【实战】基于 Hugging Face 的 LLM 高效微调全解析
引言
在人工智能领域,大型语言模型(LLM)的发展日新月异,而微调作为提升 LLM 在特定任务上性能的关键技术,备受关注。Hugging Face 作为一个强大的 NLP 工具库,为 LLM 的高效微调提供了丰富的资源和便捷的接口。本文将深入解析基于 Hugging Face 的 LLM 高效微调方法,帮助开发者更好地利用这一工具提升模型性能。
一、Hugging Face 简介
Hugging Face 提供了一系列用于自然语言处理的库和工具,包括 Transformers、Datasets、Tokenizers 等。其中,Transformers 库包含了大量预训练的语言模型,如 BERT、GPT、T5 等,这些模型可以方便地用于各种 NLP 任务。Datasets 库提供了许多常用的数据集,方便开发者快速获取和处理数据。Tokenizers 库则用于文本的分词处理,支持多种分词方法。
二、LLM 微调准备工作
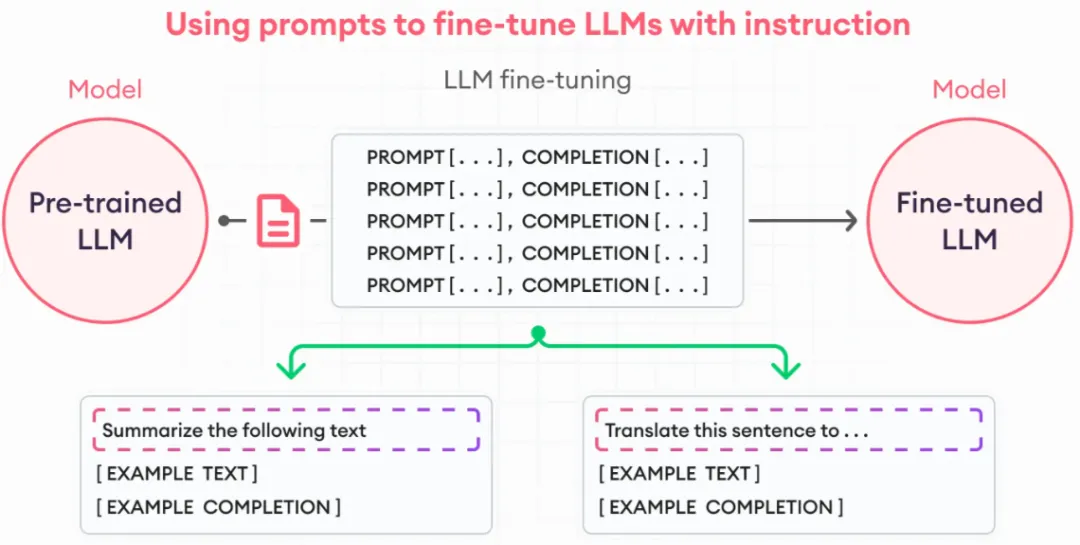
(一)数据集准备
首先需要准备用于微调的数据集。数据集的质量和多样性直接影响微调后的模型性能。可以使用 Hugging Face 的 Datasets 库加载公开数据集,也可以自己构建数据集。例如,对于文本分类任务,可以准备包含文本和对应类别的数据集。在处理数据集时,需要注意数据的清洗和预处理,如去除噪声、统一文本格式等。
(二)环境搭建
确保已经安装了 Hugging Face 的相关库。可以通过以下命令安装:
| pip install transformers datasets tokenizers |
同时,根据需要安装其他依赖库,如 PyTorch 或 TensorFlow。
(三)模型选择
根据任务需求选择合适的预训练模型。Hugging Face 的 Transformers 库提供了丰富的模型选择,如用于文本分类的 BERT 模型、用于生成任务的 GPT 模型等。可以根据模型的规模、性能和计算资源选择合适的模型。
三、LLM 高效微调技术
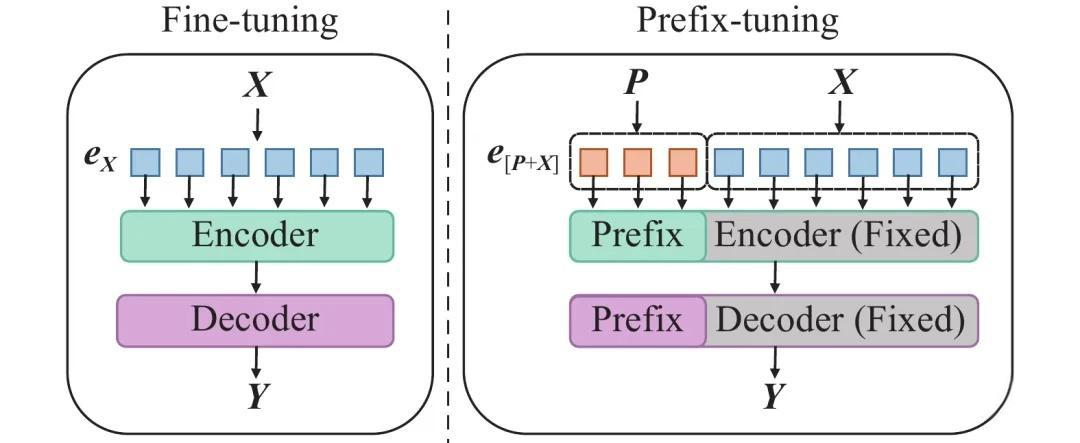
(一)全量微调(Full Fine-Tuning)
全量微调是指对预训练模型的所有参数进行微调。这种方法可以充分利用预训练模型的知识,但需要较大的计算资源和时间。在 Hugging Face 中,可以使用 Trainer 类进行全量微调。以下是一个简单的示例:
| from transformers import Trainer, TrainingArguments from datasets import load_dataset # 加载数据集 dataset = load_dataset('glue', 'sst2') # 数据预处理 tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased') def preprocess_function(examples): return tokenizer(examples['sentence'], truncation=True, max_length=128) tokenized_datasets = dataset.map(preprocess_function, batched=True) # 加载模型 model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2) # 定义训练参数 training_args = TrainingArguments( output_dir='./results', num_train_epochs=3, per_device_train_batch_size=16, per_device_eval_batch_size=16, logging_dir='./logs', ) # 初始化Trainer trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_datasets['train'], eval_dataset=tokenized_datasets['validation'], ) # 开始训练 trainer.train() |
(二)参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
当预训练模型规模较大时,全量微调需要大量的计算资源和时间,此时可以采用参数高效微调技术,只对部分参数进行微调,从而降低计算成本。Hugging Face 的 PEFT 库提供了多种参数高效微调方法,如 LoRA(Low-Rank Adaptation)、Adapter Tuning 等。
1. LoRA
LoRA 通过在预训练模型的权重矩阵上添加低秩矩阵来进行微调,只训练这些低秩矩阵的参数,而保持原预训练模型的参数不变。这种方法可以显著减少可训练参数的数量,同时保持较好的性能。以下是使用 LoRA 进行微调的示例:
| from peft import get_peft_model, LoraConfig # 定义LoRA配置 peft_config = LoraConfig( r=8, lora_alpha=32, target_modules=['q_proj', 'v_proj'], # 根据模型结构选择需要应用LoRA的模块 lora_dropout=0.1, bias='none', task_type='SEQ_CLASSIFICATION', ) # 获取PEFT模型 peft_model = get_peft_model(model, peft_config) |
2. Adapter Tuning
Adapter Tuning 在预训练模型中插入适配器(Adapter)模块,只对适配器的参数进行微调。适配器通常是一个小型的神经网络,如全连接层。以下是使用 Adapter Tuning 的示例:
| from transformers import AdapterConfig # 定义适配器配置 adapter_config = AdapterConfig( type='houlsby', reduction_factor=16, ) # 添加适配器 model.add_adapter('my_adapter', config=adapter_config) model.train_adapter('my_adapter') |
四、微调过程中的注意事项
(一)学习率调整
学习率是微调过程中的重要参数,过高的学习率可能导致模型不收敛,过低的学习率可能导致训练速度过慢。可以使用学习率调度器(Learning Rate Scheduler)来动态调整学习率,如线性衰减、余弦衰减等。
(二)批量大小设置
批量大小的设置需要考虑计算资源的限制。较大的批量大小可以提高训练速度,但可能导致内存不足。需要根据显卡的显存大小合理设置批量大小。
(三)模型评估
在微调过程中,需要定期对模型进行评估,以监控模型的性能变化。可以使用开发集进行评估,根据评估指标(如准确率、F1 值等)调整训练参数。
五、模型保存与部署
(一)模型保存
微调完成后,可以使用 Hugging Face 的 save_pretrained 方法保存模型和分词器:
| model.save_pretrained('fine-tuned-model') tokenizer.save_pretrained('fine-tuned-model') |
(二)模型部署
可以将保存的模型部署到各种平台上,如服务器、云平台等。Hugging Face 提供了 Inference API 等工具,方便模型的部署和使用。
六、总结
基于 Hugging Face 进行 LLM 的高效微调,能够充分利用预训练模型的知识,提升模型在特定任务上的性能。通过合理选择微调技术、设置训练参数和进行模型评估,可以在有限的计算资源下取得较好的微调效果。希望本文对开发者在 LLM 微调方面的实践有所帮助,推动 NLP 技术的进一步应用和发展。