深入探究 MySQL 架构:从查询到硬件
了解数据库的底层工作原理对于开发人员和系统架构师来说至关重要。在本指南中,我们将探索 MySQL 查询的奇妙旅程,从它离开应用程序的那一刻起,直到到达物理存储层——每个步骤都配有真实的示例。
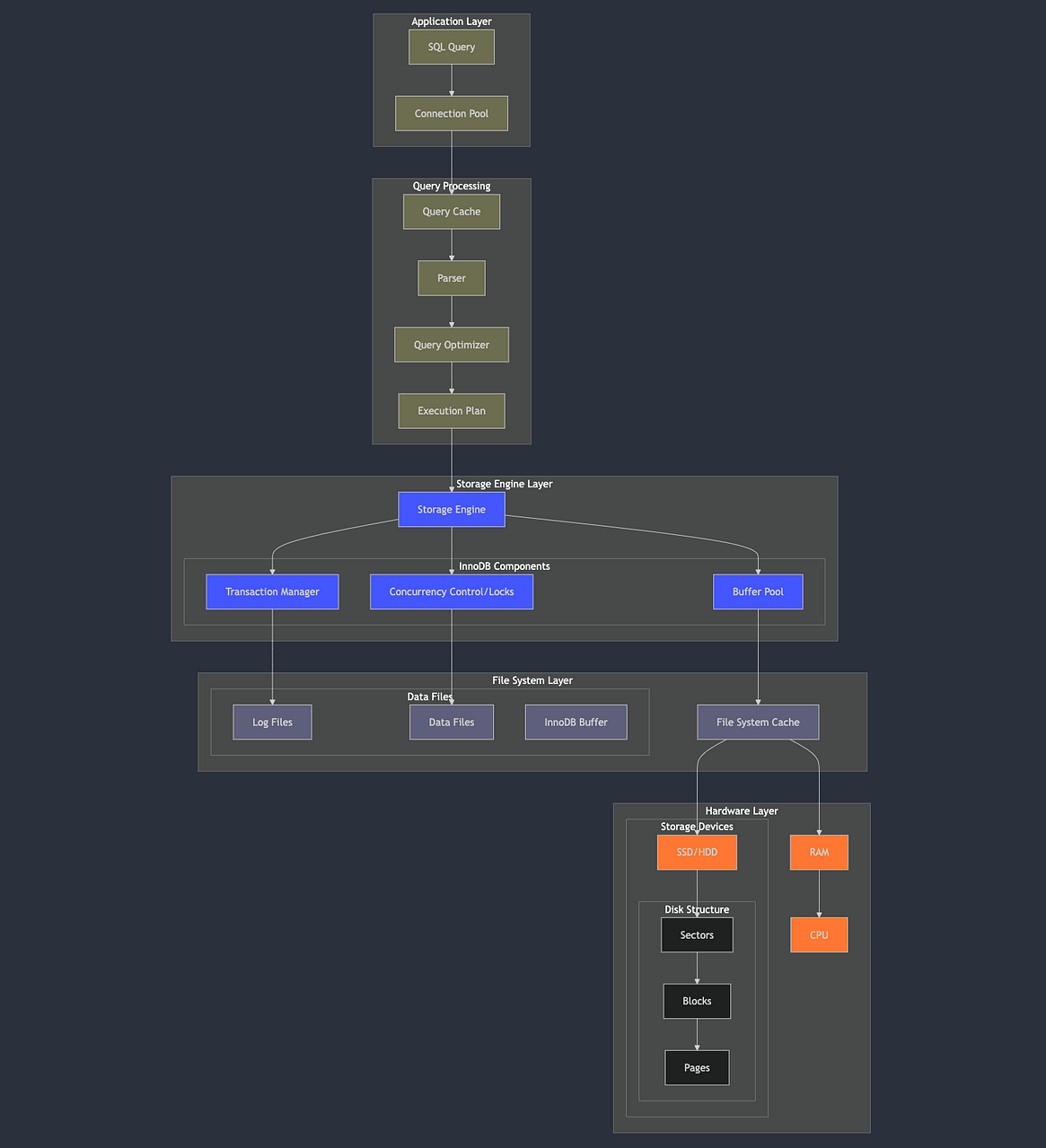
旅程开始:应用层
当您的应用程序执行 SQL 查询时,它会启动一系列复杂的事件。
第一站是连接池,它是管理和重用数据库连接的关键组件。池不会为每个查询创建新的连接(这会很昂贵),而是维护一组预先建立的连接,从而显著降低了延迟和资源开销。
我们来看一个典型的连接场景:
# 使用连接池的 Python 示例
from mysql.connector.pooling import MySQLConnectionPooldbconfig = { "pool_name" : "mypool" , "pool_size" : 5 , "host" : "localhost" , "user" : "root" , "password" : "password" , "database" : "employees"}
# 初始化连接池
connection_pool = MySQLConnectionPool(**dbconfig)
def get_employee ( emp_id ): # 从池中获取连接 connection= connection_pool.get_connection() try : cursor = connection.cursor() cursor.execute( "SELECT * FROM employees WHERE id = %s" , (emp_id,)) return cursor.fetchone() finally : # 将连接返回到池中connection.close()
如果没有连接池,每个查询都需要一个新连接:
新连接所 花费的时间:~ 100 -300毫秒连接池所花费的时间: ~ 5 -20毫秒
查询处理:魔法发生的地方
查询缓存(旧功能)
在 MySQL 5.7 中已弃用,并在 MySQL 8.0 中删除
虽然在较新版本的 MySQL 中已弃用查询缓存,但了解查询缓存有助于掌握数据库优化的演变。该组件存储 SELECT 查询的结果及其文本。如果收到相同的查询,MySQL 可以立即返回缓存的结果,从而绕过所有其他处理步骤。
解析器和优化器的实际应用
解析器是 MySQL 的语法检查器和查询验证器。它将