MYSQL之数据类型
数据类型分类

数值类型
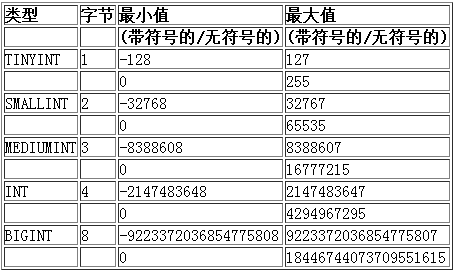
在MySQL中, 整型可以指定是有符号的和无符号的, 默认是有符号的. 可以通过 UNSIGNED 来说明某个字段是无符号的.
tinyint类型
以tinyint为例, 其它的整型类型都只是数据范围的区别.
数据越界
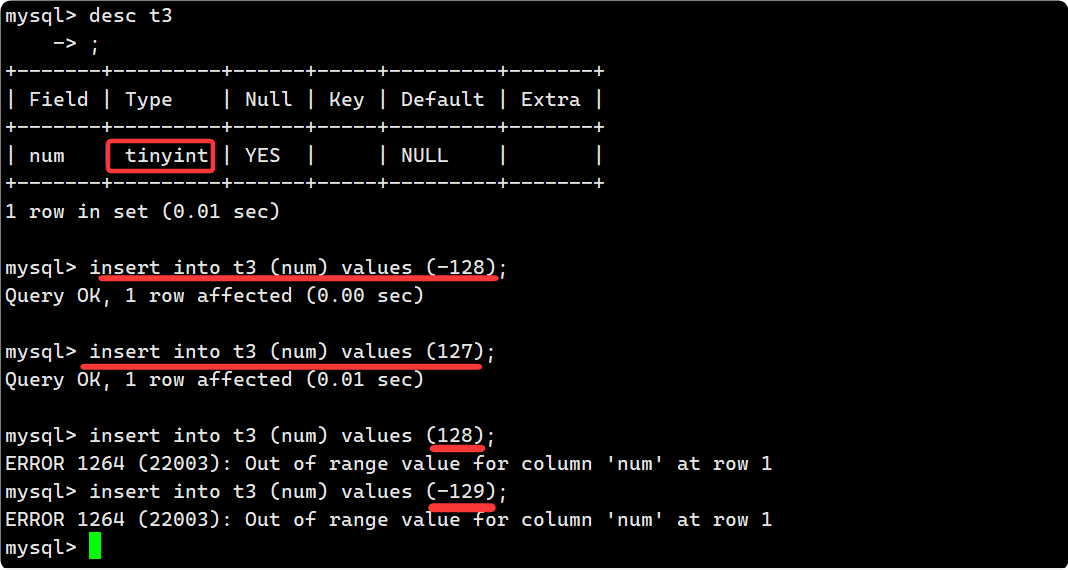
创建一个 tinyint 类型的 num 的属性, 大小为 1 字节, 不加 unsigned 修饰的话范围是[-128,127], 可以发现插入范围之外的值会越界报错:
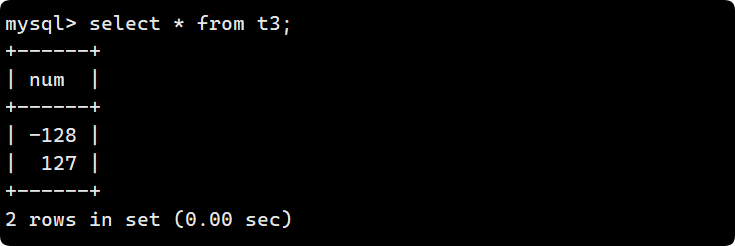
插入后的结果:
给表添加一列 tinyint unsigned 类型的属性num2, 同样会有越界的问题, 此时的数据范围是[0, 255]:
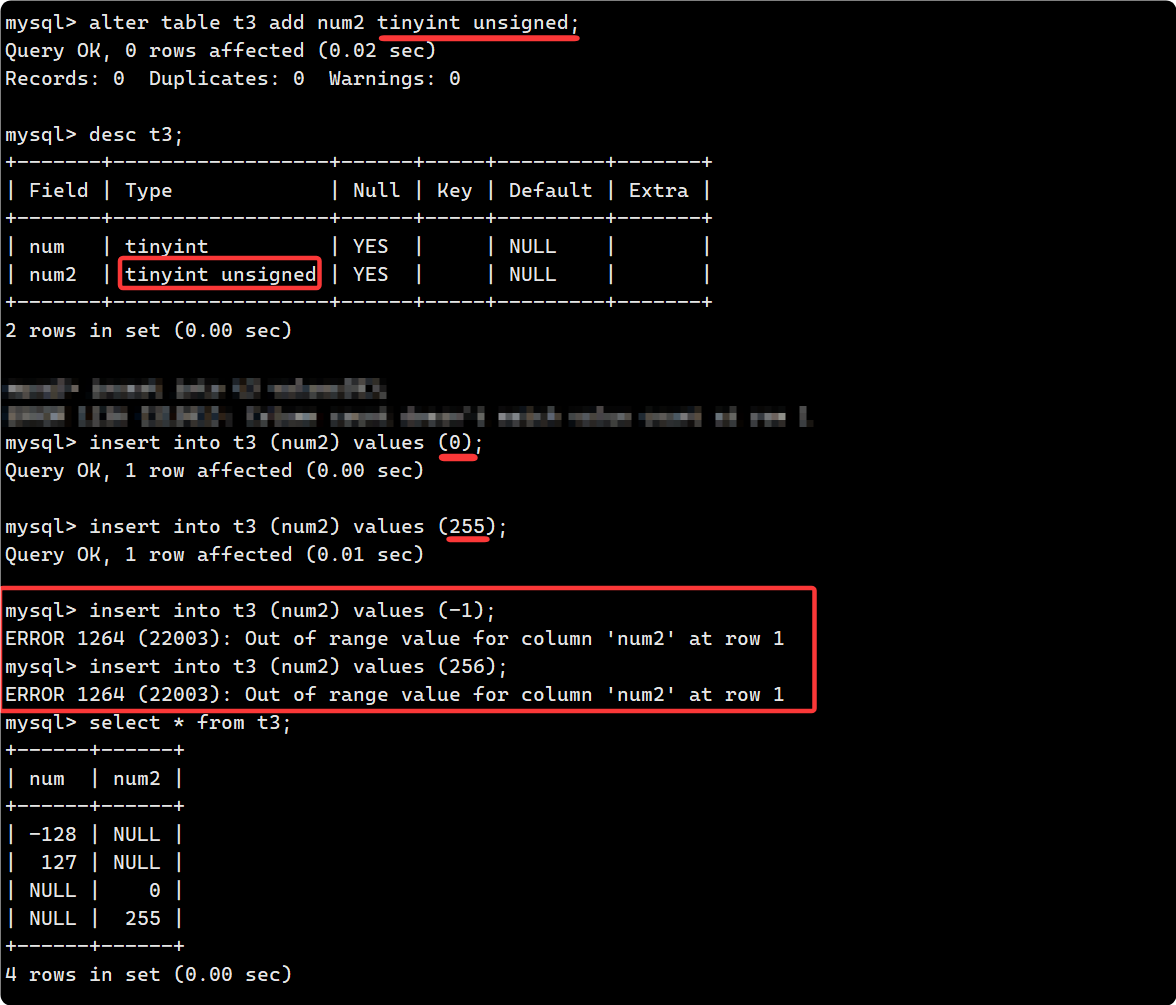
所以说明向mysql中的特定类型插入不合法数据, MySQL一般会直接拦截我们(报错), 而并不像C语言, 会去做截断. 换句话说, 已经插入到表中的数据一定是合法的.
因此在mysql中, 一般而言数据类型本身也是一种约束, 倒逼程序员尽可能正确的插入.
注意:尽量不使用unsigned, 对于int类型可能存放不下的数据, int unsigned同样可能存放不下, 与其如此, 还不如设计时, 将int类型提升为 bigint 类型. 但是也不绝对, 这要取决于场景, 有些场景下取值不可能为负数, 也应该用unsigned.
bit类型
bit[(M)] : 位字段类型. M 表示每个值的位数, 范围从1 到 64. 如果 M 被忽略, 默认为 1.
现在创建一个 bit 类型的 gender 属性: 0 为 女, 1 为男
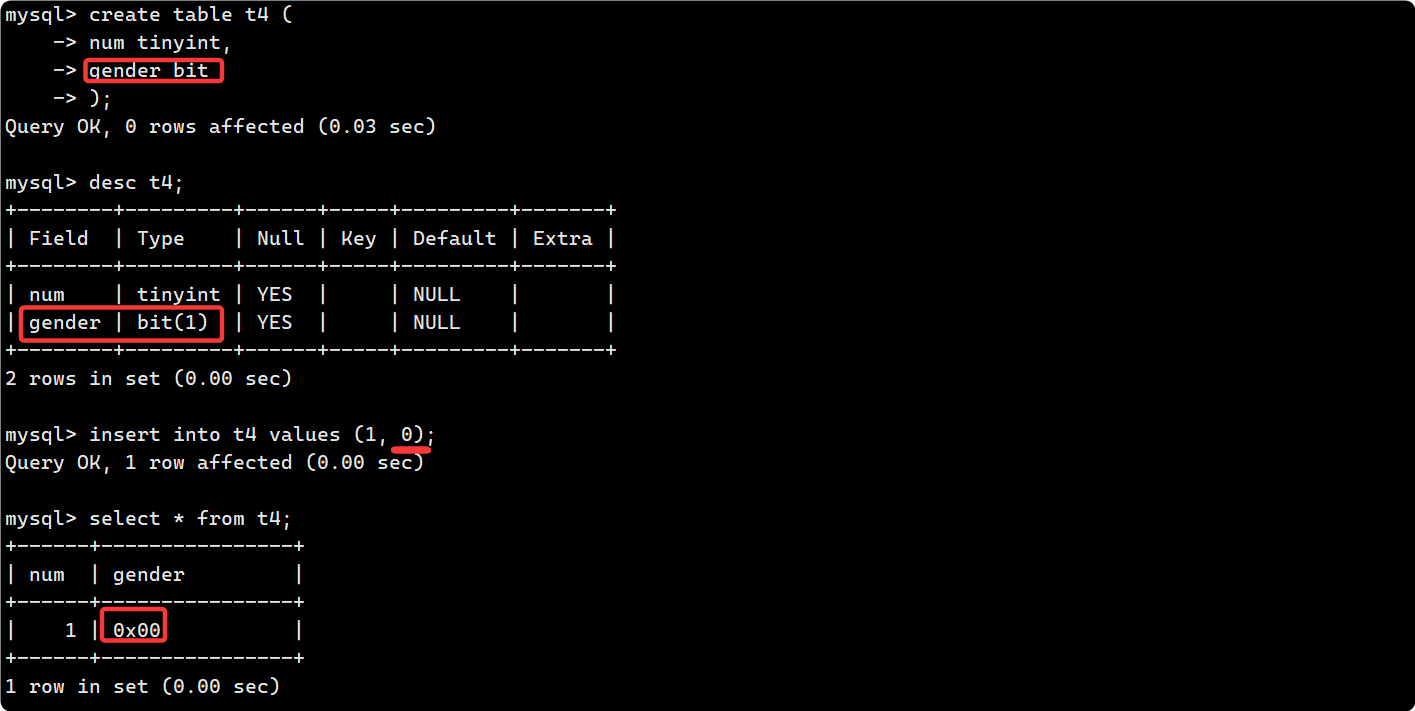
超出数据类型的范围依然会报错, 下面的例子因为bit(1)只能表示0,1, 插入2越界:

再创建一个 8 位的 bit 类型数据flag:
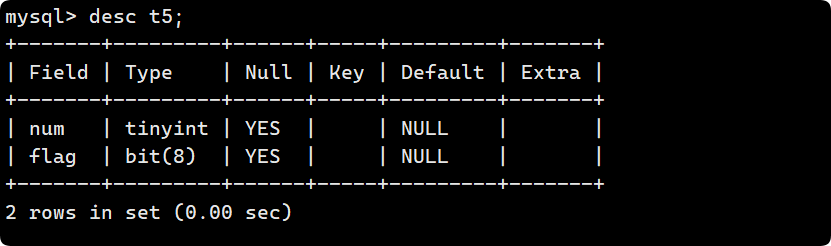
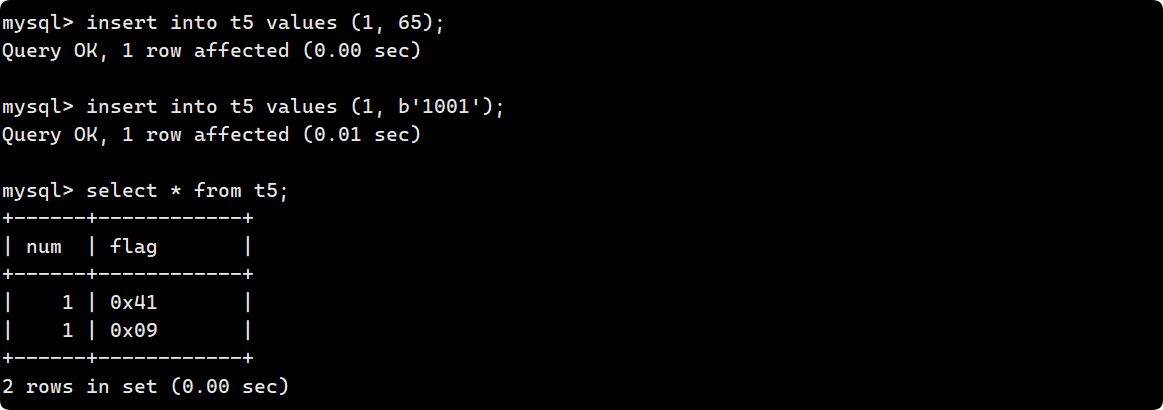
可以直接插入十进制整数, 也可以通过b’1001’的形式插入二进制, 最终select 在MySQL 8.0 中默认对于bit类型的数据是按照十六进制显示的, 而在MYSQL 5.5 中默认是 assic码 的形式显示.
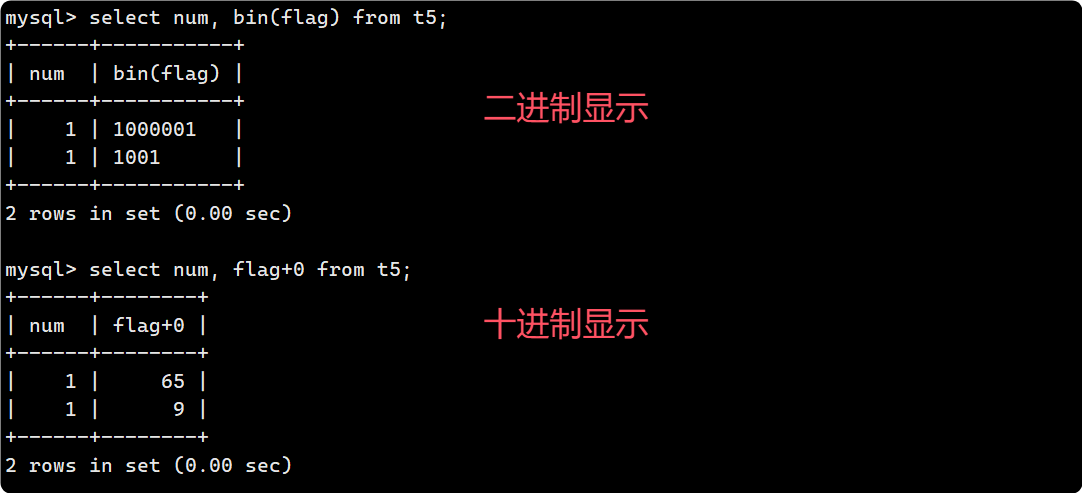
还可以有多种格式去显示:

浮点类型
float
语法: float[(m, d)] [unsigned] : M指定显示长度, d指定小数位数, 占用空间4个字节.
(m,d)精度是可选的, 如果直接写一个 float, 精度大约7位.
有符号float
举个例子, 小数: float(4,2) 表示的范围是 [-99.99 ~ 99.99], MySQL在保存值时会进行四舍五入
现在创建一个 float(4,2) 属性的 num 列:
create table t6 ( id int, num float(4,2) );
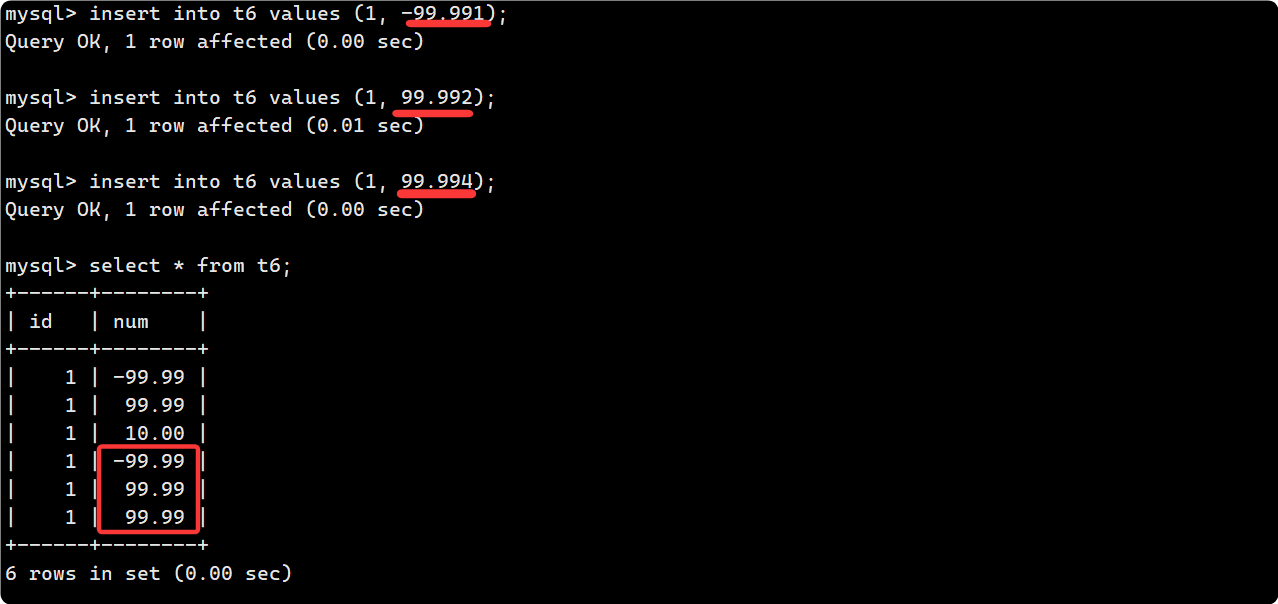
向表中插入一些正常的数据, 注意其中 10.0 会自动精确到 10.00:

再插入一些非法的数据, 不满足float(4,2):
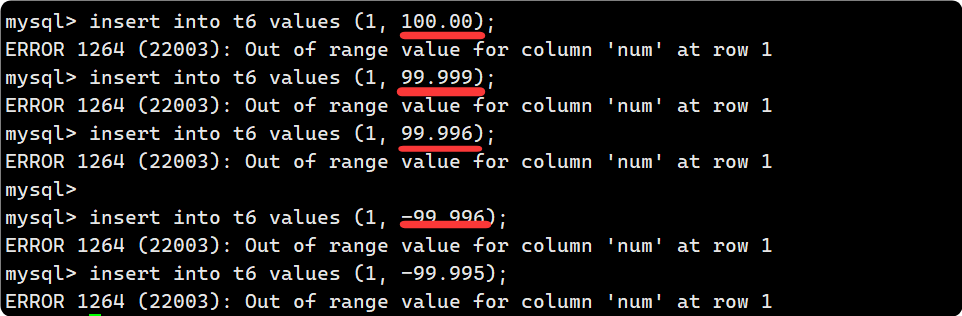
再插入几个形如 float(5,3) 的数据, 为什么插入成功了? 而且最终都被存为 99.99?
因为浮点数存储时, 如果精度并不严格满足定义, 但四舍五入之后数值范围仍在规定的范围内(本例为[-99.99, 99.99]), 则MYSQL会放宽约束条件.
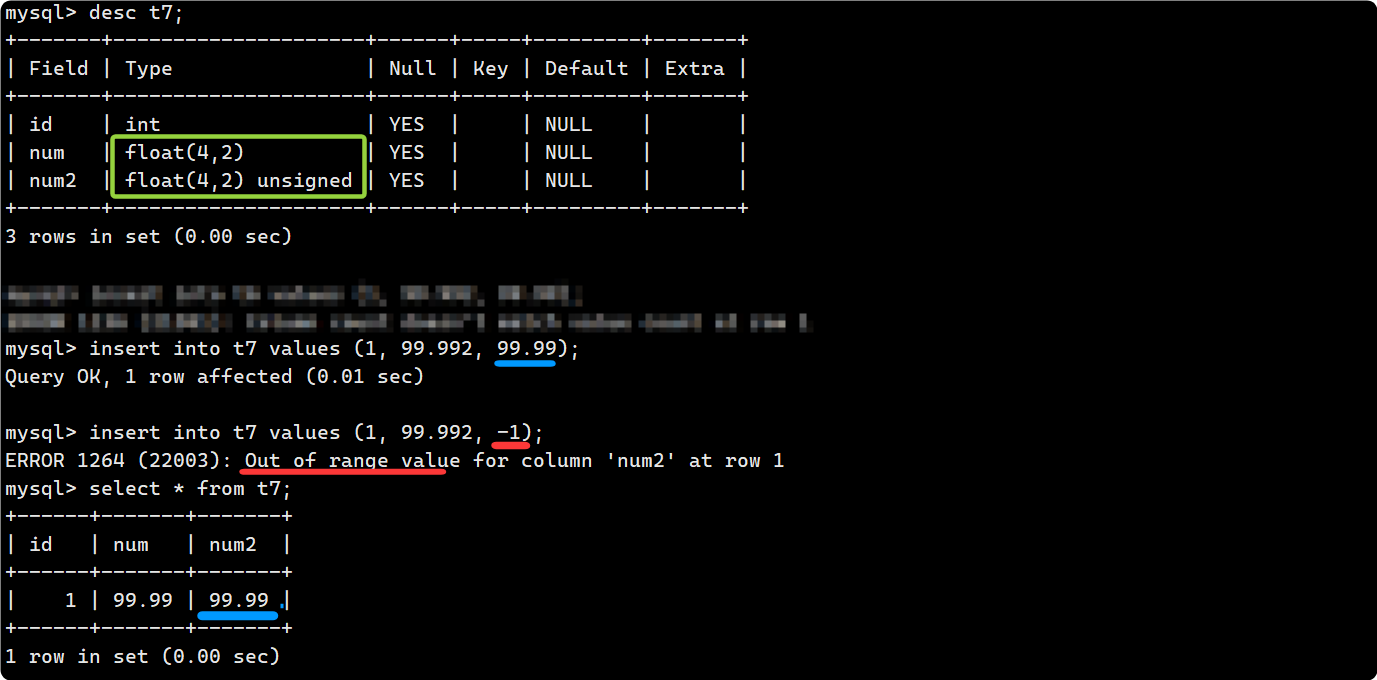
无符号float
如果定义的是 float(4,2) unsigned 这时,因为把它指定为无符号的数,范围是 0 ~ 99.99. 因此无符号浮点数的取值范围很简单粗暴, 就是把有符号浮点数的负数范围去掉.
double
double 和 float用法类似, 主要是精度的区别, 默认大约是15~16位.
decimal
主要来看一下decimal类型, 由于 float, double 浮点数使用的是 二进制科学记数法, 也就是数字在内部会被转化成 1.xxxxx × 2^y 的形式. 所以有些十进制数在转换为二进制时会发生舍入误差, 特别是对于无法精确表示的数字, 如 0.1 .
而 DECIMAL 类型则使用 十进制数表示法, 它以精确的十进制数进行存储和运算, 不会有类似浮点数的二进制精度问题.
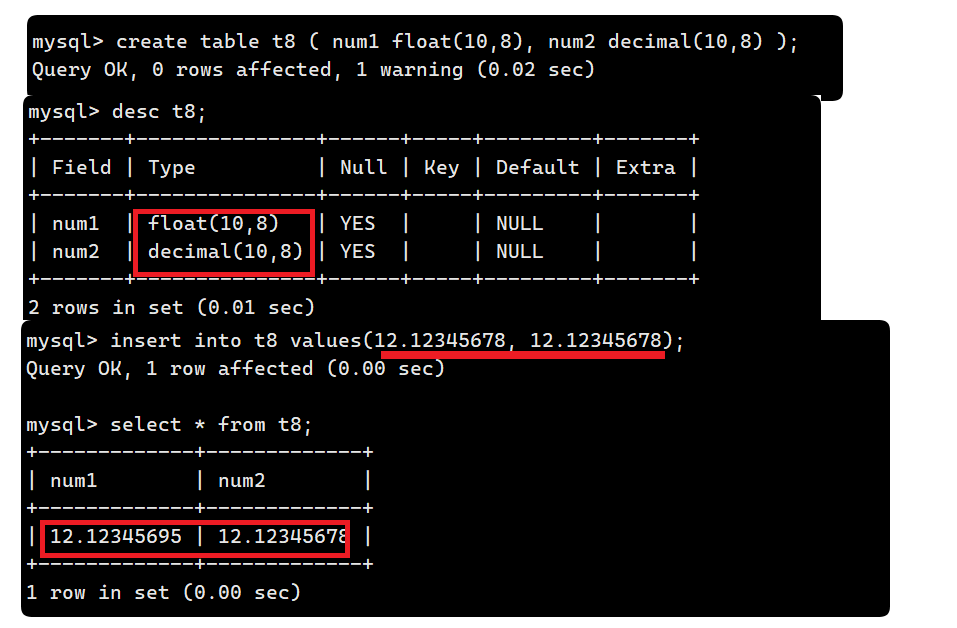
语法: decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数, 可以看出它的用法和float基本一样.
现在插入两个相同的数据 12.12345678, 发现 float 最终的结果并不准确, 而 decimal 则一位不差:
float/double VS decimal 应用场景:
-
浮点数(FLOAT / DOUBLE):
浮点数适合进行科学计算、物理模拟、图形处理等领域, 这些领域可以容忍一定程度的误差. 而在数值要求非常精确的领域, 浮点数不适用. -
DECIMAL:
DECIMAL 类型适合用于需要精确表示和计算的小数的场合, 例如金融计算, 货币运算, 税务计算等. 这些应用对误差非常敏感, 要求精确到每一位.
字符串类型
char
语法: char(L) 其中固定长度字符串, L是可以存储的长度, 单位为字符, 最大长度值可以为255.
MYSQL 中的字符和 C/C++等语言中的字符概念不同, 语言中我们认为一个字符为一个字节, 而MYSQL中字符是一种符号, 无论是 “ABC” 中的单个字母, 还是 “你好” 中的单个汉字, 我们都认为是一个字符, 即使底层存储需要的字节数不同.
create table t9 ( id int, name char(2), address varchar(10) );
现在往表中插入一条数据, name赋值为张三, 由于utfmb4一个字符为4字节, 这里虽然是char(2), 但是可以存下 8 字节的张三, 因为SQL中字符是指 “一个字符” :
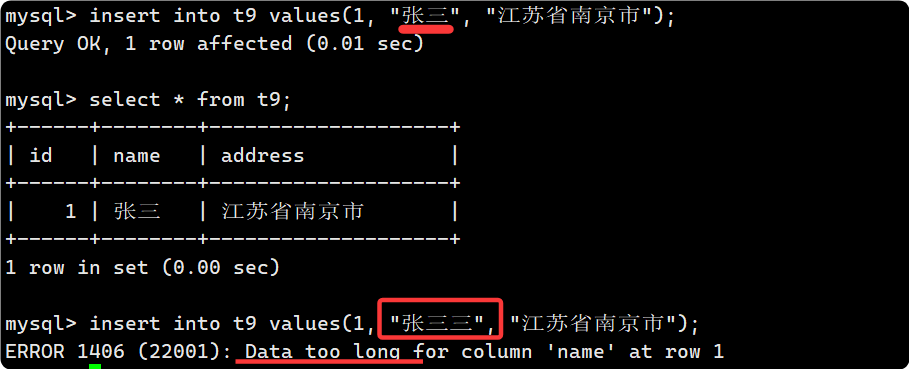
如果要存储超过 256 字节的大文本就不要用char, 用BLOB或者TEXT:

varchar
varchar能实现变长存储的核心在于其结构是: [实际长度字节] + [实际字符串内容], 有点类似C++的 string, 其由char* str, size 和 capacity 去维护, varchar中的实际字符串内容类比char* str, varchar的长度前缀类比 size, varchar(len)的 len 类比capacity.
关于varchar(len),len到底是多大, 这个len值, 和表的编码密切相关:
- varchar长度可以指定为 0 到 65535 之间的值, 但是有1 - 3 个字节用于记录数据大小, 所以说有效字节数是 65532 - 65534. 比如varchar(256), 那么就只需要1字节去记录大小即可.
- 当我们的表的编码是utf8mb4时, varchar(n) 的参数 n 最大值是 65532/4=16383 [因为utf中, 一个字符占用3个字节], 如果编码是gbk, varchar(n)的参数n最大是65532/2=32766 (因为gbk中,一个字符占用2字节)
- 注意 65535 是 MySQL 单行的 65535 字节限制, 这意味着表只有 varchar 一个元素时, 其参数 n 的最大值是 65532/3=21844, 但是如果有多个其他属性, 是所有列加起来 (包括 INT, VARCHAR等, 不包括BLOB 和 TEXT) 所占的实际存储空间, 不能超过 65535 字节, 所以在表内有多个属性时, 最终的varchar(len)的len值只会更小
可以看到 MYSQL 提示我们 max=16383, 而16383*4=65532 = 65535 - 3

可以看到现在添加一个int属性的id, varchar的参数只能更小:

char与varchar对比:

如何选择定长或变长字符串?
- 如果数据确定长度都一样, 就使用定长(char), 比如: 身份证, 手机号, md5
- 如果数据长度有变化,就使用变长(varchar),比如: 名字, 地址, 但是你要保证最长的能存的进去
- 定长的磁盘空间比较浪费, 但是效率高; 变长的磁盘空间比较节省, 但是效率低. 定长的意义是, 直接开辟好对应的空间 变长的意义是, 在不超过自定义范围的情况下, 用多少, 开辟多少
日期和时间类型
常见的日期类型:
- 日期 = 年月日, date :
yyyy-mm-dd, 占用三字节 - 日期时间 = 年月日时分秒, datetime:
yyyy-mm-dd HH:ii:ss表示范围从 1000 到 9999 , 占用八字节. (可以用户自定义) - 时间戳, 从1970年开始的. timestamp:
yyyy-mm-dd HH:ii:ss格式和 datetime 完全一致, 占用四字节
日期和时间戳的区别是:
- 时间戳会随时间变化, 而 datatime 则是固定的.
- 在MYSQL 5.x 中, 当向表插入(insert)数据时, 不需要去关心 timestamp 类型的数据, 它会自动被插入, 而datetime 需要手动插入. 在更新(update)数据时, 不需要去关心 timestamp 数据, 它会自动更新, 而datetime需要手动更新…; 在MYSQL 8.0 中, 需要在 timestamp 类型后添加 DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP 去保证默认插入和自动更新, 否则也必须自己手动插入.
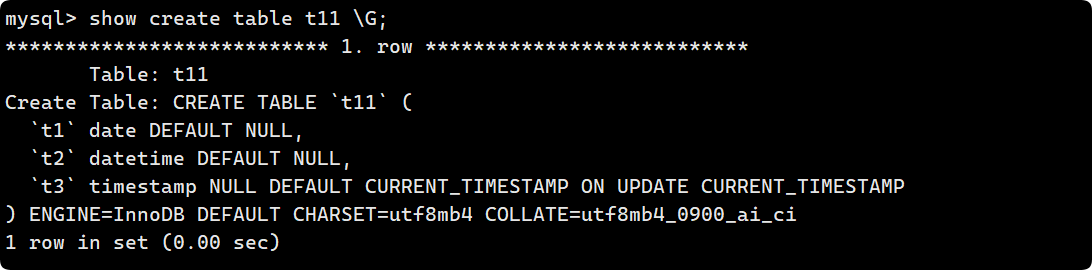
举个例子, 现在有 t1 date, t2 datetime, t3 timestamp 三个数据, timestamp 类型没有约束条件, 因此没有被默认插入:
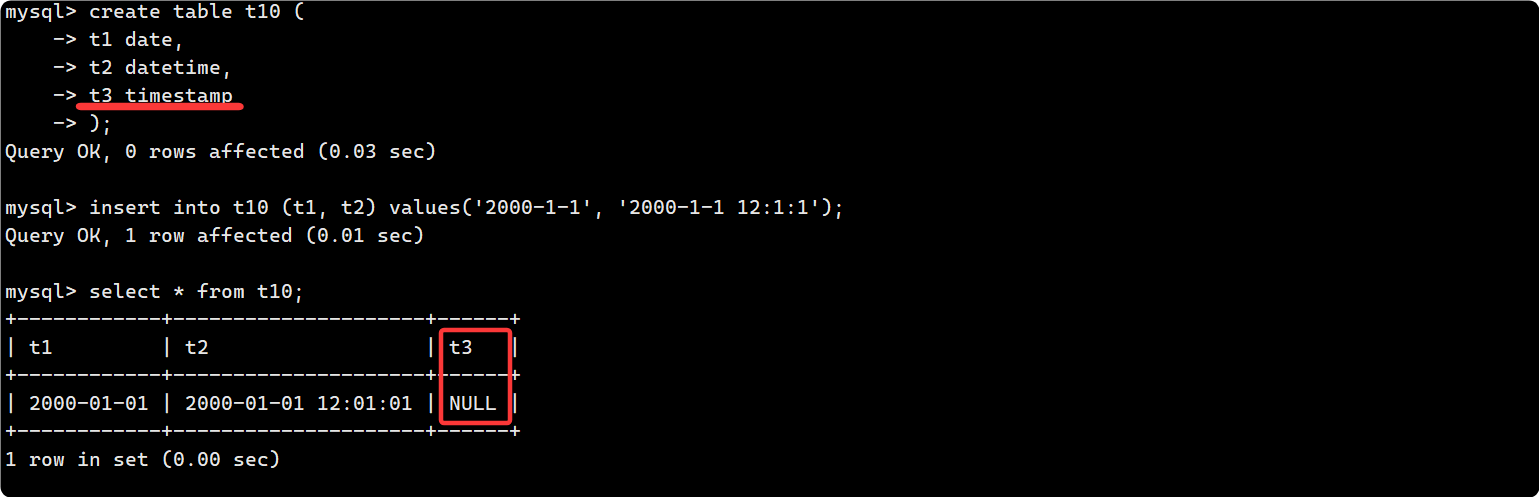
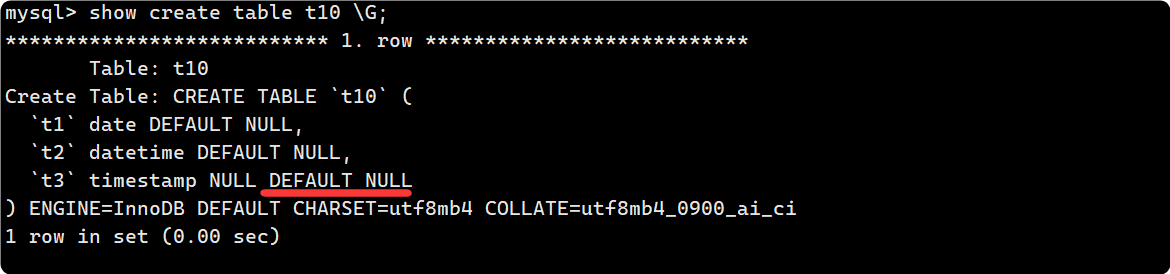
通过show create table t10 也可以验证, timestamp默认是NULL:
现在我们加上 DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP 约束条件:
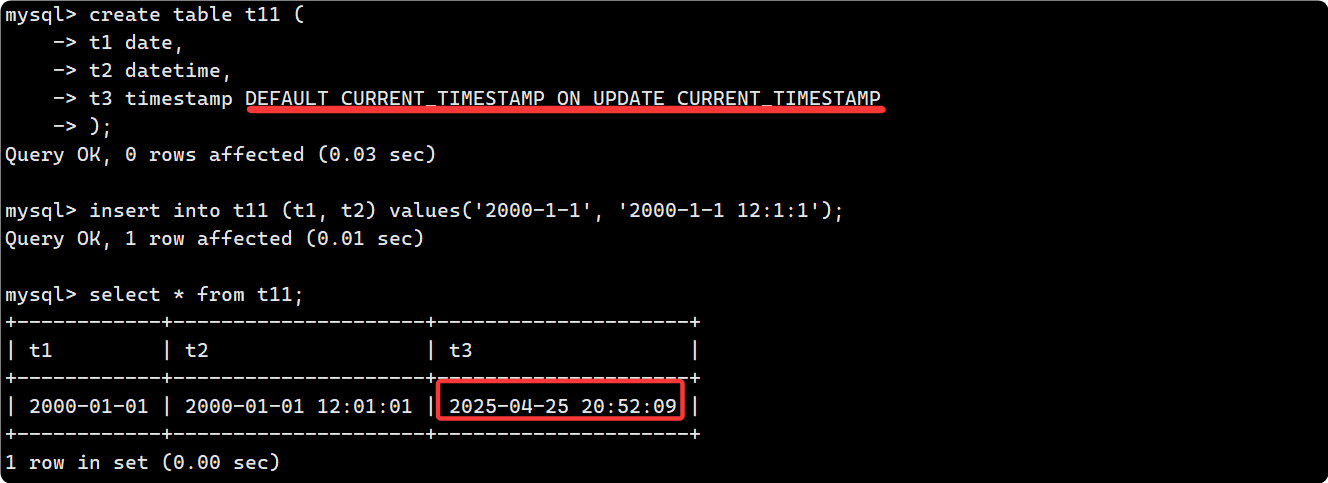
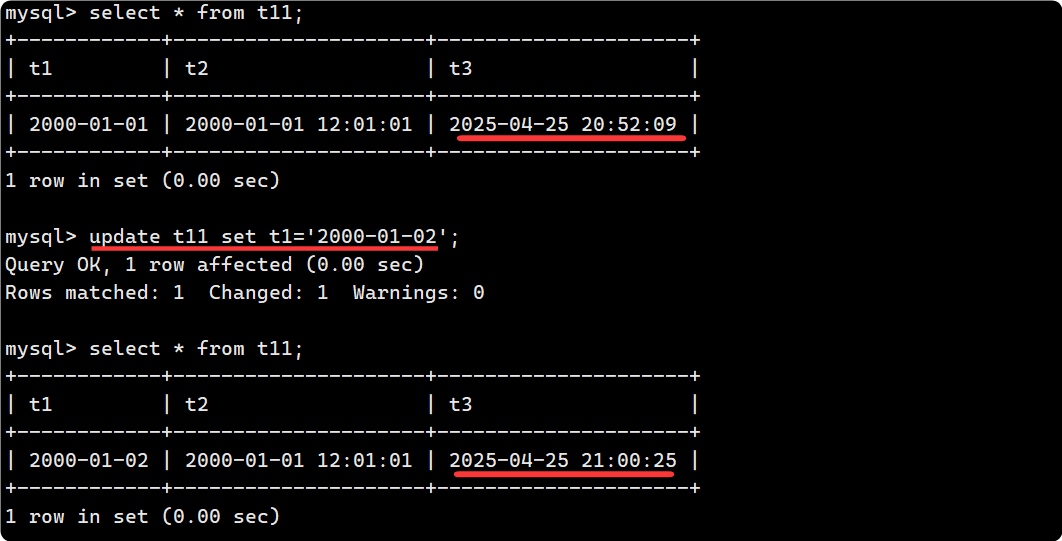
现在更新一下 t11 表, 发现 t3 自动更新为当前的时间戳:
enum和set
- enum: 枚举, “单选”类型;
enum(‘选项1’,‘选项2’,‘选项3’,…);
该设定只是提供了若干个选项的值, 最终一个单元格中, 实际只存储了其中一个值;而且出于效率考虑, 这些值实际存储的是“数字”, 因为这些选项的每个选项值依次对应如下数字: 1,2,3,…最多65535个; 当我们添加枚举值时, 也可以添加对应的数字编号. - set: 集合, “多选”类型
set(‘选项值1’,‘选项值2’,‘选项值3’, …);
该设定只是提供了若干个选项的值, 最终一个单元格中, 实际可存储了其中任意多个值; 而且出于效率考虑, 这些值实际存储的是“数字”, 因为这些选项的每个选项值依次对应如下数字: 1,2,4,8,16,32,…最多64个.
先创建一个 votes 表, set类型表示hobby, enum类型表示gender:
create table votes(-> username varchar(30),-> hobby set('登山','游泳','篮球','足球','武术'),-> gender enum('男','女')-> );
然后用不同的几种风格向表中插入数据:
insert into votes values('张三', '登山', '男');
insert into votes values('李四', '游泳', 2);
insert into votes values('王五', '游泳, 篮球, 足球', 1);
insert into votes values('赵六', 23, 1);
第一行就正常输入字符串插入, 很容易理解;
第二行的枚举类型我们使用了下标去插入, 因为 enum 实际存储的就是从1开始的数字;
第三行演示了如何正常地插入 set 类型的数据, 在一对单引号内部以逗号分隔开选项即可, 然后也改变了enum的插入风格;
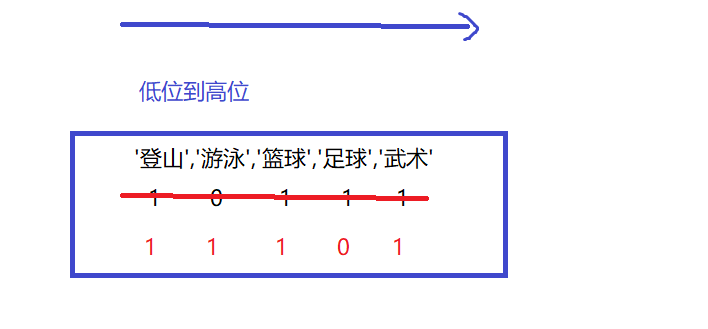
第四行我们主要改变了set的插入风格, 23 的二进制是10111, 但是SET 类型中的 第一个元素是最低位, 因此要反过来去解释:
结论:
- 对于枚举类型, 在插入时既可以用定义时的枚举选项常量, 也可以用从 1 开始的下标:
- 对于集合类型, 在插入时既可以用定义时的集合选项常量, 也可以用一个被看作位图的整型.
enum 和 set 的查询
集合查询使用 find_ in_ set 函数:
find_in_set(sub,str_list) : 如果 sub 在 str_list 中, 则返回下标; 如果不在, 返回0; str_list 用逗号分隔的字符串
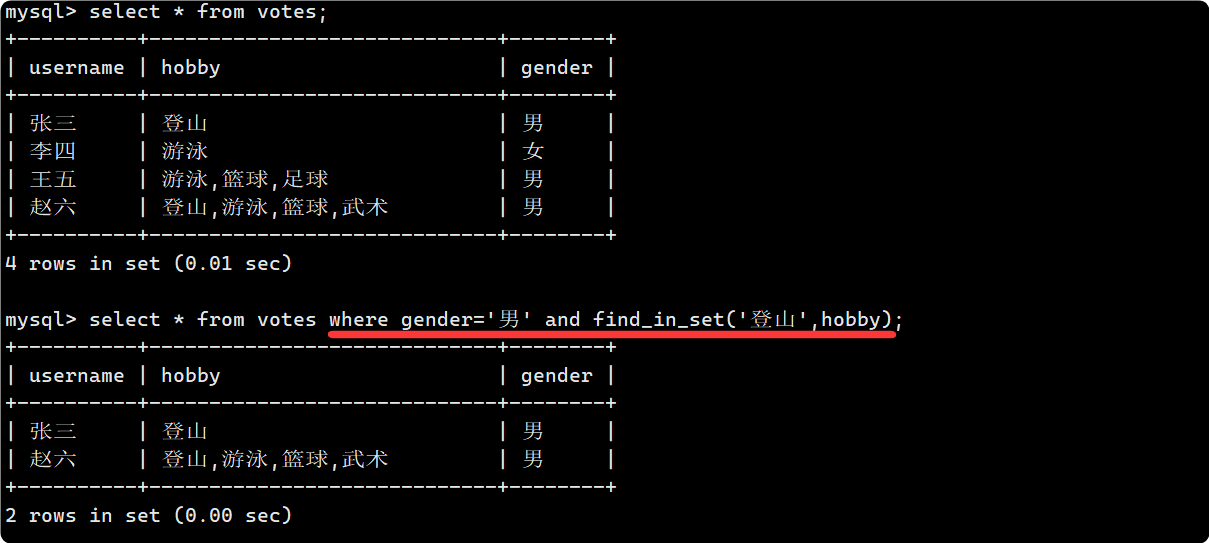
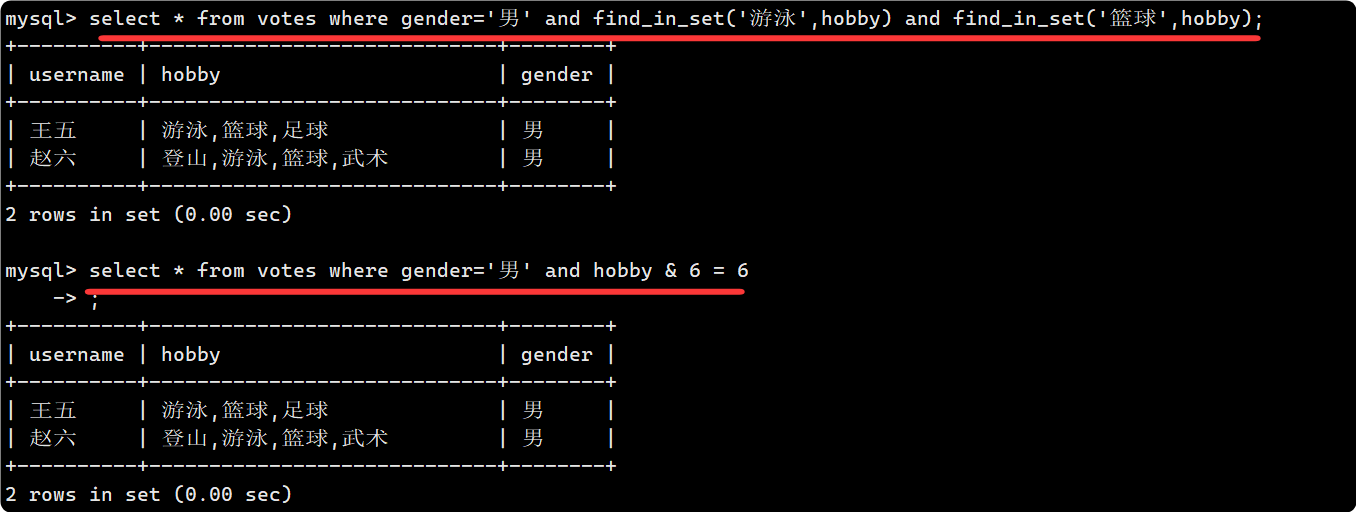
查找喜欢游泳和篮球的男生, 第一种写法比较容易理解, 用and连接多个条件即可, 但是比较长; 我们可以利用set的位运算, 由于’篮球,游泳’的二进制是 110, 因此我们可以用 hobby & 6 = 6去表示:
select * from votes where gender='男' and find_in_set('游泳',hobby)
and find_in_set('篮球',hobby);select * from votes where gender='男' and hobby & 6 = 6;
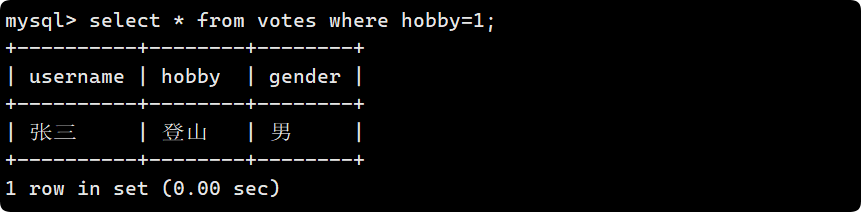
如果想找出只喜欢登山的人, 而不是喜欢登山, 那么用 hobby=1 或者 hobby=‘登山’ 去比较:
总结: 数据类型天然是一种约束, 如果不满足约束条件不允许被插入, 除了 float 可以宽松一点采用四舍五入.