中,将展示一个可以实际操作的过程。
请阅读。
IPv6 自动配置
IPv6 的地址不好记忆 一直是 IPv4 卫道士们的一个槽点,然而谁让你去记忆 IPv6 地址了?
IPv6 庞大到天文数字的地址数量,天生就是为万物互联而生的,如若真的每一粒沙子都有一个 IPv6 地址,试问哪个人可以靠记忆去手敲地址进行配置,就算不靠疲惫的大脑来记忆,如果把这些地址和配置打印在 A4 的纸上,实际上最大的图书馆都装不下,那么存在计算机存储介质上呢?你试着算算看它们将占据多大的存储空间,以及读取它们需要多久的时间?
别指望靠人去配置了!随着技术的发展,人是越来越靠不住的,机器才可以。
于是,IPv6 的一个杀手特性引起了人们的注意,即自动配置!
来自 RFC4862 的福音,请先阅读:
- RFC 4862-IPv6 Stateless Address Autoconfiguration:
https://tools.ietf.org/html/rfc4862
有人说,IPv4 不也有 DHCP 吗?是的,但是它们的本质却是不同的。DHCP 需要你去配置 另一个协议的服务,即你需要搭建 DHCP 服务器,你需要 DHCP 客户端,比如在 Windows 上,你就要开启 dhcp client 服务,天啊,这也是个服务!
换句话说,DHCP 是 IPv4 协议本身之外的东西。而 IPv6 自动配置却是其内在的东西,它是 IPv6 协议标准的一部分。一个 IPv6 终端,只要简单的开机,它就会自动获得 IPv6 地址。
广泛点说,IPv4 的 Zeroconf 不也是一种标准吗?zeroconf 详见:
- Zero-configuration networking:
https://en.wikipedia.org/wiki/Zero-configuration_networking
嗯,看起来是啦,但还是不一定。
事实上,这种事一直在上演。Anycast 这种 Trick 不也是在 IPv4 网络被实践了很多年吗?互联网领域内这种没有门槛的算法之外的技术,只有想不到,没有做不到,这不是粒子对撞机。
XXX 古已有之这种说辞到处可以说,我们早已习惯,但是看实质,那还真的不一样。
IPv6 地址生命周期
当使能 IPv6 自动配置时,一个节点在从获得自动配置的地址开始,到地址不再可用的这段时间,成为该地址的一个生命周期,在时间轴上,我将其列如下:

在 Linux 系统中间隔几秒连续两次查看同一个网卡的同一个自动配置的地址 (下图中的自动配置的地址来自于我的常规配置,不必较真儿这是为什么,下面全部讲清楚):

在 Prefered 和 Invalid 之间,即 Prefered 时间已经退到了 0,而 Invalid 时间还有剩余,此时的地址就处在 Deprecated 状态,该状态的地址可以继续作为目标地址,但是不建议作为源地址,除非它的 scope 更加合适,详见 RFC3484:
Rule 2: Prefer appropriate scope.
If Scope (SA) < Scope (SB): If Scope (SA) < Scope (D), then prefer SB and otherwise prefer SA. Similarly, if Scope (SB) < Scope (SA): If Scope (SB) < Scope (D), then prefer SA and otherwise prefer SB.
Rule 3: Avoid deprecated addresses.
The addresses SA and SB have the same scope. If one of the two source addresses is “preferred” and one of them is “deprecated” (in the RFC 2462 sense), then prefer the one that is “preferred.”
邻居发现和 Anycast
关于 Anycast 这个话题,详见:
- 闲谈 IPv6-Anycast 以及在 Linux/Win7 系统上的 Anycast 配置:(见下文)
https://blog.csdn.net/dog250/article/details/88071601
如果想要彻底理解 IPv6 自动配置以及通信的过程,这里有必要联系邻居发现再说一下 Anycast。
IPv6 的邻居发现和 IPv4 的 ARP 有大不同。
-
IPv4 的 ARP
IPv4 在发送 ARP 请求学习目标主机的 MAC 地址时,收到 ARP 请求的主机会顺便学习发送者的 MAC 地址,但是这会引起混乱!特别在防止 ARP 表项抖动的时候,需要非常复杂的配置或者说 Hack!
-
IPv6 的邻居发现
IPv6 地址发现将请求和通告严格区分为两个独立的过程。ICMPv6 的邻居发现使用 override 标识位来判断需要不需要覆盖旧的邻居,而不仅仅根据状态时间。
仔细看 RFC4861 中的协议格式:

RFC4861 中对 O 位的解释是:
Override flag. When set, the O-bit indicates that the advertisement should override an existing cache entry and update the cached link-layer address.
When it is not set the advertisement will not update a cached link-layer address though it will update an existing Neighbor Cache entry for which no link-layer address is known.
It SHOULD NOT be set in solicited advertisements for anycast addresses and in solicited proxy advertisements.
It SHOULD be set in other solicited advertisements and in unsolicited advertisements.
【注意,邻居请求协议中没有 O 位】
明确表明,针对 Anycast 地址的邻居请求,不会覆盖已经有的邻居条目,这意味着,一个 Anycast set 中的路由器,谁的通告先到达请求者,请求者就将谁设置为邻居,后面再来的通告不会覆盖已经有的邻居项。
我们再看看专门对 Anycast 邻居发现的约束:
Anycast addresses
Anycast addresses identify one of a set of nodes providing an equivalent service, and multiple nodes on the same link may be configured to recognize the same anycast address.
Neighbor Discovery handles anycasts by having nodes expect to receive multiple Neighbor Advertisements for the same target.
All advertisements for anycast addresses are tagged as being non-Override advertisements.
A non-Override advertisement is one that does not update or replace the information sent by another advertisement.
These advertisements are discussed later in the context of Neighbor advertisement messages. This invokes specific rules to determine which of potentially multiple advertisements should be used.
理解了这个,就可以明白为什么可以把 Anycast 地址设置位默认网关而不会出现邻居表抖动了。
------
我们回顾一下 IPv4 的 ARP。
ARP 其实不算是标准的 IP 协议,它只能说是 IP 协议的辅助协议,它位于 IP 协议之下。比如它通信的时候,不必封装标准 IPv4 协议头。但是 IPv6 的邻居发现则不同。
IPv6 的邻居发现封装于 ICMPv6 报文中,而 ICMPv6 则必然立于 IP 协议之上,它是由标准的 IPv6 协议头封装的,于是,事情就统一了,好一个统一,帅得很!
也就是说,哪怕发送一个邻居发现报文,即 ICMPv6 报文,也要封装一个 IPv6 协议头。但是自动配置之前,主机节点并不知道自己的 IP 地址,在先有鸡还是先有蛋的困局下,于是链路本地地址就派上了用场。IPv6 链路本地地址是一块使能了 IPv6 协议的网卡与生俱来的!我们知道,IPv6 自动配置中,链路本地地址是关键,它不像 IPv4 时代必须在后来见招拆招般规定一个保留地址段,比如 169.254/16 用于无地址通信。IPv6 扫除了 IPv4 年代大部分 Zeroconf 机制存在的必要性!
既然 ICMPv6 邻居发现协议也是一个普通的 IPv6 报文,那么如何解析 Anycast 地址的 MAC 呢?
如果把 Anycast 地址配置为默认网关,那么在发包到外网时,势必需要解析它的 MAC 地址,然而 Anycast 节点是一个 Set 而不是一台特定的主机,所以,基于最短度量,IPv6 采用先到先得,不覆盖的原则来解析,即离请求主机最近的 Anycast Set 中的路由器肯定最先回复邻居通告,然后忽略掉后来的那些更远的通告。这对正向主动的发包过程是很好理解的,但是如果返回路径的包从另一个 Anycast Set 中的路由器过来呢?
该路由器 R1 不是正向数据包出发时经由的那台路由器 R0,它要解析主机的 MAC 地址,于是它发送邻居请求给主机。
看到这里,我想很多人都会有个疑问,如果路由器 R1 发送邻居请求,它是 Anycast Set 的一员,自然也有 Anycast 地址,那么它的邻居请求被主机 H 接收到之后,R1 的 MAC 地址会不会冲掉原始的 R0 邻居项呢?
Anycast-R0 的 MAC 会不会被 Anycast-R1 的 MAC 地址替换?你说呢?
答案是不会! Why?
因为关于 Anycast,有一个原则,即Anycast 地址不要作为源地址! 因此,在路由器 R1 发出的针对 H 的邻居请求的 IPv6 协议头部中,源地址并不是这个 Anycast 地址,而是路由器 R1 的相关网卡的链路本地地址,详情还是要参看 RFC3484 关于 IPv6 报文源地址的选择细节,这里只要关注,IPv6 邻居发现报文是一个 ICMPv6 报文,它也是一个普通的 IPv6 协议封装的报文!
临时地址
IPv6 真正标识了网络,这点和 IPv4 有着本质的不同。
IPv6 路由器管理的是网段,而不是主机。IPv6 路由器靠邻居发现仅仅管理到满足它知道这个邻居属于自己的一个网段这样的程度即可!这点是靠类似 IPv6 EUI-64 映射机制实现的。
**也就是说,IPv6 的主机标识由主机自己来生成和维护!**IPv6 实现了 OSI 模型的地址形式,将网络路由器 / 路由器的寻址和路由器 / 主机之间的寻址区分了开来:
-
路由器 / 路由器寻址:使用路由协议交换转发信息,最长前缀匹配算法寻址
-
路由器 / 主机寻址:使用 ICMPv6 邻居发现协议寻址
嗯,真正的 Internet!
但这会出现一个问题,且往下看。
在 IPv4 网络中,如果一个节点换了 IP 地址,那基本上没人会猜测到两个 IP 地址之间的关联,比如我的笔记本电脑在家的时候,它的地址是 192.168.1.101,当我把这台电脑带到了一个星巴克,它可能会被分配另一个地址 172.16.2.33,没人知道这两个地址标识的是一台设备!
但是,这在 IPv6 中却有问题。
简单起见,姑且把 EUI-64 先等同于 MAC 地址前导 16 个 0 组成,比如你的 MAC 地址是 08:00:27:ff:26:e6,那么 EUI-64 生成的主机标识则是 00:00:08:00:27:ff:26:e6,反正你就知道能通过你的 MAC 唯一算出你的主机标识就好了。
假设我家里的 IPv6 段是 2001:111:222::/64,我的笔记本 MAC 地址是 08:00:27:ff:26:e6,那么我的笔记本电脑的地址就是 2001:111:222::00:00:08:00:27:ff:26:e6/64。
如果我把这台电脑拿到了星巴克,虽然水网段前缀发生了变化,但是由于 MAC 地址没有变化,因此新 IPv6 地址的低 64 位是不变的!!
考虑到 MAC 地址的唯一性以及其和网卡厂商,售卖点等信息的关联性,如果你买这个电脑时恰好用了微信支付或者支付宝,你相当于实名买了这台电脑,那么只要你带着这台电脑并且使用,通过下面的线索就能定位你的隐私:
接入点搜集的邻居信息–> 你的 MAC 地址–> 支付记录以及 MAC 地址序列号的出货记录–> 你是谁。
或者说,如果有人知道你的 MAC 地址,他就有可能知道你在什么时间去过什么地方…
所以说,某些时候,我们不希望使用 EUI-64 机制来生成主机标识信息,相反我们更希望使用随机一点的值。这就是所谓 IPv6 临时地址。
只要你启用了 IPv6 临时地址,那么当你收到路由器推送下来的前缀信息时,除了根据 EUI-64 机制生成一个常规的 IPv6 主机标识并和前缀拼形成一个 IPv6 地址之外,还会使用随机算法生成一个随机主机标识并和前缀拼接形成一个随机的临时 IPv6 地址。
一般而言,这个随机的地址生命周期比较短,比如说一天时间。它一般作为源地址和远程服务器通信,通过你的偏好配置,你可以在通信发生时让协议栈优选临时地址作为源地址。 详见 RFC3484:https://tools.ietf.org/html/rfc3484#section-5 中的 rule 7。
关于临时地址的更多详情,参阅 RFC 是最标准的做法:
RFC4941-Privacy Extensions for Stateless Address Autoconfiguration in IPv6: https://tools.ietf.org/html/rfc4941
How to-Step by Step
理解了以上 IPv6 的地址特性,现在进入重头戏。
这个小节将 step-by-step 演示 IPv6 的自动配置是如何玩的。为了简单起见,我的拓扑如下:

下面我要两台机器轮流做路由器和需要被自动配置的节点主机,大家可以同时领略两种不同操作系统配置的不同风味。
为了系统净化,我特意将两台设备都进行了重置。
Windows 7 作为路由器的配置过程
首先你要学会 netsh 的使用,它非常简单和方便。值得一提的是,我没有专门学习 netsh,我看完 RFC 后,配置 Windows 路由器时,一路 help 下来的,就成功了。让我感觉这非常人性化,和 Cisco 命令行很像,秒杀 Linux 的 bash 命令行或者 iproute2。
------
我们首先用它来为**“本地连接 3”**这块网卡添加一个 IPv6 地址:
C:\>netsh int ipv6 add addr "本地连接 3" 2007:777:666::555/64
然后效果如下:
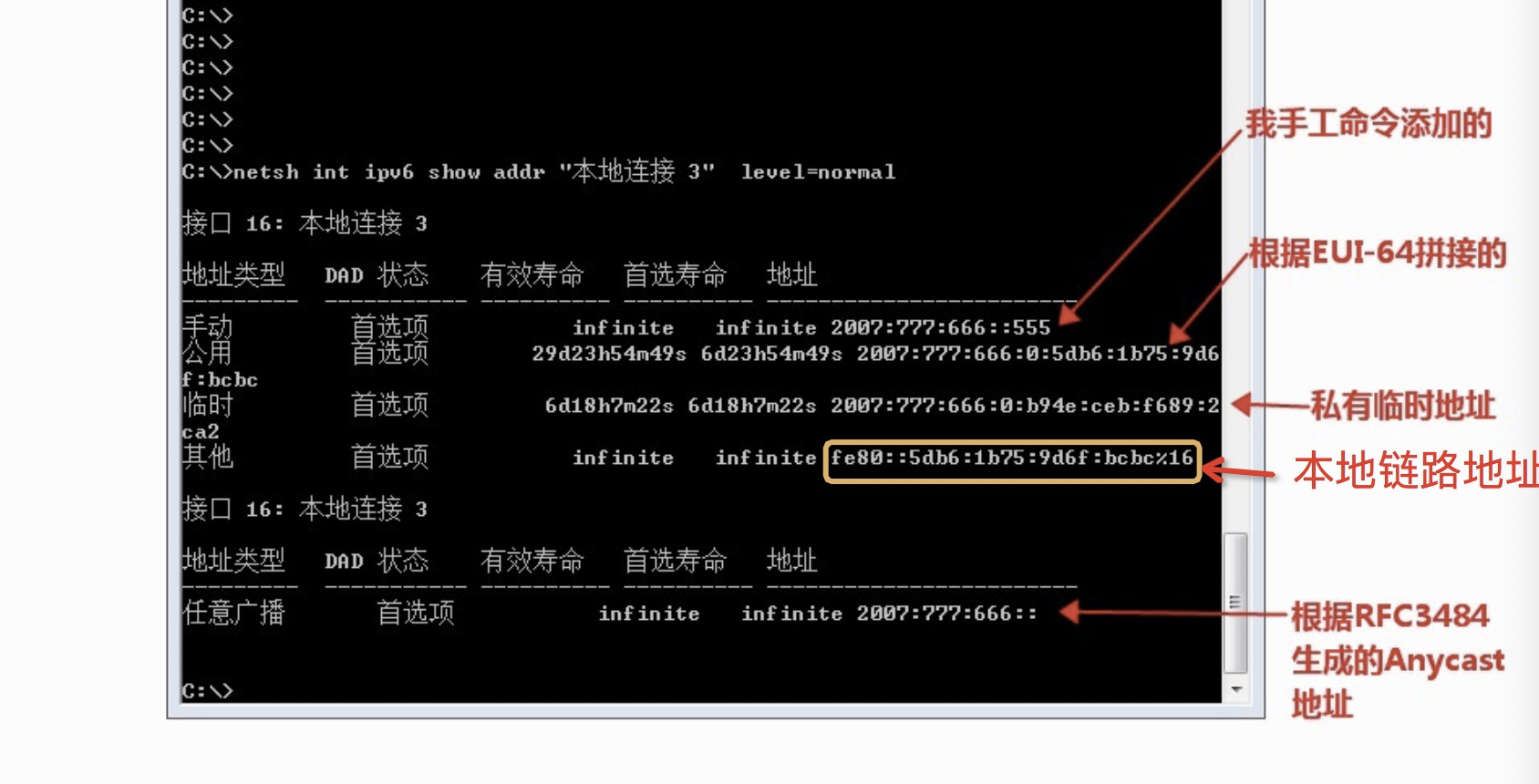
就简单 add 了一个地址,结果出现了这么多地址,应有尽有,我来分别简单解释一下:
-
手工添加的地址:配什么就是什么,类似 IPv4 的手工配置,可作为目标地址用于全局通信
-
EUI-64 拼接的地址:根据 RFC3513 规范生成的地址,可作为源地址用于全局通信
-
临时地址:为了解决 RFC4941 陈述的问题而随机生成的地址,可作为源地址用于全局通信
-
本地链路地址:为实现自动配置而自动生成的 Link 地址
-
Anycast 地址:依据 RFC3513 Reqired Anycast 规定而生成的地址
由于我手工配置的地址是2007:777:666::555/64,那么其网络前缀自然就是2007:777:666::/64,这个也是该 Windows 机器作为路由器将来要自动配置给其网内主机的地址段。
说一下最后这个 Anycast 地址,为什么会生成这个地址,不是说路由器才有这个地址吗?
是的,当然是只有路由器才有,所以说我已经把 Windows 机器变成了一台路由器。如何变的呢?非常简单,执行下面的命令即可:
C:\>netsh int ipv6 set int "本地连接 3" forwarding=enable
是的,不要去 regedit 设置注册表了,就着干就行!netsh,不二选择!
为了让本链路上的主机将自己设置为默认网关,还需要下面的命令:
C:\>netsh int ipv6 set int "本地连接 3" advertisedefault=enable
好了,此时此刻,我们的 Windows 主机已经是一台路由器了,并且按照相关的 RFC 规范,路由器需要的功能已经应有尽有,最后还差一步,即如何让这个 Windows 路由器播报自己的前缀从而给发出路由器请求的节点推送网络前缀呢?
非常简单,只要下面的命令即可:
C:\>netsh int ipv6 set route 2007:777:666::555/64 "本地连接 3" publish=yes
------
再次强调,netsh 一定要多玩!
------
至此,Windows 上的配置已经基本完毕。最后看一下 “本地连接 3” 的总配置:
此时,Linux 主机的 enp0s9 网卡要开启了!
确认以下的配置是正确的:
# 接收路由器通告
net.ipv6.conf.enp0s9.accept_ra = 1# 接受通告路由器作为默认网关
net.ipv6.conf.enp0s9.accept_ra_defrtr = 1# 接受前缀通告,这是自动配置之关键
net.ipv6.conf.enp0s9.accept_ra_pinfo = 1值得注意的是,上述的配置会在自动配置过程中被改变!
这主要是由 /sbin/NetworkManager 搞的。如果一个主机频繁收到不同的路由器通告,很容易出问题,所以最好是自己维护一个状态机,只有在确认当前的自动分配的地址已经超时而 Invalid 时,才会重新开启接收路由器通告。
NetworkManager 在收到路由器通告后,会将相关网卡的 accept_ra 等配置参数给禁止掉,事情不容小觑。
不过我建议,初学者可以先干掉这个 NetworkManager,不要被它诡异的行为影响。毕竟这主要是在演示原汁原味的纯正 IPv6 自动配置,而不是真的要用它。
好了,在我 killall -9 NetworkManager 之后,事情明朗了。
此外,在 IPv6 中,路由器和主机的角色在配置上是互斥的。这点尤其注意。比如,当你将节点配置成路由器时,它将不再接收其它的路由器通告 (除非强制配置,但不建议)。
此时此刻,同时开启抓包!且看:
[root@localhost ~]# ifconfig enp0s9 up
等待几秒:
[root@localhost ~]# ip -6 add ls dev enp0s9
4: enp0s9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qlen 1000# 自动配置的地址,由 EUI-64 生成并拼接主机标识inet6 2007:777:666:0:a00:27ff:fed0:3f5c/64 scope global mngtmpaddr dynamic# 注意这些时间!valid_lft 2591963sec preferred_lft 604763secinet6 fe80::a00:27ff:fed0:3f5c/64 scope linkvalid_lft forever preferred_lft forever
[root@localhost ~]#
[root@localhost ~]# ip -6 ro ls dev enp0s9
2007:777:666::/64 proto kernel metric 256 expires 2591890sec
fe80::/64 proto kernel metric 256
# 推下来的路由通告中的默认路由指向 Windows 的本地链路地址!
default via fe80::5db6:1b75:9d6f:bcbc proto ra metric 1024 expires 1690sec自动配置完美完成,Linux 主机的 IPv6 地址为:
2007:777:666:0:a00:27ff:fed0:3f5c/64
我们来看一下抓包文件,看看发生了什么:
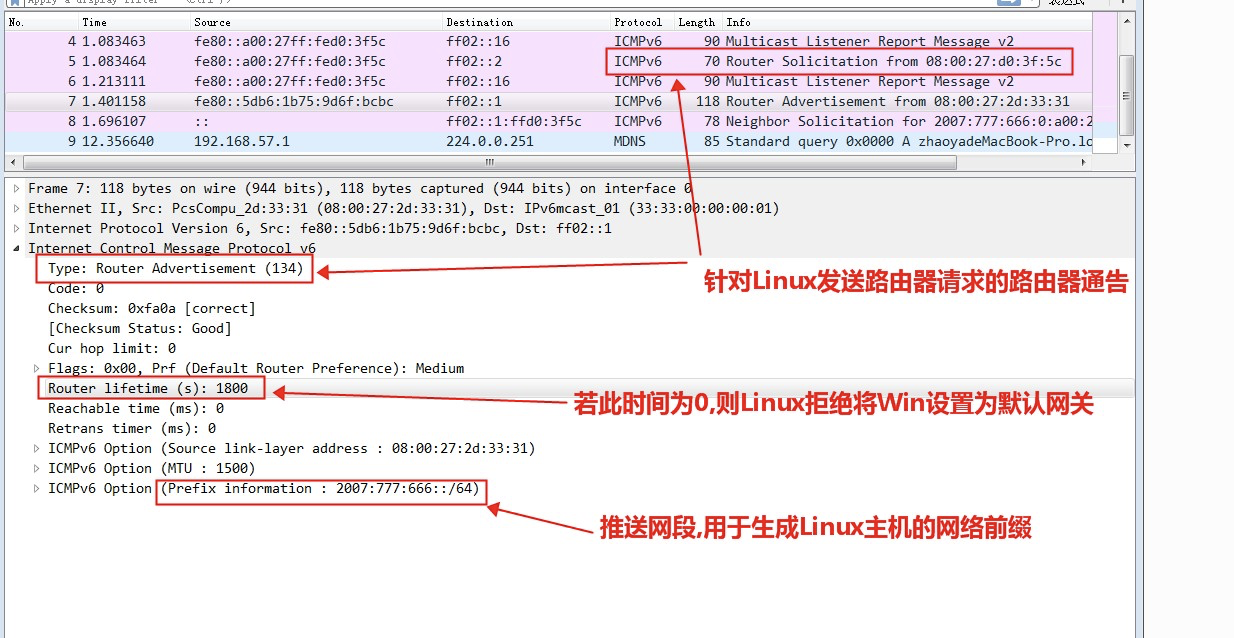
注意那个 Router lifetime 字段。RFC4861 的 6.2.3 节 这样说:
6.2.3. Router Advertisement Message Content
…
A router might want to send Router Advertisements without advertising itself as a default router.
For instance, a router might advertise prefixes for stateless address autoconfiguration while not wishing to forward packets.
Such a router sets the Router Lifetime field in outgoing advertisements to zero.
我们实际抓包试试看,比如在 disable 和 enable forwarding 开关,仅仅保留 publish 开关时,看看 Windows 路由器发送的路由器通告有什么区别:
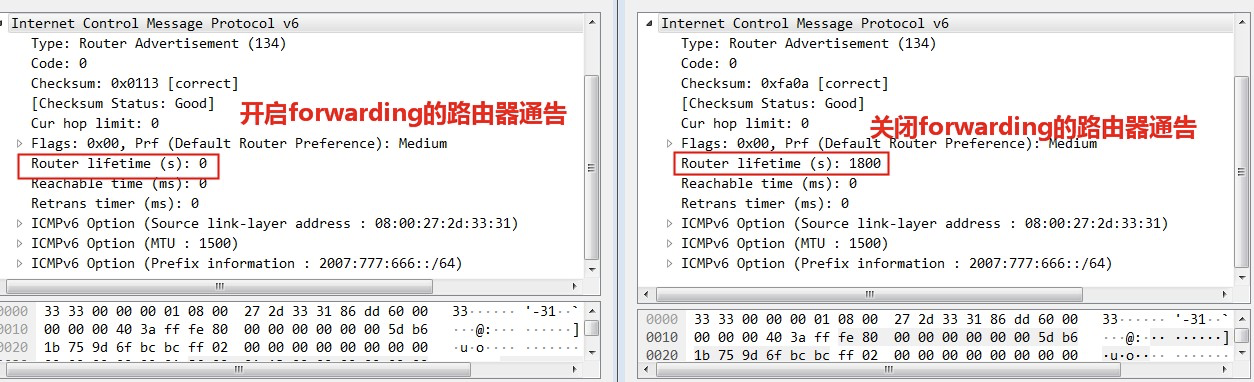
就这么点点不同而已,说明了 Windows 确实遵循了 RFC 规范。
自动配置完毕,来发个包试试看呗。
Linux 主机不是接受 Windows 路由作为默认网关了吗:
::/0 fe80::5db6:1b75:9d6f:bcbc UGDAe 1024 0 0 enp0s9
下一跳是 Windows 路由器的本地链路地址。如果这是 IPv4,在通信时,通信源地址根据和网关的最长前缀匹配原则,肯定会选择为 enp0s9 的本地链路地址,但是 IPv6 却不是这样,它严格按照 RFC3484 来选择源地址,我们来试试看:
[root@localhost ~]# telnet 3333:2222:1111::123 80
Trying 3333:2222:1111::123...
抓包截图:

命中 RFC3484 第 5 节的 rule 5:
Rule 5: Prefer outgoing interface.
------
现在来总结一下。
-
两台机器,一台 Windows 作为路由器,另一台 Linux 作为主机,准备开始演示 IPv6 自动配置。
-
将 Windows 配置成路由器,并且添加一个 IPv6 全局地址,最终根据相关 RFC 规范,生成了一堆地址。
-
开启 Windows 路由器的路由器通告前缀选项。Windows 路由器配置完成。
-
开启 Linux 主机 enp0s3 网卡,通过抓包观察自动配置的过程。
-
Linux 主机发起一个 TCPv6 连接请求,测试默认路由功能,同时验证源地址选择原则。
-
关于临时地址的使用,我并没有讲,开启net.ipv6.conf.enp0s9.use_tempaddr试试?
全程配置使用 netsh 这个非常好用的 Windows 工具。
CentOS Linux 作为路由器的配置过程
接下来该对换角色了。
这次 Linux 作为路由器,而 Windows 作为主机。为此,我重置了两台机器的既有配置。切记,一定要关闭 Windows 的路由器转发以及路由器通告功能,它才能作为普通主机接收自动配置。
现在开始配置 Linux 路由器。这个很简单,打开 forwarding 即可:
[root@localhost ~]# sysctl -w net.ipv6.conf.all.forwarding=1
net.ipv6.conf.all.forwarding = 1
开启这个路由转发功能后,Anycast 地址自然生成,这个和 Windows 一样,遵循 RFC 的规范行事。接下来配置路由器通告。
在 Linux 中,这个可以由 radvd 守护进程完成。如果有人非要抬杠说**既然路由器通告是 IPv6 自带的一部分,为何不在内核实现,而要专门由一个用户态守护进程支持,这个和 DHCP 不也一样么?**关于这点,我觉得,本来就没有什么内核态,用户态之说由于路由器通告配置比较复杂,拥有很多的参数,而内核态又不被建议被搞复杂,只能做在用户态咯,这都无所谓。如果非要抬杠,给我两天带薪休假时间,我给你做进内核去。
------
言归正传,在我们的 CentOS 上,radvd 并不需要编译源码,它比较成熟,直接 yum install 即可:
yum install radvd
然后大致看一下 manual:
RADVD (8) RADVD (8)
NAME
radvd - router advertisement daemon for IPv6
…
按照配置文件的建议,自行大约摸配置即可。或者说,你看一遍 radvd.conf 的 manual 就可以玩转了,非常之详细:
[root@localhost ~]# man radvd.conf
限于篇幅,我也不想复制粘贴,我给出一个我自己的一个配置文件,位于 /etc/radvd.conf:
interface enp0s9
{AdvSendAdvert on;MinRtrAdvInterval 30;MaxRtrAdvInterval 100; prefix 2001:dddd:1:0::/64{AdvOnLink on;AdvAutonomous on;AdvRouterAddr off;AdvValidLifetime 120; # 120 秒过期AdvPreferredLifetime 100; # 100 秒后不再建议使用};route 2006:222:666::444/128 # 推送这个主机路由{};
};
下面开始配置过程,我感觉虽然配置上看起来比 Windows 配置简单,但是并没有 Windows 的直观。
先给 enp0s9 配置一个和 radvd 通告的前缀一致的 IPv6 地址:
[root@localhost ~]# ip -6 a add dev enp0s9 2001:dddd:1:0::123/64
好了,现在开启 radvd 服务 (同时开启 tcpdump/wireshark 抓包):
[root@localhost ~]# service radvd start
Redirecting to /bin/systemctl start radvd.service
[root@localhost ~]#
OK,这时看看 Windows 主机接收得如何,show 一下 address:

完美!该有的地址都有了。再看看默认路由有没有推送下来,必须推下来了的:

对了,还有一条主机路由呢,我在 radvd.conf 里配置的那个:
2006:222:666::444/128 via $MEMeme

必须有啊!
我们看看抓包,这一切背后发生了什么?看看 Linux 的路由器通告就好了:

一切全部浮到了水面上。IPv6 的自动配置就是这么玩的。
Windows VS. Linux
这次,我竟然用 Windows 做路由器,拿 Linux 做靶子。也不奇怪,自从我第一眼看到 netsh,我就喜欢它了,它竟然什么东西都能 help 出来,这一点让我回忆起了我熟悉的 Cisco 命令行。
我经常拿 netsh 和 Linux iproute2 对对比,我一直倾向于在心理上希望 iproute2 更胜一筹,但事实上,我觉得 netsh 玩的更爽!
所以,在我演示这个 IPv6 自动配置这么重要的特性的过程中,Windows 的 netsh 让我感觉好舒服。
后记
我的感觉,IPv6 才是真正的互联互通网络协议,它真的是太方便了!真的是比 IPv4 方便多了。
即便是路由器上要手工配置的那个全局地址,那个被写在了 DNS 节点 AAAA 里面的地址,它也是有章可循的,它的 128 比特地址里通过一些比特就知道它所处的路由位置,这些就是天然聚类的收益!
不过不要指望去靠某个人手工维护这些。
这是一个寂静的雨后之夜,在早上,我发了一个朋友圈,关于一个知乎上的问题 “为什么东亚人活得这么累” 其中有一个回答,我是很赞同的,这个回答是这样的:
然后,这是我的评价:
我是同意这个地缘学解释的,这也是我的解释。
我总是拿着家里那个标注地形地貌的地球仪给疯子和小小看,“你们看,小时候老师给我们讲中国地大物博,资源丰富,其实现在看来,那是骗人的。看看美国,欧洲,中南美,大部分都是海拔很低,地形平坦,有丰富植被以及水域覆盖,而我们中国,这种地方仅限于从山东往南,经过浙江,沿海到广东一带,往西止于河南郑州,湖北武汉连线,东北资源可以处于西伯利亚和季风要冲,异常寒冷。这怎么跟欧美比。在地球仪上看,我们和非洲中南部非常类似……”
就是这么简单的道理,资源贫乏,但却令人遗憾地培育了水稻这种作物,因此便在资源匮乏地带养活了海量的人口,造成了一种现象,那就是 “不管干什么事,拿人堆就行了” 这种劳动密集型观念,而劳动密集观念其实是个 “延长劳动时间” 等价的,都是线性效应而不是指数效应。唉:-(
不用扯那些现代经济学术语装逼,再复杂的现象的本质往往道理都是最简单的。动不动就外汇储备什么,扯淡!中国古代人难道就不苦逼吗?不苦逼怎么会有 “头悬梁锥子扎屁股,吃得苦中苦成为人上人,愚公移山,精卫填海,铁杵磨针,书中自有 BMW” 这种苦逼至上价值观?!
再看看欧洲古代中世纪,落后是落后,但人少,没人干活自然要想一些在中国看来是奇技淫巧的技巧,再往前就是罗马帝国后期了,那时有大量奴隶劳动力,也是拿人堆,但苦逼的是奴隶而不是普通老百姓啊。
欧洲文明中最苦逼和中国最像的就是罗马打赢迦太基后到屋大维内战结束那一段 100 多年的时间了,到很快结束了,毕竟高卢,北非,近东环地中海这片资源太丰富了!
又能怎么样呢?我一直以来都不喜欢知乎,在知乎里面学不到知识,到处都是装逼,抬杠,编那些啰里八嗦的故事,最烦的就是分割线,傻逼一样的存在。好的答案没几个,却让读者浪费了大量的时间,标榜高大上却处处都是垃圾!
反正都是一样。
闲谈 IPv6-Anycast 以及在 Linux/Win7 系统上的 Anycast 配置
dog250 于 2019-03-02 09:18:10 发布
杭州,外面依然是寒雨夜,屋里也没开空调,我穿个夏天的短袖,旁边放一杯热茶,喝完了还有昨晚实在喝不下去的汉拿山烧酒,再喝完还有上周菜市场买的米酒… 作此文一篇。
在我们 check IPv6 的基本特征列表时,总是可以看到 IPv6 对 Anycast 的支持。说实话,对于很多人而言,这是个比较陌生的概念,对于希望看看 Anycast 到底是什么样子的人而言,甚至在网上很难搜到关于如何配置 Anycast的资源。这是比较令人遗憾的。
抛开概念,那么本文尝试从不同的角度来针对 Anycast 探究一番。
IPv4 年代的 Anycast
说起 Anycast,并不是在 IPv6 标准中突然出现的概念,一个概念怎么可能突然出现?不可能的。
早在很久很久以前,业界就针对 IPv4 提出了 Anycast 的说法,只不过相对而言,IPv6 在操作上将其标准化了而已,如果说 IPv4 年代的 Anycast 标准只是建议,那么 IPv6 的 Anycast 就是规定了些许MUST,MAY。
建议阅读:
RFC1546-Host Anycasting Service:https://tools.ietf.org/html/rfc1546
RFC3513:IPv6 Addressing Architecture:https://tools.ietf.org/html/rfc3513#section-2.6
那么,到底如何理解 Anycast?
本质上,Anycast 就是将同一个 IP 地址配置在不同的主机网卡上,然后利用各种选路机制欺骗源主机的一种通信方式。
什么?同一个 IP 地址配置在不同的主机上,这不是地址冲突了吗?我们记得在初学网络基础的时候,教程上就讲过**IP 地址不能冲突!**现在为什么 IP 冲突变成了一种通信方式了呢?真是只许州官放火,不许百姓点灯啊!
其实不然,我倒是觉得 Anycast 是内功深到一定程度,自然而然的一个想法。我们简单地从路由说起。
我们知道,IP 地址存在的目的就是为了指挥路由器选路,最终将数据包路由到目的地,那么 IP 地址冲突的结果是什么?
IP 地址冲突不是问题,路由冲突才是!!
IP 地址冲突只有导致路由器的路由冲突 (be confusing) 的时候才有问题。
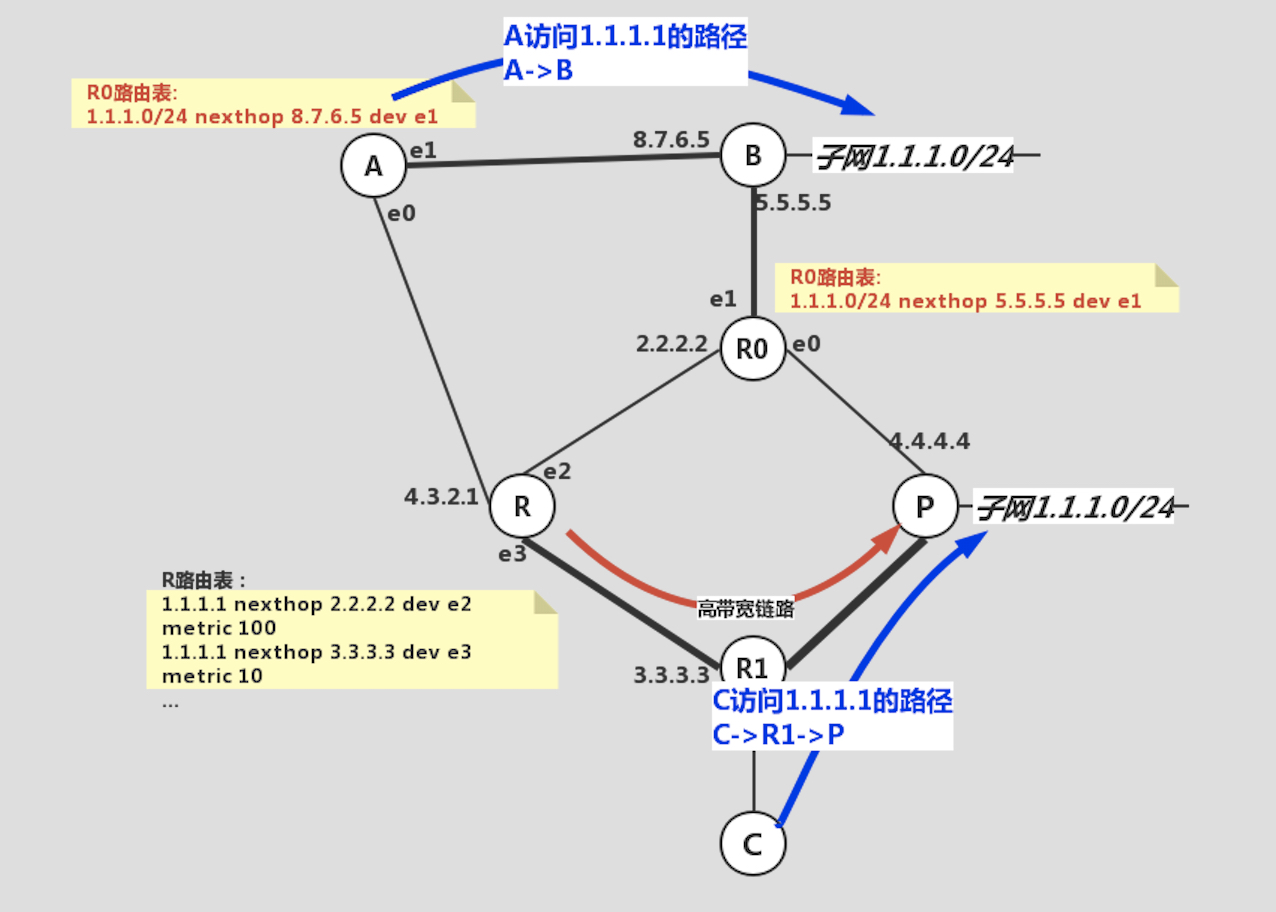
比如路由器 R 上配置的下面的两条路由:
1.1.1.1 nexthop 2.2.2.2 dev e2
1.1.1.1 nexthop 3.3.3.3 dev e3
请问一个去往目的地 1.1.1.1 的数据包到达路由器 R 之后到底是从 e2 走呢,还是从 e3 走呢?这就是问题。但是同样的路由,加一个约束就不会有问题:
1.1.1.1 nexthop 2.2.2.2 dev e2 metric 100
1.1.1.1 nexthop 3.3.3.3 dev e3 metric 10
路由器会毫不犹豫地将去往 1.1.1.1 的数据包从 e3 发出!
对于上述的两条路由,你说是 IP 地址冲突吗?不!并不是。
互联网本身就是一个互相网状连通的连通图,到达同一个目的地的路径不止一条,对于路由器 R 而言,它只管选路,逐跳转发数据包,它并不关注 1.1.1.1 这个目标地址到底在哪里。
好了,现在我们知道只要路由不冲突,就没有问题,数据包总是可以特定的路径,逐跳被转发,最终到达目的地。现在,我们看一下这条路是如何形成的,或者说路由器 R 是怎么知道到达 1.1.1.1 有两条路可走的。
由于这只是一篇散文,并不是技术文档,所以我并不想引入 BGP,AS 这些概念,姑且把全球的互联网看作是一张如下图所示的连通图:
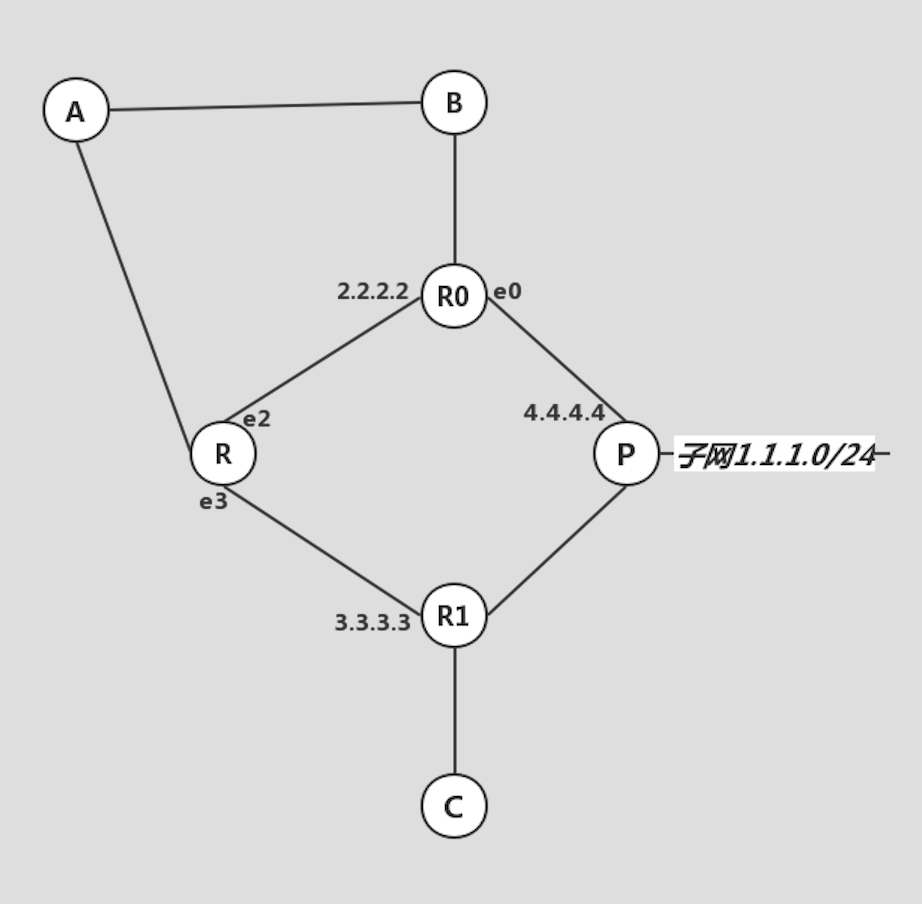
然后在这张图标识的网络开始工作时,各个节点开始彼此交换自己携带的子网信息,我们可以将其理解为路由通告。显然路由器节点 P 向上游路由器 R0 通告了子网 1.1.1.0/24,意思就是说,“嗨,R0 邻居兄弟,如果有到达 1.1.1.0/24 的包,请交给我”,同样的信息,路由器 P 也会告诉它的所有其它邻居,然后路由器 R0 回复路由器 P,放心,我知道了,我已经配置上了 1.1.1.0/24 nexthop 4.4.4.4 dev e0,并且我也已经将这个消息转给了我的所有邻居,放心,它们如果有到达你那里 1.1.1.0/24 的包,会先交给我的……
就这样,子网信息,路由信息在整张网上彼此交换,传播,最终在每一台路由器上形成了稳定的路由表:

请注意,A 会在两个接口同时收到关于 1.1.1.0/24 的通告,这并不会造成路由冲突:
-
常规路由协议以及 SPF 算法均有避环的措施;
-
有意为之的环被视为备份路由,由 Metric 做优先级取舍或者由 ECMP 管理。
如果说在这张网中有 A 和 C 需要访问 1.1.1.1,那么很显然,路径如下:
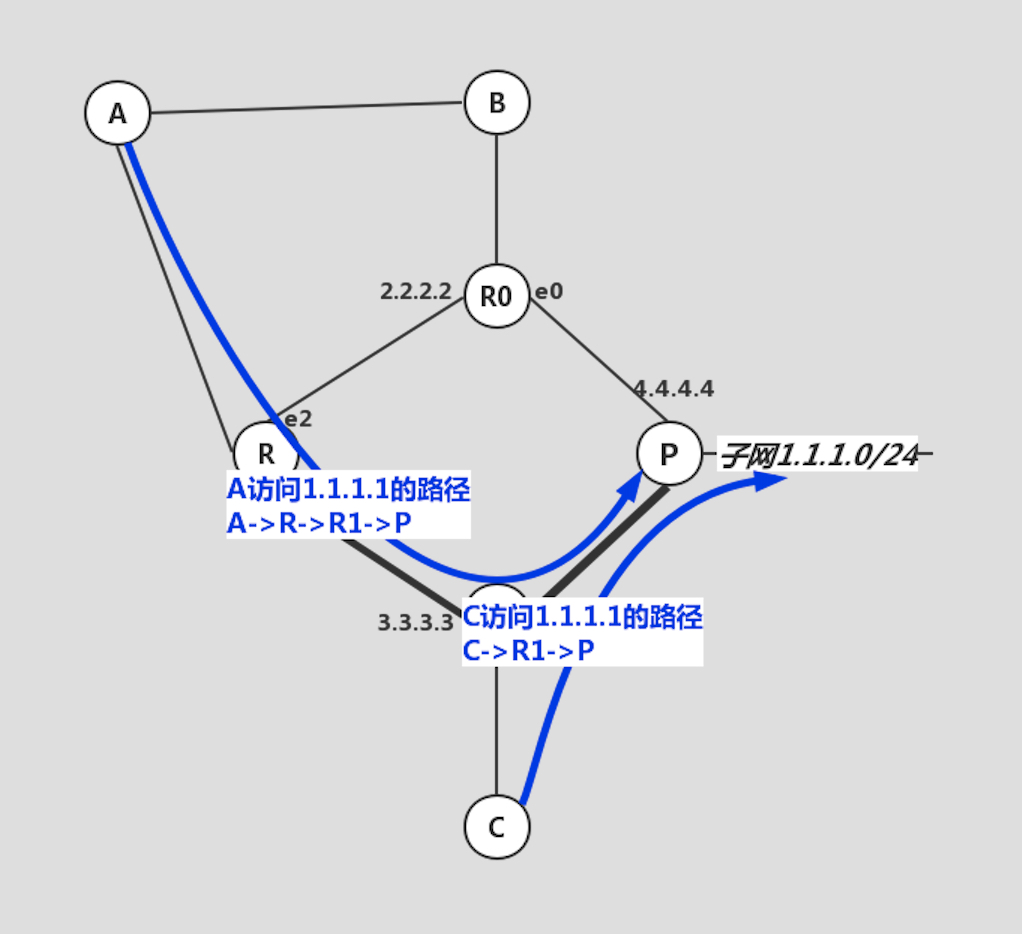
非常好,道路是通达的,但是并不完美!Why?
这会造成路由器 R1 和路由器 P 之间的链路异常拥堵,为什么 R0 不能分担一部分流量呢?
嗯,我能想到的,TCP/IP 标准化协会的那帮人难道能想不到?这就是 ECMP 的由来。再后来,干脆来个 SDN 全局统一分发好了… 但是这和 Anycast 没有半毛钱的关系,所以就此打住,我们来看看另外一种引出 Anycast 的解法。
试想,如果 B 节点也通告 1.1.1.0/24 的路由会怎样?
按照前面的路子,我们知道,B 和 P 均通告相同的路由,这会造成图上所有路由器均会收到来自 B 和 P 关于 1.1.1.0/24 的通告,按照上面的两个基本原则:
- 常规路由协议以及 SPF 算法均有避环的措施;
- 有意为之的环被视为备份路由,由 Metric 做优先级取舍或者由 ECMP 管理。
你猜怎么着?最终成了下面的样子了:
是不是很像在世界互联网上部署了一个天然的负载均衡设施啊!是的!这就是所有的IP 地址冲突导致的结果!这就是Anycast。
其精髓就是:**在路由器看来,它们并不知道不同指向的下一跳最终将数据包导向不同的目的地,它们只是认为这只是通往同一个目的地的不同路径罢了!**简单点说,Anycast 之所以得以部署和实现,就是利用了 IP 协议逐跳寻址的特性!
事实上,Anycast 的结果是,相同的 IP 地址位于不同的主机,因此,它的弊端也是显而易见的。
由于逐跳的路由收敛和端到端的五元组连接之间并没有同步,因此 Anycast 并不适合基于端到端连接的 TCP 应用。
TCP 并没有广域范围的连接迁移机制,因此如果路由重新收敛,将会导致连接断开!比如上述的例子,如果 A 到 B 之间的线路拥塞或者说断开,那么路由会重新收敛到 A-R-R1-P 这条路径,A 和 B 的 1.1.1.0/24 子网的主机之间的 TCP 连接将会断开,这并不是人们所期望的。
因此,上述描述中的 Anycast 只适合于一来一回两个包的 oneshot 式的交互通信,比如 DNS!
是的,DNS 就是这么部署的,比如我们经常使用的 Google DNS 8.8.8.8,它实际上就是 Anycast 部署在世界不同地方的多台主机,地址全部都是 8.8.8.8!
请使劲阅读:https://developers.google.com/speed/public-dns/faq
然后去深撸这个站点,溯源:https://bgp.he.net
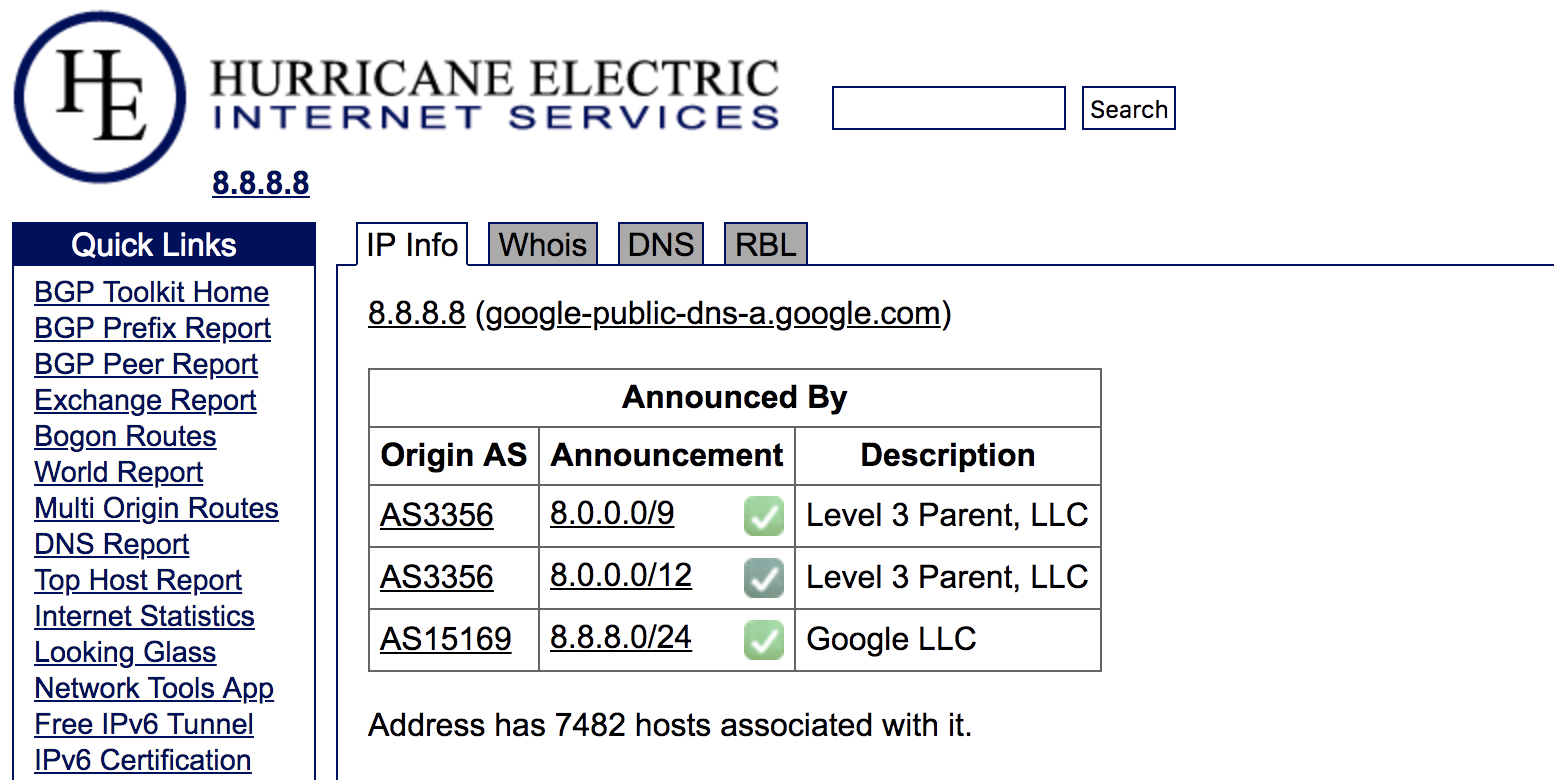
至此,我觉得关于 Anycast 的概念,已经大致陈述清楚了。
下面是 IPv6 的世界。我们跟踪问题本身以及其解法,跟着 RFC 来梳理 IPv6 Anycast 的来龙去脉,其实一切都很清晰。
IPv6 的 Anycast
重看 Anycast 在 IPv4 上的问题,我们知道,**把同一个 IP 地址配置在不同的主机上,这确实是不妥的,比如占据互联网流量头把交椅的 TCP 应用就不适合,**既然无法让主子心安理得的承认,那索性在 Anycast 标准化中就不要这么做就是了。
但是,只要 Anycast 不是部署在端节点,而是部署在路径节点,比如路由器上,那就是妥妥的。逐跳寻址原则最终导致 Anycast 部署在路由器上之后,会自然而然地实现 ECMP,即多条路径分担同样的端到端通信。
在继续下去之前,这里先说一个观点。那就是端到端通信多路分担这种机制对 TCP 是不好的!
又 TMD 的是 TCP,是的,这里,我觉得这不是逐跳寻址的问题,这根本就是 TCP 的缺陷!缺陷!缺陷!
TCP 要求在协议层面而不是应用层面按序到达,这就要求所有的字节最好是一路上顺序地排队前进,而多路径会影响顺序同步性,导致乱序。TCP 的字节按序到达这个约束会恶化流量高峰期的链路拥塞。
由此而得到的另一个 Trick 就是 Flowlet!它大大增加了端到端拥塞控制的复杂度。
然而我们看看 QUIC,它就并没有要求严格的字节按序到达,而是基于窗口的按序到达,这就使得 QUIC 可以大大利用多路径分担带来的收益。其实对于 TCP 而言,不光是链路最好不要多路径,甚至在路由器,交换机这种中间节点,多 CPU,多处理卡也不能负载均衡分担同一条 TCP 流的不同数据包!
有了 TCP,几乎所有的负载均衡都得按照流的粒度进行。
TCP 真是太恶心了!
好了,我们先不管 TCP 了,任它腐烂!
IPv6 对 Anycast 进行了标准化,首先在 RFC3513 中,它对 Anycast 提出了两点约束:
oAn anycast address must not be used as the source address of an
IPv6 packet.oAn anycast address must not be assigned to an IPv6 host, that is,
it may be assigned to an IPv6 router only.
有了这两点约束,我们可以知道:在 IPv6 中,Anycast 不是用来通信的,而是用来寻址的。
紧接着,RFC3513 要求所有的路由器的所有接口都必须配置一个必选的 Anycast 地址:
2.6.1 Required Anycast Address
The Subnet-Router anycast address is predefined. Its format is as
follows:| n bits | 128-n bits |
±-----------------------------------------------±---------------+
| subnet prefix | 00000000000000 |
±-----------------------------------------------±---------------+
The “subnet prefix” in an anycast address is the prefix which
identifies a specific link. This anycast address is syntactically
the same as a unicast address for an interface on the link with the
interface identifier set to zero.Packets sent to the Subnet-Router anycast address will be delivered
to one router on the subnet. All routers are required to support the
Subnet-Router anycast addresses for the subnets to which they have
interfaces.
比方说,路由 R 有两个接口,分别配置了两个 IP 地址:
e0: 240e:909:2001::4e3/64
e1: 240e:101:4004::111/64那么根据 RFC 的要求,这个路由器上将会生成下面的 Anycast 地址:
e0 Anycast: 240e:909:2001::/64
e1 Anycast: 240e:101:4004::/642为了使得这些 Anycast 能被访问到,需要添加两条本地主机路由:
Local 240e:909:2001::/128 dev loopback
Local 240e:101:4004::/128 dev loopback这里需要解释一点,刚才不是说 IPv6 的 Anycast 不是用来通信的吗?那为什么还要被访问呢?
因为需要邻居解析 (IPv6 Ndp)。如果有谁把这个地址设置为下一跳了,那么需要解析这个地址,这就是被访问!
纳尼?Anycast 作为下一跳?
是的,这就是 IPv6 Anycast 的核心用法,它不是用来标识主机服务让你的应用程序通信,它是用来寻址的:
-
Anycast 地址被设置为下一跳
-
Anycast 地址被设置进 IPv6 路由扩展头以支持源路由
来吧,我们还是举例子的好。
我的局域网为了备份,希望部署两台或者多台路由器做热备,姑且就先两台:
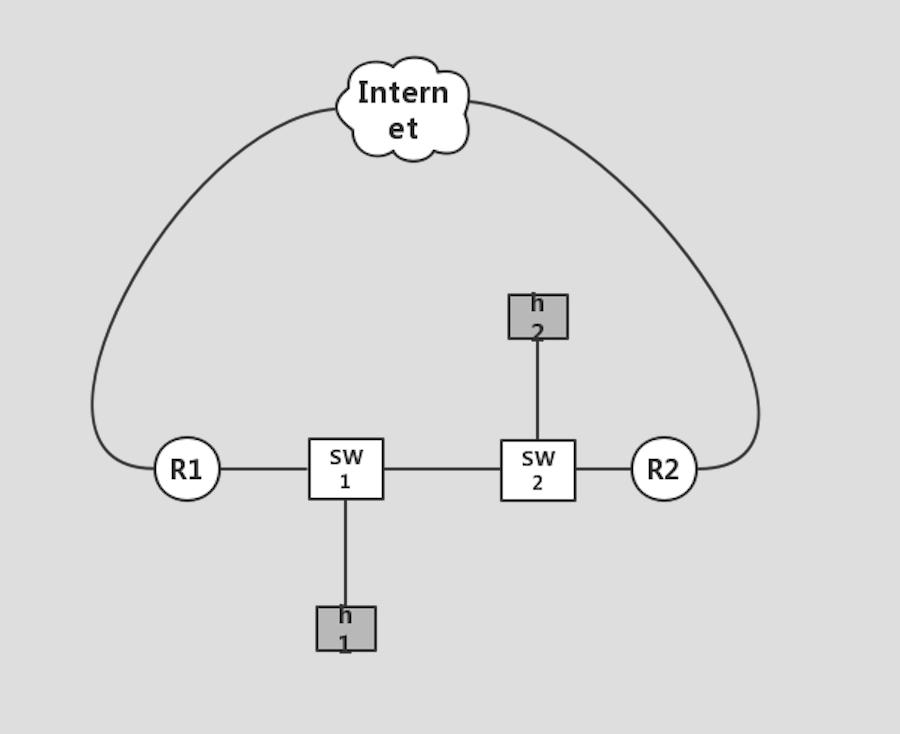
假设两台路由器都能接外网,如果跑 IPv4 协议,那么自然而然的想法就是安装 keepalived 跑 VRRP,这种成熟的东西,想必都可以瞬间完成配置。
但是,我们知道,这两台路由器只有一台是工作状态,另外一台处于 backup standby,是不是感觉浪费了资源?如果你想让它们一起工作,那就要:
1.为它们配置不同的 IP 地址,gw1,gw2;
2.内部局域网一半一半分别配置两个不同的 gateway,即 gw1,gw2。
万万不能配置成相同的 IPv4 地址的,因为这种地址冲突会导致交换机的转发表以及 ARP 表的混乱。当然,对于我个人而言,我是有办法将其配置成相同的 IP 地址又不会 confuse 各种表的,但是,配置太复杂了 (涉及 iptables,ebtables,arptables,arp,iproute2,STP 等等)。正如 IPv4 的 Anycast 一样,没有什么是 IPv4 配置不出来的,只是这些大部分都是奇技淫巧般的 Trick!玩物丧志!
我们看一下用 IPv6 会怎样。
不用干别的,如果路由器的实现遵循 RFC 标准,那么你只需要配置两台路由器不同的同网段地址即可,如下:
路由器 1 e0: 240e:110:1001::fbb2:0a1e:0e59:15eb/64 [低 64bit 为 EUI-64 映射而来]
路由器 2 e0: 240e:110:1001::eb7c:b2da:7088:3c38/64 [低 64bit 为 EUI-64 映射而来]
然后所有主机的默认网关设置成其 Anycast 地址即可:
::/0 nexthop 240e:110:1001::
就这么简单!Why?
因为路由器 1 和路由器 2 在配置好内网 e0 的地址后,根据 RFC3513,它们会自动生成 Anycast 地址以及 Anycast 地址的主机路由以被内网主机邻居解析。
RFC 要求各层寻址 Anycast 地址时以本层次的路由距离来度量,那么对于二层链路,其距离默认就是物理距离,光速不变,距离等效于时间,因此会等效为谁先回复我的邻居请求,谁就是我要寻址的 Anycast 节点!
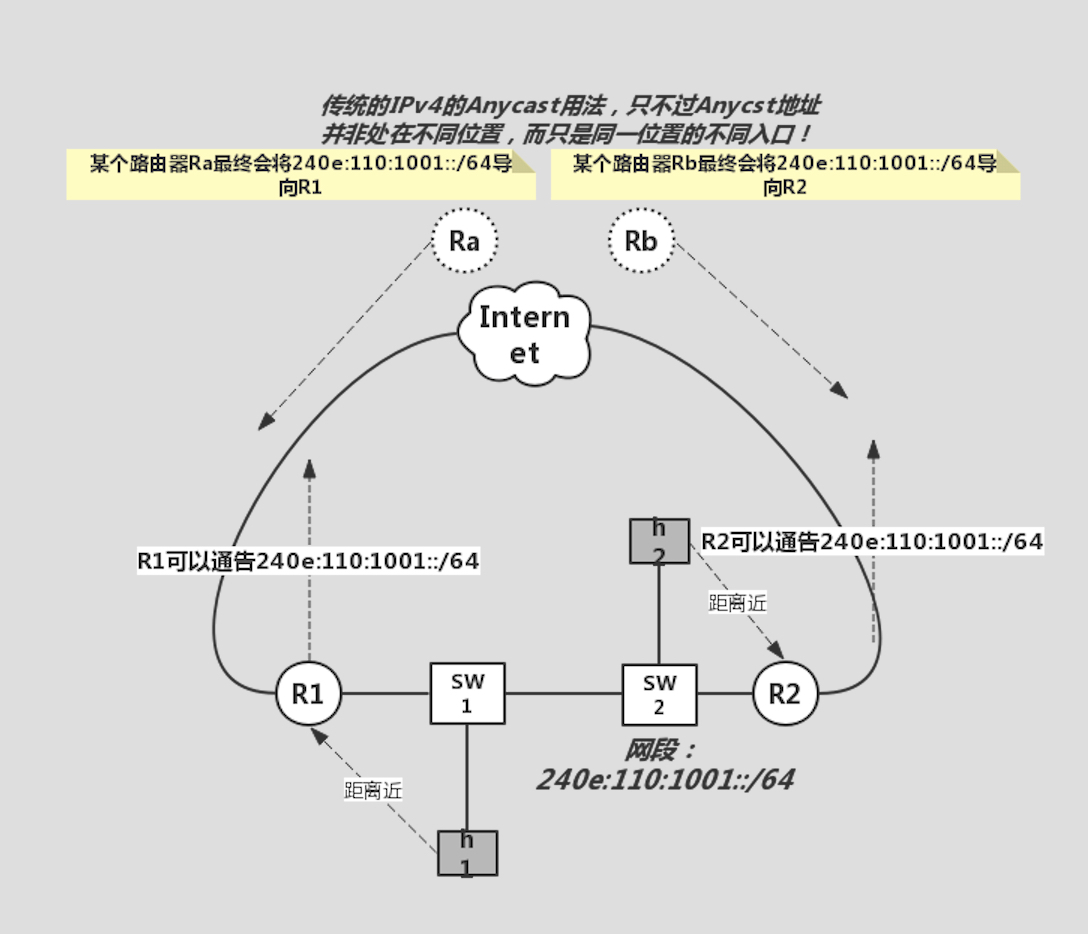
是不是天然的负载均衡了呢?炫酷!
现在有个不可回避的问题需要解决,那就是访问互联网服务的正向包和返回包路径不对称问题。
比如,h1 主机访问服务器 S 走的 R1 作为默认网关,然而 S 返回 h1 时,却从 R2 返回,此时 R2 解析 h1 的地址,h1 收到 R2 的解析请求后,会不会更新自己关于 Anycast 邻居的信息呢?如果是的话,那势必会造成邻居表信息的剧烈抖动啊!
答案是**并不会!**Why?
因为 IPv6 在解析邻居时,ICMPv6 协议头里会写清楚下面的信息:
-
自己是不是路由器
-
邻居信息需不需要覆盖
这一点和 IPv4 的 ARP 不同,ARP 是双向更新的,在回复自己的 MAC 地址时,同时也更新了自己的 ARP 表,但在 IPv6 中,两者分开了:
-
请求你的 MAC 信息
-
请更新你自己的邻居信息
R2 发送给 h1 的邻居请求,只是请求 h1 的 MAC 地址而已,并没有说要 h1 更新其邻居信息,所以万事大吉:
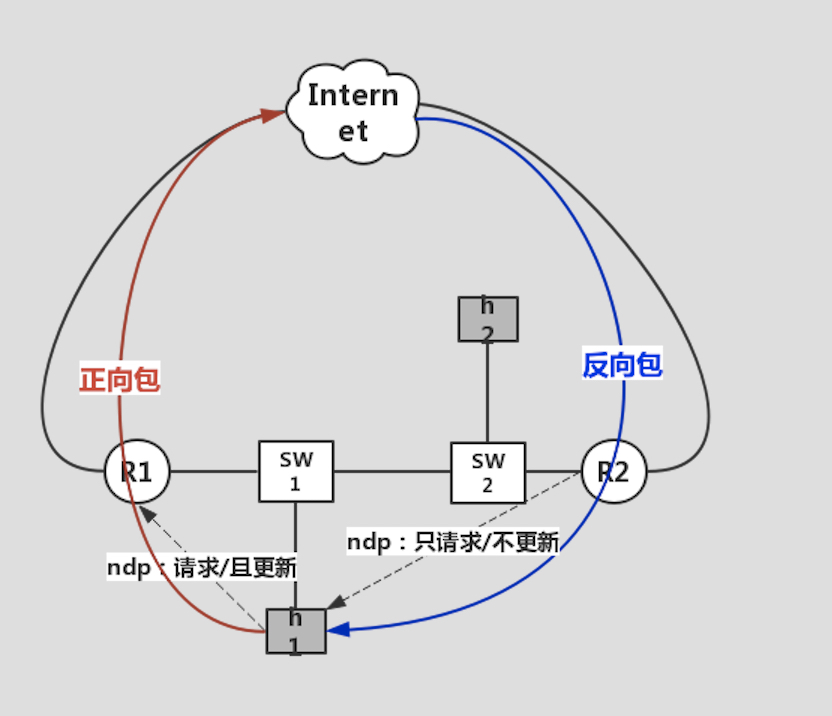
配置和实现
现在该看看实现了。
很少有资料讲如何在 Linux 上配置 IPv6 的 Anycast的,这一次可能我又占了坑。
其实很简单,只要开启 IPv6 的转发即可:
sysctl -w net.ipv6.conf.all.forwarding=1这个时候,你就会在 /proc/net/anycast6 看到内容:
[root@localhost src]# cat /proc/net/anycast6
3 enp0s8 fe800000000000000000000000000000 1
4 enp0s9 fe800000000000000000000000000000 1
4 enp0s9 240e0918800300000000000000000000 1
我在 enp0s9 上配置了如下的 IPv6 地址:
[root@localhost src]# ip -6 addr ls dev enp0s9
4: enp0s9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qlen 1000inet6 240e:918:8003::3f5/64 scope globalvalid_lft forever preferred_lft foreverinet6 fe80::eb7c:b2da:7088:3c38/64 scope link noprefixroutevalid_lft forever preferred_lft forever
所以说,什么都不用干,Linux 内核自动帮我生成了其对应的 Anycast 地址,对应 RFC3513 的 2.6.1 Required Anycast Address 格式:240e:918:8003::
按照上面一个小节最后的例子,我们知道,这个 240e:918:8003:: 是可以被邻居发现而解析的,而我们知道,IPv6 的邻居发现使用的是组播地址,其组播构成规则详见:
RFC3513-2.7 Multicast Addresses: https://tools.ietf.org/html/rfc3513#section-2.7
对应组播地址:
FF02::1:FF00:0000/104 Solicited-Node Address [RFC3513] -RFC4291 对其进行了增强更新
Solicited-Node Address:
FF02:0:0:0:0:1:FFXX:XXXX
Solicited-node multicast address are computed as a function of a node’s unicast and anycast addresses. A solicited-node multicast address is formed by taking the low-order 24 bits of an address (unicast or anycast) and appending those bits to the prefixFF02:0:0:0:0:1:FF00::/104resulting in a multicast address in the range
FF02:0:0:0:0:1:FF00:0000
to
FF02:0:0:0:0:1:FFFF:FFFF
请求节点多播地址作为节点的单播地址和任意播地址的函数来计算。请求节点组播地址是通过获取地址(单播或任意播)的低序 24
位并将这些位附加到前缀‘ FF02:0:0:0:0:1:FF00::/104 ’形成的,从而在该范围内生成组播地址
我们针对 Linux 的如上配置确认一下:
[root@localhost src]# cat /proc/net/igmp6
1 lo ff020000000000000000000000000001 1 0000000C 0
1 lo ff010000000000000000000000000001 1 00000008 0
...
# 下面这个便是!
4 enp0s9 ff0200000000000000000001ff000000 2 00000004 0
...
将 Anycast 地址作为默认网关发送数据,最终邻居解析的时候,只要发送到组播地址 ff02::1:FF00:: 就可以解析出该网段上的 Anycast 地址的 MAC 地址信息,然后取第一个到达的作为邻居即可!
上面关于组播的设置,请看 addrconf_join_anycast 函数:
static void addrconf_join_anycast (struct inet6_ifaddr*ifp)
{struct in6_addr addr;if (ifp->prefix_len >= 127) /* RFC 6164*/return;ipv6_addr_prefix (&addr, &ifp->addr, ifp->prefix_len);if (ipv6_addr_any (&addr))return;ipv6_dev_ac_inc (ifp->idev->dev, &addr);
}
其中,ipv6_dev_ac_inc 值得观摩!
配置也配好了,那么我们找两台机器练一练手。
这次我部署的另外一个机器是 Windows 7 系统,顺便玩一下 netsh。这台 Win7 系统机器和我们的 Linux Rh7.2 直连,拓扑我就不画了,非常简单。我只是把 Win7 上的地址配置发布出来。
很简单,Win7 上配置一个 240e:918:8003::/64 同网段的 IPv6 地址:
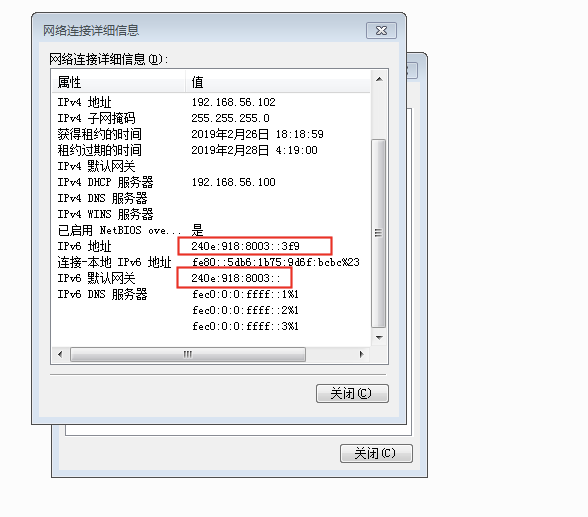
这个时候,将 Win7 的默认网关设置成 240e:918:8003:: 这个 Linux 上使能的 Anycast 地址,看看如何通信。
按照惯例,ping 一下这个 240e:918:8003:: 地址:

不通!
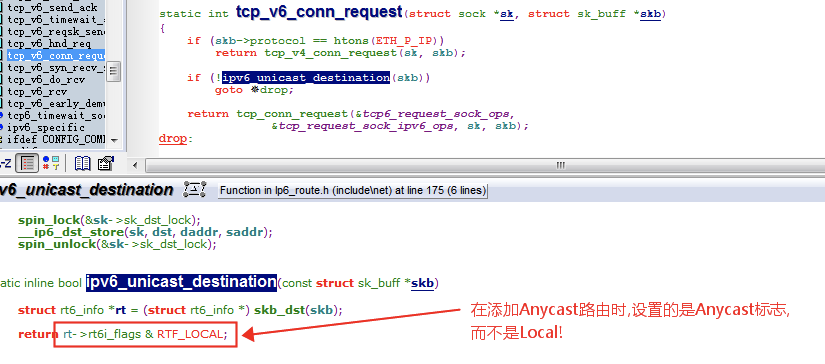
在 Linux 上抓包,发现是有回复 ICMPv6 Echo Reply 的,只是说回复的源 IP 地址不是 Win7 期望的 Anycast 地址,而是 Linux 上 enp0s9 网卡的地址,这正是印证了**An anycast address must not be used as the source address of an IPv6 packet.**这句话!
我很好奇 Linux 内核是怎么做到不让 Anycast 地址作为源地址的,ping 不行,TCP 的 Telnet 也不行… 其实看一下代码就完全明白了。
先看下 Telnet 为什么完全就没有 SYN-ACK 回复:
再看看为什么 ping 回复的时候用的不是 Anycast 地址,而是选择了网卡上配置的地址:
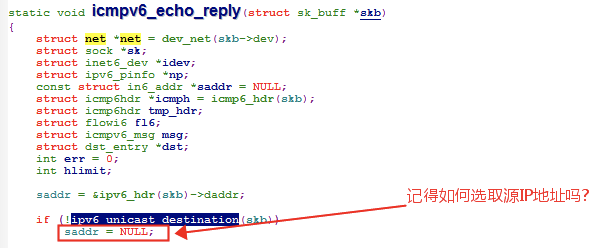
这个关于源地址选择的细节,详见 RFC3484 以及我的前一篇闲谈:
-
Default Address Selection for Internet Protocol version 6 (IPv6)
https://www.ietf.org/rfc/rfc3484.txt -
闲谈 IPv6 - 源 IP 地址的选择 (RFC3484 读后感)
https://blog.csdn.net/dog250/article/details/87815123
脉络理清了之后,我们来反一下,让 Win7 主机配置 Anycast。
我特意没有按照 RFC 的规定,去配置了一个非标准的 Required Anycast Address,且看:

配置方法如下:

我并没有让低 n-bit 为全 0,竟然成功了,这说明 Win7 并没有严格按照 RFC 的规范行事,它完全是手动的。
那么好,我在 Linux 上去 ping 这个 Win7 的 Anycast 地址:
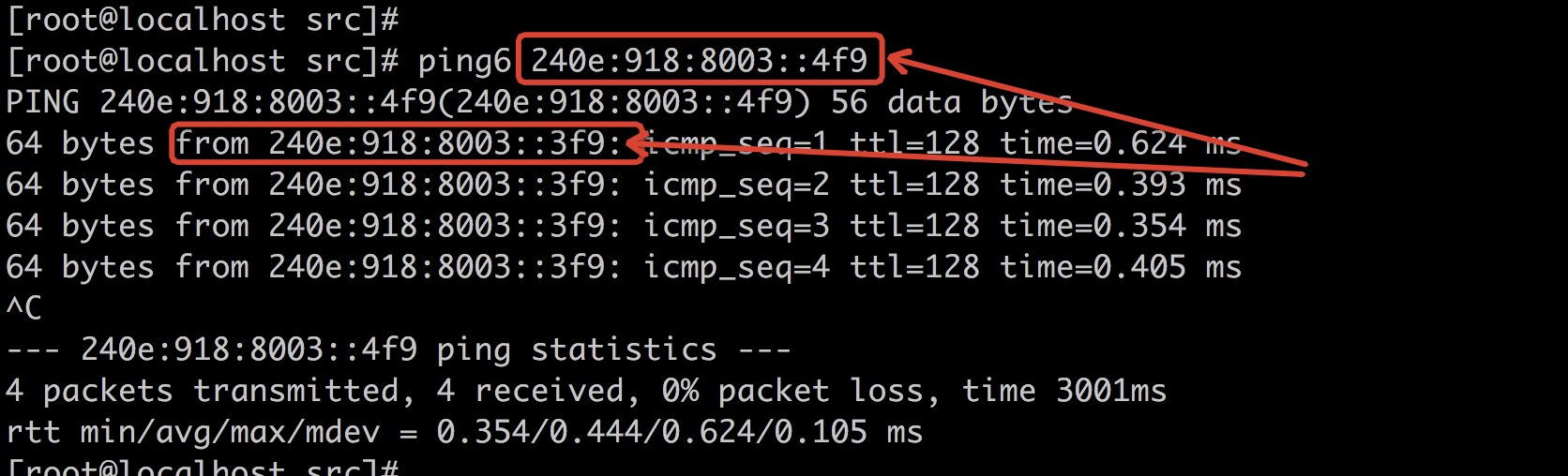
得到了 Win7 的回复,然而源地址不是 Win7 的 Anycast 地址,却是 Win7 的物理网卡本地连接 3上配置的 IPv6 地址。这依然印证了 An anycast address must not be used as the source address of an IPv6 packet. 这句话。
只是说,Win7 对 Anycast 地址并没有严格遵循 subnet 后面的低 bits 均为 0 的约束,即 Win7 没有实现严格的 Required Anycast Address!
不管怎么样,痛则不通,通则不痛,后面也没啥可玩的了。
总结
IPv6 的 Anycast:
-
以往 IPv4 的规则在 IPv6 RFC 约束下依然适用
-
独添了 subnet-Anycast,见上文
因此我们可以将 Anycast 总结为:
-
广义的 Global Anycast - 作用于 IPv4/IPv6
-
狭义的 IPv6 subnet Anycast - 作用于 IPv6
此外,RFC2526 又规定了保留的 Anycast 地址用于不同的目的:
- RFC2526-Reserved IPv6 Subnet Anycast Addresses:
https://tools.ietf.org/html/rfc2526
本文不涉及 RFC2526 的内容,但是提醒注意,仅此而已。
阅读笔记
为了写这篇文章,我深夜快速浏览了 RFC 标准,因为我要在这些个标准之上才能胡扯形而上。
这两个截图体现了 IPv6 Anycast 的作用,它到底用在哪?我想我在上文呢,已经阐述清楚了。


后记
为 Anycast 添加一条 host 路由,让 anycast 地址可以被设置成网关。
闲谈 IPv6-IPv6 地址聚类分配原则与源地址选择的关系
dog250 于 2019-03-09 08:29:56 发布
我一向喜欢对比两类相似的东西或者同类的两个版本,然后褒一个贬另一个,我不太喜欢中庸,也不太善于一分为二看问题,近期在做 IPv6 相关的事情,所以自然要和 IPv4 做对比,那么,哪怕一个细节上,我都忍不住要吐槽 IPv4,但这并不意味着 IPv4 真的就那么挫,这只是我的特色而已。
------
还是以一个实际例子入手,先吐槽一顿 IPv4,然后再说说 IPv6 怎么怎么好。
看以下的拓扑,一个有钱的用户从三大运营商同时接入互联网:

他要么是为了备份线路,要么是为了负载均衡,要么是为了实现访问联通的服务走联通的线路,访问电信的服务走电信的线路… 无所谓,不管怎样,显然,它获得了三个 IP 地址。
此时它发起一个连接,想访问一个服务器,请问:
该连接的源 IP 地址如何选择?是 ip1,ip2 还是 ip3?*
无疑,这个服务器的 IP 地址肯定是接入三大运营商之一的,DNS 会用发起请求的用户 IP 来给用户返回相同运营商的 IP 地址,答案似乎很简单,用相同运营商的呗。
是的,这是正确答案,走同运营商的线路可以避免冷土豆跨运营商转交,服务质量更能得到保证,走同运营商当然要用同运营商地址。
这一切都是在路由选择算法中完成的, 源地址选择和下一跳属于同一网段的地址!*
我们只要知道了路由,就能决定选择哪个地址作为源 IP 地址。至于路由嘛,肯定是事先已经配置好的咯。或者说,随便用一个 IP 作为源地址,然后请求 DNS 解析域名,DNS 返回的一般都是同运营商的目标地址,然后就用请求 DNS 解析时的 IP 作为源就得了。
所以,这件事并不难。
------
但是,路由和 DNS 是可信任的吗?路由配置就一定稳定可靠吗?如果说这个用户配置了三条等价的默认路由,怎么办呢?
# 联通默认路由
0.0.0.0/0 via $cnc metric 100
# 电信默认路由
0.0.0.0/0 via $tel metric 100
# 移动默认路由
0.0.0.0/0 via $mob metric 100
很多人都这么玩,最终所有上行流量都从 cnc 出去 (取决于实现,要么是第一个配置的,要么是最后配置的),下行流量分布在三条线路,于是就造成了好多跨运营商传输。
你可能会说,可以配置 Policy Routing 啊,但是,哥,天下那么多服务器地址,你事先怎么知道哪些地址是联通的,哪些地址是电信的…
只要在你发起一条连接的第一个数据包时没有猜对下一跳,就意味着源地址会选错,源地址如果选择了不同运营商的,那么冷土豆转交将会伴随连接的整个生命周期。 所以说,路由一定要选对!
这又是一个先有鸡还是先有蛋的问题,好在我们能拿到一个条目非常全的地址库,或者 DNS 也能告诉我们这样一个东西,我们剩余的工作就是发挥愚公移山精卫填海铁杵磨成针的精神,去配置!
无论如何,这个事情对外部机制的依赖太多了,就选择一个源 IP 地址而已,却牵扯到了路由,DNS,Policy Routing…
等等!我最近就碰到配置上万条策略路由的!任何困难都难不倒勤劳的人民。
有没有更简单或者更复杂的方法呢?绝对有!我非常擅长解决这种问题。我用 Policy Routing,IP Mark,conntrack 就可以配置出这种效果,但是我在本文不说,反正非常复杂繁琐且易出错,说白了就是 Trick。这种东西我能说一个礼拜,不然怎么能说自己靠着 iptables,iproute2 这些打通了内核协议栈任督二脉呢…
IPv6 登场,事情起了变化,一切变得不一样!
------
先来看看 IPv6 地址的分配原则。
首先,IPv6 的分配要遵循一个类似身份证的分层的原则:

这就使得所有的提供商在自己所辖的辖区内的路由都是可聚合的!IPv6 地址提供商的层级结构和 IPv6 地址空间本身的层级结构完全一致!
分配机构一般会给一个高级别的运营商一个前缀比较短的整个网段,可以容纳百万级的子网,对于外部而言,这么大个运营商网络,可以从一条通告聚合路由抵达,该大运营商在其次级运营商那里分配地址也是同样的原则。
我这里定义一个 “提供商距离” 的概念。全世界所有的提供商形成一个树形结构,所谓的提供商距离就是两个 IPv6 地址的直接提供商在这棵树纵向上的距离。
请阅读:
RFC3177:https://tools.ietf.org/html/rfc3177
RFC6177:https://tools.ietf.org/html/rfc6177
------
对于 “提供商距离” 不用说太多,一个例子足矣。
如果自己有一个 IPv6 地址,随便给定另一个 IPv6 地址,我们算一下它们共享前缀的长度,就能知道它们共享到几级提供商。比如给定一个地址240e:8880:4448:1300::222/64,问下面 3 个地址谁跟它的 **提供商距离 **最近:
a1=240e:8880:4448:1334::123/64*
a2=240e:8870:4448:1334::123/64*
a3=240e:8880:4448:1000::123/64*
非常简单,直接最长前缀匹配就好了嘛!
看着一个地址,就能算出在 IPv6 地址空间,它离我的 IPv6 地址有多亲近。
所以,RFC3484 里面的源 IP 地址选择策略中,有个 Rule 8:
Rule 8: Use longest matching prefix.*
【为啥是 Rule 8 而不是优先级更高呢?仔细想想!】
If CommonPrefixLen (SA, D) > CommonPrefixLen (SB, D), then prefer SA.
Similarly, if CommonPrefixLen (SB, D) > CommonPrefixLen (SA, D), then prefer SB.
IPv6 的源地址选择,不再像 IPv4 一样以下一跳为基准执行最长前缀匹配,而是直接以目标地址为基准执行最长前缀匹配!因此,IPv6 的源地址选择不再依赖路由!
------
我们看看,对于 IPv6 地址的使用者而言,这个分配原则意味着什么。
这意味着,如果你搬了家,或者你的公司搬了家,你大概率不能继续使用原来的 IPv6 地址了,甚至你必须更改服务提供商,除非你搬到了同一个被分配了相同 64 位前缀网段的地理范围内。
如果在 IPv4 的世界,更换一个家庭或者企业的外部 IP 地址并不是什么问题,因为 NAT 遍地都是,没人会为内网每一个主机都分配一个公共地址,也没人有这个财力… 但是在 IPv6 世界,NAT 不再被建议使用,甚至强烈建议不使用,那么这就意味着,内网有多少设备,就要改多少设备的 IP 地址!
天啊,这是一场灾难!在这一点上,IPv4+NAT 完胜!
幸运的是,IPv6 分层聚合 + IPv6 自动配置 (更多的是指无状态自动配置,缩写为 SLAAC) 可以完美胜任这一艰巨的任务!顺着一溜下去,你几乎不用动手,事情就完了!
…
------
之所以 IPv4 会有本文一开始陈述的那个问题,就是因为 IPv4 分配机制的无规则且混乱。
你搬家甚至可以带着你的 IPv4 地址一起搬,你交点服务费,运营商为你添加一条路由即可。理论上讲,如果每个人都这么玩,核心路由表项将会有数亿条。如果我们假设 D 类,E 类地址也能参与分配,且没有私有地址,那么将会有 43 亿条的路由表项充斥各大路由器!
我来写一个程序,看看在常规的现代计算机上仅仅遍历 43 亿次执行递增操作需要多久:
#include <stdio.h>
#include <stdlib.h>
int main()
{unsigned int i = 0;for(i = 0; i < 0xffffffff; i++){//i++;}printf("%0x\n", i);
}
看一下执行时间:
[root@localhost NetworkManager]# time ./a.out
ffffffff
real 0m6.644s
user 0m6.637s
sys 0m0.007s
如果换成数亿次的路由表项匹配,呵呵。
IPv4 的问题在于它过于灵活,过于灵活在业务无关的底层并不是什么好事。地址随意飘,加路由即可,地址随便分配,不考虑聚合,以为算法总是可以解决效率问题,这便是问题。
IPv6 靠强制措施,硬性规定了很多条条框框,从地址分配时就考虑路由表的聚合问题。
Linux 实现的 ARP 缓存老化时间原理解析
dog250! 于 2012-02-11 22:00:09 发布
一. 问题
众所周知,ARP 是一个链路层的地址解析协议,它以 IP 地址为键值,查询保有该 IP 地址主机的 MAC 地址。协议的详情就不详述了,你可以看 RFC,也可以看教科书。这里写这么一篇文章,主要是为了做一点记录,同时也为同学们提供一点思路。具体呢,我遇到过两个问题:
-
使用 keepalived 进行热备份的系统需要一个虚拟的 IP 地址,然而该虚拟 IP 地址到底属于哪台机器是根据热备群的主备来决定的,因此主机器在获得该虚拟 IP 的时候,必须要广播一个免费的 arp,起初人们认为这没有必要,理由是不这么做,热备群也工作的很好,然而事实证明,这是必须的;
-
ARP 缓存表项都有一个老化时间,然而在 linux 系统中却没有给出具体如何来设置这个老化时间。那么到底怎么设置这个老化时间呢?
二. 解答问题前的说明
ARP 协议的规范只是阐述了地址解析的细节,然而并没有规定协议栈的实现如何去维护 ARP 缓存。ARP 缓存需要有一个到期时间,这是必要的,因为 ARP 缓存并不维护映射的状态,也不进行认证,因此协议本身不能保证这种映射永远都是正确的,它只能保证该映射在得到 arp 应答之后的一定时间内是有效的。这也给了 ARP 欺骗以可乘之机,不过本文不讨论这种欺骗。
像 Cisco 或者基于 VRP 的华为设备都有明确的配置来配置 arp 缓存的到期时间,然而 Linux 系统中却没有这样的配置,起码可以说没有这样的直接配置。Linux 用户都知道如果需要配置什么系统行为,那么使用 sysctl 工具配置 procfs 下的 sys 接口是一个方法,然而当我们 google 了好久,终于发现关于 ARP 的配置处在 /proc/sys/net/ipv4/neigh/ethX 的时候,我们最终又迷茫于该目录下的 N 多文件,即使去查询 Linux 内核的 Documents 也不能清晰的明了这些文件的具体含义。对于 Linux 这样的成熟系统,一定有办法来配置 ARP 缓存的到期时间,但是具体到操作上,到底怎么配置呢?这还得从 Linux 实现的 ARP 状态机说起。
如果你看过《Understading Linux Networking Internals》并且真的做到深入理解,那么本文讲的基本就是废话,但是很多人是没有看过那本书的,因此本文的内容还是有一定价值的。
Linux 协议栈实现为 ARP 缓存维护了一个状态机,在理解具体的行为之前,先看一下下面的图 (该图基于
《Understading Linux Networking Internals》里面的图 26-13 修改,在第二十六章):
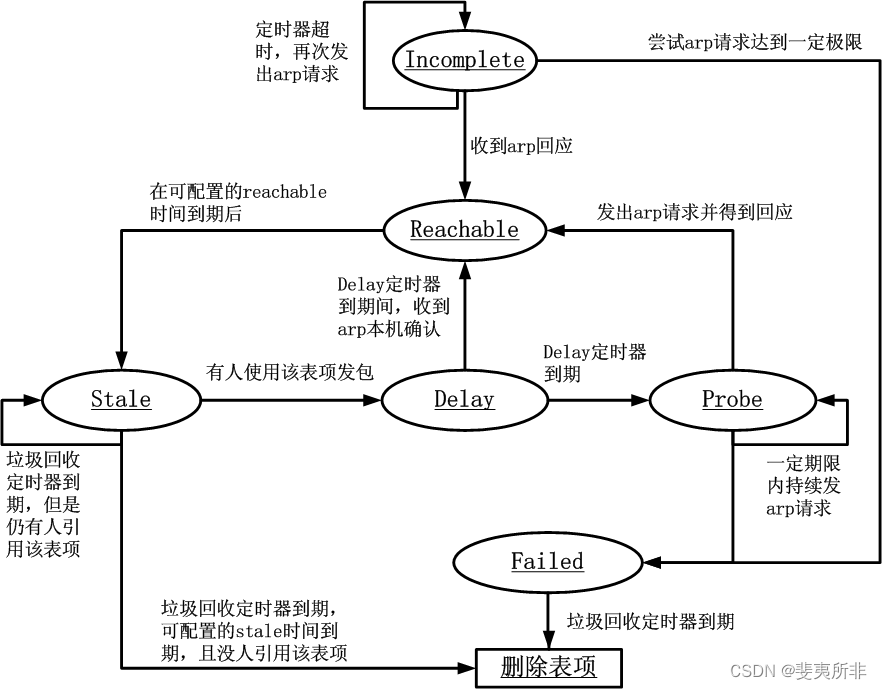
在上图中,我们看到只有 arp 缓存项的 reachable 状态对于外发包是可用的,对于 stale 状态的 arp 缓存项而言,它实际上是不可用的。如果此时有人要发包,那么需要进行重新解析,对于常规的理解,重新解析意味着要重新发送 arp 请求,然后事实上却不一定这样,因为 Linux 为 arp 增加了一个 “事件点” 来 “不用发送 arp 请求” 而对 arp 协议生成的缓存维护的优化措施,事实上,这种措施十分有效。这就是 arp 的 “确认” 机制,也就是说,如果说从一个邻居主动发来一个数据包到本机,那么就可以确认该包的 “上一跳” 这个邻居是有效的,然而为何只有到达本机的包才能确认 “上一跳” 这个邻居的有效性呢?因为 Linux 并不想为 IP 层的处理增加负担,也即不想改变 IP 层的原始语义。
Linux 维护一个 stale 状态其实就是为了保留一个 neighbour 结构体,在其状态改变时只是个别字段得到修改或者填充。如果按照简单的实现,只保存一个 reachable 状态即可,其到期则删除 arp 缓存表项。Linux 的做法只是做了很多的优化,但是如果你为这些优化而绞尽脑汁,那就悲剧了…
三. Linux 如何来维护这个 stale 状态
在 Linux 实现的 ARP 状态机中,最复杂的就是 stale 状态了,在此状态中的 arp 缓存表项面临着生死抉择,抉择者就是本地发出的包,如果本地发出的包使用了这个 stale 状态的 arp 缓存表项,那么就将状态机推进到 delay 状态,如果在 “垃圾收集” 定时器到期后还没有人使用该邻居,那么就有可能删除这个表项了,到底删除吗?
这样看看有木有其它路径使用它,关键是看路由缓存,路由缓存虽然是一个第三层的概念,然而却保留了该路由的下一条的 ARP 缓存表项,这个意义上,Linux 的路由缓存实则一个转发表而不是一个路由表。
如果有外发包使用了这个表项,那么该表项的 ARP 状态机将进入 delay 状态,在 delay 状态中,只要有 “本地” 确认的到来 (本地接收包的上一跳来自该邻居),linux 还是不会发送 ARP 请求的,但是如果一直都没有本地确认,那么 Linux 就将发送真正的 ARP 请求了,进入 probe 状态。
因此可以看到,从 stale 状态开始,所有的状态只是为一种优化措施而存在的,stale 状态的 ARP 缓存表项就是一个缓存的缓存,如果 Linux 只是将过期的 reachable 状态的 arp 缓存表项删除,语义是一样的,但是实现看起来以及理解起来会简单得多!
再次强调,reachable 过期进入 stale 状态而不是直接删除,是为了保留 neighbour 结构体,优化内存以及 CPU 利用,实际上进入 stale 状态的 arp 缓存表项时不可用的,要想使其可用,要么在 delay 状态定时器到期前本地给予了确认,比如 tcp 收到了一个包,要么 delay 状态到期进入 probe 状态后 arp 请求得到了回应。否则还是会被删除。
四.Linux 的 ARP 缓存实现要点
在 blog 中分析源码是儿时的记忆了,现在不再浪费版面了。只要知道 Linux 在实现 arp 时维护的几个定时器的要点即可。
- Reachable 状态定时器
每当有 arp 回应到达或者其它能证明该 ARP 表项表示的邻居真的可达时,启动该定时器。到期时根据配置的时间将对应的 ARP 缓存表项转换到下一个状态。
- 垃圾回收定时器
定时启动该定时器,具体下一次什么到期,是根据配置的 base_reachable_time 来决定的,具体见下面的代码:
static void neigh_periodic_timer(unsigned long arg)
{...if (time_after(now, tbl->last_rand + 300 * HZ)) { //内核每5分钟重新进行一次配置struct neigh_parms *p;tbl->last_rand = now;for (p = &tbl->parms; p; p = p->next)p->reachable_time =neigh_rand_reach_time(p->base_reachable_time);}.../* Cycle through all hash buckets every base_reachable_time/2 ticks.* ARP entry timeouts range from 1/2 base_reachable_time to 3/2* base_reachable_time.*/expire = tbl->parms.base_reachable_time >> 1;expire /= (tbl->hash_mask + 1);if (!expire)expire = 1;//下次何时到期完全基于base_reachable_time);mod_timer(&tbl->gc_timer, now + expire);...
}
一旦这个定时器到期,将执行 neigh_periodic_timer 回调函数,里面有以下的逻辑,也即上面的… 省略的部分:
if (atomic_read(&n->refcnt) == 1 && //n->used可能会因为“本地确认”机制而向前推进(state == NUD_FAILED || time_after(now, n->used + n->parms->gc_staletime))) {*np = n->next;n->dead = 1;write_unlock(&n->lock);neigh_release(n);continue;
}
如果在实验中,你的处于 stale 状态的表项没有被及时删除,那么试着执行一下下面的命令:
ip route flush cache
然后再看看 ip neigh ls all 的结果,注意,不要指望马上会被删除,因为此时垃圾回收定时器还没有到期呢… 但是我敢保证,不长的时间之后,该缓存表项将被删除。
五. 第一个问题的解决
在启用 keepalived 进行基于 vrrp 热备份的群组上,很多同学认为根本不需要在进入 master 状态时重新绑定自己的 MAC 地址和虚拟 IP 地址,然而这是根本错误的,如果说没有出现什么问题,那也是侥幸,因为各个路由器上默认配置的 arp 超时时间一般很短,然而我们不能依赖这种配置。请看下面的图示:
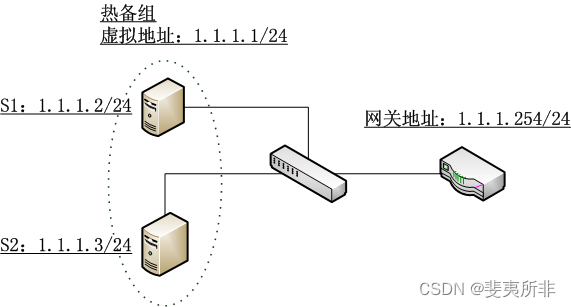
如果发生了切换,假设路由器上的 arp 缓存超时时间为 1 小时,那么在将近一小时内,单向数据将无法通信 (假设群组中的主机不会发送数据通过路由器,排出 “本地确认”,毕竟我不知道路由器是不是在运行 Linux),路由器上的数据将持续不断的法往原来的 master,然而原始的 matser 已经不再持有虚拟 IP 地址。
因此,为了使得数据行为不再依赖路由器的配置,必须在 vrrp 协议下切换到 master 时手动绑定虚拟 IP 地址和自己的 MAC 地址,在 Linux 上使用方便的 arping 则是:
arping -i ethX -S 1.1.1.1 -B -c 1
这样一来,获得 1.1.1.1 这个 IP 地址的 master 主机将 IP 地址为 255.255.255.255 的 ARP 请求广播到全网,假设路由器运行 Linux,则路由器接收到该 ARP 请求后将根据来源 IP 地址更新其本地的 ARP 缓存表项 (如果有的话),然而问题是,该表项更新的结果状态却是 stale,这只是 ARP 的规定,具体在代码中体现是这样的,在 arp_process 函数的最后:
if (arp->ar_op != htons(ARPOP_REPLY) || skb->pkt_type != PACKET_HOST)state = NUD_STALE;
neigh_update(n, sha, state, override ? NEIGH_UPDATE_F_OVERRIDE : 0);
由此可见,只有实际的外发包的下一跳是 1.1.1.1 时,才会通过 “本地确认” 机制或者实际发送 ARP 请求的方式将对应的 MAC 地址映射 reachable 状态。
更正:在看了 keepalived 的源码之后,发现这个担心是多余的,毕竟 keepalived 已经很成熟了,不应该犯 “如此低级的错误”,keepalived 在某主机切换到 master 之后,会主动发送免费 arp,在 keepalived 中有代码如是:
vrrp_send_update(vrrp_rt * vrrp, ip_address * ipaddress, int idx)
{char *msg;char addr_str[41];if (!IP_IS6(ipaddress)) {msg = "gratuitous ARPs";inet_ntop(AF_INET, &ipaddress->u.sin.sin_addr, addr_str, 41);send_gratuitous_arp(ipaddress);} else {msg = "Unsolicited Neighbour Adverts";inet_ntop(AF_INET6, &ipaddress->u.sin6_addr, addr_str, 41);ndisc_send_unsolicited_na(ipaddress);}if (0 == idx && debug & 32) {log_message(LOG_INFO, "VRRP_Instance(%s) Sending %s on %s for %s",vrrp->iname, msg, IF_NAME(ipaddress->ifp), addr_str);}
}
六。第二个问题的解决
扯了这么多,在 Linux 上到底怎么设置 ARP 缓存的老化时间呢?
我们看到 /proc/sys/net/ipv4/neigh/ethX 目录下面有多个文件,到底哪个是 ARP 缓存的老化时间呢?实际上,直接点说,就是 base_reachable_time 这个文件。其它的都只是优化行为的措施。比如 gc_stale_time 这个文件记录的是 “ARP 缓存表项的缓存” 的存活时间,该时间只是一个缓存的缓存的存活时间,在该时间内,如果需要用到该邻居,那么直接使用表项记录的数据作为 ARP 请求的内容即可,或者得到 “本地确认” 后直接将其置为 reachable 状态,而不用再通过路由查找,ARP 查找,ARP 邻居创建,ARP 邻居解析这种慢速的方式。
默认情况下,reachable 状态的超时时间是 30 秒,超过 30 秒,ARP 缓存表项将改为 stale 状态,此时,你可以认为该表项已经老化到期了,只是 Linux 的实现中并没有将其删除罢了,再过了 gc_stale_time 时间,表项才被删除。在 ARP 缓存表项成为非 reachable 之后,垃圾回收器负责执行 “再过了 gc_stale_time 时间,表项才被删除” 这件事,这个定时器的下次到期时间是根据 base_reachable_time 计算出来的,具体就是在 neigh_periodic_timer 中:
if (time_after(now, tbl->last_rand + 300 * HZ)) {struct neigh_parms *p;tbl->last_rand = now;for (p = &tbl->parms; p; p = p->next)//随计化很重要,防止“共振行为”引发的ARP解析风暴p->reachable_time = neigh_rand_reach_time(p->base_reachable_time);
}
...
expire = tbl->parms.base_reachable_time >> 1;
expire /= (tbl->hash_mask + 1);
if (!expire)expire = 1;
mod_timer(&tbl->gc_timer, now + expire);
可见一斑啊!适当地,我们可以通过看代码注释来理解这一点,好心人都会写上注释的。为了实验的条理清晰,我们设计以下两个场景:
-
使用 iptables 禁止一切本地接收,从而屏蔽 arp 本地确认,使用 sysctl 将 base_reachable_time 设置为 5 秒,将 gc_stale_time 为 5 秒。
-
关闭 iptables 的禁止策略,使用 TCP 下载外部网络一个超大文件或者进行持续短连接,使用 sysctl 将 base_reachable_time 设置为 5 秒,将 gc_stale_time 为 5 秒。
在两个场景下都使用 ping 命令来 ping 本地局域网的默认网关,然后迅速 Ctrl-C 掉这个 ping,用 ip neigh show all 可以看到默认网关的 arp 表项,然而在场景 1 下,大约 5 秒之内,arp 表项将变为 stale 之后不再改变,再 ping 的话,表项先变为 delay 再变为 probe,然后为 reachable,5 秒之内再次成为 stale,而在场景 2 下,arp 表项持续为 reachable 以及 dealy,这说明了 Linux 中的 ARP 状态机。那么为何场景 1 中,当表项成为 stale 之后很久都不会被删除呢?其实这是因为还有路由缓存项在使用它,此时你删除路由缓存之后,arp 表项很快被删除。
七. 总结
-
在 Linux 上如果你想设置你的 ARP 缓存老化时间,那么执行 sysctl -w net.ipv4.neigh.ethX=Y 即可,如果设置别的,只是影响了性能,在 Linux 中,ARP 缓存老化以其变为 stale 状态为准,而不是以其表项被删除为准,stale 状态只是对缓存又进行了缓存;
-
永远记住,在将一个 IP 地址更换到另一台本网段设备时,尽可能快地广播免费 ARP,在 Linux 上可以使用 arping 来玩小技巧。
篇外:
“全栈”工程师请不要随意去做
小北哥哥和北妈于 2017-03-28 11:41:35 发布
今天我来给大家说说“全栈工程师”的事儿。
写这篇文的背景原因是:最近越来越多的人想做全栈工程师,他们的目标就是全栈。他们才入行短短 1 - 2 年,甚至刚从培训班出来,就说“我的目标是做全栈,我啥都要学会,啥都会写,这样我就是大牛了,可以挣大钱。就算创业,我也不用招那么多人,一个人搞定一个产品,融资上市,当 CEO,娶白富美……”
我给他的回复是:去你 xx 的,你连 JS 数组和对象用法都搞不清,抄几个效果,看几个视频教程摸索摸索就要做万能人了?
“全栈”工程师的定义
全栈工程师,英文叫 Full Stack Developer,是指掌握多种技能,并能利用多种技能独立完成产品的人 — 来自某百科。
一般理解:全栈工程师就是啥都会,啥都能搞,上能入天、下能入地。各种技能各种语言眼花缭乱,各种 5 杀 6 杀、偷塔组合技能,pio pio pio,一人挑起全世界,各个技术栈技术点,前后通吃,疑难杂症统统不在话下,在世达芬奇,全能奇才多么牛 x。
然而,真正的全栈是:我也不知道,我从来都做不了全栈而且也不想做啊,只知道,我在 web 前端行业挖得够深、够猛、够快乐就好了,T 字形人才,下面一竖要足够高足够粗了,才能撑起来上边的一横。
我只知道,我从网上扒出来的计算机全栈大牛都是:基础知识无比扎实,蹲马步十个小时不带喘气的。从二进制到基础电路电位,到计算机运行原理、内存控制原理、数学计算基础、外语适应能力、逻辑思维能力、解决实际问题能力、出疑难杂症解决方案能力等等等等都是一把好手。各种编程语言和工具应用只是他们解决某个特定问题的工具而已,仅仅是工具。
几位大牛
- 发明 nodejs 的作者:Ryan Dahl — 后端语言无所不通,思路绝顶聪明,计算机原理各种 666,不然也不会解决多少年来让人头疼的阻塞问题。
- JS 宗师人物:道格拉斯・克罗(俗称老道) — 是无数前端人的偶像。他从 C 语言、Java、C++、Ruby、汇编什么的,市面上有的,他都得心应手,并且是许多语言规范的发明和贡献者,可谓语言界的“全栈”鼻祖,尤其对 JS 贡献巨大。现在许多 web 规范和语言范畴都是他制定的。出了十几本畅销 20 年左右的技术书。
- Linux 之父:Linus Torvald — 此人更传奇了,可谓颠覆计算机世界,无所不能。“My name is Linus, and I am your God” 这句话出自他口。他说自己是神,大部分人是信了。此人会什么自己去百度吧。
自己造火箭的埃隆・马斯克,确实啥都懂,火箭飞船都自己私人公司造。你想想他各个领域的基础知识和汇聚知识并为己用的能力是有多变态。不过他再牛,也是需要团队的,期间各个细节也是把控不了的。世界上真的有所谓的全才吗?
以上几位才能在一定意义上说是全栈。基础知识扎实,基础素养和习惯良好,才是成为全才的关键。
否则都是二半吊子,啥都会,其实就是啥都不会
以下几种人很典型,并大有人在:
- 会个 PHP + JS + MySQL 就吵吵自己是全栈,前后通吃。
- 会做 APP、会做网站、会弄数据库、配置服务器环境,自己就是全栈了,有任何问题找我。
- 从 Java、C++ 语言转型前端,或者去做硬件,然后掌握了不少框架和工具之后,就说我是全栈了。
- 配置了服务器、了解了一门后台语言、听说和查阅过各种前端框架用法之后膨胀了,并立志我要做一个全栈。
我都不想说了,以上几种人在各位的实际生活中、公司中绝对都见过,而且吹牛逼的也很厉害。感觉公司离了他不能转,有任何难题就一句话:“简单,我会啊!”结果他留下的坑比要填的坑还要大。
具体原因:
- 基础知识太渣,急于求成表现,盈利。
- 坐井观天,会一项或者几项技能之后,自信心膨胀。
- 技术浮于表面,经不起细节和解决具体问题方案的推敲。
- 缺乏对解决问题的深度思考和负责人的能力。
看我总结的公式:
- 普通人
全栈 = 全干 = 啥都会 = 啥都不会
- 真全栈
全栈 = 全都不干 = 全都有解决方案 = 各个行业都能干
所以,一开始就要喊做全栈,你看看自己到底行不行,再来改变下你的定位。
最后结合我自己,熟悉我的人都知道,我除了帅,就是帅了,其实技术也就够吃饭、够撩妹的。
我从来不说自己想做全栈,不说自己啥都会。我总觉得自己啥都不会,三省吾身的,感觉自己知识还是不够牢固。了解的越多,越觉得自己是井底之蛙,还有很多不了解和学不会的,那就不学了吧 / 笑哭。
虽说我 C、C++、C#、Java、PHP、Python 等甚至 VB 老掉牙的语言我都写过和学过,尤其是 C 语言,当年我大学可是名列前茅。但最后我不还是选择了前端,专攻 JS,毕竟我还是个视觉感性动物。
后端语言经历为我打了良好的语言逻辑基础和解决项目难题的思路。所以没有现在刚入门的新人这么困难,没有后端编程语言,尤其是 C 系列语言的概念基础,学 JS 确实有些困难和迷惑。
收尾:如果你真的想做“全栈”,请你结合我以上观点,深刻挖掘自己潜力,务必打好基础体系架构(这也是我个人一直强调的),不要急功近利,慢慢地往上走,把一门学科做到深入和佼佼者,自然融会贯通。因为世界万物到最后都是“物质”二字,都是一样的道理。
但,注意口型:请不要随意做“全栈(贱)”工程师。
via:
-
闲谈 IPv6 - 典型特征的一些技术细节 - CSDN 博客 iteye_21199 于 2012-11-10 20:54:00 发布
https://blog.csdn.net/iteye_21199/article/details/82441458-
那段时间,那段故事,请参阅下面的链接:
-
Windows 配置路由时可以指定源地址:
https://blog.csdn.net/dog250/article/details/10044433 -
彻底征服 Windows 上 OpenVPN 客户端的源地址选择问题
https://blog.51cto.com/dog250/1268836 -
在 Linux 上实现一个可用的 stateless 双向静态 NAT 模块:
https://blog.csdn.net/dog250/article/details/42046867 -
一个可以直接使用的可用 iptables 配置的 stateless NAT 实现:
https://blog.csdn.net/dog250/article/details/42196919 -
static stateless 2-way NAT on Linux with iptables 的应用实例:
https://blog.csdn.net/dog250/article/details/42360579
-
-
-
闲谈 IPv6 - 源 IP 地址的选择 (RFC3484 读后感)-CSDN 博客 dog250 于 2019-02-21 21:33:56 发布
https://blog.csdn.net/dog250/article/details/87815123-
关于 IP 网段间互访的问题 — 路由是根本:
https://blog.csdn.net/dog250/article/details/5303291 -
两台不同网段的 PC 直连是否可以相互 ping 通:
https://blog.csdn.net/dog250/article/details/68951615 -
“全栈”工程师 请不要随意去做_全栈工程师-CSDN博客
https://blog.csdn.net/xllily_11/article/details/67634075
-
-
闲谈 IPv6-Anycast 以及在 Linux/Win7 系统上的 Anycast 配置-CSDN 博客 dog250 于 2019-03-02 09:18:10 发布
https://blog.csdn.net/dog250/article/details/88071601 -
闲谈 IPv6 - 一起玩转 IPv6 地址自动配置_临时 ipv6 地址 - CSDN 博客 dog250 于 2019-03-06 00:15:57 发布
https://blog.csdn.net/dog250/article/details/88176596 -
闲谈 IPv6-IPv6 地址聚类分配原则与源地址选择的关系_ipv6 内核支持 rfc3484 源地址选择算法 - CSDN 博客 dog250 于 2019-03-09 08:29:56 发布
https://blog.csdn.net/dog250/article/details/88353332 -
Linux 实现的 ARP 缓存老化时间原理解析_linux 中 arp 表的老化机制 - CSDN 博客 dog250! 于 2012-02-11 22:00:09 发布
https://blog.csdn.net/dog250/article/details/7251689