LLM应用于自动驾驶方向相关论文整理(大模型在自动驾驶方向的相关研究)
1、《HILM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving》
2023年9月发表的大模型做自动驾驶的论文,来自香港科技大学和人华为诺亚实验室(代码开源)。
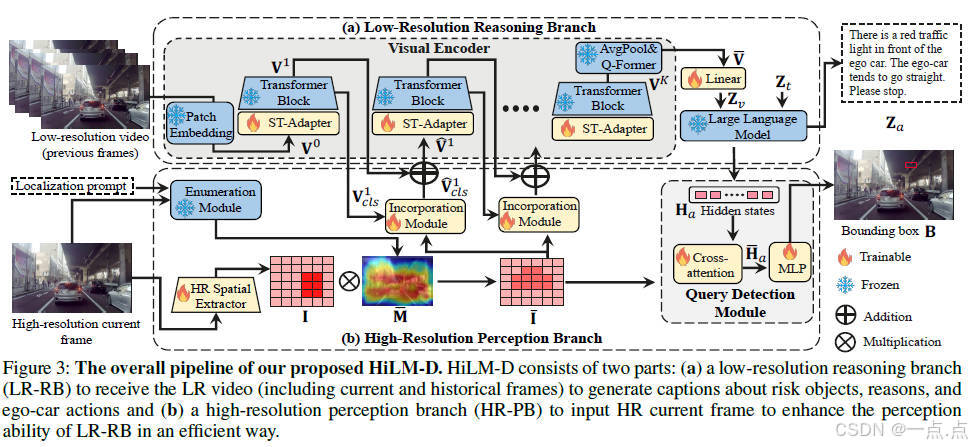
论文简介:
本文提出HiLM-D方法,通过整合低分辨率推理分支(LR-RB)和高分辨率感知分支(HR-PB),解决多模态大语言模型(MLLMs)在自动驾驶任务中因低分辨率输入导致的小物体漏检和显著物体过于关注的问题。HiLM-D利用高分辨率图像提取视觉特征并增强风险区域感知,以统一模型实现风险对象定位、意图解释和运动建议生成(ROLISP任务)。实验表明,该方法在DRAMA-ROLISP数据集上显著优于现有MLLMs,Captioning的BLEU-4提升4.8%,检测mIoU提升17.2%,且模块轻量化设计支持即插即用。
2、《MotionLM: Multi-Agent Motion Forecasting as Language Modeling》
2023年9月发表,来自Waymo团队(代码开源)。
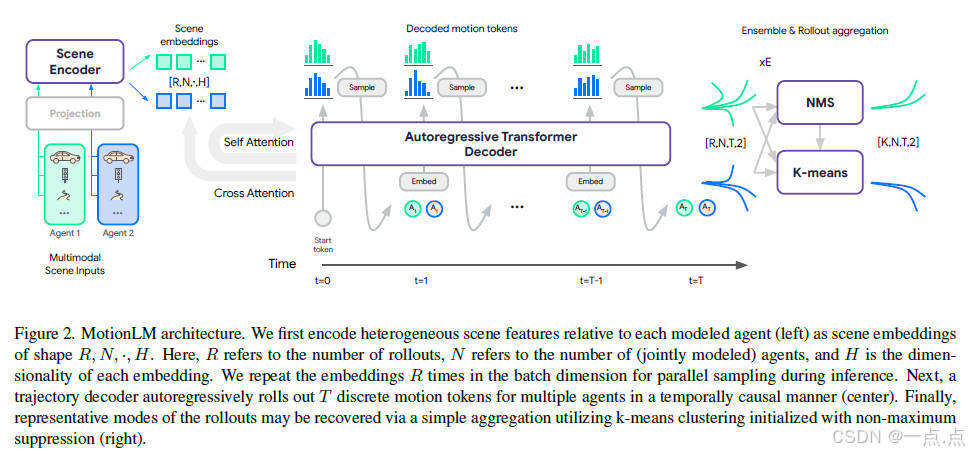
论文简介:
本文提出MotionLM,将多智能体运动预测建模为语言模型任务,通过离散化连续轨迹为运动标记,利用自回归解码生成联合分布,避免了锚点或隐变量设计。其核心创新在于以单一语言建模目标直接捕捉多智能体交互的时序因果关系,并在Waymo数据集上实现交互预测任务的SOTA性能,关键指标提升6%。实验表明,模型支持因果条件预测,且通过高频交互注意力有效减少场景冲突。
3、《BEVGPT: Generative Pretrained Large Model for Autonomous Driving Prediction, Decision-Making, and Planning》
2023年10月发表,来自香港科技大学、同济大学和华盛顿大学等(代码非开源)。
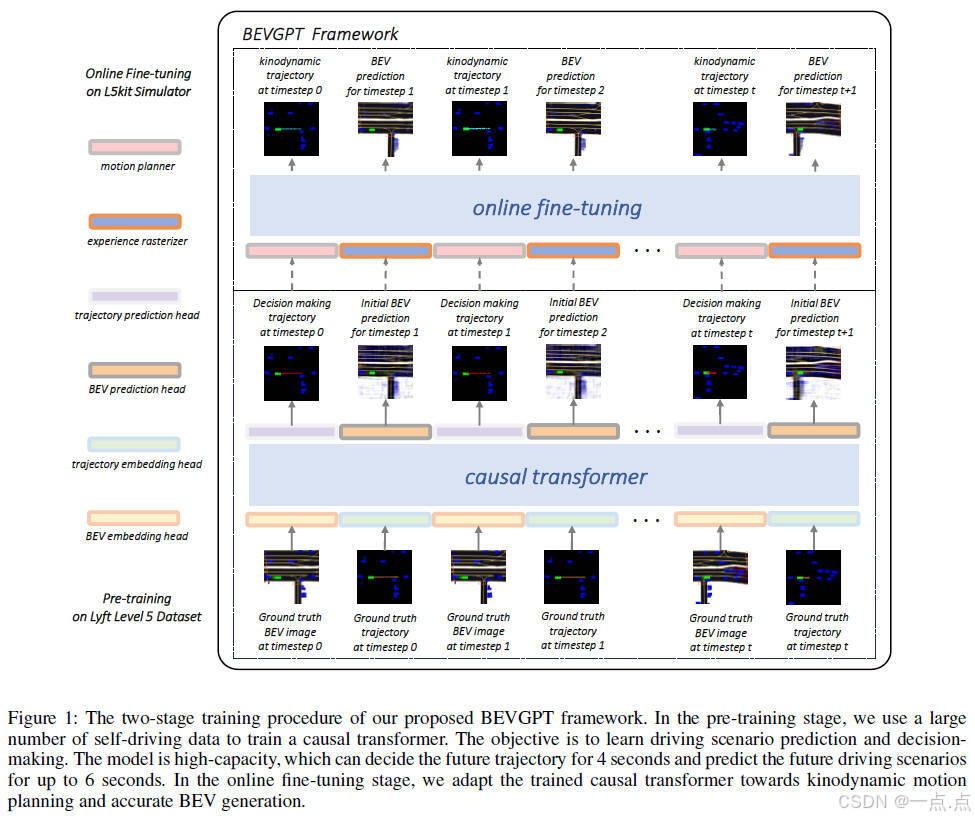
论文简介:
这篇论文提出BEVGPT,首个基于纯鸟瞰图(BEV)输入的生成式预训练大模型,将自动驾驶的预测、决策与规划整合为统一框架。其核心创新包括:1)仅以BEV图像为输入,通过两阶段训练(预训练+在线微调)实现多任务协同,避免模块化系统的误差累积;2)采用因果Transformer自回归生成未来驾驶场景,支持长达6秒的BEV预测;3)结合最小化急动度优化的运动规划算法,保障轨迹可行性。实验表明,模型在Lyft数据集上决策指标全面领先,运动规划碰撞率显著低于基线,并在复杂交通场景下展示出长期预测鲁棒性,为自动驾驶系统一体化设计提供了新范式。
4、《GPT-DRIVER: LEARNING TO DRIVE WITH GPT》
2023年10月发表,作者来自美国USC和清华大学赵行团队(代码开源)。

论文简介:
这篇论文提出GPT-Driver,首次将GPT-3.5模型转化为自动驾驶运动规划器,核心创新在于将轨迹规划重构为语言建模问题:通过将坐标数值拆解为语言标记(如“23.17”转为“23”、“.”、“17”),利用LLM自回归生成轨迹,并设计“提示-推理-微调”三阶段策略,激发模型数值推理能力与决策透明度。实验表明,模型在nuScenes数据集上L2误差显著领先SOTA方法(3秒误差1.52m vs. 1.65m),碰撞率与基线相当,且在10%训练数据下仍保持强泛化性。其链式思维推理可输出关键障碍物分析及决策逻辑,增强可解释性,但实时性与闭环验证仍是未来改进方向。
5、《Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving》
2023年10月发表,Wayve公司(代码开源)。
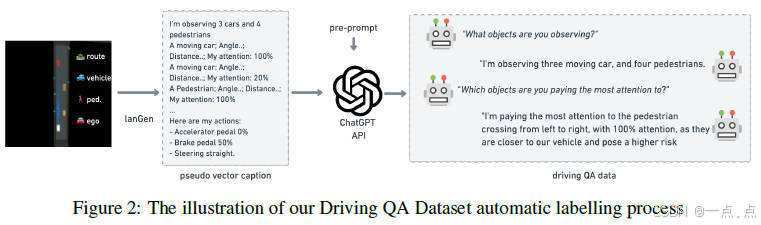
论文简介:
这篇论文提出了一种新型多模态架构,将自动驾驶中的对象级向量数据与预训练大语言模型(LLM)融合,以增强场景理解和决策可解释性。研究者构建了包含16万问答对的数据集,通过强化学习(RL)专家和GPT-3.5生成驾驶控制指令及场景问答,并设计了两阶段训练策略:预训练对齐向量与语言表示,微调优化驾驶问答与动作预测。实验表明,该模型在感知推理和动作生成任务中优于传统行为克隆方法,且能生成人类可理解的决策解释,但闭环控制精度和实时性仍需改进。论文为LLM在自动驾驶中的可解释性应用提供了首个系统性框架与开源基准。
6、《LanguageMPC: Large Language Models as Decision Makers for Autonomous Driving》
2023年10月发表,来自清华大学、香港大学和加州伯克利分校(代码非开源)。
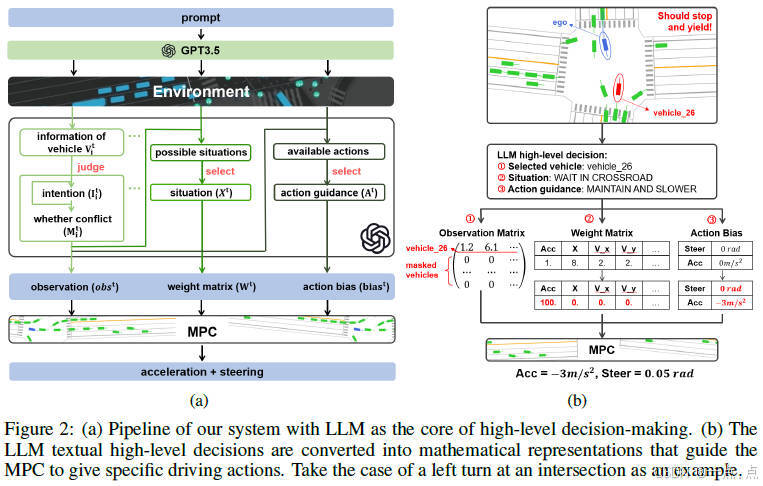
论文简介:
这篇论文提出了一种将大型语言模型(LLM)作为自动驾驶系统核心决策组件的方法(LanguageMPC),通过设计认知推理路径将LLM的文本决策转化为数学模型参数,指导底层模型预测控制器(MPC)生成具体驾驶指令。实验表明,该方法在单车辆任务中显著降低了事故率和总体成本(如无信号交叉路口场景下总体成本降低18.1%),并能处理多车辆协同控制、文本调节驾驶风格等复杂场景。其优势在于利用LLM的常识推理能力和可解释性,解决了传统自动驾驶系统在长尾事件处理、规则泛化与透明性方面的不足,为安全、高效且可解释的自动驾驶系统提供了新思路。
7、《DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving》
2023年12月发表,来自上海AI实验室、香港中文大学、商汤科技、斯坦福大学、南京大学和清华大学(代码开源)。
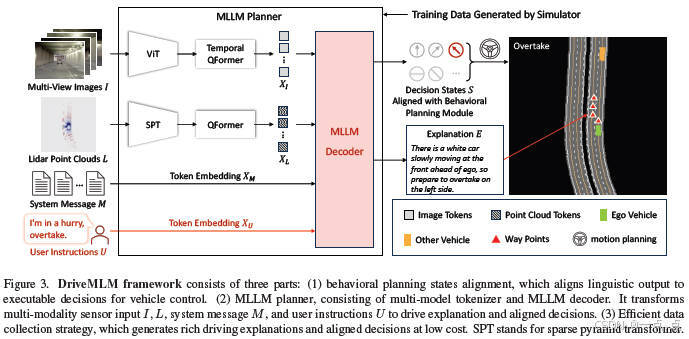
论文简介:
DriveMLM提出了一种基于多模态大语言模型(LLM)的自动驾驶框架,通过将LLM的决策输出与行为规划模块的状态对齐,解决了语言决策到车辆控制的转换难题。该框架整合多模态输入(如摄像头、LiDAR、交通规则和用户指令),利用高效数据引擎生成丰富的驾驶场景标注,并在CARLA仿真环境中实现闭环驾驶。实验表明,DriveMLM在驾驶评分(76.1)和安全性(MPI 0.96)上显著优于传统方法(如Apollo),同时支持通过自然语言指令动态调整驾驶策略,并生成可解释的决策原因,为自动驾驶系统的灵活性和透明性提供了新思路。
8.《DriveLM: Driving with Graph Visual Question Answering》
2023年12月发表,来自上海AI实验室(OpenDriveLab)、德国图宾根大学、图宾根AI中心和香港大学(代码开源)。
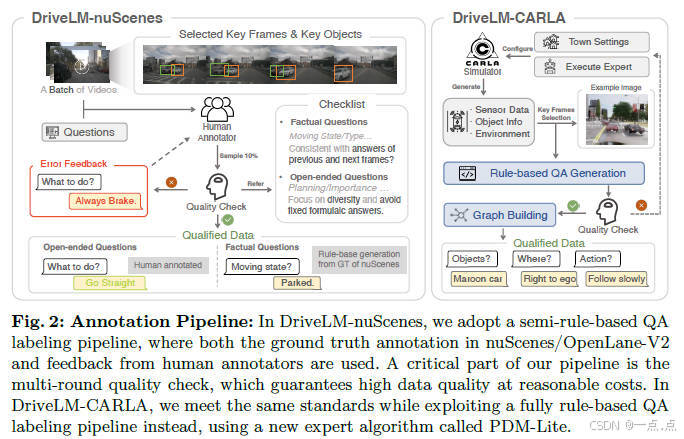
论文简介:
DriveLM提出了一种基于图视觉问答(GVQA)的端到端自动驾驶框架,通过模拟人类多步推理过程,将感知、预测、规划等任务建模为具有逻辑依赖的问答图结构。研究团队构建了DriveLM-Data数据集(涵盖nuScenes和CARLA),并开发了基于视觉语言模型(如BLIP-2)的基线模型DriveLM-Agent,利用轨迹标记和图提示策略整合多阶段推理。实验表明,该方法在nuScenes和Waymo上表现优异,尤其在零样本泛化场景下显著优于传统模型,验证了语言模型在自动驾驶中提升泛化与可解释性的潜力。研究为语言模型与自动驾驶的融合提供了新思路,但其推理效率与传感器适配仍是未来改进方向。
9、《LMDrive: Closed-Loop End-to-End Driving with Large Language Models》
23年12月发表,来自香港中文大学、商汤科技、InnoHK 感知交互智能中心、多伦多大学和上海AI实验室(代码开源)。
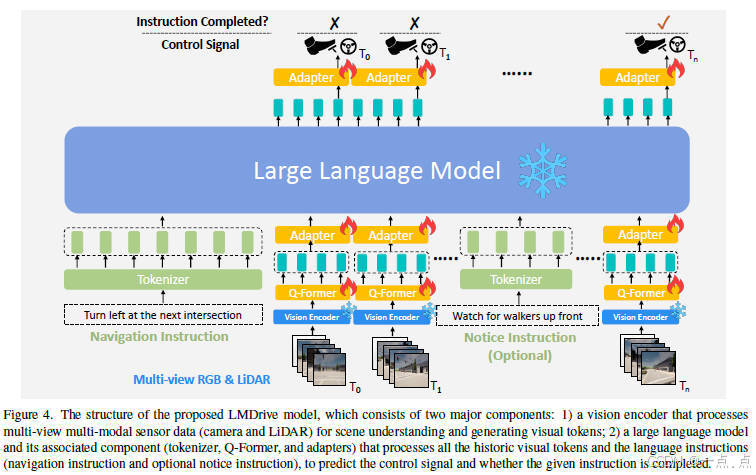
论文简介:
LMDrive提出了一种基于大语言模型(LLM)的闭环端到端自动驾驶框架,通过整合多模态传感器数据(摄像头、LiDAR)和自然语言指令,实现了与人类及导航软件的交互。该框架利用预训练的视觉编码器提取场景特征,并通过冻结的LLM进行指令理解和控制信号生成,解决了传统方法在长尾事件处理、语言交互和闭环执行中的不足。研究还公开了包含64K指令数据的数据集和LangAuto基准测试,实验验证了其在复杂场景下的有效性和鲁棒性,尤其在处理误导指令和多步骤指令时表现突出。该工作为语言驱动的自动驾驶研究提供了新思路与工具支持。
10、《LingoQA Visual Question Answering for Autonomous Driving》
2023年12月发表,来自Wayve公司(代码开源)。
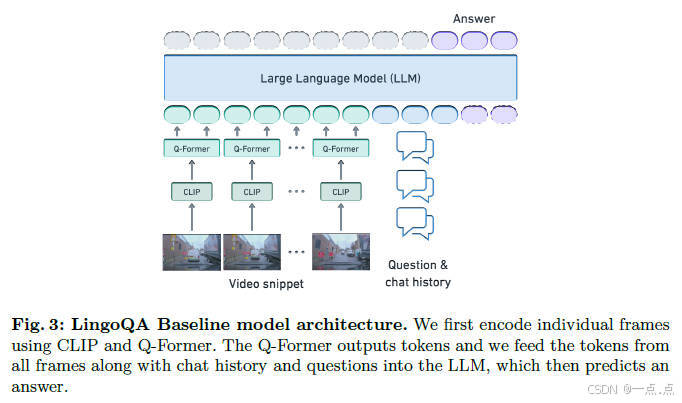
论文简介:
这篇论文提出了LingoQA,一个用于自动驾驶的视觉问答(VQA)新基准,包含28K短视频场景和419K标注的多样化数据集,覆盖驾驶行为、场景感知与推理任务。其核心贡献是开发了Lingo-Judge评估指标,通过微调DeBERTa-V3模型实现高效自动化评估,与人类评估的Spearman相关系数达0.95,显著优于传统指标和GPT-4。作者还构建了基于Vicuna-1.5-7B的视觉语言模型基线,通过多帧视频融合和分阶段训练策略优化性能。实验表明,现有模型(如GPT-4V)在自动驾驶场景中的真实回答率(59.6%)仍远低于人类水平(96.6%),突显该基准对推动可信自动驾驶系统发展的重要性。
11、《DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models》
2024年2月发表,来自清华和理想汽车的论文(代码开源)。
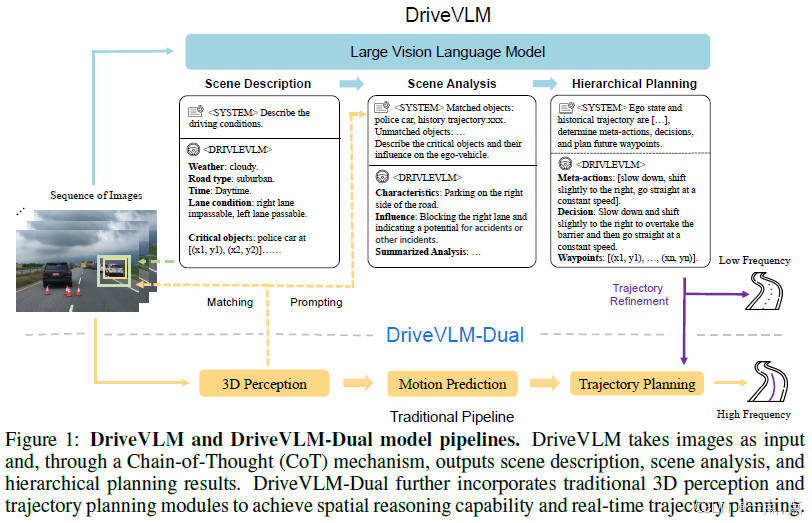
论文简介:
这篇论文提出了一种名为DriveVLM的自动驾驶系统,通过结合视觉语言模型(VLMs)提升复杂场景理解和规划能力。其核心是通过链式推理(CoT)模块实现场景描述、分析和分层规划,并进一步提出混合系统DriveVLM-Dual,融合传统3D感知与规划模块以弥补VLMs的空间推理缺陷。实验表明,该系统在nuScenes和自建数据集SUP-AD上表现优异,尤其在长尾场景中显著优于现有方法,且DriveVLM-Dual已成功部署于实车验证,兼顾实时性与安全性。
12、《VLM-MPC: Model Predictive Controller Augmented Vision Language Model for Autonomous Driving》
2024年8月发表,来自威斯康星大学的论文(代码开源)。
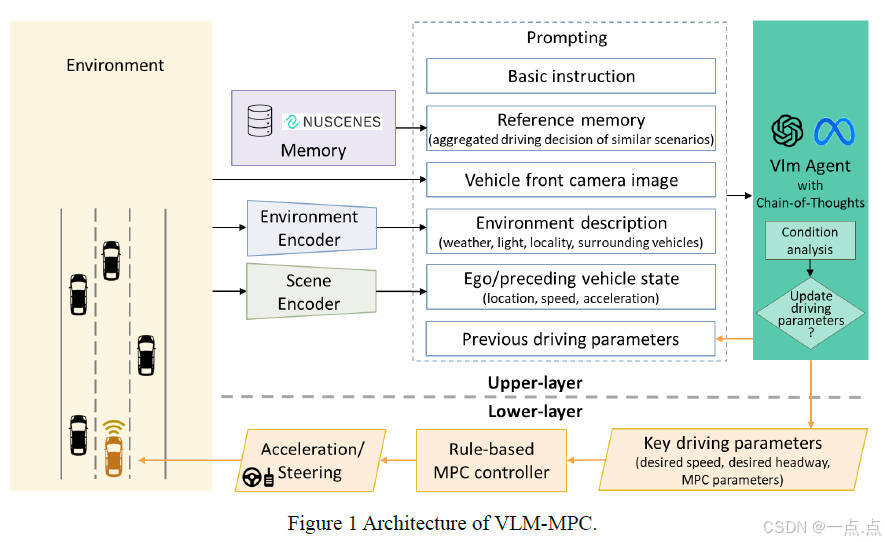
论文简介:
这篇论文提出了一种结合视觉语言模型(VLM)与模型预测控制(MPC)的自动驾驶控制器VLM-MPC,通过双层异步架构实现决策与控制分离。上层VLM基于摄像头图像、环境描述和历史记忆生成动态驾驶参数,下层MPC依据参数实时调整车辆运动,兼顾车辆动力学约束。实验表明,VLM-MPC在复杂场景(如雨天、夜间)中显著提升安全性(保持碰撞后侵入时间高于安全阈值)和驾驶平顺性(降低加速度波动),并通过消融测试验证了参考记忆和环境编码器对稳定性的关键作用。该框架解决了传统VLM响应速度不足的问题,为模型推理与实时控制的融合提供了新思路。
13、《DriveGenVLM: Real-world Video Generation for Vision Language Model based Autonomous Driving》
2024年8月发表,来自哥伦比亚大学的论文(代码非开源)。
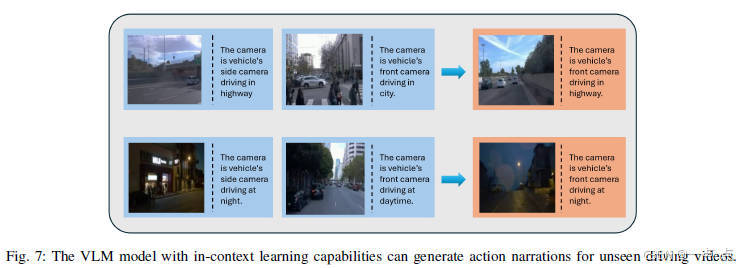
论文简介:
这篇论文提出了DriveGenVLM框架,通过去噪扩散概率模型(DDPM)生成自动驾驶场景视频,并利用视觉语言模型(EILEV)验证视频的可解释性。基于Waymo数据集的实验表明,自适应分层采样方法生成的视频在Frechet视频距离(FVD)指标上表现最优,且生成的视频可通过VLM生成场景描述,为自动驾驶的决策算法提供支持。尽管模型在复杂交通场景中仍存在挑战,但该框架展示了生成模型与视觉语言模型结合在自动驾驶领域的潜力。
14、《DriveGPT4: Interpretable End-to-End Autonomous Driving via Large Language Model》
2024年10月发表,来自香港大学、浙江大学、华为和悉尼大学(代码开源)。
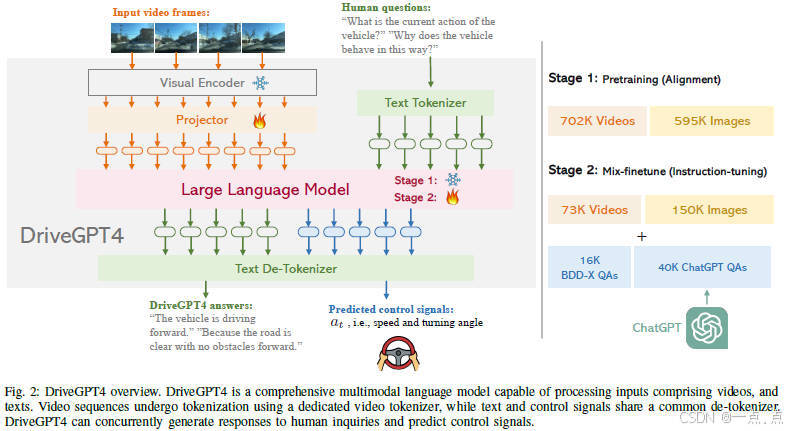
论文简介:
DriveGPT4是一种基于多模态大语言模型的可解释端到端自动驾驶系统,能够通过处理多帧视频和文本输入,生成车辆行为解释并预测控制信号。通过结合定制化的视觉指令调优数据集和混合微调策略,该系统在BDD-X数据集上展现出优于现有方法的性能,并在自动驾驶任务中接近或超越GPT4-V的表现。实验表明,DriveGPT4在动作描述、推理问答及控制信号预测等任务中均表现卓越,同时具备零样本泛化能力,为可解释自动驾驶提供了新思路。
15、《Large Language Models for Autonomous Driving (LLM4AD): Concept, Benchmark, Simulation, and Real-Vehicle Experiment》
2024年10月发表,来自普渡大学和北美丰田汽车的论文(代码开源)。
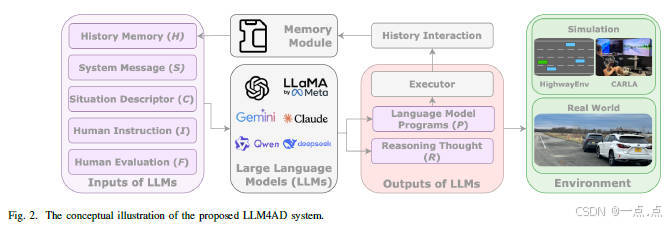
论文简介:
这篇论文提出了LLM4AD框架,将大型语言模型(LLM)融入自动驾驶系统,通过自然语言交互和上下文推理增强车辆的高层决策与个性化控制。作者构建了LaMPilot-Bench基准和CARLA仿真测试,验证了LLM在指令跟随、复杂场景处理中的性能,并通过真实车辆实验展示了云端LLM(Talk2Drive)和车载视觉语言模型(VLM)在个性化驾驶中的有效性。研究同时揭示了LLM4AD面临的挑战,包括实时性延迟、安全隐私风险、模型部署复杂性及用户信任问题,为未来在安全关键场景中融合语言模型提供了理论支持和实践参考。
16、《Robust RL with LLM-Driven Data Synthesis and Policy Adaptation for Autonomous Driving》
2024年10月发表,来自利物浦大学、华威大学和东南大学的论文(代码非开源)。
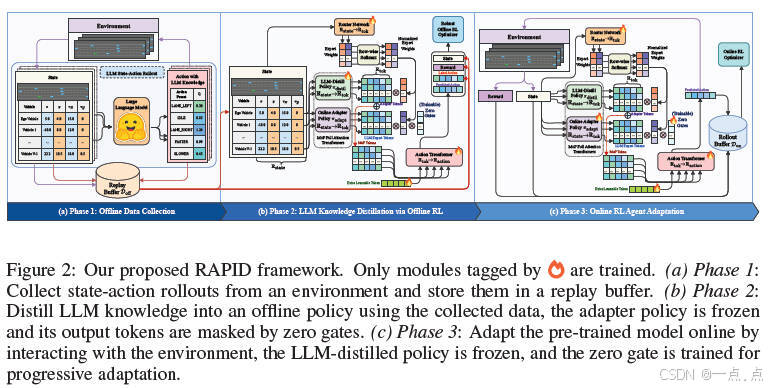
论文简介:
该论文提出了一种名为RAPID的鲁棒自适应策略融合与蒸馏框架,旨在将大型语言模型(LLM)的常识推理能力高效迁移至强化学习(RL)策略,以解决自动驾驶场景中LLM实时推理延迟和对抗攻击脆弱性的问题。RAPID通过三个核心设计实现目标:1)利用LLM生成的离线数据蒸馏专家知识至轻量级RL策略;2)引入鲁棒蒸馏机制,继承LLM的鲁棒性;3)采用混合略与在线适配器实现动态决策。实验表明,RAPID在复杂驾驶环境中显著提升了策略的实时性、泛化性和抗干扰能力,并验证了其在多场景下的高效知识迁移与适应性优化效果。
17、《Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving》
2024年10月发表,来自华中理工和地平线的论文(代码开源)。
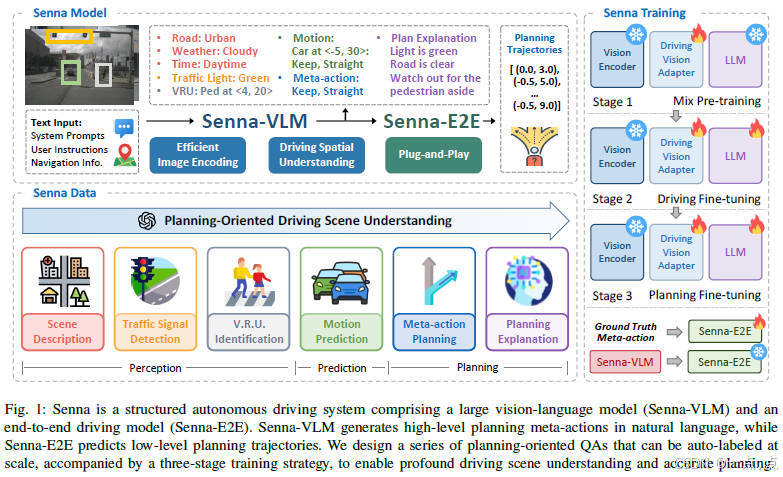
论文简介:
Senna提出了一种结合大型视觉语言模型(Senna-VLM)与端到端自动驾驶模型(Senna-E2E)的创新框架,通过自然语言生成高层规划决策,再由端到端模型预测精确轨迹,解决了传统方法在复杂场景中缺乏常识的问题。该系统采用多图像编码、多视角提示和规划导向的问答数据,结合三阶段训练策略,显著提升了规划性能。实验表明,Senna在nuScenes和DriveX数据集上实现了最先进的规划精度,平均规划误差降低27.12%,碰撞率减少33.33%,并展示了强大的跨场景泛化能力。研究为融合语言模型与自动驾驶提供了结构化解决方案,推动了安全性与鲁棒性的提升。
18、《HE-Drive:Human-Like End-To-End Driving With Vision Language Models》
2024年10月发表,来自地平线、香港大学、中科院大学和北京交大的论文(代码开源)。
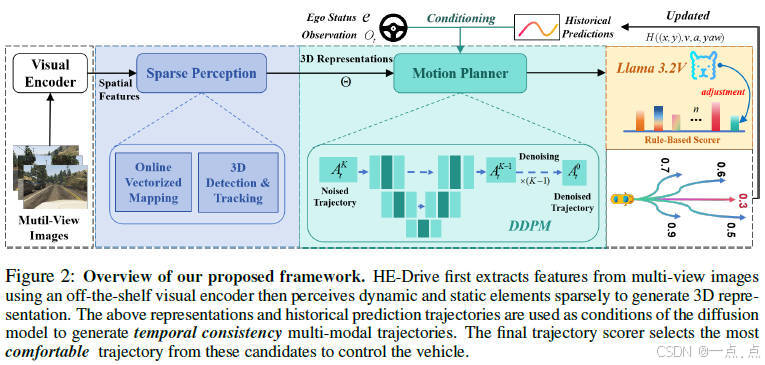
论文简介:
HE-Drive提出了一种结合稀疏感知、扩散模型和视觉语言模型(VLM)的类人端到端自动驾驶框架,通过扩散模型生成时间一致的多模态轨迹,并利用VLM动态调整规则评分权重以提升驾驶舒适性。系统采用稀疏感知提取3D环境表示,基于条件去噪扩散模型(DDPM)生成轨迹,结合VLM的零样本推理能力优化安全与舒适性指标。实验表明,HE-Drive在nuScenes等数据集上显著降低平均碰撞率71%,运行效率提升1.9倍,并在真实场景中实现舒适度32%的提升,验证了其在复杂场景下的强泛化能力和人机协同决策的有效性。
19、《FASIONAD FAst and Slow FusION Thinking Systems for Human-Like Autonomous Driving with Adaptive Feedback》
2024年11月发表,来自清华、早稻田大学、明尼苏达大学、多伦多大学、厦门大学马来西亚分校、电子科大(成都)、智平方科技和河南润泰数字科技的论文(代码非开源)。
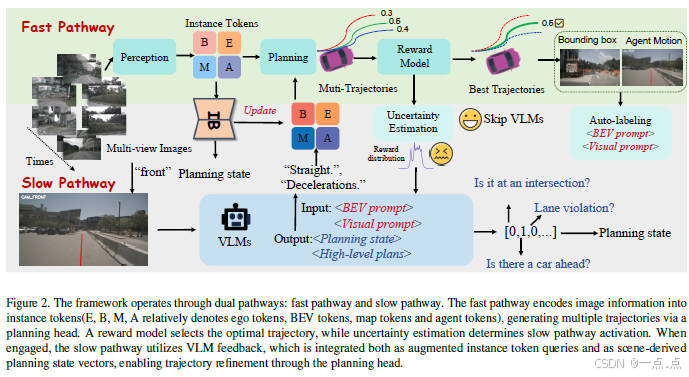
论文简介:
本文提出了一种名为FASIONAD的双系统自动驾驶框架,受心理学“快与慢”认知模型启发,将驾驶决策分为快速路径和慢速路径:前者通过数据驱动实时处理常规任务,后者利用视觉语言模型(VLM)进行复杂场景的深度推理。通过动态切换机制和自适应反馈,系统在nuScenes和CARLA基准测试中显著提升了导航成功率与安全性(碰撞率降低10-15%),尤其在长尾事件中表现突出。该框架创新性地融合了高效实时响应与人类式推理,为自动驾驶系统的适应性和可解释性提供了新方向。
20、《DriveMM: All-in-One Large Multimodal Model for Autonomous Driving》
2024年12月发表,来自中山大学深圳分校和美团的论文(代码开源)。
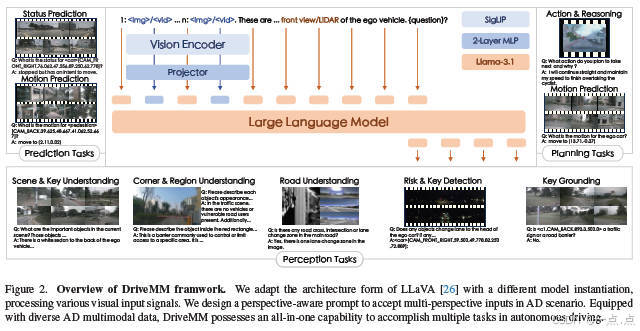
论文简介:
DriveMM是一种面向自动驾驶的全能大型多模态模型,能够处理图像、多视角视频等多种输入,并执行感知、预测、规划等多样化任务。通过课程预训练和数据集增强标准化方法,该模型显著提升了泛化能力和多任务适应性。实验表明,DriveMM在六个公共基准测试中均达到最先进性能,并在零样本迁移任务中表现出色,为自动驾驶提供了一种高效统一的解决方案。
21、《Large Language Model guided Deep Reinforcement Learning for Decision Making in Autonomous Driving》
2024年12月发表,来自北理工的论文(代码非开源)。
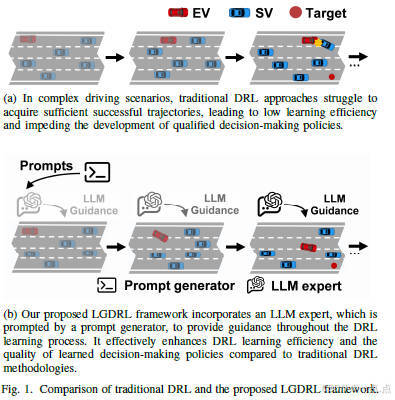
论文简介:
DriveMM是一种面向自动驾驶的全能大型多模态模型,能够处理图像、多视角视频等多种输入,并执行感知、预测、规划等多样化任务。通过课程预训练和数据集增强标准化方法,该模型显著提升了泛化能力和多任务适应性。实验表明,DriveMM在六个公共基准测试中均达到最先进性能,并在零样本迁移任务中表现出色,为自动驾驶提供了一种高效统一的解决方案。
22、《VLM-RL: A Unified Vision Language Models and Reinforcement Learning Framework for Safe Autonomous Driving》
2024年12月发表,来自Wisconsin Madison分校和Purdue大学的论文(代码开源)。
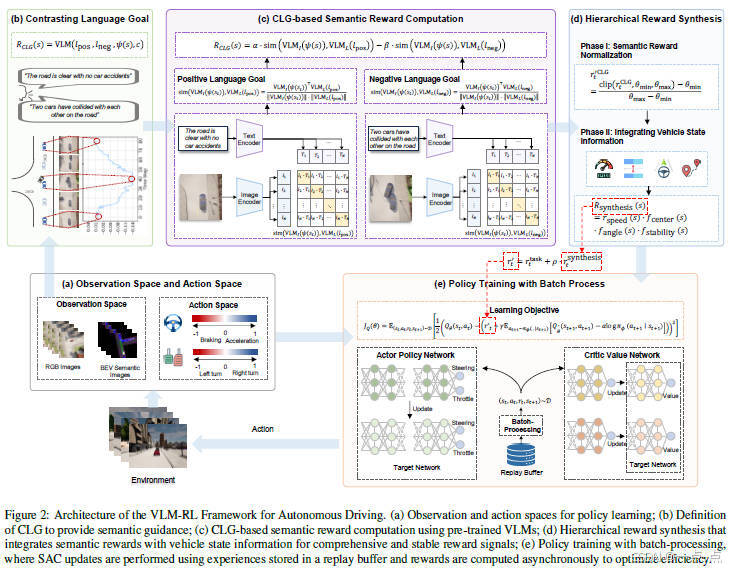
论文简介:
这篇论文提出了VLM-RL框架,通过整合视觉语言模型(VLM)与强化学习(RL)解决自动驾驶中的奖励设计难题。其核心创新包括:提出对比语言目标(CLG)范式,利用正负语言描述生成语义奖励;设计分层奖励合成方法,结合语义奖励与车辆状态信息以提高稳定性;引入批量处理技术优化计算效率。实验表明,VLM-RL在CARLA模拟器中显著降低碰撞率(10.5%)、提升路线完成率(104.6%),并在未见场景中展现强泛化能力。该方法无需人工设计奖励或微调VLM,首次验证了VLM与RL在端到端自动驾驶中的可行性,为安全驾驶提供了可扩展的解决方案,但极端光照等复杂环境仍是挑战。
23、《Generalizing End-To-End Autonomous Driving In Real-World Environments Using Zero-Shot LLMs》
2024年12月发表,来自纽约stony brook大学、UIC和桑瑞思(数字化医疗科技公司)的论文(代码非开源)。
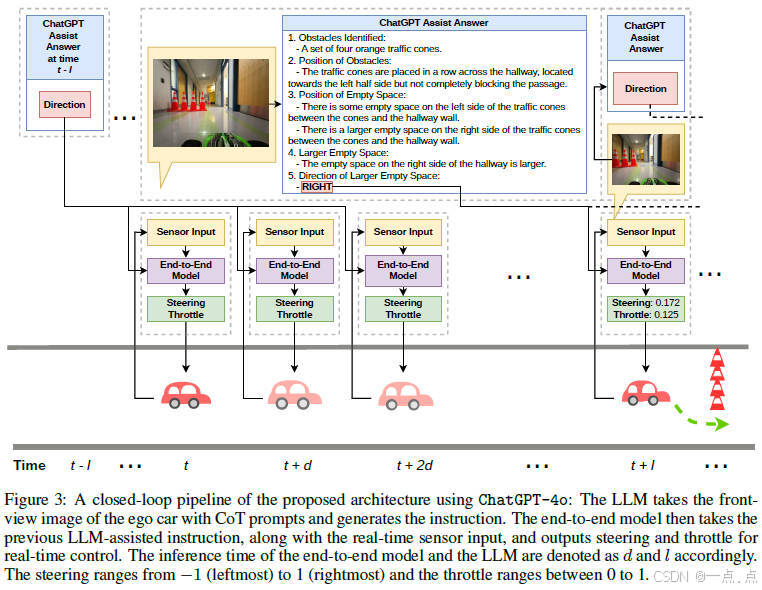
论文简介:
这篇论文提出了一种结合多模态大语言模型(LLM)与端到端自动驾驶模型的新架构,通过LLM生成高级驾驶指令(如左转、右转)来指导端到端模型输出具体动作(如方向盘和油门控制)。该方法无需微调LLM,利用提示工程技术(如思维链)降低数据需求,并通过缓存指令缓解LLM的高延迟问题。实验表明,在仅用简单场景(单个障碍物)训练后,模型在复杂真实环境(多障碍物)中的成功率显著提升(如LLaVA-LLaMA2+ViT测试成功率达83%)。主要贡献在于首次在真实闭环环境中验证了LLM增强端到端驾驶的可行性,同时通过解耦高层指令与底层控制,实现了低数据依赖和高适应性,但LLM在光照剧烈变化时仍存在局限性。
24、《WiseAD: Knowledge Augmented End-to-End Autonomous Driving with Vision-Language Model》
2024年12月发表,来自新加坡国立和浙大的论文(代码非开源)。

论文简介:
这篇论文提出了WiseAD,一种基于视觉语言模型(VLM)的知识增强端到端自动驾驶框架,通过整合广泛的驾驶知识(如场景理解、风险分析和驾驶建议)来提升轨迹规划能力。该方法基于轻量级MobileVLM模型,通过联合训练驾驶知识问答数据与轨迹规划数据,实现了知识对齐的闭环驾驶。实验表明,在CARLA模拟器中,WiseAD显著提升了驾驶评分(11.9%)和路线完成率(12.4%),同时减少了关键事故(如碰撞和闯红灯),并在零样本知识评估中优于其他VLM。核心贡献在于首次验证了深度和广度扩展的驾驶知识对自动驾驶性能的持续提升,为知识驱动的自动驾驶研究提供了新方向。
25、《SafeDrive: Knowledge- and Data-Driven Risk-Sensitive Decision-Making for Autonomous Vehicles with Large Language Models》
2024年12月发表,来自USC、U Wisconsin、U Michigan、清华大学和香港大学的论文(代码开源)。
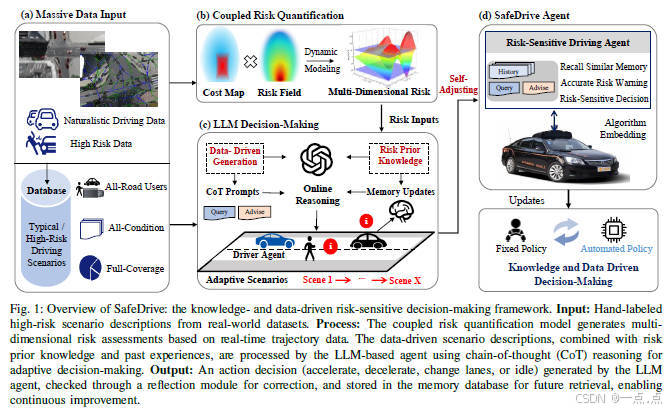
论文简介:
该论文提出了SafeDrive框架,通过结合知识驱动和数据驱动方法,利用大语言模型(LLM)提升自动驾驶车辆在动态高风险场景下的决策安全性与适应性。其核心模块包括风险量化模型(全方向风险评估)、记忆模块(经验存储与检索)、LLM推理模块(上下文感知决策)和反思模块(迭代优化决策)。实验表明,该框架在高速公路、交叉路口和环岛等真实场景中实现了100%安全率及超过85%的决策与人类行为对齐,显著优于传统方法,为解决长尾事件和复杂交互场景提供了创新解决方案。
26、《VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision》
2024年12月发表,来自Cruise和美国东北大学的论文(代码非开源)。
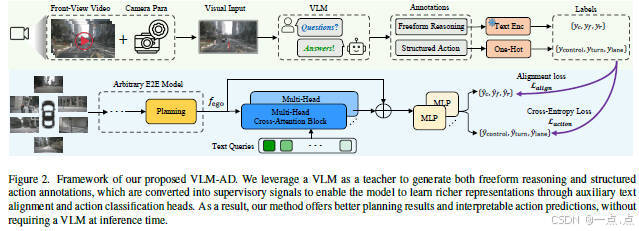
论文简介:
这篇论文提出了一种名为VLM-AD的端到端自动驾驶方法,通过引入视觉语言模型(VLM)作为教师模型,在训练阶段生成包含非结构化推理文本和结构化动作标签的监督信号,以增强模型的驾驶决策能力。该方法无需在推理阶段依赖VLM,降低了计算成本。实验表明,VLM-AD在nuScenes数据集上显著降低了规划误差(L2误差减少14.6%-33.3%)和碰撞率(降低38.7%-57.4%),并通过消融研究验证了推理标注的关键作用。该方法为自动驾驶系统提供了更丰富的特征表达和可解释性,同时保持了实时部署的实用性。
27、《LeapVAD: A Leap in Autonomous Driving via Cognitive Perception and Dual-Process Thinking》
2025年1月发表,来自浙江大学、上海AI实验室、慕尼黑工大、同济大学和中科大的论文(代码非开源)。
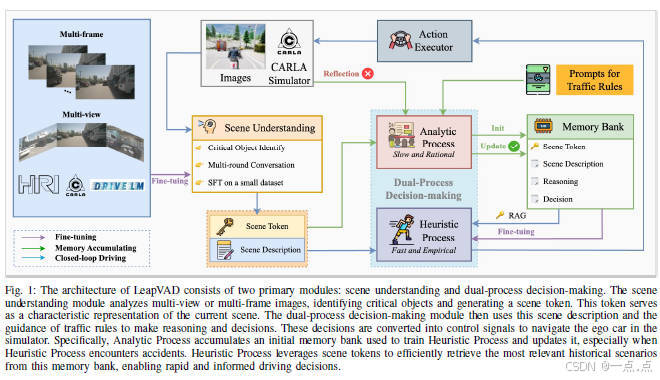
论文简述:
LeapVAD提出了一种基于认知感知和双过程思维的自动驾驶方法,通过模拟人类注意力机制识别关键交通元素,并整合分析过程(逻辑推理)与启发式过程(快速决策)实现高效决策。其创新点包括多帧时序场景理解、高效的场景编码器检索机制,以及通过反思和记忆库实现持续学习与跨领域知识迁移。实验表明,在CARLA和DriveArena仿真平台上,LeapVAD在有限训练数据下显著优于现有方法,驾驶分数提升最高达42.6%,尤其在复杂场景中展现出强鲁棒性和泛化能力。
28、《LearningFlow: Automated Policy Learning Workflow for Urban Driving with Large Language Models》
2025年1月发表,来自香港科技大学广州分校的论文(代码非开源)。
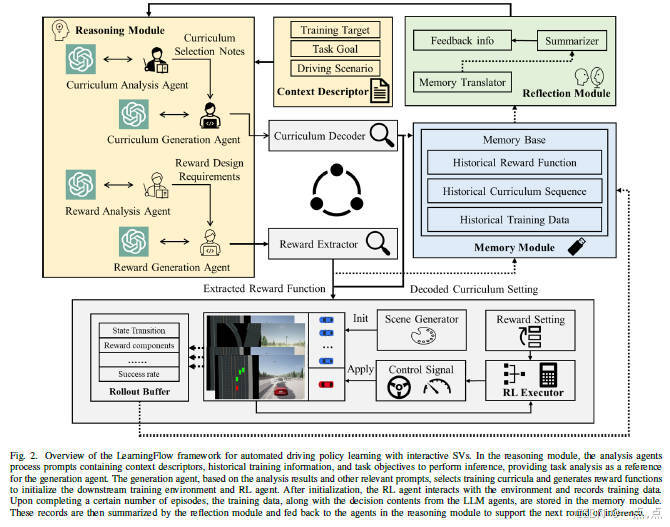
论文简述:
论文提出LearningFlow,一种基于多大型语言模型(LLM)代理协作的自动化策略学习框架,通过动态生成训练课程和奖励函数,解决城市自动驾驶中奖励函数手动设计复杂和样本效率低的问题。该框架结合课程强化学习(CRL),利用分析代理与生成代理的协同工作,支持实时调整训练环境与奖励机制。实验验证显示,在CARLA模拟器中,LearningFlow在多种复杂驾驶任务(如多车道超车、匝道汇入)中表现优异,成功率和泛化能力显著优于传统方法,并能适配不同强化学习算法(如PPO、DQN、SAC)。其核心贡献在于降低人工干预需求,提升策略安全性与训练效率。
29、《Sce2DriveX: A Generalized MLLM Framework for Scene-to-Drive Learning》
2025年2月发表,来自中科院软件所和中科院大学的论文(代码非开源)。
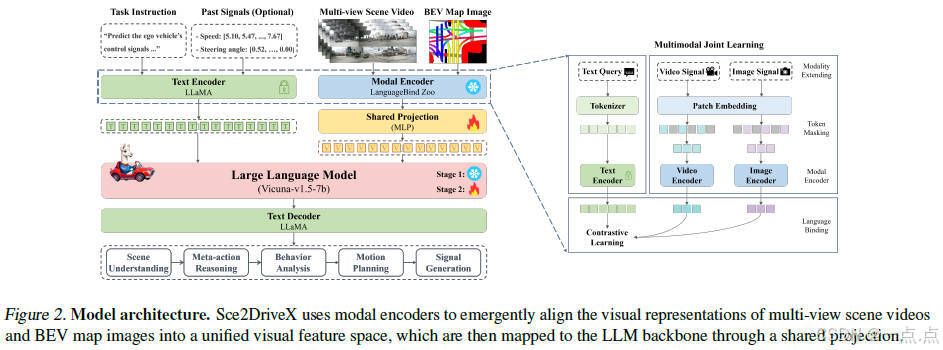
论文简介:
该论文提出了Sec2DriveX框架,通过结合多模态大语言模型(MLLM)与局部场景视频、全局鸟瞰图(BEV)的联合学习,实现对长时空关系和道路拓扑的深度理解,从而提升自动驾驶的跨场景泛化能力。其创新点包括:1)构建首个面向3D空间理解与长轴任务推理的VQA驾驶指令数据集;2)设计链式推理框架,从场景理解逐步推导至行为分析、运动规划与控制信号生成,模拟人类驾驶认知过程;3)提出三阶段训练流程(混合对齐预训练、场景理解微调、端到端驾驶微调)。实验表明,Sec2DriveX在场景理解、轨迹规划等任务中性能最优,并在复杂场景下展现出强泛化性。
30、《VLM-E2E Enhancing End-to-End Autonomous Driving with Multimodal Driver Attention Fusion》
2025年2月发表,来自香港科大广州分校、理想汽车和厦门大学的论文(代码非开源)。
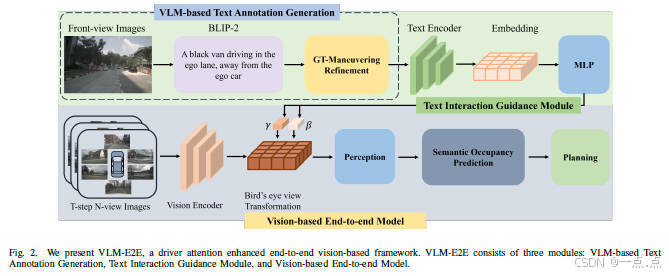
论文简介:
该论文提出了一种名为VLM-E2E的端到端自动驾驶框架,通过融合视觉语言模型(VLMs)的语义理解能力与鸟瞰图(BEV)的几何特征,增强系统在复杂动态场景中的决策能力。其核心创新包括:1)利用BLIP-2生成文本描述并借助CLIP编码,提取驾驶员注意力语义;2)提出动态加权融合策略(BEV-Text),自适应平衡视觉与文本模态的贡献;3)通过语义精炼和时空建模,解决VLM的幻觉问题并提升环境表征的鲁棒性。实验表明,在nuScenes数据集上,VLM-E2E在感知(如行人检测提升24.4%)、预测(IoU提升4.47%)和规划(3秒碰撞率降至1.17%)任务中均显著优于现有方法,尤其在长期安全性与人类驾驶行为对齐方面表现突出。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!