启动你的RocketMQ之旅(六)-Broker详细——主从复制
前言:
👏作者简介:我是笑霸final。
📝个人主页: 笑霸final的主页2
📕系列专栏:java专栏
📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
🔥如果感觉博主的文章还不错的话,👍点赞👍 + 👀关注👀 + 🤏收藏🤏
上一章节:启动你的RocketMQ之旅(五)-Broker详细——消息传输
目录
- 概述
- 主节点发送消息方法WriteSocketService
- 主向从发心跳包的格式
- 从节点接收数据
- 主节点接收从数据ReadSocketService
概述
上一节介绍了rocketmq的消息通信原理,这一节主要介绍它的高可用机制-主从复制。
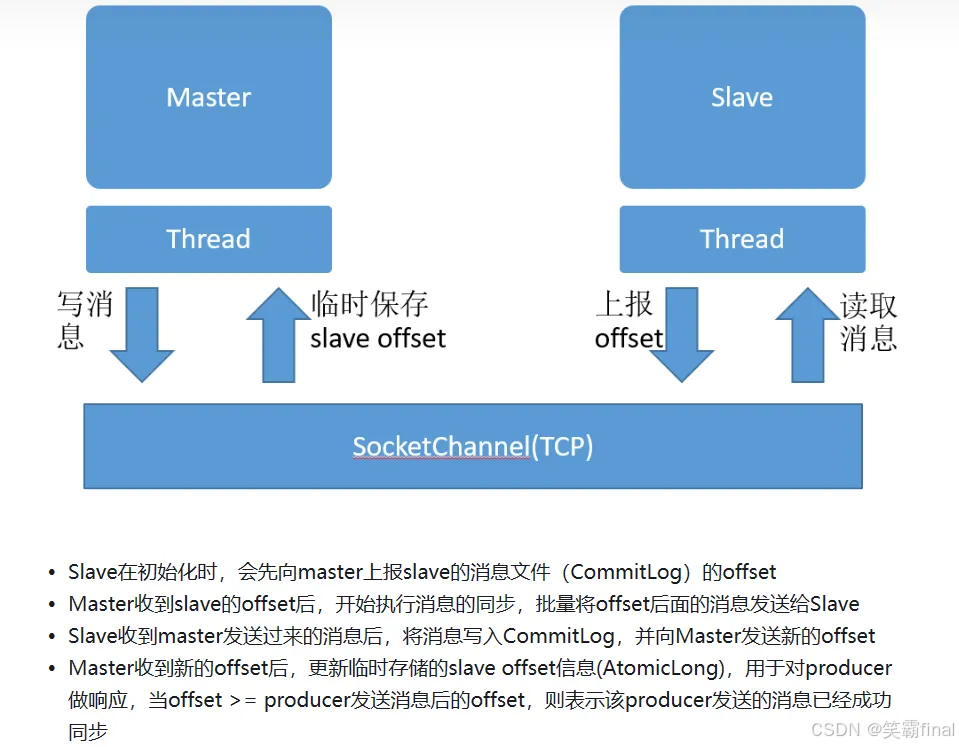
RocketMQ 的主从复制(Master-Slave Replication)机制是其高可用性架构的重要组成部分,主要用于提高系统的可靠性和数据的安全性。通过主从架构,RocketMQ 能够在主节点(Master)发生故障时,迅速切换到从节点(Slave),以保证消息服务的连续性。
主从架构概述
在 RocketMQ 中,Broker 分为 Master 和 Slave 两种角色。一个 Master 可以对应多个 Slave,但每个 Slave 只能属于一个 Master。Master 节点负责处理客户端的读写请求,而 Slave 节点则主要负责数据备份和提供只读服务(可选配置)。这种设计确保了即使 Master 发生故障,系统也能快速恢复服务,并且不会丢失数据。
数据同步方式
RocketMQ 支持两种类型的数据同步方式:
- 同步双写(Sync):在这种模式下,Producer 发送的消息会同时写入 Master 和 Slave。只有当消息成功写入 Master 和所有关联的 Slave 后,才会向 Producer 返回确认响应。【供了更高的数据一致性,但也带来了较高的延迟】
- 异步复制(Async):Producer 只需将消息发送给 Master 并收到确认即可。随后,Master 会异步地将消息同步给 Slave。【消息写入速度快,但存在一定的数据丢失风险】
源码图片
这三个类就是关于Ha服务的 HAservice的构造方法和HAConnection的构造方法
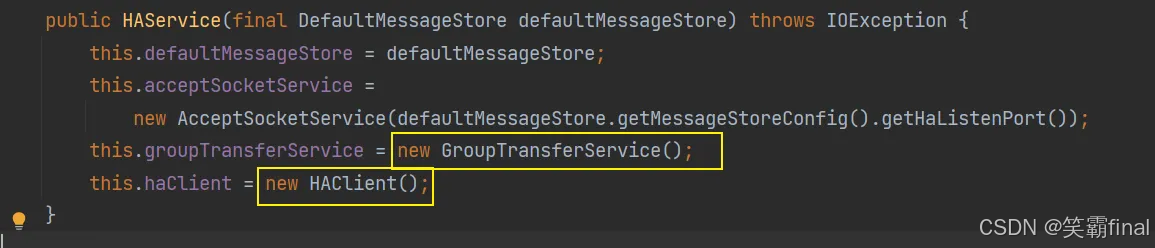
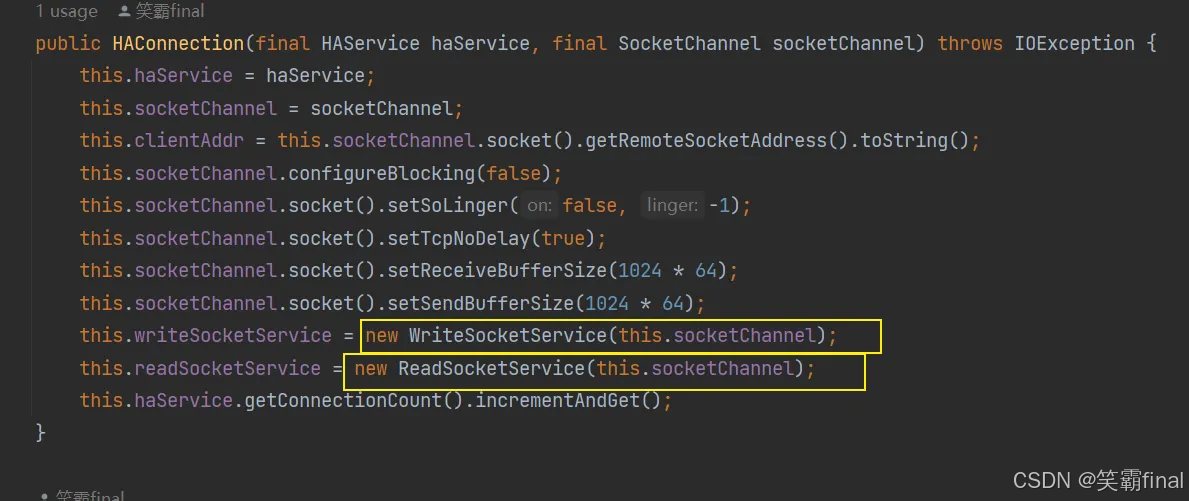
这上面两个构造方法内 都还有4个新的类
● WriteSocketService通常负责处理向网络通道写入数据的任务,也就是将数据发送到远程节点。
● ReadSocketService则专注于从网络通道读取数据,接收来自远程节点的信息。
● groupTransferService:负责将主节点写入的消息组按照一定的策略分发到从节点,确保消息在集群间的同步。
● HAClient通常用来实现主从节点间的通信和协调,包括但不限于心跳检测、状态同步、数据复制等操作,确保系统的高可用性和数据一致性。
主节点发送消息方法WriteSocketService
public void run() {HAConnection.log.info(this.getServiceName() + " service started");while (!this.isStopped()) {try {// 使用选择器(Selector)等待1秒钟,检测是否有网络事件(如连接请求或数据接收)this.selector.select(1000);if (-1 == HAConnection.this.slaveRequestOffset) {//如果从节点请求的偏移量尚未初始化(值为-1) 睡眠10ms 继续下一轮循环Thread.sleep(10);continue;}// 如果从节点请求的偏移量尚未初始化(值为-1)if (-1 == this.nextTransferFromWhere) {// 从阶段请求偏移量为0的情况if (0 == HAConnection.this.slaveRequestOffset) {//获得主节点最大偏移量(最后一个commitLog)long masterOffset = HAConnection.this.haService.getDefaultMessageStore().getCommitLog().getMaxOffset();// 对齐到CommitLog映射文件大小的整数倍,以便进行数据传输// 对齐到单个文件的起始偏移量masterOffset =masterOffset- (masterOffset % HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getMappedFileSizeCommitLog());if (masterOffset < 0) {masterOffset = 0;}// 设置从哪里开始向从节点传输数据this.nextTransferFromWhere = masterOffset;} else {this.nextTransferFromWhere = HAConnection.this.slaveRequestOffset;}log.info("master transfer data from " + this.nextTransferFromWhere + " to slave[" + HAConnection.this.clientAddr+ "], and slave request " + HAConnection.this.slaveRequestOffset);}/*** 这段代码的核心逻辑是检查是否到了应该发送心跳包的时间(根据lastWriteTimestamp与当前时间差判断),* 如果是,则构建心跳包并尝试发送;如果不是心跳发送时间,则尝试发送实际数据。* 不论发送的是心跳包还是实际数据,都会根据transferData方法的返回结果决定是否继续循环等待下一次发送机会。*///如果最后一次写入已经完成if (this.lastWriteOver) {// 计算当前系统时间与上一次写入完成的时间戳之间的间隔(毫秒)long interval =HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now() - this.lastWriteTimestamp;// 间隔时间超过了发送心跳最大时间 5sif (interval > HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getHaSendHeartbeatInterval()) {// Build Header 构建心跳包头信息this.byteBufferHeader.position(0);this.byteBufferHeader.limit(headerSize);this.byteBufferHeader.putLong(this.nextTransferFromWhere);this.byteBufferHeader.putInt(0);this.byteBufferHeader.flip();//发送心跳包this.lastWriteOver = this.transferData();if (!this.lastWriteOver)continue;}} else {//发送实际数据this.lastWriteOver = this.transferData();if (!this.lastWriteOver)continue;}//从commitLog中读取数据SelectMappedBufferResult selectResult =HAConnection.this.haService.getDefaultMessageStore().getCommitLogData(this.nextTransferFromWhere);if (selectResult != null) {int size = selectResult.getSize();if (size > HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getHaTransferBatchSize()) {size = HAConnection.this.haService.getDefaultMessageStore().getMessageStoreConfig().getHaTransferBatchSize();}//发送下一个偏移量long thisOffset = this.nextTransferFromWhere;this.nextTransferFromWhere += size;// 缓冲区从新设置为size大小selectResult.getByteBuffer().limit(size);this.selectMappedBufferResult = selectResult;// Build Headerthis.byteBufferHeader.position(0);this.byteBufferHeader.limit(headerSize);this.byteBufferHeader.putLong(thisOffset);this.byteBufferHeader.putInt(size);this.byteBufferHeader.flip();// 发送数据this.lastWriteOver = this.transferData();} else {// 这行代码是在等待特定条件满足或者等待一段时间后继续执行HAConnection.this.haService.getWaitNotifyObject().allWaitForRunning(100);}} catch (Exception e) {HAConnection.log.error(this.getServiceName() + " service has exception.", e);break;}}// 关闭服务//这一行代码从等待线程表中移除当前线程。在高可用(HA)服务中,可能存在一个线程等待表,记录着等待特定条件满足的线程。// 执行此行代码意味着当前线程完成了它的等待任务,不再需要留在等待线程表中。HAConnection.this.haService.getWaitNotifyObject().removeFromWaitingThreadTable();if (this.selectMappedBufferResult != null) {this.selectMappedBufferResult.release();//释放缓存区}this.makeStop();readSocketService.makeStop();haService.removeConnection(HAConnection.this);SelectionKey sk = this.socketChannel.keyFor(this.selector);if (sk != null) {sk.cancel();}try {this.selector.close();this.socketChannel.close();} catch (IOException e) {HAConnection.log.error("", e);}HAConnection.log.info(this.getServiceName() + " service end");}
上面方法大致流程(循环里):
● 获得主节点最后一个commitLog文件偏移量。
● 查是否到了应该发送心跳包的时间
● 如果是,则构建心跳包并尝试发送;如果不是心跳发送时间,则尝试发送实际数据。
● 不论发送的是心跳包还是实际数据,都会根据transferData方法的返回结果决定是否继续循环等待下一次发送机会。
进入transferData()方法
private boolean transferData() throws Exception {int writeSizeZeroTimes = 0;// Write Header 写头 如果byteBufferHeader还有空间/*** 当连续三次发送的数据为0则表示数据发送完毕*/while (this.byteBufferHeader.hasRemaining()) {// 返回这次实际发出的数据int writeSize = this.socketChannel.write(this.byteBufferHeader);if (writeSize > 0) {writeSizeZeroTimes = 0;this.lastWriteTimestamp = HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now();} else if (writeSize == 0) {if (++writeSizeZeroTimes >= 3) {break;}} else {throw new Exception("ha master write header error < 0");}}if (null == this.selectMappedBufferResult) {return !this.byteBufferHeader.hasRemaining();}writeSizeZeroTimes = 0;// Write Bodyif (!this.byteBufferHeader.hasRemaining()) {// commitLog中的数据 也是如果连续3次发送的数据为0则认为发送完毕while (this.selectMappedBufferResult.getByteBuffer().hasRemaining()) {int writeSize = this.socketChannel.write(this.selectMappedBufferResult.getByteBuffer());if (writeSize > 0) {writeSizeZeroTimes = 0;this.lastWriteTimestamp = HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now();} else if (writeSize == 0) {if (++writeSizeZeroTimes >= 3) {break;}} else {throw new Exception("ha master write body error < 0");}}}boolean result = !this.byteBufferHeader.hasRemaining() && !this.selectMappedBufferResult.getByteBuffer().hasRemaining();if (!this.selectMappedBufferResult.getByteBuffer().hasRemaining()) {this.selectMappedBufferResult.release();this.selectMappedBufferResult = null;}return result;}
● 通过循环发送数据,确保数据完整传输,当writeSize大于0时,表示有数据成功发送,当writeSize等于0时,累计次数,连续三次等于0则认为发送完毕。这种方法有效地处理了网络不稳定或阻塞等情况,提高了数据传输的鲁棒性(稳定性:我也不知道为啥当初要音译)。
● 整个方法确保了数据的原子性发送,只有当头和正文均发送完毕时,才返回true,表示传输完成,从而确保了主从节点之间数据的一致性。
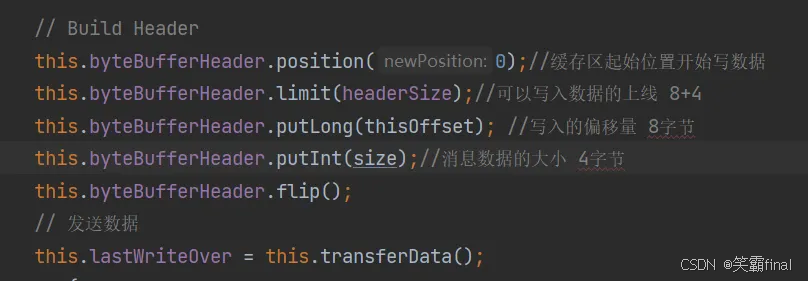
主向从发心跳包的格式
心跳包 大小12字节包含:
● 8字节的 写入偏移量
● 4字节的 消息大小

从节点接收数据
HAClient的run()的方法
分析while循环代码,下面processReadEvent就是接收方法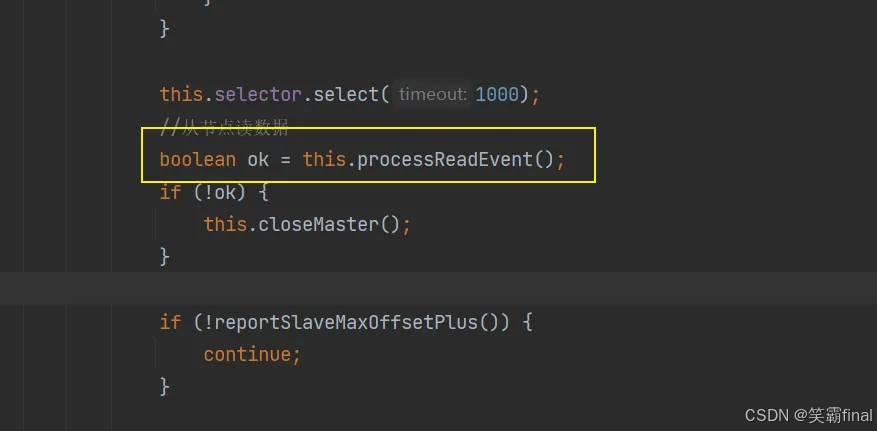
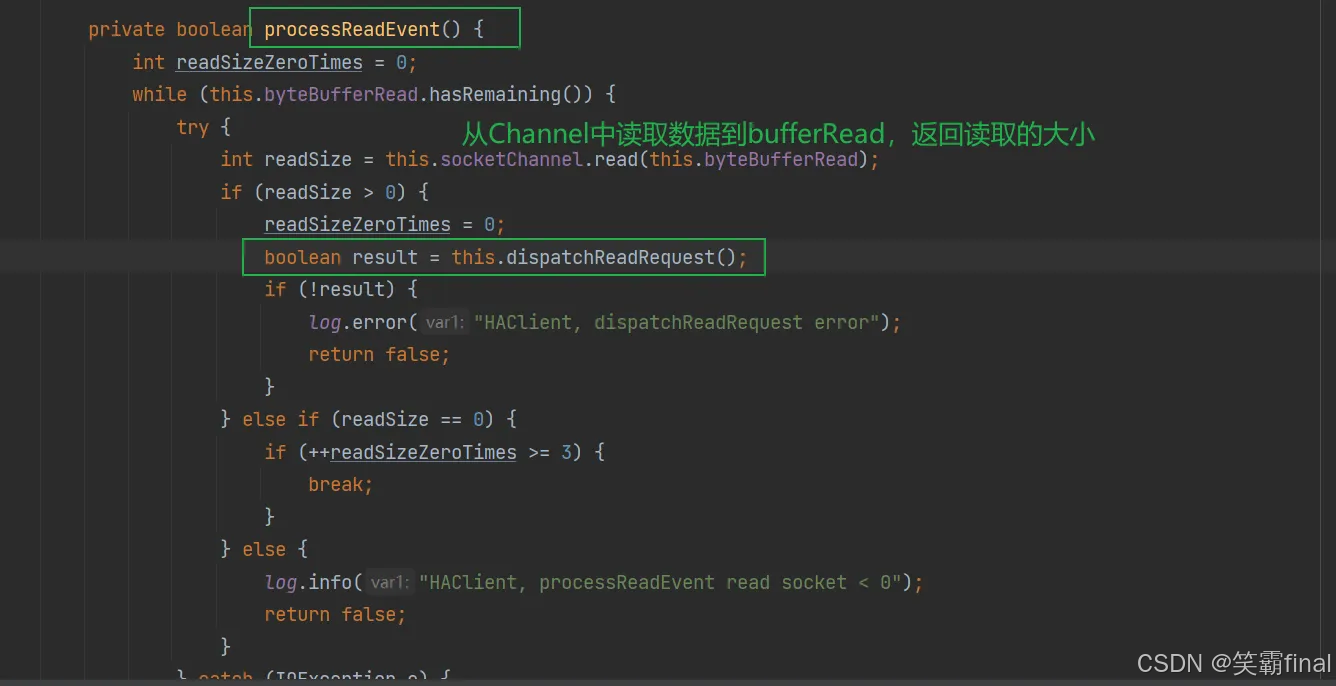
dispatchReadRequest就是保存消息的方法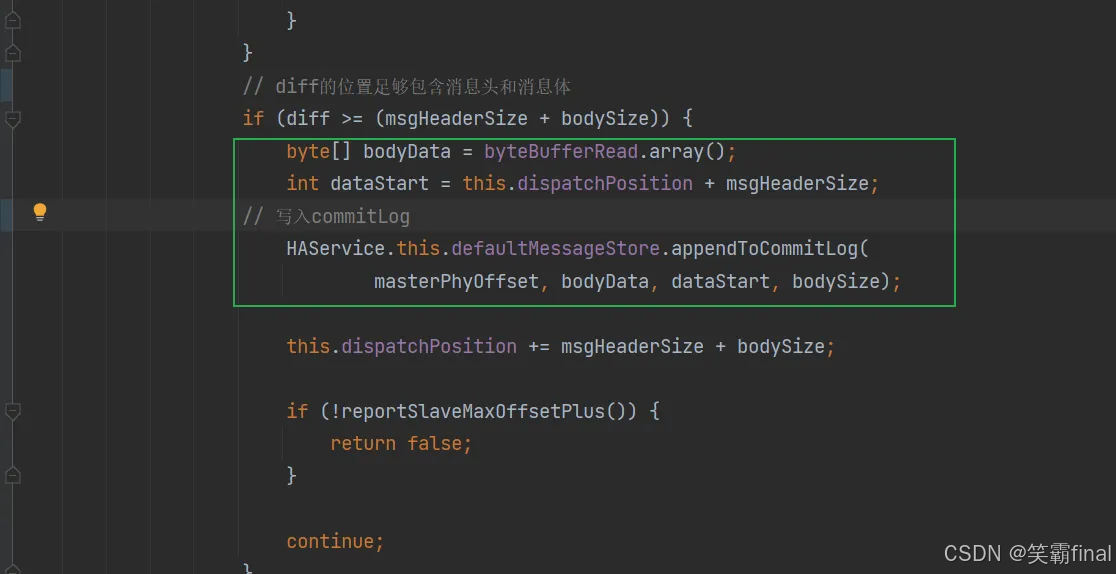
主节点接收从数据ReadSocketService
ReadSocketService.run()方法中processReadEvent是具体接收的方法,在processReadEvent里面whie循环里面是核心过程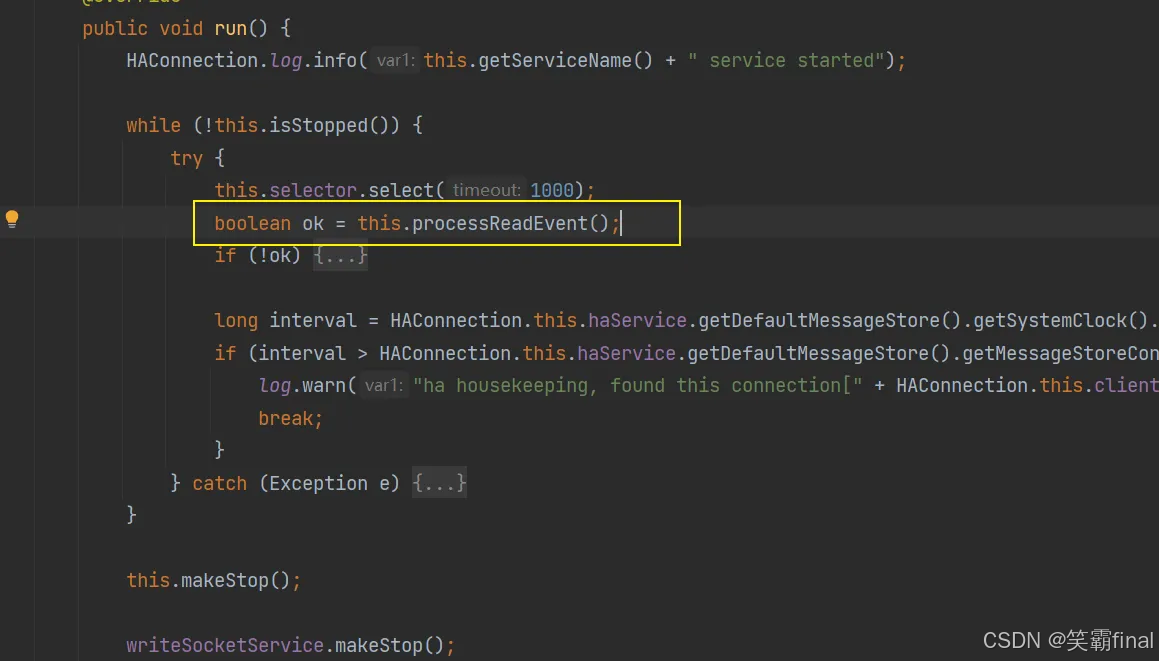
while (this.byteBufferRead.hasRemaining()) {try {// 从Channel里面读数据到 byteBufferReadint readSize = this.socketChannel.read(this.byteBufferRead);if (readSize > 0) {readSizeZeroTimes = 0;this.lastReadTimestamp = HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now();// 因为偏移量信息通常是8字节if ((this.byteBufferRead.position() - this.processPosition) >= 8) {// 确保8字节对齐 8int pos = this.byteBufferRead.position() - (this.byteBufferRead.position() % 8);//读取一个长整型的偏移量 (8位)long readOffset = this.byteBufferRead.getLong(pos - 8);this.processPosition = pos;// ack 表示主节点已知从节点已经处理到的位置HAConnection.this.slaveAckOffset = readOffset;if (HAConnection.this.slaveRequestOffset < 0) {// 检查slaveRequestOffset是否小于0,如果是,则说明这是从节点首次反馈其处理位置,// 将readOffset赋值给slaveRequestOffset并记录日志。HAConnection.this.slaveRequestOffset = readOffset;log.info("slave[" + HAConnection.this.clientAddr + "] request offset " + readOffset);}// 通知主节点已经收到了从节点的ACK,可以依据slaveAckOffset来决定下一轮数据同步的起始位置。HAConnection.this.haService.notifyTransferSome(HAConnection.this.slaveAckOffset);}} else if (readSize == 0) {// 连续三次读到的数据为0 则认为消息读取完毕跳出循环if (++readSizeZeroTimes >= 3) {break;}} else {log.error("read socket[" + HAConnection.this.clientAddr + "] < 0");return false;}} catch (IOException e) {log.error("processReadEvent exception", e);return false;}}
这段代码是RocketMQ 主从复制(Master-Slave Replication)中 主节点处理从节点反馈的逻辑 的核心实现。它负责读取从节点发送过来的 ACK 消息,并更新主节点对从节点同步状态的认知
总结
ACK 数据格式: 从节点发送的 ACK 数据是一个长整型(8 字节),表示从节点已处理的消息偏移量。对齐处理: 在读取偏移量时,确保数据对齐到 8 字节边界,避免读取不完整或错误的数据。状态更新: 主节点会根据从节点发送的偏移量更新 slaveAckOffset 和 slaveRequestOffset,以便后续数据同步。通知机制: 主节点通过 notifyTransferSome 方法通知自己,可以依据从节点的 ACK 偏移量决定下一轮同步的起始位置。异常处理: 对各种异常情况进行处理(如读取失败、IO 异常等),确保系统的健壮性。