ElasticSearch从入门到精通-覆盖DSL操作和Java实战
一、ElasticSearch基础概念
1.1 认识elasticSearch
ElasticSearch(简称ES)是一款开源的、分布式的搜索引擎,它建立在Apache Lucene之上。简单来说,ElasticSearch就是一个能让你以极快速度进行数据搜索、存储和分析的系统。它不仅支持全文检索,还可以做结构化数据的高效查询、复杂聚合统计分析,广泛应用在网站搜索、日志分析、指标监控、电商推荐等领域。
简单举个例子,假设你有一张商品表(Product),要查商品名称里包含“手机”的记录:
SELECT * FROM product WHERE name LIKE CONCAT('%', '手机', '%');
SQL会一行行扫描name字段,看哪个name里有“手机”两个字,数据少时没啥问题,数据多了就会非常卡,很耗CPU
但在ElasticSearch里,早就把所有商品名建立好了倒排索引,比如:
-
“小米手机”会被拆成“小米”和“手机”两个词
-
“苹果手机壳”也被拆成“苹果”、“手机”、“壳”
所以当你搜索“手机”,ElasticSearch只需要:
-
快速定位所有包含“手机”的文档ID
-
直接返回结果,几乎不需要扫描每一条数据
速度快得不是一星半点!一句话总结:ElasticSearch就是一款为了快速检索大量数据而生的强大工具。
1.2 倒排索引
倒排索引是一种以词为核心,记录每个词在哪些文档中出现的数据结构。
-
传统索引记录的是「文档 → 内容」(比如文档ID 1 内容是“我喜欢看电影”),
-
倒排索引反过来记录「词 → 文档ID列表」(比如词“电影”出现在文档1和文档3里)。
这样,当我们想搜索某个词时,直接找到相关文档ID,比全文扫描快了太多!
假设有3篇文档:
| 文档ID | 内容 |
|---|---|
| 1 | 我喜欢看电影 |
| 2 | 我喜欢看小说 |
| 3 | 小说比电影更有趣 |
经过分词后:
| 文档ID | 分词结果 |
|---|---|
| 1 | 我、喜欢、看、电影 |
| 2 | 我、喜欢、看、小说 |
| 3 | 小说、比、电影、更、有趣 |
那么倒排索引就是:
| 词语 | 出现在哪些文档 |
|---|---|
| 我 | 1, 2 |
| 喜欢 | 1, 2 |
| 看 | 1, 2 |
| 电影 | 1, 3 |
| 小说 | 2, 3 |
| 比 | 3 |
| 更 | 3 |
| 有趣 | 3 |
比如搜索“电影”,倒排索引直接告诉你:文档1、文档3里有,不需要逐条遍历所有文档内容!
正向索引 vs 倒排索引(详细对比)
| 对比维度 | 正向索引(Forward Index) | 倒排索引(Inverted Index) |
|---|---|---|
| 组织方式 | 文档ID → 词或内容 | 词 → 文档ID列表 |
| 查询方式 | 给定文档ID快速取内容 | 给定关键词快速取文档ID |
| 搜索效率 | 适合按ID查找,不适合全文搜索(要全表扫描) | 适合全文搜索,关键词检索极快 |
| 适用场景 | 文档管理系统(如只按ID检索的存储系统) | 搜索引擎(如ElasticSearch、Lucene等) |
| 存储空间 | 比较小,结构简单 | 较大(存储了额外的词频、位置等信息) |
| 更新操作 | 插入新文档简单,搜索逻辑简单 | 插入新文档需要重新构建或增量更新倒排列表 |
1.3 核心概念
1.3.1 索引(Index)
-
类似于Mysql的数据表(Table)。
-
一个索引中存储一类相似的数据,比如:商品信息、用户信息。
-
索引是存数据的地方,文档的集合。
比如有一个products索引,里面存各种商品。
1.3.2. 文档(Document)
-
类似于数据表里的行数据(Row)。
-
每个文档是一个 JSON 对象,包含一组字段和值。
比如:
{ "name": "小米手机", "price": 1999, "category": "手机" }
文档是存储的最小单位。
1.3.3. 字段(Field)
-
类似于数据库中的列(Column)。
-
文档里面的每个键值对,就是一个字段。
-
不同字段可以设置不同的索引方式,比如:有些字段用于搜索,有些只用于存储。
比如上面文档里的name、price、category就是字段。
1.3.4. 映射(Mapping)
-
类似于数据库的表结构(Schema)。
-
是索引中文档的约束,例如字段类型约束
1.3.5. 节点(Node)
-
运行着一个 ElasticSearch 实例的服务器叫节点。
-
一个节点可以管理一部分数据,也可以跟其他节点组成集群。
1.3.6. 集群(Cluster)
-
多个节点组成一个 ElasticSearch 集群。
-
集群中有一个“主节点”(Master),管理整个集群的健康、协调。
1.3.7. 分片(Shard)和副本(Replica)
-
分片(Shard):把数据分成小块,每块独立存储和查询,提高扩展性。
-
副本(Replica):每个分片可以有多个副本,防止单点故障,提高查询能力。
比如,一个索引有3个主分片(primary shard),每个主分片有1个副本(replica),总共有6个分片在集群中分布。
1.3.8 MySQL和Elasticsearch对应的结构关系
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
1.4 分词器
1.4.1什么是分词器
在 ElasticSearch 中,分词器(Analyzer)就是把一段文本按照一定规则切分成一个个词语(Term)的工具。英文中单词之间有空格,很好切,但中文是连续的,没有自然的空格,所以需要分词器来判断词的边界。
它的作用是:
-
在建立倒排索引时,把文本切成词,方便快速检索。
-
在用户搜索时,也把输入的搜索词切成词,跟索引时的词对齐,保证能查到。
简单理解就是:
分词器=文本预处理器,帮你把整段话切分成能索引和搜索的小单元。
1.4.2 分词器的工作流程
一个完整的分词过程,通常包括 三步:
-
字符过滤(Character Filters)
在分词前,先对文本做预处理,比如去除HTML标签、替换某些字符等。 -
分词(Tokenizer)
把文本按照一定规则切分成一个个词。 -
词元过滤(Token Filters)
在分完词后,对每个词做进一步处理,比如统一大小写、去掉停用词(如“的”“了”等)、同义词处理等。
1.4.3 分词器的类型
ElasticSearch 自带了很多分词器,不同场景可以选择不同的,常见的有:
| 分词器名称 | 特点 | 示例 |
|---|---|---|
| standard(标准分词器) | 默认分词器,按照英语单词规则切分 | "The quick brown fox" → ["the", "quick", "brown", "fox"] |
| simple(简单分词器) | 以非字母字符作为分隔,全部转小写 | "Hello World!" → ["hello", "world"] |
| whitespace(空格分词器) | 仅仅根据空格切分,不改大小写 | "Hello World!" → ["Hello", "World!"] |
| keyword(关键词分词器) | 不分词,整体作为一个词 | "手机壳保护套" → ["手机壳保护套"] |
| ik_max_word(中文分词器,最大词数) | 把句子尽可能拆成所有可能的词 | "我喜欢看电影" → ["我", "喜欢", "看", "电影"] |
| ik_smart(中文分词器,智能简洁) | 更倾向于分成有意义的大词块 | "我喜欢看电影" → ["我喜欢", "看电影"] |
其中,IK分词器是中文处理中最常用的第三方分词器(需要安装插件)。
二、DSL操作
DSL(Domain Specific Language,领域特定语言)类似于SQL
在 ElasticSearch 中,就是一种用 JSON 格式编写的搜索或管理指令。
我们用 DSL 来创建索引、插入数据、查询数据、更新数据等等。
2.1 索引库操作
1. 创建一个索引(带字段Mapping)
PUT /products
{"settings": {"number_of_shards": 3, # 主分片数量"number_of_replicas": 1 # 副本数量},"mappings": {"properties": {"name": {"type": "text", # 支持分词搜索"analyzer": "ik_max_word" # 中文分词器},"price": {"type": "float" # 浮点型},"createTime": {"type": "date", # 日期类型"format": "yyyy-MM-dd HH:mm:ss||strict_date_optional_time||epoch_millis"},"category": {"type": "keyword" # 关键词,不分词,适合分类、标签}}}
}
✅ 解释:
-
settings是索引的配置,比如分片、副本数。 -
mappings是字段的类型定义,比如是字符串、数值、日期。 -
analyzer指定分词器。
结果:成功创建一个名字叫 products 的索引。
2. 查看索引结构(Mapping)
GET /products/_mapping✅ 作用:查看 products 索引定义了哪些字段,字段类型是什么。
3. 查看索引基本信息(Settings)
GET /products/_settings✅ 作用:查看 products 索引的分片、副本配置。
4. 删除索引
DELETE /products✅ 作用:彻底删除 products 索引库(数据也会一起删掉)。
⚠️ 注意:一旦删除,数据没了,不可恢复!
5. 修改索引(增加字段)
ElasticSearch允许动态映射(默认情况下),但如果想手动新增字段,可以这样:
PUT /products/_mapping
{"properties": {"brand": {"type": "keyword"}}
}
✅ 作用:给 products 索引新增一个 brand 字段。
2.2. 文档基本操作
2.2.1 添加文档(Create / Index)
1. 指定ID添加
PUT /products/_doc/1
{"name": "小米手机12","price": 3699,"createTime": "2025-04-26 10:00:00","category": "手机"
}
✅ 解释:
-
products是索引名 -
_doc是类型(ES7以后可以不管) -
1是文档ID(自己指定) -
Body 是文档内容(JSON格式)
成功后,id=1 的文档就被保存到 products 索引里了。
2. 自动生成ID添加
POST /products/_doc
{"name": "苹果手机14","price": 6999,"createTime": "2025-04-26 11:00:00","category": "手机"
}
✅ 解释:
-
不自己指定ID,ES会自动生成一个随机ID。
这种适合高并发、大批量新增数据。
3. 批量新增文档
POST /products/_bulk
{ "index": { "_id": "5" } }
{ "name": "苹果耳机", "price": 299, "category": "手机", "createTime": "2025-04-26T10:00:00" }
{ "index": { "_id": "6" } }
{ "name": "小米耳机", "price": 399, "category": "手机", "createTime": "2025-04-26T10:05:00" }
{ "index": { "_id": "7" } }
{ "name": "华为耳机", "price": 199, "category": "耳机", "createTime": "2025-04-26T10:10:00" }
为什么要用 Bulk?
-
效率高:一次性发请求,减少网络开销
-
批量处理:常用于大数据导入、系统初始化、测试批量插入等场景
2.2.2 获取文档(Get)
GET /products/_doc/1
✅ 作用:
根据ID查询,获取到刚刚添加的小米手机那条数据。
返回结果会包含 _source 字段,里面就是文档的内容。
2.2.3 更新文档(Update)
1. 局部更新(只改一部分字段)
POST /products/_update/1
{"doc": {"price": 3499}
}
✅ 解释:
-
用
doc关键字,表示只修改price字段,其他字段不变。 -
更新后,小米手机的价格变成了 3499。
2. 全量更新(覆盖式更新)
PUT /products/_doc/1
{"name": "小米手机12 Pro","price": 3999,"createTime": "2025-04-26 12:00:00","category": "手机旗舰"
}
✅ 解释:
-
直接
PUT,相当于整条覆盖原来的数据。 -
小心使用,因为没传的字段会丢失!
2.2.4 删除文档(Delete)
DELETE /products/_doc/1
✅ 解释:
-
根据 ID 删除
id=1的文档(小米手机)。 -
删除后,查询不到了。
2.2.5 搜索文档(Query)
ElasticSearch最强大的功能就是搜索,下面举简单例子:
查询所有文档(match_all)
GET /products/_search
{"query": {"match_all": {}}
}
✅ 解释:
-
查询
products索引里的所有数据。 -
一般用于测试或全量展示。
2.3 叶子查询
在 Elasticsearch 中,叶子查询(Leaf Query)是最基础的一种查询类型。它们直接针对 单个字段的值 进行匹配,比如判断某个字段是否等于某个值、是否包含某个词、是否大于或小于某个数等等。
特点:
-
不需要组合其他查询。
-
直接对单个字段做判断。
-
查询逻辑简单直接。
常见的叶子查询有:
| 叶子查询类型 | 说明 | 示例 |
|---|---|---|
term | 精确匹配 | 查询 category = 手机 |
match | 分词查询 | 查询 name 包含“小米” |
range | 范围查询 | 查询 price >= 4000 |
exists | 字段存在 | 查询有 createTime 字段 |
prefix | 前缀匹配 | 查询 name 以“苹果”开头 |
wildcard | 通配符查询 | 查询 name 包含“手机” |
2.3.1. match 查询(匹配查询)
场景:查找 name 字段中包含 "苹果" 的所有商品。
GET /products/_search
{"query": {"match": {"name": "苹果"}}
}
解释:
-
match查询会对字段进行分词处理,所以name字段中包含“苹果”的所有文档都会匹配。 -
适用于文本字段(如
name),能够通过分词进行模糊匹配。
2.3.2. term 查询(精确查询)
场景:查找 category 为 手机 的所有商品(精确匹配,不分词)。
GET /products/_search
{"query": {"term": {"category": "手机"}}
}
解释:
-
term查询是精确匹配,不进行分词处理,适用于keyword类型的字段(如category)。 -
只有
category精确等于 "手机" 的文档会被匹配,手机旗舰不会匹配。
2.3.3. range 查询(范围查询)
场景:查找价格大于等于 4000 的商品。
GET /products/_search
{"query": {"range": {"price": {"gte": 4000}}}
}
解释:
-
range查询用于范围筛选,常用于数字、日期等字段。 -
这个查询会返回
price >= 4000的商品,匹配苹果手机14(价格为 6999)。 -
对于范围查询的关键字:gte:大于等于; gt:大于;lte:小于等于;lt:小于
2.3.4. exists 查询(字段存在性查询)
场景:查找那些存在 createTime 字段的商品。
GET /products/_search
{"query": {"exists": {"field": "createTime"}}
}
解释:
-
exists查询检查文档中是否存在某个字段。 -
这个查询会返回所有有
createTime字段的商品。
2.3.5. prefix 查询(前缀匹配查询)
场景:查找 name 字段以 "苹果" 开头的商品。
GET /products/_search
{"query": {"prefix": {"name": "苹果"}}
}
解释:
-
prefix查询用于匹配字段值的前缀。 -
该查询会返回
name字段以 "苹果" 开头的所有商品,匹配苹果手机14。
2.3.6. wildcard 查询(通配符查询)
场景:查找 name 字段中包含 "手机" 的商品。
GET /products/_search
{"query": {"wildcard": {"name": "*手机*"}}
}
解释:
-
wildcard查询用于通配符查询,*表示任意字符,可以匹配字段值中的任意部分。 -
该查询会返回
name中包含 "手机" 的所有商品,匹配苹果手机14和小米手机12 Pro。
2.4 复合查询
在 Elasticsearch 中,复合查询(Compound Query)用于组合多个查询条件,使得用户能够执行更复杂的查询。复合查询是由多个查询条件组成,可以使用逻辑操作符来组合不同的子查询,以达到灵活的查询效果。
2.4.1 查询条件和查询类型
Elasticsearch 提供了多种复合查询类型,它们通过逻辑条件(如 must、should、must_not)将不同的查询条件组合起来。
查询条件含义如下:
-
must:包含的查询条件都必须满足(即“与”操作)。
-
should:包含的查询条件至少满足一个(即“或”操作)。如果至少一个
should子句匹配到文档,文档会得分更高。 -
must_not:包含的查询条件不能匹配(即“非”操作)。
-
filter:类似于
must,但不影响文档的得分。用于过滤数据(例如通过 ID 或范围过滤数据)。
查询类型含义如下:
| 查询类型 | 说明 | 适用场景 |
|---|---|---|
bool | 通过 must、should、must_not 等组合多个查询条件 | 复杂的组合查询,支持多条件筛选 |
dis_max | 选择多个查询中的得分最高的结果 | 最匹配查询,不关注其他查询结果 |
constant_score | 为查询结果分配固定得分,忽略实际得分 | 不关心得分排序,仅关心匹配结果 |
|
| 根据自定义评分规则修改文档得分 | 自定义评分,调整排序和优先级 |
2.4.2 bool 查询
bool 查询是最常用的复合查询,它允许将多个查询条件组合在一起,并通过 must、should、must_not 和 filter 进行条件筛选。
示例:查找名字包含“苹果”且价格大于等于 4000 的手机,且排除 category 为 "手机旗舰" 的商品:
GET /products/_search
{"query": {"bool": {"must": [{ "match": { "name": "苹果" }},{ "range": { "price": { "gte": 4000 }}}],"must_not": [{ "term": { "category": "手机旗舰" }}]}}
}
2.4.3 dis_max 查询
dis_max 查询会选择多个子查询中的最匹配文档,通常用于“最匹配”的搜索场景。如果你有多个查询条件,dis_max 查询会返回得分最高的结果。
示例:查找 name 包含“苹果”或者 category 为“手机”的商品:
GET /products/_search
{"query": {"dis_max": {"queries": [{ "match": { "name": "苹果" }},{ "term": { "category": "手机" }}]}}
}
2.4.4 constant_score 查询
constant_score 查询是一种常用的优化方式,它可以对某些查询应用一个固定的得分,而不考虑实际的查询得分。它通常用于只关心文档匹配与否,而不关心文档的评分排序的场景。
示例:查找 category 为 “手机” 的商品,使用固定得分:
GET /products/_search
{"query": {"constant_score": {"filter": { "term": { "category": "手机" }},"boost": 1.2}}
}
2.4.5 function_score 查询
function_score 查询允许你根据文档的匹配情况对文档的得分进行自定义修改。你可以为每个文档设置权重或者其他的自定义评分规则。
示例:查找 category 为 “手机” 的商品,并根据 price 字段进行加权排序
GET /products/_search
{"query": {"function_score": {"query": {"term": { "category": "手机" }},"functions": [{"field_value_factor": {"field": "price","factor": 0.1,"modifier": "log1p","missing": 1}}]}}
}
2.5 排序
在 Elasticsearch 中,排序是根据查询结果的得分(_score)或者字段值来对文档进行排序的过程。排序操作可以帮助我们根据特定的条件获取最相关、最符合要求的文档。排序在搜索中非常重要,尤其是在显示搜索结果时,它直接影响到文档的显示顺序。
排序操作通常基于两种因素进行:1、得分排序(默认),文档会根据查询条件的匹配程度来得分,得分越高的文档越靠前;2、字段值排序,根据某个字段的值进行升序或降序排序;
示例:根据价格(price)进行升序排序:
GET /products/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc"}}]
}
示例:根据价格(price)降序排序,并且根据创建时间(createTime)升序排序:
GET /products/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "desc"}},{"createTime": {"order": "asc"}}]
}
2.6 分页
2.6.1 简单概述
分页是指将查询结果分成多个部分(页),每次返回一部分数据,常用于处理大量数据的查询。Elasticsearch 提供了非常灵活的分页功能,通过 from 和 size 参数来控制查询的结果集。分页对于提升用户体验和优化系统性能至关重要,尤其是在处理大量数据时,分页可以避免一次性加载全部数据而导致的性能问题。分页操作的核心参数如下:
-
from:指定查询结果从哪一条开始,表示偏移量(类似 SQL 中的OFFSET)。 -
size:指定返回的结果数量,表示每页的记录数(类似 SQL 中的LIMIT)。
示例:假设我们需要查询 products 索引中的文档,每页显示 10 条记录,查询第 2 页的数据(即第 11 至第 20 条文档)
GET /products/_search
{"query": {"match_all": {}},"from": 10,"size": 10
}
2.6.2 分页的限制-深度分页
分页的工作原理是通过控制查询结果的偏移量(from)和每页显示的数量(size)来限制返回的数据。具体来说,Elasticsearch 会根据查询条件匹配文档,然后根据 from 和 size 进行过滤和分页。
虽然分页非常有用,但也存在一些性能问题,尤其是在处理非常大的数据集时:
-
深度分页性能下降:当使用非常大的
from值(例如from=1000000)时,性能会下降,因为 Elasticsearch 需要跳过大量的文档。这会导致查询响应变慢。 -
滚动查询(Scroll):为了避免深度分页带来的性能问题,Elasticsearch 提供了滚动查询(Scroll)功能,适用于大规模数据的遍历。
2.6.3 深度分页解决方案
在大数据量场景下,分页查询时 from 值的增大可能导致性能下降。为了改善这种情况,Elasticsearch 提供了几种方案:
-
使用
search_after参数:search_after可以通过排序后的最后一条记录来继续查询下一个页面的数据,避免使用from参数来跳过大量文档。 -
滚动查询(Scroll):用于遍历大量数据,尤其适合导出所有数据或深度查询。
示例:使用 search_after 进行分页
search_after 通过提供上一次查询返回的排序字段的值来继续获取下一页数据,而不是使用 from。它适合用于深度分页,可以避免性能下降。
GET /products/_search
{"query": {"match_all": {}},"size": 10,"sort": [{ "price": "asc" }],"search_after": [6999]
}
解释:
-
search_after: 指定上一页的排序字段值,这样可以避免深度分页时的性能问题。在这个例子中,我们使用了price字段进行排序,search_after表示上一页最后一条记录的price值。 -
该查询会返回价格大于 6999 的下一页数据。
示例:滚动查询
滚动查询允许你按页一次性获取大量数据,并且可以通过游标继续获取未返回的文档。
GET /products/_search?scroll=1m
{"query": {"match_all": {}},"size": 100
}
解释:
-
scroll: 设置滚动时间(如 1 分钟),在此期间可以继续使用返回的scroll_id来获取接下来的数据。 -
size: 每次返回 100 条文档。 -
返回的响应中会包含一个
scroll_id,通过这个scroll_id可以继续查询未返回的文档。
2.7 高亮
高亮(Highlighting)是 Elasticsearch 提供的一项功能,用于在查询结果中突出显示与查询条件匹配的部分内容,通常用于搜索引擎和日志系统中,帮助用户更容易地识别匹配的部分。
在 Elasticsearch 中,查询时会自动检查哪些文档与查询条件匹配,然后根据设定的高亮字段突出显示这些匹配的部分。高亮通常在搜索结果中显示,以帮助用户快速找到与其搜索词相关的内容。
比如在博客用户搜索“小钊”,就能出现相关的用户信息,并且所有“小钊”都会红色高亮。
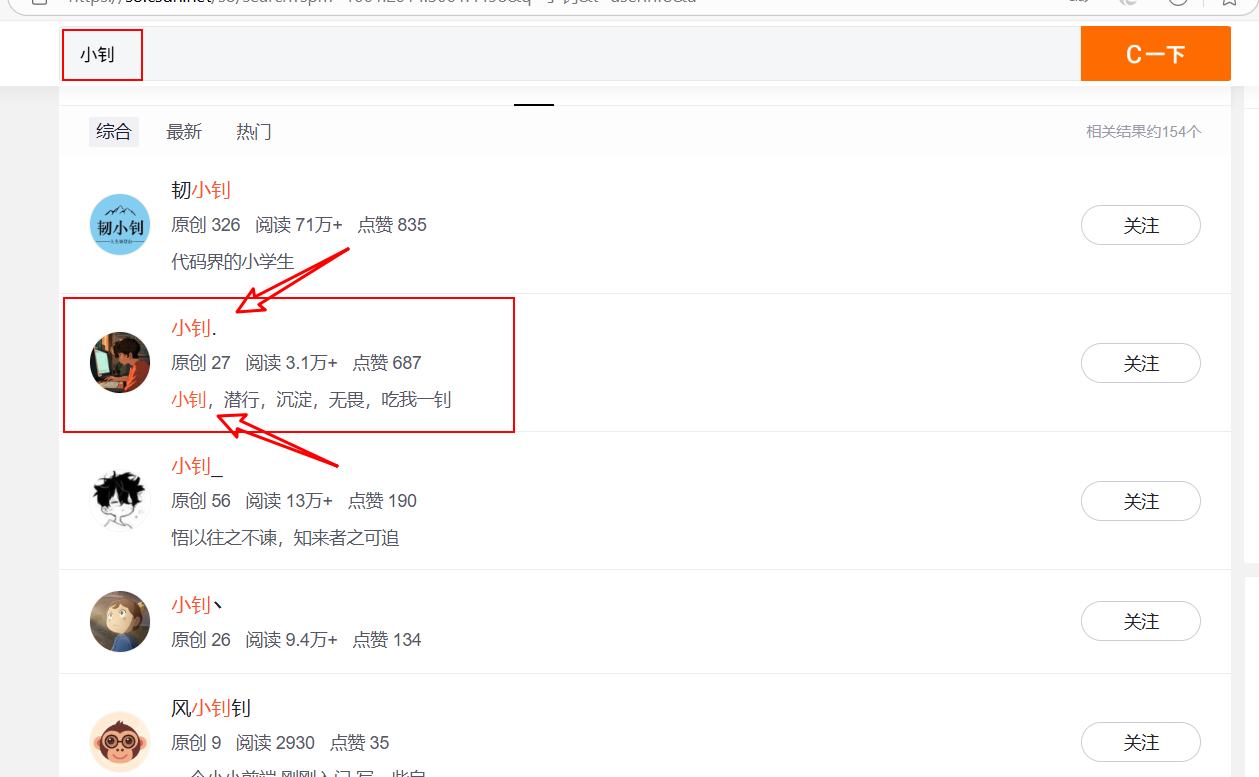
高亮的关键要素:
-
highlight:Elasticsearch 提供的一个特殊字段,用于定义高亮的参数。 -
pre_tags和post_tags:设置高亮文本的前后标记,常用的是<em>和</em>,用于标记高亮部分。 -
fields:定义哪些字段需要进行高亮处理。 -
boundary_scanner:设置边界扫描器,控制如何处理高亮文本的分词。
示例:假设我们要在 products 索引中查找包含“苹果”的手机,并对 name 字段进行高亮显示
GET /products/_search
{"query": {"match": {"name": "苹果"}},"highlight": {"pre_tags": ["<em>"],"post_tags": ["</em>"],"fields": {"name": {}}}
}
解释:
-
query: 使用match查询查找包含 “苹果” 的文档。 -
highlight: 该部分指定需要高亮显示的字段和样式。-
pre_tags: 设置高亮的开始标记,这里使用<em>标签。 -
post_tags: 设置高亮的结束标记,这里使用</em>标签。 -
fields: 指定高亮的字段,这里对name字段进行高亮。
-
2.8 数据聚合
数据聚合(Aggregation)是 Elasticsearch 提供的一项强大功能,用于对大量的数据进行汇总和分析。聚合操作可以让我们对数据进行分组、求和、计数、平均、最大值、最小值等统计操作。聚合是分析数据的核心组件,广泛应用于日志分析、业务数据报表、数据挖掘等领域。
Elasticsearch 中的聚合通常是通过 aggregations 或简称 aggs 来实现的。在查询体中,聚合操作作为一个子元素存在,通常与查询语句并行使用。
聚合的基本概念
-
聚合:Elasticsearch 中的聚合操作类似于 SQL 中的
GROUP BY和HAVING子句,它对数据进行分组并返回聚合结果。 -
桶聚合(Bucket Aggregation):将文档分组(桶),每个桶代表一组文档。比如按日期分组、按范围分组、按字段值分组等。
-
度量聚合(Metric Aggregation):对文档进行计算,例如求和、求平均、计算最大值或最小值等。
-
管道聚合(Pipeline Aggregation):在已有聚合的基础上进行进一步的计算和转换,例如计算一个聚合的平均值等。
-
复合聚合(Compound Aggregation):将多个聚合操作嵌套组合使用,从而实现更复杂的聚合需求。
2.8.1 桶聚合(Bucket Aggregation)
桶聚合将文档分组,每个组称为一个“桶”。常用的桶聚合有:
-
terms:基于某个字段的值进行分组。 -
range:基于某个字段的范围进行分组。 -
date_histogram:按时间区间进行分组。
比如,查询商品类别的分布情况:
GET /products/_search
{"size": 0,"aggs": {"categories": {"terms": {"field": "category"}}}
}
2.8.2 度量聚合(Metric Aggregation)
度量聚合对数据进行计算,返回一个数值,如总和、最大值、最小值、平均值等。
示例:计算所有商品的平均价格
GET /products/_search
{"size": 0,"aggs": {"avg_price": {"avg": {"field": "price"}}}
}
2.8.3 复合聚合(Compound Aggregation)
复合聚合是将多个聚合组合在一起使用,从而实现更复杂的需求。可以将桶聚合和度量聚合组合在一起,甚至可以在一个桶聚合内嵌套其他聚合。
示例:terms + avg 聚合(按类别分组,并计算每个类别的平均价格)
GET /products/_search
{"size": 0,"aggs": {"categories": {"terms": {"field": "category"},"aggs": {"avg_price": {"avg": {"field": "price"}}}}}
}
2.8.4 管道聚合(Pipeline Aggregation)
管道聚合是基于其他聚合的结果进行计算和处理。常用的管道聚合有:
-
bucket_sort:对桶的结果进行排序。 -
moving_avg:计算移动平均。 -
derivative:计算聚合结果的差异。
示例:对每个类别的聚合结果进行排序,按平均价格从高到低排序
GET /products/_search
{"size": 0,"aggs": {"categories": {"terms": {"field": "category"},"aggs": {"avg_price": {"avg": {"field": "price"}},"sorted_by_price": {"bucket_sort": {"sort": [{"avg_price": {"order": "desc"}}]}}}}}
}
三、Java代码实战
3.1 导入依赖和配置
3.1.1 导入Maven依赖
首先,确保在你的 pom.xml 中添加 Elasticsearch 的相关依赖。
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.17.21</version> </dependency>
🔵 注意:版本要兼容,比如 Spring Boot 2.x 通常对应 Elasticsearch 7.x,Spring Boot 3.x 对应 Elasticsearch 8.x。
3.1.2 配置类
@Configuration
public class ElasticSearchConfig {@Beanpublic RestHighLevelClient restHighLevelClient() {return new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.150.102", 9200, "http")));}
}192.168.150.102是我的IP地址,需要根据你的IP地址做修改
3.2 索引操作
一般来说,项目中对索引的操作比较少,修改、查询索引更是没什么需要,就不一一列举。
3.2.1 创建索引
@Testpublic void testCreateIndex() throws IOException {// 1.创建索引请求CreateIndexRequest request = new CreateIndexRequest("products");// 2.设置索引的配置(settings)request.settings(Settings.builder().put("index.number_of_shards", 3) // 主分片数量.put("index.number_of_replicas", 1) // 副本数量);// 3.设置索引的映射(mappings)final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" },\n" +" \"price\":{\n" +" \"type\": \"float\"\n" +" },\n" +" \"category\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"createTime\":{\n" +" \"type\": \"date\"\n" +" }\n" +" }\n" +" }\n" +"}";// 4.准备请求参数request.source(MAPPING_TEMPLATE, XContentType.JSON);// 5.执行索引创建请求try {CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);System.out.println("索引创建结果:" + response.isAcknowledged());} catch (MapperParsingException e) {// 处理映射解析异常System.out.println("映射错误: " + e.getMessage());}}3.2.2 删除索引
@Testvoid testDeleteIndex() throws IOException {// 1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("products");// 2.发送请求client.indices().delete(request, RequestOptions.DEFAULT);}3.2.3 判断索引是否存在
@Testvoid testExistsIndex() throws IOException {// 1.创建Request对象GetIndexRequest request = new GetIndexRequest("products");// 2.发送请求boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);// 3.输出System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");}3.3 文档基本操纵
3.3.1 生成文档
生成文档可以指定ID,也可以不指定ID,注意:不指定ID的话,ElasticSearch会自动生成一个ID,但查询返回的对象ID为空。
指定ID生成文档:
@Testpublic void testAddProduct() throws IOException {// 1. 创建一个 Product 对象Product product = new Product();product.setId("3");product.setName("苹果手机 8Pro");product.setPrice(4999.0);product.setCategory("寿命长");product.setCreateTime(LocalDateTime.now());// 2. 创建 IndexRequest对象IndexRequest request = new IndexRequest("products").id(product.getId()) // 指定文档 ID.source(JSONUtil.toJsonStr(product), XContentType.JSON); // 设置数据源,JSON 格式// 3. 执行新增操作IndexResponse response = client.index(request, RequestOptions.DEFAULT);System.out.println("插入成功,ID:" + response.getId() + "product: " + product);}不指定ID生成文档:
@Testpublic void testAddProductWithoutId() throws IOException {// 1. 创建一个 Product 对象Product product = new Product();product.setName("苹果手机14");product.setPrice(6999.0);product.setCategory("寿命长");product.setCreateTime(LocalDateTime.now());// 2. 创建 IndexRequest对象IndexRequest request = new IndexRequest("products").source(JSONUtil.toJsonStr(product), XContentType.JSON);// 3. 执行新增操作IndexResponse response = client.index(request, RequestOptions.DEFAULT);System.out.println("插入成功,自动生成ID:" + response.getId() + ",Product:" + product);}3.3.2 根据Id获取文档
@Testpublic void testGetProductById() throws IOException {// 1.创建GerRequest对象GetRequest request = new GetRequest("products", "1");// 2.执行查询操作GetResponse response = client.get(request, RequestOptions.DEFAULT);// 3.解析查询结果if (response.isExists()) {String sourceAsString = response.getSourceAsString();System.out.println("查询到文档:" + sourceAsString);} else {System.out.println("文档不存在");}}3.3.3 更新文档
修改文档分为局部修改和全局修改,全局修改即新增文档操作,根据ID判断文档是否存在,存在就执行修改操作,不存在就执行新增操作。
局部修改:
@Testpublic void testUpdateProduct() throws IOException {// 1.创建UpdateRequest对象UpdateRequest request = new UpdateRequest("products", "1");// 2. 局部修改Map<String, Object> fields = new HashMap<>();fields.put("price", 3499.0);request.doc(fields);// 3.执行修改操作UpdateResponse response = client.update(request, RequestOptions.DEFAULT);System.out.println("更新成功,版本号:" + response.getVersion());}全局修改:
@Testpublic void testOverwriteProduct() throws IOException {// 1.创建Product对象Product product = new Product();product.setId("1");product.setName("小米手机12 Pro");product.setPrice(3993.0);product.setCategory("价格低");product.setCreateTime(LocalDateTime.now());// 2.创建IndexRequest对象IndexRequest request = new IndexRequest("products").id(product.getId()).source(JSONUtil.toJsonStr(product), XContentType.JSON);// 3.执行修改操作IndexResponse response = client.index(request, RequestOptions.DEFAULT);System.out.println("覆盖更新成功,ID:" + response.getId());}3.3.4 删除文档
@Testpublic void testDeleteProductById() throws IOException {// 1.创建DeleteRequest对象DeleteRequest request = new DeleteRequest("products", "1");// 2.执行删除操作DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);System.out.println("删除成功,ID:" + response.getId());}3.3.5 查询所有文档
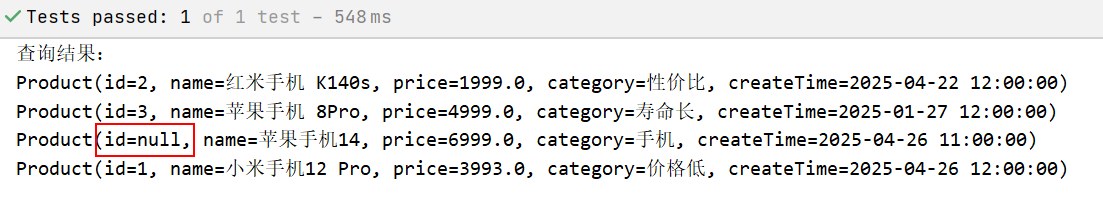
@Testpublic void testSearchAllProducts() throws IOException {// 1.创建SearchRequest对象SearchRequest request = new SearchRequest("products");// 2. 创建查询条件,这里是查询所有(match_all)SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();sourceBuilder.query(new MatchAllQueryBuilder());request.source(sourceBuilder);// 3.执行查询操作SearchResponse response = client.search(request, RequestOptions.DEFAULT);System.out.println("查询结果:");for (SearchHit hit : response.getHits()) {System.out.println(JSONUtil.toBean(hit.getSourceAsString(), Product.class));}}可以看出,第三条文档没有指定ID,查询的结果ID为空
3.4 叶子查询
3.4.1 match查询(匹配查询)
查询name中包含“苹果”的文档
/*** 1. Match 查询 name 包含“苹果”*/@Test@DisplayName("Match 查询:name 包含 '苹果'")public void testMatchQuery() throws IOException {// 1. 创建 SearchRequest 对象SearchRequest request = new SearchRequest("products");SearchSourceBuilder builder = new SearchSourceBuilder();builder.query(QueryBuilders.matchQuery("name", "苹果"));request.source(builder);// 2. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 3. 打印查询结果System.out.println("查询到 " + response.getHits().getTotalHits().value + " 条数据:");for (SearchHit hit : response.getHits()) {System.out.println(JSONUtil.toJsonPrettyStr(hit.getSourceAsMap()));}}3.4.2 term查询(精确查询)
查询category == “性价比”的文档
/*** 2. Term 查询 category = "性价比"*/@Test@DisplayName("Term 查询:category = '性价比'")public void testTermQuery() throws IOException {// 1. 创建 SearchRequest 对象SearchRequest request = new SearchRequest("products");SearchSourceBuilder builder = new SearchSourceBuilder();builder.query(QueryBuilders.termQuery("category", "性能好"));request.source(builder);// 2. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 3. 打印查询结果System.out.println("查询到 " + response.getHits().getTotalHits().value + " 条数据:");for (SearchHit hit : response.getHits()) {System.out.println(JSONUtil.toJsonPrettyStr(hit.getSourceAsMap()));}}3.4.3 range查询(范围查询)
查询价格大于等于4000的文档
/*** 3. Range 查询 price >= 4000*/@Test@DisplayName("Range 查询:price 大于等于 4000")public void testRangeQuery() throws IOException {// 1. 创建 SearchRequest 对象SearchRequest request = new SearchRequest("products");SearchSourceBuilder builder = new SearchSourceBuilder();builder.query(QueryBuilders.rangeQuery("price").gte(4000));request.source(builder);// 2. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 3. 打印查询结果System.out.println("查询到 " + response.getHits().getTotalHits().value + " 条数据:");for (SearchHit hit : response.getHits()) {System.out.println(JSONUtil.toJsonPrettyStr(hit.getSourceAsMap()));}}3.4.4 exists查询(字段存在性查询)
查询createTime字段存在的文档
/*** 4. Exists 查询存在 createTime 字段的文档*/@Test@DisplayName("Exists 查询:存在 createTime 字段")public void testExistsQuery() throws IOException {// 1. 创建 SearchRequest 对象SearchRequest request = new SearchRequest("products");SearchSourceBuilder builder = new SearchSourceBuilder();builder.query(QueryBuilders.existsQuery("createTime"));request.source(builder);// 2. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 3. 打印查询结果System.out.println("查询到 " + response.getHits().getTotalHits().value + " 条数据:");for (SearchHit hit : response.getHits()) {System.out.println(JSONUtil.toJsonPrettyStr(hit.getSourceAsMap()));}}3.4.5 prefix查询(前缀匹配查询)
查询name前缀是“苹果”的文档
/*** 5. Prefix 查询 name 前缀是“苹果”*/@Test@DisplayName("Prefix 查询:name 前缀为 '苹果'")public void testPrefixQuery() throws IOException {// 1. 创建 SearchRequest 对象SearchRequest request = new SearchRequest("products");SearchSourceBuilder builder = new SearchSourceBuilder();builder.query(QueryBuilders.prefixQuery("name", "苹果"));request.source(builder);// 2. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 3. 打印查询结果System.out.println("查询到 " + response.getHits().getTotalHits().value + " 条数据:");for (SearchHit hit : response.getHits()) {System.out.println(JSONUtil.toJsonPrettyStr(hit.getSourceAsMap()));}}3.4.6 wildcard查询(通配符查询)
查询name中包含“手机”的文档
/*** 6. Wildcard 查询 name 包含“手机”*/@Test@DisplayName("Wildcard 查询:name 包含 '手机'")public void testWildcardQuery() throws IOException {// 1. 创建 SearchRequest 对象SearchRequest request = new SearchRequest("products");SearchSourceBuilder builder = new SearchSourceBuilder();builder.query(QueryBuilders.wildcardQuery("name", "*手机*"));request.source(builder);// 2. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 3. 打印查询结果System.out.println("查询到 " + response.getHits().getTotalHits().value + " 条数据:");for (SearchHit hit : response.getHits()) {System.out.println(JSONUtil.toJsonPrettyStr(hit.getSourceAsMap()));}}3.5 复合查询
3.5.1 bool查询
@Testpublic void testBoolQuery() throws IOException {// 1. 创建 SearchRequest,指定索引SearchRequest request = new SearchRequest("products");// 2. 构建 Bool 查询,设置 must、must_not 条件BoolQueryBuilder boolQuery = QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "苹果")) // 必须匹配 name 包含“苹果”.must(QueryBuilders.rangeQuery("price").gte(4000)) // 必须 price >= 4000.mustNot(QueryBuilders.termQuery("category", "昂贵")); // 排除 category 为“昂贵”的数据// 3. 封装到 SearchSourceBuilder 中SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().query(boolQuery);request.source(sourceBuilder);// 4. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5. 遍历查询结果for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString());}}3.5.2 dis_max查询
@Testpublic void testDisMaxQuery() throws IOException {// 1. 创建 SearchRequest,指定索引SearchRequest request = new SearchRequest("products");// 2. 构建 DisMax 查询,多个子查询取最大得分DisMaxQueryBuilder disMaxQuery = QueryBuilders.disMaxQuery().add(QueryBuilders.matchQuery("name", "苹果")) // 匹配 name 包含“苹果”.add(QueryBuilders.termQuery("category", "寿命长")); // 或者 category 是“寿命长”// 3. 封装到 SearchSourceBuilder 中SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().query(disMaxQuery);request.source(sourceBuilder);// 4. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5. 遍历查询结果for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString());}}3.5.3 constant_score查询
@Testpublic void testConstantScoreQuery() throws IOException {// 1. 创建 SearchRequest,指定索引SearchRequest request = new SearchRequest("products");// 2. 构建 ConstantScore 查询,匹配 category 为“寿命长”,得分固定提升1.2倍ConstantScoreQueryBuilder constantScoreQuery = QueryBuilders.constantScoreQuery(QueryBuilders.termQuery("category", "寿命长")).boost(1.2f); // 设置 boost 权重// 3. 封装到 SearchSourceBuilder 中SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().query(constantScoreQuery);request.source(sourceBuilder);// 4. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5. 遍历查询结果for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString());}}3.5.4 function_score查询
@Testpublic void testFunctionScoreQuery() throws IOException {// 1. 创建 SearchRequest,指定索引SearchRequest request = new SearchRequest("products");// 2. 构建 FunctionScore 查询,根据 price 字段动态调整得分FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery(QueryBuilders.termQuery("category", "寿命长"), // 查询条件:category 为“寿命长”new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{new FunctionScoreQueryBuilder.FilterFunctionBuilder(ScoreFunctionBuilders.fieldValueFactorFunction("price").factor(0.1f) // 调整因子.modifier(FieldValueFactorFunction.Modifier.LOG1P) // 取对数后加1.missing(1) // 如果字段不存在,默认用1)});// 3. 封装到 SearchSourceBuilder 中SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().query(functionScoreQuery);request.source(sourceBuilder);// 4. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5. 遍历查询结果for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString());}}3.6 排序和分页
3.6.1 排序
@Testpublic void testMatchAllSort() throws IOException {// 1. 创建 SearchRequest 对象,指定索引名SearchRequest request = new SearchRequest("products");// 2. 创建查询条件,使用 match_all 查询所有文档MatchAllQueryBuilder matchAllQuery = new MatchAllQueryBuilder();// 3. 构建查询源(SearchSourceBuilder),设置查询条件和排序规则SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().query(matchAllQuery).sort("price", SortOrder.DESC) // 按价格降序.sort("createTime", SortOrder.ASC); // 再按创建时间升序request.source(sourceBuilder);// 4. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5. 遍历查询结果for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString());}}3.6.2 分页
@Testpublic void testMatchNameWithPagination() throws IOException {// 1. 创建 SearchRequest 对象,指定索引名SearchRequest request = new SearchRequest("products");// 2. 创建查询条件,使用 match 查询 name 字段,值为"苹果"MatchQueryBuilder matchQuery = new MatchQueryBuilder("name", "苹果");// 3. 构建查询源(SearchSourceBuilder),设置查询条件和分页信息SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().query(matchQuery).from(10) // 从第11条记录开始(分页起始位置,默认从0开始).size(10); // 每页显示10条记录request.source(sourceBuilder);// 4. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5. 遍历查询结果for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString());}}3.6.3 高亮
@Testpublic void testMatchAndHighlight() throws IOException {// 1. 创建 SearchRequest 对象,指定索引名SearchRequest request = new SearchRequest("products");// 2. 创建查询条件,使用 match 查询 name 字段为"苹果"MatchQueryBuilder matchQuery = new MatchQueryBuilder("name", "苹果");// 3. 创建高亮构建器 HighlightBuilderHighlightBuilder highlightBuilder = new HighlightBuilder().field("name") // 指定需要高亮的字段.preTags("<em>") // 高亮前缀.postTags("</em>"); // 高亮后缀// 4. 构建查询源 SearchSourceBuilder,设置查询条件和高亮SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().query(matchQuery).highlighter(highlightBuilder);request.source(sourceBuilder);// 5. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 6. 遍历查询结果for (SearchHit hit : response.getHits()) {// 获取原始数据String sourceAsString = hit.getSourceAsString();System.out.println("原始数据:" + sourceAsString);// 获取高亮字段Map<String, HighlightField> highlightFields = hit.getHighlightFields();HighlightField highlightName = highlightFields.get("name");if (highlightName != null) {String highlightedName = highlightName.getFragments()[0].string();System.out.println("高亮后的name字段:" + highlightedName);}}}3.7 数据聚合
3.7.1 桶聚合
/*** 按 category 字段分组聚合*/@Testpublic void testAggTermsCategory() throws IOException {// 1. 创建请求对象SearchRequest request = new SearchRequest("products");// 2. 构建聚合TermsAggregationBuilder aggBuilder = new TermsAggregationBuilder("categories").field("category");SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().size(0).aggregation(aggBuilder);request.source(sourceBuilder);// 3. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4. 解析聚合结果Terms categories = response.getAggregations().get("categories");for (Terms.Bucket bucket : categories.getBuckets()) {System.out.println("分类:" + bucket.getKeyAsString() + ",数量:" + bucket.getDocCount());}}3.7.2 度量聚合
/*** 计算所有商品的价格平均值*/@Testpublic void testAggAvgPrice() throws IOException {// 1. 创建请求对象SearchRequest request = new SearchRequest("products");// 2. 构建聚合AvgAggregationBuilder avgBuilder = new AvgAggregationBuilder("avg_price").field("price");SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().size(0).aggregation(avgBuilder);request.source(sourceBuilder);// 3. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4. 解析聚合结果Avg avgPrice = response.getAggregations().get("avg_price");System.out.println("平均价格:" + avgPrice.getValue());}3.7.3 复合聚合
/*** 按 category 分组,每组内再计算平均价格*/@Testpublic void testAggTermsAndAvg() throws IOException {// 1. 创建请求对象SearchRequest request = new SearchRequest("products");// 2. 构建聚合TermsAggregationBuilder categories = new TermsAggregationBuilder("categories").field("category");AvgAggregationBuilder avgPrice = new AvgAggregationBuilder("avg_price").field("price");categories.subAggregation(avgPrice);SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().size(0).aggregation(categories);request.source(sourceBuilder);// 3. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4. 解析聚合结果Terms categoryAgg = response.getAggregations().get("categories");for (Terms.Bucket bucket : categoryAgg.getBuckets()) {System.out.println("分类:" + bucket.getKeyAsString() + ",数量:" + bucket.getDocCount());Avg avg = bucket.getAggregations().get("avg_price");System.out.println("平均价格:" + avg.getValue());}}3.7.4 管道聚合
/*** 按 category 分组,每组算平均价格,并按平均价格降序排序*/@Testpublic void testAggTermsAvgAndSort() throws IOException {// 1. 创建请求对象SearchRequest request = new SearchRequest("products");// 2. 构建聚合TermsAggregationBuilder categories = new TermsAggregationBuilder("categories").field("category");AvgAggregationBuilder avgPrice = new AvgAggregationBuilder("avg_price").field("price");BucketSortPipelineAggregationBuilder sort = new BucketSortPipelineAggregationBuilder("sorted_by_price",List.of(new org.elasticsearch.search.sort.FieldSortBuilder("avg_price").order(SortOrder.DESC)));categories.subAggregation(avgPrice);categories.subAggregation(sort);SearchSourceBuilder sourceBuilder = new SearchSourceBuilder().size(0).aggregation(categories);request.source(sourceBuilder);// 3. 执行查询SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4. 解析聚合结果Terms categoryAgg = response.getAggregations().get("categories");for (Terms.Bucket bucket : categoryAgg.getBuckets()) {System.out.println("分类:" + bucket.getKeyAsString() + ",数量:" + bucket.getDocCount());Avg avg = bucket.getAggregations().get("avg_price");System.out.println("平均价格:" + avg.getValue());}}