x86系列CPU寄存器和汇编指令总结
文章目录
- 概要
- 一、寄存器
- 1.1、8086寄存器
- 1.2、通用寄存器
- 1.3、扩展寄存器
- 二、指令集
- 三、x86指令集常见指令使用说明
- 四、汇编
- 4.1、汇编语法
- 4.2、nsam汇编
- 五、参考
概要
在对学习Go的过程中,涉及到了汇编,因此对X86系列CPU的背景、寄存器、汇编指令做了一番了解,仅以本文作为总结,便于后续查看。
x86架构始于Intel在1978年推出的8086 CPU(典中典),它是从Intel 8008处理器中发展而来的,而8008则是发展自Intel 4004的。8086在三年后为IBM PC所选用,之后x86便成为了电脑的标配(当然,现在有些电脑采用ARM架构的CPU,比如mac m1),成为了非常成功的CPU架构。
除了Intel公司,其他公司也有制造x86架构的CPU,比如IBM、IDT以及Transmeta,但Intel以外最成功的制造商要数AMD了,其早先产品Athlon系列处理器的市场份额仅次于Intel的Pentium。
值得注意的是8086是16位处理器,直到1985年32位的80386(IA-32)才被开发,接着推出了一系列针对32位架构细微改进的CPU型号,直到2003年AMD对于这个架构进行了64位的扩展,并命名为AMD64,后来英特尔也推出了与之兼容的处理器,并命名为Intel 64。两者一般被统称为x86-64或x64,开创了x86的64位时代。
一、寄存器
正如概要中所说,x86系列发展从16、32到64位,寄存器也随之发展。
1.1、8086寄存器
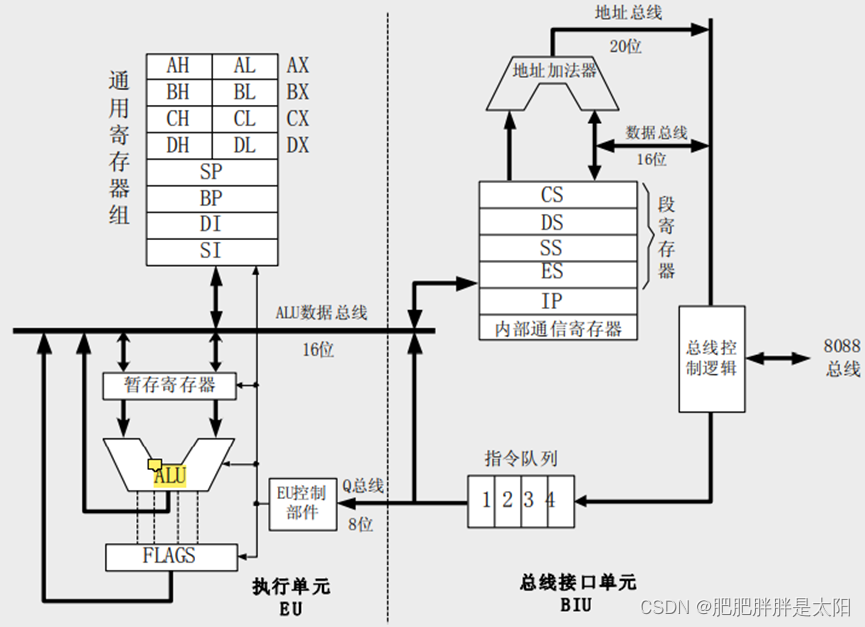
8086中寄存器总共为 14 个,且均为 16 位。
- 通用寄存器
| 寄存器 | 含义 |
|---|---|
| AX、BX、CX、DX 也称为数据寄存器 | AX (Accumulator):累加寄存器,也称之为累加器; BX (Base):基地址寄存器; CX (Count):计数器寄存器; DX (Data):数据寄存器; |
| SP、BP 也称为指针寄存器 | SP (Stack Pointer):堆栈指针寄存器,存放栈顶偏移地址,与SS配合使用,即栈顶地址=SS给出的栈段首地址+SP中偏移地址; BP (Base Pointer):基指针寄存器,一般存放函数栈帧起始指针; |
| SI、DI 也称为变址寄存器 | SI (Source Index):源变址寄存器; DI (Destination Index):目的变址寄存器; |
ps:AX可以通过AH操作其高8位,AL操作其低8位(这样可以当做两个8位寄存器使用了),BX、CX、DX同理。
- 控制寄存器
| 寄存器 | 含义 |
|---|---|
| IP | IP (Instruction Pointer):指令指针寄存器;存放下一条指令的偏移地址,搭配CS使用,即下一条指令的地址=CS给出代码段基址<<4+IP中偏移地址 |
| FLAG | 标志寄存器 |
ps:偏移地址也称偏移量,就是计算机里的内存分段后,在段内某一地址相对于段首地址(段地址)的偏移量。
- 段寄存器
| 寄存器 | 含义 |
|---|---|
| CS | CS (Code Segment):代码段寄存器; |
| DS | DS (Data Segment):数据段寄存器; |
| SS | SS (Stack Segment):堆栈段寄存器; |
| ES | ES (Extra Segment):附加段寄存器; |
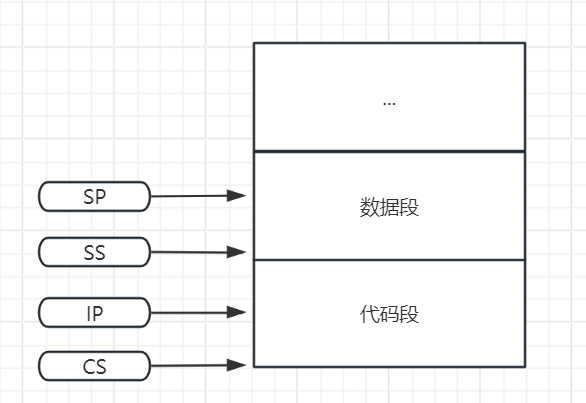
DS 寄存器和 ES 寄存器都属于段寄存器,其实它们和 CS 寄存器以及 SS 寄存器用起来区别不大,既然是段寄存器的话,自然它们存放的就是某个段地址了 。我们已经知道,如果 CPU 要访问一个内存单元时,我们必须要提供一个指向这个内存单元的物理地址给 CPU ,而我们也知道在 8086 CPU 中,物理地址是由段地址左移 4 位,然后加上偏移地址形成的,所以,我们也就只需要提供段地址和偏移地址即 OK 。8086 CPU 呢,提供了一个 DS 寄存器,并且通常都是通过这个 DS 段寄存器来存放要访问的数据的段地址 。DS(Data Segment):很显然,DS 中存放的是数据段的段地址 。但是这里不得不再点一下,那就是我们对段的支持是在 CPU 上体现的,而不是在内存中实现了段,所以事实上我们使用的段其实是一个逻辑概念,即是我们自己定义的,再说白了,我定义一个段,我说它是数据段那它就是数据段,我说它是代码段那么它就是代码段,它们其实都是一块连续的内存而已,我们只要能定位不同段即可,至于为什么要区分为数据段和代码段,很明显,是用来给我们编程提供方便的,即我们在自己的思想上或者说是编码习惯上规定,数据放数据段中,代码放代码段中 。而我们在使用数据段的时候,为了方便或者说是代码的编写方便起见,我们一般把数据段的段地址放在 DS 寄存器中,当然,如果你硬要觉得 DS 不顺眼,那你可以换个 ES 也是一样的,至于 ES(Extra Segment) 段寄存器的话,自然,是一个附加段寄存器,如果再说得过分点,就当它是个扩展吧,当你发现,你几个段寄存器不够用的时候,你可以考虑使用 ES 段寄存器,在使用方式上,则和其他的段寄存器没什么区别 。
1.2、通用寄存器
通用寄存器在汇编指令中是最多用到了,所以这里多说一嘴。
最初的8086有8个16位通用寄存器从%ax~%sp,等开发出32位时,这8个寄存器也被扩展成32位寄存器,标号命名以%e(Extense)开头从%eax ~ %esp,后来又了64位的,这8个寄存器也被扩展成64位寄存器,标号命名以%r(Register)开头从%rax ~ %rsp,另外还增加了8个寄存器,它们的标号命名规则为%r8 ~%r15。
x64通用寄存器:
| 64位寄存器 | 操作低32位 | 操作低16位 | 操作低8位 |
|---|---|---|---|
| rax | eax | ax | al |
| … | … | … | rax与rsp之间的寄存器同理 |
| rsp | esp | sp | spl |
| r8 | r8d | r8w | r8b |
| … | … | … | r8与r15之间的同理 |
| r15 | r15d | r15w | r15b |
另外rax、rbx、rcx 和 rdx 的高 8 位仍可通过 ah、bh、ch、dh访问。
1.3、扩展寄存器
Intel为了增强CPU对多媒体信息的处理能力,提高CPU处理3D图形、视频和音频信息的能力,在1996年推出了多媒体扩展指令集MMX(Multi-Media Extension),为了支持该指令集,增加了[MM0,MM7]8个64位的寄存器。
由于MMX指令集只局限于整数的运算,反响并不好。在1999年Intel推出SSE指令集(Streaming SIMD Extension),支持整数和浮点数运算,从此多了[XMM0,XMM15]共16个128位的寄存器。后续又接连推出了SSE2到SSE4.2作为补充的SSE家族,还有AVX、AVX-512、AMX等指令指令集家族,相应的也增加了[YMM0,YMM15]16个256位的寄存器和[ZMM0,ZMM31]32个512位的寄存器
ps:当然,x86系列寄存器肯定不止这些,本文只介绍了相对常用的,有兴趣的可到Intel官网了解传送门
二、指令集
指令集,就是CPU中用来计算和控制计算机系统的一套指令的集合,而每一种新型的CPU在设计时就规定了一系列与其他硬件电路相配合的指令系统。而指令集的先进与否,也关系到CPU的性能发挥,它也是CPU性能体现的一个重要标志。
通俗的理解,指令集就是CPU能认识的语言,指令集运行于一定的微架构之上,不同的微架构可以支持相同的指令集,比如Intel和AMD的CPU的微架构是不同的,但是同样支持X86指令集,这很容易理解,指令集只是一套指令集合,一套指令规范,具体的实现,仍然依赖于CPU的翻译和执行。
指令集一般分为RISC(精简指令集 Reduced Instruction Set Computer)和CISC(复杂指令集Complex Instruction Set Computer)。Intel X86的第一个CPU定义了第一套指令集,后来一些公司发现很多指令并不常用,所以决定设计一套简洁高效的指令集,称之为RICS指令集(ARM指令集),从而将原来的Intel X86指令集定义为CISC指令集。两者的使用场合不一样,对于复杂的系统,CISC更合适,否则,RICS更合适,且低功耗。
-
X86指令集
X86指令集是Intel为其第一块16位CPU(i8086)专门开发的,IBM1981年推出的世界第一台PC机中的CPU—i8088(i8086简化版)使用的也是X86指令,同时电脑中为提高浮点数据处理能力而增加的X87芯片系列数学协处理器则另外使用X87指令,以后就将X86指令集和X87指令集统称为X86指令集。常见的如mov、add、sub、pop、push等. -
MMX指令集
1996年Intel的MMX(AMD认为这是矩阵数学扩展Matrix Math Extensions的缩写,但大多数时候都被当成Multi-Media Extension,而Intel从来没有官方宣布过词源)技术出现。尽管这项新的科技得到广泛宣传,但它的精髓是非常简单的:MMX定义了八个64位SIMD寄存器,与Intel Pentium处理器的FPU堆栈有相重叠。不幸的是,这些指令无法非常简单地对应到由原来C编译器所产生的脚本中。MMX也只局限于整数的运算。这项技术的缺点导致MMX在它早期的存在有轻微的影响。现今,MMX通常是用在某些2D影片应用程序中。 -
SSE指令集
由于MMX指令并没有带来3D游戏性能的显著提升,所以,1999年Inter公司在Pentium III CPU产品中推出了数据流单指令序列扩展指令(SSE),兼容MMX指令。SSE为Streaming SIMD Extensions的缩写,如同其名称所表示的,是一种SSE指令包括了四个主要的部份:单精确度浮点数运算指令、整数运算指令(此为MMX之延伸,并和MMX使用同样的寄存器)、Cache控制指令、和状态控制指令。
在Pentium 4 CPU中,Inter公司开发了新指令集SSE2。SSE2指令一共144条,包括浮点SIMD指令、整形SIMD指令、SIMD浮点和整形数据之间转换、数据在MMX寄存器中转换等几大部分。其中重要的改进包括引入新的数据格式,如:128位SIMD整数运算和64位双精度浮点运算等。相对于SSE2,SSE3又新增加了13条新指令,此前它们被统称为pni(prescott new instructions)。13条指令中,一条用于视频解码,两条用于线程同步,其余用于复杂的数学运算、浮点到整数转换和SIMD浮点运算。SSE4增加了50条新的增加性能的指令,这些指令有助于编译、媒体、字符/文本处理和程序指向加速。
这里说下 SIMD(Single Instruction Multiple Data),单指令多数据,其不是指令集,而是一种思想,MMX、SSE、AVX等指令集就是这种思想的具体实现。它的精髓就是要通过一条指令,实现对寄存器上多组数据并行操作。比如arr:=[]int64{1,2,3,4},计算下标1与下标3之和,下标2与下标4之和,如果使用x86指令集,就要执行add rax,rbx两次,而SSE指令直接addpd xmm0,xmm1就搞定了。
ps:AVX、AVX-512、AMX等指令集,就不一一介绍了。传送门
三、x86指令集常见指令使用说明
x86指令大全传送门。
本章节最好结合实战文章来看1和2。
汇编语法有很多,主流如Intel 语法(源操作数在后,目标操作数在前)、AT&T 语法(源操作数在前,目标操作数在后)、本节解释指令示例用Intel 语法,x86-64环境
- mov
mov指令将源操作数(可以是寄存器的内容、内存中的内容或立即数)复制到目的操作数(寄存器中或内存上)。mov不能用于直接从内存复制到内存。
语法如下:
mov <reg>,<reg>
mov <reg>,<mem>
mov <mem>,<reg>
mov <reg>,<const>
mov <mem>,<const>
示例如下:
mov rax, rbx; 将rbx的值拷贝到rax
mov rax, 0x5; 将立即数5加载到rax寄存器
mov qword ptr [rsp+0x18], 0x1;将立即数1(qword ptr表示占8字节)加载到地址rsp+0x18到rsp+0x20之间的内存区域
mov qword ptr [rsp+0x18], rax; 将rax寄存器的内容(qword ptr表示大小为8字节)加载到地址rsp+0x18到rsp+0x20之间的内存区域
- lea - Load effective address
lea是一个载入有效地址的指令,将源操作数表示的地址载入到目的操作数(寄存器)中。
语法如下:
lea <reg>,<mem>
示例如下:
lea rbp, ptr [rsp-0x10]; 将地址rsp-0x10到rsp-0x8之间内存区域存储的8字节地址(指针)加载到rbp寄存器
- push
push指令扩栈后将操作数压入栈顶。通过第一章寄存器可知,一般栈顶由rsp寄存器确定。栈一般从高地址向低地址扩张。
语法如下:
push <reg>
push <mem>
push <const>
示例如下:
push rbp; 将rbp寄存器的内容压入栈,x86-64下等价于sub rsp 0x8; mov rsp, rbp,也就是说push指令改变栈大小,减8字节
- pop
pop指令与push指令相反,将栈顶内容弹出,并缩栈。
语法如下:
pop <reg>
pop <mem>
示例如下:
pop rbp; 将栈顶内容写入rbp寄存器,x86-64下等价于 mov rbp,rsp; add rsp 0x8 也就是说pop指令改变栈大小,增8字节
- call
call指令跳转到标签处,其主要工作是扩栈(字节数为指针大小)后将call下一条指令地址写入栈顶(下一条指令由rip寄存器会自动装载的),并跳转到标签。
语法如下:
call <label>
示例如下:
call $main.sub; 调用sub函数,等价于push rip,jmp <label>; 也就是说call指令也会改变栈大小,x86-64下减8字节
- ret
ret指令指令实现子程序的返回机制, 其主要工作是将栈顶内容写入rip寄存器,并缩栈,后续cpu继续执行rip的指令。这样就和call实现的函数的调用与返回。
ret; 等价于pop rip;也就是说ret指令也会改变栈大小,x86-64下增加8字节
- cmp
cmp指令比较源操作数与目的操作数大小,比较结果设置到FLAG寄存器中。 - jxx条件跳转,根据FLAG寄存器特定标志位来决定是否跳转
je或jz 如果相等(等于零)跳转;
jne或jnz 如果不相等(等于零)跳转;
js 如果为负值跳转;
jns 如果不为负值跳转;
jg 如果大于跳转;
jge 如果大于等于跳转;
jl 如果小于跳转;
jle 如果小于等于跳转;
…
运算指令
add rax,rbx;加法,rbx+rax,并将结果保存到rax中。
sub rax,rbx;减法,rbx-rax并将结果保存到rax中。
inc rax; 自增,rax=rax+1;
dex rax;自减,rax=rax-1
imul rax,rbx;乘法
idiv rax,rbx;除法
and、or、xor、not、neg 都是位运算,依次是与、或、异或、非、求补
四、汇编
提到汇编,不得不说汇编器和汇编语法。
4.1、汇编语法
| 汇编器 | 默认语法 | 典型应用场景 |
|---|---|---|
| NASM | Intel | Windows/Linux 跨平台 |
| GNU Assembler(GAS、AS) | AT&T | Linux 内核及 GCC 工具链 |
| MASM | Intel | Windows 平台开发 |
| YASM | Intel | 跨平台优化 |
| go tool asm | plan9 | go编译过渡阶段 |
汇编语法也各有特色,简单说下其核心差异:
| 差异\语法 | Intel | AT&T | plan9 |
|---|---|---|---|
| 操作数顺序 | 目标在前,源在后 | 源在前,目标在后 | 源在前,目标在后 |
| 寄存器前缀 | 无前缀 | 前缀 %,如%eax | 无前缀 |
| 立即数前缀 | 无前缀 | 前缀 $,如$0x5 | 前缀 $,如$0x5 |
| 指令后缀 | 无,但通过byte ptr(1字节)、word ptr(2字节)、 dword ptr(4字节)、qword ptr(8字节)修饰符表示多少字节, 如mov qword ptr [rsp+0x10], 0x2 | b(1字节)、w(2字节)、l(4字节)、q(8字节) 如movq $0x2 %rax | 同AT&T,如SUBQ $48, SP |
| 寻址方式 | []作为修饰符,如[rsp+0x8],定位栈偏移 0x8 处的内存地址 | ()作为修饰符,如8(%ebp),定位栈偏移 0x8 处的内存地址 | 同AT&T |
| 寄存器抽象 | 不支持 | 不支持 | 支持,也叫伪寄存器,如SB、SP、FP、PC,用于简化内存寻址 |
| 函数声明 | 无专用指令,通过标签和栈操作实现 | 无专用指令,通过标签和栈操作实现 | TEXT func(SB), flags, $size |
4.2、nsam汇编
汇编语言程序由三种类型的语句组成:
- 可执行指令:直接告诉处理器要执行的操作,如mov、add等;
- 汇编器指令:指导汇编器如何处理源代码及其生成的输出,如section、global _start、db、dw、resb等;
- 宏:在源代码级别进行文本替换。
- 汇编程序一般分成3个区域:
- data section: 用于声明初始化的数据或者常量,运行时不会更改;
- bss section: 用于声明全局变量;
- text section: 用于保存实际的代码。这个部分必须以声明global _start开始,它告诉内核程序从哪里开始执行。
这里着重说下section汇编指令。
section 指令用于定义或切换段;
section .my_data progbits alloc write ; 定义可读写的初始化数据段
section .my_code progbits alloc exec ; 定义可执行的代码段
section .my_rodata progbits alloc ; 定义只读数据段(不可写)
section .my_data progbits alloc writemy_var: dd 0x12345678 ; 定义可写数据section .text
global _start
_start:mov eax, [my_var] ; 正常读取mov dword [my_var], 0 ; 允许写入
我们一般给程序内存分为代码段、数据段、堆、栈等、其中代码段和数据段的内容在汇编中就由section 指令定义:
section .data 存放已初始化全局变量
section .bss 存放未初始化全局变量
section .text 存放可执行代码,特别注意。这个部分必须以声明global _start开始,它告诉内核程序从哪里开始执行。
section .rodata 存放只读数据(如字符串,常量等)
这几种段无需设置读写权限,nsam汇编器会自动追加上,比如还会在.bss后追加nobits alloc write,表示未初始化且可写,因为一般程序会这么分,约定俗成了。
一个输出hello world的汇编程序:
#hello.asm 文件
section .datahello db 'Hello, World!',0xA ; 定义字符串并以换行符结束len equ $ - hello ; 计算字符串长度section .textglobal _start ; 指定入口点_start:; 写字符串到标准输出mov eax, 4 ; 系统调用号 (sys_write)mov ebx, 1 ; 文件描述符 (stdout)mov ecx, hello ; 要写入的缓冲区地址mov edx, len ; 缓冲区长度int 0x80 ; 触发中断; 退出程序mov eax, 1 ; 系统调用号 (sys_exit)xor ebx, ebx ; 返回状态码 0int 0x80 ; 触发中断
x86-64下yum安装下nasm汇编器
nasm -f elf64 hello.asm -o hello.o
ld hello.o -o hello
./hello # Hello, World!
五、参考
1]:维基百科Intel_8086
2]:维基百科x86发展
3]:x86汇编指令
4]:Intel官网SSE
5]:x64 体系结构
6]:nasm官网