【语法】C++的stack和queue
目录
简单介绍
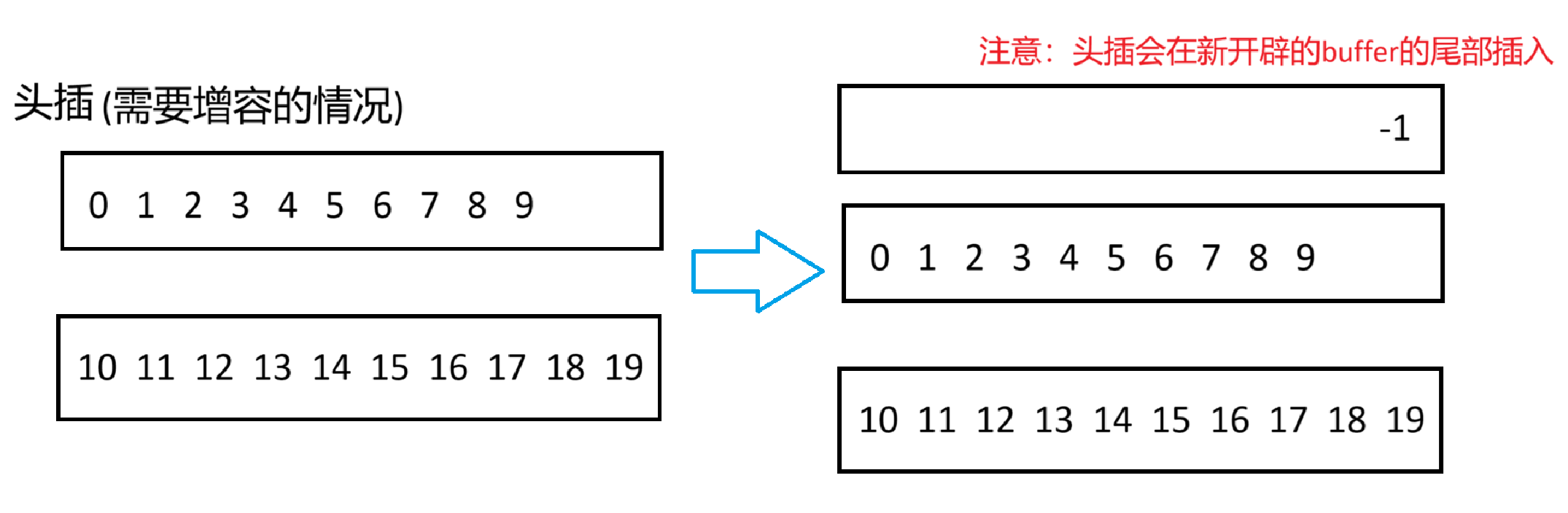
什么是容器适配器?
deque(双端队列)
priority_queue(优先级队列)
数组中第K个最大元素:
参考代码:
简单介绍
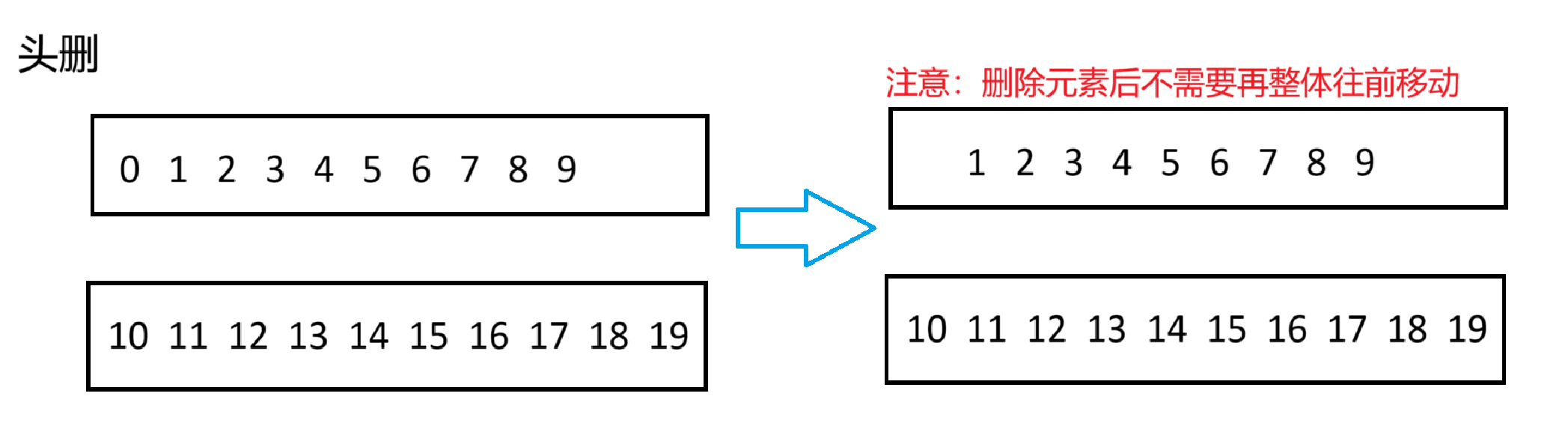
stack是LIFO(last-in first-out)(后进先出)的数据结构
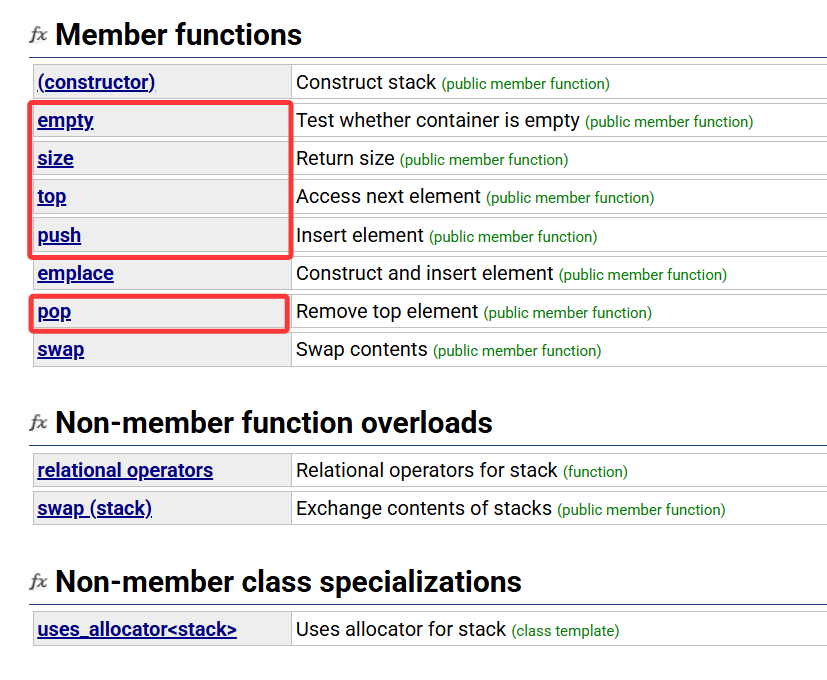
这是stack比较重要的接口,很多都和前面容器的用法类似
stack<int> s;
s.push(1);
s.push(2);
s.push(3);
stack<int>::iterator it;
for (it = s.begin(); it != s.end(); it++)
{cout << *it << " ";
}先拿来看一下上述代码可不可以运行
这里用的stack的迭代器进行遍历,看着没有问题,但其实是运行不了的,因为stack没有迭代器,不止stack,queue也没有迭代器,因为他它们是都是容器适配器,而不是像string,vector,list这样的容器,那我们要怎么遍历他们呢?
stack<int> s;
s.push(1);
s.push(2);
s.push(3);
while(!s.empty())//empty是判断栈是否为空,空返回true
{cout<<s.top()<<endl;//top是返回栈顶元素,但不删除s.pop();//pop是删除栈顶元素
}得益于它的LIFO机制,stack的插入不分尾插和头插,默认就是从栈顶插入(入栈),而删除也不分尾删和头删,默认就是从栈顶删除(出栈)
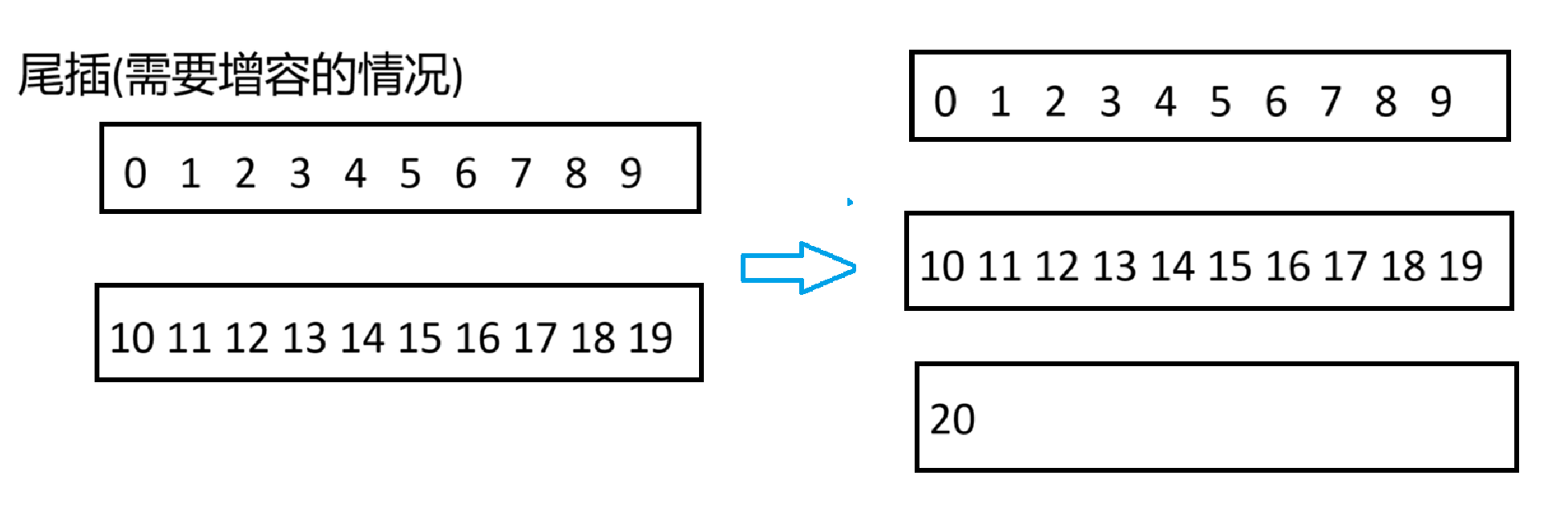
queue是FIFO(first-in first-out)(先进先出)的数据结构
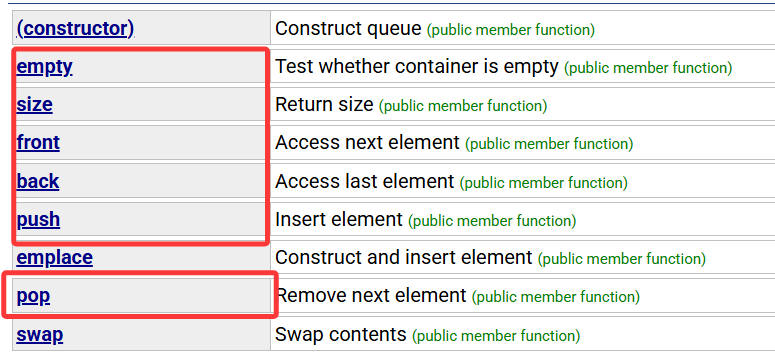
这是queue比较重要的接口,大部分也都和stack一样
至于front和back,就是分别取出队头和队尾的数据,而pop是删除队头的数据(出队),那么queue的遍历方式也显而易见
queue<int> q;
q.push(1);
q.push(2);
q.push(3);
while(!q.empty())//判断队列是否为空,是空就返回true
{cout<<q.front()<<endl;//front是取出队头的数据q.pop();//删除队头的数据
}什么是容器适配器?
stack和queue被叫做容器适配器,而之前学的vector,string,list都是容器,他们两者有什么区别呢?
在日常生活中,我们常提到的电源适配器,指的是连接笔记本电脑与电源插座的设备,它的主要功能是将220V的家庭用电电压转换为适合笔记本电脑充电所需的特定电流和电压。没有这个适配器,我们就无法安全地给笔记本电脑充电;如果直接将220V电压接入电脑,肯定会造成损坏。换句话说,电源适配器在这个过程中扮演了一个关键的中介角色,确保电力能够以适当的形式被利用。
就像电源适配器在电子设备中起到转换电压、确保安全充电的作用一样,编程中的容器适配器(Container Adapters)也发挥着类似的中介功能。容器适配器是设计用来提供特定接口的数据结构,但为用户提供了更加简便或者特定用途的操作方式。
具体来说,容器适配器通过封装底层的标准容器类型,例如vector、list或string,来提供一套定制化的接口。比如,栈(container adapter)通常只允许在数据结构的一端进行插入和删除操作,实现了后进先出(LIFO)的原则;而队列则是在一端进行插入,在另一端进行删除,遵循先进先出(FIFO)原则。这种封装让用户无需关心底层的具体实现细节,只需要关注如何使用这些预定义的行为即可。
因此,容器适配器就像是软件开发中的“电源适配器”,它不仅简化了对复杂数据结构的操作,还增强了代码的可读性和维护性。无论是构建简单的应用程序还是复杂系统,合理利用容器适配器都能大大提高开发效率和程序性能。
先来说栈

可以看到,stack的模板除了class T,后面还有一个class Container,并且它的默认类型是deque<T>
deque<T>我们一会再来细讲,先来讲讲Container有什么用
我们平常在定义stack时,通常就直接stack<int>,只传一个参数,但实际上是需要传两个参数的,只不过第二个参数的缺省值是deque<T>
当我们使用标准库中的
stack时,默认情况下,它会基于deque(双端队列)来存储数据。然而,stack的设计非常灵活,允许我们指定一个底层容器作为其存储结构。例如,在stack<int, vector<int>>中,vector<int>就是我们为栈指定的底层容器。这里,
vector<int>的作用是充当栈的实际存储机制。也就是说,栈的所有操作(如入栈push、出栈pop和访问栈顶元素top等)都会通过vector<int>来实现。换句话说,虽然栈本身是一个后进先出(LIFO)的抽象数据结构,但它的具体行为依赖于底层容器的功能支持。
int main()
{stack<int,vector<int>> st;st.push(1);st.push(2);st.push(3);st.push(4);st.pop();return 0;
}看上面这段代码,我在stack的参数中加了一个vector<int>,也就代表我这个st的底层是vector,只不过是在vector的基础上定义了push,pop,empty,top等等接口。stack<int,list<int>> st1;也就代表st1的底层是用的list。总结一下,vector<int> 在 stack<int, vector<int>> 中扮演了“幕后英雄”的角色,负责实际的数据管理,而 stack 则提供了一个简洁的接口,屏蔽了底层实现的复杂性,让我们能够专注于栈的操作逻辑。
以下是stack和queue的简单实现
template<class T, class Container>
class stack
{
public:void push(const T& x){con.push_back(x);}void pop() { con.pop_back(); }T& top() { return con.back(); }bool empty() { return con.empty(); }size_t size() { return con.size(); }private:Container con;
};void test()
{stack<int, vector<int>> st;for (int i = 0; i < 10; i++)st.push(i);while (!st.empty()){cout << st.top()<< " ";st.pop();}
}template<class T,class Container>
class queue
{
public:void push(const T& x) { con.push_back(x); }void pop() { con.pop_front(); }T& top() { return con.front(); }bool empty() { return con.empty(); }size_t size() { return con.size(); }
private:Container con;
};void qtest()
{queue<int,list<int>> q;for (int i = 0; i < 10; i++)q.push(i);while (!q.empty()){cout << q.top() << " ";q.pop();}
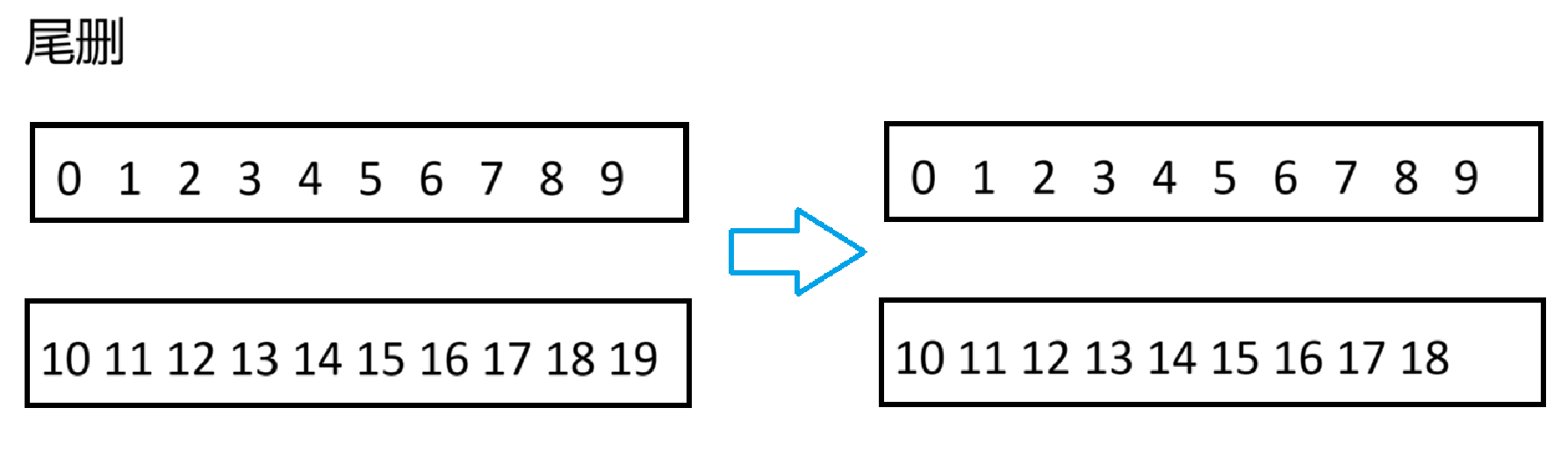
}细心的同学可能会发现,为什么在queue中Container参数不用vector了,因为queue需要用到头删操作,但vector没有系统的头删,要自己实现,为了统一,就用的list
总结:STL中的stack和queue是通过容器适配器转换出来的,不是原生实现的,至于原因——能复用当然是复用更好啦
但官方的stack和queue的Container参数都是deque,这是个什么东西呢?
deque(双端队列)
deque是 "double-ended queue" 的缩写,中文可以翻译为“双端队列”。它是一种允许从两端进行插入和删除操作的队列,提供了相较于普通队列(只能在一端进行插入,在另一端进行删除)更灵活的数据管理方式。在C++的标准模板库(STL)中,deque是一个非常有用且高效的容器类,适用于需要在序列两端频繁添加或移除元素的场景。
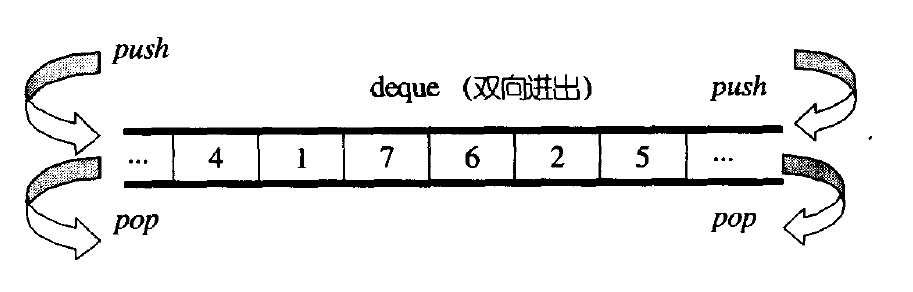
也就是说,虽然叫做双端队列,但和队列的特性没什么关系,因为它可以双向进出,看着很像list对吧,但它又同时支持随机访问(operator[])
可以把它理解为集vector和list优点的集大成之容器——至少表面上是这样的
众所周知,vector的优点是随机访问,而list的优点是不需要扩容,且在任何地方插入数据的效率都是O(1)
deque同时具备这两种优点

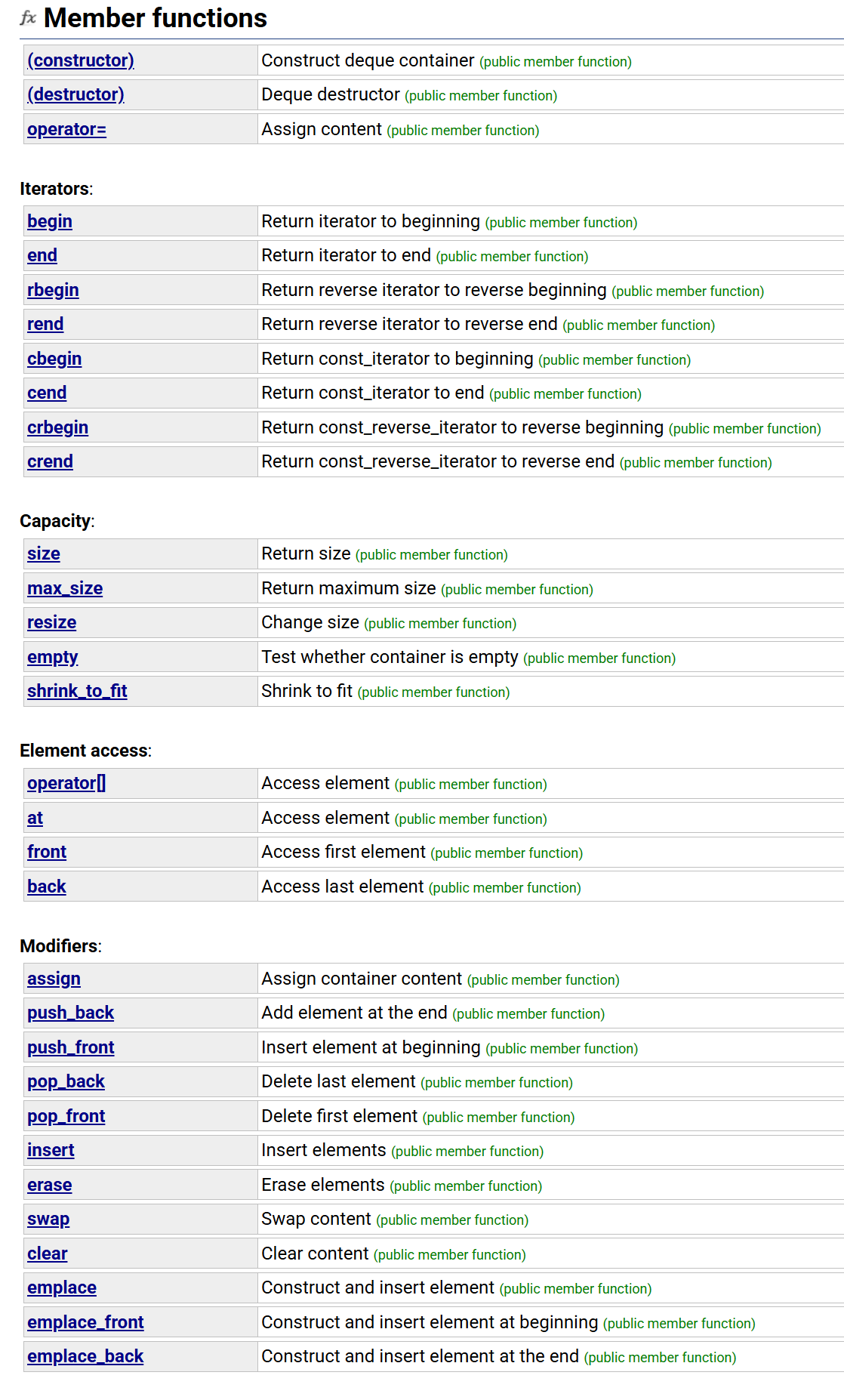
这是deque的成员函数,非常的全,可以说是应有尽有(注意,有迭代器和operator[])
那它是怎么实现vector和list的集大成优点的呢?它的缺点又是什么?
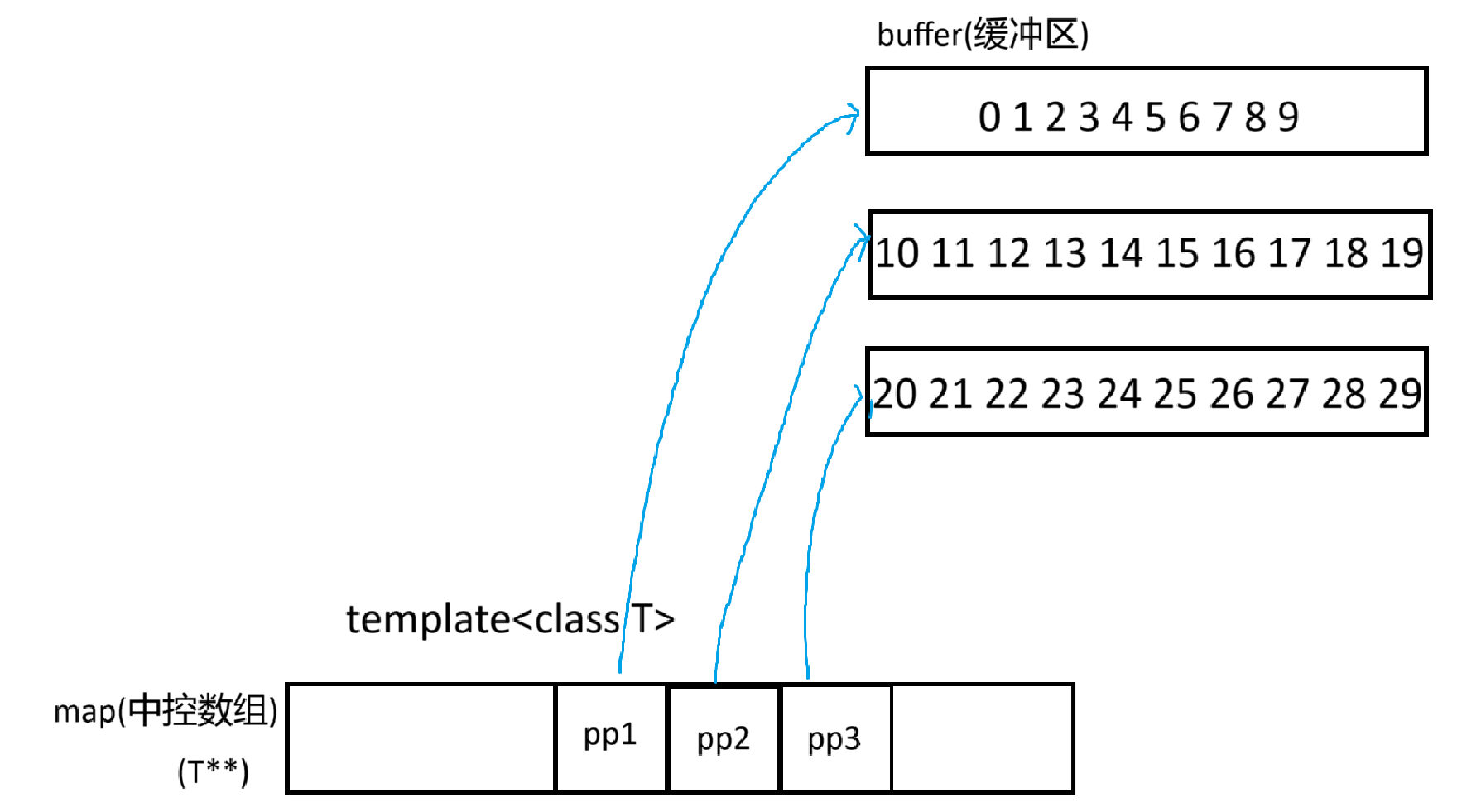
deque中真正存储数据的其实是buffer(缓冲区),缓冲区是固定大小的一段空间,而map是其实是一个指针数组,负责管理一个个的buffer(中控映射),里面存的都是二级指针,二级指针中存的是每一个缓冲区的地址(map是从中间开始存指针的,这样如果是尾插,就往后走,头插可以往前走,如果map存满了就像vector一样扩容)
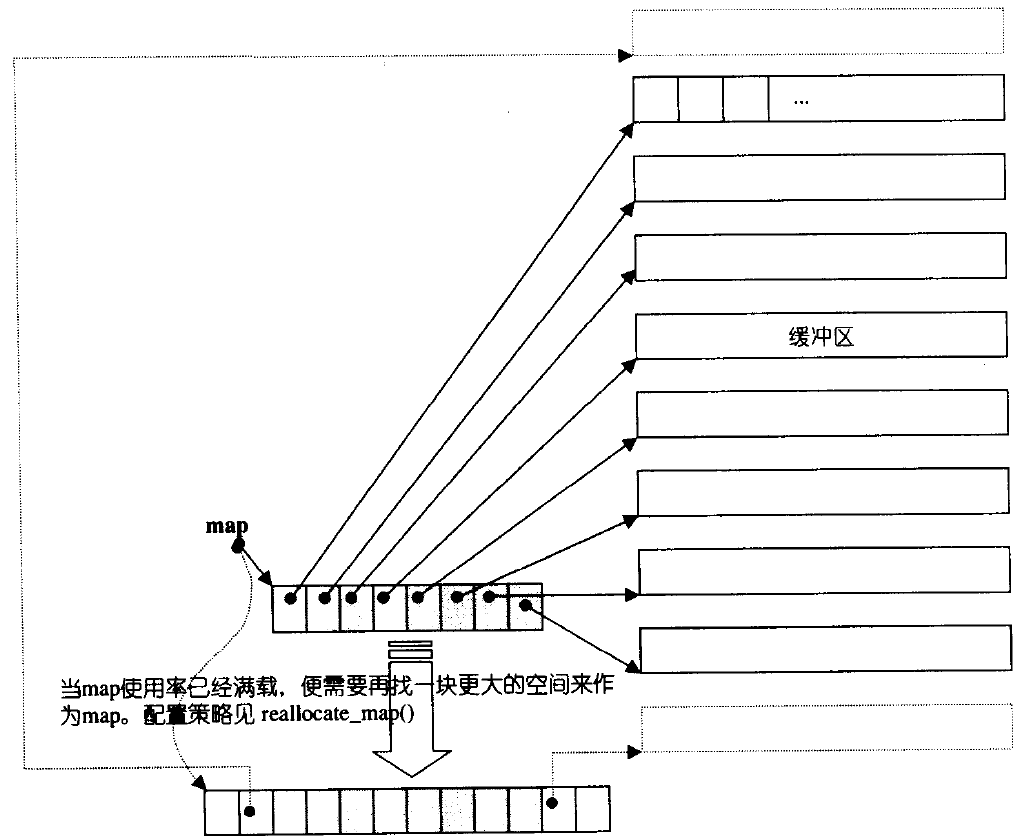
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
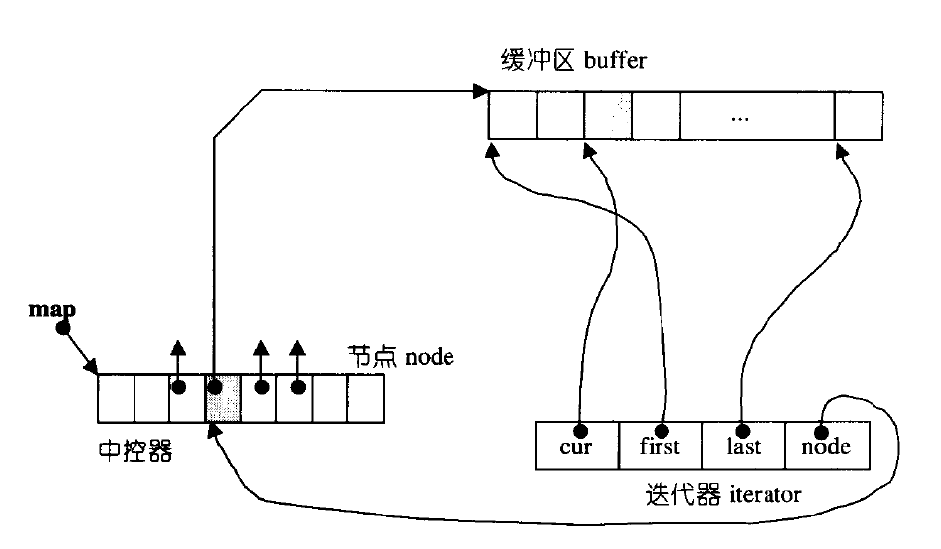
迭代器是4个指针,cur指向当前遍历的元素,first指向当前元素所在缓冲区的头,last指向当前元素所在缓冲区的尾的下一个,而node指向当前缓冲区被指向的map(中控数组)元素
因此,deque要借助迭代器维护假想的连续空间,就会非常复杂
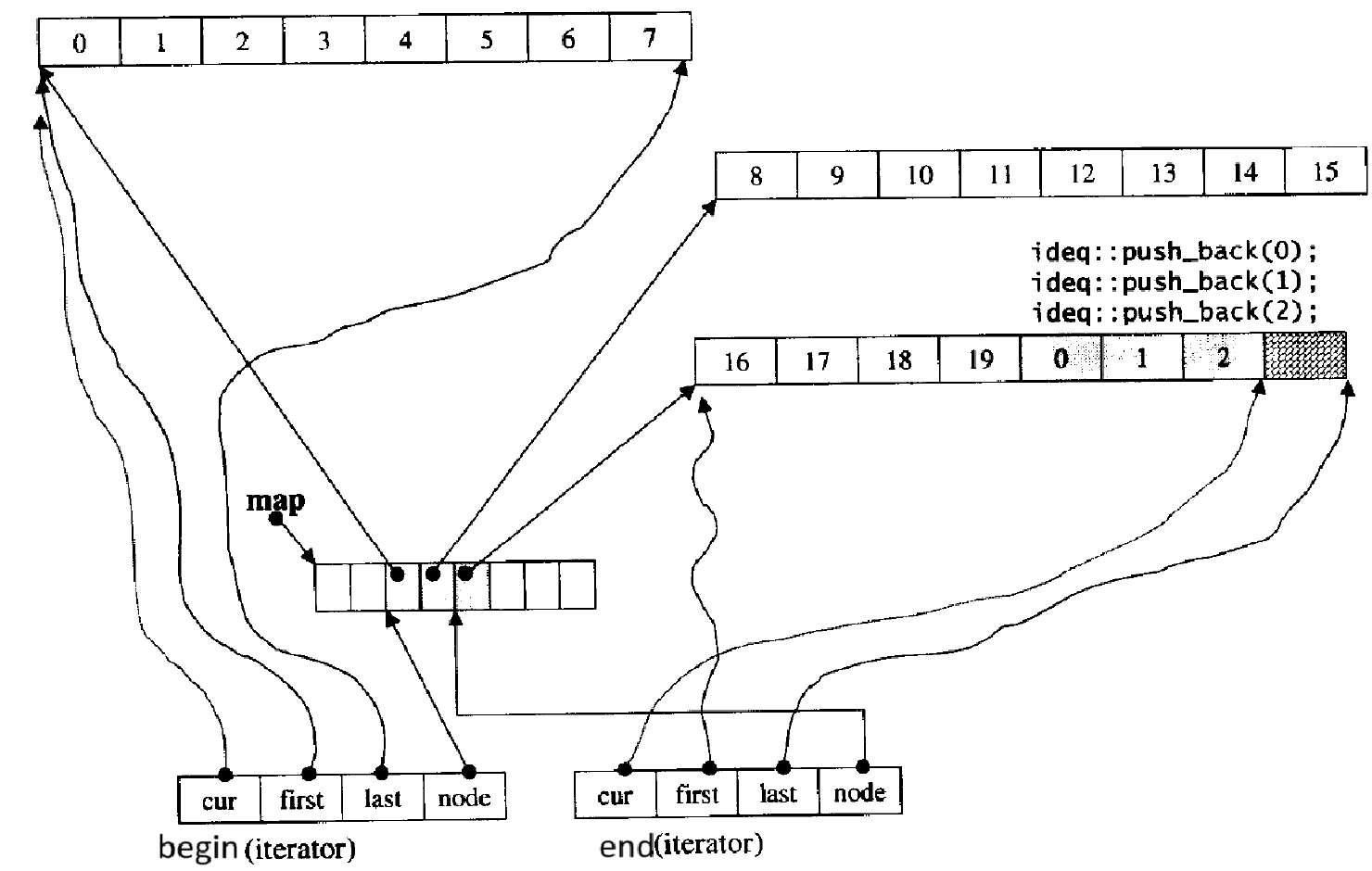
那它同时具备了vector和list的优点,代价是什么呢?
#include <iostream>
#include <vector>
#include <deque>
#include <time.h>
#include <algorithm>
using namespace std;
int main()
{deque<int> dq;vector<int> v;int n = 100000;int i = 0;srand(time(NULL));for (int i = 0; i < n; i++){int x = rand();dq.push_back(x);v.push_back(x);}size_t start1 = clock();sort(dq.begin(), dq.end());size_t end1 = clock();size_t start2 = clock();sort(v.begin(), v.end());size_t end2 = clock();cout << "Deque: " << (end1 - start1) << endl;cout << "Vector: " << (end2 - start2) << endl;return 0;
}这段代码,分别对vector和deque的实例化类进行排序,记录下他们各自所用的毫秒数
输出结果:
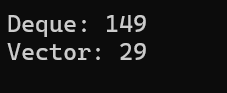
可以看到,虽然deque支持随机访问,也间接支持二分查找,排序等算法,但它的效率在数据很多时会和vector有明显差距
因为deque的operator[]实现需要计算访问的第i个数据在哪个buffer中,当数据量大了之后,效率就变低了
这也是为什么deque没有替代vector和list的原因
但为什么栈和队列的默认容器是deque呢?
stack和queue中也没用用到它的随机访问,只用到了头尾的插删操作,而deque的插删操作效率还是很高的
priority_queue(优先级队列)
在头文件<queue>中,除了queue(队列),还有一个priority_queue(优先级队列),它也是一个容器适配器,那优先级队列和队列有啥区别呢?
priority_queue<int> pq;
pq.push(2);
pq.push(5);
pq.push(1);
pq.push(6);
pq.push(3);
while (!pq.empty())
{cout << pq.top() << " ";pq.pop();
}如果pq是queue的话,这段代码输出的应该是2 5 1 6 3,因为先进先出嘛
但实际输出结果是

这既不是先进先出,也不是后进先出。
优先级队列, 顾名思义,就是优先级大的先出队,而默认是越大的数优先级越高,所以也可以用于排序
那我如果想改越小的数优先级越高要怎么改呢?(也就是输出时是升序)

这是优先级队列的模板原型,可以看到除了另外两个容器适配器有的class T 和 class Container,还有一个class Compare,并且它的默认值是less
这里的Compare是一个仿函数,用来指定比较的方式,而默认是less<T>,就说明如果传的是less,就是数越大优先级越高与less相对应的是greater<T>,就是数越小优先级越高
priority_queue<int,vector<int>,greater<int>> pq;//要想改Compare参数,就得先写上前面的Container参数
pq.push(2);
pq.push(5);
pq.push(1);
pq.push(6);
pq.push(3);
while (!pq.empty())
{cout << pq.top() << " ";pq.pop();
}输出结果:
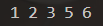
less和greater都是std中已经有的仿函数,所以可以直接调用
数组中第K个最大元素:

在知道了优先级队列的用法之后,这道题看似很简单
int findKthLargest(vector<int>& nums, int k)
{priority_queue<int> pq;int i=0;while(i<nums.size()){pq.push(nums[i]);i++;}k--;while(k--){pq.pop();}return pq.top();
}但这样实现的时间复杂度是O(N*log(n)),而题目要求必须是O(N)
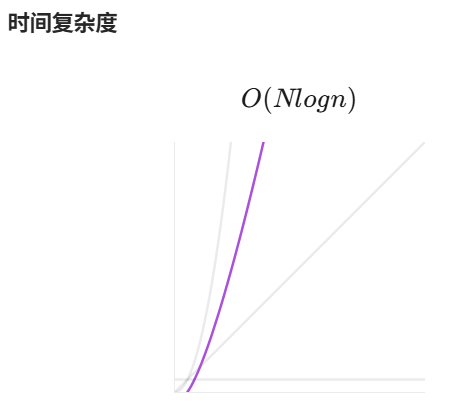
这道题其实是需要用TopK问题的思路来解
而TopK问题需要用到什么呢?堆
不了解TopK问题的可以看我的这篇文章
【基础算法】堆排序与TopK问题(C语言)
有点开阔了没?没错,优先级队列的逻辑就是堆
当Compare参数传的是less<T>时,这就是一个大堆,反之就是小堆
参考代码:
int findKthLargest(vector<int>& nums, int k)
{priority_queue<int,vector<int>,greater<int>> pq;//建一个小堆int i;for(i=0;i<k;i++)//把前k个元素入堆{pq.push(nums[i]);}//现在堆顶的数据就是前k个元素最小的那个while(i<nums.size()){if(pq.top() < nums[i])//如果当前元素比堆顶的元素大,就交换(删掉原堆顶数据,让当前元素入堆){pq.pop();pq.push(nums[i]);}i++;}//现在堆顶的元素就是最大的K个元素中最小的那个了,也就是第K个最大元素return pq.top();
}上述代码的时间复杂度就是O(N*log(K))(在长度为K的堆中插入数据,时间复杂度是logK)
