GoLang基础
1.Go认知
简介:
Go(又称 Golang)是 Google 的 Robert Griesemer,Rob Pike 及 Ken Thompson 开发的一种计算机编程语言语言。
设计初衷:
Go语言是谷歌推出的一种的编程语言,可以在不损失应用程序性能的情况下降低代码的复杂性。谷歌首席软件工程师罗布派克(Rob Pike)说:我们之所以开发Go,是因为过去10多年间软件开发的难度令人沮丧。派克表示,和今天的C++或C一样,Go是一种系统语言。他解释道,"使用它可以进行快速开发,同时它还是一个真正的编译语言,我们之所以现在将其开源,原因是我们认为它已经非常有用和强大。"
设计原因:
1.计算机硬件技术更新频繁,性能提高很快。目前主流的编程语言发展明显落后于硬件,不能合理利用多核多CPU的优势提升软件系统性能。2.软件系统复杂度越来越高,维护成本越来越高,目前缺乏一个足够简洁高效的编程语言。3.企业运行维护很多c/c++的项目,c/c++程序运行速度虽然很快,但是编译速度确很慢,同时还存在内存泄漏的一系列的困扰需要解决。
发展简史
2007年,谷歌工程师Rob Pike, Ken Thompson和Robert Grisemer开始设计一门全新的语言,这是Go语言的最初原型。 2009年11月,Google将Go语言以开放源代码的方式向全球发布。 2015年8月,Go1.5版发布,本次更新中移除了"最后残余的c代码" 2017年2月,Go语言Go 1.8版发布。 2017年8月,Go语言Go 1.9版发布。 2018年2月,Go语言Go1.10版发布。 2018年8月,Go语言Go1.11版发布。 2019年2月,Go语言Go1.12版发布。 2019年9月,Go语言Go1.13版发布。 2020年2月,Go语言Go1.14版发布。 2020年8月,Go语言Go1.15版发布。 ....一直迭代
吉祥物

2.开发环境+GoLand下载
搭建Go开发环境 - 安装和配置SDK
基本介绍: 1.SDK的全称(Software Development Kit 软件开发工具包) 2.SDK是提供给开发人员使用的,其中包含了对应开发语言的工具包。
SDK下载
1.Go语言的官网为: golang.org ,无法访问,需要翻墙。 2.SDK下载地址 : Golang中文社区:Go下载 - Go语言中文网 - Golang中文社区 (1.15.6版本)
安装SDK:
请注意:安装路径不要有中文或者特殊符号如空格等
3.基本语法
Go的基本语法十分简洁且简单,下面通过一个简单的示例来进行讲解。
package mainimport "fmt"func main() {fmt.Println("Hello 世界!")
}package关键字代表的是当前go文件属于哪一个包,启动文件通常是main包,启动函数是main函数,在自定义包和函数时命名应当尽量避免与之重复。
import是导入关键字,后面跟着的是被导入的包名。
func是函数声明关键字,用于声明一个函数。
fmt.Println("Hello 世界!")是一个语句,调用了fmt包下的Println函数进行控制台输出。
以上就是一个简单的语法介绍。
包
在Go中,程序是通过将包链接在一起来构建的,也可以理解为最基本的调用单位是包,而不是go文件。包其实就是一个文件夹,包内共享所有源文件的变量,常量,函数以及其他类型。包的命名风格建议都是小写字母,并且要尽量简短。
导入
例如创建一个example包,包下有如下函数
package exampleimport "fmt"func SayHello() {fmt.Println("Hello")
}在main函数中调用
package mainimport "example"func main() {example.SayHello()
}还可以给包起别名
package mainimport e "example"func main() {e.SayHello()
}批量导入时,可以使用括号()来表示
package mainimport ("fmt""math"
)func main() {fmt.Println(math.MaxInt64)
}或者说只导入不调用,通常这么做是为了调用该包下的init函数。
package mainimport ("fmt"_ "math" // 下划线表示匿名导入
)func main() {fmt.Println(1)
}注意
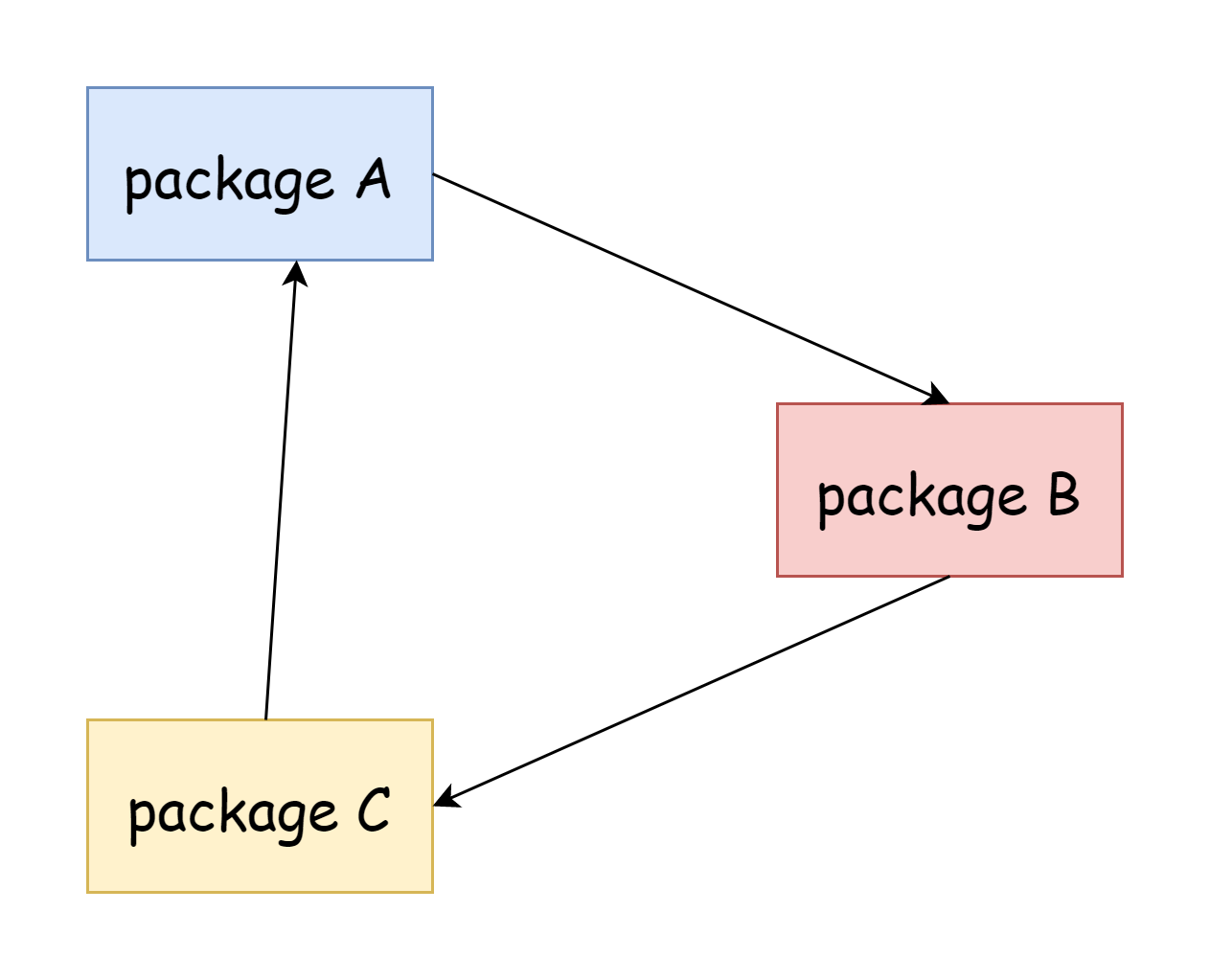
在Go中完全禁止循环导入,不管是直接的还是间接的。例如包A导入了包B,包B也导入了包A,这是直接循环导入,包A导入了包C,包C导入了包B,包B又导入了包A,这就是间接的循环导入,存在循环导入的话将会无法通过编译。
导出
在Go中,导出和访问控制是通过命名来进行实现的,如果想要对外暴露一个函数或者一个变量,只需要将其名称首字母大写即可,例如example包下的SayHello函数。
package exampleimport "fmt"// 首字母大写,可以被包外访问
func SayHello() {fmt.Println("Hello")
}如果想要不对外暴露的话,只需将名称首字母改为小写即可,例如下方代码
package exampleimport "fmt"// 首字母小写,外界无法访问
func sayHello() {fmt.Println("Hello")
}对外暴露的函数和变量可以被包外的调用者导入和访问,如果是不对外暴露的话,那么仅包内的调用者可以访问,外部将无法导入和访问,该规则适用于整个Go语言,例如后续会学到的结构体及其字段,方法,自定义类型,接口等等。
内部包
go中约定,一个包内名为internal 包为内部包,外部包将无法访问内部包中的任何内容,否则的话编译不通过,下面看一个例子。
/home/user/go/src/crash/bang/ (go code in package bang)b.gofoo/ (go code in package foo)f.gobar/ (go code in package bar)x.gointernal/baz/ (go code in package baz)z.goquux/ (go code in package main)y.go由文件结构中可知,crash包无法访问baz包中的类型。
注释
Go支持单行注释和多行注释,注释与内容之间建议隔一个空格,例如
// 这是main包
package main// 导入了fmt包
import "fmt"/*
*
这是启动函数main函数
*/
func main() {// 这是一个语句fmt.Println("Hello 世界!")
}标识符
标识符就是一个名称,用于包命名,函数命名,变量命名等等,命名规则如下:
-
只能由字母,数字,下划线组成
-
只能以字母和下划线开头
-
严格区分大小写
-
不能与任何已存在的标识符重复,即包内唯一的存在
-
不能与Go任何内置的关键字冲突
break default func interface select case defer go map struct chan else goto package switch const fallthrough if range type continue for import return var
字面量
字面量,按照计算机科学的术语来讲是用于表达源代码中一个固定值的符号,也叫字面值。两个叫法都是一个意思,写了什么东西,值就是什么,值就是“字面意义上“的值。
整型字面量
为了便于阅读,允许使用下划线_来进行数字划分,但是仅允许在前缀符号之后和数字之间使用。
24 // 24 024 // 24 2_4 // 24 0_2_4 // 24 10_000 // 10k 100_000 // 100k 0O24 // 20 0b00 // 0 0x00 // 0 0x0_0 // 0
浮点数字面量
通过不同的前缀可以表达不同进制的浮点数
0. 72.40 072.40 // == 72.40 2.71828 1.e+0 6.67428e-11 1E6 .25 .12345E+5 1_5. // == 15.0 0.15e+0_2 // == 15.00x1p-2 // == 0.25 0x2.p10 // == 2048.0 0x1.Fp+0 // == 1.9375 0X.8p-0 // == 0.5 0X_1FFFP-16 // == 0.1249847412109375 0x15e-2 // == 0x15e - 2 (integer subtraction)
复数字面量
0i 0123i // == 123i 0o123i // == 0o123 * 1i == 83i 0xabci // == 0xabc * 1i == 2748i 0.i 2.71828i 1.e+0i 6.67428e-11i 1E6i .25i .12345E+5i 0x1p-2i // == 0x1p-2 * 1i == 0.25i
字符字面量
字符字面量必须使用单引号括起来'',Go中的字符完全兼容utf8。
'a' 'ä' '你' '\t' '\000' '\007' '\377' '\x07' '\xff' '\u12e4' '\U00101234'
转义字符
Go中可用的转义字符
\a U+0007 响铃符号(建议调高音量) \b U+0008 回退符号 \f U+000C 换页符号 \n U+000A 换行符号 \r U+000D 回车符号 \t U+0009 横向制表符号 \v U+000B 纵向制表符号 \\ U+005C 反斜杠转义 \' U+0027 单引号转义 (该转义仅在字符内有效) \" U+0022 双引号转义 (该转义仅在字符串内有效)
字符串字面量
字符串字面量必须使用双引号""括起来或者反引号(反引号字符串不允许转义)
`abc` // "abc" `\n \n` // "\\n\n\\n" "\n" "\"" // `"` "Hello, world!\n" "今天天气不错" "日本語" "\u65e5本\U00008a9e" "\xff\u00FF"
风格
关于编码风格这一块Go是强制所有人统一同一种风格,Go官方提供了一个格式化工具gofmt,通过命令行就可以使用,该格式化工具没有任何的格式化参数可以传递,仅有的两个参数也只是输出格式化过程,所以完全不支持自定义,也就是说所有通过此工具的格式化后的代码都是同一种代码风格,这会极大的降低维护人员的心智负担,所以在这一块追求个性显然是一个不太明智的选择。
下面会简单列举一些规则,平时在编写代码的时候也可以稍微注意一下。
-
花括号,关于花括号
{}到底该不该换行,几乎每个程序员都能说出属于自己的理由,在Go中所有的花括号都不应该换行。
// 正确示例
func main() {fmt.Println("Hello 世界!")
}// 错误示例
func main()
{fmt.Println("Hello 世界!")
}-
缩进,Go默认使用
tab也就是制表符进行缩进,仅在一些特殊情况会使用空格。 -
间隔,Go中大部分间隔都是有意义的,从某种程度上来说,这也代表了编译器是如何看待你的代码的,例如下方的数学运算
2*9 + 1/3*2
众所周知,乘法的优先级比加法要高,在格式化后,
*符号之间的间隔会显得更紧凑,意味着优先进行运算,而+符号附近的间隔则较大,代表着较后进行运算。 -
还是花括号,花括号在任何时候都不能够省略,就算是只有一行代码,例如
// 正确示例 if a > b {a++ } // 错误示例 if a > b a++
4.变量的创建和使用
变量是用于保存一个值的存储位置,允许其存储的值在运行时动态的变化。每声明一个变量,都会为其分配一块内存以存储对应类型的值。
声明
在go中的类型声明是后置的,变量的声明会用到var关键字,格式为var 变量名 类型名,变量名的命名规则必须遵守标识符的命名规则。
var intNum int
var str string
var char byte当要声明多个相同类型的变量时,可以只写一次类型
var numA, numB, numC int当要声明多个不同类型的变量时,可以使用()进行包裹,可以存在多个()。
var (name stringage intaddress string
)var (school stringclass int
) 一个变量如果只是声明而不赋值,那么变量存储的值就是对应类型的零值。
赋值
赋值会用到运算符=,例如
var name string
name = "jack"也可以声明的时候直接赋值
var name string = "jack"或者这样也可以
var name string
var age int
name, age = "jack", 1第二种方式每次都要指定类型,可以使用官方提供的语法:短变量初始化,可以省略掉var关键字和后置类型,具体是什么类型交给编译器自行推断。
name := "jack" // 字符串类型的变量。虽然可以不用指定类型,但是在后续赋值时,类型必须保持一致,下面这种代码无法通过编译。
a := 1
a = "1"还需要注意的是,短变量初始化不能使用nil,因为nil不属于任何类型,编译器无法推断其类型。
name := nil // 无法通过编译短变量声明可以批量初始化
name, age := "jack", 1短变量声明方式无法对一个已存在的变量使用,比如
// 错误示例
var a int
a := 1// 错误示例
a := 1
a := 2但是有一种情况除外,那就是在赋值旧变量的同时声明一个新的变量,比如
a := 1
a, b := 2, 2这种代码是可以通过编译的,变量a被重新赋值,而b是新声明的。
在go语言中,有一个规则,那就是所有在函数中的变量都必须要被使用,比如下面的代码只是声明了变量,但没有使用它
func main() {a := 1
}那么在编译时就会报错,提示你这个变量声明了但没有使用
a declared and not used这个规则仅适用于函数内的变量,对于函数外的包级变量则没有这个限制,下面这个代码就可以通过编译。
var a = 1
func main() {
}匿名
用下划线可以表示不需要某一个变量
Open(name string) (*File, error)比如os.Open函数有两个返回值,我们只想要第一个,不想要第二个,可以按照下面这样写
file, _ := os.Open("readme.txt")未使用的变量是无法通过编译的,当你不需要某一个变量时,就可以使用下划线_代替。
交换
在Go中,如果想要交换两个变量的值,不需要使用指针,可以使用赋值运算符直接进行交换,语法上看起来非常直观,例子如下
num1, num2 := 25, 36
num1, num2 = num2, num1三个变量也是同样如此
num1, num2, num3 := 25, 36, 49
num1, num2, num3 = num3, num2, num1思考下面这一段代码,这是计算斐波那契数列的一小段代码,三个变量在计算后的值分别是什么
a, b, c := 0, 1, 1
a, b, c = b, c, a+b答案是
1 1 1你可能会疑惑为什么不是
1 1 2明明a已经被赋予b的值了,为什么a+b的结果还是1?go在进行多个变量赋值运算时,它的顺序是先计算值再赋值,并非从左到右计算。
a, b, c = b, c, a+b你可能会以为它会被展开成下面这段
a = b
b = c
c = a + b但实际上它会将a, b, c三个数的值分别计算好再赋给它们,就等同于下面这段代码
a, b, c = 1, 1, 0+1当涉及到函数调用时,这个效果就更为明显,我们有一个函数sum可以计算两个数字的返回值
func sum(a, b int) int {return a + b
}通过函数来进行两数相加
a, b, c := 0, 1, 1
a, b, c = b, c, sum(a, b)结果没有变化,在计算sum函数返回值时,它的入参依旧是0和1
1 1 1所以代码应该这样分开写。
a, b = b, c
c = a + b比较
变量之间的比较有一个大前提,那就是它们之间的类型必须相同,go语言中不存在隐式类型转换,像下面这样的代码是无法通过编译的
func main() {var a uint64var b int64fmt.Println(a == b)
}编译器会告诉你两者之间类型并不相同
invalid operation: a == b (mismatched types uint64 and int64)所以必须使用强制类型转换
func main() {var a uint64var b int64fmt.Println(int64(a) == b)
}在没有泛型之前,早期go提供的内置min,max函数只支持浮点数,到了1.21版本,go才终于将这两个内置函数用泛型重写,现在可以使用min函数比较最小值
minVal := min(1, 2, -1, 1.2)使用max函数比较最大值
maxVal := max(100, 22, -1, 1.12)它们的参数支持所有的可比较类型,go中的可比较类型有
-
布尔
-
数字
-
字符串
-
指针
-
通道 (仅支持判断是否相等)
-
元素是可比较类型的数组(切片不可比较)
-
字段类型都是可比较类型的结构体(仅支持判断是否相等)
除此之外,还可以通过导入标准库cmp来判断,不过仅支持有序类型的参数,在go中内置的有序类型只有数字和字符串。
import "cmp"func main() {cmp.Compare(1, 2)cmp.Less(1, 2)
}代码块
在函数内部,可以通过花括号建立一个代码块,代码块彼此之间的变量作用域是相互独立的。例如下面的代码
func main() {a := 1{a := 2fmt.Println(a)}{a := 3fmt.Println(a)}fmt.Println(a)
}它的输出是
2
3
1块与块之间的变量相互独立,不受干扰,无法访问,但是会受到父块中的影响。
func main() {a := 1{a := 2fmt.Println(a)}{fmt.Println(a)}fmt.Println(a)
}它的输出是
2
1
15.常量的创建和使用
常量的值无法在运行时改变,一旦赋值过后就无法修改,其值只能来源于:
-
字面量
-
其他常量标识符
-
常量表达式
-
结果是常量的类型转换
-
iota
常量只能是基本数据类型,不能是
-
除基本类型以外的其它类型,如结构体,接口,切片,数组等函数的返回值
-
常量的值无法被修改,否则无法通过编译
定义
常量的定义格式:
const identifier [type] = value你可以省略类型说明符 [type],因为编译器可以根据变量的值来推断其类型。
-
显式类型定义:
const b string = "abc" -
隐式类型定义:
const b = "abc"
多个相同类型的声明可以简写为:
const c_name1, c_name2 = value1, value2初始化
常量的声明需要用到const关键字,常量在声明时就必须初始化一个值,并且常量的类型可以省略,例如
const name string = "Jack" // 字面量
const msg = "hello world" // 字面量
const num = 1 // 字面量
const numExpression = (1+2+3) / 2 % 100 + num // 常量表达式如果仅仅只是声明而不指定值,将会无法通过编译
const name string编译器报错
missing init expr for name批量声明常量可以用()括起来以提升可读性,可以存在多个()达到分组的效果。
const (Count = 1Name = "Jack"
)
const (Size = 16Len = 25
)在同一个常量分组中,在已经赋值的常量后面的常量可以不用赋值,其值默认就是前一个的值,比如
const (A = 1B // 1C // 1D // 1E // 1
)iota
iota是一个内置的常量标识符,通常用于表示一个常量声明中的无类型整数序数,一般都是在括号中使用。
const iota = 0 看几个使用案例
const (Num = iota // 0Num1 // 1Num2 // 2Num3 // 3Num4 // 4
)也可以这么写
const (Num = iota*2 // 0Num1 // 2Num2 // 4Num3 // 6Num4 // 8
)还可以
const (Num = iota << 2*3 + 1 // 1Num1 // 13Num2 // 25Num3 = iota // 3Num4 // 4
)通过上面几个例子可以发现,iota是递增的,第一个常量使用iota值的表达式,根据序号值的变化会自动的赋值给后续的常量,直到用新的iota重置,这个序号其实就是代码的相对行号,是相对于当前分组的起始行号,看下面的例子
const (Num = iota<<2*3 + 1 // 1 第一行Num2 = iota<<2*3 + 1 // 13 第二行_ // 25 第三行Num3 //37 第四行Num4 = iota // 4 第五行_ // 5 第六行Num5 // 6 第七行
)例子中使用了匿名标识符_占了一行的位置,可以看到iota的值本质上就是iota所在行相对于当前const分组的第一行的差值。而不同的const分组则相互不会影响。
枚举
Go语言没有为枚举单独设计一个数据类型,不像其它语言通常会有一个enum来表示。一般在Go中,都是通过自定义类型 + const + iota来实现枚举,下面是一个简单的例子
type Season uint8const (Spring Season = iotaSummerAutumnWinter
)这些枚举实际上就是数字,Go也不支持直接将其转换为字符串,但我们可以通过给自定义类型添加方法来返回其字符串表现形式,实现Stringer接口即可。
func (s Season) String() string {switch s {case Spring:return "spring"case Summer:return "summer"case Autumn:return "autumn"case Winter:return "winter"}return ""
}这样一来就是一个简单的枚举实现了。你也可以通过官方工具Stringeropen in new window来自动生成枚举。
不过它有以下缺点:
-
类型不安全,因为
Season是自定义类型,可以通过强制类型转换将其他数字也转换成该类型Season(6)
-
繁琐,字符串表现形式需要自己实现
-
表达能力弱,因为
const仅支持基本数据类型,所以这些枚举值也只能用字符串和数字来进行表示
6.常用数据类型
布尔类型
布尔类型只有真值和假值。
| 类型 | 描述 |
|---|---|
bool | true为真值,false为假值 |
提示:
在Go中,整数0并不代表假值,非零整数也不能代表真值,即数字无法代替布尔值进行逻辑判断,两者是完全不同的类型。
整型
Go中为不同位数的整数分配了不同的类型,主要分为无符号整型与有符号整型。
| 序号 | 类型和描述 |
|---|---|
uint8 | 无符号 8 位整型 |
uint16 | 无符号 16 位整型 |
uint32 | 无符号 32 位整型 |
uint64 | 无符号 64 位整型 |
int8 | 有符号 8 位整型 |
int16 | 有符号 16 位整型 |
int32 | 有符号 32 位整型 |
int64 | 有符号 64 位整型 |
uint | 无符号整型 至少32位 |
int | 整型 至少32位 |
uintptr | 等价于无符号64位整型,但是专用于存放指针运算,用于存放死的指针地址。 |
浮点型
IEEE-754浮点数,主要分为单精度浮点数与双精度浮点数。
| 类型 | 类型和描述 |
|---|---|
float32 | IEEE-754 32位浮点数 |
float64 | IEEE-754 64位浮点数 |
复数类型
| 类型 | 描述 |
|---|---|
complex128 | 64位实数和虚数 |
complex64 | 32位实数和虚数 |
字符类型
go语言字符串完全兼容UTF-8
| 类型 | 描述 |
|---|---|
byte | 等价 uint8 可以表达ANSCII字符 |
rune | 等价 int32 可以表达Unicode字符 |
string | 字符串即字节序列,可以转换为[]byte类型即字节切片 |
派生类型下·
| 类型 | 例子 |
|---|---|
| 数组 | [5]int,长度为5的整型数组 |
| 切片 | []float64,64位浮点数切片 |
| 映射表 | map[string]int,键为字符串类型,值为整型的映射表 |
| 结构体 | type Gopher struct{},Gopher结构体 |
| 指针 | *int,一个整型指针。 |
| 函数 | type f func(),一个没有参数,没有返回值的函数类型 |
| 接口 | type Gopher interface{},Gopher接口 |
| 通道 | chan int,整型通道 |
零值
官方文档中零值称为zero value,零值并不仅仅只是字面上的数字零,而是一个类型的空值或者说默认值更为准确。
| 类型 | 零值 |
|---|---|
| 数字类型 | 0 |
| 布尔类型 | false |
| 字符串类型 | "" |
| 数组 | 固定长度的对应类型的零值集合 |
| 结构体 | 内部字段都是零值的结构体 |
| 切片,映射表,函数,接口,通道,指针 | nil |
nil
源代码中的nil,可以看出nil仅仅只是一个变量。
var nil TypeGo中的nil并不等同于其他语言的null,nil仅仅只是一些类型的零值,并且不属于任何类型,所以nil == nil这样的语句是无法通过编译的。
7.运算符
算术运算符
下表列出了所有Go语言的算术运算符。假定 A 值为 10,B 值为 20。
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 相加 | A + B 输出结果 30 |
| - | 相减 | A - B 输出结果 -10 |
| * | 相乘 | A * B 输出结果 200 |
| / | 相除 | B / A 输出结果 2 |
| % | 求余 | B % A 输出结果 0 |
| ++ | 自增 | A++ 输出结果 11 |
| -- | 自减 | A-- 输出结果 9 |
以下实例演示了各个算术运算符的用法:
实例
package mainimport "fmt"func main() {var a int = 21var b int = 10var c intc = a + bfmt.Printf("第一行 - c 的值为 %d\n", c )c = a - bfmt.Printf("第二行 - c 的值为 %d\n", c )c = a * bfmt.Printf("第三行 - c 的值为 %d\n", c )c = a / bfmt.Printf("第四行 - c 的值为 %d\n", c )c = a % bfmt.Printf("第五行 - c 的值为 %d\n", c )a++fmt.Printf("第六行 - a 的值为 %d\n", a )a=21 // 为了方便测试,a 这里重新赋值为 21a--fmt.Printf("第七行 - a 的值为 %d\n", a )
}以上实例运行结果:
第一行 - c 的值为 31
第二行 - c 的值为 11
第三行 - c 的值为 210
第四行 - c 的值为 2
第五行 - c 的值为 1
第六行 - a 的值为 22
第七行 - a 的值为 20关系运算符
下表列出了所有Go语言的关系运算符。假定 A 值为 10,B 值为 20。
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个值是否相等,如果相等返回 True 否则返回 False。 | (A == B) 为 False |
| != | 检查两个值是否不相等,如果不相等返回 True 否则返回 False。 | (A != B) 为 True |
| > | 检查左边值是否大于右边值,如果是返回 True 否则返回 False。 | (A > B) 为 False |
| < | 检查左边值是否小于右边值,如果是返回 True 否则返回 False。 | (A < B) 为 True |
| >= | 检查左边值是否大于等于右边值,如果是返回 True 否则返回 False。 | (A >= B) 为 False |
| <= | 检查左边值是否小于等于右边值,如果是返回 True 否则返回 False。 | (A <= B) 为 True |
以下实例演示了关系运算符的用法:
实例
package mainimport "fmt"func main() {var a int = 21var b int = 10if( a == b ) {fmt.Printf("第一行 - a 等于 b\n" )} else {fmt.Printf("第一行 - a 不等于 b\n" )}if ( a < b ) {fmt.Printf("第二行 - a 小于 b\n" )} else {fmt.Printf("第二行 - a 不小于 b\n" )}if ( a > b ) {fmt.Printf("第三行 - a 大于 b\n" )} else {fmt.Printf("第三行 - a 不大于 b\n" )}/* Lets change value of a and b */a = 5b = 20if ( a <= b ) {fmt.Printf("第四行 - a 小于等于 b\n" )}if ( b >= a ) {fmt.Printf("第五行 - b 大于等于 a\n" )}
}以上实例运行结果:
第一行 - a 不等于 b
第二行 - a 不小于 b
第三行 - a 大于 b
第四行 - a 小于等于 b
第五行 - b 大于等于 a逻辑运算符
下表列出了所有Go语言的逻辑运算符。假定 A 值为 True,B 值为 False。
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 逻辑 AND 运算符。 如果两边的操作数都是 True,则条件 True,否则为 False。 | (A && B) 为 False |
| || | 逻辑 OR 运算符。 如果两边的操作数有一个 True,则条件 True,否则为 False。 | (A || B) 为 True |
| ! | 逻辑 NOT 运算符。 如果条件为 True,则逻辑 NOT 条件 False,否则为 True。 | !(A && B) 为 True |
以下实例演示了逻辑运算符的用法:
实例
package mainimport "fmt"func main() {var a bool = truevar b bool = falseif ( a && b ) {fmt.Printf("第一行 - 条件为 true\n" )}if ( a || b ) {fmt.Printf("第二行 - 条件为 true\n" )}/* 修改 a 和 b 的值 */a = falseb = trueif ( a && b ) {fmt.Printf("第三行 - 条件为 true\n" )} else {fmt.Printf("第三行 - 条件为 false\n" )}if ( !(a && b) ) {fmt.Printf("第四行 - 条件为 true\n" )}
}以上实例运行结果:
第二行 - 条件为 true
第三行 - 条件为 false
第四行 - 条件为 true位运算符
位运算符对整数在内存中的二进制位进行操作。
下表列出了位运算符 &, |, 和 ^ 的计算:
| P | Q | P & Q | P | Q | P ^ Q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
假定 A = 60; B = 13; 其二进制数转换为:
A = 0011 1100B = 0000 1101-----------------A&B = 0000 1100A|B = 0011 1101A^B = 0011 0001
Go 语言支持的位运算符如下表所示。假定 A 为60,B 为13:
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符"&"是双目运算符。 其功能是参与运算的两数各对应的二进位相与。 | (A & B) 结果为 12, 二进制为 0000 1100 |
| | | 按位或运算符"|"是双目运算符。 其功能是参与运算的两数各对应的二进位相或 | (A | B) 结果为 61, 二进制为 0011 1101 |
| ^ | 按位异或运算符"^"是双目运算符。 其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。 | (A ^ B) 结果为 49, 二进制为 0011 0001 |
| << | 左移运算符"<<"是双目运算符。左移n位就是乘以2的n次方。 其功能把"<<"左边的运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 | A << 2 结果为 240 ,二进制为 1111 0000 |
| >> | 右移运算符">>"是双目运算符。右移n位就是除以2的n次方。 其功能是把">>"左边的运算数的各二进位全部右移若干位,">>"右边的数指定移动的位数。 | A >> 2 结果为 15 ,二进制为 0000 1111 |
以下实例演示了位运算符的用法:
实例
package mainimport "fmt"func main() {var a uint = 60 /* 60 = 0011 1100 */var b uint = 13 /* 13 = 0000 1101 */var c uint = 0 c = a & b /* 12 = 0000 1100 */fmt.Printf("第一行 - c 的值为 %d\n", c )c = a | b /* 61 = 0011 1101 */fmt.Printf("第二行 - c 的值为 %d\n", c )c = a ^ b /* 49 = 0011 0001 */fmt.Printf("第三行 - c 的值为 %d\n", c )c = a << 2 /* 240 = 1111 0000 */fmt.Printf("第四行 - c 的值为 %d\n", c )c = a >> 2 /* 15 = 0000 1111 */fmt.Printf("第五行 - c 的值为 %d\n", c )
}以上实例运行结果:
第一行 - c 的值为 12
第二行 - c 的值为 61
第三行 - c 的值为 49
第四行 - c 的值为 240
第五行 - c 的值为 15赋值运算符
下表列出了所有Go语言的赋值运算符。
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 | C = A + B 将 A + B 表达式结果赋值给 C |
| += | 相加后再赋值 | C += A 等于 C = C + A |
| -= | 相减后再赋值 | C -= A 等于 C = C - A |
| *= | 相乘后再赋值 | C *= A 等于 C = C * A |
| /= | 相除后再赋值 | C /= A 等于 C = C / A |
| %= | 求余后再赋值 | C %= A 等于 C = C % A |
| <<= | 左移后赋值 | C <<= 2 等于 C = C << 2 |
| >>= | 右移后赋值 | C >>= 2 等于 C = C >> 2 |
| &= | 按位与后赋值 | C &= 2 等于 C = C & 2 |
| ^= | 按位异或后赋值 | C ^= 2 等于 C = C ^ 2 |
| |= | 按位或后赋值 | C |= 2 等于 C = C | 2 |
以下实例演示了赋值运算符的用法:
实例
package mainimport "fmt"func main() {var a int = 21var c intc = afmt.Printf("第 1 行 - = 运算符实例,c 值为 = %d\n", c )c += afmt.Printf("第 2 行 - += 运算符实例,c 值为 = %d\n", c )c -= afmt.Printf("第 3 行 - -= 运算符实例,c 值为 = %d\n", c )c *= afmt.Printf("第 4 行 - *= 运算符实例,c 值为 = %d\n", c )c /= afmt.Printf("第 5 行 - /= 运算符实例,c 值为 = %d\n", c )c = 200;c <<= 2fmt.Printf("第 6行 - <<= 运算符实例,c 值为 = %d\n", c )c >>= 2fmt.Printf("第 7 行 - >>= 运算符实例,c 值为 = %d\n", c )c &= 2fmt.Printf("第 8 行 - &= 运算符实例,c 值为 = %d\n", c )c ^= 2fmt.Printf("第 9 行 - ^= 运算符实例,c 值为 = %d\n", c )c |= 2fmt.Printf("第 10 行 - |= 运算符实例,c 值为 = %d\n", c )}以上实例运行结果:
第 1 行 - = 运算符实例,c 值为 = 21
第 2 行 - += 运算符实例,c 值为 = 42
第 3 行 - -= 运算符实例,c 值为 = 21
第 4 行 - *= 运算符实例,c 值为 = 441
第 5 行 - /= 运算符实例,c 值为 = 21
第 6行 - <<= 运算符实例,c 值为 = 800
第 7 行 - >>= 运算符实例,c 值为 = 200
第 8 行 - &= 运算符实例,c 值为 = 0
第 9 行 - ^= 运算符实例,c 值为 = 2
第 10 行 - |= 运算符实例,c 值为 = 2其他运算符
下表列出了Go语言的其他运算符。
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 返回变量存储地址 | &a; 将给出变量的实际地址。 |
| * | 指针变量。 | *a; 是一个指针变量 |
以下实例演示了其他运算符的用法:
实例
package mainimport "fmt"func main() {var a int = 4var b int32var c float32var ptr *int/* 运算符实例 */fmt.Printf("第 1 行 - a 变量类型为 = %T\n", a );fmt.Printf("第 2 行 - b 变量类型为 = %T\n", b );fmt.Printf("第 3 行 - c 变量类型为 = %T\n", c );/* & 和 * 运算符实例 */ptr = &a /* 'ptr' 包含了 'a' 变量的地址 */fmt.Printf("a 的值为 %d\n", a);fmt.Printf("*ptr 为 %d\n", *ptr);
}以上实例运行结果:
第 1 行 - a 变量类型为 = int
第 2 行 - b 变量类型为 = int32
第 3 行 - c 变量类型为 = float32
a 的值为 4
*ptr 为 4运算符优先级
有些运算符拥有较高的优先级,二元运算符的运算方向均是从左至右。下表列出了所有运算符以及它们的优先级,由上至下代表优先级由高到低:
| 优先级 | 运算符 |
|---|---|
| 5 | * / % << >> & &^ |
| 4 | + - | ^ |
| 3 | == != < <= > >= |
| 2 | && |
| 1 | || |
当然,你可以通过使用括号来临时提升某个表达式的整体运算优先级。
以上实例运行结果:
实例
package mainimport "fmt"func main() {var a int = 20var b int = 10var c int = 15var d int = 5var e int;e = (a + b) * c / d; // ( 30 \* 15 ) / 5fmt.Printf("(a + b) * c / d 的值为 : %d\n", e );e = ((a + b) * c) / d; // (30 \* 15 ) / 5fmt.Printf("((a + b) * c) / d 的值为 : %d\n" , e );e = (a + b) * (c / d); // (30) * (15/5)fmt.Printf("(a + b) * (c / d) 的值为 : %d\n", e );e = a + (b * c) / d; // 20 + (150/5)fmt.Printf("a + (b * c) / d 的值为 : %d\n" , e );
}以上实例运行结果:
(a + b) * c / d 的值为 : 90
((a + b) * c) / d 的值为 : 90
(a + b) * (c / d) 的值为 : 90
a + (b * c) / d 的值为 : 508.条件控制
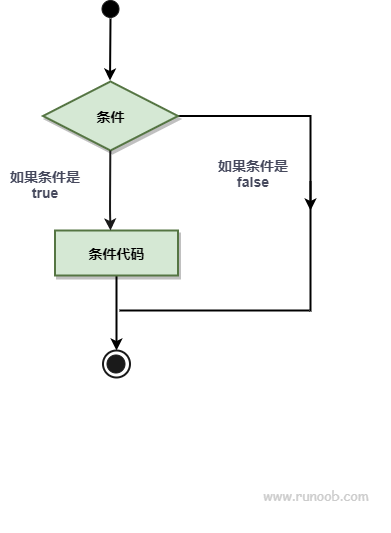
条件语句需要开发者通过指定一个或多个条件,并通过测试条件是否为 true 来决定是否执行指定语句,并在条件为 false 的情况在执行另外的语句。
下图展示了程序语言中条件语句的结构:
在Go中,条件控制语句总共有三种if,switch,select。
if
if 语句由布尔表达式后紧跟一个或多个语句组成。
语法
Go 编程语言中 if 语句的语法如下:
if 布尔表达式 {/* 在布尔表达式为 true 时执行 */
}
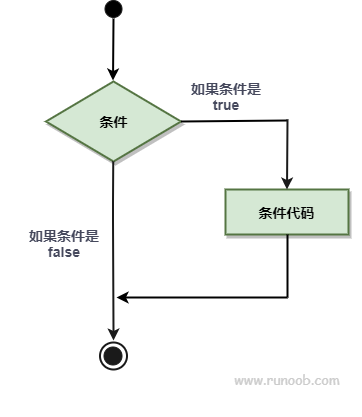
If 在布尔表达式为 true 时,其后紧跟的语句块执行,如果为 false 则不执行。
流程图如下:
实例
package mainimport "fmt"func main() {/* 定义局部变量 */var a int = 10/* 使用 if 语句判断布尔表达式 */if a < 20 {/* 如果条件为 true 则执行以下语句 */fmt.Printf("a 小于 20\n" )}fmt.Printf("a 的值为 : %d\n", a)
}以上代码执行结果为:
a 小于 20 a 的值为 : 10
if else
if else至多两个判断分支,语句格式如下
if expression {}
或者
if expression {}else {}
expression必须是一个布尔表达式,即结果要么为真要么为假,必须是一个布尔值,例子如下:
func main() {a, b := 1, 2if a > b {b++} else {a++}
}
也可以把表达式写的更复杂些,必要时为了提高可读性,应当使用括号来显式的表示谁应该优先计算。
func main() {a, b := 1, 2if a<<1%100+3 > b*100/20+6 { // (a<<1%100)+3 > (b*100/20)+6b++} else {a++}
}
同时if语句也可以包含一些简单的语句,例如:
func main() {if x := 1 + 1; x > 2 {fmt.Println(x)}
}
else if
else if 语句可以在if else的基础上创建更多的判断分支,语句格式如下:
if expression1 {}else if expression2 {}else if expression3 {}else {}
在执行的过程中每一个表达式的判断是从左到右,整个if语句的判断是从上到下 。一个根据成绩打分的例子如下,第一种写法
func main() {score := 90var ans stringif score == 100 {ans = "S"} else if score >= 90 && score < 100 {ans = "A"} else if score >= 80 && score < 90 {ans = "B"} else if score >= 70 && score < 80 {ans = "C"} else if score >= 60 && score < 70 {ans = "E"} else if score >= 0 && score < 60 {ans = "F"} else {ans = "nil"}fmt.Println(ans)
}第二种写法利用了if语句是从上到下的判断的前提,所以代码要更简洁些。
func main() {score := 90var ans stringif score >= 0 && score < 60 {ans = "F"} else if score < 70 {ans = "D"} else if score < 80 {ans = "C"} else if score < 90 {ans = "B"} else if score < 100 {ans = "A"} else if score == 100 {ans = "S"}else {ans = "nil"}fmt.Println(ans)
}switch
switch语句也是一种多分支的判断语句,语句格式如下:
switch expr {case case1:statement1case case2:statement2default:default statement
}一个简单的例子如下
func main() {str := "a"switch str {case "a":str += "a"str += "c"case "b":str += "bb"str += "aaaa"default: // 当所有case都不匹配后,就会执行default分支str += "CCCC"}fmt.Println(str)
}还可以在表达式之前编写一些简单语句,例如声明新变量
func main() {switch num := f(); { // 等价于 switch num := f(); true {case num >= 0 && num <= 1:num++case num > 1:num--fallthroughcase num < 0:num += num}
}func f() int {return 1
}switch语句也可以没有入口处的表达式。
func main() {num := 2switch { // 等价于 switch true { case num >= 0 && num <= 1:num++case num > 1:num--case num < 0:num *= num}fmt.Println(num)
}通过fallthrough关键字来继续执行相邻的下一个分支。
func main() {num := 2switch {case num >= 0 && num <= 1:num++case num > 1:num--fallthrough // 执行完该分支后,会继续执行下一个分支case num < 0:num += num}fmt.Println(num)
}label
标签语句,给一个代码块打上标签,可以是goto,break,continue的目标。例子如下:
func main() {A: a := 1B:b := 2
}单纯的使用标签是没有任何意义的,需要结合其他关键字来进行使用。
goto
goto将控制权传递给在同一函数中对应标签的语句,示例如下:
func main() {a := 1if a == 1 {goto A} else {fmt.Println("b")}
A:fmt.Println("a")
}在实际应用中goto用的很少,跳来跳去的很降低代码可读性,性能消耗也是一个问题。
select 语句
select 是 Go 中的一个控制结构,类似于 switch 语句。 select 语句只能用于通道操作,每个 case 必须是一个通道操作,要么是发送要么是接收。 select 语句会监听所有指定的通道上的操作,一旦其中一个通道准备好就会执行相应的代码块。 如果多个通道都准备好,那么 select 语句会随机选择一个通道执行。如果所有通道都没有准备好,那么执行 default 块中的代码。
语法
Go 编程语言中 select 语句的语法如下:
select {case <- channel1:// 执行的代码case value := <- channel2:// 执行的代码case channel3 <- value:// 执行的代码// 你可以定义任意数量的 casedefault:// 所有通道都没有准备好,执行的代码
}以下描述了 select 语句的语法:
-
每个 case 都必须是一个通道
-
所有 channel 表达式都会被求值
-
所有被发送的表达式都会被求值
-
如果任意某个通道可以进行,它就执行,其他被忽略。
-
如果有多个 case 都可以运行,select 会随机公平地选出一个执行,其他不会执行。
否则:
-
如果有 default 子句,则执行该语句。
-
如果没有 default 子句,select 将阻塞,直到某个通道可以运行;Go 不会重新对 channel 或值进行求值。
-
实例
package mainimport ("fmt""time"
)func main() {c1 := make(chan string)c2 := make(chan string)go func() {time.Sleep(1 * time.Second)c1 <- "one"}()go func() {time.Sleep(2 * time.Second)c2 <- "two"}()for i := 0; i < 2; i++ {select {casa msg1 := <-c1:fmt.Println("received", msg1)case msg2 := <-c2:fmt.Println("received", msg2)}}
}以上代码执行结果为:
received one received two
以上实例中,我们创建了两个通道 c1 和 c2。
select 语句等待两个通道的数据。如果接收到 c1 的数据,就会打印 "received one";如果接收到 c2 的数据,就会打印 "received two"。
以下实例中,我们定义了两个通道,并启动了两个协程(Goroutine)从这两个通道中获取数据。在 main 函数中,我们使用 select 语句在这两个通道中进行非阻塞的选择,如果两个通道都没有可用的数据,就执行 default 子句中的语句。
以下实例执行后会不断地从两个通道中获取到的数据,当两个通道都没有可用的数据时,会输出 "no message received"。
实例
package mainimport "fmt"func main() {// 定义两个通道ch1 := make(chan string)ch2 := make(chan string)// 启动两个 goroutine,分别从两个通道中获取数据go func() {for {ch1 <- "from 1"}}()go func() {for {ch2 <- "from 2"}}()// 使用 select 语句非阻塞地从两个通道中获取数据for {select {case msg1 := <-ch1:fmt.Println(msg1)case msg2 := <-ch2:fmt.Println(msg2)default:// 如果两个通道都没有可用的数据,则执行这里的语句fmt.Println("no message received")}}
}9.循环语法
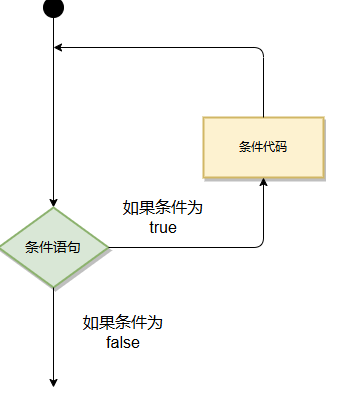
在不少实际问题中有许多具有规律性的重复操作,因此在程序中就需要重复执行某些语句。
以下为大多编程语言循环程序的流程图:
在Go中,有仅有一种循环语句:for,Go抛弃了while语句,for语句可以被当作while来使用。
for
语句格式如下
for init statement; expression; post statement {execute statement
}
当只保留循环条件时,就变成了while。
for expression {execute statement
}
这是一个死循环,永远也不会退出
for {execute statement
}
示例
这是一段输出[0,20]区间数字的代码
for i := 0; i <= 20; i++ {fmt.Println(i)
}
你可以同时初始化多个变量,然后将其递增
for i, j := 1, 2; i < 100 && j < 1000; i, j = i+1, j+1 {fmt.Println(i, j)
}
当成while来使用
num := 1
for num < 100 {num *= 2
}
双循环打印九九乘法表,这是一个很经典的循环案例
package mainimport "fmt"func main() {for i := 1; i <= 9; i++ {for j := 1; j <= i; j++ {fmt.Printf("%dX%d=%d", j, i, i*j)fmt.Print(" ")}fmt.Println()}
}输出如下
1X1=1 1X2=2 2X2=4 1X3=3 2X3=6 3X3=9 1X4=4 2X4=8 3X4=12 4X4=16 1X5=5 2X5=10 3X5=15 4X5=20 5X5=25 1X6=6 2X6=12 3X6=18 4X6=24 5X6=30 6X6=36 1X7=7 2X7=14 3X7=21 4X7=28 5X7=35 6X7=42 7X7=49 1X8=8 2X8=16 3X8=24 4X8=32 5X8=40 6X8=48 7X8=56 8X8=64 1X9=9 2X9=18 3X9=27 4X9=36 5X9=45 6X9=54 7X9=63 8X9=72 9X9=81
for range
由于完整的range的学习需要学习后面的字符串,映射和通道等作为基础,所以具体的内容在第17章。
for range可以更加方便的遍历一些可迭代的数据结构,如数组,切片,字符串,映射表,通道。语句格式如下:
for index, value := range iterable {// body
}
index为可迭代数据结构的索引,value则是对应索引下的值,例如使用for range遍历一个字符串。
func main() {sequence := "hello world"for index, value := range sequence {fmt.Println(index, value)}
}
for range也可以迭代一个整型值,字面量,常量,变量都是有效的。
for i := range 10 {fmt.Println(i)
}n := 10
for i := range n {fmt.Println(i)
}const n = 10
for i := range n {fmt.Println(i)
}
对于每一个种数据结构,for range的实现都有所不同,后续也会讲到,你可以前往Go - for statementopen in new window以了解更多细节。
break
break关键字会终止最内层的for循环,结合标签一起使用可以达到终止外层循环的效果,例子如下:这是一个双循环
func main() {for i := 0; i < 10; i++ {for j := 0; j < 10; j++ {if i <= j {break}fmt.Println(i, j)}}
}
输出
1 0 2 0 2 1 3 0 3 1 3 2 ... 9 6 9 7 9 8
使用标签来中断外层循环
func main() {
Outer:for i := 0; i < 10; i++ {for j := 0; j < 10; j++ {if i <= j {break Outer}fmt.Println(i, j)}}
}
continue
continue关键字会跳过最内层循环的本次迭代,直接进入下一次迭代,结合标签使用可以达到跳过外层循环的效果,例子如下
func main() {for i := 0; i < 10; i++ {for j := 0; j < 10; j++ {if i > j {continue}fmt.Println(i, j)}}
}
输出
0 0 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 ... 7 7 7 8 7 9 8 8 8 9 9 9
使用标签
func main() {
Out:for i := 0; i < 10; i++ {for j := 0; j < 10; j++ {if i > j {continue Out}fmt.Println(i, j)}}
}
输出
0 0 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9
10.函数
在Go中,函数是一等公民,函数是Go最基础的组成部分,也是Go的核心。
声明
函数的声明格式如下
func 函数名([参数列表]) [返回值] {函数体
}
声明函数有两种办法,一种是通过func关键字直接声明,另一种就是通过var关键字来声明,如下所示
func sum(a int, b int) int {return a + b
}var sum = func(a int, b int) int {return a + b
}
函数签名由函数名称,参数列表,返回值组成,下面是一个完整的例子,函数名称为Sum,有两个int类型的参数a,b,返回值类型为int。
func Sum(a int, b int) int {return a + b
}
还有一个非常重要的点,即Go中的函数不支持重载,像下面的代码就无法通过编译
type Person struct {Name stringAge intAddress stringSalary float64
}func NewPerson(name string, age int, address string, salary float64) *Person {return &Person{Name: name, Age: age, Address: address, Salary: salary}
}func NewPerson(name string) *Person {return &Person{Name: name}
}
Go的理念便是:如果签名不一样那就是两个完全不同的函数,那么就不应该取一样的名字,函数重载会让代码变得混淆和难以理解。这种理念是否正确见仁见智,至少在Go中你可以仅通过函数名就知道它是干什么的,而不需要去找它到底是哪一个重载。
参数
Go中的参数名可以不带名称,一般这种是在接口或函数类型声明时才会用到,不过为了可读性一般还是建议尽量给参数加上名称
type ExWriter func(io.Writer) error type Writer interface {ExWrite([]byte) (int, error)
}
对于类型相同的参数而言,可以只需要声明一次类型,不过条件是它们必须相邻
func Log(format string, a1, a2 any) {...
}
变长参数可以接收0个或多个值,必须声明在参数列表的末尾,最典型的例子就是fmt.Printf函数。
func Printf(format string, a ...any) (n int, err error) {return Fprintf(os.Stdout, format, a...)
}
值得一提的是,Go中的函数参数是传值传递,即在传递参数时会拷贝实参的值。如果你觉得在传递切片或map时会复制大量的内存,我可以告诉你大可不必担心,因为这两个数据结构本质上都是指针。
返回值
下面是一个简单的函数返回值的例子,Sum函数返回一个int类型的值。
func Sum(a, b int) int {return a + b
}
当函数没有返回值时,不需要void,不带返回值即可。
func ErrPrintf(format string, a ...any) {_, _ = fmt.Fprintf(os.Stderr, format, a...)
}
Go允许函数有多个返回值,此时就需要用括号将返回值围起来。
func Div(a, b float64) (float64, error) {if a == 0 {return math.NaN(), errors.New("0不能作为被除数")}return a / b, nil
}
Go也支持具名返回值,不能与参数名重复,使用具名返回值时,return关键字可以不需要指定返回哪些值。
func Sum(a, b int) (ans int) {ans = a + breturn
}
和参数一样,当有多个同类型的具名返回值时,可以省略掉重复的类型声明
func SumAndMul(a, b int) (c, d int) {c = a + bd = a * breturn
}
不管具名返回值如何声明,永远都是以return关键字后的值为最高优先级。
func SumAndMul(a, b int) (c, d int) {c = a + bd = a * b// c,d将不会被返回return a + b, a * b
}
值传递
传递是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
默认情况下,Go 语言使用的是值传递,即在调用过程中不会影响到实际参数。
以下定义了 swap() 函数:
/* 定义相互交换值的函数 */
func swap(x, y int) int {var temp inttemp = x /* 保存 x 的值 */x = y /* 将 y 值赋给 x */y = temp /* 将 temp 值赋给 y*/return temp;
}
接下来,让我们使用值传递来调用 swap() 函数:
实例
package mainimport "fmt"func main() {/* 定义局部变量 */var a int = 100var b int = 200fmt.Printf("交换前 a 的值为 : %d\n", a )fmt.Printf("交换前 b 的值为 : %d\n", b )/* 通过调用函数来交换值 */swap(a, b)fmt.Printf("交换后 a 的值 : %d\n", a )fmt.Printf("交换后 b 的值 : %d\n", b )
}/* 定义相互交换值的函数 */
func swap(x, y int) int {var temp inttemp = x /* 保存 x 的值 */x = y /* 将 y 值赋给 x */y = temp /* 将 temp 值赋给 y*/return temp;
}
以下代码执行结果为:
交换前 a 的值为 : 100 交换前 b 的值为 : 200 交换后 a 的值 : 100 交换后 b 的值 : 200
程序中使用的是值传递, 所以两个值并没有实现交互,我们可以使用 引用传递来实现交换效果。
引用传递值
引用传递是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。
引用传递指针参数传递到函数内,以下是交换函数 swap() 使用了引用传递:
/* 定义交换值函数*/
func swap(x *int, y *int) {var temp inttemp = *x /* 保持 x 地址上的值 */*x = *y /* 将 y 值赋给 x */*y = temp /* 将 temp 值赋给 y */
}
以下我们通过使用引用传递来调用 swap() 函数
package mainimport "fmt"func main() {/* 定义局部变量 */var a int = 100var b int= 200fmt.Printf("交换前,a 的值 : %d\n", a )fmt.Printf("交换前,b 的值 : %d\n", b )/* 调用 swap() 函数* &a 指向 a 指针,a 变量的地址* &b 指向 b 指针,b 变量的地址*/swap(&a, &b)fmt.Printf("交换后,a 的值 : %d\n", a )fmt.Printf("交换后,b 的值 : %d\n", b )
}func swap(x *int, y *int) {var temp inttemp = *x /* 保存 x 地址上的值 */*x = *y /* 将 y 值赋给 x */*y = temp /* 将 temp 值赋给 y */
}
以上代码执行结果为:
交换前,a 的值 : 100 交换前,b 的值 : 200 交换后,a 的值 : 200 交换后,b 的值 : 100
作为实参
Go 语言可以很灵活的创建函数,并作为另外一个函数的实参。以下实例中我们在定义的函数中初始化一个变量,该函数仅仅是为了使用内置函数 math.sqrt(),实例为:
实例
package mainimport ("fmt""math"
)func main(){/* 声明函数变量 */getSquareRoot := func(x float64) float64 {return math.Sqrt(x)}/* 使用函数 */fmt.Println(getSquareRoot(9))}
以上代码执行结果为:
3
匿名函数
匿名函数就是没有签名的函数,例如下面的函数func(a, b int) int,它没有名称,所以我们只能在它的函数体后紧跟括号来进行调用。
func main() {func(a, b int) int {return a + b}(1, 2)
}
在调用一个函数时,当它的参数是一个函数类型时,这时名称不再重要,就可以直接传递一个匿名函数,如下所示
type Person struct {Name stringAge intSalary float64
}func main() {people := []Person{{Name: "Alice", Age: 25, Salary: 5000.0},{Name: "Bob", Age: 30, Salary: 6000.0},{Name: "Charlie", Age: 28, Salary: 5500.0},}slices.SortFunc(people, func(p1 Person, p2 Person) int {if p1.Name > p2.Name {return 1} else if p1.Name < p2.Name {return -1}return 0})
}
这是一个自定义排序规则的例子,slices.SortFunc接受两个参数,一个是切片,另一个就是比较函数,不考虑复用的话,我们就可以直接传递匿名函数。
闭包
闭包(Closure)这一概念,在一些语言中又被称为Lamda表达式,与匿名函数一起使用,闭包 = 函数 + 环境引用吗,看下面一个例子:
func main() {grow := Exp(2)for i := range 10 {fmt.Printf("2^%d=%d\n", i, grow())}
}func Exp(n int) func() int {e := 1return func() int {temp := ee *= nreturn temp}
}
输出
2^0=1 2^1=2 2^2=4 2^3=8 2^4=16 2^5=32 2^6=64 2^7=128 2^8=256 2^9=512
Exp函数的返回值是一个函数,这里将称成为grow函数,每将它调用一次,变量e就会以指数级增长一次。grow函数引用了Exp函数的两个变量:e和n,它们诞生在Exp函数的作用域内,在正常情况下随着Exp函数的调用结束,这些变量的内存会随着出栈而被回收。但是由于grow函数引用了它们,所以它们无法被回收,而是逃逸到了堆上,即使Exp函数的生命周期已经结束了,但变量e和n的生命周期并没有结束,在grow函数内还能直接修改这两个变量,grow函数就是一个闭包函数。
利用闭包,可以非常简单的实现一个求费波那契数列的函数,代码如下
func main() {// 10个斐波那契数fib := Fib(10)for n, next := fib(); next; n, next = fib() {fmt.Println(n)}
}func Fib(n int) func() (int, bool) {a, b, c := 1, 1, 2i := 0return func() (int, bool) {if i >= n {return 0, false} else if i < 2 {f := ii++return f, true}a, b = b, cc = a + bi++return a, true}
}
输出为
0 1 1 2 3 5 8 13 21 34
延迟调用
defer关键字可以使得一个函数延迟一段时间调用,在函数返回之前这些defer描述的函数最后都会被逐个执行,看下面一个例子
func main() {Do()
}func Do() {defer func() {fmt.Println("1")}()fmt.Println("2")
}
输出
2 1
因为defer是在函数返回前执行的,你也可以在defer中修改函数的返回值
func main() {fmt.Println(sum(3, 5))
}func sum(a, b int) (s int) {defer func() {s -= 10}()s = a + breturn
}
当有多个defer描述的函数时,就会像栈一样先进后出的顺序执行。
func main() {fmt.Println(0)Do()
}func Do() {defer fmt.Println(1)fmt.Println(2)defer fmt.Println(3)defer fmt.Println(4)fmt.Println(5)
}
0
2
5
4
3
1
延迟调用通常用于释放文件资源,关闭网络连接等操作,还有一个用法是捕获panic,不过这是错误处理一节中才会涉及到的东西。
循环
虽然没有明令禁止,一般建议不要在for循环中使用defer,如下所示
func main() {n := 5for i := range n {defer fmt.Println(i)}
}
输出如下
4 3 2 1 0
这段代码结果是正确的,但过程也许不对。在Go中,每创建一个defer,就需要在当前协程申请一片内存空间。假设在上面例子中不是简单的for n循环,而是一个较为复杂的数据处理流程,当外部请求数突然激增时,那么在短时间内就会创建大量的defer,在循环次数很大或次数不确定时,就可能会导致内存占用突然暴涨,这种我们一般称之为内存泄漏。
参数预计算
对于延迟调用有一些反直觉的细节,比如下面这个例子
func main() {defer fmt.Println(Fn1())fmt.Println("3")
}func Fn1() int {fmt.Println("2")return 1
}
这个坑还是非常隐晦的,我以前就因为这个坑,半天排查不出来是什么原因,可以猜猜输出是什么,答案如下
2 3 1
可能很多人认为是下面这种输出
3 2 1
按照使用者的初衷来说,fmt.Println(Fn1())这部分应该是希望它们在函数体执行结束后再执行,fmt.Println确实是最后执行的,但Fn1()是在意料之外的,下面这个例子的情况就更加明显了。
func main() {var a, b inta = 1b = 2defer fmt.Println(sum(a, b))a = 3b = 4
}func sum(a, b int) int {return a + b
}
它的输出一定是3而不是7,如果使用闭包而不是延迟调用,结果又不一样了
func main() {var a, b inta = 1b = 2f := func() {fmt.Println(sum(a, b))}a = 3b = 4f()
}
闭包的输出是7,那如果把延迟调用和闭包结合起来呢
func main() {var a, b inta = 1b = 2defer func() {fmt.Println(sum(a, b))}()a = 3b = 4
}
这次就正常了,输出的是7。下面再改一下,没有闭包了
func main() {var a, b inta = 1b = 2defer func(num int) {fmt.Println(num)}(sum(a, b))a = 3b = 4
}
输出又变回3了。通过对比上面几个例子可以发现这段代码
defer fmt.Println(sum(a,b))
其实等价于
defer fmt.Println(3)
go不会等到最后才去调用sum函数,sum函数早在延迟调用被执行以前就被调用了,并作为参数传递了fmt.Println。总结就是,对于defer直接作用的函数而言,它的参数是会被预计算的,这也就导致了第一个例子中的奇怪现象,对于这种情况,尤其是在延迟调用中将函数返回值作为参数的情况尤其需要注意。
方法
方法与函数的区别在于,方法拥有接收者,而函数没有,且只有自定义类型能够拥有方法。先来看一个例子。
type IntSlice []intfunc (i IntSlice) Get(index int) int {return i[index]
}
func (i IntSlice) Set(index, val int) {i[index] = val
}func (i IntSlice) Len() int {return len(i)
}
先声明了一个类型IntSlice,其底层类型为[]int,再声明了三个方法Get,Set和Len,方法的长相与函数并无太大的区别,只是多了一小段(i IntSlice) 。i就是接收者,IntSlice就是接收者的类型,接收者就类似于其他语言中的this或self,只不过在Go中需要显示的指明。
func main() {var intSlice IntSliceintSlice = []int{1, 2, 3, 4, 5}fmt.Println(intSlice.Get(0))intSlice.Set(0, 2)fmt.Println(intSlice)fmt.Println(intSlice.Len())
}
方法的使用就类似于调用一个类的成员方法,先声明,再初始化,再调用。
值接收者
接收者也分两种类型,值接收者和指针接收者,先看一个例子
type MyInt intfunc (i MyInt) Set(val int) {i = MyInt(val) // 修改了,但是不会造成任何影响
}func main() {myInt := MyInt(1)myInt.Set(2)fmt.Println(myInt)
}
上述代码运行过后,会发现myInt的值依旧是1,并没有被修改成2。方法在被调用时,会将接收者的值传入方法中,上例的接收者就是一个值接收者,可以简单的看成一个形参,而修改一个形参的值,并不会对方法外的值造成任何影响,那么如果通过指针调用会如何呢?
func main() {myInt := MyInt(1)(&myInt).Set(2)fmt.Println(myInt)
}
遗憾的是,这样的代码依旧不能修改内部的值,为了能够匹配上接收者的类型,Go会将其解引用,解释为(*(&myInt)).Set(2)。
指针接收者
稍微修改了一下,就能正常修改myInt的值。
type MyInt intfunc (i *MyInt) Set(val int) {*i = MyInt(val)
}func main() {myInt := MyInt(1)myInt.Set(2)fmt.Println(myInt)
}
现在的接收者就是一个指针接收者,虽然myInt是一个值类型,在通过值类型调用指针接收者的方法时,Go会将其解释为(&myint).Set(2)。所以方法的接收者为指针时,不管调用者是不是指针,都可以修改内部的值。
函数的参数传递过程中,是值拷贝的,如果传递的是一个整型,那就拷贝这个整型,如果是一个切片,那就拷贝这个切片,但如果是一个指针,就只需要拷贝这个指针,显然传递一个指针比起传递一个切片所消耗的资源更小,接收者也不例外,值接收者和指针接收者也是同样的道理。在大多数情况下,都推荐使用指针接收者,不过两者并不应该混合使用,要么都用,要么就都不用,看下面一个例子。
提示:需要先了解接口
type Animal interface {Run()
}type Dog struct {
}func (d *Dog) Run() {fmt.Println("Run")
}func main() {var an Animalan = Dog{}// an = &Dog{} 正确方式an.Run()
}
这一段代码将会无法通过编译,编译器将会输出如下错误
cannot use Dog{} (value of type Dog) as type Animal in assignment:Dog does not implement Animal (Run method has pointer receiver)
翻译过来就是,无法使用Dog{}初始化Animal类型的变量,因为Dog没有实现Animal,解决办法有两种,一是将指针接收者改为值接收者,二是将Dog{}改为&Dog{},接下来逐个讲解。
type Dog struct {
}func (d Dog) Run() { // 改为了值接收者fmt.Println("Run")
}func main() { // 可以正常运行var an Animalan = Dog{}// an = &Dog{} 同样可以an.Run()
}
在原来的代码中,Run 方法的接收者是*Dog ,自然而然实现Animal接口的就是Dog指针,而不是Dog结构体,这是两个不同的类型,所以编译器就会认为Dog{}并不是Animal的实现,因此无法赋值给变量an,所以第二种解决办法就是赋值Dog指针给变量an。不过在使用值接收者时,Dog指针依然可以正常赋值给animal,这是因为Go会在适当情况下对指针进行解引用,因为通过指针可以找到Dog结构体,但是反过来的话,无法通过Dog结构体找到Dog指针。如果单纯的在结构体中混用值接收者和指针接收者的话无伤大雅,但是和接口一起使用后,就会出现错误,倒不如无论何时要么都用值接收者,要么就都用指针接收者,形成一个良好的规范,也可以减少后续维护的负担。
还有一种情况,就是当值接收者是可寻址的时候,Go会自动的插入指针运算符来进行调用,例如切片是可寻址,依旧可以通过值接收者来修改其内部值。比如下面这个代码
type Slice []intfunc (s Slice) Set(i int, v int) {s[i] = v
}func main() {s := make(Slice, 1)s.Set(0, 1)fmt.Println(s)
}
输出
[1]
但这样会引发另一个问题,如果对其添加元素的话,情况就不同了。看下面的例子
type Slice []intfunc (s Slice) Set(i int, v int) {s[i] = v
}func (s Slice) Append(a int) {s = append(s, a)
}func main() {s := make(Slice, 1, 2)s.Set(0, 1)s.Append(2)fmt.Println(s)
}
[1]
它的输出还是和之前一样,append函数是有返回值的,向切片添加完元素后必须覆盖原切片,尤其是在扩容后,在方法中对值接收者修改并不会产生任何影响,这也就导致了例子中的结果,改成指针接收者就正常了。
type Slice []intfunc (s *Slice) Set(i int, v int) {(*s)[i] = v
}func (s *Slice) Append(a int) {*s = append(*s, a)
}func main() {s := make(Slice, 1, 2)s.Set(0, 1)s.Append(2)fmt.Println(s)
}
输出
[1 2]
递归函数
递归,就是在运行的过程中调用自己。
语法格式如下:
func recursion() { recursion() /* 函数调用自身 */ }
func main() { recursion() }
Go 语言支持递归。但我们在使用递归时,开发者需要设置退出条件,否则递归将陷入无限循环中。
递归函数对于解决数学上的问题是非常有用的,就像计算阶乘,生成斐波那契数列等。
阶乘
以下实例通过 Go 语言的递归函数实例阶乘:
实例
package mainimport "fmt"func Factorial(n uint64)(result uint64) {if (n > 0) {result = n * Factorial(n-1)return result}return 1
}func main() { var i int = 15fmt.Printf("%d 的阶乘是 %d\n", i, Factorial(uint64(i)))
}
以上实例执行输出结果为:
15 的阶乘是 1307674368000
斐波那契数列
以下实例通过 Go 语言的递归函数实现斐波那契数列:
实例
package mainimport "fmt"func fibonacci(n int) int {if n < 2 {return n}return fibonacci(n-2) + fibonacci(n-1)
}func main() {var i intfor i = 0; i < 10; i++ {fmt.Printf("%d\t", fibonacci(i))}
}
以上实例执行输出结果为:
0 1 1 2 3 5 8 13 21 34
求平方根
以下实例通过 Go 语言使用递归方法实现求平方根的代码:
实例
package mainimport ("fmt"
)func sqrtRecursive(x, guess, prevGuess, epsilon float64) float64 {if diff := guess*guess - x; diff < epsilon && -diff < epsilon {return guess}newGuess := (guess + x/guess) / 2if newGuess == prevGuess {return guess}return sqrtRecursive(x, newGuess, guess, epsilon)
}func sqrt(x float64) float64 {return sqrtRecursive(x, 1.0, 0.0, 1e-9)
}func main() {x := 25.0result := sqrt(x)fmt.Printf("%.2f 的平方根为 %.6f\n", x, result)
}
以上实例中,sqrtRecursive 函数使用递归方式实现平方根的计算。
sqrtRecursive 函数接受四个参数:
-
x 表示待求平方根的数
-
guess 表示当前猜测的平方根值
-
prevGuess 表示上一次的猜测值
-
epsilon 表示精度要求(即接近平方根的程度)
递归的终止条件是当前猜测的平方根与上一次猜测的平方根非常接近,差值小于给定的精度 epsilon。
在 sqrt 函数中,我们调用 sqrtRecursive 来计算平方根,并传入初始值和精度要求,然后在 main 函数中,我们调用 sqrt 函数来求解平方根,并将结果打印出来。
执行以上代码输出结果为:
25.00 的平方根为 5.000000
11.变量作用域
作用域为已声明标识符所表示的常量、类型、变量、函数或包在源代码中的作用范围。
Go 语言中变量可以在三个地方声明:
-
函数内定义的变量称为局部变量
-
函数外定义的变量称为全局变量
-
函数定义中的变量称为形式参数
接下来让我们具体了解局部变量、全局变量和形式参数。
局部变量
在函数体内声明的变量称之为局部变量,它们的作用域只在函数体内,参数和返回值变量也是局部变量。
以下实例中 main() 函数使用了局部变量 a, b, c:
实例
package mainimport "fmt"func main() {/* 声明局部变量 */var a, b, c int/* 初始化参数 */a = 10b = 20c = a + bfmt.Printf ("结果: a = %d, b = %d and c = %d\n", a, b, c)
}
以上实例执行输出结果为:
结果: a = 10, b = 20 and c = 30
全局变量
在函数体外声明的变量称之为全局变量,全局变量可以在整个包甚至外部包(被导出后)使用。
全局变量可以在任何函数中使用,以下实例演示了如何使用全局变量:
实例
package mainimport "fmt"/* 声明全局变量 */
var g intfunc main() {/* 声明局部变量 */var a, b int/* 初始化参数 */a = 10b = 20g = a + bfmt.Printf("结果: a = %d, b = %d and g = %d\n", a, b, g)
}
以上实例执行输出结果为:
结果: a = 10, b = 20 and g = 30
Go 语言程序中全局变量与局部变量名称可以相同,但是函数内的局部变量会被优先考虑。实例如下:
实例
package mainimport "fmt"/* 声明全局变量 */
var g int = 20func main() {/* 声明局部变量 */var g int = 10fmt.Printf ("结果: g = %d\n", g)
}
以上实例执行输出结果为:
结果: g = 10
形式参数
形式参数会作为函数的局部变量来使用。实例如下:
实例
package mainimport "fmt"/* 声明全局变量 */
var a int = 20;func main() {/* main 函数中声明局部变量 */var a int = 10var b int = 20var c int = 0fmt.Printf("main()函数中 a = %d\n", a);c = sum( a, b);fmt.Printf("main()函数中 c = %d\n", c);
}/* 函数定义-两数相加 */
func sum(a, b int) int {fmt.Printf("sum() 函数中 a = %d\n", a);fmt.Printf("sum() 函数中 b = %d\n", b);return a + b;
}
以上实例执行输出结果为:
main()函数中 a = 10 sum() 函数中 a = 10 sum() 函数中 b = 20 main()函数中 c = 30
初始化局部和全局变量
不同类型的局部和全局变量默认值为:
| 数据类型 | 初始化默认值 |
|---|---|
| int | 0 |
| float32 | 0 |
| pointer | nil |