C++入门小馆: STL 之queue和stack
嘿,各位技术潮人!好久不见甚是想念。生活就像一场奇妙冒险,而编程就是那把超酷的万能钥匙。此刻,阳光洒在键盘上,灵感在指尖跳跃,让我们抛开一切束缚,给平淡日子加点料,注入满满的passion。准备好和我一起冲进代码的奇幻宇宙了吗?Let's go!
我的博客:yuanManGan
我的专栏:C++入门小馆 C言雅韵集 数据结构漫游记 闲言碎语小记坊 题山采玉 领略算法真谛


目录
怎么使用队列和栈:
队列和栈的模拟实现:
deque:
priority_queue
先来了解
怎么使用队列和栈:

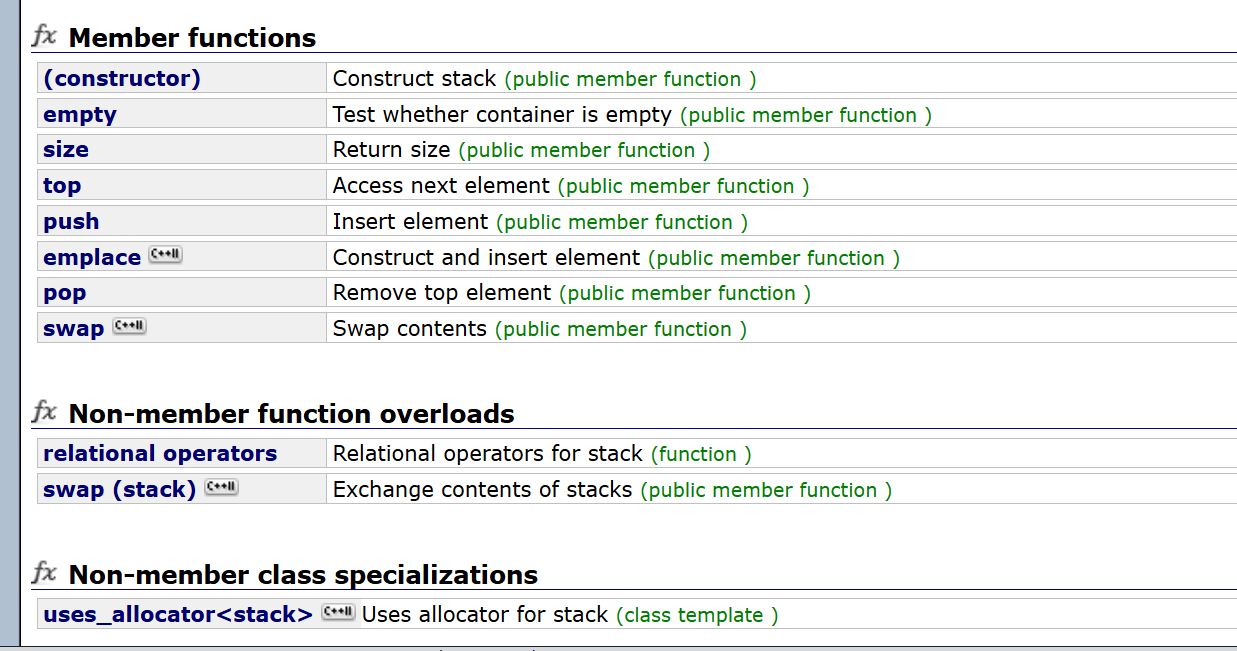
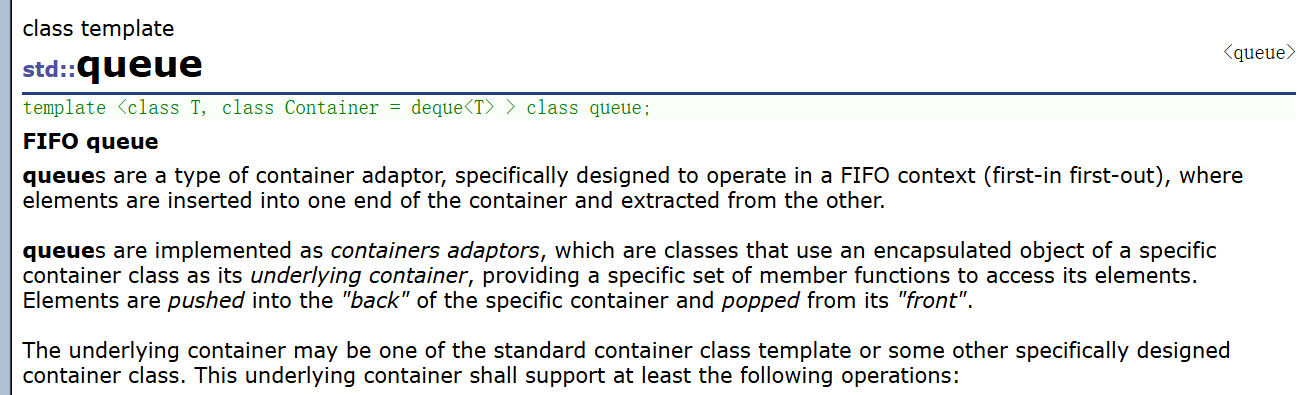
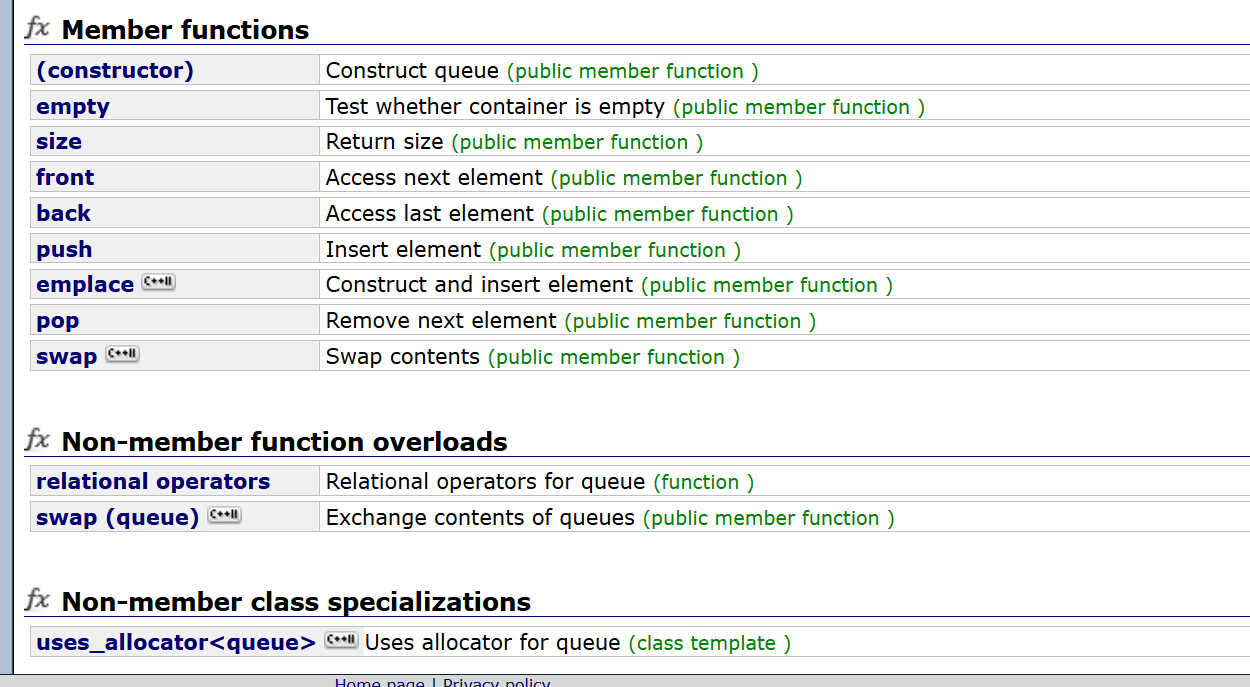
这些接口看起来已经很熟悉了。
直接来看看使用吧:
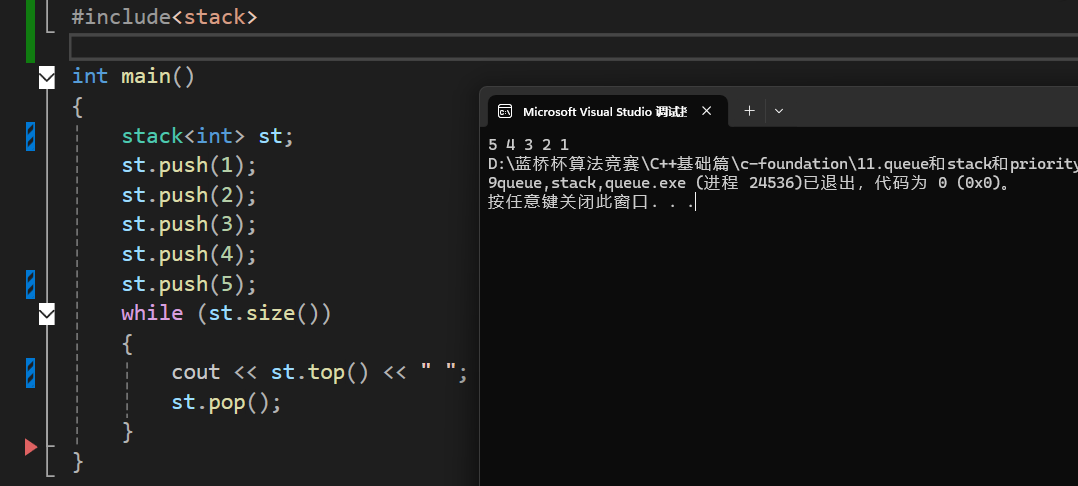
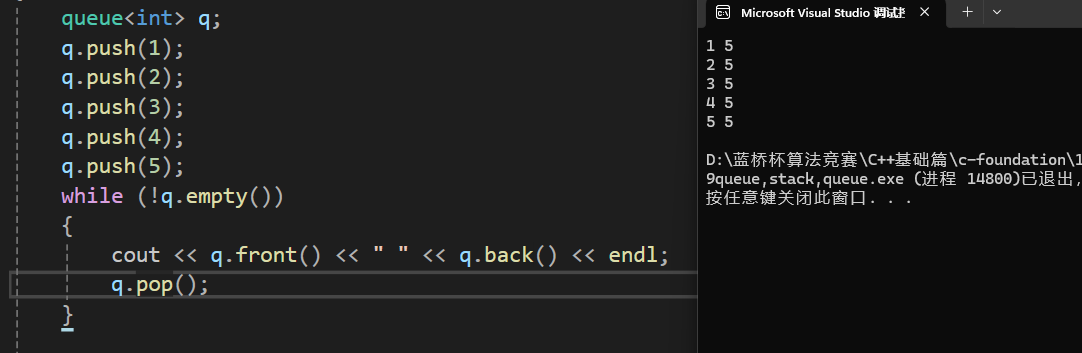
使用就很简单了。
队列和栈的模拟实现:
我们先来了解一下适配器:
适配器大家比较熟悉的就是电源适配器,我们的充电器。
queue和stack都是一种容器适配器。

我们用其他类来封装这两个容器。
我们回忆一下stack只需要在一方插入和删除,我们vector和list都能满足要求,所以我们来简单来实现一下。
#pragma once #include<vector> #include<list> #include<deque>namespace refrain {template<class T, class Container = std::deque<T>>class stack{public:T& top() {return _con.back();}const T& top() const{return _con.back();}void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}size_t size() const{return _con.size();}bool empty(){return _con.empty();}private:Container _con;}; }
deque:
这里的缺省值给的是deque双端队列,等会再来讲解。
再来回忆一下队列,它是先进先出,一端入数据一端出数据,我们就拿头部出数据,尾部入数据,简单实现如下:
#include<deque>
#include<iostream>
using namespace std;
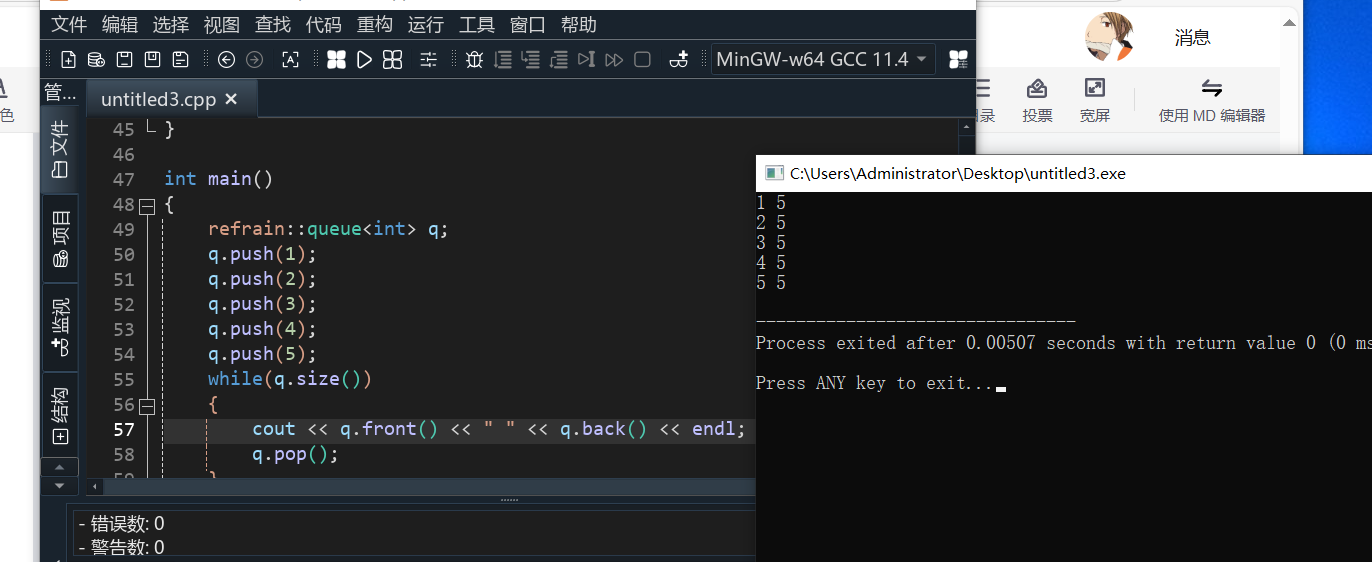
namespace refrain
{template<class T, class Container = std:: deque<T>>class queue{public:void push(const T& x){_con.push_back(x);}T& front(){return _con.front();}const T& front() const{return _con.front();}T& back(){return _con.back();}const T& back() const{return _con.back();}void pop(){_con.pop_front();}size_t size() const{return _con.size();}bool empty(){return _con.empty();}private:Container _con;};
}
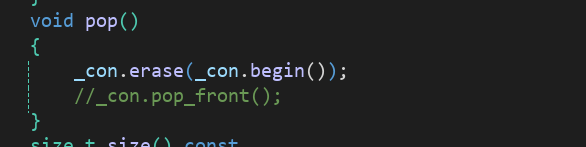
这里我们有个问题我们的vector不是没有pop_front吗,那我们是不是不能用vector来实现队列呢?的确库里面他就是用的pop_front,库里面不想你使用vector来实现,因为vector头部操作麻烦时间复杂度高,那我们能不能强制实现呢?我们可以使用erase来实现头部删除就可以用vector来实现queue了。
这是库里实现的:
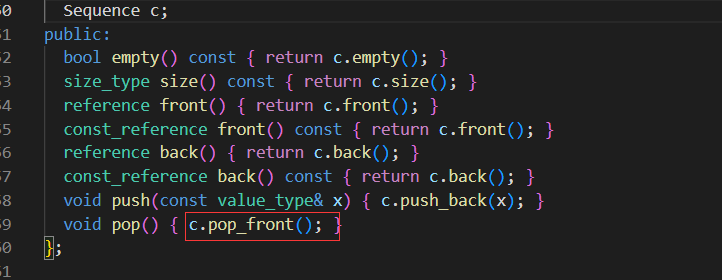
这样就适用了,但我们一般用deque这个更优秀
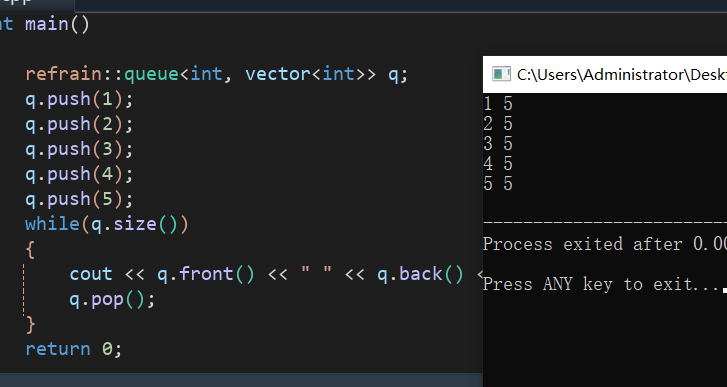
接下来就简单讲讲deque了:
先来对比一下list和vector的各自的优缺点:
而我们vector的优点就是list的缺点,vector的缺点就是list的优点。
| 优点: | 缺点 | |
| vector | 1.支持下标随机访问, 2.CPU高速缓存命中率高 | 1.头部或中间位置的插入删除操作效率低下,因为要挪动数据 2.扩容有一定的成本,存在一定的浪费。比如现在容量为100满了扩成200只插入了120空间浪费了80空间。 |
| list | 1.容易位置的插入和删除的时间复杂度都是O(1),不需要挪动数据。 2.不存在扩容,按需申请释放,不浪费空间。 | 1.不支持下标随机访问 2.CPU高速缓存命中率低 |
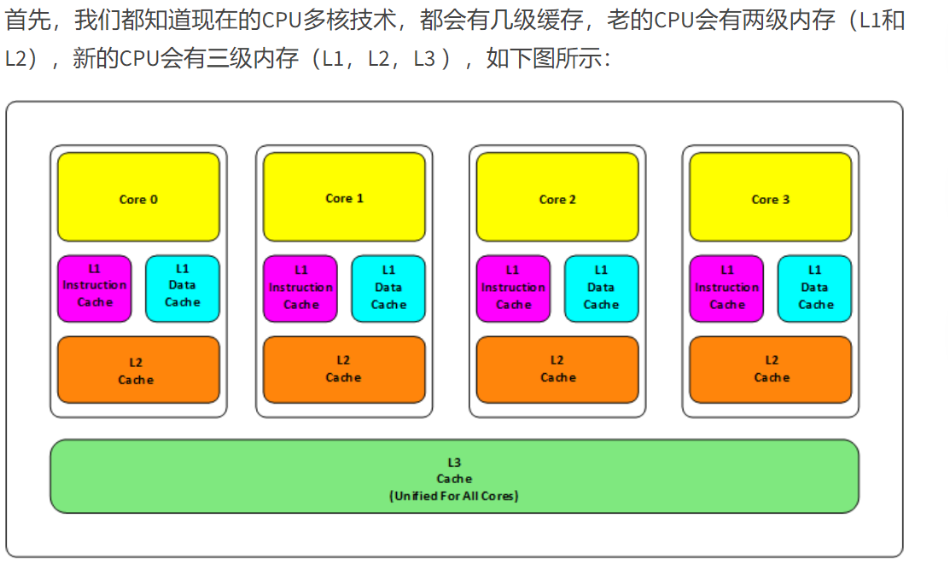
这里补充一个知识CPU高速缓存命中率的知识:
cpu想要访问内存的一个数据,要看这个数据是否在缓存,在就缓存命中,不在就不命中;不命中就先加载到缓存,然后再访问缓存。
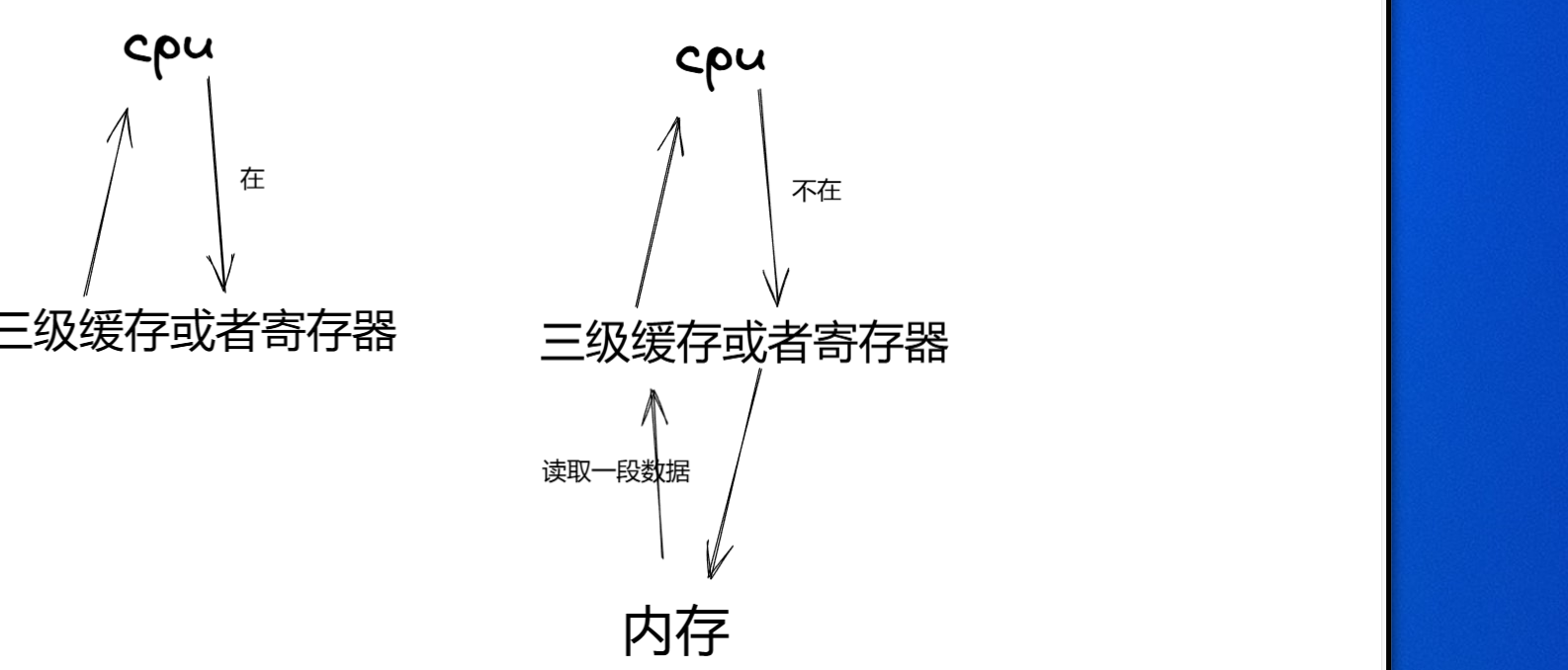
它加载到缓存不是只加载一个数据而是加载一个范围的数据,因为vector创建的是连续的空间,cpu的高高速缓存就高,而list每次都得先加载到缓存然后再访问缓存。
接下来就来简单了解一下deque的底层实现了。

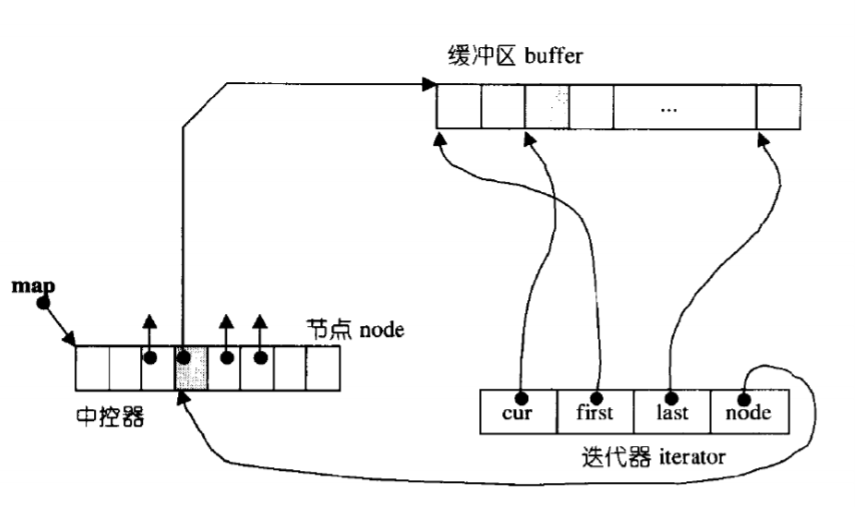
我们用四个指针封装deque的迭代器。

我们创建多个buff数组,用first指向buff的第一个位置,last指向最后一个位置。用cur指向当前位置。
再创建一个中控数组map,map里面存储着指向buff数组的指针,也就是二级指针。
这样设计有什么好处呢?
当我们迭代器++时
直接++cur,如果cur是最后一个的时候就移动node代码如下:
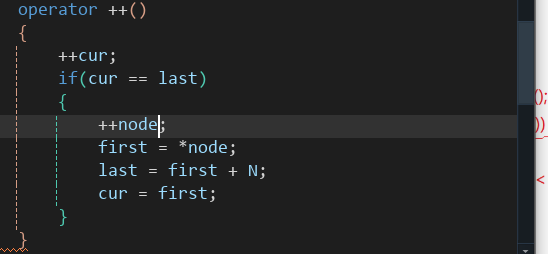
库里面是这样实现的:

逻辑是一样的,但它的细节 处理的更好。
减减也是相同的逻辑,就不实现了。
解引用操作就很简单了

直接解引用cur。
push_back:
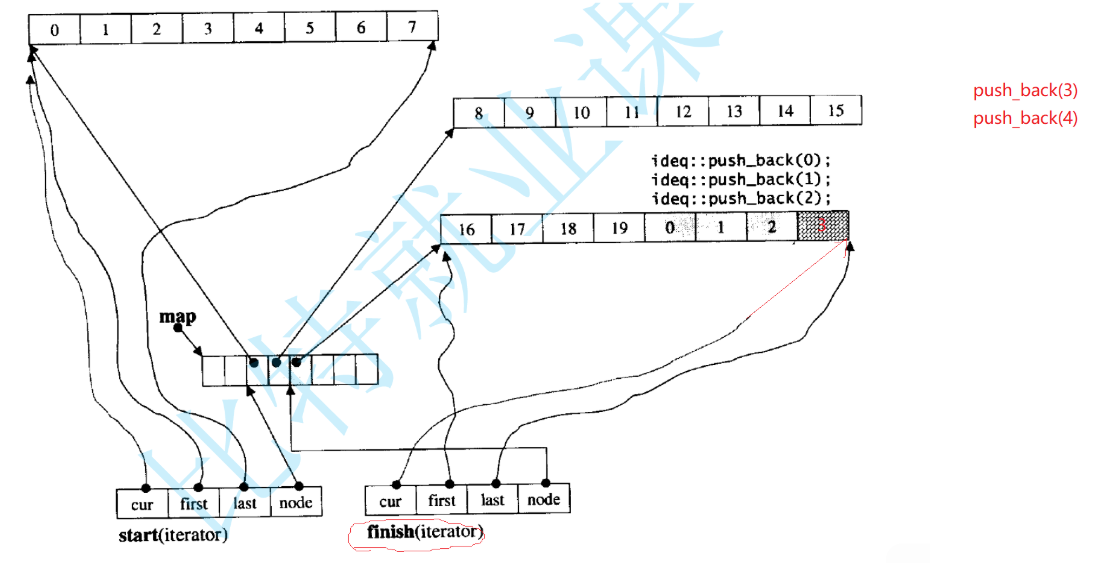
如果push_back时buff没有慢,就直接cur++,last++。
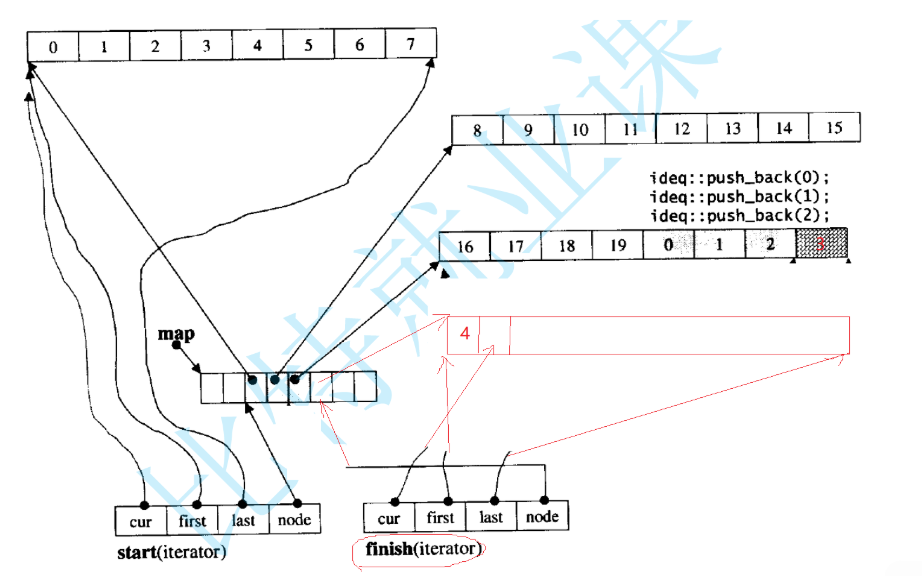
当buff已经满了,我们就得创建一个buff了,让node++,然后cur指向buff的第二个元素,last指向末尾,first指向第一个元素,如图。
再来看看push_front
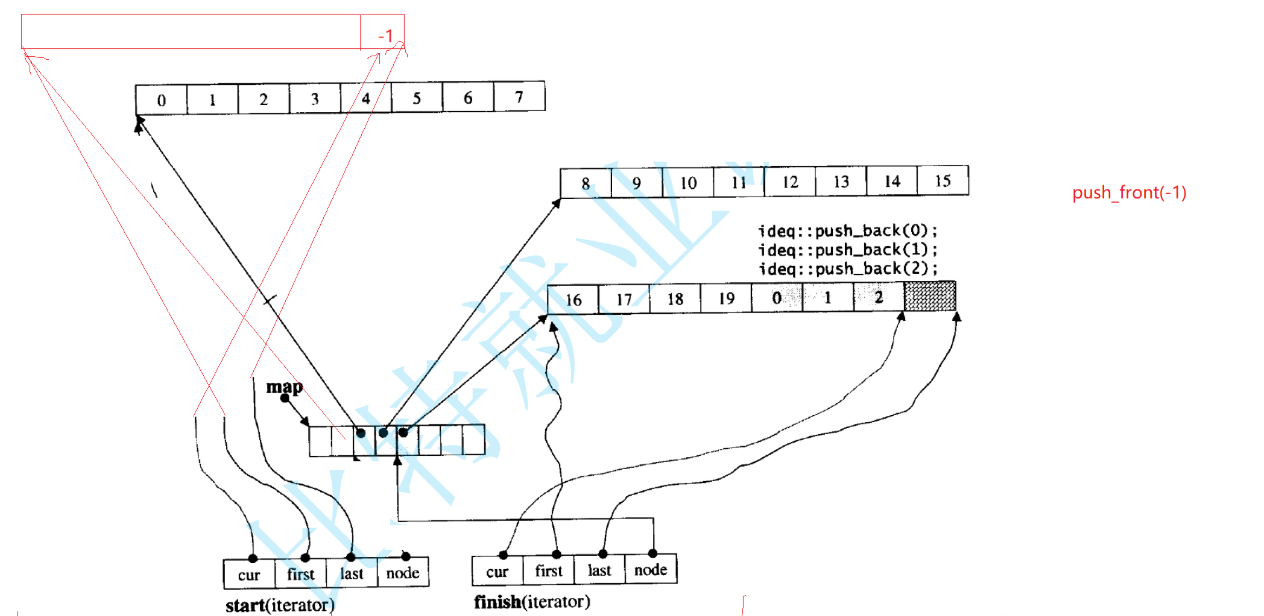
当buff满了,就创buff,此时我们cur不是指向第一个元素,指向的是最后一个元素,要保持连续性,node--,last,first指向尾和头。
再头插一个:
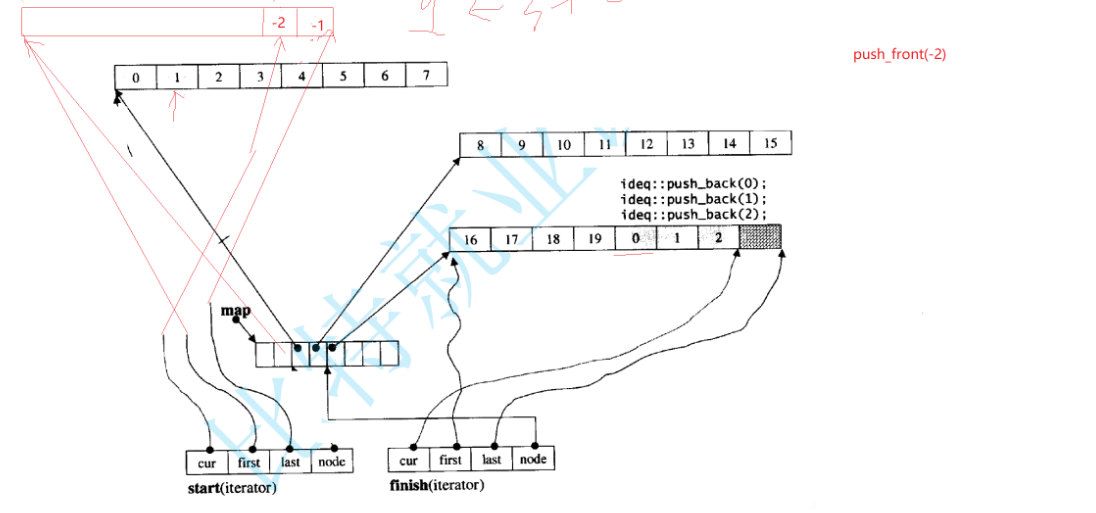
j就直接cur--就行了。
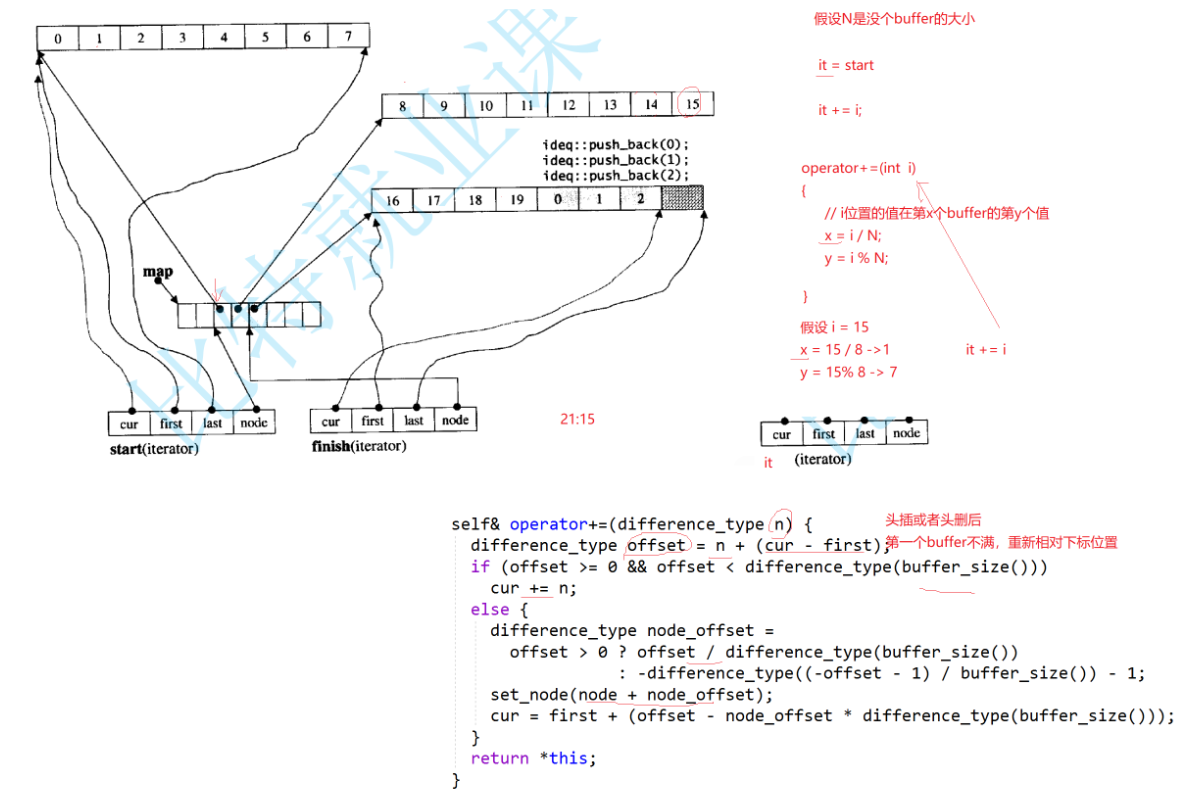
总结一下:
| 优点: 1.头尾部插入删除效率很高 2.下标随机访问效率还可以,但不如vector。 |
| 缺点: 1.中间位置插入和删除效率一般。 2.对比vector和list没有那么极致。(不专一) |
适合做stack和queue的适配器
priority_queue
优先级队列也不是队列是堆,堆之前我们用c语言就实现过,我们看看stl库里面怎样实现的。
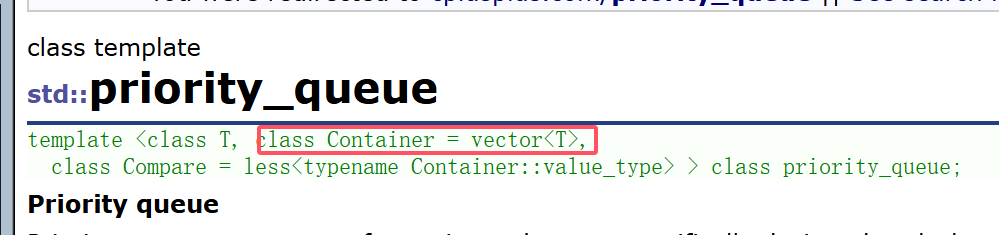
我们之前实现的堆,大家回忆一下,是不是用到了大量的下标访问 ,我们就可以使用vector来当容器适配器。
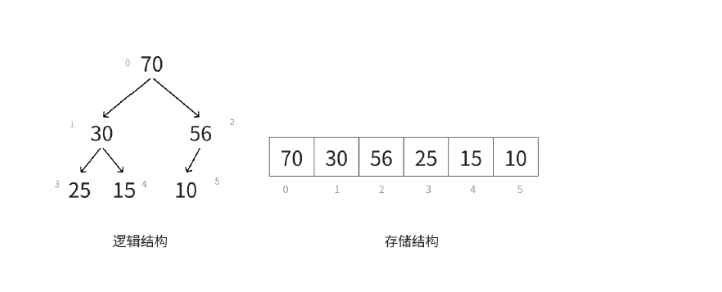
当我们插入一个数50的时候,这时候还是一个堆,就不进行操作
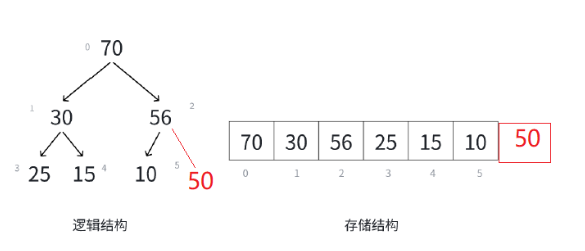
而当我们插入35的时候:我们要进行向上调整算法。
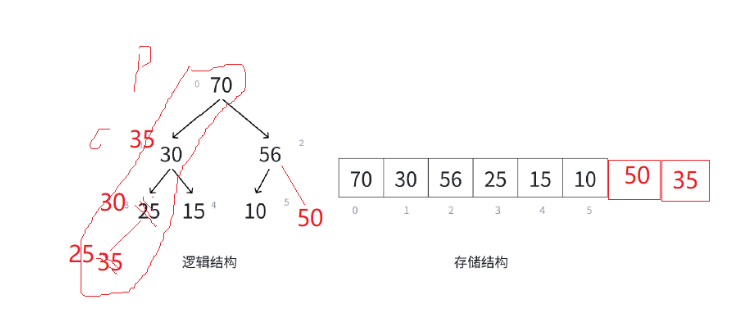
那我们回忆一下怎么找父亲节点呢?
parent = (child - 1)/ 2。
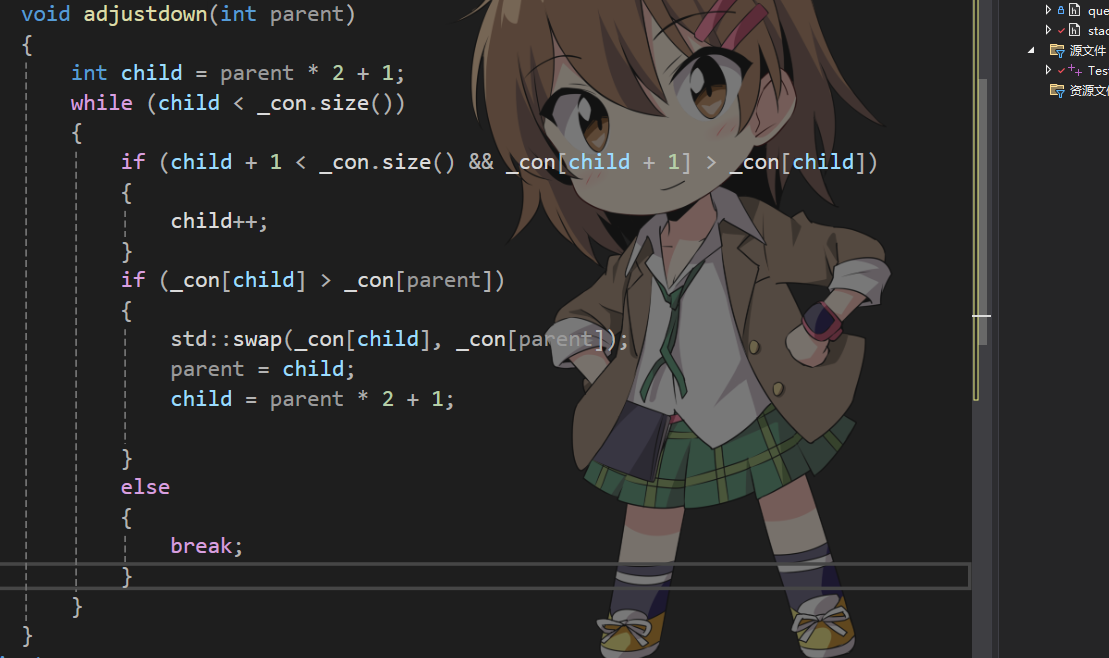
我们就写一个向下调整算法
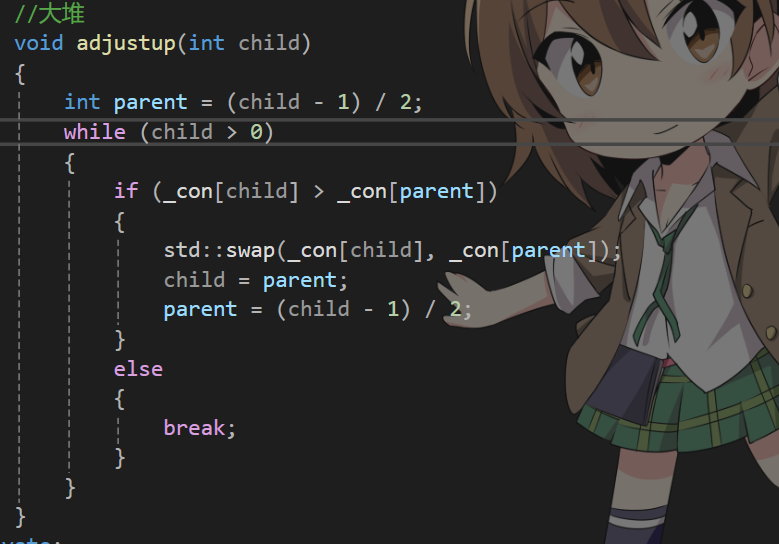
如果c语言实现的时候认真学习的应该没有什么问题。
同样的删除堆顶时我们交换堆顶和最后一个位置,然后尾删,进行向下调整算法
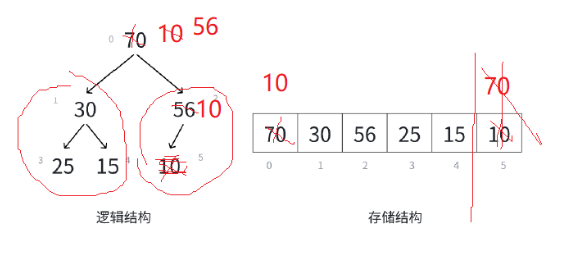
我们找左右孩子怎么找到呢?
左孩子: child = parent * 2 + 1
右孩子:child = parent* 2 + 2
一样实现的轻而易举:
 我们就来实现一下堆吧:
我们就来实现一下堆吧:
template<class T, class Container = std::vector<T>>
class priority_queue
{
public:void push(const T& x){_con.push_back(x);adjustup(_con.size() - 1);}void pop(){std::swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjustdown(0);}const T& top() const{return _con[0];}bool empty(){return _con.empty();}//大堆void adjustup(int child){int parent = (child - 1) / 2;while (child > 0){if (_con[child] > _con[parent]){std::swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}}void adjustdown(int parent){int child = parent * 2 + 1;while (child < _con.size()){if (child + 1 < _con.size() && _con[child + 1] > _con[child]){child++;}if (_con[child] > _con[parent]){std::swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}
private:Container _con;
};
这里的top就不能实现两个版本了,因为栈顶的元素不支持修改。

这里还缺少一个参数是什么呢,这里可以用仿函数来实现:
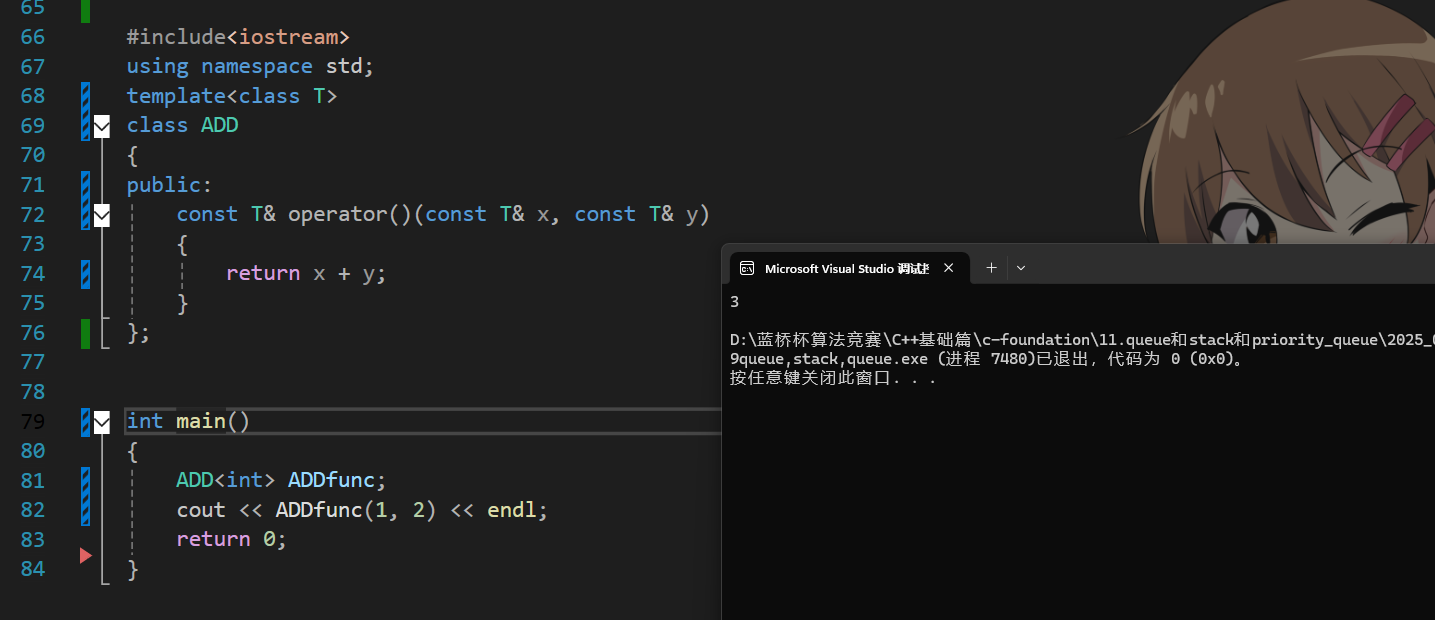
仿函数
我们可以通过重载( )括号运算符来实现仿函数:
我们可以利用这个特性来让我们选择能创的是大堆还是小堆,但我们这个有点坑,传less创建的是小堆,我们只好按它的来哦。
#pragma once
#include<vector>
#include<iostream>namespace refrain
{template<class T>class less{public:bool operator()(const T& x, const T& y){return x < y;}};template<class T>class greater{public:bool operator()(const T& x, const T& y){return x > y;}};template<class T, class Container = std::vector<T>, class Compare = less<T>>class priority_queue{public:Compare com;void push(const T& x){_con.push_back(x);adjustup(_con.size() - 1);}void pop(){std::swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjustdown(0);}const T& top() const{return _con[0];}bool empty(){return _con.empty();}//大堆void adjustup(int child){int parent = (child - 1) / 2;while (child > 0){if (com(_con[parent], _con[child])){std::swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}}void adjustdown(int parent){int child = parent * 2 + 1;while (child < _con.size()){if (child + 1 < _con.size() && com(_con[child], _con[child + 1])){child++;}if (com(_con[parent], _con[child])){std::swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}private:Container _con;};}完了over!