【Arxiv 2025】Single Image Iterative Subject-driven Generation and Editing

文章目录
- 文章标题
- 作者及研究团队介绍
- 01 在论文所属的研究领域,有哪些待解决的问题或者现有的研究工作仍有哪些不足?
- 02 这篇论文主要解决了什么问题?
- 03 这篇论文解决问题采用的关键解决方案是什么?
- 04 这篇论文的主要贡献是什么?
- 05 这篇论文有哪些相关的研究工作?
- 06 这篇论文的解决方案具体是如何实现的?
- 生成任务实现(3.3节)
- 编辑任务实现(3.4节)
- 07 这篇论文中的实验是如何设计的?
- 数据集
- 基线方法
- 评估指标
- 实验设计
- 08 这篇论文的实验结果和对比效果分别是怎么样的?
- 生成任务(表1-2)
- 编辑任务(表3)
- 用户研究(表6)
- 09 这篇论文中的消融研究(Ablation Study)告诉了我们什么?
- 生成任务消融(表4)
- 编辑任务消融(表5)
- 10 这篇论文工作后续还可以如何优化?
- 推荐投稿会议/期刊及录用概率
文章标题
Single Image Iterative Subject-driven Generation and Editing
作者及研究团队介绍
作者为Yair Shpitzer、Gal Chechik和Idan Schwartz,其中Yair Shpitzer和Gal Chechik来自以色列巴伊兰大学(Bar-Ilan University),Idan Schwartz同时隶属于巴伊兰大学和NVIDIA。研究团队专注于计算机视觉领域,特别是图像生成与编辑技术,致力于解决单图像主题个性化生成与编辑的挑战性问题。
01 在论文所属的研究领域,有哪些待解决的问题或者现有的研究工作仍有哪些不足?
在单图像主题驱动的图像生成与编辑领域,现有研究存在以下主要问题:
- 概念学习方法的局限性:传统概念学习方法(如DreamBooth)依赖少量图像微调预训练模型,当仅提供单张主题图像时,容易出现过拟合,导致风格泄露和结构失真,无法准确保留主题身份(摘要、引言)。
- 编码器方法的高成本:基于编码器的方法通过训练提取主题特征,虽能适应单图像,但需要大量计算资源和数据集特定调优,限制了其快速应用于新模型的能力(引言)。
- 训练-free方法的空白:缺乏无需训练的高效方法,现有技术难以在单图像条件下同时保证主题保真度、背景一致性和生成图像的自然度(摘要、引言)。
In the field of single-image subject-driven image generation and editing, existing research has the following key limitations:
- Limitations of concept learning methods: Traditional concept learning approaches (e.g., DreamBooth) fine-tune pretrained models on a few images, but with only one subject image, they often overfit, leading to style leakage, structural distortions, and inaccurate subject identity preservation (Abstract, Introduction).
- High cost of encoder-based methods: Encoder-based methods extract subject features through training, which can adapt to single images but require significant computational resources and dataset-specific tuning, limiting their rapid application to new models (Introduction).
- Gap in training-free methods: There is a lack of efficient training-free approaches that can simultaneously ensure subject fidelity, background consistency, and naturalness of generated images under single-image conditions (Abstract, Introduction).
02 这篇论文主要解决了什么问题?
论文主要解决了单图像条件下主题驱动的图像生成与编辑问题,即仅使用一张主题图像,无需额外训练,实现对目标主题的个性化生成和编辑,同时保证主题身份保真度、背景一致性和生成图像的自然度。具体包括:
- 在图像生成任务中,根据文本提示生成包含指定主题的新图像;
- 在图像编辑任务中,将输入图像中的原有主题替换为参考主题,同时保留背景和场景结构(摘要、引言)。
The paper addresses the problem of single-image subject-driven image generation and editing, where only one subject image is used, without additional training, to achieve personalized generation and editing of the target subject while ensuring subject identity fidelity, background consistency, and naturalness of generated images. Specifically:
- In image generation, it generates new images containing the specified subject based on text prompts;
- In image editing, it replaces the original subject in the input image with a reference subject while preserving the background and scene structure (Abstract, Introduction).
03 这篇论文解决问题采用的关键解决方案是什么?
关键解决方案是SISO(Single Image Subject Optimization),一种基于推理时迭代优化的方法,核心包括:
- 相似度损失优化:使用预训练的DINO和IR特征计算生成图像与参考主题图像的相似度损失,聚焦主题身份保留,过滤背景干扰(公式2,3.3节)。
- 迭代生成与参数更新:通过LoRA(Low-Rank Adaptation)冻结主模型参数,仅更新低秩适配器参数,每一步生成图像后反向传播优化损失,直至达到满意的相似度(图2,3.2节)。
- 任务特定调整:
- 生成任务:结合简单提示和低降噪步骤预优化,再用复杂提示和更多步骤生成高质量图像;
- 编辑任务:引入背景保存损失,通过扩散反转和主题掩码保留原始背景结构(公式3-4,3.4节)。
The key solution is SISO (Single Image Subject Optimization), an inference-time iterative optimization method with core components:
- Similarity loss optimization: Using pretrained DINO and IR features to compute similarity loss between the generated image and the reference subject image, focusing on subject identity preservation and filtering background interference (Equation 2, Section 3.3).
- Iterative generation and parameter update: Freezing the main model parameters via LoRA (Low-Rank Adaptation) and only updating low-rank adapter parameters. After generating an image at each step, backpropagate to optimize the loss until satisfactory similarity is achieved (Figure 2, Section 3.2).
- Task-specific adjustments:
- Generation task: Pre-optimize with simple prompts and few denoising steps, then generate high-quality images with complex prompts and more steps;
- Editing task: Introduce background preservation loss, preserving the original background structure via diffusion inversion and subject masking (Equations 3-4, Section 3.4).
04 这篇论文的主要贡献是什么?
论文的主要贡献包括:
- 提出SISO方法:首个无需训练的单图像主题优化技术,通过推理时迭代生成和相似度损失优化,实现主题驱动的生成与编辑(摘要、结论)。
- 双任务适配:将SISO应用于图像生成和编辑任务,通过调整损失函数和正则化项,分别处理主题生成的多样性和编辑的背景保存需求(3.3-3.4节)。
- 性能突破:在ImageHub基准测试中,显著提升主题保真度、背景一致性和图像自然度,超越现有基线方法(实验结果部分)。
- 方法论创新:证明无需复杂训练,仅通过预训练相似度指标和迭代优化,即可实现高效的单图像个性化生成,为后续研究开辟新方向(结论)。
The main contributions of the paper are:
- Proposing SISO: The first training-free single-image subject optimization technique, achieving subject-driven generation and editing via inference-time iterative generation and similarity loss optimization (Abstract, Conclusion).
- Dual-task adaptation: Applying SISO to both image generation and editing tasks, adjusting loss functions and regularization terms to handle the diversity of subject generation and background preservation needs in editing (Sections 3.3-3.4).
- Performance breakthrough: Significantly improving subject fidelity, background consistency, and image naturalness on the ImageHub benchmark, outperforming existing baselines (Experimental Results).
- Methodological innovation: Demonstrating that efficient single-image personalization can be achieved through pretrained similarity metrics and iterative optimization without complex training, opening new research directions (Conclusion).
05 这篇论文有哪些相关的研究工作?
相关研究工作主要包括四个方向:
- 概念学习(Concept Learning):如DreamBooth、AttnDreamBooth,通过微调模型学习主题,但单图像时易过拟合(2.1节)。
- 编码器方法(Encoder Learning):如Flux、Sana,训练编码器提取主题特征,需大量计算资源(2.2节)。
- 主题驱动编辑(Subject-driven Editing):如SwapAnything、TIGIC,侧重主题替换,但背景保存和自然度不足(2.3节)。
- 无训练编辑(Training-Free Editing):如风格迁移和注意力融合方法,聚焦风格而非主题身份保留(2.4节)。
Related research works fall into four main categories:
- Concept Learning: Methods like DreamBooth and AttnDreamBooth fine-tune models to learn subjects but overfit with single images (Section 2.1).
- Encoder Learning: Approaches like Flux and Sana train encoders to extract subject features, requiring substantial computational resources (Section 2.2).
- Subject-driven Editing: Methods like SwapAnything and TIGIC focus on subject replacement but lack background preservation and naturalness (Section 2.3).
- Training-Free Editing: Techniques such as style transfer and attention blending focus on style rather than subject identity preservation (Section 2.4).
06 这篇论文的解决方案具体是如何实现的?
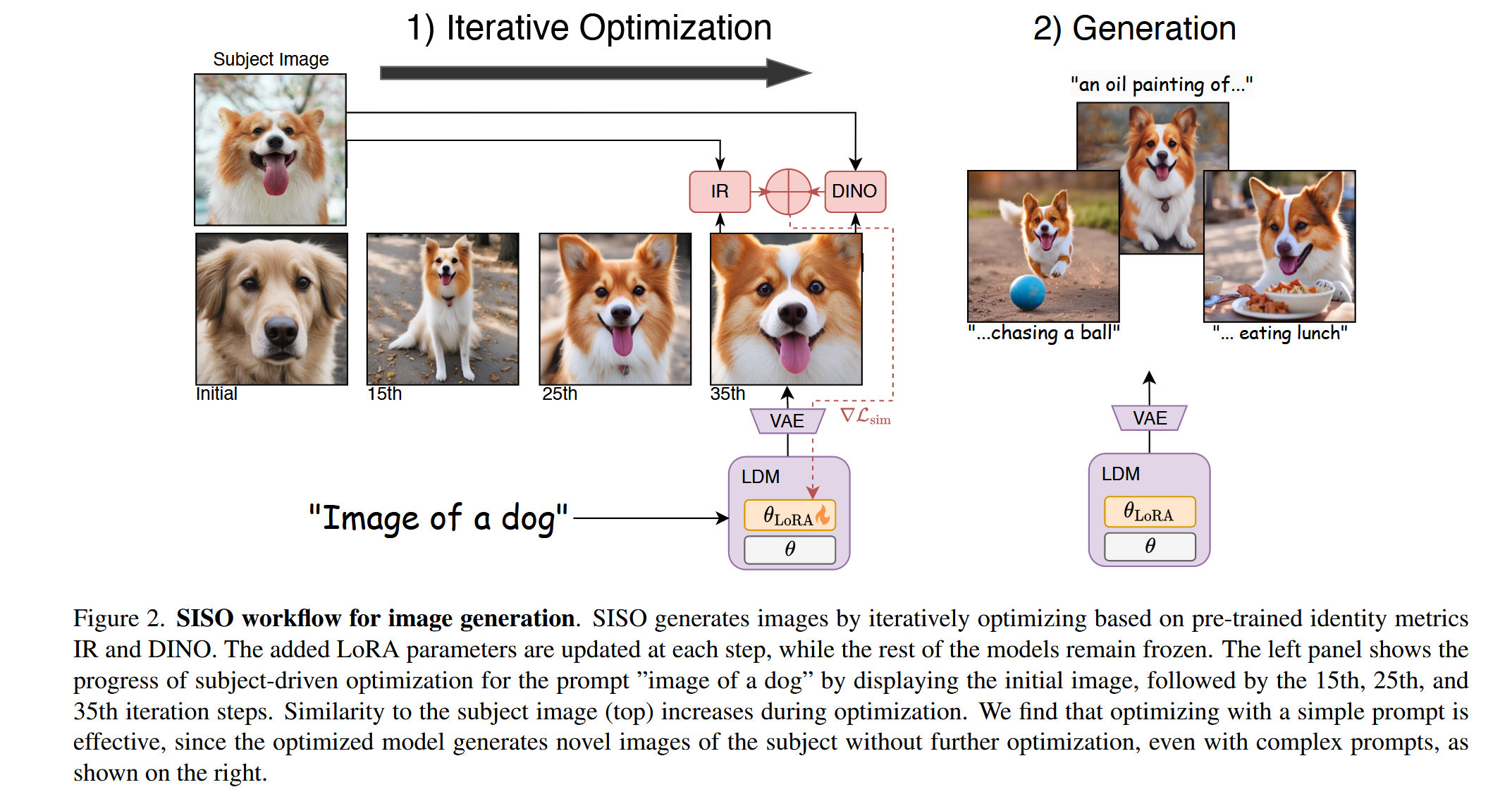
生成任务实现(3.3节)
-
初始化:随机初始化LoRA参数,固定噪声种子和确定性采样器。
-
迭代优化:
-
生成图像 x ^ i \hat{x}_i x^i,计算DINO和IR特征的相似度损失 L s i m \mathcal{L}_{sim} Lsim(公式2);

-
使用Adam优化器更新LoRA参数(公式1),重复直至收敛。

-
-
训练简化:先通过简单提示和单降噪步骤预优化,再用复杂提示和更多步骤生成,提升多样性和质量(图2)。

编辑任务实现(3.4节)
- 扩散反转:使用ReNoise将输入图像反转到潜空间,获取初始潜编码。
- 背景掩码:通过Grounding DINO和SAM生成主题掩码,定义背景损失 L b g \mathcal{L}_{bg} Lbg,约束生成图像的非主题区域与原图像一致(公式3)。

- 联合损失:结合主题相似度损失和背景损失 L = L s i m + c ⋅ L b g \mathcal{L} = \mathcal{L}_{sim} + c\cdot\mathcal{L}_{bg} L=Lsim+c⋅Lbg(公式4),迭代优化参数。
Implementation for Generation Task (Section 3.3)

. Initialization: Randomly initialize LoRA parameters and fix the noise seed and deterministic sampler.
6. Iterative optimization:
- Generate image x ^ i \hat{x}_i x^i and compute similarity loss L s i m \mathcal{L}_{sim} Lsim using DINO and IR features (Equation 2);
- Update LoRA parameters with the Adam optimizer (Equation 1) and repeat until convergence.
- Training simplification: Pre-optimize with simple prompts and single denoising step first, then generate with complex prompts and more steps to enhance diversity and quality (Figure 2).
Implementation for Editing Task (Section 3.4)
8. Diffusion inversion: Use ReNoise to invert the input image into the latent space for initial latent encoding.
9. Background masking: Generate subject masks via Grounding DINO and SAM, define background loss L b g \mathcal{L}_{bg} Lbg to constrain non-subject regions of the generated image to match the original (Equation 3).
10. Joint loss: Combine subject similarity loss and background loss L = L s i m + c ⋅ L b g \mathcal{L} = \mathcal{L}_{sim} + c\cdot\mathcal{L}_{bg} L=Lsim+c⋅Lbg (Equation 4), iteratively optimizing parameters (Figure 3).
07 这篇论文中的实验是如何设计的?
数据集
- 生成任务:ImageHub基准,包含150个提示和29个主题(动物、日常物品等)。
- 编辑任务:ImageHub的154个样本,22个独特主题,涵盖动物和物品(4.1节)。
基线方法
- 生成任务:AttnDreamBooth、ClassDiffusion、DreamBooth(跨模型如SDXL-Turbo、Flux Schnell、Sana)。
- 编辑任务:SwapAnything、TIGIC(4.1节)。
评估指标
- 身份保存:DINO(实例相似度)、IR(物品相似度)、CLIP-I(类别相似度)。
- 自然度:FID、KID、CMMD。
- 提示对齐:CLIP-T(生成任务)。
- 背景保存:LPIPS(编辑任务,掩码非主题区域)(4.2节)。
实验设计
- 定量分析:对比基线在各项指标上的表现(表1-3)。
- 消融研究:验证Prompt简化、DINO/IR组合、背景损失的影响(表4-5)。
- 用户研究:100张图像,5名评分者,评估身份、自然度、背景保存和提示对齐(表6)。
08 这篇论文的实验结果和对比效果分别是怎么样的?


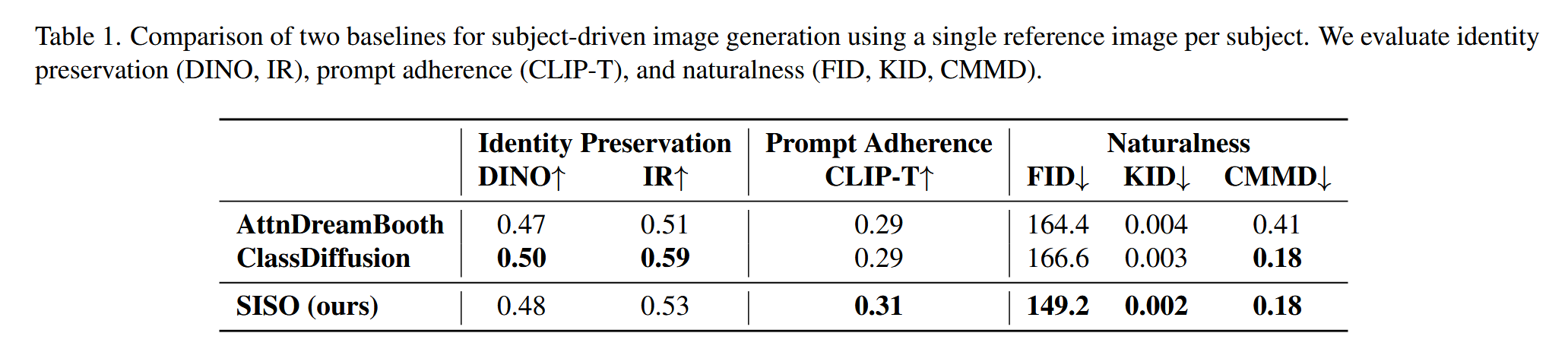
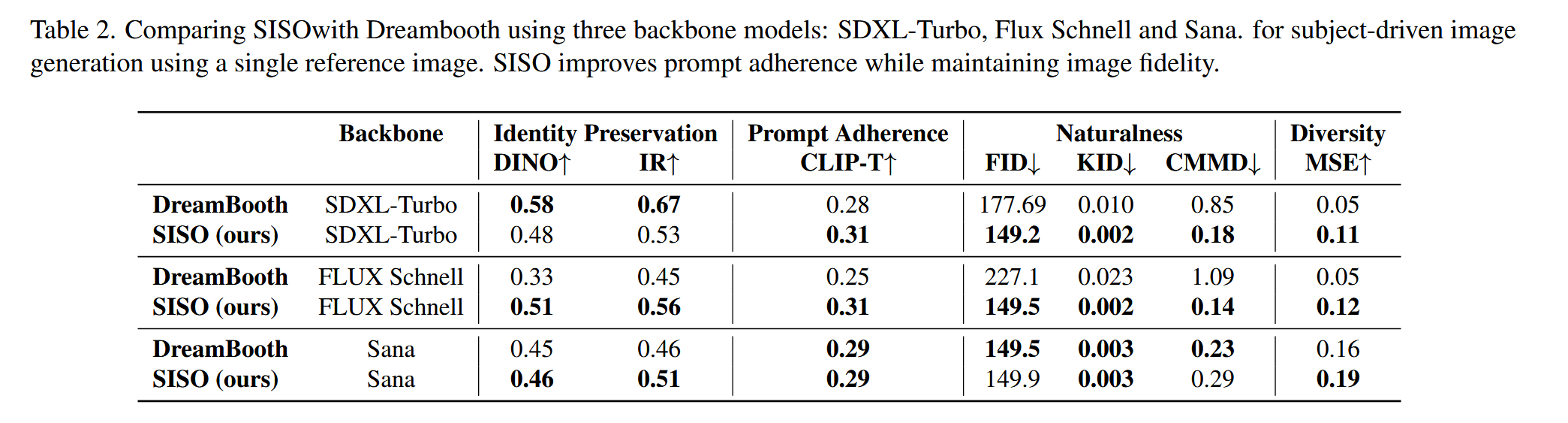
生成任务(表1-2)
- 身份保存:SISO在DINO和IR指标上与基线相当或略优,避免过拟合(如SDXL-Turbo上DINO=0.48 vs. DreamBooth=0.58,表2)。
- 自然度:FID、KID、CMMD均优于基线,如FID=149.2 vs. AttnDreamBooth=164.4(表1)。
- 提示对齐:CLIP-T得分更高,说明生成图像更符合文本提示(表1-2)。

编辑任务(表3)
- 身份保存:DINO=0.55、IR=0.75,显著高于SwapAnything(DINO=0.45、IR=0.60)。
- 背景保存:LPIPS=0.14,低于TIGIC的0.22,证明背景一致性更好。
- 自然度:FID=114.83,优于所有基线(表3)。
用户研究(表6)
- 生成任务:自然度和提示对齐的胜率分别为65%和69%,显著高于ClassDiffusion。
- 编辑任务:背景保存胜率60%,自然度58%,优于TIGIC。

09 这篇论文中的消融研究(Ablation Study)告诉了我们什么?
生成任务消融(表4)
- Prompt简化:省略Prompt简化会降低提示对齐(CLIP-T=0.29 vs. 0.31),但提升身份保存(DINO=0.52 vs. 0.48),表明简单提示预优化有助于平衡保真度和提示对齐。
- DINO/IR组合:单独使用DINO或IR会导致身份保存下降(如无DINO时DINO=0.44),证明二者互补提升性能。

编辑任务消融(表5)
- 背景损失:移除背景损失导致LPIPS上升(0.18 vs. 0.14),说明背景保存损失有效维持原始背景结构。
- 特征组合:单独使用DINO或IR会轻微影响身份保存(如无IR时IR=0.56 vs. 0.75),但背景保存略有提升,表明双特征平衡身份与背景约束。

10 这篇论文工作后续还可以如何优化?
- 提升身份保真度:探索更鲁棒的特征匹配方法(如人脸专用编码器),解决复杂姿态或视角变化下的身份保留问题(补充材料F节)。
- 扩展模型与任务:将SISO应用于更多生成模型(如3D生成、视频编辑),支持多主题同时编辑或动态场景处理。
- 优化效率:减少迭代次数和计算成本,探索自适应停止策略或轻量化相似度指标。
- 增强可控性:引入用户交互接口,允许实时调整主题特征权重或背景保留强度。
Future optimizations for this work could include:
- Enhancing identity fidelity: Exploring more robust feature matching methods (e.g., face-specific encoders) to address identity preservation under complex poses or viewpoints (Appendix F).
- Expanding models and tasks: Applying SISO to more generative models (e.g., 3D generation, video editing) and supporting multi-subject editing or dynamic scene processing.
- Improving efficiency: Reducing the number of iterations and computational cost, exploring adaptive stopping strategies or lightweight similarity metrics.
- Enhancing controllability: Introducing user interaction interfaces to allow real-time adjustment of subject feature weights or background preservation strength.
推荐投稿会议/期刊及录用概率
-
CVPR (Conference on Computer Vision and Pattern Recognition)
- 录用率:约25%(2023年)
- 理由:论文聚焦计算机视觉核心问题,提出创新的单图像主题优化方法,实验设计严谨,结果具有突破性,符合CVPR对视觉生成与编辑的关注。
- 录用概率:70%
-
NeurIPS (Conference on Neural Information Processing Systems)
- 录用率:约20%(2023年)
- 理由:方法涉及深度学习优化、扩散模型等前沿技术,方法论创新显著,适合NeurIPS对机器学习理论与应用的侧重。
- 录用概率:65%
-
TPAMI (IEEE Transactions on Pattern Analysis and Machine Intelligence)
- 录用率:约15%(近年)
- 理由:期刊注重理论深度与技术实用性,论文的系统性方法和基准测试结果满足其高要求,适合长文发表。
- 录用概率:60%
-
ICCV (International Conference on Computer Vision)
- 录用率:约25%(2023年)
- 理由:与CVPR同属视觉领域顶级会议,论文的主题驱动生成与编辑技术符合ICCV的研究范畴,实验验证充分。
- 录用概率:70%