人工智能—— K-means 聚类算法
目录
摘要
16 K-means 聚类算法
16.1 本章工作任务
16.2 本章技能目标
16.3 本章简介
16.4 编程实战
16.5 本章总结
16.6 本章作业
本章已完结!!!
摘要
本章实现的工作是:首先采用Python语言读取样本数据(学生的语文、数学成绩)。然后建立 K-means 聚类算法模型并求解模型(得到质心坐标),同时得到每个样本点所属的簇。在二维平面中绘制样本点,样本点的形状由上述聚类的结果决定,最后画出质心。
本章掌握的技能是:1、掌握Python求解欧式距离的方法。2、掌握求解 K-means 模型的方法。3、使用Matplotlib 库实现聚类结果的可视化。
16 K-means 聚类算法
16.1 本章工作任务
采用 K-means 聚类算法编写程序,对100名学生的数学、语文成绩进行聚类。1、算法的输入是:100名学生的数学、语文成绩数据。2、算法模型需要求解的是:各个聚类质心(即聚类的中心)。3、算法的结果是:各个数据(每个 学生)所属簇(一类数据对象的集合)。
16.2 本章技能目标
掌握 K-means 聚类算法原理。
使用过Python实现对 K-means 聚类算法建模与求解。
依据 K-means 聚类算法模型计算样本数据所属簇。
使用Python对聚类结果进行可视化展示。
16.3 本章简介
聚类是指:将相似的对象归到同一簇中的过程。
K-means 聚类是指:一种迭代求解的聚类分析算法,算法的核心内容是找到 K 个聚类中心,使得各样本点距离其聚类中心距离最近。
K-means 算法可以解决的实际应用问题是:已知100名学生的语文和数学成绩,准备将这些聚为3类,聚类结束后,进一步根据第 k 个类别中学生的成绩分析出第 k 个类别的特征(例如,如果第k个类别的学生,数学成绩均大于90分,语文成绩均小于60分,则可以将第k个类别解释为理科生)。
本章的重点是:K-means 聚类过程的理解和使用。
16.4 编程实战
步骤1 导入外部包,引入NumPy包,random和os库,其中os库是系统与文件操作模块,可以处理文件和目录。引入matplotlib.pyplot 和 pandas库,并分别命名为 plt 和 pd。
from numpy import *
import random
import matplotlib.pyplot as plt
import os
import pandas as pd步骤2 定义计算欧式距离的函数。函数名为 calDistance,函数的功能是计算欧式距离。函数的参数是:1、第一个点的坐标 vec1 。 2、第二个点的坐标 vec2。函数的返回值是:两点之间的欧式距离。
def calDistance(vec1, vec2):vec1 = array(vec1)vec2 = array(vec2)return sqrt(sum(pow(vec1-vec2, 2)))步骤3 定义随机选取初始质心函数。函数名为 getInitCentroid。函数的功能是:随机初始化 k 个质心(这些质心与样本点可以重合,也可以不重合)。函数的参数是:1、训练样本 dataSet。2、聚类的簇数 k。函数的返回值是:k 个随机初始化的质心坐标。
def getInitCentroid(dataSet, k):m,n = shape(dataSet)centroid = zeros((k, n))for i in range(k):index = random.uniform(0, len(dataSet))centroid[i, :] = dataSet[int(index),:]return mat(centroid)步骤4 定义 K-means 模型求解函数。函数名为 kmeans。函数的功能是:根据样本数据,计算出稳定的质心和聚类结果。函数的参数是:1、数据集dataSet。2、聚类的簇数k。函数的返回值是:质心坐标和每个点所属的簇。
def kmeans(dataSet, k):m, n = shape(dataSet)clusterAssment = mat(zeros((m, 1)))centroid = getInitCentroid(dataSet, k)isEnd = Truewhile isEnd:isEnd = Falsefor i in range(len(dataSet)):minDistance = 10000minindex = -1for j in range(k):distance = calDistance(dataSet[i, :], centroid[j, :])if distance < minDistance:minDistance = distanceminindex = jif clusterAssment[i, 0] != minindex:isEnd = TrueclusterAssment[i, 0] = minindexfor n in range(k):test1 = clusterAssment[:, 0].A == ntest2 = nonzero(test1)test3 = test2[0]test4 = dataSet[test3]centroid[n, :] = mean(test4, axis=0)return centroid, clusterAssment步骤5 预先定义聚类结果绘制图函数,函数名为 showCluster。函数的功能是:画出聚类结果的图像。函数的参数是:1、数据集 dataSet。2、聚类的簇数k。3、质心坐标 centroids。4、每个点所属簇 clusterAssment。
def showCluster(dataSet, k, centroids, clusterAssment):numSamples, dim = dataSet.shapeif dim != 2:print("Sorry! I can not draw because the dimension of your data is not 2!")return 1mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']if k > len(mark):print("Sorry! Your k is too large!")return 1markers = ['x', 'o', 'v', 'd', '+', 'l', '8', 's', 'p', '*']for i in range(numSamples):markIndex = int(clusterAssment[i,0])plt.plot(dataSet[i,0], dataSet[i, 1], mark[markIndex],marker=markers[markIndex])mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']for i in range(k):plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize=6)plt.show()步骤6 设置当前工作路径。其中,os.path.abspath()用于将相对路径转化为绝对路径。os.chdir()用于改变当前工作目录。os.getcwd()用于获取当前工作目录(默认为当前文件所在文件夹,不同设备的路径可能不同)。
thisFilePath = os.path.abspath('.')
os.chdir(thisFilePath)
os.getcwd()输出结果:
'D:\\MyPythonFiles'步骤7 导入数据集。pd.read_csv用于读取储存学生成绩的CSV文件。
dataSet = pd.read_csv('python3.12.csv')
dataSet.head()输出结果:
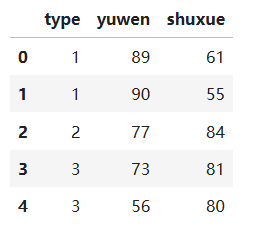
步骤8 从样本数据集中提取训练集。将dataSet中的语文和数学成绩用mat函数转化为矩阵格式并保存为dataSet_matrix,方便后续操作。其中用iloc函数提取出第二列和第三列(Python默认为前闭后开)。
type(dataSet)
dataSet_matrix = mat(dataSet.iloc[:, 1:3])
type(dataSet_matrix)
dataSet_matrix[1:5]输出结果:matrix([[90, 55],[77, 84],[73, 81],[56, 80]], dtype=int64)步骤9 求解 K-means 模型,根据模型计算所有测试样本的聚类结果。得出质心坐标及每个点所属簇。判断出每个点所属簇 clusterAssment 的类型,结果应为矩阵。
centroid, clusterAssment = kmeans(dataSet_matrix, 3)
type(clusterAssment)输出结果:numpy.matrix步骤10 显示样本数据的聚类结果和所有聚类质心。显示 clusterAssment 的前5行数据和 centroid 的数据。其中,clusterAssment是每个点所属簇,centroid是质心坐标。
clusterAssment[1:5]输出结果:matrix([[0.],[1.],[1.],[2.]])步骤11 将样本数据和聚类结果一同显示。输出带有聚类信息的DataFrame对象,将语文成绩和数学成绩和类别合成一个矩阵 dataSet_matrix_merge。之后用column_stack将这两个低维数据进行拼接组合,合成一个有语文和数学成绩以及聚类结果的矩阵。用 DataFrame函数将得到的矩阵dataSet_matrix_merge 加上列标题,创建DataFrame对象 dataSet_df_merge,并显示前5行。
dataSet_matrix_merge = column_stack((dataSet_matrix, clusterAssment+1))
dataSet_df_merge = pd.DataFrame(dataSet_matrix_merge, columns=['yuwen','shuxue','Kmeans-type'])
dataSet_df_merge.head(5)输出结果:
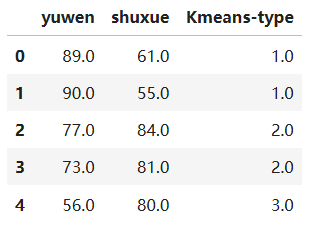
步骤12 聚类结果可视化。画出显示聚类结果的二维图。使用在步骤5中国 预定义的showCluster函数,对聚类结果进行可视化处理。图中的横轴是语文成绩,纵轴是数学成绩,不同形状(圆、倒三角,叉)代表不同的簇,第 k 个点表示第 k 个学生的成绩,菱形表示第 k 个质心。
showCluster(dataSet_matrix, 3, centroid, clusterAssment)
plt.show()输出结果:
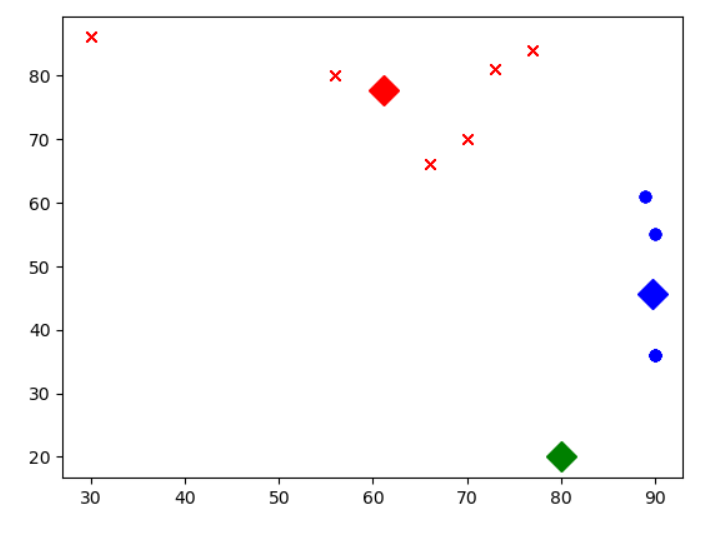
16.5 本章总结
本章实现的工作是:首先采用Python语言读取样本数据(学生的语文、数学成绩)。然后建立 K-means 聚类算法模型并求解模型(得到质心坐标),同时得到每个样本点所属的簇。在二维平面中绘制样本点,样本点的形状由上述聚类的结果决定,最后画出质心。
本章掌握的技能是:1、掌握Python求解欧式距离的方法。2、掌握求解 K-means 模型的方法。3、使用Matplotlib 库实现聚类结果的可视化。
16.6 本章作业
实现本章的案例,即读取样本数据,实现 K-means 聚类算法的建模、求解和将数据可视化。
本章已完结!!!