基础学习:(9)vit -- vision transformer 和其变体调研
文章目录
- 前言
- 1 vit 热点统计
- 1.1 目标分类 / 基础与改进
- 1.2 轻量化 ViT / 移动部署优化(移动端)
- 1.3 密集预测(语义分割 / 深度估计等)
- 1.4 目标/词汇 检测
- 1.5 掩码改进
- 1.6 多模态/ 通用大模型
- 1.7 分布式训练 / 效果提升
- 1.8 任务特化应用(图表 / 语音 / 视频等)
- 2 重点网络分析
- 2.1 Transformers for Image Recognition at Scale
- 2.1.1 结构描述
- 2.1.2 embedding
- 2.2 Vision Transformers Need Registers
- 2.2.1 DINOv2
- 2.2.2 为什么DINO v2 有而v1没有?
- 2.3 FastViT
- 2.3.1 RepMixer
- 2.3.2 结构重参数化(Structural Reparameterization)
- 2.3.3 大核(7x7)卷积
- 2.4 Vision Transformers for Dense Prediction
- 2.4.1 encoder
- 2.4.2 Convolutional decoder
- 2.4.3 fusion
- 2.5 Exploring Plain Vision Transformer Backbones for Object Detection
- 2.6 BEIT V2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
- 2.6.1 VQ-KD
- 2.6.2 patch aggregation strategy
- 2.6.2 code book collapse
- 2.7 VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
- 2.7.1 Tokenization and Positional Encoding 和 DropToken:
- 2.7.2 Common Space Projection
- 2.7.3 Common Space Projection
- 2.7.4 only self attention
- 2.8 总结
- 2.8 Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
- 2.9 Qwen-VL
- 2.9.1 Naive Dynamic Resolution
- 2.9.2 Multimodal Rotary Position Embedding
- 2.9.3 Unified Image and Video Understanding
- 2.10 Colossal-AI
- 2.11 Neural Architecture Search using Property Guided Synthesis(NAS)
前言
transformer 是一条新的思路, 可以在 paper with code 上看到 vit 的火爆程度

其中 vit相关变体网络, 在 paper with code 上累计大概2000篇论文,如果一次都看没有意义,因此我这里统计了 前40 人气论文进行初步探索以增加 在 ViT方面的广度.
1 vit 热点统计
我这里根据paper with code 上前40的 论文进行统计,基本涵盖了 检测/识别/分割/深度识别/工程落地等几个方向.从
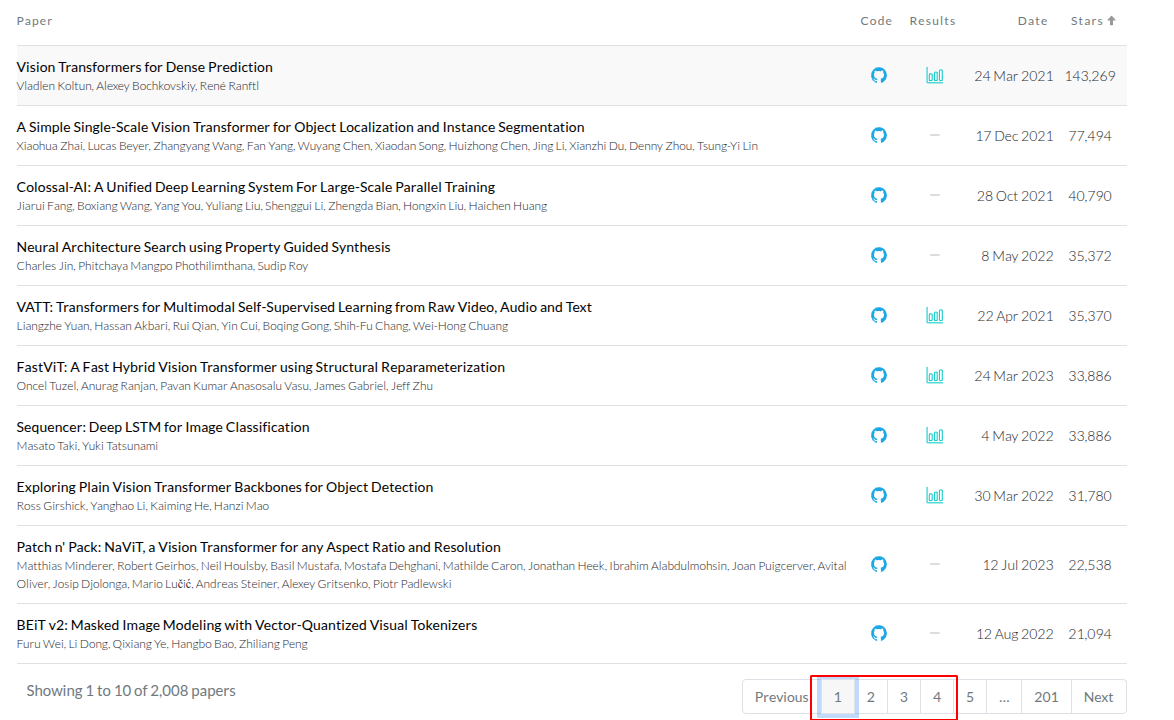
1.1 目标分类 / 基础与改进
| 名称 | 描述 | starts |
|---|---|---|
Transformers for Image Recognition at Scale | 原始 ViT 提出,图像 patch + Transformer | 11,261 |
| DeiT III: Revenge of the ViT | 高效训练技巧,无需大数据也能训练 ViT | 4,177 |
| Scaling Vision Transformers | 扩大 ViT 模型规模的训练优化 | 2,822 |
| Better plain ViT baselines for ImageNet-1k | ViT 标准 baseline 提升 | 2,822 |
Vision Transformers Need Registers | 引入寄存器 token 改善信息保留 | 10,300 |
| AutoFormer | 自动结构搜索 ViT 架构 | 1,742 |
| PVT v2 | 金字塔结构 Transformer,适合密集任务 | 1,797 |
1.2 轻量化 ViT / 移动部署优化(移动端)
| 名称 | 描述 | starts |
|---|---|---|
| MobileViT | CNN + ViT 融合,面向移动端 | 1,856 |
FastViT | 重参数化结构,高速高效 | 33,886 |
| Reversible Vision Transformers | 可逆结构,节省内存 | 6,901 |
| DepGraph | 针对 ViT 的结构剪枝优化 | 2,980 |
1.3 密集预测(语义分割 / 深度估计等)
| 名称 | 描述 | starts |
|---|---|---|
Vision Transformers for Dense Prediction | Dense Prediction Transformer(DPT)提出 | 143,269 |
| MiDaS v3.1 | 单目深度估计,ViT backbone | 4,834 |
| Depth Pro | 高效深度估计 | 4,357 |
A Simple Single-Scale ViT | 结构简单但效果强,分割与检测 | 77,494 |
| Efficient Track Anything | 任意目标跟踪模块 | 2,319 |
| Multi-Granularity Prediction for Scene Text Recognition | 场景文字识别,使用多尺度 ViT | 1,688 |
1.4 目标/词汇 检测
| 名称 | 描述 | starts |
|---|---|---|
| Simple Open-Vocabulary Object Detection with Vision Transformers | 支持开放类名目标检测 | 3,512 |
| Grounding DINO grounding + DINO | 组合用于大规模目标检测 | 7,889 |
Exploring Plain Vision Transformer Backbones for Object Detection | 研究纯 ViT backbone 在检测中的性能 | 31,780 |
1.5 掩码改进
| 名称 | 描述 | starts |
|---|---|---|
BEiT v2 | 自监督视觉 tokenizer + Masked Modeling | 21,094 |
| Emerging Properties in Self-Supervised Vision Transformers | ViT 自监督下的泛化与行为分析 | 6,777 |
| Improving Pixel-based MIM by Reducing Wasted Modeling Capability | 提升掩码建模 token 利用率 | 3,635 |
VATT | 跨模态(视频/音频/文本)自监督预训练 | 35,370 |
1.6 多模态/ 通用大模型
| 名称 | 描述 | starts |
|---|---|---|
Grounded SAM | ViT 结合 SAM,用于泛化视觉任务 | 16,148 |
Qwen-VL Technical Report | 多模态 GPT-VL,视觉编码为 ViT | 9,904 |
| Yi: Open Foundation Models by 01.AI | 通用多模态开源模型 | 7,831 |
| InternLM-XComposer2-4KHD | 视觉输入自适应支持 4K | 2,813 |
1.7 分布式训练 / 效果提升
| 名称 | 描述 | starts |
|---|---|---|
Colossal-AI | 分布式训练系统,支持大规模 ViT | 40,790 |
Neural Architecture Search using Property Guided Synthesis | 结构搜索提升 ViT 表现 | 35,372 |
| Pyramid Adversarial Training Improves ViT Performance | 对抗训练增强鲁棒性 | 3,512 |
1.8 任务特化应用(图表 / 语音 / 视频等)
| 名称 | 描述 | starts |
|---|---|---|
| TinyChart | 图表结构理解与 token 合并 | 2,158 |
| FastFlow | 基于 ViT 的无监督异常检测 | 2,789 |
| S4ND | 视频状态建模(state space + transformer) | 2,609 |
| Pushing the Limits of Self-Supervised Speaker Verification using Regularized Distillation | ViT 用于语音验证的蒸馏框架 | 1,932 |
2 重点网络分析
2.1 Transformers for Image Recognition at Scale
2.1.1 结构描述
和 nanogpt 不同的是 ViT 只有encoder 结构, Nano GPT 是 decoder only.
[ViT / BERT] (Encoder-only): input → Attention(no mask) → FFN → Output
[NanoGPT / GPT] (Decoder-only): input → Attention(masked, 也就是 只能看到过去的token) → FFN → Output
这是 ViT 的 attention 过程,没有 mask 所以 qkv 输出可以直接懟到输出上. 其中欧冠你 attend 是 softmax
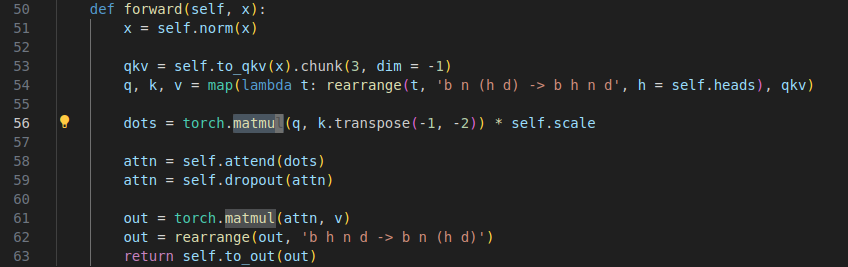
看代码也可以看到 nano gpt 仅仅是增加了一个mask 过程.其他和 vit 无差别.

2.1.2 embedding
作为图像处理最主要的就是如何将图像编码,
可以看到ViT 就是将图像 分成 3 * 16 * 16 的 小 patch, 每个patch 中的 一个 pixel 就是属于 layerNorm中的一个维度, 比如这里 3 * 16 * 16 刚好是 768.
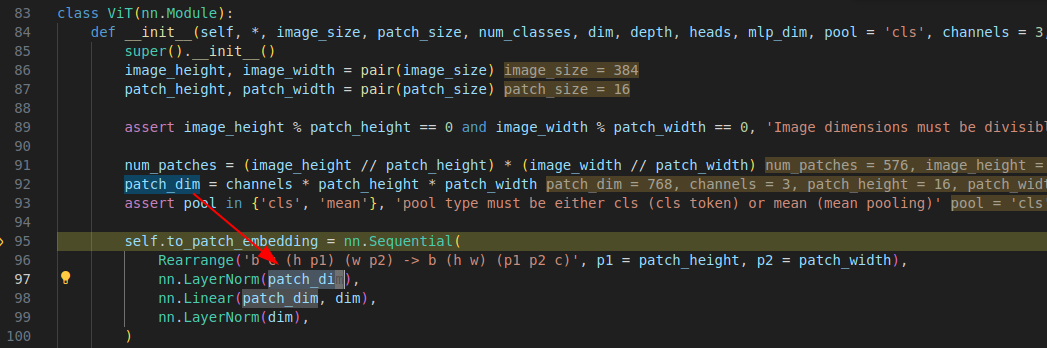
我个人在实践的时候发现,如果用 hugging face 的 pretrained 模型,将其参数迁移ViT(当然 ViT进行了改动,但是分类结果和 hugging face的不一致…不过作为调研和学习足够了,剩下的工程化过程再解)
2.2 Vision Transformers Need Registers
其实这个人气并不是 这篇论文,而是 DINOv2 一个自监督学习ViT

2.2.1 DINOv2
其实原论文比较朴素, 就是在 ViT 训练中,发现经常有artifacts 出现, 下图就是 “高范数伪影的特征”, 这些token的范数约为其他token的10倍,占总token数量的约2%。这些token通常出现在图像的背景区域,原本信息量较低, 但携带更多的全局信息。
这种情况出现在例如图中的 DINO v2 非常多平坦区域的artifact, 而 DINO v1 几乎没有.
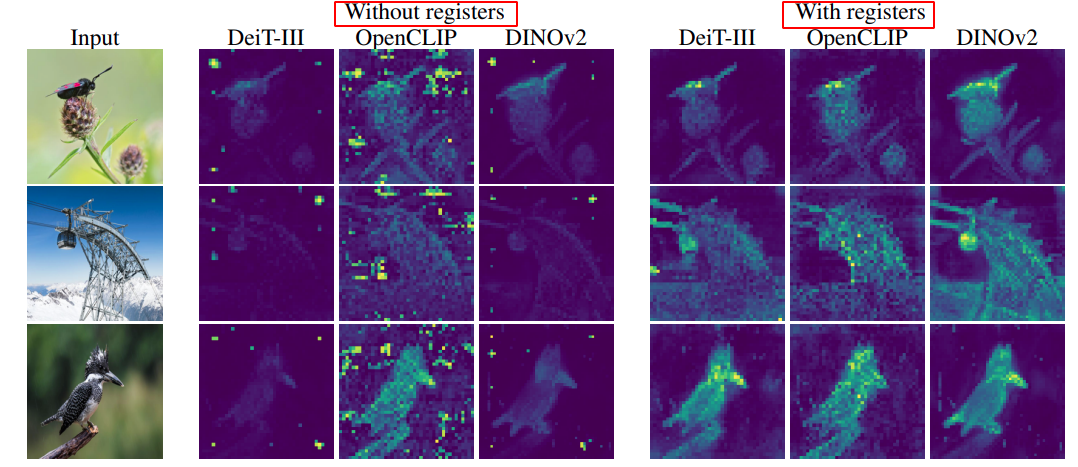
2.2.2 为什么DINO v2 有而v1没有?
原因一:训练目标不同(Contrastive vs. Distillation)
DINO v1 使用的是 对比学习(contrastive learning),目标是学习空间上连贯、语义一致的 embedding。它鼓励所有 token 都有意义(避免冗余 token)。会对异常 token 产生惩罚。所以模型不会“偷偷”把背景 patch 用作临时内存。
原因二:模型容量更大,ViT 有“懒惰策略”
训练目标更复杂,主要关注 cls token 的表现。对 patch token 的约束变弱,模型更容易利用背景区域做“缓存”。
原因三:DINO v1 更强的 per-token 学习机制
DINO v1 每个 patch token 都被要求有一致性输出(比如用不同视角增强后的结果一致)。而 DINO v2 由于有 teacher-student distillation 和更多 cls-guided 目标,patch token 不一定需要一致。
说实话我觉得 cls-guided 才是罪魁祸首.
ViT 分类策略中经常有:[CLS] + patch_1 + patch_2 + … + patch_n 这种方式 CLS token 就成了全局
因为论文作者这么说:The root cause of the artifact is that ViTs are usually supervised via the [CLS] token only, allowing the model to utilize other tokens for internal memory without constraint.
所以作者引入了更多的全局 register 变为:[CLS] + Register1 ,…,Register R, patch_1 + patch_2 + … + patch_n
说白了就是从 [CLS] + N 个 patch token 变为 [CLS] + R 个 Register token + N 个 patch token
2.3 FastViT
fastViT 来自于苹果. 目标是做一个卷积和Attention 的低延时混合架构,因为这种架构有效地结合了 CNN 和 Transformer(以前的构架是 cnn 后面懟个transformer, 这里是融合) 的优势,在多个视觉任务上有竞争力。本文的目标是建立一个模型,实现 SOTA 的精度-延时 Trade-off.
核心点有三个:
(1)结构重参数化(Structural Reparameterization)
该模块利用结构重参数化技术,在训练阶段采用具有跳跃连接的复杂结构以增强表示能力,而在推理阶段将其简化为更高效的结构,从而降低内存访问成本并提高推理速度。
这里包括 repmixer 和
(3)大核(7x7)卷积的应用
FastViT 在保持低延迟的同时,利用大核卷积增强模型的感受野和特征提取能力,从而提升精度。
其整体结构如下(苹果工程师写的论文真的非常清晰, 看得巨爽):
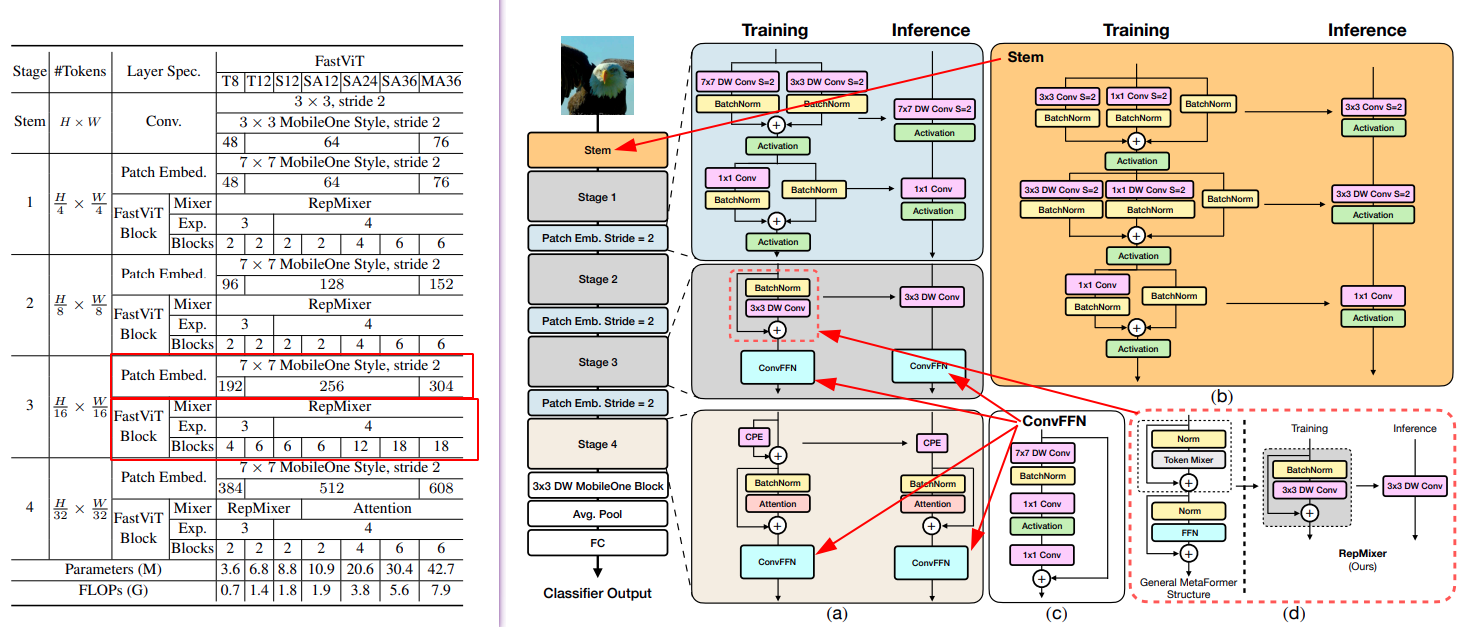
图中 DW 指depthwise, 最左侧是整体数据流. 每个子图中写明了 training 的结构和inference结构. 按照描述 每个"Patch Emb. stride=2" 都是相同结构. stage1-3 也是相同结构(原文是这么描述的 Stages 1, 2, and 3 have the same architecture and uses RepMixer for token mixing)
2.3.1 RepMixer
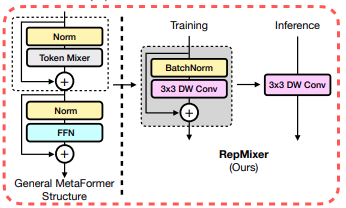

这个结构可以有效减少 memory 访问 开销. 其实 repmixer 是 结构参数化的一部分,只是比较重要,我单独拎出来说.
2.3.2 结构重参数化(Structural Reparameterization)
Output = Conv(x) + x # skip connection
和 2.3.1 一样,只是2.3.1 单独拎出来说.
2.3.3 大核(7x7)卷积
作者指出,如果用 self-attention 计算负担较重,所以引入了大核卷积. 而且作者指出已有 卷及可以替代 attention

2.4 Vision Transformers for Dense Prediction
这是 vit 里的爆款. 应用于像素级的密集预测任务,如语义分割和单目深度估计. 对于很多分割任务, 传统的卷积神经网络(CNN)在处理密集预测任务时,通常采用编码器-解码器结构。编码器逐步下采样输入图像,以提取多尺度特征;解码器则将这些特征逐步上采样,恢复到原始分辨率。然而,这种下采样-上采样的过程可能导致细节信息的丢失,尤其是在深层次的特征中。典型例子就是 UNet.
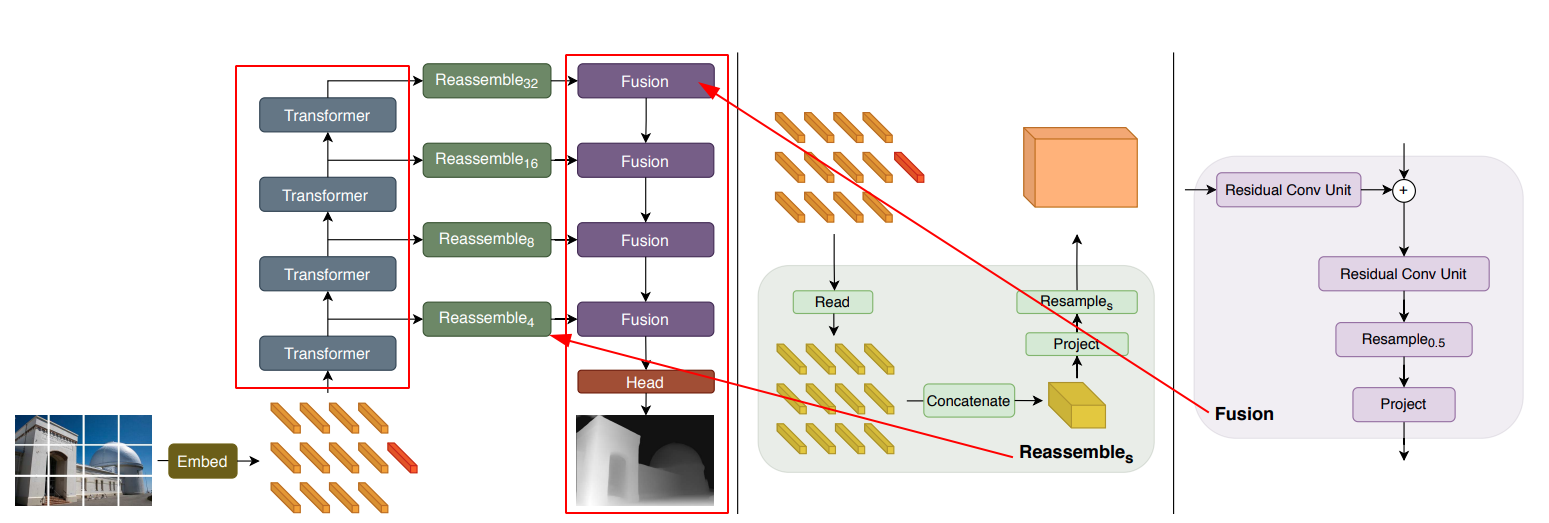
2.4.1 encoder
Encoder部分就是VIT. ViT 输出的 token 被重构为不同尺度的 feature maps,用于密集预测.
2.4.2 Convolutional decoder
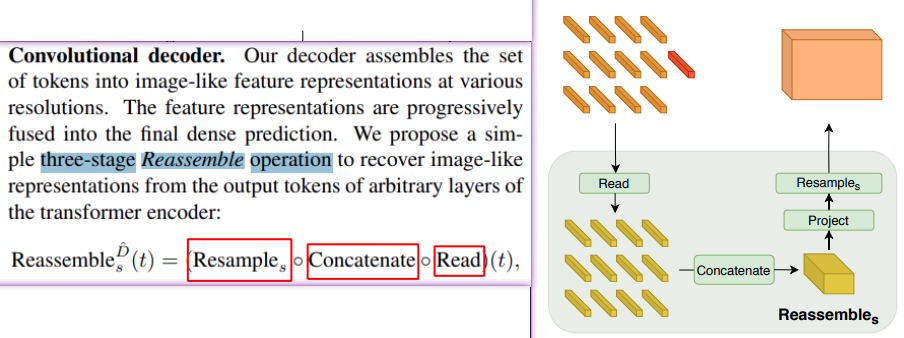
我是这么理解的:
1 如果有, 那么要去掉 [CLS] token
2 因为ViT 的 token 是 3 * patch_height * patch_width 我们用 N = h * w
所以卷积就可以 将 数据从 (B, N, D) 卷积为 (B, D, h, w), 也就是 将N 展开 为 h, w.
2.4.3 fusion
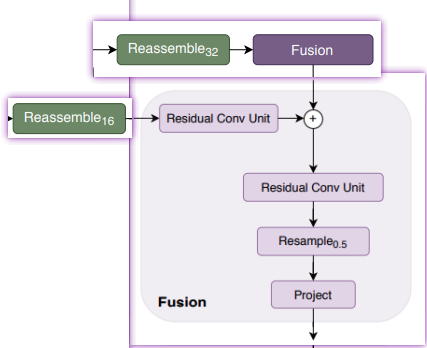
看来这里也需要不同尺寸的数据, 进行 crouse to fine 的进行判断. 这里 没什么特别的地方和UNet 非常像.
2.5 Exploring Plain Vision Transformer Backbones for Object Detection
这个ViT 是 何凯明大神的工作–SFP 简单特征金字塔
如截图, 就是研究什么模块发挥什么作用.

2.6 BEIT V2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
这里有个几个词汇:
(1) patch aggregation : patch 汇集
(2) code book collapse: 在 VQ(Vector Quantization)训练中,一个常见问题是 codebook collapse,即只有少数几个 code(离散码)会被频繁使用,大多数 code 永远用不上
首先作者肯定了Masked image modeling (MIM) 在自监督学习上的效果, 同时也指出问题就是 大部分的已有工作都是在 low-level image pixels 上搞事情, 所以本文提出了一个 方法将 MIM 从 pixel-level 提高到 semantic-level.
作者提出了一个自监督的网络,并且有如下贡献:
1 使用 Vector-Quantized Knowledge Distillation (VQ-KD),也就是使用一个强大的视觉教师模型(比如 RegNet)生成 soft target,然后再离散化成视觉 token。
2 提出了一个 patch汇合策略(patch aggregation strategy), 这个策略会基于给定的离散语义token上增强全局结构.

2.6.1 VQ-KD
VQ-KD 的结构如下图:
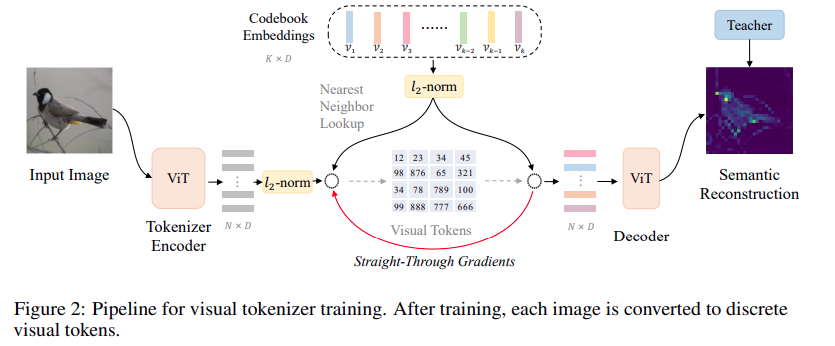
这里要说明的是,其实作者工作内容没有那么牛逼:
1 构建了一个 codebook
2 将输入图片通过ViT 生成 token
3 和 code book 比较 二范式的距离, 进行翻译后 得到一个 visual token
4 再将visual token 送给decoder 也是 ViT, 得到一个 semantic reconstruction, 这个reconstruction 可以 和 老师 模型的 reconstruction 进行比较
所以 VQ 就是常见做法, KD 就是 用一个 teacher 模型 比较下结果, 就这么简单.
这里我说下 VQ, 先要定义一个离散隐变量空间KaTeX parse error: Undefined control sequence: \inR at position 2: e\̲i̲n̲R̲^{K*D}, 也成为embedding 空间. 其中 K 是空间大小, D 是 每个embedding向量 e i e_i ei的维度.所以得到一个 encoder 的输出token可以按照下述方法量化:
z q ( x ) = Q u a n t i z e ( z e ( x ) ) = e k 其中 , k = a r g m i n i ∣ ∣ z e ( x ) − e i ∣ ∣ 2 z_q(x) = Quantize(z_e(x)) = e_k 其中 , k= arg min_i || z_e(x) - e_i||_2 zq(x)=Quantize(ze(x))=ek其中,k=argmini∣∣ze(x)−ei∣∣2 也就是图中说的找二范数距离.
该方法和之前的方法: VQ-VAE非常像,只不过红框内换成了 ViT
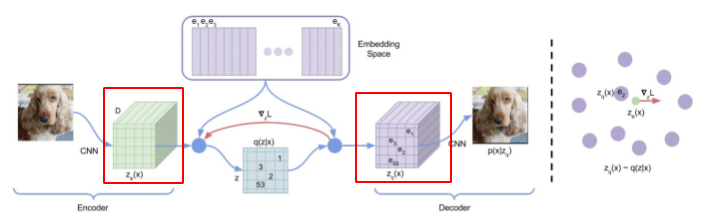
VQ-VAE的讲解可以看:https://zhuanlan.zhihu.com/p/463043201,
2.6.2 patch aggregation strategy
这个 aggregation 比较常见,这里做一个对比
| 传统 CNN | ViT 的 Patch Aggregation |
|---|---|
| 卷积 + 池化 | patch 合并 + 投影 |
| 多层感受野变大 | token 数量减少,语义增强 |
下图 是作者列出的 patch aggregation strategy, 和 很多 ViT 一样, 用[CLS] token 与所有 patch token 建立关联,从而提升模型的全局理解能力, 后面基层的token 只用 cls 前面
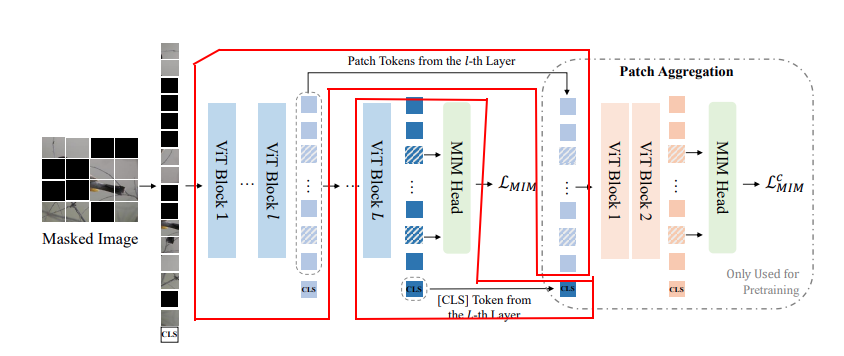
代码中也可以看到 ,前6层作为一个输入,后6层的 cls 作为 一个 输入, 送入两层的ViT中,就是这么简单
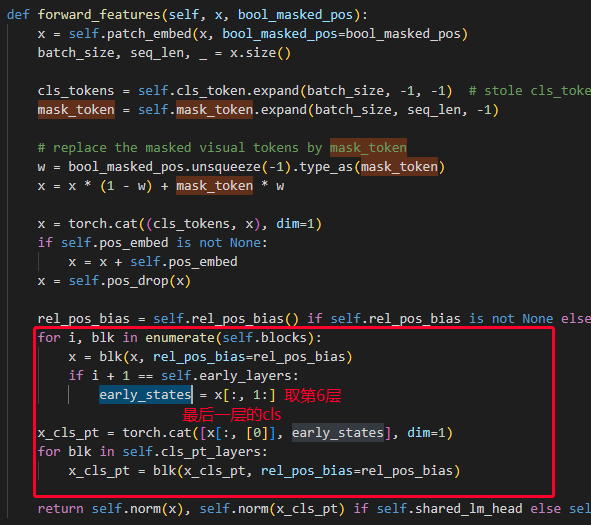
来自:https://blog.csdn.net/weixin_50862344/article/details/131262830
2.6.2 code book collapse
作者
2.7 VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
框架的核心思想是使用纯 Transformer 架构(无卷积)从原始的多模态数据(视频、音频和文本)中学习通用的表示。VATT 通过对比学习的方式进行训练,能够在多个下游任务中实现优异的性能.
该论文中定义:
视觉模态(vision modality): rgb 的 video
听觉模态(audio modality): 就是声波
文本模态(text modality): 就是字符串
注意这里有个概念 voxel: 是 "volume" + "pixel" 的组合词,表示三维空间中的一个小立方体单位,就像像素是二维图像中的最小单位一样。
该论文有益点有3:
(1) Tokenization and Positional Encoding 和 DropToken:
(2) Common Space Projection
(3) Multimodal Contrastive Learning
2.7.1 Tokenization and Positional Encoding 和 DropToken:
对于video 数据:
假设整个 video 数据尺寸是 THW , 一个 patch 大小 是 t * h * w, 那么就可以将 video转为 ⌈ T / t ⌉ × ⌈ H / h ⌉ × ⌈ W / w ⌉ \lceil T/t \rceil \times \lceil H/h \rceil \times \lceil W/w \rceil ⌈T/t⌉×⌈H/h⌉×⌈W/w⌉ 个 patch.
注意: 最小单元 是 t * h * w * 3 叫做 voxel
因此对于 video 形成的可用于训练学习的 weight 为 W v p ∈ R t ∗ h ∗ w ∗ 3 × d W_{vp} \in R^{t*h*w*3 \times d} Wvp∈Rt∗h∗w∗3×d , d 是向量的维度. 也就是 d 个 voxel. vp 指 video position
对于 auido 数据:
假设整个audio 数据是1D 数据,长度 为T’, 那么就是 ⌈ T ′ / t ′ ⌉ \lceil T'/t' \rceil ⌈T′/t′⌉
因此对于 audio 形成的可用于训练学习的 weight 为 W a p ∈ R t ′ × d W_{ap} \in R^{t' \times d} Wap∈Rt′×d , d 是向量的维度. 也就是 d 个 voxel. ap 指 audio position
对于 text 数据:
和 nanogpt 基本一样, 映射到 一个字典空间中, 该空间 是 v*d, v 指 vocabulary size.
那么有 W t p ∈ R v × d W_{tp} \in R^{v \times d} Wtp∈Rv×d
得到最终 embedding
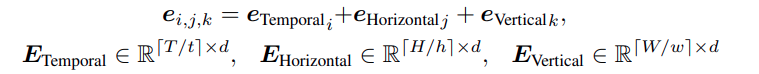
因此, 可以看到 只有 video 有 hoizon 和 vertical 分量, text 和 audio 都没有.
| 模态 | 使用的位置信息 | 说明 |
|---|---|---|
| Text | Temporal(时间/顺序) | 文本是一个自然的序列:第1个词、第2个词… |
| Audio | Temporal(时间帧序列) | 通常使用音频的时间维度进行帧级patch划分(例如 spectrogram),也只用1D位置编码 |
| Video | Temporal Horizontal + Vertical | 视频是三维结构(时间 × 高 × 宽),所以需要 3D 位置编码 |
DropToken 和 dropout 类似,就是随机丢掉token :
(1) 防止过拟合
(2) 防止 过分以来某个token
2.7.2 Common Space Projection
首先说明下两个专有词汇:三元组: video-audio-text triplet 以及 语义粒度: semantic granularity.
接着,作者定义了两个 pair: video-audio pair 和 video-text pair 如图:

我这里 有个疑问, 为什么没有text-> audio 的空间? 我是这么理解的, 因为 video 维度最全,信息最多, 音频 和 text 都是 粗粒度的,因次有 video->audio 和 video->text
2.7.3 Common Space Projection
这里 还有个细节:
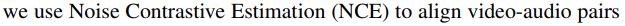
而
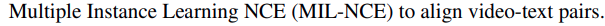
这里有这样的 理解: video 和 audio 可以时序对应起来 ,但是 text 不是.
所以 video 和 audio的 就是对应求NCE 也就是这个公式
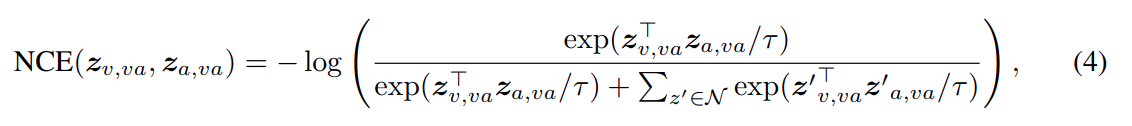
因为 text 和 video 不是这样映射, 因此有:
给定 video feature: z v , v t \mathbf{z}{v,vt} zv,vt 和一组与之对应的文本特征集合 z t , v t {\mathbf{z}{t,vt}} zt,vt (有多个! 所以需要 Σ \Sigma Σ)
其中: P P P 是这些文本的集合,都是正样本; N \mathcal{N} N 是负样本集合。
所以就有了下面论文中哦个你的公式
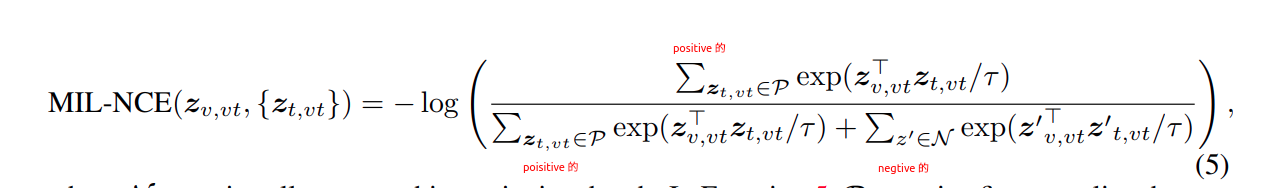
这个公式整体也是个 softmax
因为是 triplet 关系,所以最后最后来了个整体 loss:
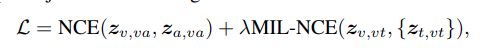
2.7.4 only self attention
2.7.3 中的 NCE 就是在各自模态下算特征, 所以 VATT 没有 cross attention, 总结下 (和 后面 的 Qwen 大模型不一样的思路):
Video Encoder: 纯视频特征 -> 自己的Transformer(Self-Attention)
Audio Encoder: 纯音频特征 -> 自己的Transformer(Self-Attention)
Text Encoder: 纯文本特征 -> 自己的Transformer(Self-Attention)
Late Fusion: 三个特征合并
2.8 总结
step1: 每个模态(Video, Audio, Text)单独走自己的 Transformer Encoder
(1)输入是patch embedding(视频帧patch、音频帧patch、文本tokens)
(2)每个Transformer内部是纯Self-Attention
(3)得到一个 [CLS] token 或者 global pooled特征
step2: 模态内自己加个小MLP头(projection head)
(1)让每个模态的 [CLS] 特征,变成一个统一长度(比如512维)的向量
(2)用来放到共享对比空间里
step3 :对比损失(NCE)
(1) Audio和Video特征计算 InNCE loss
(2)Video和Text特征计算 multi-NCE loss
(3) vt loss 和 va-loss 相加, 得到特征计算 InfoNCE loss
2.8 Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
论文里的这张图清晰地说明了 Grounded DAM 是什么 以及 可以做什么

其他没有啥了
2.9 Qwen-VL
论文地址 https://arxiv.org/pdf/2409.12191 Qwen-VL 没有开源,只给了 modeling 和 fine tunning.
词汇:scaling laws: 扩展规律
我们先了解下 Qwen-VL 结构
如果说的简单一些, 千问模型就是 vit + llm.
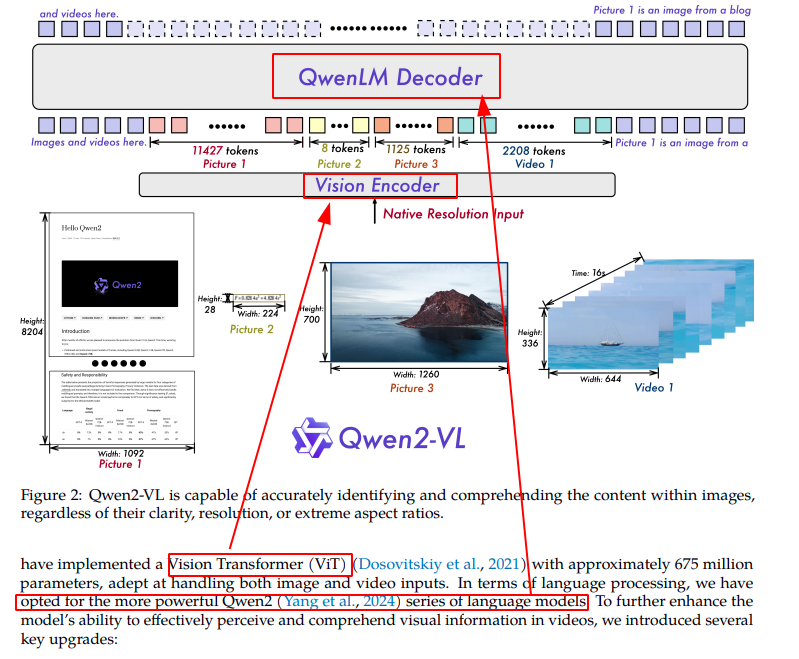
但是千问团队绝没有这么简单. 根据文章描述,
2.9.1 Naive Dynamic Resolution

很简单
train 过程就是 加了2D-RoPE
infernece 过程用的还是将其形成1D token 并且将 2x2 的 位置关系的token 压缩为一个token.

2.9.2 Multimodal Rotary Position Embedding
注意这里有个细节, 在 ViT 部分,作者用了RoPE

但是在 llm 部分,如果还用RoPE 那么就有问题, 因为用1D 位置编码限制了模型对于空间(space)和时序(temporal)上的变化. 所以本文提出了 MRoPE
这里 附上苏剑林大佬的博文,写的挺好的https://www.spaces.ac.cn/archives/10040
代码实现见:
https://github.com/huggingface/transformers/blob/1759bb9126e59405f58693a17ef9f58040c2008b/src/transformers/models/qwen2_vl/modeling_qwen2_vl.py#L1357
不赘述
2.9.3 Unified Image and Video Understanding
(1) 采取一秒取两帧
(2) 用了3D-conv 一次卷积两个input(就是一秒的两帧)
2.10 Colossal-AI
分布式ai 训练库, 重要的分布式训练工程, 不赘述.
2.11 Neural Architecture Search using Property Guided Synthesis(NAS)
这个工程就是大名鼎鼎的 NAS, 就是大力出奇迹,就是用大量的计算资源来试网络,帮你设计网络, 这样不用低效的人工探索.
这个工程地址:https://github.com/google-research/google-research
知乎的这篇讲解非常好,不赘述: https://www.zhihu.com/question/359162202