[Kaggle]:使用Kaggle服务器训练YOLOv5模型 (白嫖服务器)
![[LOGO]:CoreKSets](https://i-blog.csdnimg.cn/direct/731088657ae348d4a1f679ad3008534a.png)
【核知坊】:释放青春想象,码动全新视野。
我们希望使用精简的信息传达知识的骨架,启发创造者开启创造之路!!!
内容摘要:最近需要使用 YOLOv5 框架训练一个识别模型,数据集有5000多张图片,直接在3000笔记本CPU上跑,怕是要几天。于是付费使用 OpenBayes 的云服务器,但云服务器使用价格较贵,配置重复。对小众需求者不太友好,于是我去 Kaggle 尝试了白嫖服务器,并成功训练了自己的模型。
关键词:YOLOv5 Kaggle 模型训练
其他相关文章:
⛏。。。
高性能云服务器OpenBayes
花钱去OpenBayes开云计算服务器进行模型训练,花钱训练的就是快,大内存可以直接配置 batch-size 批次 32 或者 64。头疼的的每次启动都要配置一下环境,下载一些依赖包(关闭会被清除,不清楚原因),正式开始使用之前都要花费10分钟时间。用了几天,花了我50块大洋后,心疼不已,于是去Kaggle看看能不能免费训练。
OpenBayes对新用户优惠力度很大,注册赠送 240 分钟 RTX 4090 使用时长+ 300 分钟高性能 CPU 使用时长。直接点击前往:signup - OpenBayes
Kaggle
Kaggle 是一个全球领先的数据科学和机器学习平台,由 Anthony Goldbloom 和 Ben Hamner 于 2010 年创立,并于 2017 年被 Google 收购,现为 Google LLC 的子公司。Kaggle 提供了一个在线社区,汇聚了来自世界各地的数据科学家和机器学习工程师,致力于通过竞赛、数据集分享和代码协作推动人工智能的发展。
🎁 Kaggle 每周福利:免费 GPU 使用
✅ 每周 30 小时免费 GPU 资源
Kaggle 为每位用户每周提供 30 小时 的免费 GPU 使用时间。这些 GPU 资源可用于在 Kaggle 的 Jupyter Notebook 环境中运行和训练模型。
💻 支持的 GPU 类型
Kaggle 提供的 GPU 类型包括:
-
NVIDIA Tesla P100:16GB 显存,适合大多数深度学习任务。
-
NVIDIA T4:15GB 显存,支持混合精度计算,适用于推理和训练任务。
用户可以在 Notebook 设置中选择所需的 GPU 类型。
⏱️ 使用限制
-
单次运行时间:每次 Notebook 会话最长可运行 12 小时,超过时间将被强制中断。
-
每周总时长:每位用户每周最多可使用 30 小时 的 GPU 资源。
🌟 Kaggle 的核心功能
1. 竞赛(Competitions)
Kaggle 的竞赛平台允许企业和研究机构发布实际问题和数据集,吸引全球的数据科学家参与解决。参赛者需在规定时间内提交模型,平台根据预设的评估指标(如准确率、AUC 等)进行排名。优胜者不仅可获得奖金,还可能获得与赞助企业合作的机会,甚至直接受聘于这些公司。PyTorch Tutorial
2.数据集(Datasets)
Kaggle 提供了丰富的开放数据集,涵盖自然语言处理、计算机视觉、金融分析等多个领域。用户可以浏览、下载这些数据集,用于学习、研究或项目开发。kaggle-china.com
3.代码共享(Code / Notebooks)
Kaggle 提供基于云的 Jupyter Notebook 环境,称为 Kernels,用户可以在其中编写、运行和分享代码,进行数据分析和模型训练。这促进了社区成员之间的协作与学习。kaggle-china.com
4.学习资源(Kaggle Learn)
Kaggle Learn 提供了一系列免费的微课程,涵盖 Python 编程、数据可视化、机器学习、深度学习等主题,帮助用户系统地提升技能。
数据集上传
数据集准备:
按照YOLO要求的格式,把数据集整理好后打包为 data.zip 压缩包: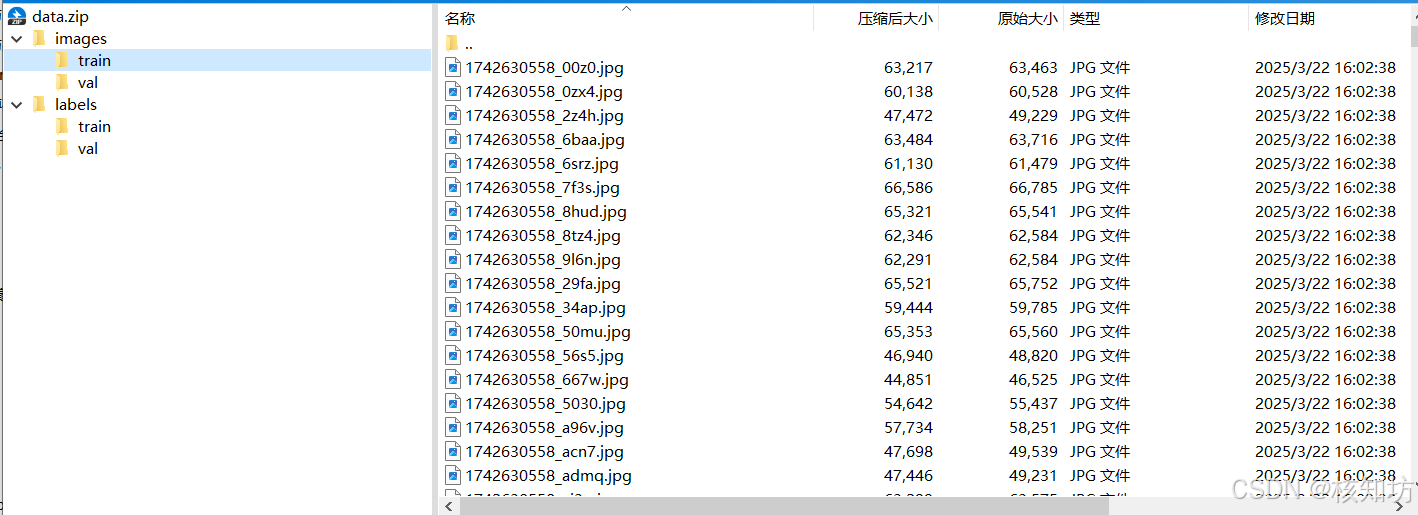
登录或注册Kaggle后点击左侧导航栏 You Work :
点击 Create,选择 New Dataset:
点击 New Dataset:
右侧会出现上传界面,点击上传 data.zip 压缩包,该过程看你的数据大小,需要耐心等待。输入数据集名称,可以追加上传更多文件。最后点击右下角 Create 完成数据集创建。
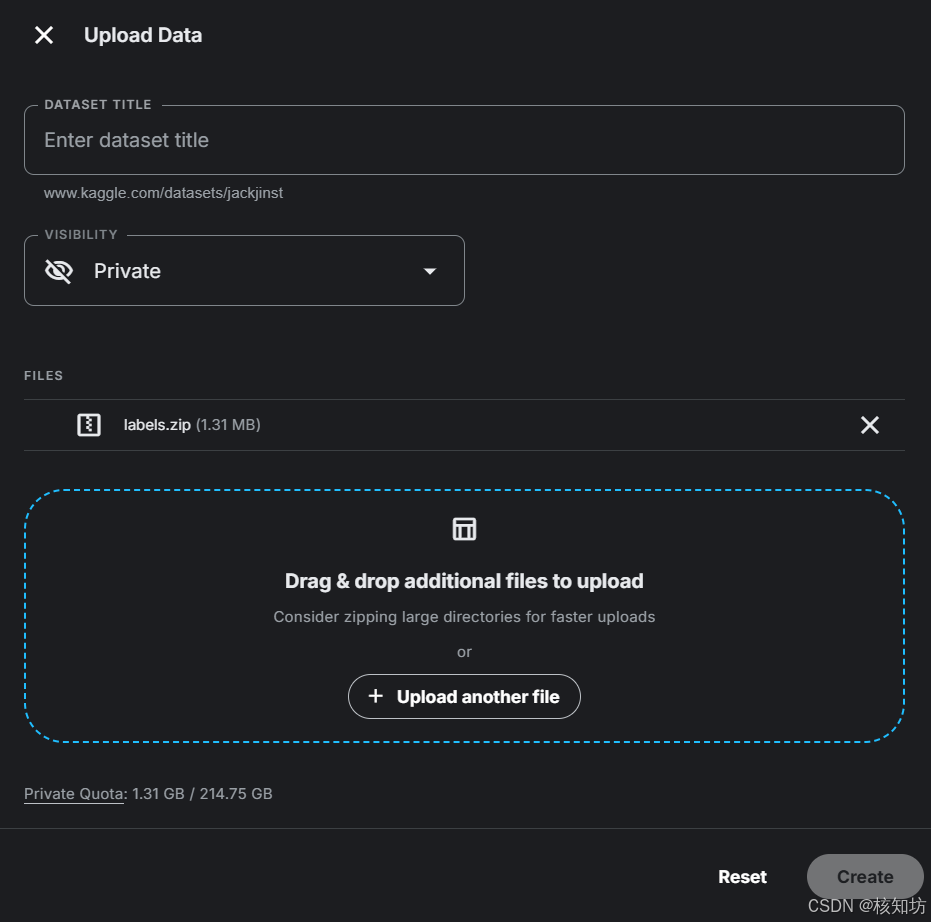
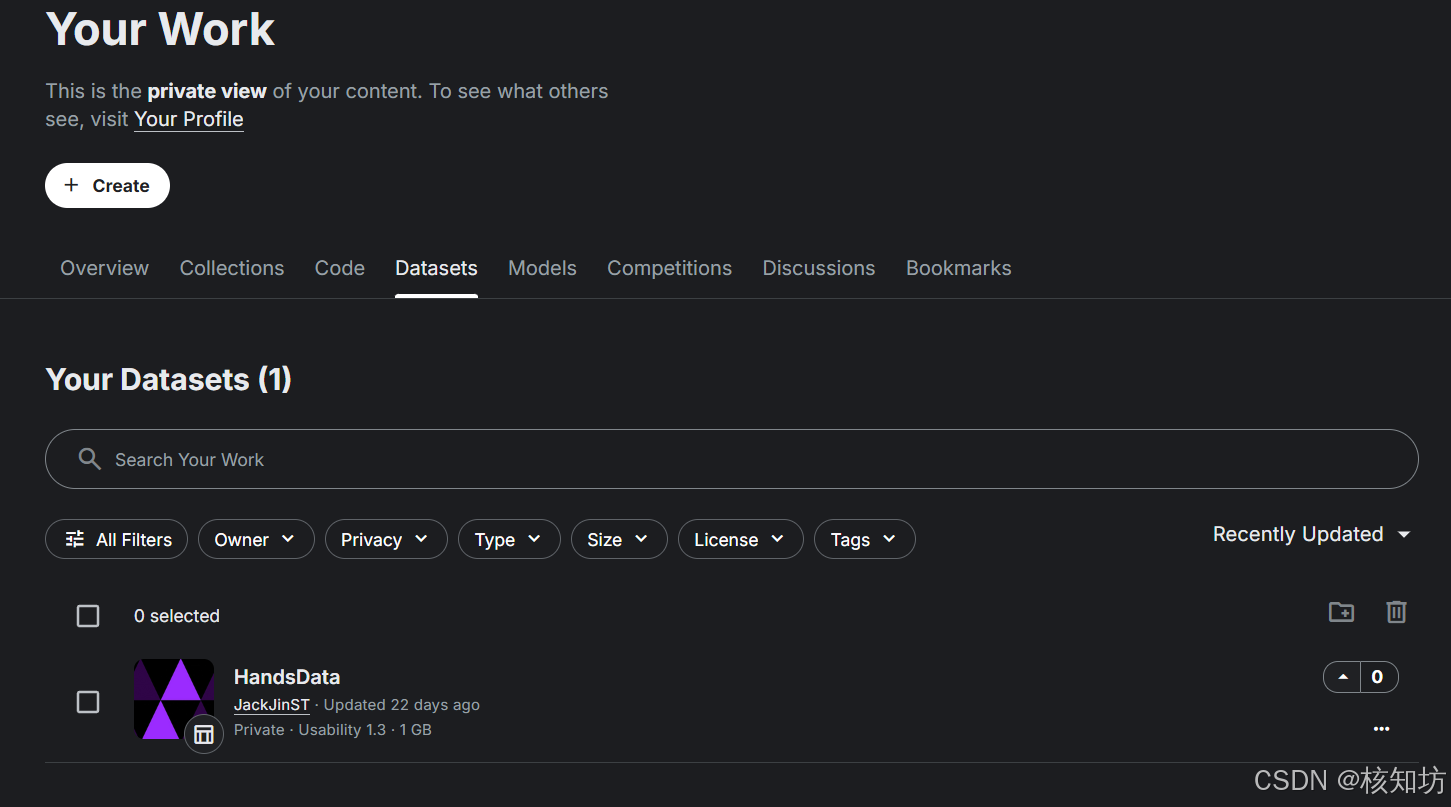
创建成功后你可以在左侧导航栏的 You Work 内的 DataSets 看到所有你的数据集。
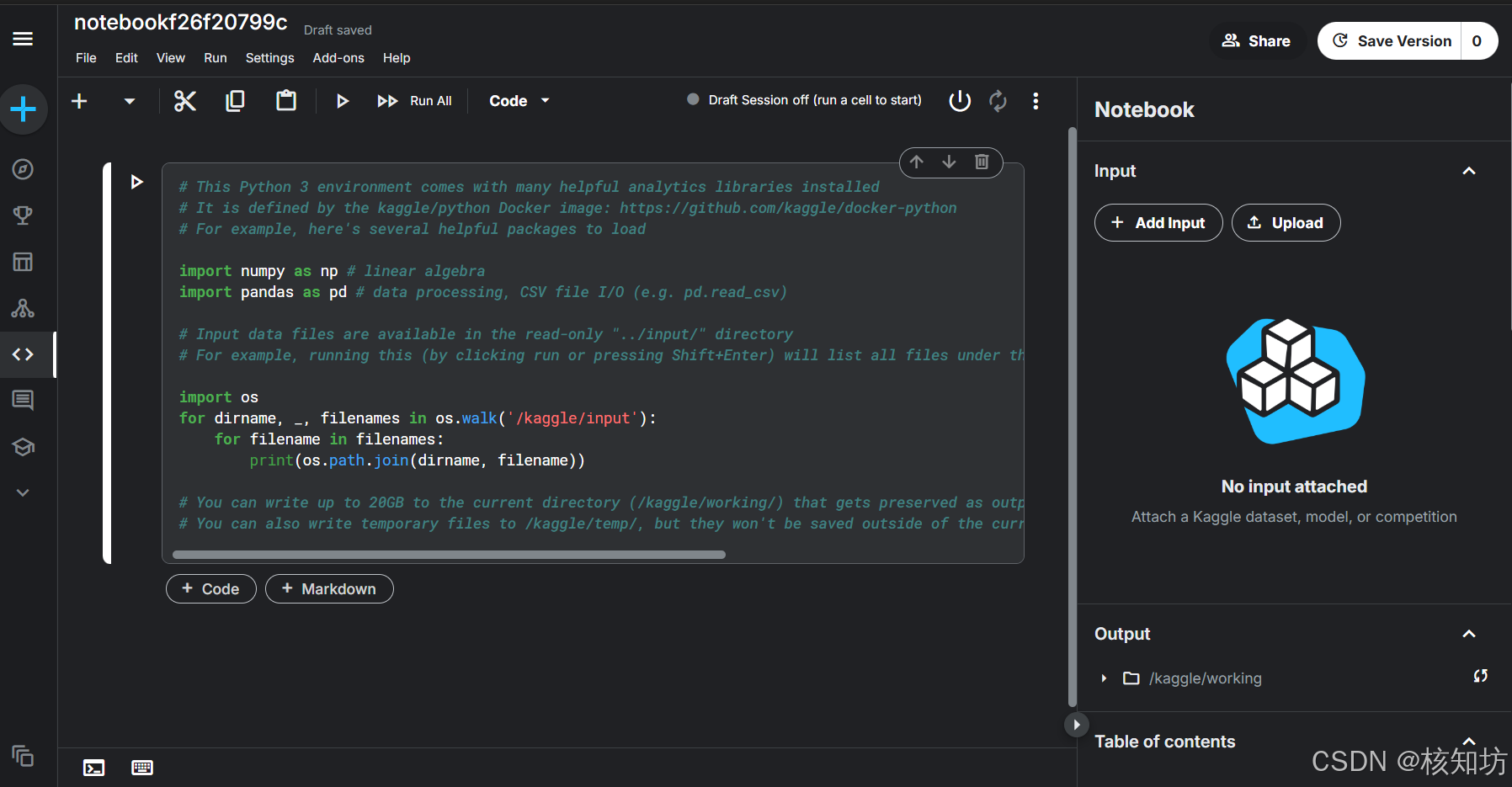
创建编辑器(NoteBook)
点击 Create,选择 New Notebook:
绑定数据集
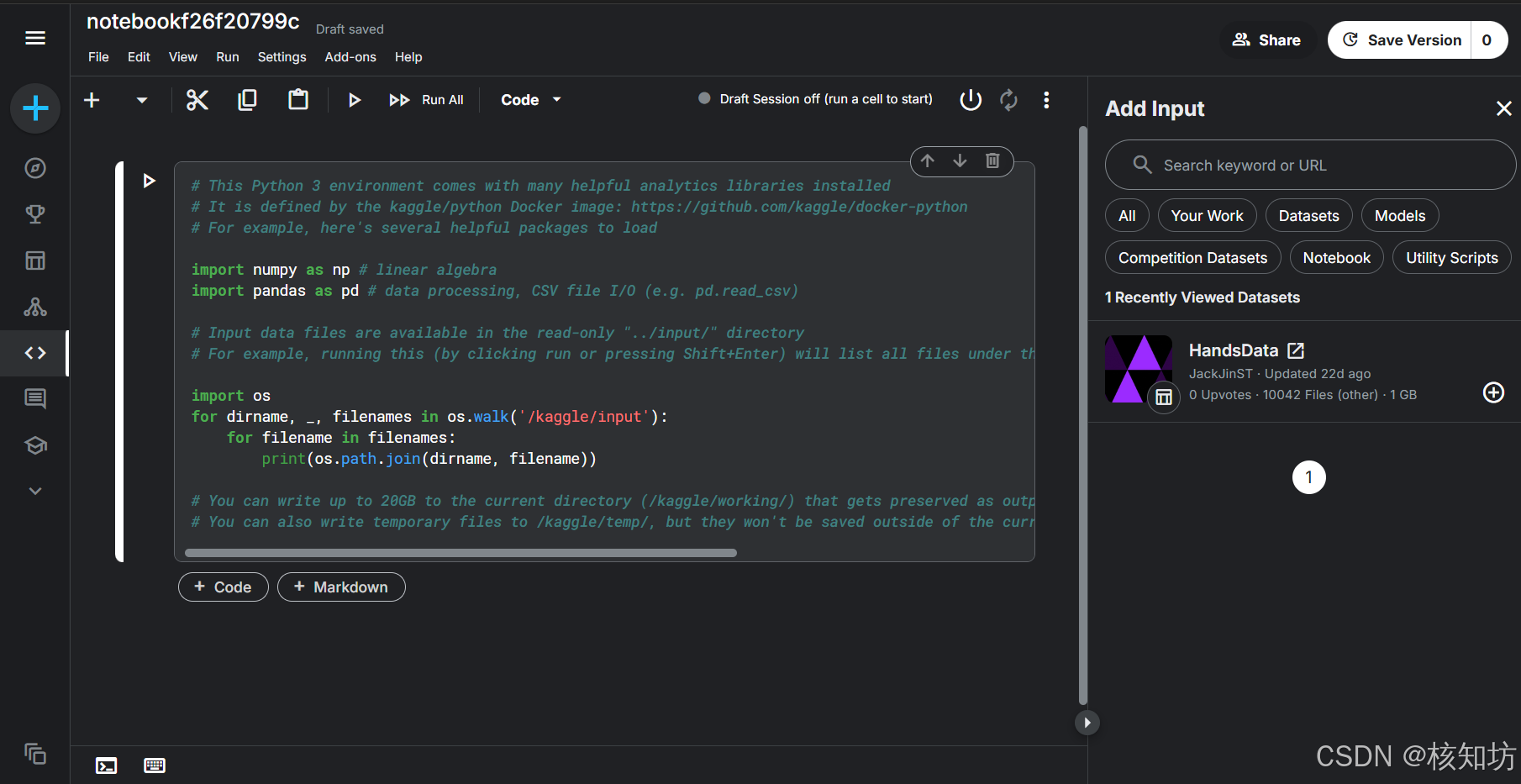
进入界面后,点击右侧 +Add Input 按钮预览数据集,如果你预览过自己刚上传的数据库,就可以直接看到它,没有请去预览一下。
然后点击你的数据库选项右下角的 ➕ 号:
配置YOLOv5框架
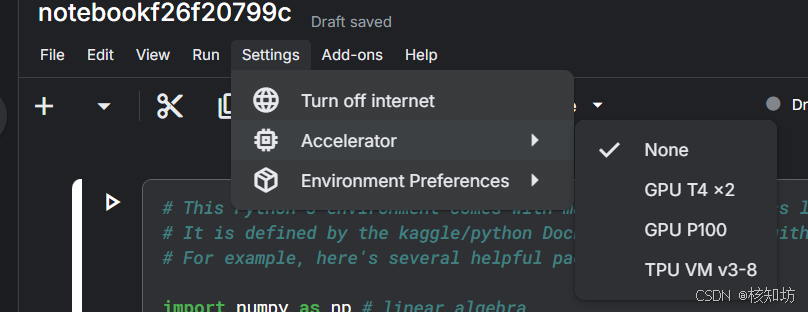
现在开始,直接使用编辑器开始运行代码,服务器型号可以在 Settings->Accelerator 选择:
第一次运行代码时系统自动启动服务器
语法规则(英文):
-
shell 命令: 使用感叹号“!” 作为前缀,直接可以在编辑器中运行。
-
python 代码:直接写
拉取YOLOv5框架源码,等待下载完成:
!git clone https://github.com/ultralytics/yolov5完成后,你可以在右侧状态栏看到文件夹目录:
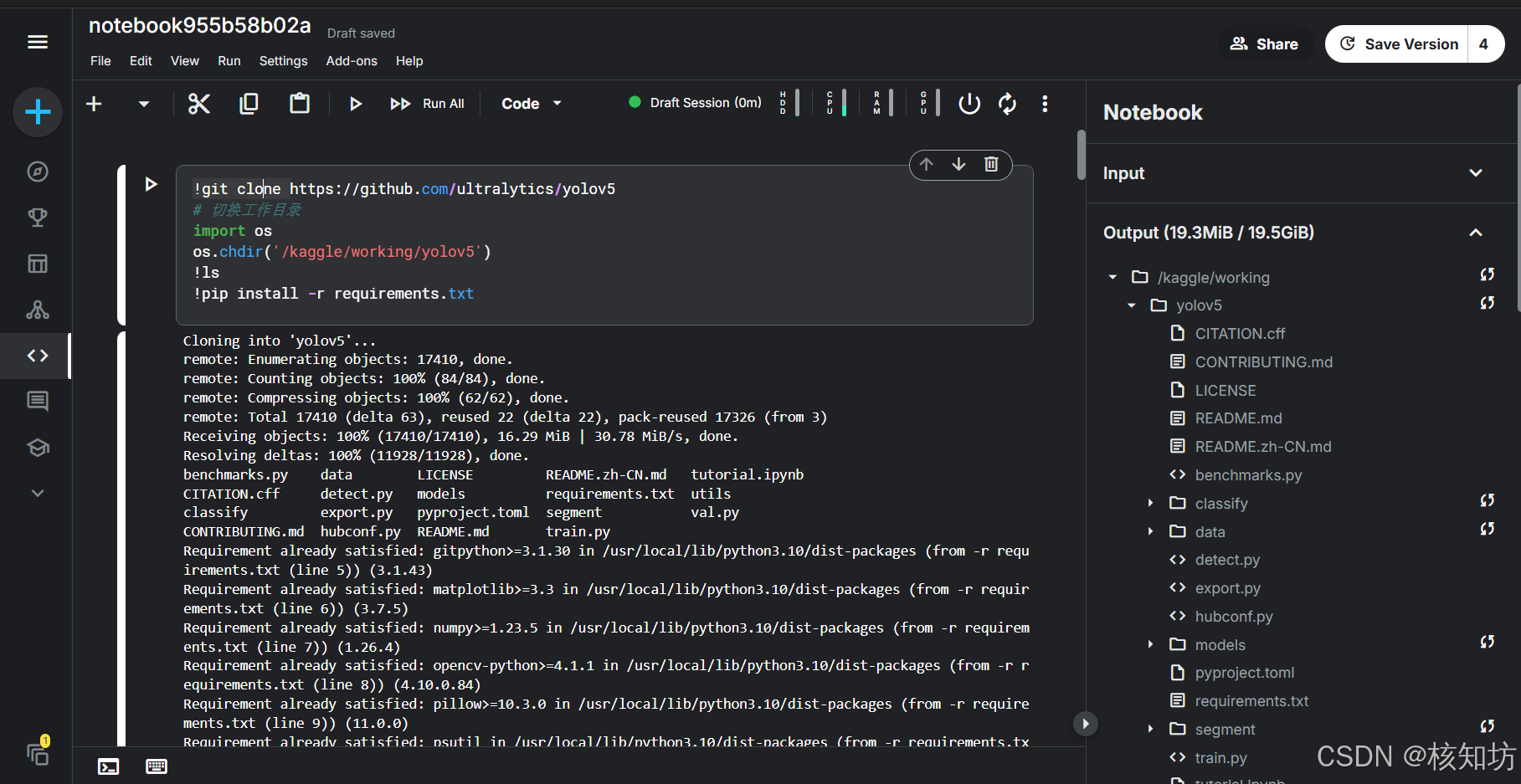
切换目录,进入yolov5框架,安装依赖:
# 切换工作目录
import os
os.chdir('/kaggle/working/yolov5')
!ls
!pip install -r requirements.txt现在,可以为所欲为了!!!但是Kaggel的编辑器不能在线编辑框架里的源码,所以我们直接使用整个文件内容替换命令:第一行 (%%writefile + 文件路径 ), 第一行下的所有内容会覆盖原始文件内容。我建议,自己在笔记本上修改,改好后直接复制粘贴。注意路径前缀 /kaggle/working/
配置数据集
%%writefile /kaggle/working/yolov5/data/coco128.yaml
path: /kaggle/input/handsdata
%%writefile /kaggle/working/yolov5/data/coco128.yaml
# 修改coco128
path: /kaggle/input/handsdata
train: images/train
val: images/val
nc: 1
names: ['Hand']修改超参数文件(进阶,可选)
%%writefile /kaggle/working/yolov5/data/hyps/hyp.scratch-low.yaml
# 修改超参数文件
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
修改模型结构文件(进阶,可选)
%%writefile /kaggle/working/yolov5/models/yolov5n.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32
activation: nn.SiLU()
# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 1, C3, [128, 1]], # 2[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 1, C3, [256, 1]], # 4[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 1, C3, [512, 1]], # 6[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 1, C3, [1024, 1]], # 8[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 1, C3, [512, 1]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 1, C3, [256, 1]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 13], 1, Concat, [1]], # cat head P4[-1, 1, C3, [512, 1]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 9], 1, Concat, [1]], # cat head P5[-1, 1, C3, [1024, 1]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
配置模块输入参数(进阶,可选)
%%writefile /kaggle/working/yolov5/models/common.py
# 修改 common.py# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
"""Common modules."""import ast
import contextlib
import json
import math
import platform
import warnings
import zipfile
from collections import OrderedDict, namedtuple
from copy import copy
from pathlib import Path
from urllib.parse import urlparseimport cv2
import numpy as np
import pandas as pd
import requests
import torch
import torch.nn as nn
from PIL import Image
from torch.cuda import amp# Import 'ultralytics' package or install if missing
try:import ultralyticsassert hasattr(ultralytics, "__version__") # verify package is not directory
except (ImportError, AssertionError):import osos.system("pip install -U ultralytics")import ultralyticsfrom ultralytics.utils.plotting import Annotator, colors, save_one_boxfrom utils import TryExcept
from utils.dataloaders import exif_transpose, letterbox
from utils.general import (LOGGER,ROOT,Profile,check_requirements,check_suffix,check_version,colorstr,increment_path,is_jupyter,make_divisible,non_max_suppression,scale_boxes,xywh2xyxy,xyxy2xywh,yaml_load,
)
from utils.torch_utils import copy_attr, smart_inference_modedef autopad(k, p=None, d=1):"""Pads kernel to 'same' output shape, adjusting for optional dilation; returns padding size.`k`: kernel, `p`: padding, `d`: dilation."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):"""Applies a convolution, batch normalization, and activation function to an input tensor in a neural network."""default_act = nn.ReLU6() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""Initializes a standard convolution layer with optional batch normalization and activation."""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""Applies a convolution followed by batch normalization and an activation function to the input tensor `x`."""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""Applies a fused convolution and activation function to the input tensor `x`."""return self.act(self.conv(x))class DWConv(Conv):"""Implements a depth-wise convolution layer with optional activation for efficient spatial filtering."""def __init__(self, c1, c2, k=1, s=1, d=1, act=True):"""Initializes a depth-wise convolution layer with optional activation; args: input channels (c1), outputchannels (c2), kernel size (k), stride (s), dilation (d), and activation flag (act)."""super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)class DWConvTranspose2d(nn.ConvTranspose2d):"""A depth-wise transpose convolutional layer for upsampling in neural networks, particularly in YOLOv5 models."""def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0):"""Initializes a depth-wise transpose convolutional layer for YOLOv5; args: input channels (c1), output channels(c2), kernel size (k), stride (s), input padding (p1), output padding (p2)."""super().__init__(c1, c2, k, s, p1, p2, groups=math.gcd(c1, c2))class TransformerLayer(nn.Module):"""Transformer layer with multihead attention and linear layers, optimized by removing LayerNorm."""def __init__(self, c, num_heads):"""Initializes a transformer layer, sans LayerNorm for performance, with multihead attention and linear layers.See as described in https://arxiv.org/abs/2010.11929."""super().__init__()self.q = nn.Linear(c, c, bias=False)self.k = nn.Linear(c, c, bias=False)self.v = nn.Linear(c, c, bias=False)self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)self.fc1 = nn.Linear(c, c, bias=False)self.fc2 = nn.Linear(c, c, bias=False)def forward(self, x):"""Performs forward pass using MultiheadAttention and two linear transformations with residual connections."""x = self.ma(self.q(x), self.k(x), self.v(x))[0] + xx = self.fc2(self.fc1(x)) + xreturn xclass TransformerBlock(nn.Module):"""A Transformer block for vision tasks with convolution, position embeddings, and Transformer layers."""def __init__(self, c1, c2, num_heads, num_layers):"""Initializes a Transformer block for vision tasks, adapting dimensions if necessary and stacking specifiedlayers."""super().__init__()self.conv = Noneif c1 != c2:self.conv = Conv(c1, c2)self.linear = nn.Linear(c2, c2) # learnable position embeddingself.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))self.c2 = c2def forward(self, x):"""Processes input through an optional convolution, followed by Transformer layers and position embeddings forobject detection."""if self.conv is not None:x = self.conv(x)b, _, w, h = x.shapep = x.flatten(2).permute(2, 0, 1)return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)class Bottleneck(nn.Module):"""A bottleneck layer with optional shortcut and group convolution for efficient feature extraction."""def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):"""Initializes a standard bottleneck layer with optional shortcut and group convolution, supporting channelexpansion."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):"""Processes input through two convolutions, optionally adds shortcut if channel dimensions match; input is atensor."""return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class BottleneckCSP(nn.Module):"""CSP bottleneck layer for feature extraction with cross-stage partial connections and optional shortcuts."""def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):"""Initializes CSP bottleneck with optional shortcuts; args: ch_in, ch_out, number of repeats, shortcut bool,groups, expansion."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)self.cv4 = Conv(2 * c_, c2, 1, 1)self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)self.act = nn.SiLU()self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):"""Performs forward pass by applying layers, activation, and concatenation on input x, returning feature-enhanced output."""y1 = self.cv3(self.m(self.cv1(x)))y2 = self.cv2(x)return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))class CrossConv(nn.Module):"""Implements a cross convolution layer with downsampling, expansion, and optional shortcut."""def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):"""Initializes CrossConv with downsampling, expanding, and optionally shortcutting; `c1` input, `c2` outputchannels.Inputs are ch_in, ch_out, kernel, stride, groups, expansion, shortcut."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, (1, k), (1, s))self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)self.add = shortcut and c1 == c2def forward(self, x):"""Performs feature sampling, expanding, and applies shortcut if channels match; expects `x` input tensor."""return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C3(nn.Module):"""Implements a CSP Bottleneck module with three convolutions for enhanced feature extraction in neural networks."""def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):"""Initializes C3 module with options for channel count, bottleneck repetition, shortcut usage, groupconvolutions, and expansion."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):"""Performs forward propagation using concatenated outputs from two convolutions and a Bottleneck sequence."""return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))class C3x(C3):"""Extends the C3 module with cross-convolutions for enhanced feature extraction in neural networks."""def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):"""Initializes C3x module with cross-convolutions, extending C3 with customizable channel dimensions, groups,and expansion."""super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e)self.m = nn.Sequential(*(CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)))class C3TR(C3):"""C3 module with TransformerBlock for enhanced feature extraction in object detection models."""def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):"""Initializes C3 module with TransformerBlock for enhanced feature extraction, accepts channel sizes, shortcutconfig, group, and expansion."""super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e)self.m = TransformerBlock(c_, c_, 4, n)class C3SPP(C3):"""Extends the C3 module with an SPP layer for enhanced spatial feature extraction and customizable channels."""def __init__(self, c1, c2, k=(5, 9, 13), n=1, shortcut=True, g=1, e=0.5):"""Initializes a C3 module with SPP layer for advanced spatial feature extraction, given channel sizes, kernelsizes, shortcut, group, and expansion ratio."""super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e)self.m = SPP(c_, c_, k)class C3Ghost(C3):"""Implements a C3 module with Ghost Bottlenecks for efficient feature extraction in YOLOv5."""def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):"""Initializes YOLOv5's C3 module with Ghost Bottlenecks for efficient feature extraction."""super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e) # hidden channelsself.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))class SPP(nn.Module):"""Implements Spatial Pyramid Pooling (SPP) for feature extraction, ref: https://arxiv.org/abs/1406.4729."""def __init__(self, c1, c2, k=(5, 9, 13)):"""Initializes SPP layer with Spatial Pyramid Pooling, ref: https://arxiv.org/abs/1406.4729, args: c1 (input channels), c2 (output channels), k (kernel sizes)."""super().__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])def forward(self, x):"""Applies convolution and max pooling layers to the input tensor `x`, concatenates results, and returns outputtensor."""x = self.cv1(x)with warnings.catch_warnings():warnings.simplefilter("ignore") # suppress torch 1.9.0 max_pool2d() warningreturn self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))class SPPF(nn.Module):"""Implements a fast Spatial Pyramid Pooling (SPPF) layer for efficient feature extraction in YOLOv5 models."""def __init__(self, c1, c2, k=5):"""Initializes YOLOv5 SPPF layer with given channels and kernel size for YOLOv5 model, combining convolution andmax pooling.Equivalent to SPP(k=(5, 9, 13))."""super().__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * 4, c2, 1, 1)self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)def forward(self, x):"""Processes input through a series of convolutions and max pooling operations for feature extraction."""x = self.cv1(x)with warnings.catch_warnings():warnings.simplefilter("ignore") # suppress torch 1.9.0 max_pool2d() warningy1 = self.m(x)y2 = self.m(y1)return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))class Focus(nn.Module):"""Focuses spatial information into channel space using slicing and convolution for efficient feature extraction."""def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):"""Initializes Focus module to concentrate width-height info into channel space with configurable convolutionparameters."""super().__init__()self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)# self.contract = Contract(gain=2)def forward(self, x):"""Processes input through Focus mechanism, reshaping (b,c,w,h) to (b,4c,w/2,h/2) then applies convolution."""return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))# return self.conv(self.contract(x))class GhostConv(nn.Module):"""Implements Ghost Convolution for efficient feature extraction, see https://github.com/huawei-noah/ghostnet."""def __init__(self, c1, c2, k=1, s=1, g=1, act=True):"""Initializes GhostConv with in/out channels, kernel size, stride, groups, and activation; halves out channelsfor efficiency."""super().__init__()c_ = c2 // 2 # hidden channelsself.cv1 = Conv(c1, c_, k, s, None, g, act=act)self.cv2 = Conv(c_, c_, 5, 1, None, c_, act=act)def forward(self, x):"""Performs forward pass, concatenating outputs of two convolutions on input `x`: shape (B,C,H,W)."""y = self.cv1(x)return torch.cat((y, self.cv2(y)), 1)class GhostBottleneck(nn.Module):"""Efficient bottleneck layer using Ghost Convolutions, see https://github.com/huawei-noah/ghostnet."""def __init__(self, c1, c2, k=3, s=1):"""Initializes GhostBottleneck with ch_in `c1`, ch_out `c2`, kernel size `k`, stride `s`; see https://github.com/huawei-noah/ghostnet."""super().__init__()c_ = c2 // 2self.conv = nn.Sequential(GhostConv(c1, c_, 1, 1), # pwDWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dwGhostConv(c_, c2, 1, 1, act=False),) # pw-linearself.shortcut = (nn.Sequential(DWConv(c1, c1, k, s, act=False), Conv(c1, c2, 1, 1, act=False)) if s == 2 else nn.Identity())def forward(self, x):"""Processes input through conv and shortcut layers, returning their summed output."""return self.conv(x) + self.shortcut(x)class Contract(nn.Module):"""Contracts spatial dimensions into channel dimensions for efficient processing in neural networks."""def __init__(self, gain=2):"""Initializes a layer to contract spatial dimensions (width-height) into channels, e.g., input shape(1,64,80,80) to (1,256,40,40)."""super().__init__()self.gain = gaindef forward(self, x):"""Processes input tensor to expand channel dimensions by contracting spatial dimensions, yielding output shape`(b, c*s*s, h//s, w//s)`."""b, c, h, w = x.size() # assert (h / s == 0) and (W / s == 0), 'Indivisible gain's = self.gainx = x.view(b, c, h // s, s, w // s, s) # x(1,64,40,2,40,2)x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)return x.view(b, c * s * s, h // s, w // s) # x(1,256,40,40)class Expand(nn.Module):"""Expands spatial dimensions by redistributing channels, e.g., from (1,64,80,80) to (1,16,160,160)."""def __init__(self, gain=2):"""Initializes the Expand module to increase spatial dimensions by redistributing channels, with an optional gainfactor.Example: x(1,64,80,80) to x(1,16,160,160)."""super().__init__()self.gain = gaindef forward(self, x):"""Processes input tensor x to expand spatial dimensions by redistributing channels, requiring C / gain^2 ==0."""b, c, h, w = x.size() # assert C / s ** 2 == 0, 'Indivisible gain's = self.gainx = x.view(b, s, s, c // s**2, h, w) # x(1,2,2,16,80,80)x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)return x.view(b, c // s**2, h * s, w * s) # x(1,16,160,160)class Concat(nn.Module):"""Concatenates tensors along a specified dimension for efficient tensor manipulation in neural networks."""def __init__(self, dimension=1):"""Initializes a Concat module to concatenate tensors along a specified dimension."""super().__init__()self.d = dimensiondef forward(self, x):"""Concatenates a list of tensors along a specified dimension; `x` is a list of tensors, `dimension` is anint."""return torch.cat(x, self.d)class DetectMultiBackend(nn.Module):"""YOLOv5 MultiBackend class for inference on various backends including PyTorch, ONNX, TensorRT, and more."""def __init__(self, weights="yolov5s.pt", device=torch.device("cpu"), dnn=False, data=None, fp16=False, fuse=True):"""Initializes DetectMultiBackend with support for various inference backends, including PyTorch and ONNX."""# PyTorch: weights = *.pt# TorchScript: *.torchscript# ONNX Runtime: *.onnx# ONNX OpenCV DNN: *.onnx --dnn# OpenVINO: *_openvino_model# CoreML: *.mlpackage# TensorRT: *.engine# TensorFlow SavedModel: *_saved_model# TensorFlow GraphDef: *.pb# TensorFlow Lite: *.tflite# TensorFlow Edge TPU: *_edgetpu.tflite# PaddlePaddle: *_paddle_modelfrom models.experimental import attempt_download, attempt_load # scoped to avoid circular importsuper().__init__()w = str(weights[0] if isinstance(weights, list) else weights)pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle, triton = self._model_type(w)fp16 &= pt or jit or onnx or engine or triton # FP16nhwc = coreml or saved_model or pb or tflite or edgetpu # BHWC formats (vs torch BCWH)stride = 32 # default stridecuda = torch.cuda.is_available() and device.type != "cpu" # use CUDAif not (pt or triton):w = attempt_download(w) # download if not localif pt: # PyTorchmodel = attempt_load(weights if isinstance(weights, list) else w, device=device, inplace=True, fuse=fuse)stride = max(int(model.stride.max()), 32) # model stridenames = model.module.names if hasattr(model, "module") else model.names # get class namesmodel.half() if fp16 else model.float()self.model = model # explicitly assign for to(), cpu(), cuda(), half()elif jit: # TorchScriptLOGGER.info(f"Loading {w} for TorchScript inference...")extra_files = {"config.txt": ""} # model metadatamodel = torch.jit.load(w, _extra_files=extra_files, map_location=device)model.half() if fp16 else model.float()if extra_files["config.txt"]: # load metadata dictd = json.loads(extra_files["config.txt"],object_hook=lambda d: {int(k) if k.isdigit() else k: v for k, v in d.items()},)stride, names = int(d["stride"]), d["names"]elif dnn: # ONNX OpenCV DNNLOGGER.info(f"Loading {w} for ONNX OpenCV DNN inference...")check_requirements("opencv-python>=4.5.4")net = cv2.dnn.readNetFromONNX(w)elif onnx: # ONNX RuntimeLOGGER.info(f"Loading {w} for ONNX Runtime inference...")check_requirements(("onnx", "onnxruntime-gpu" if cuda else "onnxruntime"))import onnxruntimeproviders = ["CUDAExecutionProvider", "CPUExecutionProvider"] if cuda else ["CPUExecutionProvider"]session = onnxruntime.InferenceSession(w, providers=providers)output_names = [x.name for x in session.get_outputs()]meta = session.get_modelmeta().custom_metadata_map # metadataif "stride" in meta:stride, names = int(meta["stride"]), eval(meta["names"])elif xml: # OpenVINOLOGGER.info(f"Loading {w} for OpenVINO inference...")check_requirements("openvino>=2023.0") # requires openvino-dev: https://pypi.org/project/openvino-dev/from openvino.runtime import Core, Layout, get_batchcore = Core()if not Path(w).is_file(): # if not *.xmlw = next(Path(w).glob("*.xml")) # get *.xml file from *_openvino_model dirov_model = core.read_model(model=w, weights=Path(w).with_suffix(".bin"))if ov_model.get_parameters()[0].get_layout().empty:ov_model.get_parameters()[0].set_layout(Layout("NCHW"))batch_dim = get_batch(ov_model)if batch_dim.is_static:batch_size = batch_dim.get_length()ov_compiled_model = core.compile_model(ov_model, device_name="AUTO") # AUTO selects best available devicestride, names = self._load_metadata(Path(w).with_suffix(".yaml")) # load metadataelif engine: # TensorRTLOGGER.info(f"Loading {w} for TensorRT inference...")import tensorrt as trt # https://developer.nvidia.com/nvidia-tensorrt-downloadcheck_version(trt.__version__, "7.0.0", hard=True) # require tensorrt>=7.0.0if device.type == "cpu":device = torch.device("cuda:0")Binding = namedtuple("Binding", ("name", "dtype", "shape", "data", "ptr"))logger = trt.Logger(trt.Logger.INFO)with open(w, "rb") as f, trt.Runtime(logger) as runtime:model = runtime.deserialize_cuda_engine(f.read())context = model.create_execution_context()bindings = OrderedDict()output_names = []fp16 = False # default updated belowdynamic = Falseis_trt10 = not hasattr(model, "num_bindings")num = range(model.num_io_tensors) if is_trt10 else range(model.num_bindings)for i in num:if is_trt10:name = model.get_tensor_name(i)dtype = trt.nptype(model.get_tensor_dtype(name))is_input = model.get_tensor_mode(name) == trt.TensorIOMode.INPUTif is_input:if -1 in tuple(model.get_tensor_shape(name)): # dynamicdynamic = Truecontext.set_input_shape(name, tuple(model.get_profile_shape(name, 0)[2]))if dtype == np.float16:fp16 = Trueelse: # outputoutput_names.append(name)shape = tuple(context.get_tensor_shape(name))else:name = model.get_binding_name(i)dtype = trt.nptype(model.get_binding_dtype(i))if model.binding_is_input(i):if -1 in tuple(model.get_binding_shape(i)): # dynamicdynamic = Truecontext.set_binding_shape(i, tuple(model.get_profile_shape(0, i)[2]))if dtype == np.float16:fp16 = Trueelse: # outputoutput_names.append(name)shape = tuple(context.get_binding_shape(i))im = torch.from_numpy(np.empty(shape, dtype=dtype)).to(device)bindings[name] = Binding(name, dtype, shape, im, int(im.data_ptr()))binding_addrs = OrderedDict((n, d.ptr) for n, d in bindings.items())batch_size = bindings["images"].shape[0] # if dynamic, this is instead max batch sizeelif coreml: # CoreMLLOGGER.info(f"Loading {w} for CoreML inference...")import coremltools as ctmodel = ct.models.MLModel(w)elif saved_model: # TF SavedModelLOGGER.info(f"Loading {w} for TensorFlow SavedModel inference...")import tensorflow as tfkeras = False # assume TF1 saved_modelmodel = tf.keras.models.load_model(w) if keras else tf.saved_model.load(w)elif pb: # GraphDef https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxtLOGGER.info(f"Loading {w} for TensorFlow GraphDef inference...")import tensorflow as tfdef wrap_frozen_graph(gd, inputs, outputs):"""Wraps a TensorFlow GraphDef for inference, returning a pruned function."""x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), []) # wrappedge = x.graph.as_graph_elementreturn x.prune(tf.nest.map_structure(ge, inputs), tf.nest.map_structure(ge, outputs))def gd_outputs(gd):"""Generates a sorted list of graph outputs excluding NoOp nodes and inputs, formatted as '<name>:0'."""name_list, input_list = [], []for node in gd.node: # tensorflow.core.framework.node_def_pb2.NodeDefname_list.append(node.name)input_list.extend(node.input)return sorted(f"{x}:0" for x in list(set(name_list) - set(input_list)) if not x.startswith("NoOp"))gd = tf.Graph().as_graph_def() # TF GraphDefwith open(w, "rb") as f:gd.ParseFromString(f.read())frozen_func = wrap_frozen_graph(gd, inputs="x:0", outputs=gd_outputs(gd))elif tflite or edgetpu: # https://www.tensorflow.org/lite/guide/python#install_tensorflow_lite_for_pythontry: # https://coral.ai/docs/edgetpu/tflite-python/#update-existing-tf-lite-code-for-the-edge-tpufrom tflite_runtime.interpreter import Interpreter, load_delegateexcept ImportError:import tensorflow as tfInterpreter, load_delegate = (tf.lite.Interpreter,tf.lite.experimental.load_delegate,)if edgetpu: # TF Edge TPU https://coral.ai/software/#edgetpu-runtimeLOGGER.info(f"Loading {w} for TensorFlow Lite Edge TPU inference...")delegate = {"Linux": "libedgetpu.so.1", "Darwin": "libedgetpu.1.dylib", "Windows": "edgetpu.dll"}[platform.system()]interpreter = Interpreter(model_path=w, experimental_delegates=[load_delegate(delegate)])else: # TFLiteLOGGER.info(f"Loading {w} for TensorFlow Lite inference...")interpreter = Interpreter(model_path=w) # load TFLite modelinterpreter.allocate_tensors() # allocateinput_details = interpreter.get_input_details() # inputsoutput_details = interpreter.get_output_details() # outputs# load metadatawith contextlib.suppress(zipfile.BadZipFile):with zipfile.ZipFile(w, "r") as model:meta_file = model.namelist()[0]meta = ast.literal_eval(model.read(meta_file).decode("utf-8"))stride, names = int(meta["stride"]), meta["names"]elif tfjs: # TF.jsraise NotImplementedError("ERROR: YOLOv5 TF.js inference is not supported")elif paddle: # PaddlePaddleLOGGER.info(f"Loading {w} for PaddlePaddle inference...")check_requirements("paddlepaddle-gpu" if cuda else "paddlepaddle")import paddle.inference as pdiif not Path(w).is_file(): # if not *.pdmodelw = next(Path(w).rglob("*.pdmodel")) # get *.pdmodel file from *_paddle_model dirweights = Path(w).with_suffix(".pdiparams")config = pdi.Config(str(w), str(weights))if cuda:config.enable_use_gpu(memory_pool_init_size_mb=2048, device_id=0)predictor = pdi.create_predictor(config)input_handle = predictor.get_input_handle(predictor.get_input_names()[0])output_names = predictor.get_output_names()elif triton: # NVIDIA Triton Inference ServerLOGGER.info(f"Using {w} as Triton Inference Server...")check_requirements("tritonclient[all]")from utils.triton import TritonRemoteModelmodel = TritonRemoteModel(url=w)nhwc = model.runtime.startswith("tensorflow")else:raise NotImplementedError(f"ERROR: {w} is not a supported format")# class namesif "names" not in locals():names = yaml_load(data)["names"] if data else {i: f"class{i}" for i in range(999)}if names[0] == "n01440764" and len(names) == 1000: # ImageNetnames = yaml_load(ROOT / "data/ImageNet.yaml")["names"] # human-readable namesself.__dict__.update(locals()) # assign all variables to selfdef forward(self, im, augment=False, visualize=False):"""Performs YOLOv5 inference on input images with options for augmentation and visualization."""b, ch, h, w = im.shape # batch, channel, height, widthif self.fp16 and im.dtype != torch.float16:im = im.half() # to FP16if self.nhwc:im = im.permute(0, 2, 3, 1) # torch BCHW to numpy BHWC shape(1,320,192,3)if self.pt: # PyTorchy = self.model(im, augment=augment, visualize=visualize) if augment or visualize else self.model(im)elif self.jit: # TorchScripty = self.model(im)elif self.dnn: # ONNX OpenCV DNNim = im.cpu().numpy() # torch to numpyself.net.setInput(im)y = self.net.forward()elif self.onnx: # ONNX Runtimeim = im.cpu().numpy() # torch to numpyy = self.session.run(self.output_names, {self.session.get_inputs()[0].name: im})elif self.xml: # OpenVINOim = im.cpu().numpy() # FP32y = list(self.ov_compiled_model(im).values())elif self.engine: # TensorRTif self.dynamic and im.shape != self.bindings["images"].shape:i = self.model.get_binding_index("images")self.context.set_binding_shape(i, im.shape) # reshape if dynamicself.bindings["images"] = self.bindings["images"]._replace(shape=im.shape)for name in self.output_names:i = self.model.get_binding_index(name)self.bindings[name].data.resize_(tuple(self.context.get_binding_shape(i)))s = self.bindings["images"].shapeassert im.shape == s, f"input size {im.shape} {'>' if self.dynamic else 'not equal to'} max model size {s}"self.binding_addrs["images"] = int(im.data_ptr())self.context.execute_v2(list(self.binding_addrs.values()))y = [self.bindings[x].data for x in sorted(self.output_names)]elif self.coreml: # CoreMLim = im.cpu().numpy()im = Image.fromarray((im[0] * 255).astype("uint8"))# im = im.resize((192, 320), Image.BILINEAR)y = self.model.predict({"image": im}) # coordinates are xywh normalizedif "confidence" in y:box = xywh2xyxy(y["coordinates"] * [[w, h, w, h]]) # xyxy pixelsconf, cls = y["confidence"].max(1), y["confidence"].argmax(1).astype(np.float)y = np.concatenate((box, conf.reshape(-1, 1), cls.reshape(-1, 1)), 1)else:y = list(reversed(y.values())) # reversed for segmentation models (pred, proto)elif self.paddle: # PaddlePaddleim = im.cpu().numpy().astype(np.float32)self.input_handle.copy_from_cpu(im)self.predictor.run()y = [self.predictor.get_output_handle(x).copy_to_cpu() for x in self.output_names]elif self.triton: # NVIDIA Triton Inference Servery = self.model(im)else: # TensorFlow (SavedModel, GraphDef, Lite, Edge TPU)im = im.cpu().numpy()if self.saved_model: # SavedModely = self.model(im, training=False) if self.keras else self.model(im)elif self.pb: # GraphDefy = self.frozen_func(x=self.tf.constant(im))else: # Lite or Edge TPUinput = self.input_details[0]int8 = input["dtype"] == np.uint8 # is TFLite quantized uint8 modelif int8:scale, zero_point = input["quantization"]im = (im / scale + zero_point).astype(np.uint8) # de-scaleself.interpreter.set_tensor(input["index"], im)self.interpreter.invoke()y = []for output in self.output_details:x = self.interpreter.get_tensor(output["index"])if int8:scale, zero_point = output["quantization"]x = (x.astype(np.float32) - zero_point) * scale # re-scaley.append(x)if len(y) == 2 and len(y[1].shape) != 4:y = list(reversed(y))y = [x if isinstance(x, np.ndarray) else x.numpy() for x in y]y[0][..., :4] *= [w, h, w, h] # xywh normalized to pixelsif isinstance(y, (list, tuple)):return self.from_numpy(y[0]) if len(y) == 1 else [self.from_numpy(x) for x in y]else:return self.from_numpy(y)def from_numpy(self, x):"""Converts a NumPy array to a torch tensor, maintaining device compatibility."""return torch.from_numpy(x).to(self.device) if isinstance(x, np.ndarray) else xdef warmup(self, imgsz=(1, 3, 640, 640)):"""Performs a single inference warmup to initialize model weights, accepting an `imgsz` tuple for image size."""warmup_types = self.pt, self.jit, self.onnx, self.engine, self.saved_model, self.pb, self.tritonif any(warmup_types) and (self.device.type != "cpu" or self.triton):im = torch.empty(*imgsz, dtype=torch.half if self.fp16 else torch.float, device=self.device) # inputfor _ in range(2 if self.jit else 1): #self.forward(im) # warmup@staticmethoddef _model_type(p="path/to/model.pt"):"""Determines model type from file path or URL, supporting various export formats.Example: path='path/to/model.onnx' -> type=onnx"""# types = [pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle]from export import export_formatsfrom utils.downloads import is_urlsf = list(export_formats().Suffix) # export suffixesif not is_url(p, check=False):check_suffix(p, sf) # checksurl = urlparse(p) # if url may be Triton inference servertypes = [s in Path(p).name for s in sf]types[8] &= not types[9] # tflite &= not edgetputriton = not any(types) and all([any(s in url.scheme for s in ["http", "grpc"]), url.netloc])return types + [triton]@staticmethoddef _load_metadata(f=Path("path/to/meta.yaml")):"""Loads metadata from a YAML file, returning strides and names if the file exists, otherwise `None`."""if f.exists():d = yaml_load(f)return d["stride"], d["names"] # assign stride, namesreturn None, Noneclass AutoShape(nn.Module):"""AutoShape class for robust YOLOv5 inference with preprocessing, NMS, and support for various input formats."""conf = 0.25 # NMS confidence thresholdiou = 0.45 # NMS IoU thresholdagnostic = False # NMS class-agnosticmulti_label = False # NMS multiple labels per boxclasses = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogsmax_det = 1000 # maximum number of detections per imageamp = False # Automatic Mixed Precision (AMP) inferencedef __init__(self, model, verbose=True):"""Initializes YOLOv5 model for inference, setting up attributes and preparing model for evaluation."""super().__init__()if verbose:LOGGER.info("Adding AutoShape... ")copy_attr(self, model, include=("yaml", "nc", "hyp", "names", "stride", "abc"), exclude=()) # copy attributesself.dmb = isinstance(model, DetectMultiBackend) # DetectMultiBackend() instanceself.pt = not self.dmb or model.pt # PyTorch modelself.model = model.eval()if self.pt:m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()m.inplace = False # Detect.inplace=False for safe multithread inferencem.export = True # do not output loss valuesdef _apply(self, fn):"""Applies to(), cpu(), cuda(), half() etc.to model tensors excluding parameters or registered buffers."""self = super()._apply(fn)if self.pt:m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()m.stride = fn(m.stride)m.grid = list(map(fn, m.grid))if isinstance(m.anchor_grid, list):m.anchor_grid = list(map(fn, m.anchor_grid))return self@smart_inference_mode()def forward(self, ims, size=640, augment=False, profile=False):"""Performs inference on inputs with optional augment & profiling.Supports various formats including file, URI, OpenCV, PIL, numpy, torch."""# For size(height=640, width=1280), RGB images example inputs are:# file: ims = 'data/images/zidane.jpg' # str or PosixPath# URI: = 'https://ultralytics.com/images/zidane.jpg'# OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)# PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)# numpy: = np.zeros((640,1280,3)) # HWC# torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)# multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of imagesdt = (Profile(), Profile(), Profile())with dt[0]:if isinstance(size, int): # expandsize = (size, size)p = next(self.model.parameters()) if self.pt else torch.empty(1, device=self.model.device) # paramautocast = self.amp and (p.device.type != "cpu") # Automatic Mixed Precision (AMP) inferenceif isinstance(ims, torch.Tensor): # torchwith amp.autocast(autocast):return self.model(ims.to(p.device).type_as(p), augment=augment) # inference# Pre-processn, ims = (len(ims), list(ims)) if isinstance(ims, (list, tuple)) else (1, [ims]) # number, list of imagesshape0, shape1, files = [], [], [] # image and inference shapes, filenamesfor i, im in enumerate(ims):f = f"image{i}" # filenameif isinstance(im, (str, Path)): # filename or uriim, f = Image.open(requests.get(im, stream=True).raw if str(im).startswith("http") else im), imim = np.asarray(exif_transpose(im))elif isinstance(im, Image.Image): # PIL Imageim, f = np.asarray(exif_transpose(im)), getattr(im, "filename", f) or ffiles.append(Path(f).with_suffix(".jpg").name)if im.shape[0] < 5: # image in CHWim = im.transpose((1, 2, 0)) # reverse dataloader .transpose(2, 0, 1)im = im[..., :3] if im.ndim == 3 else cv2.cvtColor(im, cv2.COLOR_GRAY2BGR) # enforce 3ch inputs = im.shape[:2] # HWCshape0.append(s) # image shapeg = max(size) / max(s) # gainshape1.append([int(y * g) for y in s])ims[i] = im if im.data.contiguous else np.ascontiguousarray(im) # updateshape1 = [make_divisible(x, self.stride) for x in np.array(shape1).max(0)] # inf shapex = [letterbox(im, shape1, auto=False)[0] for im in ims] # padx = np.ascontiguousarray(np.array(x).transpose((0, 3, 1, 2))) # stack and BHWC to BCHWx = torch.from_numpy(x).to(p.device).type_as(p) / 255 # uint8 to fp16/32with amp.autocast(autocast):# Inferencewith dt[1]:y = self.model(x, augment=augment) # forward# Post-processwith dt[2]:y = non_max_suppression(y if self.dmb else y[0],self.conf,self.iou,self.classes,self.agnostic,self.multi_label,max_det=self.max_det,) # NMSfor i in range(n):scale_boxes(shape1, y[i][:, :4], shape0[i])return Detections(ims, y, files, dt, self.names, x.shape)class Detections:"""Manages YOLOv5 detection results with methods for visualization, saving, cropping, and exporting detections."""def __init__(self, ims, pred, files, times=(0, 0, 0), names=None, shape=None):"""Initializes the YOLOv5 Detections class with image info, predictions, filenames, timing and normalization."""super().__init__()d = pred[0].device # devicegn = [torch.tensor([*(im.shape[i] for i in [1, 0, 1, 0]), 1, 1], device=d) for im in ims] # normalizationsself.ims = ims # list of images as numpy arraysself.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)self.names = names # class namesself.files = files # image filenamesself.times = times # profiling timesself.xyxy = pred # xyxy pixelsself.xywh = [xyxy2xywh(x) for x in pred] # xywh pixelsself.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalizedself.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalizedself.n = len(self.pred) # number of images (batch size)self.t = tuple(x.t / self.n * 1e3 for x in times) # timestamps (ms)self.s = tuple(shape) # inference BCHW shapedef _run(self, pprint=False, show=False, save=False, crop=False, render=False, labels=True, save_dir=Path("")):"""Executes model predictions, displaying and/or saving outputs with optional crops and labels."""s, crops = "", []for i, (im, pred) in enumerate(zip(self.ims, self.pred)):s += f"\nimage {i + 1}/{len(self.pred)}: {im.shape[0]}x{im.shape[1]} " # stringif pred.shape[0]:for c in pred[:, -1].unique():n = (pred[:, -1] == c).sum() # detections per classs += f"{n} {self.names[int(c)]}{'s' * (n > 1)}, " # add to strings = s.rstrip(", ")if show or save or render or crop:annotator = Annotator(im, example=str(self.names))for *box, conf, cls in reversed(pred): # xyxy, confidence, classlabel = f"{self.names[int(cls)]} {conf:.2f}"if crop:file = save_dir / "crops" / self.names[int(cls)] / self.files[i] if save else Nonecrops.append({"box": box,"conf": conf,"cls": cls,"label": label,"im": save_one_box(box, im, file=file, save=save),})else: # all othersannotator.box_label(box, label if labels else "", color=colors(cls))im = annotator.imelse:s += "(no detections)"im = Image.fromarray(im.astype(np.uint8)) if isinstance(im, np.ndarray) else im # from npif show:if is_jupyter():from IPython.display import displaydisplay(im)else:im.show(self.files[i])if save:f = self.files[i]im.save(save_dir / f) # saveif i == self.n - 1:LOGGER.info(f"Saved {self.n} image{'s' * (self.n > 1)} to {colorstr('bold', save_dir)}")if render:self.ims[i] = np.asarray(im)if pprint:s = s.lstrip("\n")return f"{s}\nSpeed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {self.s}" % self.tif crop:if save:LOGGER.info(f"Saved results to {save_dir}\n")return crops@TryExcept("Showing images is not supported in this environment")def show(self, labels=True):"""Displays detection results with optional labels.Usage: show(labels=True)"""self._run(show=True, labels=labels) # show resultsdef save(self, labels=True, save_dir="runs/detect/exp", exist_ok=False):"""Saves detection results with optional labels to a specified directory.Usage: save(labels=True, save_dir='runs/detect/exp', exist_ok=False)"""save_dir = increment_path(save_dir, exist_ok, mkdir=True) # increment save_dirself._run(save=True, labels=labels, save_dir=save_dir) # save resultsdef crop(self, save=True, save_dir="runs/detect/exp", exist_ok=False):"""Crops detection results, optionally saves them to a directory.Args: save (bool), save_dir (str), exist_ok (bool)."""save_dir = increment_path(save_dir, exist_ok, mkdir=True) if save else Nonereturn self._run(crop=True, save=save, save_dir=save_dir) # crop resultsdef render(self, labels=True):"""Renders detection results with optional labels on images; args: labels (bool) indicating label inclusion."""self._run(render=True, labels=labels) # render resultsreturn self.imsdef pandas(self):"""Returns detections as pandas DataFrames for various box formats (xyxy, xyxyn, xywh, xywhn).Example: print(results.pandas().xyxy[0])."""new = copy(self) # return copyca = "xmin", "ymin", "xmax", "ymax", "confidence", "class", "name" # xyxy columnscb = "xcenter", "ycenter", "width", "height", "confidence", "class", "name" # xywh columnsfor k, c in zip(["xyxy", "xyxyn", "xywh", "xywhn"], [ca, ca, cb, cb]):a = [[x[:5] + [int(x[5]), self.names[int(x[5])]] for x in x.tolist()] for x in getattr(self, k)] # updatesetattr(new, k, [pd.DataFrame(x, columns=c) for x in a])return newdef tolist(self):"""Converts a Detections object into a list of individual detection results for iteration.Example: for result in results.tolist():"""r = range(self.n) # iterablereturn [Detections([self.ims[i]],[self.pred[i]],[self.files[i]],self.times,self.names,self.s,)for i in r]def print(self):"""Logs the string representation of the current object's state via the LOGGER."""LOGGER.info(self.__str__())def __len__(self):"""Returns the number of results stored, overrides the default len(results)."""return self.ndef __str__(self):"""Returns a string representation of the model's results, suitable for printing, overrides defaultprint(results)."""return self._run(pprint=True) # print resultsdef __repr__(self):"""Returns a string representation of the YOLOv5 object, including its class and formatted results."""return f"YOLOv5 {self.__class__} instance\n" + self.__str__()class Proto(nn.Module):"""YOLOv5 mask Proto module for segmentation models, performing convolutions and upsampling on input tensors."""def __init__(self, c1, c_=256, c2=32):"""Initializes YOLOv5 Proto module for segmentation with input, proto, and mask channels configuration."""super().__init__()self.cv1 = Conv(c1, c_, k=3)self.upsample = nn.Upsample(scale_factor=2, mode="nearest")self.cv2 = Conv(c_, c_, k=3)self.cv3 = Conv(c_, c2)def forward(self, x):"""Performs a forward pass using convolutional layers and upsampling on input tensor `x`."""return self.cv3(self.cv2(self.upsample(self.cv1(x))))class Classify(nn.Module):"""YOLOv5 classification head with convolution, pooling, and dropout layers for channel transformation."""def __init__(self, c1, c2, k=1, s=1, p=None, g=1, dropout_p=0.0): # ch_in, ch_out, kernel, stride, padding, groups, dropout probability"""Initializes YOLOv5 classification head with convolution, pooling, and dropout layers for input to outputchannel transformation."""super().__init__()c_ = 1280 # efficientnet_b0 sizeself.conv = Conv(c1, c_, k, s, autopad(k, p), g)self.pool = nn.AdaptiveAvgPool2d(1) # to x(b,c_,1,1)self.drop = nn.Dropout(p=dropout_p, inplace=True)self.linear = nn.Linear(c_, c2) # to x(b,c2)def forward(self, x):"""Processes input through conv, pool, drop, and linear layers; supports list concatenation input."""if isinstance(x, list):x = torch.cat(x, 1)return self.linear(self.drop(self.pool(self.conv(x)).flatten(1)))#
class RepConv(nn.Module):"""RepConv module with training and deploy modes.This module is used in RT-DETR and can fuse convolutions during inference for efficiency.Attributes:conv1 (Conv): 3x3 convolution.conv2 (Conv): 1x1 convolution.bn (nn.BatchNorm2d, optional): Batch normalization for identity branch.act (nn.Module): Activation function.default_act (nn.Module): Default activation function (SiLU).References:https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py"""default_act = nn.ReLU6() # default activation# def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True)def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):"""Initialize RepConv module with given parameters.Args:c1 (int): Number of input channels.c2 (int): Number of output channels.k (int): Kernel size.s (int): Stride.p (int): Padding.g (int): Groups.d (int): Dilation.act (bool | nn.Module): Activation function.bn (bool): Use batch normalization for identity branch.deploy (bool): Deploy mode for inference."""super().__init__()assert k == 3 and p == 1self.g = gself.c1 = c1self.c2 = c2self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()self.bn = nn.BatchNorm2d(num_features=c1) if bn and c2 == c1 and s == 1 else None# def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True)self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False)def forward_fuse(self, x):"""Forward pass for deploy mode.Args:x (torch.Tensor): Input tensor.Returns:(torch.Tensor): Output tensor."""return self.act(self.conv(x))def forward(self, x):"""Forward pass for training mode.Args:x (torch.Tensor): Input tensor.Returns:(torch.Tensor): Output tensor."""id_out = 0 if self.bn is None else self.bn(x)return self.act(self.conv1(x) + self.conv2(x) + id_out)def get_equivalent_kernel_bias(self):"""Calculate equivalent kernel and bias by fusing convolutions.Returns:(tuple): Tuple containing:- Equivalent kernel (torch.Tensor)- Equivalent bias (torch.Tensor)"""kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)kernelid, biasid = self._fuse_bn_tensor(self.bn)return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid@staticmethoddef _pad_1x1_to_3x3_tensor(kernel1x1):"""Pad a 1x1 kernel to 3x3 size.Args:kernel1x1 (torch.Tensor): 1x1 convolution kernel.Returns:(torch.Tensor): Padded 3x3 kernel."""if kernel1x1 is None:return 0else:return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])def _fuse_bn_tensor(self, branch):"""Fuse batch normalization with convolution weights.Args:branch (Conv | nn.BatchNorm2d | None): Branch to fuse.Returns:(tuple): Tuple containing:- Fused kernel (torch.Tensor)- Fused bias (torch.Tensor)"""if branch is None:return 0, 0if isinstance(branch, Conv):kernel = branch.conv.weightrunning_mean = branch.bn.running_meanrunning_var = branch.bn.running_vargamma = branch.bn.weightbeta = branch.bn.biaseps = branch.bn.epselif isinstance(branch, nn.BatchNorm2d):if not hasattr(self, "id_tensor"):input_dim = self.c1 // self.gkernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)for i in range(self.c1):kernel_value[i, i % input_dim, 1, 1] = 1self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)kernel = self.id_tensorrunning_mean = branch.running_meanrunning_var = branch.running_vargamma = branch.weightbeta = branch.biaseps = branch.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta - running_mean * gamma / stddef fuse_convs(self):"""Fuse convolutions for inference by creating a single equivalent convolution."""if hasattr(self, "conv"):returnkernel, bias = self.get_equivalent_kernel_bias()self.conv = nn.Conv2d(in_channels=self.c1,out_channels=self.c2,kernel_size=self.s,stride=self.conv1.conv.stride,padding=self.conv1.conv.padding,dilation=self.conv1.conv.dilation,groups=self.conv1.conv.groups,bias=True,).requires_grad_(False)self.conv.weight.data = kernelself.conv.bias.data = biasfor para in self.parameters():para.detach_()self.__delattr__("conv1")self.__delattr__("conv2")if hasattr(self, "nm"):self.__delattr__("nm")if hasattr(self, "bn"):self.__delattr__("bn")if hasattr(self, "id_tensor"):self.__delattr__("id_tensor")class ECA(nn.Module):"""Constructs a ECA module.Args:channel: Number of channels of the input feature mapk_size: Adaptive selection of kernel size"""def __init__(self, c1, c2, k_size=3):super(ECA, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):# feature descriptor on the global spatial informationy = self.avg_pool(x)y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)# Multi-scale information fusiony = self.sigmoid(y)return x * y.expand_as(x)引入创新模块(进阶,可选)
%%writefile /kaggle/working/yolov5/models/yolo.py
# 修改 yolo.py
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
"""
YOLO-specific modules.Usage:$ python models/yolo.py --cfg yolov5s.yaml
"""import argparse
import contextlib
import math
import os
import platform
import sys
from copy import deepcopy
from pathlib import Pathimport torch
import torch.nn as nnFILE = Path(__file__).resolve()
ROOT = FILE.parents[1] # YOLOv5 root directory
if str(ROOT) not in sys.path:sys.path.append(str(ROOT)) # add ROOT to PATH
if platform.system() != "Windows":ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import (ECA,C3,C3SPP,C3TR,SPP,SPPF,Bottleneck,BottleneckCSP,C3Ghost,C3x,Classify,Concat,Contract,Conv,RepConv,CrossConv,DetectMultiBackend,DWConv,DWConvTranspose2d,Expand,Focus,GhostBottleneck,GhostConv,Proto,
)
from models.experimental import MixConv2d
from utils.autoanchor import check_anchor_order
from utils.general import LOGGER, check_version, check_yaml, colorstr, make_divisible, print_args
from utils.plots import feature_visualization
from utils.torch_utils import (fuse_conv_and_bn,initialize_weights,model_info,profile,scale_img,select_device,time_sync,
)try:import thop # for FLOPs computation
except ImportError:thop = Noneclass Detect(nn.Module):"""YOLOv5 Detect head for processing input tensors and generating detection outputs in object detection models."""stride = None # strides computed during builddynamic = False # force grid reconstructionexport = False # export modedef __init__(self, nc=80, anchors=(), ch=(), inplace=True):"""Initializes YOLOv5 detection layer with specified classes, anchors, channels, and inplace operations."""super().__init__()self.nc = nc # number of classesself.no = nc + 5 # number of outputs per anchorself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.empty(0) for _ in range(self.nl)] # init gridself.anchor_grid = [torch.empty(0) for _ in range(self.nl)] # init anchor gridself.register_buffer("anchors", torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output convself.inplace = inplace # use inplace ops (e.g. slice assignment)def forward(self, x):"""Processes input through YOLOv5 layers, altering shape for detection: `x(bs, 3, ny, nx, 85)`."""z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)if isinstance(self, Segment): # (boxes + masks)xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xywh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, conf.sigmoid(), mask), 4)else: # Detect (boxes only)xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)xy = (xy * 2 + self.grid[i]) * self.stride[i] # xywh = (wh * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, conf), 4)z.append(y.view(bs, self.na * nx * ny, self.no))return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)def _make_grid(self, nx=20, ny=20, i=0, torch_1_10=check_version(torch.__version__, "1.10.0")):"""Generates a mesh grid for anchor boxes with optional compatibility for torch versions < 1.10."""d = self.anchors[i].devicet = self.anchors[i].dtypeshape = 1, self.na, ny, nx, 2 # grid shapey, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)yv, xv = torch.meshgrid(y, x, indexing="ij") if torch_1_10 else torch.meshgrid(y, x) # torch>=0.7 compatibilitygrid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)return grid, anchor_gridclass Segment(Detect):"""YOLOv5 Segment head for segmentation models, extending Detect with mask and prototype layers."""def __init__(self, nc=80, anchors=(), nm=32, npr=256, ch=(), inplace=True):"""Initializes YOLOv5 Segment head with options for mask count, protos, and channel adjustments."""super().__init__(nc, anchors, ch, inplace)self.nm = nm # number of masksself.npr = npr # number of protosself.no = 5 + nc + self.nm # number of outputs per anchorself.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output convself.proto = Proto(ch[0], self.npr, self.nm) # protosself.detect = Detect.forwarddef forward(self, x):"""Processes input through the network, returning detections and prototypes; adjusts output based ontraining/export mode."""p = self.proto(x[0])x = self.detect(self, x)return (x, p) if self.training else (x[0], p) if self.export else (x[0], p, x[1])class BaseModel(nn.Module):"""YOLOv5 base model."""def forward(self, x, profile=False, visualize=False):"""Executes a single-scale inference or training pass on the YOLOv5 base model, with options for profiling andvisualization."""return self._forward_once(x, profile, visualize) # single-scale inference, traindef _forward_once(self, x, profile=False, visualize=False):"""Performs a forward pass on the YOLOv5 model, enabling profiling and feature visualization options."""y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return xdef _profile_one_layer(self, m, x, dt):"""Profiles a single layer's performance by computing GFLOPs, execution time, and parameters."""c = m == self.model[-1] # is final layer, copy input as inplace fixo = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1e9 * 2 if thop else 0 # FLOPst = time_sync()for _ in range(10):m(x.copy() if c else x)dt.append((time_sync() - t) * 100)if m == self.model[0]:LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} module")LOGGER.info(f"{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}")if c:LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")def fuse(self):"""Fuses Conv2d() and BatchNorm2d() layers in the model to improve inference speed."""LOGGER.info("Fusing layers... ")for m in self.model.modules():if isinstance(m, (Conv, DWConv)) and hasattr(m, "bn"):m.conv = fuse_conv_and_bn(m.conv, m.bn) # update convdelattr(m, "bn") # remove batchnormm.forward = m.forward_fuse # update forwardself.info()return selfdef info(self, verbose=False, img_size=640):"""Prints model information given verbosity and image size, e.g., `info(verbose=True, img_size=640)`."""model_info(self, verbose, img_size)def _apply(self, fn):"""Applies transformations like to(), cpu(), cuda(), half() to model tensors excluding parameters or registeredbuffers."""self = super()._apply(fn)m = self.model[-1] # Detect()if isinstance(m, (Detect, Segment)):m.stride = fn(m.stride)m.grid = list(map(fn, m.grid))if isinstance(m.anchor_grid, list):m.anchor_grid = list(map(fn, m.anchor_grid))return selfclass DetectionModel(BaseModel):"""YOLOv5 detection model class for object detection tasks, supporting custom configurations and anchors."""def __init__(self, cfg="yolov5s.yaml", ch=3, nc=None, anchors=None):"""Initializes YOLOv5 model with configuration file, input channels, number of classes, and custom anchors."""super().__init__()if isinstance(cfg, dict):self.yaml = cfg # model dictelse: # is *.yamlimport yaml # for torch hubself.yaml_file = Path(cfg).namewith open(cfg, encoding="ascii", errors="ignore") as f:self.yaml = yaml.safe_load(f) # model dict# Define modelch = self.yaml["ch"] = self.yaml.get("ch", ch) # input channelsif nc and nc != self.yaml["nc"]:LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")self.yaml["nc"] = nc # override yaml valueif anchors:LOGGER.info(f"Overriding model.yaml anchors with anchors={anchors}")self.yaml["anchors"] = round(anchors) # override yaml valueself.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelistself.names = [str(i) for i in range(self.yaml["nc"])] # default namesself.inplace = self.yaml.get("inplace", True)# Build strides, anchorsm = self.model[-1] # Detect()if isinstance(m, (Detect, Segment)):def _forward(x):"""Passes the input 'x' through the model and returns the processed output."""return self.forward(x)[0] if isinstance(m, Segment) else self.forward(x)s = 256 # 2x min stridem.inplace = self.inplacem.stride = torch.tensor([s / x.shape[-2] for x in _forward(torch.zeros(1, ch, s, s))]) # forwardcheck_anchor_order(m)m.anchors /= m.stride.view(-1, 1, 1)self.stride = m.strideself._initialize_biases() # only run once# Init weights, biasesinitialize_weights(self)self.info()LOGGER.info("")def forward(self, x, augment=False, profile=False, visualize=False):"""Performs single-scale or augmented inference and may include profiling or visualization."""if augment:return self._forward_augment(x) # augmented inference, Nonereturn self._forward_once(x, profile, visualize) # single-scale inference, traindef _forward_augment(self, x):"""Performs augmented inference across different scales and flips, returning combined detections."""img_size = x.shape[-2:] # height, widths = [1, 0.83, 0.67] # scalesf = [None, 3, None] # flips (2-ud, 3-lr)y = [] # outputsfor si, fi in zip(s, f):xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))yi = self._forward_once(xi)[0] # forward# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # saveyi = self._descale_pred(yi, fi, si, img_size)y.append(yi)y = self._clip_augmented(y) # clip augmented tailsreturn torch.cat(y, 1), None # augmented inference, traindef _descale_pred(self, p, flips, scale, img_size):"""De-scales predictions from augmented inference, adjusting for flips and image size."""if self.inplace:p[..., :4] /= scale # de-scaleif flips == 2:p[..., 1] = img_size[0] - p[..., 1] # de-flip udelif flips == 3:p[..., 0] = img_size[1] - p[..., 0] # de-flip lrelse:x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scaleif flips == 2:y = img_size[0] - y # de-flip udelif flips == 3:x = img_size[1] - x # de-flip lrp = torch.cat((x, y, wh, p[..., 4:]), -1)return pdef _clip_augmented(self, y):"""Clips augmented inference tails for YOLOv5 models, affecting first and last tensors based on grid points andlayer counts."""nl = self.model[-1].nl # number of detection layers (P3-P5)g = sum(4**x for x in range(nl)) # grid pointse = 1 # exclude layer counti = (y[0].shape[1] // g) * sum(4**x for x in range(e)) # indicesy[0] = y[0][:, :-i] # largei = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indicesy[-1] = y[-1][:, i:] # smallreturn ydef _initialize_biases(self, cf=None):"""Initializes biases for YOLOv5's Detect() module, optionally using class frequencies (cf).For details see https://arxiv.org/abs/1708.02002 section 3.3."""# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.m = self.model[-1] # Detect() modulefor mi, s in zip(m.m, m.stride): # fromb = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)b.data[:, 5 : 5 + m.nc] += (math.log(0.6 / (m.nc - 0.99999)) if cf is None else torch.log(cf / cf.sum())) # clsmi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)Model = DetectionModel # retain YOLOv5 'Model' class for backwards compatibilityclass SegmentationModel(DetectionModel):"""YOLOv5 segmentation model for object detection and segmentation tasks with configurable parameters."""def __init__(self, cfg="yolov5s-seg.yaml", ch=3, nc=None, anchors=None):"""Initializes a YOLOv5 segmentation model with configurable params: cfg (str) for configuration, ch (int) for channels, nc (int) for num classes, anchors (list)."""super().__init__(cfg, ch, nc, anchors)class ClassificationModel(BaseModel):"""YOLOv5 classification model for image classification tasks, initialized with a config file or detection model."""def __init__(self, cfg=None, model=None, nc=1000, cutoff=10):"""Initializes YOLOv5 model with config file `cfg`, input channels `ch`, number of classes `nc`, and `cuttoff`index."""super().__init__()self._from_detection_model(model, nc, cutoff) if model is not None else self._from_yaml(cfg)def _from_detection_model(self, model, nc=1000, cutoff=10):"""Creates a classification model from a YOLOv5 detection model, slicing at `cutoff` and adding a classificationlayer."""if isinstance(model, DetectMultiBackend):model = model.model # unwrap DetectMultiBackendmodel.model = model.model[:cutoff] # backbonem = model.model[-1] # last layerch = m.conv.in_channels if hasattr(m, "conv") else m.cv1.conv.in_channels # ch into modulec = Classify(ch, nc) # Classify()c.i, c.f, c.type = m.i, m.f, "models.common.Classify" # index, from, typemodel.model[-1] = c # replaceself.model = model.modelself.stride = model.strideself.save = []self.nc = ncdef _from_yaml(self, cfg):"""Creates a YOLOv5 classification model from a specified *.yaml configuration file."""self.model = None# 模型构建
def parse_model(d, ch):"""Parses a YOLOv5 model from a dict `d`, configuring layers based on input channels `ch` and model architecture."""LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw, act, ch_mul = (d["anchors"],d["nc"],d["depth_multiple"],d["width_multiple"],d.get("activation"),d.get("channel_multiple"),)# 如果 act 配置项存在,就根据配置修改卷积层的默认激活函数。if act:Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()RepConv.default_act = eval(act)LOGGER.info(f"{colorstr('activation:')} {act}") # printif not ch_mul:ch_mul = 8# 每个锚点的数量,通常为锚点列表中的每对(width, height)na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors# 每个输出的通道数,计算公式为 锚点数 * (类别数 + 5),5 代表边界框的 4 个坐标加上置信度。no = na * (nc + 5) # number of outputs = anchors * (classes + 5)layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out# 解析每一行结构for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, args# 动态解析字符串为对应的类m = eval(m) if isinstance(m, str) else m # eval stringsfor j, a in enumerate(args):with contextlib.suppress(NameError):args[j] = eval(a) if isinstance(a, str) else a # eval strings# 重复数量n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain# 卷积层处理if m in {Conv,RepConv,GhostConv,Bottleneck,GhostBottleneck,SPP,SPPF,DWConv,MixConv2d,Focus,CrossConv,BottleneckCSP,C3,ECA,C3TR,C3SPP,C3Ghost,nn.ConvTranspose2d,DWConvTranspose2d,C3x,}:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, ch_mul)args = [c1, c2, *args[1:]]if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)# TODO: channel, gw, gdelif m in {Detect, Segment}:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)if m is Segment:args[3] = make_divisible(args[3] * gw, ch_mul)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2else:c2 = ch[f]m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace("__main__.", "") # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number paramsLOGGER.info(f"{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}") # printsave.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist# 保存结构层layers.append(m_)if i == 0:ch = []ch.append(c2)return nn.Sequential(*layers), sorted(save)if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--cfg", type=str, default="yolov5s_custom.yaml", help="model.yaml")parser.add_argument("--batch-size", type=int, default=1, help="total batch size for all GPUs")parser.add_argument("--device", default="cpu", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")parser.add_argument("--profile", action="store_true", help="profile model speed")parser.add_argument("--line-profile", action="store_true", help="profile model speed layer by layer")parser.add_argument("--test", action="store_true", help="test all yolo*.yaml")opt = parser.parse_args()opt.cfg = check_yaml(opt.cfg) # check YAMLprint_args(vars(opt))device = select_device(opt.device)# Create modelim = torch.rand(opt.batch_size, 3, 640, 640).to(device)model = Model(opt.cfg).to(device)# Optionsif opt.line_profile: # profile layer by layermodel(im, profile=True)elif opt.profile: # profile forward-backwardresults = profile(input=im, ops=[model], n=3)elif opt.test: # test all modelsfor cfg in Path(ROOT / "models").rglob("yolo*.yaml"):try:_ = Model(cfg)except Exception as e:print(f"Error in {cfg}: {e}")else: # report fused model summarymodel.fuse()训练模型
直接训练命令即可开始畅想漫长的等待时刻,现在是抖音时间!!!
!python train.py --data coco128.yaml --cfg yolov5n.yaml --weights '' --epochs 150 --batch-size 64 --img-size 640 --hyp hyp.scratch-low.yaml --device 0 需要下载指定文件夹的,比如训练结果,现在压缩,然后在右侧选中文件,右边点击三个小点进行下载:
没反应的请F12抓取下载链接,直接复制到浏览器搜索栏即可下载。
import osimport zipfiledef zip_folder(source_folder, output_zip):"""将指定目录打包为 ZIP 文件。:param source_folder: 需要压缩的目录路径:param output_zip: 输出 ZIP 文件的完整路径(包含 .zip)"""with zipfile.ZipFile(output_zip, 'w', zipfile.ZIP_DEFLATED) as zipf:for root, dirs, files in os.walk(source_folder):for file in files:file_path = os.path.join(root, file)arcname = os.path.relpath(file_path, source_folder) # 保持相对路径zipf.write(file_path, arcname)print(f"文件夹 '{source_folder}' 已成功压缩至 '{output_zip}'")if __name__ == "__main__":source_directory = "./runs/train/exp2" # 需要压缩的文件夹路径output_zip_path = "./ECA_4_9_150.zip" # 目标 ZIP 文件路径# 确保输出目录存在os.makedirs(os.path.dirname(output_zip_path), exist_ok=True)zip_folder(source_directory, output_zip_path) # 终止训练# !pkill -9 -f train.py文章总结
本文详细介绍了使用 Kaggel 免费服务器进行YOLOv5模型训练,整个流程同样适用于其他训练框架。本文还提供了YOLOv5改进代码示例。
感谢阅览,如果你喜欢该内容的话,可以点赞,收藏,转发。由于 Koro 能力有限,有任何问题请在评论区内提出,Koro 看到后第一时间回复您!!!