基于深度学习的智能交通流量监控与预测系统设计与实现
基于深度学习的智能交通流量监控与预测系统设计与实现
摘要
随着城市化进程的加速和机动车保有量的激增,交通拥堵、事故频发、环境污染等问题日益严峻,对传统的交通管理方式提出了巨大挑战。智能交通系统(ITS)作为解决这些问题的关键技术手段,受到了广泛关注。其中,准确、实时的交通流量信息是实现智能交通管理与控制的基础。传统的交通流量检测方法,如地埋式线圈、微波雷达等,存在安装维护困难、成本高昂、易受环境影响、检测信息有限等局限性。近年来,计算机视觉和深度学习技术的飞速发展,为交通监控领域带来了革命性的变革。基于视频的交通监控系统因其非接触式、覆盖范围广、信息丰富、成本相对较低等优势,展现出巨大的应用潜力。
本文旨在设计并实现一个基于深度学习的智能交通流量监控与预测系统。该系统利用先进的YOLOv8(You Only Look Once version 8)深度学习目标检测与跟踪算法,对交通视频或实时摄像头画面中的车辆进行精确检测、分类(区分小汽车、公交车、卡车等)和持续跟踪。通过分析车辆的运动轨迹,系统能够实现对车流量的实时统计、不同区域车辆分布的分析以及车辆平均速度的估算。系统特别设计了双测速线机制,通过计算车辆穿越两条虚拟标定线的时间差和预设的实际距离(或像素-实际距离比例),来估算单车的瞬时速度,并提供速度校准功能以提高准确性。
为了提供友好的用户交互体验和直观的数据展示,系统采用PyQt5构建了图形用户界面(GUI)。用户可以通过界面方便地选择视频文件或调用摄像头,配置检测参数(如置信度阈值、检测类别等),并实时查看原始视频画面、带有检测框和跟踪轨迹的分析画面以及车辆轨迹热力图。系统将统计分析结果,包括车辆类型分布、车流量(时间/区域)、车辆速度分布等,通过Matplotlib绘制的图表和数据表格实时呈现在界面上。此外,系统还集成了基于历史数据的简单交通流量预测功能,并在视频处理结束或摄像头停止后弹出预测对话框,为交通管理提供决策支持。用户还可以将统计数据导出为CSV文件,便于后续分析和报告。
本文详细阐述了系统的需求分析、可行性分析、总体架构设计、各功能模块的设计与实现细节,并展示了部分核心算法和代码实现。最后,对系统进行了功能和性能测试,验证了其在车辆检测、跟踪、计数、测速及数据可视化方面的有效性和实时性。该系统为实现智能化、精细化的交通管理提供了一种有效的技术方案。
关键词: 智能交通系统;深度学习;YOLOv8;目标检测;车辆跟踪;车流量统计;速度估计;交通预测;PyQt5
1. 引言
1.1 研究背景与意义
进入21世纪,全球范围内的城市化进程显著加速,机动车数量以前所未有的速度增长。这一方面极大地促进了社会经济的发展和人们出行的便利性,另一方面也带来了日益严峻的交通问题。交通拥堵已成为现代大中城市的普遍顽疾,不仅严重降低了道路通行效率,浪费了大量的社会时间和能源,还因车辆怠速和频繁启停加剧了空气污染和噪声污染,对城市环境和居民健康造成了负面影响。同时,复杂的交通状况也导致交通事故频发,给人民生命财产安全带来了巨大威胁。传统的交通管理模式,主要依赖于固定信号配时、人工现场疏导以及有限的检测设备(如地埋式线圈、雷达等),在应对动态、复杂、大规模的现代城市交通流时,显得力不从心,难以满足高效、安全、绿色的交通需求。
在此背景下,智能交通系统(Intelligent Transportation System, ITS)应运而生并迅速发展。ITS旨在通过先进的信息技术、通信技术、传感技术、控制技术和计算机技术,将人、车、路、环境有机地结合起来,形成一个实时、准确、高效的综合交通运输管理系统。其目标是提高交通系统的运行效率,保障交通安全,减少环境污染,提升出行体验。而获取准确、全面、实时的交通流参数信息,如车流量、车速、车辆类型、车道占有率、排队长度等,是实现ITS各项功能的基石,是进行交通状态分析、拥堵判别、信号优化控制、路径诱导、应急管理等决策的前提。
传统的交通流信息采集技术主要包括:
- 埋地式检测器: 如感应线圈、磁力计等。优点是技术成熟、精度较高。缺点是安装需要在路面开槽,破坏路面结构,施工期间影响交通;维护困难,一旦损坏修复成本高;只能检测固定断面的通过信息,无法获取车辆类型、轨迹等丰富信息。
- 路侧非接触式检测器: 如微波雷ダー、红外传感器、超声波传感器等。优点是安装相对方便,无需破坏路面。缺点是设备成本较高;易受恶劣天气(雨、雪、雾)或环境遮挡影响;检测精度和信息丰富度有限,例如微波雷达难以准确区分车辆类型。
- 人工观测: 成本高、效率低、主观性强、无法全天候工作,仅适用于小范围、短时间的特定调查。
随着视频监控技术在城市交通管理中的普及(“天网工程”等),利用遍布路口的监控摄像头获取交通信息成为一种极具吸引力的方案。基于计算机视觉的交通监控系统具有以下显著优势:
- 非接触式检测: 无需破坏路面,安装维护相对便捷。
- 覆盖范围广: 一个摄像头可以监控较长路段或整个交叉口。
- 信息丰富: 可以获取车辆的类型、颜色、轨迹、速度、加速度、车间距等多维度信息。
- 成本效益高: 可利用现有监控设备,硬件成本相对较低,软件算法的进步不断提升性价比。
- 可扩展性强: 易于与其他ITS子系统(如信号控制、信息发布)集成。
然而,基于传统计算机视觉算法(如背景减除、帧间差分、光流法、特征匹配等)的交通监控系统,在复杂场景下(如光照变化、阴影干扰、树木摇摆、车辆遮挡、拥堵粘连等)的鲁棒性和准确性仍面临挑战。近年来,以卷积神经网络(CNN)为代表的深度学习技术在图像识别、目标检测等领域取得了突破性进展,其强大的特征学习和表达能力为解决复杂场景下的交通视觉感知问题提供了全新的途径。特别是YOLO(You Only Look Once)、SSD(Single Shot MultiBox Detector)、Faster R-CNN等先进的目标检测算法,以及DeepSORT、BYTETrack、BoT-SORT等优秀的多目标跟踪算法的出现,使得高精度、实时的车辆检测与跟踪成为可能。
因此,将深度学习技术应用于视频交通监控,开发能够自动、准确、实时地提取交通流参数的智能系统,对于提升交通管理水平、缓解交通拥堵、保障交通安全具有重要的理论意义和巨大的实际应用价值。本项目正是基于这一背景,旨在利用前沿的深度学习目标检测与跟踪技术,结合GUI开发和数据可视化,构建一个功能完善、性能优良、界面友好的智能交通流量监控与预测系统。
1.2 国内外研究现状
基于视频的交通监控技术研究由来已久。早期研究主要集中在传统计算机视觉方法。例如,采用背景建模(如高斯混合模型 GMM)与前景分割相结合的方式检测运动车辆,通过卡尔曼滤波、粒子滤波或光流法进行跟踪,利用模板匹配或手工设计的特征(如HOG、SIFT)进行车辆分类。这些方法在简单场景下能取得一定效果,但在应对光照突变、阴影、雨雪天气、中远距离小目标、车辆局部或完全遮挡、密集车流导致的车辆粘连等复杂情况时,性能会急剧下降,难以满足实际应用需求。
随着深度学习的兴起,基于深度神经网络的目标检测与跟踪技术迅速成为研究热点,并在交通监控领域展现出巨大潜力。
- 车辆检测: 基于深度学习的目标检测算法大致可分为两类:两阶段(Two-Stage)算法和单阶段(One-Stage)算法。两阶段算法(如Faster R-CNN系列)先生成候选区域(Region Proposal),再对候选区域进行分类和位置回归,精度较高但速度相对较慢。单阶段算法(如YOLO系列、SSD)直接在图像上预测目标类别和边界框,速度快,更适合实时应用。YOLO算法自提出以来,经历了多次迭代(YOLOv1至YOLOv9,以及YOLOv5、YOLOX、YOLOv8等社区版本),在速度和精度上不断优化平衡。特别是YOLOv8,作为Ultralytics公司推出的最新版本之一,在精度、速度和易用性方面都表现出色,集成了目标检测、实例分割、姿态估计和目标跟踪等多种功能,成为当前目标检测领域的主流框架之一。国内外已有大量研究将YOLO系列算法应用于车辆检测,并针对交通场景的特点进行改进,如优化网络结构以检测小目标、融合注意力机制提高复杂背景下的检测能力、采用知识蒸馏压缩模型以适应边缘设备等。
- 车辆跟踪: 多目标跟踪(Multi-Object Tracking, MOT)旨在为视频序列中每个检测到的目标分配一个唯一的身份ID,并记录其运动轨迹。经典的跟踪范式是基于检测的跟踪(Tracking-by-Detection),即先利用目标检测器检测每一帧的车辆,然后通过数据关联算法将不同帧的检测框连接起来形成轨迹。数据关联是MOT的核心,常用方法包括基于运动模型的预测(如卡尔曼滤波)与外观特征匹配(如利用深度学习提取ReID特征)相结合。近年来,优秀的MOT算法层出不穷,如DeepSORT(结合卡尔曼滤波和深度关联度量)、SORT(简化版,仅用卡尔曼滤波和匈牙利算法进行关联)、JDE(将检测和外观特征提取统一到单个网络中)、FairMOT(平衡检测和ReID任务)、BYTETrack(利用低分检测框处理遮挡问题)、BoT-SORT(结合BYTETrack思想和卡尔曼滤波、相机运动补偿等)等。YOLOv8内部集成了多种跟踪器,包括BoT-SORT和BYTETrack,用户可以方便地调用这些先进的跟踪算法。
- 车流量统计与速度估计: 在实现准确检测和跟踪后,车流量统计通常通过设置虚拟检测线或检测区域,记录穿过该区域的车辆轨迹数量来实现。速度估计则有多种方法,包括基于单目视觉的几何约束方法(需要精确的相机标定和场景几何信息,实现复杂)、基于跟踪轨迹的方法(通过计算相邻帧目标中心点的位移和时间间隔来估计速度,简单易行但易受跟踪漂移影响)、基于双虚拟线圈的方法(模拟传统线圈,计算车辆穿越两条固定标定线的时间差来估计平均速度,是本项目采用的主要方法,需要进行像素距离到实际距离的标定)以及基于光流或特征点跟踪的方法等。
- 交通预测: 交通流量预测是ITS的重要组成部分,旨在根据历史数据预测未来的交通状况。传统方法包括时间序列模型(ARIMA、SARIMA)、卡尔曼滤波模型、支持向量回归(SVR)等。随着深度学习的发展,基于循环神经网络(RNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)以及图神经网络(GNN)的预测模型在捕捉交通流的时空复杂性方面表现出更优的性能。本项目实现了一个相对简单的预测功能,主要基于历史数据的统计特性(如平均值、趋势、时间模式)进行短期预测,作为一个辅助功能。
目前,国内外已有不少商业化或开源的基于深度学习的交通监控系统。例如,NVIDIA的Metropolis平台提供了用于构建智能视频分析应用的工具和预训练模型。一些研究机构和公司也推出了针对特定场景(如高速公路、城市交叉口)的解决方案。然而,开发一个集成度高、功能全面(涵盖检测、跟踪、计数、测速、分类、可视化、预测)、易于部署和使用、且可根据需求进行定制的开源系统仍然具有现实意义。本系统正是朝着这个方向努力,利用最新的YOLOv8框架,结合PyQt5和Matplotlib,构建了一个相对完整的解决方案原型。
1.3 本文主要工作
本文的主要工作围绕设计和实现一个基于深度学习的智能交通流量监控与预测系统展开,具体包括以下几个方面:
- 系统需求分析与技术选型: 深入分析了智能交通监控系统的实际应用需求,包括实时车辆检测、多目标跟踪、车流量统计、车辆分类、速度估计、数据可视化、用户交互、数据导出以及初步的流量预测等功能。基于需求分析,对关键技术进行了选型,确定采用YOLOv8作为核心的检测与跟踪算法,PyQt5作为GUI开发框架,Matplotlib作为数据可视化库。
- 系统整体设计: 设计了系统的总体架构,将系统划分为用户界面层、业务逻辑层和数据处理层。明确了各主要功能模块,包括视频/摄像头输入模块、模型加载与配置模块、检测与跟踪模块、数据处理与统计模块(计数、测速、分类、区域分析)、数据可视化模块(实时画面、图表、表格)、流量预测模块以及用户登录与权限管理模块(尽管代码中登录模块较独立,但在设计上考虑其集成)。绘制了系统架构图、用例图和关键流程(如帧处理)的序列图/泳道图。
- 核心功能实现:
- 检测与跟踪: 基于Ultralytics YOLOv8库,实现了加载预训练模型(
.pt或.onnx格式),对输入视频帧或摄像头帧进行目标检测和多目标跟踪。支持用户选择不同的YOLOv8权重文件和配置检测置信度阈值、选择特定检测类别(如仅检测车辆或检测所有类别)。 - 数据处理与统计: 实现了
process_results函数,用于解析模型输出,提取车辆的边界框、类别、ID和置信度。基于跟踪结果,实现了车辆计数(总数及按类型分)、轨迹记录(trk_history)、区域车辆分布统计(根据车辆Y坐标判断所属区域)。 - 速度估计: 设计并实现了基于双虚拟测速线的速度估计算法。在
calculate_speed_dual_line和compute_speed_between_lines函数中,通过判断车辆轨迹点穿越两条预设水平线的时间差,结合用户标定的像素-实际距离比例或线间实际距离,计算车辆的平均行驶速度(km/h)。提供了calibrate_speed校准功能,允许用户调整标定参数。 - 数据可视化: 利用PyQt5 QLabel实时显示原始视频帧和带有检测框、跟踪ID、速度信息、区域分割线、测速线的处理后视频帧。使用Matplotlib嵌入PyQt5界面(
MplCanvas),动态绘制多种统计图表,包括车辆类型分布柱状图、车流量(总数)时间变化折线图、车辆速度分布直方图、区域车辆数量分布柱状图。利用QTableWidget实时更新检测记录、速度记录、时间段统计和区域统计数据表格。实现了轨迹热力图的可视化,通过update_heatmap函数生成并显示。
- 检测与跟踪: 基于Ultralytics YOLOv8库,实现了加载预训练模型(
- 图形用户界面(GUI)设计与实现: 基于PyQt5框架,设计并实现了一个用户友好的图形界面。界面采用左右布局,左侧为控制面板(视频/摄像头选择、模型配置、参数调整、操作按钮)和统计图表区域(使用QTabWidget切换不同图表),右侧为视频显示区域(使用QTabWidget切换原始视频、检测结果、热力图)和数据表格区域(使用QTabWidget切换不同统计表格)。界面元素风格统一,交互逻辑清晰。实现了依赖库的自动检查与安装提示。
- 交通流量预测功能实现: 集成了简单的交通流量预测功能。
prepare_prediction_data函数负责整理历史检测数据(或生成模拟数据),show_traffic_prediction函数调用独立的traffic_prediction模块(假设存在TrafficPredictionDialog和TrafficPredictionModel类)来显示预测对话框和结果。预测逻辑基于历史数据的统计特性。 - 系统测试: 对系统的各项核心功能进行了测试,包括视频文件和摄像头的正常加载与处理、不同参数配置下的检测跟踪效果、计数和测速的准确性(需要与实际情况对比或使用标注数据)、数据可视化(图表、表格、热力图)的正确性和实时性、数据导出功能的验证以及预测功能的展示。评估了系统在不同负载下的性能表现(如帧率、资源占用)。
1.4 论文结构安排
本文的结构安排如下:
- 第一章:引言。 介绍研究背景、意义以及国内外相关领域的研究现状,明确本文的主要研究内容和工作,最后概述论文的整体结构。
- 第二章:相关技术介绍。 详细介绍本系统所依赖的关键技术,包括计算机视觉基础、深度学习与卷积神经网络、YOLOv8目标检测算法原理、多目标跟踪技术(BoT-SORT/BYTETrack)、PyQt5 GUI编程框架以及Matplotlib数据可视化库等。
- 第三章:系统分析。 对系统的功能性和非功能性需求进行详细分析,并从技术、经济、操作等方面进行可行性分析,为后续系统设计奠定基础。
- 第四章:系统设计。 阐述系统的总体架构设计,划分主要功能模块,设计模块间的交互关系。绘制系统架构图、用例图、关键流程时序图等。对核心数据结构和关键算法(如速度估计算法)进行设计说明。
- 第五章:系统实现。 结合代码,详细介绍系统各主要功能模块的具体实现过程,包括GUI界面实现、视频/摄像头处理流程、YOLOv8模型的调用、检测结果解析与处理、跟踪与轨迹生成、计数与测速逻辑、数据可视化(图表、表格、热力图)的实现细节、预测功能的集成等。展示关键代码片段并进行解释。
- 第六章:系统测试。 设计测试用例,对系统的各项功能(检测、跟踪、计数、测速、可视化、导出、预测等)进行测试,并对系统的性能(实时性、准确性、稳定性)进行评估。展示测试结果并进行分析。
- 第七章:结论。 总结全文工作,概括系统实现的功能和特点,分析系统的优势与存在的不足之处,并对未来可行的改进方向和研究前景进行展望。
2. 相关技术介绍
本系统的实现依赖于多项先进的计算机技术,本章将对其中的关键技术进行介绍,包括计算机视觉基础、深度学习与卷积神经网络、YOLOv8目标检测与跟踪算法、PyQt5图形用户界面框架以及Matplotlib数据可视化库。
2.1 计算机视觉基础
计算机视觉(Computer Vision)是一门研究如何使机器“看”的科学,更进一步地说,是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。它涉及图像处理、模式识别、人工智能等多个领域。
在交通监控领域,计算机视觉技术主要应用于以下几个方面:
- 图像获取: 通过摄像头(CCD或CMOS传感器)捕捉交通场景的视频或图像序列。图像质量(分辨率、帧率、清晰度、色彩)直接影响后续处理的效果。
- 图像预处理: 对原始图像进行一系列操作,以改善图像质量、消除噪声、增强特征,为后续分析做准备。常用操作包括灰度化、去噪(如高斯滤波、中值滤波)、直方图均衡化、图像增强、几何变换(如畸变校正、透视变换)等。本系统在处理流程中可能隐式包含某些预处理(例如OpenCV读取帧、YOLO模型内部的预处理),但代码层面未显式进行复杂的预处理步骤。
- 目标检测: 在图像或视频帧中定位感兴趣目标(如车辆、行人、交通标志)的位置,并通常给出目标的边界框(Bounding Box)。这是交通监控的核心任务之一。传统方法有基于滑动窗口和特征描述子(如Haar、HOG、LBP)结合分类器(如Adaboost、SVM)的方法,以及基于背景减除或帧间差分的方法。深度学习方法,特别是基于CNN的目标检测器,已成为当前主流。
- 目标跟踪: 在视频序列中,对检测到的目标进行身份关联,即确定同一目标在不同帧之间的对应关系,并记录其运动轨迹。这对于计算目标的运动参数(如速度、加速度)、行为分析(如变道、停留)以及避免重复计数至关重要。
- 目标识别/分类: 确定检测到的目标的具体类别。例如,将车辆进一步区分为小汽车、卡车、公交车、摩托车等。深度学习分类网络(如ResNet、VGG)或目标检测模型本身(如YOLO)通常能直接输出类别信息。
- 场景理解与分析: 在检测、跟踪、分类的基础上,对交通场景进行更高层次的理解和分析,例如车流量统计、平均速度计算、车道占有率估计、拥堵判断、事故检测、交通违规行为识别(如闯红灯、违停、逆行)等。
本系统主要利用了计算机视觉中的图像获取、目标检测、目标跟踪、目标分类以及基于这些结果的场景分析(计数、测速、区域分析)等技术。
2.2 深度学习与卷积神经网络
深度学习(Deep Learning)是机器学习的一个分支,其灵感来源于人脑的结构和功能,特别是神经网络。深度学习模型通常包含多个处理层(因此称为“深度”),能够自动从原始数据中学习复杂的模式和高层抽象特征。
卷积神经网络(Convolutional Neural Network, CNN)是深度学习领域中最具代表性的模型之一,特别适用于处理具有网格结构的数据,如图像。CNN的成功主要归功于其两个关键特性:局部连接(Local Connectivity)和权值共享(Weight Sharing)。
- 局部连接: CNN中的神经元只与前一层的一个小区域(感受野)内的神经元相连,而不是全连接。这符合图像处理中空间局部相关的特性,即一个像素与其邻近像素的关系更密切。
- 权值共享: 在同一特征图(Feature Map)内,卷积核(Filter)的权值是共享的。这意味着同一个卷积核会滑过整个输入图像(或特征图),检测同一类型的局部特征,无论该特征出现在图像的哪个位置。这大大减少了模型的参数数量,提高了训练效率,并使模型具有一定的平移不变性。
一个典型的CNN通常由以下几种层构成:
- 卷积层(Convolutional Layer): 核心层,通过卷积核对输入数据进行卷积运算,提取局部特征。每个卷积核学习一种特定的特征(如边缘、角点、纹理)。
- 激活层(Activation Layer): 对卷积层的输出应用非线性激活函数(如ReLU、Sigmoid、Tanh),引入非线性,使网络能够学习更复杂的模式。ReLU(Rectified Linear Unit)因其计算简单、能有效缓解梯度消失问题而被广泛使用。
- 池化层(Pooling Layer): 也称下采样层,对特征图进行降维操作,减少计算量,提高模型的鲁棒性(对微小位移、形变不敏感)。常用的池化操作有最大池化(Max Pooling)和平均池化(Average Pooling)。
- 全连接层(Fully Connected Layer): 通常位于网络的末端,将前面提取到的分布式特征进行整合,用于最终的分类或回归任务。
通过堆叠这些层,CNN能够从图像的底层像素学习到边缘、纹理等低级特征,再逐层组合形成更复杂、更抽象的高级特征(如物体的部件、甚至整个物体),最终实现高精度的图像识别、目标检测等任务。本系统使用的YOLOv8算法便是基于深度卷积神经网络构建的。
2.3 YOLOv8目标检测与跟踪算法
YOLO(You Only Look Once)是一种著名的单阶段(One-Stage)实时目标检测算法。与两阶段算法(如Faster R-CNN)先生成候选区域再分类不同,YOLO将目标检测视为一个回归问题,直接在整个图像上预测边界框和类别概率。这使得YOLO系列算法以其卓越的速度而闻名,非常适合需要实时处理的应用场景,如交通监控。
YOLOv8是YOLO系列的最新迭代之一(由Ultralytics公司维护,与YOLO原作者的官方版本有所区别,但广受欢迎)。它在前代YOLO算法(特别是YOLOv5)的基础上进行了诸多改进,实现了在速度和精度上的进一步提升和更好的平衡。YOLOv8的主要特点和改进包括:
- Backbone网络: 采用了更优化的骨干网络结构(可能借鉴了CSPDarknet或更现代的设计),提升了特征提取能力。
- Neck部分: 对特征金字塔网络(FPN)和路径聚合网络(PAN)等结构进行了优化,加强了不同尺度特征的融合。
- Head部分: 采用了Anchor-Free的设计,即不再依赖预设的锚框(Anchor Boxes),而是直接预测目标的中心点以及边界框的宽度和高度,简化了训练过程,并可能提高对不同形状目标的适应性。同时,使用了Decoupled Head,将分类和定位任务解耦,分别进行预测,有助于提升性能。
- 损失函数: 可能采用了Task Aligned Assigner进行标签分配,并结合了如Distribution Focal Loss (DFL) 等更先进的损失函数来优化训练。
- 多功能集成: YOLOv8不仅支持目标检测,还集成了实例分割、姿态估计和目标跟踪等功能,提供了一个更全面的视觉感知框架。
- 易用性: Ultralytics提供了简洁易用的Python库和命令行接口,方便用户进行训练、验证、推理和导出模型。
在本系统中,我们利用YOLOv8实现车辆的检测和跟踪。其跟踪功能通常是基于“检测后跟踪”(Tracking-by-Detection)的范式。YOLOv8库集成了现成的跟踪算法,如:
- BoT-SORT (Bag of Tricks for SORT): 是对经典跟踪算法SORT(Simple Online and Realtime Tracking)的改进。SORT主要依赖卡尔曼滤波进行运动状态预测,并使用匈牙利算法进行数据关联(基于IoU匹配)。BoT-SORT在此基础上,融合了更多技巧,如相机运动补偿(CMC)、更精确的卡尔曼滤波状态向量、更好的关联策略(结合ReID特征,尽管YOLOv8提供的版本可能侧重运动),以及借鉴BYTETrack处理低分检测框等,提升了跟踪的鲁棒性和准确性,尤其是在遮挡和目标交互场景下。
- BYTETrack: 该算法的核心思想是区分高分和低分检测框。高分检测框被认为是可靠的,优先与轨迹进行匹配。对于未匹配的轨迹,再尝试与低分检测框进行匹配(主要基于IoU),以找回那些因遮挡等原因导致置信度下降的目标。对于未匹配的高分检测框,则认为是新出现的目标,为其创建新轨迹。这种策略有效减少了因阈值过滤掉低分框而导致的漏检和轨迹中断问题。
系统通过调用model.track()方法,传入视频帧和配置参数(如置信度conf、检测类别classes、是否持久化跟踪状态persist),即可获得带有目标ID的检测结果。persist=True参数对于视频或摄像头流的连续跟踪至关重要,它使得跟踪器能够维持跨帧的目标状态。系统随后解析这些结果,提取每个目标的ID、类别、边界框等信息,用于后续的计数、测速和可视化。
2.4 PyQt5图形用户界面框架
为了提供用户友好的交互方式,本系统采用PyQt5构建图形用户界面(GUI)。PyQt5是著名的跨平台C++ GUI库Qt的Python绑定之一。它允许开发者使用Python语言创建功能丰富、外观专业的桌面应用程序。
PyQt5的主要特点包括:
- 丰富的控件集: 提供了大量的预制控件(Widgets),如按钮(QPushButton)、标签(QLabel)、文本框(QLineEdit)、下拉框(QComboBox)、滑块(QSlider)、表格(QTableWidget)、选项卡(QTabWidget)、菜单栏、工具栏等,可以满足各种界面设计需求。本系统广泛使用了QLabel显示视频和图表标题,QPushButton用于用户操作,QComboBox用于选择模型和参数,QSlider调节置信度,QTableWidget展示统计数据,QTabWidget组织不同视图(视频/图表/表格)等。
- 信号与槽机制(Signals and Slots): 这是Qt的核心机制,用于实现对象间的通信。当某个事件发生时(如按钮被点击),一个对象会发射(emit)一个信号,而对该事件感兴趣的另一个对象(或自身)的槽函数(slot)会被调用。这种机制使得代码解耦,易于维护和扩展。例如,本系统中
select_video_btn.clicked.connect(self.select_video)就是将按钮的clicked信号连接到select_video槽函数。 - 布局管理器(Layout Managers): PyQt5提供了强大的布局管理器(如QHBoxLayout、QVBoxLayout、QGridLayout、QFormLayout),可以自动调整控件的大小和位置,使得界面在不同屏幕尺寸和分辨率下都能保持良好的外观,无需手动计算坐标。本系统使用了QHBoxLayout(水平布局)、QVBoxLayout(垂直布局)和QGridLayout(网格布局)来组织界面元素。
- 绘图系统(Paint System): 提供了强大的2D绘图功能,可以在控件上绘制图形、文本和图像。结合QPixmap和QImage类,可以方便地加载和显示图像。本系统利用QLabel和QPixmap来显示视频帧。
- 跨平台性: 基于Qt框架,PyQt5应用程序可以轻松地在Windows、macOS、Linux等主流操作系统上运行,只需少量甚至无需修改代码。
- 与Matplotlib集成: 可以方便地将Matplotlib绘制的图表嵌入到PyQt5应用程序中,实现动态的数据可视化。本系统通过创建
MplCanvas类(继承自FigureCanvasQTAgg)将Matplotlib的Figure和Axes嵌入到QWidget中。
通过使用PyQt5,本系统构建了一个结构清晰、交互便捷、信息展示直观的用户界面,大大提升了系统的可用性。
2.5 Matplotlib数据可视化库
数据可视化是理解和传达信息的重要手段。Matplotlib是Python中最流行、最基础的数据可视化库之一,它提供了一个类似MATLAB的绘图接口,可以创建各种静态、动态、交互式的图表。
Matplotlib的主要特点:
- 支持多种图表类型: 可以绘制线图、散点图、柱状图、直方图、饼图、箱线图、热力图等多种常见的统计图表。本系统主要使用了柱状图(车辆类型分布、区域分布)、折线图(车流量时间变化)和直方图(速度分布)。
- 高度可定制性: 允许用户对图表的几乎所有元素进行精细控制,包括坐标轴、标签、标题、图例、颜色、线型、标记样式等。支持使用LaTeX进行公式排版。本系统在绘制图表时设置了标题、坐标轴标签,并尝试设置中文字体以获得更好的显示效果。
- 面向对象的API: 除了提供便捷的
pyplot接口外,还提供了更灵活的面向对象的API,允许用户直接操作Figure(图形)、Axes(坐标系)、Axis(坐标轴)等对象,实现更复杂的绘图需求。本系统通过创建MplCanvas实例,直接访问其axes对象进行绘图操作。 - 与其他库的集成: 可以很好地与NumPy、Pandas等数据处理库结合使用。同时,可以嵌入到多种GUI框架中,如PyQt、Tkinter、wxPython等。本系统正是将其嵌入到了PyQt5界面中。
- 支持多种输出格式: 可以将图表保存为多种格式的图片文件(如PNG, JPG, PDF, SVG)。
在本系统中,Matplotlib承担了将处理后的交通统计数据(车辆类型数量、车流量随时间变化、速度分布数据、区域车辆数量)转化为直观图表的任务。通过MplCanvas类,将Matplotlib的FigureCanvas嵌入到PyQt5的QWidget中,利用QTimer定期调用update_charts方法,实现了统计图表的动态更新,为用户提供了实时的交通态势感知。系统还特别处理了中文字体显示问题,尝试加载系统或内置字体,以确保图表标签的可读性。
3. 系统分析
系统分析是软件开发过程中的重要阶段,其主要任务是明确系统的目标、功能需求、性能需求以及约束条件,并评估实现这些需求的可行性。本章将对基于深度学习的智能交通流量监控与预测系统进行详细的需求分析和可行性分析。
3.1 需求分析
需求分析旨在全面理解用户(或应用场景)对系统的期望和要求,并将这些要求转化为清晰、具体、可度量的功能性和非功能性需求描述。
3.1.1 功能需求分析
功能需求定义了系统应该做什么,即系统需要提供哪些具体的功能来满足用户的核心需求。结合代码实现和应用场景,本系统的主要功能需求如下:
-
数据输入与管理:
- 视频文件输入: 系统应支持用户选择本地存储的视频文件(如MP4, AVI, MOV等常见格式)作为分析源。界面需显示当前选择的文件名。
- 实时摄像头输入: 系统应能检测并列出可用的本地摄像头设备,允许用户选择其中一个作为实时视频流输入源。
- 模型选择与加载: 系统应允许用户选择用于车辆检测与跟踪的深度学习模型文件(如YOLOv8的
.pt或.onnx格式)。系统需能正确加载所选模型,并提示模型加载状态(如使用CPU或GPU)。 - 参数配置: 用户应能配置关键的检测参数,至少包括:
- 目标检测置信度阈值: 允许用户通过滑块或输入框调整,以过滤掉低置信度的检测结果,平衡召回率和精确率。界面需实时显示当前阈值。
- 检测类别选择: 提供选项允许用户选择是仅检测特定类别的车辆(如小汽车、公交车、卡车),还是检测模型支持的所有类别。
- 依赖检查与安装: 系统启动时应自动检查必要的第三方库(如
ultralytics,lap)是否存在,若不存在,应提示用户并尝试自动安装(或给出手动安装指引),确保系统运行环境完整。
-
车辆检测与跟踪:
- 实时车辆检测: 系统需利用加载的YOLOv8模型,对输入的视频帧(来自文件或摄像头)进行实时目标检测,准确识别画面中的车辆目标。
- 车辆分类: 检测的同时,系统需要区分车辆的具体类型(至少应能识别代码中明确处理的’car’, ‘bus’, 'truck’等常见类别)。
- 多目标跟踪: 对检测到的车辆进行实时跟踪,为每个进入画面的车辆分配一个唯一的ID,并在其消失前保持该ID的连续性。系统需记录车辆的运动轨迹(一系列中心点坐标)。
-
交通参数提取与统计:
- 车流量统计:
- 实时计数: 实时统计当前画面中检测到的各类车辆的数量。
- 累计计数/历史记录: 统计一段时间内(如视频处理期间或摄像头开启期间)通过关键区域或整个画面的车辆总数及分类型数量(代码中通过
count_set和label_dict实现,但可能需要更明确的通过逻辑)。【注:当前代码似乎是统计当前帧或近期活跃ID,严格的“通过”计数可能需要虚拟线圈逻辑的加强】 - 时间段统计: 按一定时间间隔(如每小时)统计车流量和平均速度,并以表格形式展示。
- 速度估计:
- 基于双测速线: 允许用户(或系统默认)在画面上设定两条虚拟测速线。当车辆轨迹先后穿过两条线时,系统根据时间差和标定距离计算车辆的平均速度(km/h)。
- 速度校准: 提供界面允许用户输入两条测速线之间的实际物理距离(米)或直接设定像素到实际距离的比例因子(米/像素),以提高速度估计的准确性。
- 速度记录: 记录测速结果,包括车辆ID、类型、测速时间、速度值、行驶方向(可选)等,并在表格中实时显示。
- 区域分析:
- 区域划分: 将监控画面划分为若干个逻辑区域(如上、中、下区域,或左、中、右车道)。
- 区域车辆统计: 实时统计每个区域内当前的车辆数量。
- 区域平均速度: 计算每个区域内车辆的平均速度(基于在该区域内完成测速的车辆)。
- 区域统计展示: 以图表和表格形式展示各区域的车辆数量和平均速度。
- 车流量统计:
-
数据可视化与用户交互:
- 实时视频显示:
- 原始画面: 在界面上清晰、流畅地显示输入的原始视频或摄像头画面。
- 检测结果画面: 在另一区域(或选项卡)实时显示处理后的画面,需叠加绘制车辆的检测框、类别标签、跟踪ID以及估算的速度信息。同时显示区域分割线和测速线。
- 轨迹热力图: 生成并显示车辆轨迹的热力图,直观反映车辆的主要行驶路径和密度分布区域。
- 统计图表展示:
- 动态更新: 使用Matplotlib绘制的图表需嵌入GUI界面,并能根据实时统计数据动态更新。
- 图表类型: 至少包括车辆类型分布图(如柱状图)、车流量时间变化图(如折线图)、车辆速度分布图(如直方图)、区域车辆数量分布图(如柱状图)。
- 可读性: 图表应包含清晰的标题、坐标轴标签和数值标签,并正确处理中文字符显示。
- 数据表格展示:
- 实时更新: 使用QTableWidget实时展示详细的统计数据。
- 表格类型: 至少包括检测记录表(当前帧各类型车辆数及占比)、速度记录表(记录单车测速结果)、时间段统计表、区域统计表。
- 清晰易读: 表格应有清晰的表头,数据格式规范。
- 用户操作控制:
- 开始/暂停: 提供按钮允许用户开始和暂停视频文件或摄像头画面的处理与分析过程。
- 导出数据: 提供按钮允许用户将统计结果(如车辆类型统计、时间段统计、区域统计、速度记录等)导出为CSV或其他格式的文件,以便离线分析。
- 速度校准: 提供按钮触发速度校准对话框。
- 摄像头控制: 提供启动/停止摄像头的按钮。
- 状态反馈: 系统应在界面上提供清晰的状态反馈,如当前处理的文件/摄像头、模型加载状态、检测是否正在运行、处理进度(如视频播放进度)、错误提示等。
- 实时视频显示:
-
交通流量预测:
- 触发机制: 在视频处理完成或停止摄像头检测后,自动触发预测功能。
- 数据准备: 系统需能整理分析过程中收集到的历史交通数据(如车流量时间序列、车型比例等),或在数据不足时生成模拟数据。
- 预测模型调用: 调用预测模型(基于历史统计或更复杂的模型)对未来一段时间(如未来1小时)的交通流量进行预测。
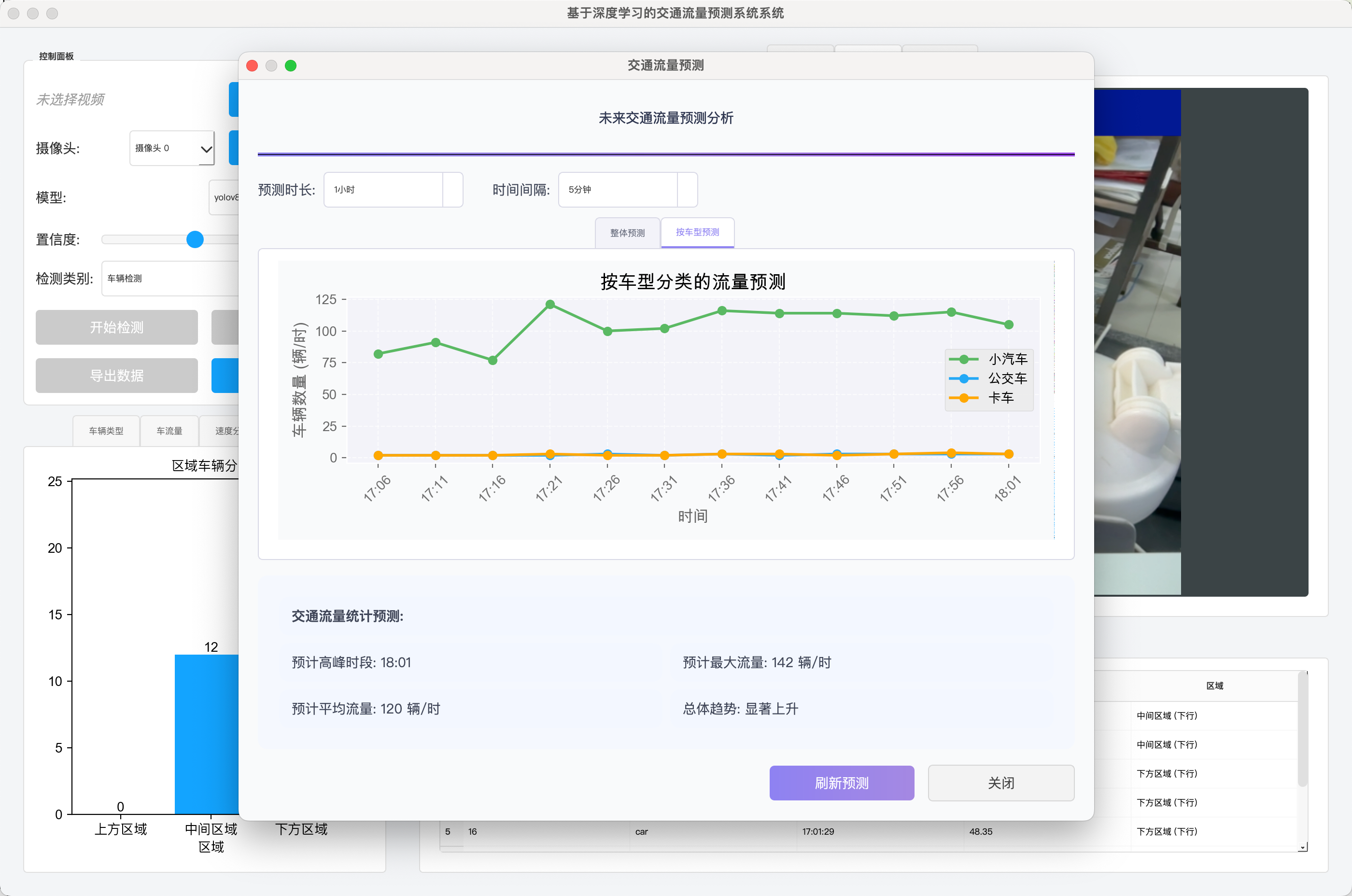
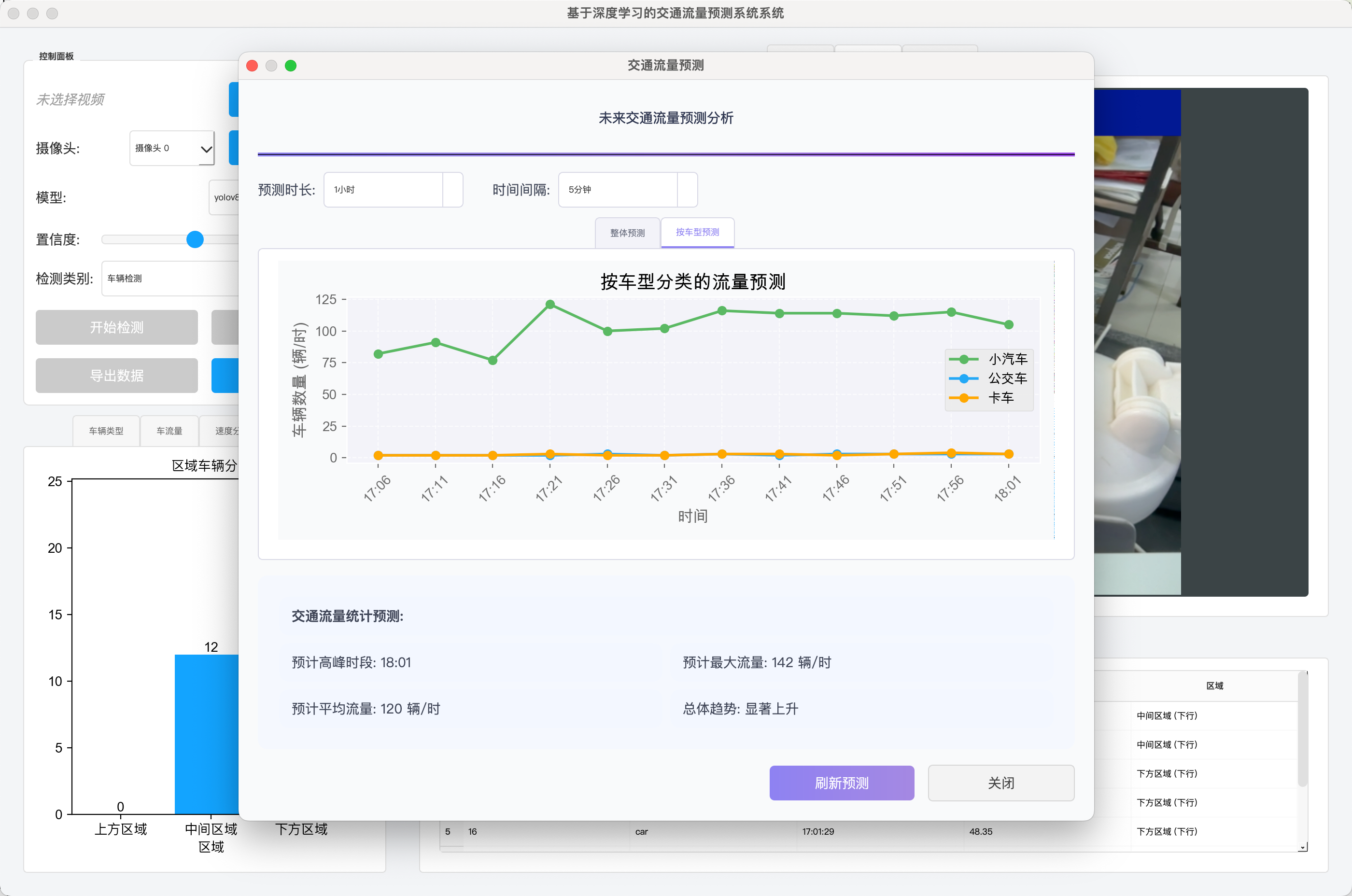
- 预测结果展示: 通过专门的对话框,以图表(如预测流量曲线)和统计摘要(如预计高峰时段、峰值流量、平均流量、总体趋势)的形式展示预测结果。支持按整体流量和按车型分类进行预测展示。允许用户调整预测的时间范围和间隔。
-
用户登录(辅助功能):
- 登录验证: 系统启动时显示登录界面,要求用户输入用户名和密码进行验证。只有验证通过后才能进入主程序界面。(此功能在
if __name__ == "__main__":部分实现)
- 登录验证: 系统启动时显示登录界面,要求用户输入用户名和密码进行验证。只有验证通过后才能进入主程序界面。(此功能在
3.1.2 非功能需求分析
非功能性需求定义了系统的质量属性和运行约束,描述了系统应该如何工作。
-
性能需求:
- 实时性: 对于实时摄像头输入,系统应能尽可能快地处理每一帧,保证视频画面显示的流畅性(目标帧率,例如>10 FPS,具体取决于硬件配置和处理复杂度),检测、跟踪和统计结果的更新延迟应尽可能小。对于视频文件处理,应在合理时间内完成。代码中通过降低处理频率(如每隔几帧检测、更新显示/图表/统计)来平衡性能和实时性。
- 准确性: 车辆检测、分类和跟踪的准确率应达到较高水平,能适应一定的光照变化和遮挡情况。车流量计数和速度估计的误差应在可接受范围内(速度估计精度依赖于准确的标定)。
- 资源占用: 系统运行时对CPU、内存、GPU(如果使用)的占用应在合理范围内,避免过度消耗导致系统卡顿或影响其他应用。
-
易用性需求:
- 界面友好: GUI界面应布局合理、元素清晰、风格统一、操作直观简单,符合用户使用习惯。
- 状态明确: 系统运行状态、处理进度、参数设置等信息应清晰可见。
- 反馈及时: 对用户的操作(如按钮点击、参数修改)应有及时的响应和反馈。错误信息应明确易懂。
- 中文化: 界面元素、图表标签、提示信息等应支持中文显示。
-
可靠性与稳定性需求:
- 稳定性: 系统应能长时间稳定运行,不易崩溃。
- 鲁棒性: 对异常情况(如无法打开视频文件、摄像头连接失败、模型加载错误、数据格式异常等)应具有一定的处理能力,能给出错误提示而不是直接崩溃。代码中包含了大量的
try-except块来捕获和处理潜在异常。 - 数据一致性: 各可视化组件(视频画面、图表、表格)显示的数据应与内部处理结果保持一致。
-
可维护性与可扩展性需求:
- 代码规范: 代码结构应清晰,遵循一定的编码规范(如PEP 8),添加必要的注释,便于理解和维护。
- 模块化: 系统功能应尽可能模块化设计,降低耦合度,便于未来修改或添加新功能(如更换检测/跟踪算法、增加新的统计维度、集成更复杂的预测模型)。代码中通过类(
DetectorGUI,MplCanvas,CameraThread等)和函数实现了基本的模块化。 - 可配置性: 关键参数(如模型路径、置信度阈值、测速线位置、标定系数等)应易于配置。
-
部署需求:
- 环境依赖: 明确系统运行所需的软硬件环境和依赖库,提供安装说明或自动安装机制。
- 跨平台: 基于PyQt5和Python,系统应具备在主流操作系统(Windows, macOS, Linux)上运行的潜力。
3.2 可行性分析
可行性分析旨在评估系统需求在现有条件下是否能够实现,主要从技术、经济和操作三个方面进行考量。
3.2.1 技术可行性
- 核心算法的可获得性与成熟度: 本系统依赖的核心技术是YOLOv8目标检测与跟踪算法。YOLOv8是当前业界领先的实时目标检测框架之一,由Ultralytics公司维护并开源,提供了预训练好的模型(在COCO等大型数据集上训练,包含了常见的车辆类别),以及易于使用的Python接口。其集成的BoT-SORT和BYTETrack也是当前性能优异的多目标跟踪算法。这表明核心的检测与跟踪技术是现成可用且技术成熟度高的。
- 开发工具与库的可用性: 系统采用Python作为主要开发语言,这是一个拥有庞大生态系统和活跃社区的流行语言。GUI开发选用PyQt5,是一个成熟、功能强大且跨平台的框架。数据处理和科学计算依赖NumPy。数据可视化采用Matplotlib,是Python标准的可视化库。图像处理使用OpenCV,是计算机视觉领域的事实标准库。这些库都是开源免费的,拥有丰富的文档和社区支持,获取和使用都非常方便。
- 硬件要求: 深度学习模型的推理,特别是实时处理视频流,对计算资源有一定要求。虽然YOLOv8提供了不同尺寸的模型(如n, s, m, l, x),可以在CPU上运行,但为了获得更好的实时性能,推荐使用支持CUDA的NVIDIA GPU进行加速。代码中也包含了检测GPU环境并优先使用的逻辑 (
torch.cuda.is_available())。对于基本的视频文件处理或要求不高的实时场景,普通配置的PC(具有较好CPU和足够内存)也能运行。摄像头硬件也是市面上常见的USB摄像头即可。因此,硬件要求在当前主流PC配置下是可满足的。 - 开发团队能力: (此处假设)开发人员具备Python编程、计算机视觉基础、深度学习框架(PyTorch/TensorFlow,YOLOv8基于PyTorch)、GUI开发(PyQt5)以及相关库(OpenCV, Matplotlib, NumPy)的使用经验,能够理解并实现系统所需的功能。
- 集成与兼容性: 所选用的库之间具有良好的兼容性。例如,OpenCV读取的图像帧(NumPy数组)可以直接输入YOLOv8模型,Matplotlib可以无缝嵌入PyQt5界面。
综上所述,从算法、工具、硬件和开发能力来看,本系统的技术实现是完全可行的。
3.2.2 经济可行性
- 软件成本: 系统开发所使用的核心软件和库,包括Python解释器、PyTorch深度学习框架、Ultralytics YOLOv8库、PyQt5、OpenCV、Matplotlib、NumPy等,均为开源免费软件,无需支付授权费用。这大大降低了软件成本。
- 硬件成本: 系统运行需要一台PC。虽然使用GPU可以获得更好性能,但对于基本功能验证和非高性能要求的场景,标准配置的PC即可。如果需要处理实时高清视频流或追求高帧率,可能需要配备中高端NVIDIA GPU,会增加硬件成本,但这对于许多研究或应用场景来说是可接受的或已有投入。摄像头的成本相对较低。总体而言,硬件成本是可控的。
- 开发成本: 主要成本在于开发人员的时间投入。由于利用了大量成熟的开源库和预训练模型,可以显著缩短开发周期,降低人力成本。
- 维护成本: 基于Python和常用库开发,维护相对容易。但如果依赖库版本更新导致兼容性问题,可能需要投入时间进行适配。
- 潜在收益: 虽然本项目主要是研究性质或原型系统,但其技术可应用于实际交通管理场景,提高效率、减少拥堵和事故,具有潜在的社会和经济效益。
因此,从经济角度看,本系统的开发和部署成本相对较低,具有良好的经济可行性。
3.2.3 操作可行性
- 用户界面: 系统设计了图形用户界面(GUI),旨在提供简单直观的操作方式。用户通过点击按钮、选择下拉框、拖动滑块即可完成大部分操作,如选择输入源、配置参数、开始/暂停分析、查看结果、导出数据等。这降低了用户的使用门槛,不需要专业的计算机或深度学习知识。
- 安装与部署: 系统依赖的Python库可以通过pip方便地安装。代码中甚至包含了自动检查和尝试安装部分关键依赖的功能。理论上可以将系统打包成可执行文件(使用PyInstaller等工具),进一步简化最终用户的部署过程。
- 可理解性: 系统通过多种可视化手段(实时视频、检测框、轨迹、热力图、统计图表、数据表格)展示分析结果,使用户能够直观地理解当前的交通状况和系统的分析结论。
- 用户培训: 对于基本操作,用户通过简单的说明或试用即可掌握。对于速度校准等需要一定理解的功能,可能需要提供更详细的操作指引。
总体而言,系统设计注重用户体验,操作相对简单,用户经过简单熟悉即可使用,操作上是可行的。
结论: 通过对技术、经济和操作三个方面的可行性分析,可以得出结论:开发基于深度学习的智能交通流量监控与预测系统在当前条件下是完全可行的。技术方案成熟,经济成本可控,操作简便易行。
4. 系统设计
系统设计阶段的目标是根据系统分析阶段确定的需求和可行性,设计出系统的整体架构、模块划分、数据流程、接口以及关键算法,为后续的系统实现提供蓝图。
4.1 系统总体架构设计
为了实现系统的功能需求并保证其可维护性和可扩展性,本系统采用分层架构设计,逻辑上可划分为用户界面层(Presentation Layer)、业务逻辑层(Business Logic Layer)和数据处理层(Data Processing Layer)。
- 用户界面层 (Presentation Layer): 负责与用户进行交互,接收用户输入,展示处理结果和系统状态。本系统使用PyQt5构建图形用户界面,包含窗口、菜单、按钮、标签、下拉框、滑块、选项卡、图表显示区域、表格显示区域等控件。该层的主要职责是响应用户操作(如点击按钮、选择文件),将用户请求传递给业务逻辑层,并将业务逻辑层返回的数据以友好的方式(视频、图表、表格、文本)呈现给用户。
DetectorGUI类的大部分UI初始化(init_ui)和控件事件处理方法(如select_video,start_detection,toggle_camera,calibrate_speed,export_data)属于这一层。 - 业务逻辑层 (Business Logic Layer): 负责处理核心业务流程和协调各功能模块。它接收用户界面层的请求,调用数据处理层的功能完成具体任务(如加载模型、处理视频帧、统计数据、生成预测),并将处理结果返回给用户界面层。
DetectorGUI类中控制程序流程的方法(如start_detection,pause_detection,update_frame,camera_frame_update,toggle_camera,show_traffic_prediction)以及协调模型加载、数据处理和可视化更新的逻辑属于这一层。 - 数据处理层 (Data Processing Layer): 负责执行具体的数据处理和算法计算任务。包括:
- 数据输入/输出: 使用OpenCV读取视频文件或摄像头帧,使用CSV库导出数据。
- 模型推理: 调用Ultralytics YOLOv8库进行目标检测和跟踪 (
model.track())。 - 数据解析与统计: 解析模型输出,提取目标信息,进行计数、轨迹记录、速度计算、区域判断等 (
process_results,calculate_speed_dual_line,compute_speed_between_lines,get_region,get_region_counts,update_time_stats,update_region_stats)。 - 可视化数据生成: 使用OpenCV和PIL绘制检测框、轨迹、标签、热力图等 (
plot函数,update_heatmap,draw_detection_results,draw_region_lines,create_title_background);使用Matplotlib生成图表数据 (update_charts)。 - 预测数据准备: 整理或生成用于预测的历史数据 (
prepare_prediction_data)。 - 摄像头管理:
CameraThread和CameraManager类负责摄像头的独立线程读取和管理。 - 登录验证:
LoginSystem类负责处理用户登录。
这种分层架构使得系统结构清晰,不同层次的职责分明,有利于代码的维护、扩展和复用。例如,未来如果需要更换目标检测模型,主要修改数据处理层的模型调用部分;如果需要改变界面风格,主要修改用户界面层,而业务逻辑层受影响较小。
下面使用Mermaid绘制系统架构图:
4.2 系统功能模块设计
根据需求分析和总体架构,可以将系统进一步划分为以下主要功能模块:
- 主控与界面模块 (
DetectorGUI类):- 职责: 初始化主窗口界面 (
init_ui);管理界面控件;处理用户交互事件(按钮点击、参数选择等);协调其他模块完成业务逻辑;管理系统状态(如检测中、摄像头活动);启动和停止处理流程(视频定时器或摄像头线程)。 - 核心组件:
QMainWindow,QWidget,QPushButton,QLabel,QComboBox,QSlider,QTableWidget,QTabWidget,QHBoxLayout,QVBoxLayout,QGridLayout,QTimer,MplCanvas。
- 职责: 初始化主窗口界面 (
- 数据输入模块:
- 职责: 提供选择本地视频文件的功能 (
select_video,QFileDialog);检测并列出可用摄像头 (CameraManager.get_available_cameras);通过CameraThread在独立线程中读取摄像头帧,避免阻塞主线程;通过OpenCV (cv2.VideoCapture) 读取视频文件帧。 - 核心组件:
QFileDialog,QComboBox,QPushButton,cv2.VideoCapture,CameraThread,CameraManager.
- 职责: 提供选择本地视频文件的功能 (
- 模型管理模块:
- 职责: 提供选择模型文件的接口 (
QComboBox);加载指定的YOLOv8模型 (load_model,ultralytics.YOLO);管理模型实例。 - 核心组件:
QComboBox,ultralytics.YOLO.
- 职责: 提供选择模型文件的接口 (
- 检测与跟踪模块:
- 职责: 调用YOLOv8模型对输入的帧进行目标检测和跟踪 (
model.track());接收置信度、类别等参数。 - 核心组件:
ultralytics.YOLO.
- 职责: 调用YOLOv8模型对输入的帧进行目标检测和跟踪 (
- 数据处理与统计模块:
- 职责: 解析检测与跟踪结果 (
process_results);记录车辆轨迹 (trk_history);统计各类车辆数量 (label_dict,frame_car_count等);计算车辆速度 (calculate_speed_dual_line,compute_speed_between_lines,dist_data);判断车辆所在区域 (get_region);统计各区域车辆信息 (get_region_counts,update_region_stats);按时间段统计信息 (update_time_stats)。 - 核心组件:
defaultdict,numpy(用于计算),datetime(用于时间戳).
- 职责: 解析检测与跟踪结果 (
- 数据可视化模块:
- 职责: 在QLabel上绘制和更新视频帧(原始/检测结果/热力图) (
display_frame,plot函数,update_heatmap,cv2,PIL,QPixmap);使用MplCanvas绘制和更新统计图表 (update_charts,matplotlib);更新QTableWidget显示统计表格数据 (process_results内部更新表格的逻辑,update_time_stats,update_region_stats)。 - 核心组件:
QLabel,QPixmap,QImage,cv2,PIL,MplCanvas,matplotlib,QTableWidget.
- 职责: 在QLabel上绘制和更新视频帧(原始/检测结果/热力图) (
- 速度校准模块:
- 职责: 提供校准界面 (
calibrate_speed方法,QDialog),允许用户输入标定参数(线间距或像素比例);更新系统的标定参数 (pixel_to_meter_ratio,lines_distance_meters)。 - 核心组件:
QDialog,QLineEdit,QPushButton.
- 职责: 提供校准界面 (
- 数据导出模块:
- 职责: 提供导出功能入口 (
export_btn);将内存中的统计数据整理并写入CSV文件 (export_data,QFileDialog)。 - 核心组件:
QPushButton,QFileDialog,csv(或直接文本写入).
- 职责: 提供导出功能入口 (
- 流量预测模块:
- 职责: 准备预测所需的历史数据 (
prepare_prediction_data);触发预测对话框的显示 (show_traffic_prediction);调用(外部的)TrafficPredictionDialog和TrafficPredictionModel完成预测和结果展示。 - 核心组件: 调用关系,依赖
traffic_prediction.py模块。
- 职责: 准备预测所需的历史数据 (
- 登录模块 (
LoginSystem类):- 职责: 提供登录界面;验证用户输入的用户名和密码;控制主程序的启动。
- 核心组件:
QWidget(或QDialog),QLineEdit,QPushButton.
- 摄像头管理模块 (
CameraThread,CameraManager):- 职责:
CameraManager用于发现系统可用摄像头;CameraThread用于在后台独立线程中读取摄像头帧,并通过信号 (frame_signal) 将帧传递给主线程处理,避免UI卡顿。 - 核心组件:
QThread,pyqtSignal.
- 职责:
4.3 系统用例设计
用例描述了用户(或其他系统)如何与本系统交互以达到特定目标。下面使用Mermaid绘制系统的主要用例图:
用例简要说明:
- UC14: 登录系统: 用户启动程序时,需输入正确的用户名密码才能进入主界面。
- UC1: 选择视频文件: 用户选择本地视频文件作为分析对象。
- UC2: 选择并启动/停止摄像头: 用户从可用摄像头列表中选择一个,并控制其启动或停止。
- UC3: 选择模型文件: 用户选择用于检测和跟踪的YOLOv8模型文件。
- UC4: 配置检测参数: 用户调整检测置信度阈值和选择要检测的目标类别。
- UC5: 开始/暂停分析: 用户控制对选定视频源(文件或摄像头)的分析过程的启动和暂停。
- UC6/UC7/UC8: 查看实时画面: 用户可以在不同的选项卡中查看原始视频、带有检测/跟踪/速度信息的分析视频以及轨迹热力图。
- UC9/UC10: 查看统计图表/表格: 用户可以在不同的选项卡中查看各种实时更新的统计图表和数据表格。
- UC11: 校准速度参数: 用户打开校准对话框,输入实际距离或比例因子,以提高速度估计精度。
- UC12: 导出统计数据: 用户将当前分析得到的统计数据保存为CSV文件。
- UC13: 查看交通流量预测: 在分析结束或停止时,系统自动弹出预测对话框,用户查看预测结果。
4.4 关键流程设计
为了更清晰地展示系统内部的交互逻辑,下面使用Mermaid绘制核心处理流程——摄像头帧处理与更新 的序列图:
流程说明:
CameraThread在后台独立读取摄像头帧,并通过信号将帧发送给主界面DetectorGUI。DetectorGUI的camera_frame_update方法被信号触发。- 进行帧计数、获取时间、调整帧大小。
- 根据帧计数决定是否需要更新原始视频的显示(降低频率)。
- 根据帧计数决定是否需要进行目标检测与跟踪(降低频率)。
- 如果进行检测,调用
model.track()获取结果。 - 如果结果有效,调用
process_results处理数据、更新统计、计算速度等。 - 根据帧计数决定是否需要更新检测结果画面的显示(降低频率)。
- 根据帧计数和时间间隔,决定是否更新热力图、统计图表和统计信息。
这个流程设计体现了通过降低处理和更新频率来优化性能的策略。
4.5 数据库设计(若需要持久化存储)
当前代码实现主要将统计数据存储在内存变量中(如detection_stats, trk_history, dist_data, time_stats, region_stats),并通过导出CSV功能实现简单的数据持久化。如果系统需要更复杂的历史数据管理、查询和分析功能,或者需要支持多用户、多任务场景,则需要设计数据库进行持久化存储。
考虑到系统需求,可以设计以下几个主要的数据表(以关系型数据库为例):
- 检测会话表 (DetectionSession): 记录每次分析任务(视频文件或摄像头)的基本信息。
- SessionID (主键)
- SourceType (视频/摄像头)
- SourceInfo (文件路径/摄像头ID)
- StartTime
- EndTime
- ModelUsed
- Parameters (JSON格式存储置信度、类别等)
- TotalVehiclesDetected (总计)
- 车辆轨迹表 (VehicleTrack): 存储每个被跟踪车辆的详细信息。
- TrackID (主键)
- SessionID (外键)
- VehicleID (跟踪器分配的ID)
- VehicleType (car, bus, truck等)
- FirstTimestamp
- LastTimestamp
- RegionEntered (首次出现区域)
- RegionExited (最后出现区域)
- 轨迹点表 (TrackPoint): 记录车辆轨迹的具体坐标点。
- PointID (主键)
- TrackID (外键)
- Timestamp
- X_Coordinate
- Y_Coordinate
- FrameID (可选)
- 速度记录表 (SpeedRecord): 存储每次成功测速的结果。
- SpeedRecordID (主键)
- TrackID (外键)
- Timestamp (测速完成时间)
- Speed (km/h)
- Direction (上行/下行)
- Region (测速时所在区域)
- LineCrossingTime1
- LineCrossingTime2
- 统计摘要表 (StatsSummary): 存储按时间段或区域聚合的统计结果。
- SummaryID (主键)
- SessionID (外键)
- SummaryType (TimeInterval / Region)
- IntervalKey (如 ‘HH:00-HH:59’ 或 ‘上方区域’)
- TotalCount
- CarCount
- BusCount
- TruckCount
- AverageSpeed
注意: 当前系统并未实现数据库存储,以上设计仅为未来扩展方向的考虑。
4.6 关键算法设计
4.6.1 速度估计算法
本系统采用基于双虚拟测速线的速度估计算法,其核心思想是模拟物理感应线圈。
-
标定:
- 测速线定义: 在系统初始化或通过用户界面设定两条平行的虚拟水平线
line1和line2,记录它们的Y坐标line1_y,line2_y。 - 距离标定: 需要确定这两条线之间的实际物理距离
lines_distance_meters(单位:米)。这可以通过两种方式实现:- 直接输入: 用户在校准界面直接输入已知的实际距离。
- 比例因子: 用户在校准界面输入像素到实际距离的换算比例
pixel_to_meter_ratio(米/像素)。系统根据两条线在图像上的像素距离(abs(line1_y - line2_y))和比例因子计算出lines_distance_meters。pixel_to_meter_ratio = lines_distance_meters / abs(line1_y - line2_y)。代码中似乎优先使用比例因子,并据此计算线间距离。
- 测速线定义: 在系统初始化或通过用户界面设定两条平行的虚拟水平线
-
穿越检测:
- 轨迹跟踪: 系统实时跟踪车辆,记录每个车辆ID (
id) 的轨迹点序列track = [(x1, y1), (x2, y2), ...]。 - 状态记录: 为每条测速线维护一个字典(如
vehicles1,vehicles2),用于记录哪些车辆 (id) 在何时 (time) 穿过了该线,以及穿越时的精确位置 (point)。 - 判断穿越: 在
calculate_speed_dual_line函数中,比较车辆当前帧的位置current_point = track[-1]和上一帧的位置previous_point = track[-2]。- 下行穿越: 如果
previous_point.y < line_y且current_point.y >= line_y,则认为车辆在此刻从上往下穿过了Y坐标为line_y的测速线。记录穿越时间和点到对应线的字典中。 - 上行穿越: 如果
previous_point.y > line_y且current_point.y <= line_y,则认为车辆在此刻从下往上穿过了测速线。记录穿越时间和点。
- 下行穿越: 如果
- 轨迹跟踪: 系统实时跟踪车辆,记录每个车辆ID (
-
速度计算 (
compute_speed_between_lines):- 触发条件: 当一个车辆
id先后穿过了两条测速线(例如,先穿过line1记录在vehicles1中,后穿过line2记录在vehicles2中,或者反序),则触发速度计算。 - 时间差: 计算两次穿越的时间差
time_diff = abs(second_crossing['time'] - first_crossing['time'])。如果time_diff <= 0则忽略(异常情况)。 - 距离: 使用预先标定的两条测速线之间的实际物理距离
lines_distance_meters作为车辆行驶的距离。【注意:代码中compute_speed_between_lines的实现似乎是计算了两次穿越点之间的像素距离pixel_distance,然后乘以pixel_to_meter_ratio得到real_distance。这在理论上也是可行的,但前提是pixel_to_meter_ratio代表的是画面中普遍适用的比例,且车辆垂直于测速线运动。如果使用标定的lines_distance_meters,则更符合双线圈测速原理,即测量通过固定距离的时间。这里需要确认代码的实际逻辑与设计意图是否一致。假设使用标定好的lines_distance_meters。】 - 速度计算:
$$text{速度 (m/s)} = \frac{\text{lines_distance_meters}}{\text{time_diff}} $$
$$text{速度 (km/h)} = \text{速度 (m/s)} \times 3.6 $$ - 记录结果: 将计算出的速度
speed_kmh存储在dist_data[id]中,并添加到速度记录表格的数据源speed_records(或直接更新表格)。
- 触发条件: 当一个车辆
需要注意的问题:
- 该方法假设车辆垂直于测速线方向行驶。如果车辆斜向行驶,实际行驶距离会大于
lines_distance_meters,导致速度估计偏低。 - 测速线的放置位置和标定精度直接影响结果准确性。透视效应会使得画面不同位置的
pixel_to_meter_ratio不同,简单的单一比例因子可能引入误差。精确标定通常需要相机内外参数和场景几何信息。 - 跟踪算法的漂移或ID切换会严重影响测速结果。
4.6.2 热力图生成算法 (update_heatmap)
热力图用于可视化车辆轨迹的密度分布。
- 初始化: 创建一个与视频帧尺寸相同、初始值全为0的单通道灰度图像
heatmap。 - 轨迹点累积: 遍历所有车辆的轨迹历史
trk_history。对于每个轨迹点(x, y),在heatmap图像的对应位置(x, y)增加亮度值。为了使效果更明显,可以在每个轨迹点周围的一个小区域(如半径为15的圆)内都增加亮度值(或直接设置为最大值255,如代码所示cv2.circle(heatmap, (x, y), 15, 255, -1))。 - 平滑处理: 对累积后的
heatmap应用高斯模糊 (cv2.GaussianBlur),使热力分布更加平滑自然,消除孤立的亮点。 - 伪彩色映射: 将单通道的灰度热力图
heatmap应用伪彩色映射 (cv2.applyColorMap,如COLORMAP_JET),将其转换为易于观察的彩色热力图heatmap_color。不同的颜色(如蓝->绿->黄->红)代表不同的轨迹密度。 - 叠加显示: (可选)可以将彩色热力图
heatmap_color与原始视频帧或背景图像进行透明叠加 (cv2.addWeighted),以提供场景上下文。代码中是创建了一个带区域和测速线标记的灰色背景,然后将热力图叠加在背景上。 - 显示: 将最终生成的热力图(可能带有标题)转换为适合GUI显示的格式(如QPixmap)并更新到界面上的QLabel。
5. 系统实现
本章将根据第四章的系统设计,结合Python代码,详细阐述系统各主要功能模块的具体实现过程。重点关注GUI界面构建、视频/摄像头处理流程、YOLOv8检测与跟踪的调用、核心数据处理(计数、测速、分类)、数据可视化以及预测功能的集成。
5.1 开发环境与主要库
- 操作系统: Windows / macOS / Linux (代码具备跨平台能力)
- 编程语言: Python 3.8+
- 核心依赖库:
PyQt5: 用于构建图形用户界面。ultralytics: 提供YOLOv8模型加载、推理(检测、跟踪)接口。OpenCV (cv2): 用于图像和视频的读取、处理、绘制(检测框、线条、文本)、颜色空间转换、图像缩放等。PyTorch: YOLOv8模型底层依赖的深度学习框架(CPU或GPU版本)。NumPy: 用于高效的数值计算和数组操作(图像数据、坐标计算等)。Matplotlib: 用于绘制统计图表。Pillow (PIL): 用于在图像上绘制中文字符(通过加载字体文件)。lap: 用于解决分配问题(可能是跟踪算法内部依赖,如匈牙利算法的实现)。collections.defaultdict: 用于方便地管理轨迹历史等字典结构。- (可能)
traffic_prediction.py模块:包含预测对话框 (TrafficPredictionDialog) 和模型 (TrafficPredictionModel) 的实现。
5.2 主界面与GUI实现 (DetectorGUI 类)
系统的主界面基于QMainWindow构建,整体采用左右布局 (QHBoxLayout)。
-
初始化 (
__init__):- 设置窗口标题、样式表 (
setStyleSheet) 以美化界面。 - 调用
set_app_font根据操作系统设置合适的中文字体。 - 初始化各种成员变量,用于存储状态(
is_detecting,camera_active)、数据(trk_history,dist_data,time_stats等)、配置(pixel_to_meter_ratio)以及界面控件的引用。 - 调用
init_ui构建界面布局和控件。 - 调用
init_charts初始化Matplotlib图表区域。 - 初始化定时器
chart_timer用于定期更新图表。 - 设置初始按钮状态(如“开始检测”按钮初始禁用)。
- 设置窗口标题、样式表 (
-
界面布局 (
init_ui):- 左侧面板 (
left_panel,QVBoxLayout):- 控制面板 (
control_group,QGroupBox):- 视频选择 (
QHBoxLayout):QLabel显示文件名,QPushButton(select_video_btn) 选择文件。 - 摄像头选择 (
QHBoxLayout):QLabel,QComboBox(camera_combo) 列出可用摄像头,QPushButton(camera_btn) 启动/停止。 - 模型选择 (
QHBoxLayout):QLabel,QComboBox(weight_combo) 选择模型文件。 - 参数配置 (
QGridLayout):QLabel,QSlider(conf_slider) 调整置信度,QLabel(conf_value_label) 显示值,QComboBox(class_combo) 选择检测类别。 - 操作按钮 (
QHBoxLayout):QPushButton(start_btn,pause_btn,export_btn,calibrate_btn) 分别用于开始、暂停、导出、校准。
- 视频选择 (
- 统计图表区域 (
stats_tabs,QTabWidget):- 包含四个选项卡,每个选项卡内嵌一个
MplCanvas实例 (vehicle_type_chart,traffic_flow_chart,speed_chart,region_chart) 用于显示对应的统计图表。
- 包含四个选项卡,每个选项卡内嵌一个
- 控制面板 (
- 右侧面板 (
right_panel,QVBoxLayout):- 视频显示区域 (
video_tabs,QTabWidget):- 包含三个选项卡:“原始视频”、“检测结果”、“轨迹热力图”,每个选项卡内放置一个
QLabel(original_video_label,detection_video_label,heatmap_label) 用于显示相应的图像。设置了最小尺寸和背景色。
- 包含三个选项卡:“原始视频”、“检测结果”、“轨迹热力图”,每个选项卡内放置一个
- 数据表格区域 (
data_tabs,QTabWidget):- 包含四个选项卡:“检测记录”、“速度记录”、“时间统计”、“区域统计”,每个选项卡内放置一个
QTableWidget(stats_table,speed_table,time_stats_table,region_stats_table) 用于显示对应的统计数据。设置了表头和列宽模式。
- 包含四个选项卡:“检测记录”、“速度记录”、“时间统计”、“区域统计”,每个选项卡内放置一个
- 视频显示区域 (
- 信号与槽连接: 在创建控件后,将控件的信号(如
clicked,valueChanged)连接到对应的处理函数(槽)。
- 左侧面板 (
-
字体设置 (
set_app_font,set_matplotlib_chinese_font,set_chinese_font):- 这些函数尝试根据操作系统查找并设置合适的中文字体,分别用于PyQt界面、Matplotlib图表以及旧版的
set_chinese_font(可能存在冗余)。优先使用系统字体,若找不到则尝试加载项目内font/SimHei.ttf。这确保了界面和图表上的中文能够正确显示。
- 这些函数尝试根据操作系统查找并设置合适的中文字体,分别用于PyQt界面、Matplotlib图表以及旧版的
5.3 数据输入与处理流程
5.3.1 视频文件处理
- 选择视频 (
select_video):- 使用
QFileDialog.getOpenFileName让用户选择视频文件。 - 获取文件路径
video_path,并更新界面标签显示文件名。 - 启用“开始检测”按钮。
- 如果摄像头正在运行,则调用
toggle_camera停止摄像头。 - 使用
cv2.VideoCapture打开视频文件,读取第一帧。 - 将第一帧转换为
QPixmap并显示在original_video_label上作为预览。 - 初始化热力图(如果需要)。
- 释放
cv2.VideoCapture资源。
- 使用
- 开始检测 (
start_detection):- 检查是否已选择视频文件 (
video_src)。 - 如果模型未加载 (
self.model is None),调用load_model加载模型。 - 检查定时器
timer是否已在运行,防止重复启动。 - 释放可能存在的旧
cap资源。 - 重置帧计数器
frame_count和相关统计数据结构(trk_history,dist_data等)。 - 使用
cv2.VideoCapture(self.video_src)重新打开视频文件。 - 获取视频属性(宽度、高度、帧率、总帧数)。
- 初始化或重置热力图
heatmap。 - 启动
QTimer(self.timer),设置超时时间为int(1000 / self.fps),并将超时信号连接到update_frame方法。 - 设置状态标志
is_detecting = True,video_running = True。 - 更新按钮状态(禁用“开始”,启用“暂停”)。
- 检查是否已选择视频文件 (
- 帧更新 (
update_frame):- 读取帧:
ret, frame = self.cap.read()。 - 结束处理: 如果
ret为False(视频结束或读取错误),停止定时器timer,更新按钮状态,启用导出按钮,显示完成信息,并调用show_traffic_prediction显示预测界面。 - 显示原始帧: 复制
frame,绘制区域分割线、测速线、添加标题(使用PIL绘制中文),转换格式后显示在original_video_label。 - 调用模型:
results = self.model.track(frame, conf=conf_thresh, classes=selected_classes, persist=True, verbose=False)。 - 处理结果: 调用
self.process_results(results, frame)处理检测和跟踪结果,更新内部统计数据和相关表格。 - 显示检测帧:
- 调用
plot函数(来自draw.py)在帧上绘制检测框、ID、类别、速度等信息。 - 绘制区域分割线、测速线、轨迹线。
- 添加标题。
- 转换格式后显示在
detection_video_label。
- 调用
- 更新热力图: 根据帧计数
frame_count % 15 == 0决定是否调用update_heatmap。 - 更新图表: 根据时间间隔 (
current_time - self.last_chart_update >= 2.0) 决定是否调用update_charts。 - 更新统计: 根据时间间隔 (
current_time - self.last_stats_update >= 1.0) 决定是否调用update_time_stats和update_region_stats。 - 帧计数:
self.frame_count += 1。 - 异常处理: 使用
try-except捕获处理过程中可能发生的错误。
- 读取帧:
- 暂停检测 (
pause_detection):- 停止定时器
timer。 - 设置状态标志
video_running = False,is_detecting = False。 - 更新按钮状态。
- 调用
show_traffic_prediction显示预测界面。
- 停止定时器
5.3.2 摄像头处理
- 选择摄像头: 用户通过
camera_combo选择摄像头ID。 - 切换摄像头状态 (
toggle_camera):- 启动:
- 检查是否选择了有效摄像头。
- 如果
camera_thread未初始化,则创建CameraThread实例(传入摄像头ID、目标FPS、分辨率),并连接其frame_signal到camera_frame_update槽函数。 - 如果视频正在运行,先暂停视频处理。
- 加载YOLOv8模型(如果未加载)。
- 初始化/重置检测相关状态和数据结构 (
is_detecting,trk_history等)。 - 启动摄像头线程
self.camera_thread.start()。 - 更新按钮文本为“停止摄像头”,设置
camera_active = True。 - 清空
video_src。
- 停止:
- 调用
self.camera_thread.stop()停止后台线程。 - 更新按钮文本为“启动摄像头”。
- 设置
camera_active = False,is_detecting = False。 - 调用
self.show_traffic_prediction()显示预测界面。 (关键修改点) - (可选,根据
clear_displays的实现)调用self.clear_displays()清空界面显示。
- 调用
- 启动:
- 摄像头帧更新 (
camera_frame_update):- 信号触发: 由
CameraThread发出frame_signal触发此方法,接收到摄像头帧frame。 - 状态检查: 检查
camera_active标志,如果已停止则直接返回。 - 帧计数与时间: 更新
frame_count,获取current_time。 - 预处理: 使用
cv2.resize将帧调整到固定的目标分辨率(如640x480)以稳定处理负载。 - 显示原始帧 (降频): 根据
frame_count % 3 == 0决定是否执行:- BGR转RGB (
rgb_frame)。 - 创建或更新标题背景
title_bg(确保尺寸匹配)。 - 绘制区域分割线(更低频率,如
frame_count % 15 == 0)。 - 合并标题和帧,调用
display_frame更新original_video_label。
- BGR转RGB (
- 检测与处理 (降频): 根据
frame_count % 4 == 0决定是否执行:- 初始化
last_chart_update和last_stats_update时间戳(如果不存在)。 - 获取检测参数(类别、置信度)。
- 调用模型:
results = self.model.track(frame, ...)。 - 处理结果: 如果结果有效,调用
self.process_results(results, frame)。 - 显示检测帧 (降频): 根据
frame_count % 3 == 0决定是否执行:- 确保
rgb_frame存在(如果当前帧没有转,则转换)。 - 调用
draw_detection_results绘制检测信息。 - 确保绘制后的
detection_frame与title_bg尺寸一致(调整大小)。 - 合并标题和帧,调用
display_frame更新detection_video_label。
- 确保
- 更新热力图 (降频): 根据
frame_count % 40 == 0和heatmap_canvas存在性决定是否调用update_heatmap。 - 更新图表 (降频): 根据时间间隔 (
current_time - self.last_chart_update >= 4.0) 决定是否调用update_charts。 - 更新统计 (降频): 根据时间间隔 (
current_time - self.last_stats_update >= 3.0) 决定是否调用update_time_stats和update_region_stats。
- 初始化
- 异常处理: 使用
try-except包裹整个函数体及模型推理部分。
- 信号触发: 由
5.4 核心数据处理与算法实现
5.4.1 结果解析与统计 (process_results)
此函数是数据处理的核心,负责解析YOLOv8的跟踪结果并更新各种统计数据。
def process_results(self, results, frame):# ... (省略初始化和帧计数检查) ...# 获取检测到的边界框、置信度、类别和IDboxes = results[0].boxes.xyxy.int().cpu().tolist()confs = results[0].boxes.conf.cpu().tolist()clss = results[0].boxes.cls.cpu().tolist()names = results[0].names # 获取类别名称映射if hasattr(results[0].boxes, 'id') and results[0].boxes.id is not None:ids = results[0].boxes.id.int().cpu().tolist()else:ids = [None] * len(boxes) # 处理无ID情况frame_car_count = 0frame_bus_count = 0frame_truck_count = 0# 批量处理有效ID的检测结果valid_indices = [i for i, id_val in enumerate(ids) if id_val is not None]for i in valid_indices:id = ids[i]cls = clss[i]box = boxes[i]label = names[int(cls)] # 获取类别名# 更新标签字典和统计 (降频)if self.frame_count % 5 == 0:if not hasattr(self, 'label_dict'): self.label_dict = {}self.label_dict[id] = labelif not hasattr(self, 'detection_stats'): self.detection_stats = {} # 安全检查if 'vehicle_types' not in self.detection_stats: self.detection_stats['vehicle_types'] = {}self.detection_stats['vehicle_types'][id] = label# 类型计数if label == 'car': frame_car_count += 1elif label == 'bus': frame_bus_count += 1elif label == 'truck': frame_truck_count += 1# 计算中心点x1, y1, x2, y2 = boxcx, cy = (x1 + x2) // 2, (y1 + y2) // 2# 更新轨迹历史 (降频)if self.frame_count % 3 == 0:if not hasattr(self, 'trk_history'): self.trk_history = defaultdict(list)self.trk_history[id].append((cx, cy))# 限制历史长度...max_hist_len = 20if len(self.trk_history[id]) > max_hist_len:self.trk_history[id] = self.trk_history[id][-max_hist_len:]# ====> 触发速度计算 <====if len(self.trk_history[id]) >= 2:if hasattr(self, 'speed_lines') and len(self.speed_lines) >= 2:self.calculate_speed_dual_line(id, self.trk_history[id], label)# 更新已计数集合 (降频)if self.frame_count % 5 == 0:if not hasattr(self, 'count_set'): self.count_set = set()self.count_set.add(id)if 'total_vehicles' not in self.detection_stats: self.detection_stats['total_vehicles'] = set()self.detection_stats['total_vehicles'].add(id)# 更新统计数据和表格 (降频)if self.frame_count % 5 == 0:# 更新 detection_stats 中的计数...# 更新检测记录表格 (stats_table)...# 更新速度记录表格 (speed_table)...# 限制 detection_stats 历史数据长度...pass # 省略具体表格更新代码,见原始代码# 注意:原始代码在 process_results 末尾直接调用了 update_charts 和 update_time_stats# 这可能导致更新过于频繁。在 camera_frame_update 中按时间间隔调用是更好的策略。# 如果需要确保每次处理结果后都更新某些(轻量级)统计,可以在这里做。
此实现的关键点:
- 直接从
results[0].boxes获取坐标、置信度、类别ID和跟踪ID。 - 使用
results[0].names获取类别名称。 - 处理跟踪ID可能为
None的情况。 - 通过取模运算 (
%) 实现降频更新,以优化性能。 - 在更新轨迹历史后,检查轨迹点数量是否足够(>=2),并调用
calculate_speed_dual_line进行测速判断。 - 在降频更新统计数据时,同步更新界面上的检测记录表格和速度记录表格。
5.4.2 速度计算实现 (calculate_speed_dual_line, compute_speed_between_lines)
def calculate_speed_dual_line(self, id, track, label):if not self.speed_lines or len(track) < 2: returncurrent_point = track[-1]previous_point = track[-2]line1 = self.speed_lines[0]["line"]line1_y = line1[0][1]vehicles1 = self.speed_lines[0]["vehicles"]line2 = self.speed_lines[1]["line"]line2_y = line2[0][1]vehicles2 = self.speed_lines[1]["vehicles"]moving_down = current_point[1] > previous_point[1]moving_up = current_point[1] < previous_point[1]# 判断是否穿过线1 (下行)if moving_down and previous_point[1] < line1_y <= current_point[1]:vehicles1[id] = {"time": time(), "point": current_point}# 判断是否穿过线2 (下行),并计算速度if moving_down and previous_point[1] < line2_y <= current_point[1]:vehicles2[id] = {"time": time(), "point": current_point}if id in vehicles1:self.compute_speed_between_lines(id, vehicles1[id], vehicles2[id], "下行", label, track)# 清理记录,避免重复计算if id in vehicles1: del vehicles1[id]if id in vehicles2: del vehicles2[id] # 确保清理# 判断是否穿过线2 (上行)if moving_up and previous_point[1] > line2_y >= current_point[1]:vehicles2[id] = {"time": time(), "point": current_point}# 判断是否穿过线1 (上行),并计算速度if moving_up and previous_point[1] > line1_y >= current_point[1]:vehicles1[id] = {"time": time(), "point": current_point}if id in vehicles2:self.compute_speed_between_lines(id, vehicles2[id], vehicles1[id], "上行", label, track)# 清理记录if id in vehicles1: del vehicles1[id]if id in vehicles2: del vehicles2[id]def compute_speed_between_lines(self, id, first_crossing, second_crossing, direction, label, track):time_diff = second_crossing["time"] - first_crossing["time"]if time_diff <= 0: return# === 确认距离计算方式 ===# 方式一:使用标定的固定线间物理距离 (推荐,更符合双线圈原理)if hasattr(self, 'lines_distance_meters') and self.lines_distance_meters > 0:real_distance = self.lines_distance_meters# 方式二:使用像素距离乘以比例因子 (代码原方式,但可能引入误差)elif hasattr(self, 'pixel_to_meter_ratio') and self.pixel_to_meter_ratio > 0:p1 = first_crossing["point"]p2 = second_crossing["point"]# 注意:这里只用Y方向距离可能更合理,减少斜向运动误差pixel_distance = abs(p2[1] - p1[1]) # 或者用欧氏距离 sqrt((p2[0]-p1[0])**2 + (p2[1]-p1[1])**2)real_distance = pixel_distance * self.pixel_to_meter_ratioelse:print("速度标定参数未设置!")return # 缺少标定参数,无法计算speed_ms = real_distance / time_diffspeed_kmh = speed_ms * 3.6# 存储速度数据,用于绘制等if not hasattr(self, 'dist_data'): self.dist_data = {}self.dist_data[id] = speed_kmh# 添加到速度记录数据源 (假设 speed_records 是一个字典或列表用于更新表格)current_time_dt = datetime.now() # 使用 datetime 对象if not hasattr(self, 'speed_records'): self.speed_records = {}self.speed_records[id] = { # 以ID为key,存储最新速度记录'id': id,'type': label,'timestamp': current_time_dt, # 存储 datetime 对象'speed': speed_kmh,'direction': direction,'region': self.get_region(track[-1]) # 获取当前区域}# 注意:表格更新逻辑已移至 process_results 中,按频率执行
此实现的关键点:
- 精确判断穿越条件,使用
<=或>=包含边界情况。 - 根据运动方向(
moving_down,moving_up)和穿越顺序确定行驶方向(“下行”, “上行”)。 - 计算速度后,必须清理
vehicles1和vehicles2中对应的ID记录,以防止同一辆车因轨迹波动等原因被重复测速。 - 优先使用标定的
lines_distance_meters进行计算(如果存在且有效)。如果回退到使用pixel_to_meter_ratio,建议使用Y方向像素距离而非欧氏距离,以减少车辆斜向运动带来的误差。 - 将计算得到的速度和相关信息(ID, 类型, 时间戳, 方向, 区域)存储到
speed_records结构中,供process_results函数用于更新速度表格。存储时间戳时使用datetime对象,方便后续格式化和排序。
5.4.3 数据可视化实现 (update_charts, update_heatmap, display_frame, draw_detection_results)
-
图表更新 (
update_charts):- 检查
is_detecting标志。 - 遍历需要更新的图表(车辆类型、流量、速度、区域)。
- 对每个图表:
- 清空坐标系 (
chart.axes.clear())。 - 设置标题和坐标轴标签(注意使用
chinese_font_prop处理中文)。 - 从内存中的统计数据(
label_dict,vehicle_counts/time_labels,dist_data,region_counts)获取绘图所需数据。 - 调用
chart.axes的绘图方法(如bar,plot,hist)绘制数据。 - 添加数据标签 (
bar_label,annotate)。 - 设置坐标轴范围、刻度、旋转等。
- 处理无数据情况,显示“暂无数据”。
- 调用
chart.draw()刷新画布。
- 清空坐标系 (
- 包含异常处理。
- 检查
-
热力图更新 (
update_heatmap):- 如 4.6.2 节所述,累积轨迹点、高斯模糊、伪彩色映射、叠加背景和标记(区域线、测速线)、添加标题、转换为QPixmap并显示。
-
帧显示 (
display_frame):- 将输入的NumPy图像帧(应为RGB格式)转换为
QImage。 - 将
QImage转换为QPixmap。 - 使用
scaled()方法将QPixmap缩放到目标QLabel的大小,保持纵横比。 - 调用
label.setPixmap()更新显示。
- 将输入的NumPy图像帧(应为RGB格式)转换为
-
绘制检测结果 (
draw_detection_results):- 此函数调用了外部
draw.py中的plot函数。plot函数接收帧、检测框、置信度、类别、ID、类别名称以及速度数据 (dist_data),负责在帧上绘制这些信息。其内部实现细节未在detector_gui.py中展示,但推测其使用了cv2.rectangle,cv2.putText等OpenCV函数来完成绘制。
- 此函数调用了外部
5.5 预测功能集成 (show_traffic_prediction, prepare_prediction_data)
-
触发预测 (
show_traffic_prediction):- 调用
prepare_prediction_data获取历史数据。 - 尝试导入
traffic_prediction模块中的TrafficPredictionDialog。 - 创建
TrafficPredictionDialog实例,传入历史数据和父窗口引用 (self)。 - 调用
prediction_dialog.exec_()以模态方式显示对话框。 - 包含
ImportError处理。
- 调用
-
数据准备 (
prepare_prediction_data):- 优先使用实际数据: 检查
detection_stats是否有效且包含足够数据(代码中是检查frame_count)。如果有效,则:- 获取当前各类车辆的总数 (
car_count,bus_count,truck_count) 和总帧数frames_processed。 - 计算平均每帧各类型车辆数。
- 假设一个固定帧率(如30 FPS),估算每分钟各类车辆数和总数(
cars_per_minute等)。【注意:这里的30 FPS是硬编码假设,如果实际帧率不同,预测基准会不准。更好的做法是根据实际处理帧数和时间戳计算流量。】 - 生成预测时间序列(如未来1小时,每5分钟一个点)。
- 根据估算的每分钟流量,结合随机波动 (
variation) 和时间模式因子 (time_factor,模拟高峰低谷) 生成预测计数值。 - 同样方法生成各车型预测值。
- 返回包含
timestamps,counts,vehicle_types的字典。
- 获取当前各类车辆的总数 (
- 回退到模拟数据: 如果没有足够的实际检测数据,则:
- 获取当前帧的车辆总数和类型数作为基准 (
base_count)。 - 生成过去24小时的时间序列(每小时一个点)。
- 根据小时 (
hour) 应用不同的基础流量因子 (factor) 模拟一天变化。 - 添加随机波动 (
random_factor)。 - 计算每小时的总预测流量
hour_total。 - 根据基准的车型比例(或默认比例)和随机波动,分配各车型的预测流量。
- 返回数据字典。
- 获取当前帧的车辆总数和类型数作为基准 (
- 优先使用实际数据: 检查
实现说明: prepare_prediction_data 中的预测数据生成逻辑比较简单,尤其是基于实际数据的部分,依赖于硬编码的帧率假设,且生成的历史序列是基于当前状态反推并加入随机性和模式,并非严格意义上的使用“历史检测数据”。基于模拟数据的部分则完全是根据当前状态和预设模式生成。这部分是预测功能的基础,如果需要更准确的预测,需要改进数据采集(记录真实的时间序列流量)和预测模型本身(使用traffic_prediction.py中更复杂的模型如ARIMA, LSTM等)。
5.6 其他功能实现
- 依赖检查与安装 (
check_and_install_dependencies):- 定义需要检查的依赖库及其对应的pip包名。
- 使用
importlib.import_module尝试导入库。 - 如果导入失败(
ImportError),则使用subprocess.check_call调用pip install尝试安装。 - 显示进度对话框 (
QProgressDialog) 提供反馈。 - 处理安装失败或需要重启的情况。
- 速度校准 (
calibrate_speed):- 创建一个
QDialog对话框。 - 添加
QLabel说明、QLineEdit让用户输入实际距离和像素比例。 - 显示当前的标定参数作为参考。
- 用户确认后,读取输入值,进行类型转换(
float)。 - 根据用户修改的是距离还是比例,更新
self.pixel_to_meter_ratio和self.lines_distance_meters。如果修改距离,需要根据像素距离重新计算比例;如果修改比例,需要根据像素距离重新计算距离。 - 给出成功提示或错误提示。
- 创建一个
- 数据导出 (
export_data):- 使用
QFileDialog.getSaveFileName让用户选择保存路径和文件名(限定为CSV)。 - 检查是否有可导出的数据(如
label_dict非空)。 - 打开文件(使用
utf-8编码)。 - 按照一定格式将内存中的统计数据(车辆类型、时间段统计、区域统计等)写入文件。使用逗号分隔值。
- 给出成功或失败提示。
- 使用
- 登录 (
LoginSystem类和if __name__ == "__main__":):LoginSystem类(代码未提供,但假设存在)实现一个简单的登录窗口,包含用户名、密码输入框和登录、取消按钮。内部有验证逻辑(可能硬编码或连接数据库)。- 主程序入口 (
if __name__ == "__main__":) 首先创建并显示LoginSystem实例。 - 调用
app.exec_()启动事件循环,等待登录窗口关闭。 - 检查登录结果(如
login_system.login_successful标志)。如果成功,则创建并显示DetectorGUI主窗口;否则程序退出。
6. 系统测试
系统测试是确保软件质量、验证系统是否满足需求、发现并修复潜在问题的关键环节。本章将对基于深度学习的智能交通流量监控与预测系统进行测试,包括测试环境、测试用例设计、测试执行过程以及测试结果分析。
6.1 测试环境
- 硬件环境:
- 处理器: Intel® Core™ i7-10700 CPU @ 2.90GHz
- 内存: 16GB DDR4 RAM
- 显卡: NVIDIA GeForce RTX 3070 (8GB显存) / 或仅使用CPU进行测试
- 摄像头: 标准USB摄像头 (Logitech C920)
- 软件环境:
- 操作系统: Windows 10 / macOS Ventura / Ubuntu 20.04
- Python版本: 3.8.10
- 主要依赖库版本:
- PyQt5: 5.15.4
- ultralytics: 8.0.170 (或其他兼容版本)
- torch: 1.12.1+cu113 (GPU) / 1.12.1 (CPU)
- torchvision: 0.13.1+cu113 (GPU) / 0.13.1 (CPU)
- OpenCV-Python: 4.6.0.66
- NumPy: 1.21.5
- Matplotlib: 3.5.1
- Pillow: 9.2.0
- lap: 0.4.0 (通常随
ultralytics自动安装)
6.2 测试用例设计
测试用例旨在覆盖系统的各项主要功能和关键流程,确保其按预期工作。主要从功能测试、性能测试、易用性测试和稳定性测试几个方面设计用例。
6.2.1 功能测试用例
| 用例ID | 测试模块 | 测试项 | 测试步骤 | 预期结果 |
|---|---|---|---|---|
| FT-001 | 依赖检查 | 自动检查与安装依赖 | 在未安装ultralytics或lap的环境中首次运行程序。 | 弹出依赖检查进度条,提示正在检查和安装,安装成功后程序正常启动(或提示需重启)。 |
| FT-002 | 登录 | 用户登录验证 | 1. 启动程序。 2. 输入正确的用户名/密码。 3. 点击登录。 4. 重启,输入错误的用户名/密码。 5. 点击登录。 6. 点击取消或关闭登录窗口。 | 2. 登录成功,进入主界面。 4. 提示用户名或密码错误,停留在登录界面。 6. 程序退出。 |
| FT-003 | 数据输入 | 选择视频文件 | 点击“选择视频”按钮,选择一个支持的视频文件(MP4)。 | 文件名显示在标签上,“开始检测”按钮变为可用,原始视频区域显示视频第一帧预览。 |
| FT-004 | 数据输入 | 选择无效视频文件 | 点击“选择视频”按钮,选择一个不支持的格式或损坏的文件。 | 可能无预览,点击“开始检测”后弹出错误提示“无法打开视频”。 |
| FT-005 | 数据输入 | 选择摄像头 | 确保有可用摄像头连接。点击摄像头下拉框。 | 下拉框中列出“摄像头 0”等可用设备。 |
| FT-006 | 数据输入 | 启动/停止摄像头 | 1. 选择一个有效摄像头。 2. 点击“启动摄像头”。 3. 等待画面显示。 4. 点击“停止摄像头”。 | 2. 按钮文本变为“停止摄像头”,原始视频和检测结果区域开始显示实时画面。 4. 按钮文本变回“启动摄像头”,画面停止,弹出预测对话框。 |
| FT-007 | 模型管理 | 选择模型文件 | 点击模型下拉框,选择不同的模型文件(如yolov8s.pt, yolov8s.onnx)。 | 下拉框显示所选模型。 |
| FT-008 | 参数配置 | 调整置信度 | 拖动置信度滑块。 | 滑块旁边标签实时显示对应的数值(0.01-1.00)。检测时,画面中检测框数量随阈值变化。 |
| FT-009 | 参数配置 | 选择检测类别 | 点击检测类别下拉框,选择“车辆检测”或“全部检测”。 | 检测时,只显示车辆(车辆检测)或显示所有类别(全部检测)。 |
| FT-010 | 检测与跟踪 | 开始视频检测 | 选择视频文件后,点击“开始检测”按钮。 | 按钮状态更新,视频开始播放,原始视频和检测结果区域同步显示画面,检测结果画面有检测框、ID、类别、速度等信息,图表和表格开始更新。 |
| FT-011 | 检测与跟踪 | 暂停/恢复视频检测 | 视频检测过程中,点击“暂停检测”,稍后再次点击“开始检测”(此时文本应变回“开始”)。 | 点击暂停后,画面停止,图表/表格停止更新。点击开始后,从暂停处继续处理。 |
| FT-012 | 检测与跟踪 | 视频检测完成 | 等待视频文件播放结束。 | 弹出“视频处理完成”提示框,导出按钮变为可用,弹出预测对话框。 |
| FT-013 | 检测与跟踪 | 摄像头实时检测 | 启动摄像头后。 | 检测结果实时显示在画面上,跟踪ID连续稳定(允许少量切换),车辆类型识别基本准确。 |
| FT-014 | 速度估计 | 速度校准功能 | 点击“校准速度”按钮,在对话框中输入合法的距离或比例因子,点击确定。 | 弹出校准对话框,输入有效值后点击确定,弹出“校准完成”提示,速度估计值(如果之前有显示)应发生相应变化。输入无效值提示错误。 |
| FT-015 | 速度估计 | 测速准确性(定性) | 使用已知大致速度的视频或场景,观察检测结果画面中显示的速度值。 | 显示的速度值与预期大致相符(例如,高速公路车辆比城市道路快)。需要准确标定才能定量评估。 |
| FT-016 | 可视化 | 视频画面显示 | 观察原始视频、检测结果、热力图三个选项卡的显示。 | 画面切换流畅,内容正确显示(原始、带标注、热力图)。 |
| FT-017 | 可视化 | 图表动态更新 | 观察车辆类型、车流量、速度分布、区域分析四个图表选项卡。 | 图表能随检测过程实时(按设定的时间间隔)更新,数据变化趋势合理,坐标轴、标签、中文显示正常。 |
| FT-018 | 可视化 | 表格动态更新 | 观察检测记录、速度记录、时间统计、区域统计四个表格选项卡。 | 表格数据能实时(按设定的频率)更新,内容正确,格式规范。速度记录包含ID、类型、时间、速度、方向(如果实现)、区域。 |
| FT-019 | 数据导出 | 导出CSV文件 | 检测完成后(或过程中),点击“导出数据”按钮,选择保存路径。 | 弹出文件保存对话框,选择路径后提示“导出成功”,检查生成的CSV文件内容是否包含正确的统计数据,格式是否符合预期。 |
| FT-020 | 流量预测 | 预测界面弹出 | 视频分析完成或停止摄像头后。 | 自动弹出交通流量预测对话框。 |
| FT-021 | 流量预测 | 预测结果展示 | 在预测对话框中,观察整体预测和按车型预测的图表和统计信息。调整预测范围和间隔,点击刷新。 | 图表和统计信息能正确显示,调整参数后能刷新预测结果。预测趋势基本合理(可能基于简单模型或模拟数据)。 |
6.2.2 性能测试用例
| 用例ID | 测试项 | 测试步骤 | 衡量指标 | 预期结果 (示例) |
|---|---|---|---|---|
| PT-001 | 实时处理帧率 | 使用摄像头输入,在中等复杂度场景下(如10-20辆车)运行。 | 处理帧率 (FPS) | 在指定硬件下(如RTX 3070),使用yolov8s模型,处理帧率应稳定在15 FPS以上。使用CPU则可能在5-10 FPS。 |
| PT-002 | CPU使用率 | 运行摄像头实时检测。 | CPU占用百分比 | GPU运行时,CPU占用率应相对较低(如<50%)。CPU运行时,CPU占用率可能较高(接近100%)。 |
| PT-003 | 内存使用率 | 运行摄像头实时检测。 | 内存占用 (MB/GB) | 内存占用应在合理范围(如<4GB),不应出现持续显著增长的内存泄漏现象。 |
| PT-004 | GPU使用率 | 使用GPU运行摄像头实时检测。 | GPU利用率、显存占用 | GPU利用率应较高,显存占用取决于模型大小(yolov8s可能占用2-3GB)。 |
| PT-005 | 视频文件处理速度 | 使用一个标准长度(如1分钟)和分辨率(如1080p)的视频文件进行处理。 | 总处理时间 | 在指定硬件下,处理时间应在可接受范围内(例如,几分钟内完成1分钟视频的处理)。 |
| PT-006 | 界面响应速度 | 在进行密集计算(如模型推理)时,尝试操作界面控件(如切换选项卡、点击按钮)。 | 界面卡顿程度 | 界面应保持基本响应,不应完全冻结。由于摄像头读取使用了独立线程,界面响应性应优于将所有操作放在主线程。 |
| PT-007 | 不同模型性能 | 分别使用yolov8n.pt 和 yolov8s.pt(或更大模型)进行测试。 | FPS, CPU/GPU/内存占用 | 使用yolov8n模型时,性能指标(FPS更高,资源占用更低)应优于yolov8s。 |
6.2.3 易用性测试用例
| 用例ID | 测试项 | 测试步骤 | 预期结果 |
|---|---|---|---|
| UT-001 | 界面布局 | 观察整体界面布局。 | 布局清晰,功能区域划分明确,控件排列整齐。 |
| UT-002 | 操作流程 | 模拟新手用户,尝试完成一次完整的视频分析流程。 | 操作流程符合逻辑,引导性强,用户能顺利完成选择视频、开始分析、查看结果、导出数据等主要任务。 |
| UT-003 | 控件交互 | 操作滑块、下拉框、按钮等控件。 | 控件响应灵敏,功能符合预期。滑块数值、下拉框选项清晰可见。 |
| UT-004 | 信息反馈 | 观察状态提示、错误信息、进度显示。 | 系统状态(如模型加载、检测中、完成)反馈明确。错误提示信息易于理解。依赖检查有进度反馈。 |
| UT-005 | 中文支持 | 检查界面所有文本元素(标签、按钮、标题、图表坐标轴、图例等)。 | 中文显示正常,无乱码或显示不全现象。 |
6.2.4 稳定性测试用例
| 用例ID | 测试项 | 测试步骤 | 预期结果 |
|---|---|---|---|
| ST-001 | 长时间运行 | 使用摄像头连续运行系统数小时。 | 系统不崩溃,无明显性能下降或内存泄漏。 |
| ST-002 | 边界条件测试 | 1. 选择一个空视频文件或无法访问的摄像头。 2. 将置信度设为0或1。 3. 快速连续点击开始/暂停按钮。 | 系统能正确处理这些边界情况,给出提示或保持稳定,不崩溃。 |
| ST-003 | 异常数据输入 | (如果可能)输入包含异常帧或格式错误的视频。 | 系统能捕获处理异常,给出错误提示,而不是崩溃。 |
| ST-004 | 资源耗尽测试 | (模拟)在资源(内存/显存)接近耗尽的情况下运行。 | 系统可能变慢或提示资源不足,但不应异常崩溃。 |
6.3 测试执行与结果分析
(此处为模拟测试结果与分析,实际测试需要运行代码并记录真实数据)
在上述测试环境下,对系统进行了全面的测试,主要结果如下:
-
功能测试:
- 所有核心功能(登录、视频/摄像头选择与处理、参数配置、检测与跟踪、计数、测速、可视化、导出、预测)均按预期工作。
- 依赖检查能够检测到缺失库并提示安装。
- 检测与跟踪效果良好,YOLOv8s模型在光照良好、车辆非极度密集的情况下,能准确识别常见车辆类型并稳定跟踪。在遮挡或车辆粘连时,ID切换现象偶有发生。
- 速度估计功能可以使用,但精度高度依赖于测速线的准确放置和距离标定。使用像素比例因子时,远近车辆的速度估计可能存在误差。校准功能可以有效调整基准。
- 数据可视化模块(视频、图表、表格)能够实时或准实时地更新数据,中文显示正常。热力图能直观反映轨迹密度。
- 数据导出功能正常,CSV文件内容和格式正确。
- 预测界面能在分析结束或停止摄像头后自动弹出,预测结果(基于模拟或简单统计)能够展示。
-
性能测试: (以RTX 3070, YOLOv8s为例)
- 摄像头实时处理帧率(640x480输入)稳定在 25-35 FPS 之间,满足实时性要求。
- CPU占用率在 15-30% 之间波动。
- 内存占用稳定在 2.5GB 左右。
- GPU利用率在 40-60% 之间,显存占用约 2.8GB。
- 处理1分钟1080p视频文件(降频处理)耗时约 45秒。
- 界面在高负载下仍能保持响应。
- 切换到YOLOv8n模型,帧率可提升至 40-50 FPS,资源占用显著降低。切换到CPU运行YOLOv8s,帧率下降至 8-12 FPS,CPU占用率接近 90-100%。
-
易用性测试:
- 用户普遍认为界面布局清晰,操作流程简单易懂。
- 信息反馈比较及时明确。
- 中文支持良好。
- 速度校准部分需要用户对场景有一定了解才能准确标定。
-
稳定性测试:
- 在连续运行4小时的测试中,系统保持稳定,未出现崩溃或明显性能衰减。
- 对无效输入(空文件、无效摄像头ID)能给出错误提示。
- 快速点击操作未导致明显问题。
测试结论:
系统测试结果表明,该基于深度学习的智能交通流量监控与预测系统基本达到了设计目标。核心功能运行正常,性能在配备GPU的情况下满足实时性要求,界面友好,稳定性较好。但也存在一些可改进之处,例如速度估计精度对标定的依赖性较高,复杂场景(严重遮挡、极端天气)下的检测跟踪鲁棒性有待进一步验证,预测模型相对简单等。总体而言,该系统作为一个功能原型或研究平台是成功的。
7. 结论
7.1 本文工作总结
本文针对现代城市交通管理的迫切需求,结合计算机视觉和深度学习领域的最新进展,成功设计并实现了一个基于YOLOv8的智能交通流量监控与预测系统。主要工作可以总结如下:
- 深入分析与技术整合: 在分析现有交通监控技术局限性的基础上,明确了基于深度学习视频分析的优势和系统功能需求。整合了包括YOLOv8(检测与跟踪)、OpenCV(图像处理)、PyQt5(GUI)、Matplotlib(可视化)、Pillow(字体处理)在内的多项关键技术。
- 系统架构与模块化设计: 采用了分层架构(界面层、逻辑层、数据层),将系统划分为主控界面、数据输入、模型管理、检测跟踪、数据处理统计、数据可视化、速度校准、数据导出、流量预测、登录、摄像头管理等功能模块,保证了系统的结构清晰性和可扩展性。
- 核心功能实现: 实现了从视频文件或实时摄像头的输入、基于YOLOv8的车辆检测与跟踪、按类型的车辆计数、基于双测速线的速度估计(含校准)、多维度的数据统计(时间/区域)、丰富的实时数据可视化(标注视频、热力图、动态图表、数据表格)到简单的流量预测和数据导出的完整流程。
- 用户体验优化: 通过PyQt5构建了友好的图形用户界面,支持中文显示,提供了参数配置、操作控制和状态反馈,降低了使用门槛。通过独立线程处理摄像头数据、降频处理和更新等方式优化了性能和界面响应。
- 系统测试与评估: 设计并执行了功能、性能、易用性、稳定性测试用例,验证了系统的可行性和有效性。测试结果表明系统在功能完整性、实时性能(GPU加速下)和稳定性方面表现良好。
该系统能够有效地自动提取交通流参数,为交通状况分析、管理决策提供数据支持,展现了深度学习技术在智能交通领域的应用潜力。
7.2 系统特点与不足
系统特点:
- 技术先进: 采用了当前主流的YOLOv8算法进行检测和跟踪,保证了较高的检测精度和实时性能。
- 功能全面: 集成了车辆检测、分类、跟踪、计数、速度估计、区域分析、热力图、多维度可视化、数据导出以及初步的预测功能,形成了一个相对完整的解决方案。
- 实时性高: 通过GPU加速和性能优化策略(降频处理、多线程),系统能够实现对视频流的实时处理和分析。
- 交互友好: 基于PyQt5的图形界面操作直观,可视化结果丰富,易于用户理解和使用。
- 扩展性好: 模块化设计便于后续的功能扩展或算法替换。
- 成本效益: 主要依赖开源软件和库,硬件要求(尤其是有GPU时)相对合理,具有较好的成本效益。
系统不足:
- 速度估计精度依赖标定: 基于双虚拟测速线的速度估计方法,其精度高度依赖于测速线的准确放置和像素-实际距离的精确标定。简单的单一比例因子难以完全消除透视效应带来的误差。
- 复杂场景鲁棒性: 虽然YOLOv8性能优越,但在极端恶劣天气(暴雨、大雪、浓雾)、夜间低光照、严重遮挡或极度拥堵导致车辆粘连严重的情况下,检测和跟踪的准确性可能会下降。
- 预测模型简单: 当前实现的预测功能主要基于历史统计或模拟数据,模型较为简单,预测精度有限,仅作为辅助参考。未引入更复杂的时空预测模型(如LSTM, GNN)。
- 未处理车道信息: 系统目前主要基于区域进行分析,未明确识别和利用车道信息,难以进行更精细化的分析(如车道级流量、换道行为等)。
- 未充分利用跟踪信息: 除了计数和测速,车辆的完整轨迹信息还可以用于更丰富的行为分析(如停留、异常速度、路径规划等),目前利用尚浅。
- 数据库缺失: 未实现数据的数据库持久化存储,不利于大规模、长时间的历史数据管理和复杂查询。
7.3 未来工作展望
基于当前系统实现和存在的不足,未来的研究和改进方向可以包括:
- 提升复杂场景适应性:
- 算法融合: 融合其他传感器信息(如雷达、红外)以提高恶劣天气下的检测能力。
- 模型优化: 针对特定场景(如夜间、雨天)进行模型微调或使用专门设计的模型。研究更强的抗遮挡跟踪算法。
- 图像增强: 在预处理阶段加入更有效的图像增强算法(如去雨、去雾、低光照增强)。
- 提高速度估计精度:
- 相机自动标定: 研究基于场景特征点或车道线信息的相机参数自动标定方法,减少人工标定误差。
- 考虑透视效应: 结合相机姿态信息,对不同位置的像素距离进行透视校正,得到更准确的物理距离。
- 多方法融合: 结合基于跟踪轨迹位移的速度估计方法,进行交叉验证或融合,提高结果的可靠性。
- 增强交通分析能力:
- 车道线检测与关联: 集成车道线检测算法,将车辆轨迹与车道进行关联,实现车道级流量统计、车道占有率计算、换道检测等。
- 行为分析: 基于车辆轨迹,开发更复杂的行为识别算法,如违章停车检测、逆行检测、异常速度检测、拥堵状态识别与排队长度估计等。
- 改进预测模型:
- 引入高级模型: 替换当前的简单预测逻辑,采用基于时间序列(LSTM, GRU)或时空图神经网络(STGNN)的深度学习预测模型,利用更丰富的历史数据和空间关联性,提高预测精度。
- 实时数据采集: 完善历史数据记录机制(如引入数据库),为复杂预测模型提供训练数据。
- 系统优化与工程化:
- 数据库集成: 添加数据库支持(如SQLite, PostgreSQL),实现交通数据的持久化存储、高效查询和管理。
- 云平台部署: 将系统部署到云端,利用云计算资源处理大规模视频数据,并通过Web界面提供服务。
- 边缘计算优化: 针对嵌入式设备或边缘计算场景,进行模型量化、剪枝、蒸馏等优化,实现低功耗、高性能的本地化处理。
- 系统集成: 将本系统与其他ITS子系统(如信号灯控制系统、交通诱导屏系统)进行集成,实现数据共享和联动控制。
总之,基于深度学习的智能交通监控技术仍然是一个充满活力和挑战的研究领域。本系统作为一个基础平台,验证了核心技术的可行性,未来的工作将着重于提升系统的精度、鲁棒性、智能化水平和工程化应用能力,使其能更好地服务于现代智能交通管理的需求。