关于Spark知识点与代码测试的学习总结
在大数据技术飞速发展的时代,Spark 作为分布式计算框架的佼佼者,在数据处理、分析和机器学习等领域展现出强大的性能和广泛的应用前景。作为一名大数据相关专业的大学生,为了提升自己在大数据领域的技能,适应未来职业发展的需求,在老师的带领下,我深入学习了 Spark 技术。
我在自己的笔记本电脑上搭建了 Spark 开发环境,包括安装 Java、Scala、Spark 等软件,并配置相关环境变量。通过本地环境的搭建,我熟悉了 Spark 的安装和配置过程,为后续的实践操作打下了基础。
在学习知识点和代码测试中,使我掌握了 Spark 的核心原理和架构,包括 RDD、Spark SQL、Spark Streaming 等核心组件的使用方法。
当然在学习的过程中也是困难重重,在搭建 Spark 开发环境时,遇到了 Java 版本不兼容、Scala 和 Spark 版本匹配等问题。在学习 Scala 和 Spark 编程时,对一些语法和 API 的使用不太熟悉,导致代码编写困难等,还好通过查找资料和仔细审查等解决了这些难题。以下就是我在学习过程中掌握的知识点以及所学代码的测试:
安装Spark
一、Spark
1.Spark 是一种由 Scala 语言开发的快速、通用、可扩展的大数据分析引擎
2.Spark Core 中提供了 Spark 最基础与最核心的功能
3.Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
4.Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。
- 开启三台linux虚拟机
2.准备好spark的压缩包
步骤:
- 将spark的安装包上传到虚拟机node01中(建议路径:/opt/software/spark)并解压缩文件。将解压文件夹重命名为spark-local
解压:tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz
重命名:mv spark-3.0.0-bin-hadoop3.2.tgz spark-local
- 启动Local环境。进入spark-local中,执行如下命令:
bin/spark-shell
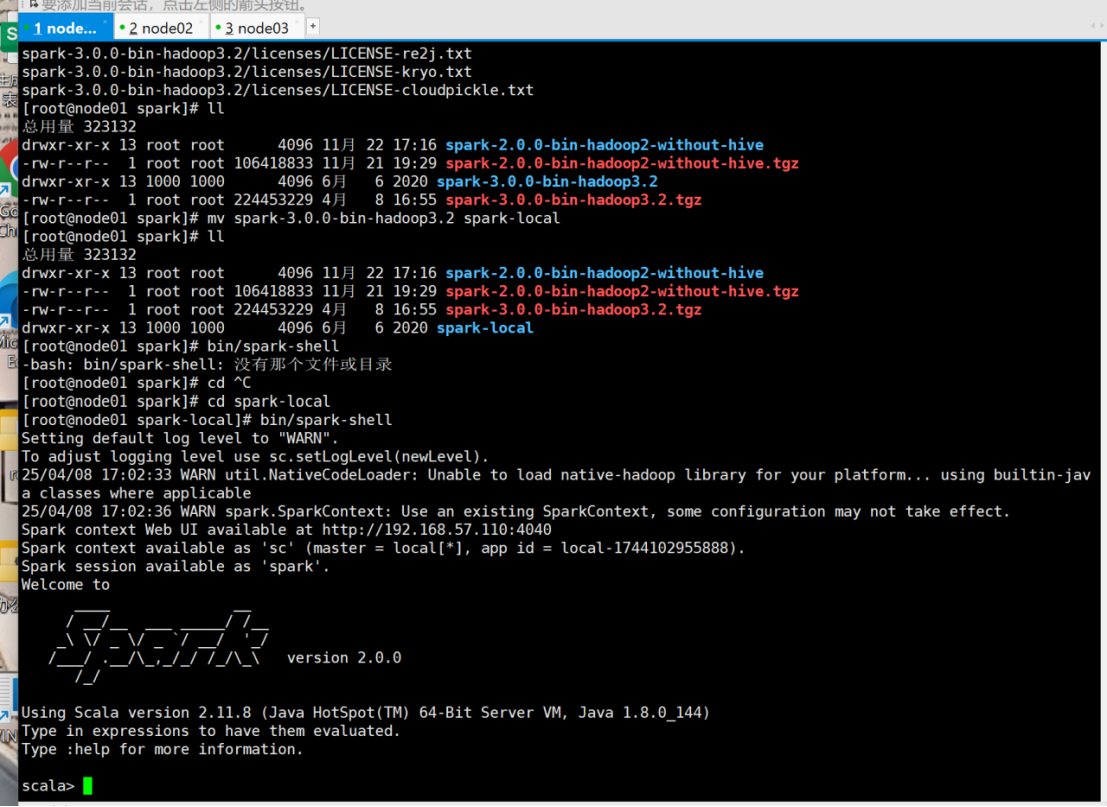
启动成功后,可以输入网址进行Web UI监控页面进行访问。
- 命令行工具
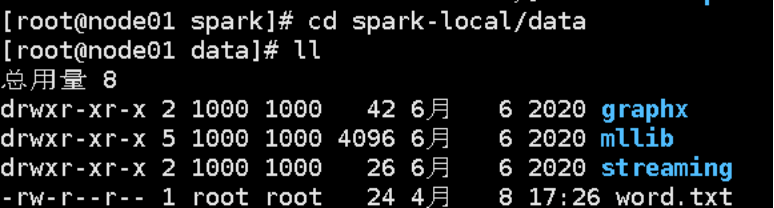
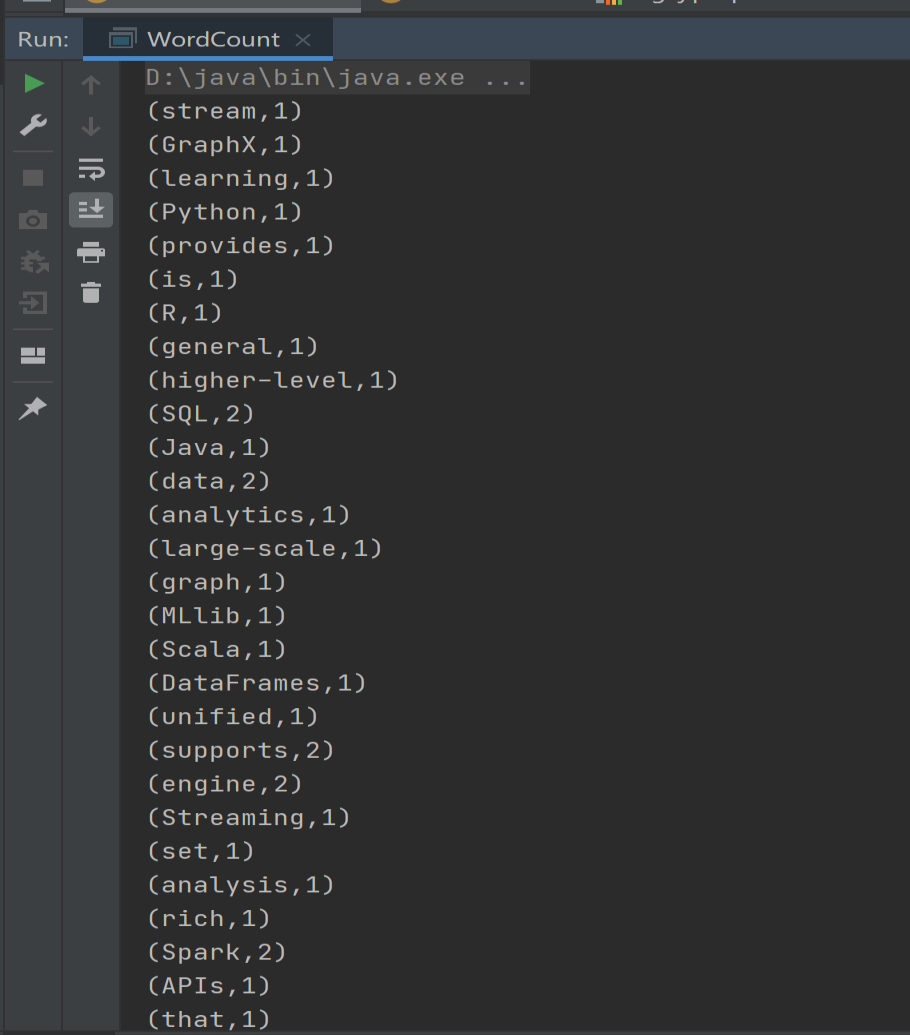
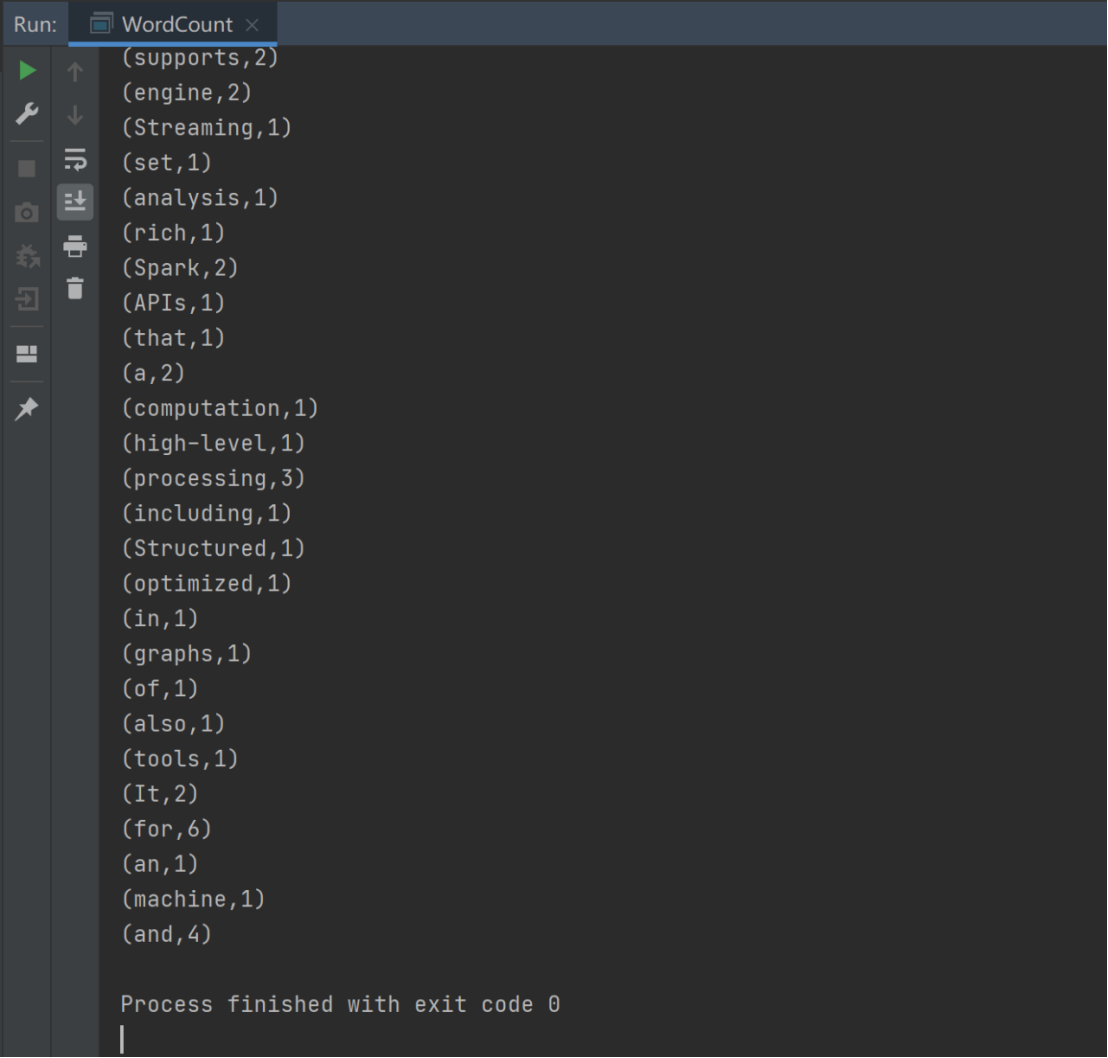
在解压缩文件夹下的 data 目录中,添加 word.txt 文件。

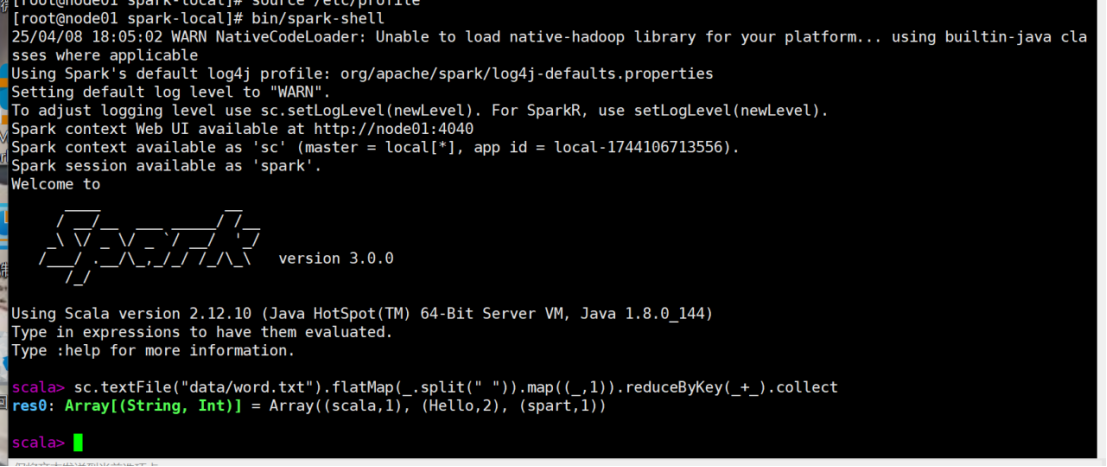
在命令行工具中执行如下代码指令。
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
- 提交测试应用
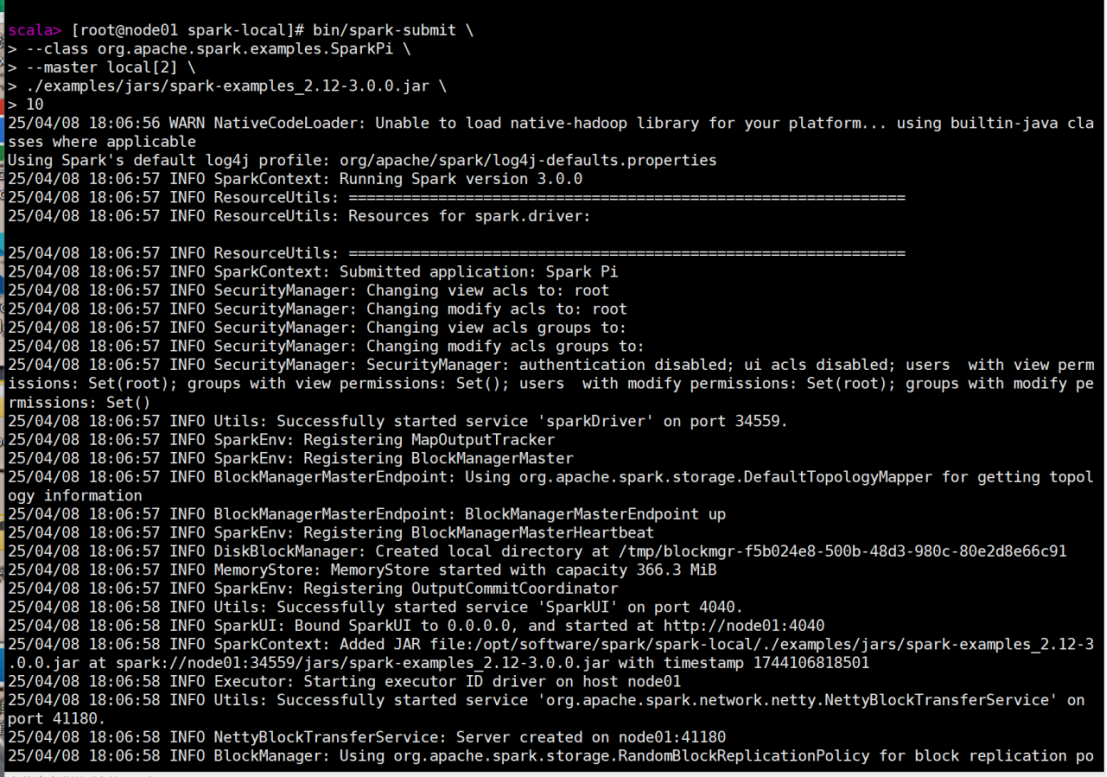
在spark-local路径中输入以下指令:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.0.0.jar \
5.
指令说明:
1) --class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
2) --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
3) spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,实际使用时,可以设定为咱们自己打的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
运行结果:
Spark运行架构
运行架构
Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。
RDD相关概念
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
RDD : 弹性分布式数据集
累加器:分布式共享只写变量
广播变量:分布式共享只读变量
RDD
什么是 RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
Spark-Core编程
Spark Core
Spark-Core编程(二)
RDD转换算子
RDD 根据数据处理方式的不同将算子整体上分为 Value 类型、双 Value 类型和 Key-Value 类型。
Value类型:
- map
➢ 函数签名
def map[U: ClassTag](f: T => U): RDD[U]
➢ 函数说明
将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换。
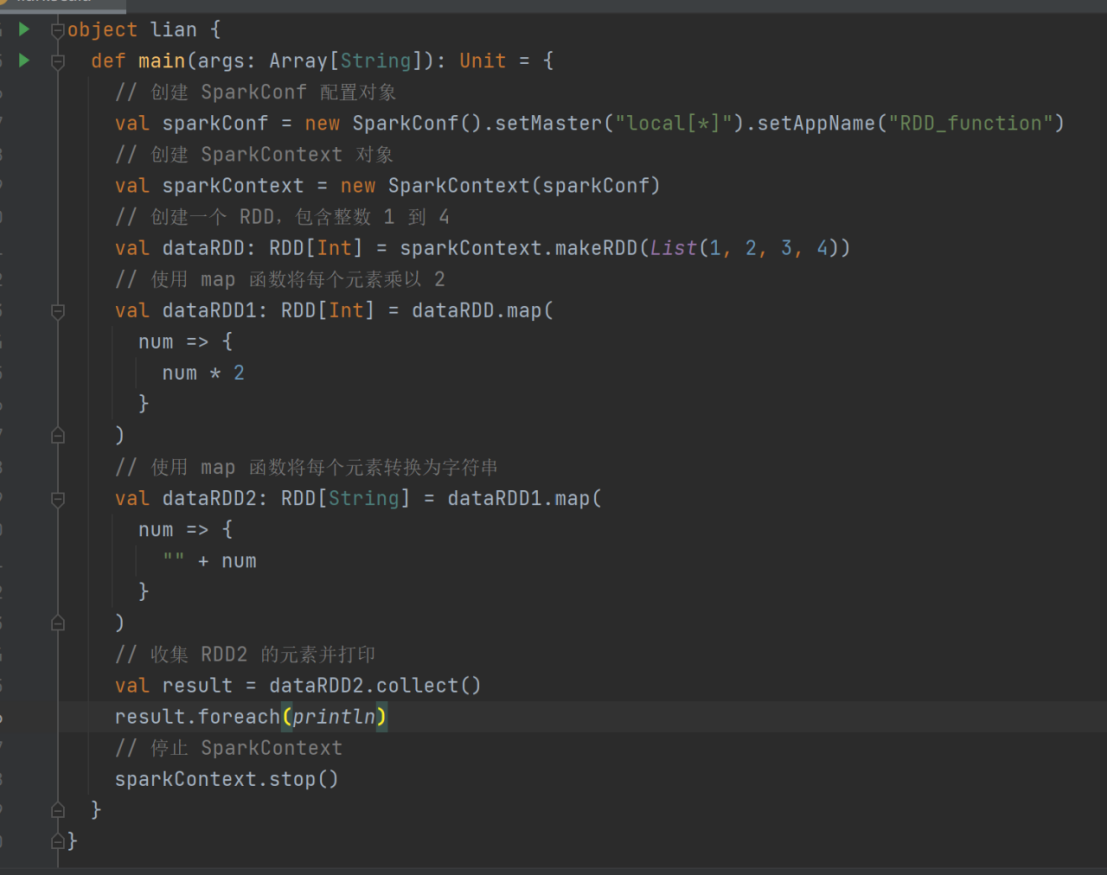
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD_function")
val sparkContext = new SparkContext(sparkConf)
val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4))
val dataRDD1: RDD[Int] = dataRDD.map(
num => {
num * 2
}
)
val dataRDD2: RDD[String] = dataRDD1.map(
num => {
"" + num
}
)
sparkContext.stop()
代码测试:
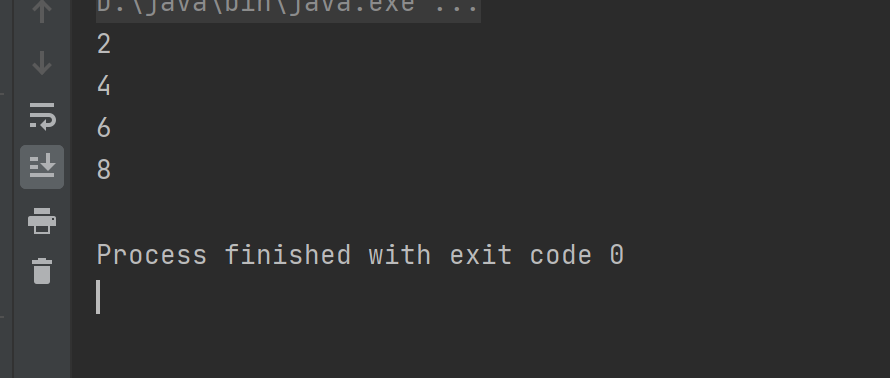
- mapPartitions
➢ 函数签名
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
➢ 函数说明
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据。
val dataRDD1: RDD[Int] = dataRDD.mapPartitions(
datas => {
datas.filter(_==2)
}
)
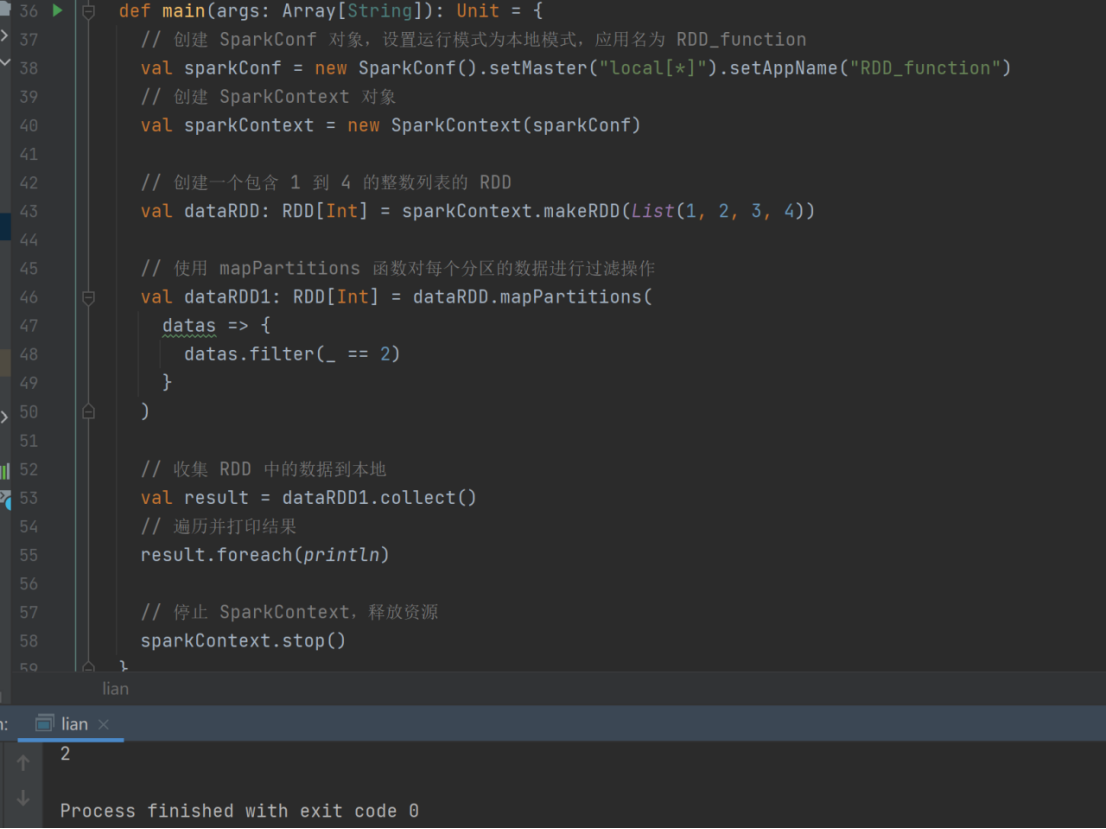
map 和 mapPartitions 的区别:
➢ 数据处理角度
Map 算子是分区内一个数据一个数据的执行,类似于串行操作。而 mapPartitions 算子是以分区为单位进行批处理操作。
➢ 功能的角度
Map 算子主要目的将数据源中的数据进行转换和改变。但是不会减少或增多数据。MapPartitions 算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变,所以可以增加或减少数据
➢ 性能的角度
Map 算子因为类似于串行操作,所以性能比较低,而是 mapPartitions 算子类似于批处理,所以性能较高。但是 mapPartitions 算子会长时间占用内存,那么这样会导致内存可能不够用,出现内存溢出的错误。所以在内存有限的情况下,不推荐使用。使用 map 操作。
- mapPartitionsWithIndex
➢ 函数签名
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
➢ 函数说明
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据,在处理时同时可以获取当前分区索引。
- flatMap
➢ 函数签名
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
➢ 函数说明
将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射。
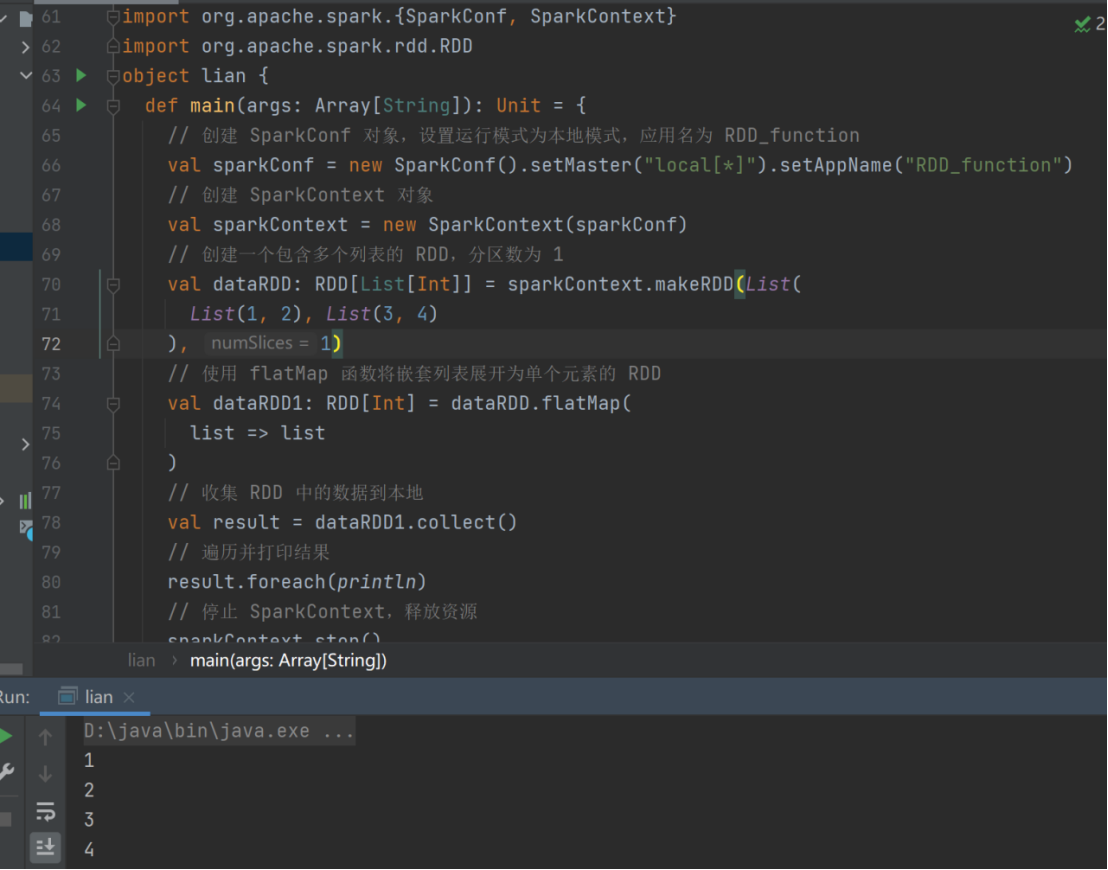
val dataRDD = sparkContext.makeRDD(List(
List(1,2),List(3,4)
),1)
val dataRDD1 = dataRDD.flatMap(
list => list
)
map和flatMap的区别:
map会将每一条输入数据映射为一个新对象。
flatMap包含两个操作:会将每一个输入对象输入映射为一个新集合,然后把这些新集合连成一个大集合。
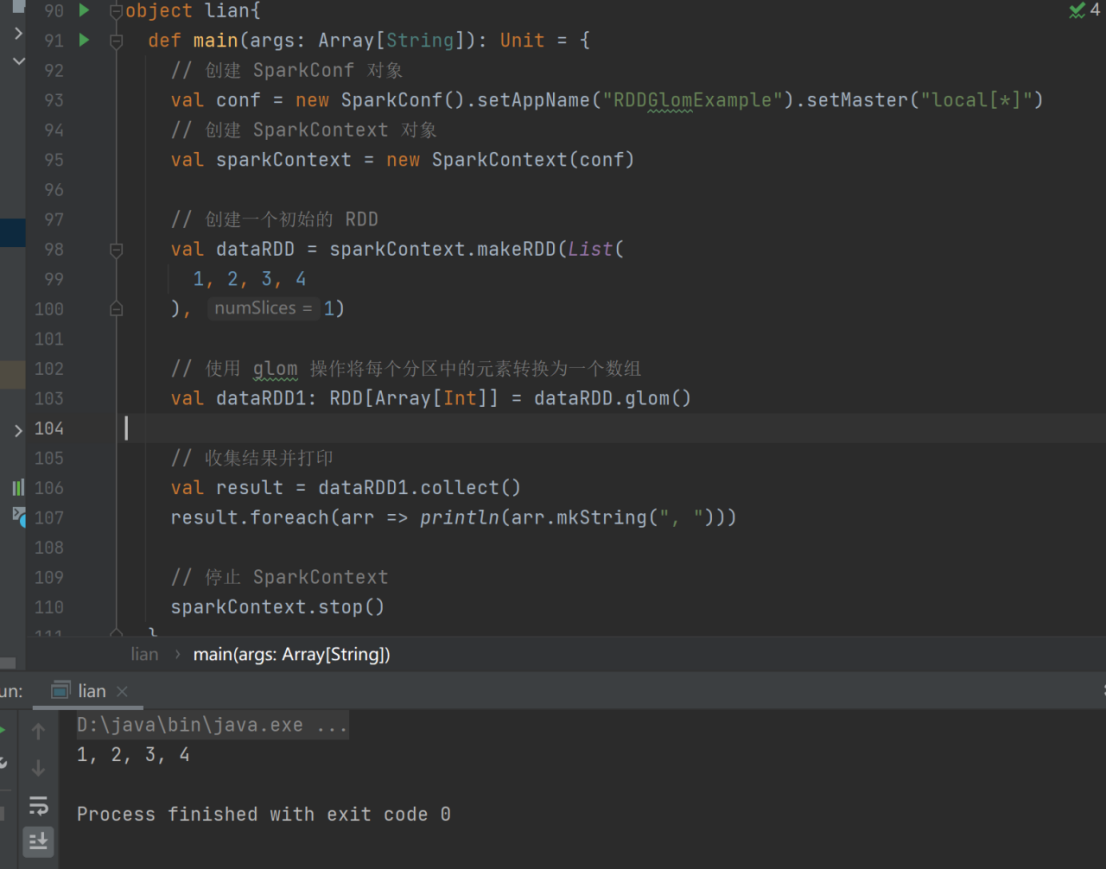
- glom
➢ 函数签名
def glom(): RDD[Array[T]]
➢ 函数说明
将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4
),1)
val dataRDD1:RDD[Array[Int]] = dataRDD.glom()
- groupBy
➢ 函数签名
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]
➢ 函数说明
将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样的操作称之为 shuffle。极限情况下,数据可能被分在同一个分区中。
一个组的数据在一个分区中,但是并不是说一个分区中只有一个组val dataRDD = sparkContext.makeRDD(List(1,2,3,4),1)
val dataRDD1 = dataRDD.groupBy(
_%2
)
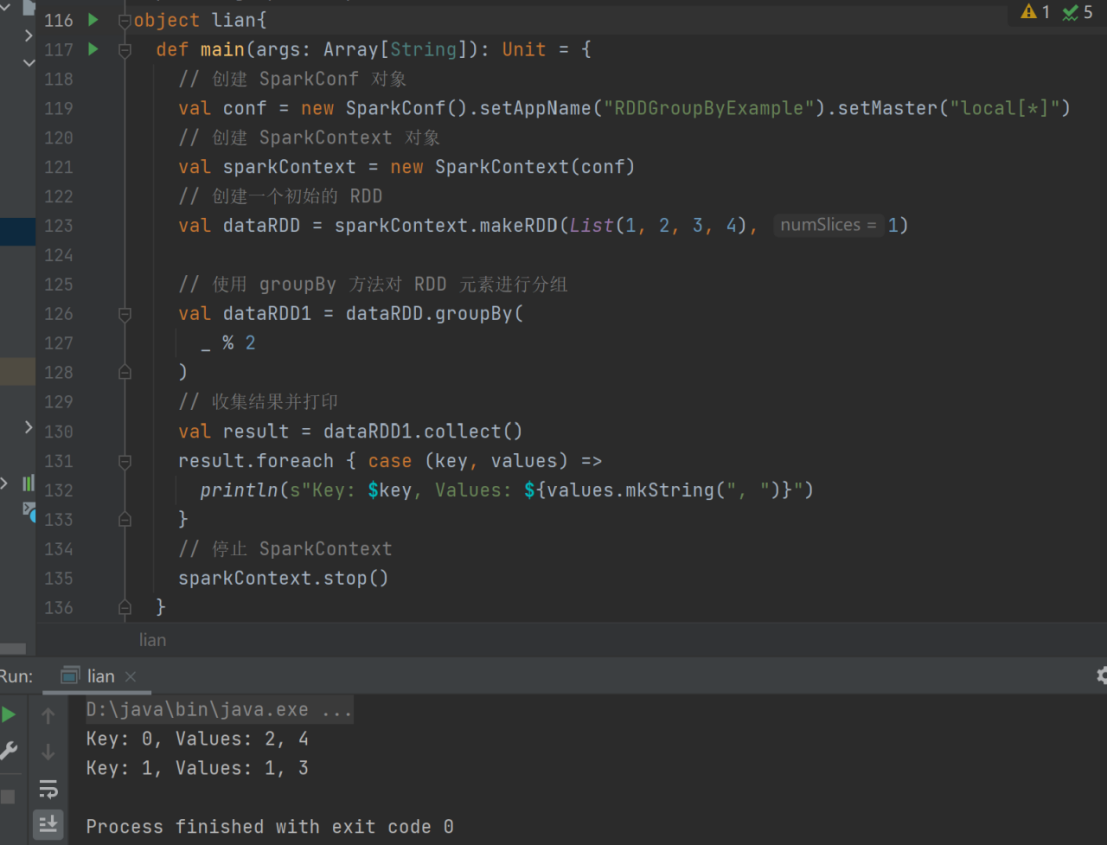
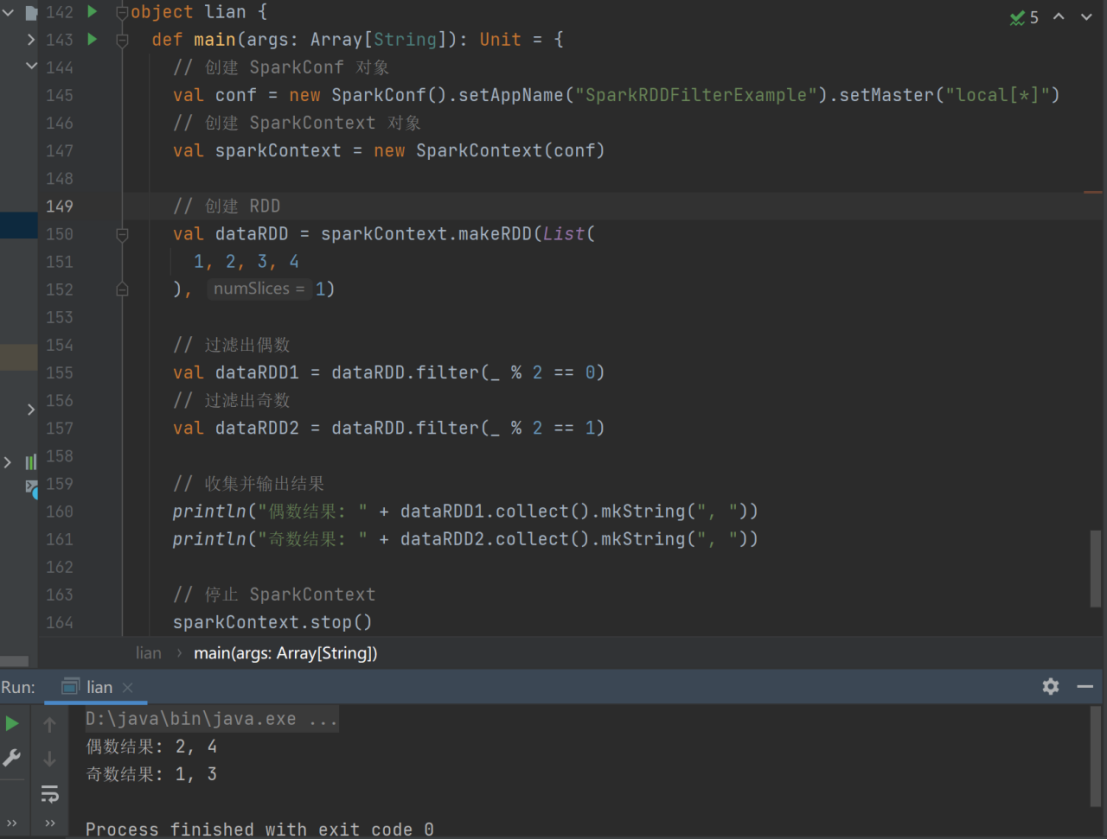
- filter
函数签名
def filter(f: T => Boolean): RDD[T]
函数说明
将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。
当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出
现数据倾斜。
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4
),1)
val dataRDD1 = dataRDD.filter(_%2 == 0)
val dataRDD2 = dataRDD.filter(_%2 == 1)
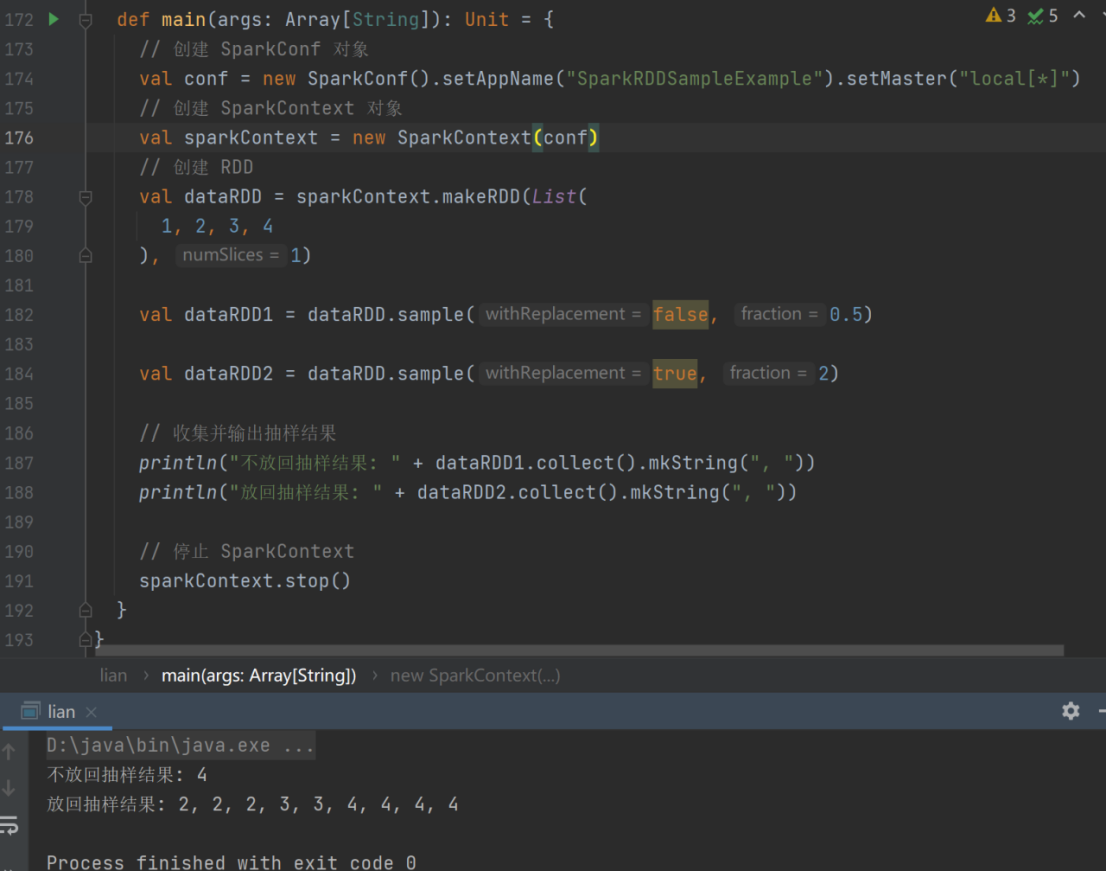
- sample
函数签名
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]
➢ 函数说明
根据指定的规则从数据集中抽取数据
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4
),1)
// 抽取数据不放回(伯努利算法)
// 伯努利算法:又叫 0、1 分布。例如扔硬币,要么正面,要么反面。
// 具体实现:根据种子和随机算法算出一个数和第二个参数设置几率比较,小于第二个参数要,大于不要
// 第一个参数:抽取的数据是否放回,false:不放回
// 第二个参数:抽取的几率,范围在[0,1]之间,0:全不取;1:全取;
// 第三个参数:随机数种子
val dataRDD1 = dataRDD.sample(false, 0.5)
// 抽取数据放回(泊松算法)
// 第一个参数:抽取的数据是否放回,true:放回;false:不放回
// 第二个参数:重复数据的几率,范围大于等于 0.表示每一个元素被期望抽取到的次数
// 第三个参数:随机数种子
val dataRDD2 = dataRDD.sample(true, 2)
Spark Core
Spark-Core编程(三)
Value类型:
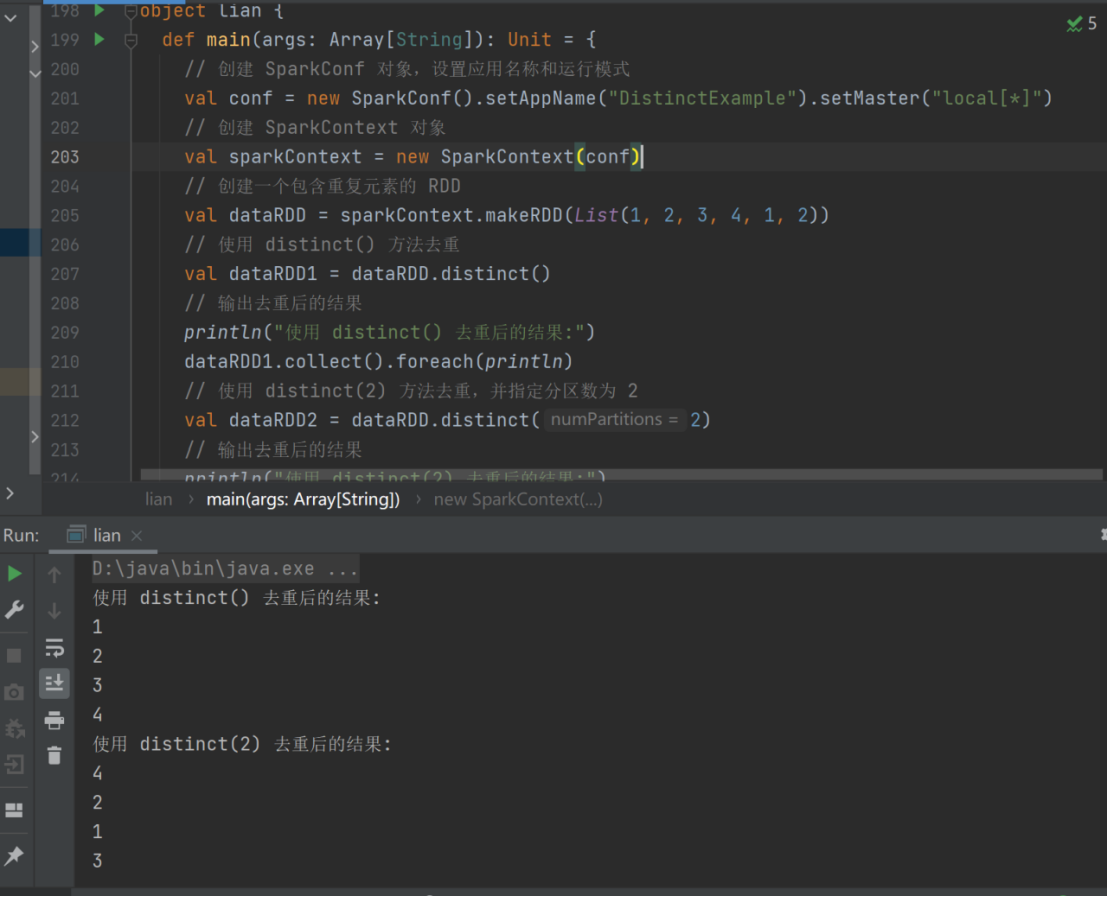
9) distinct
➢ 函数签名
def distinct()(implicit ord: Ordering[T] = null): RDD[T]
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
➢ 函数说明
将数据集中重复的数据去重
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4,1,2
))
val dataRDD1 = dataRDD.distinct()
val dataRDD2 = dataRDD.distinct(2)
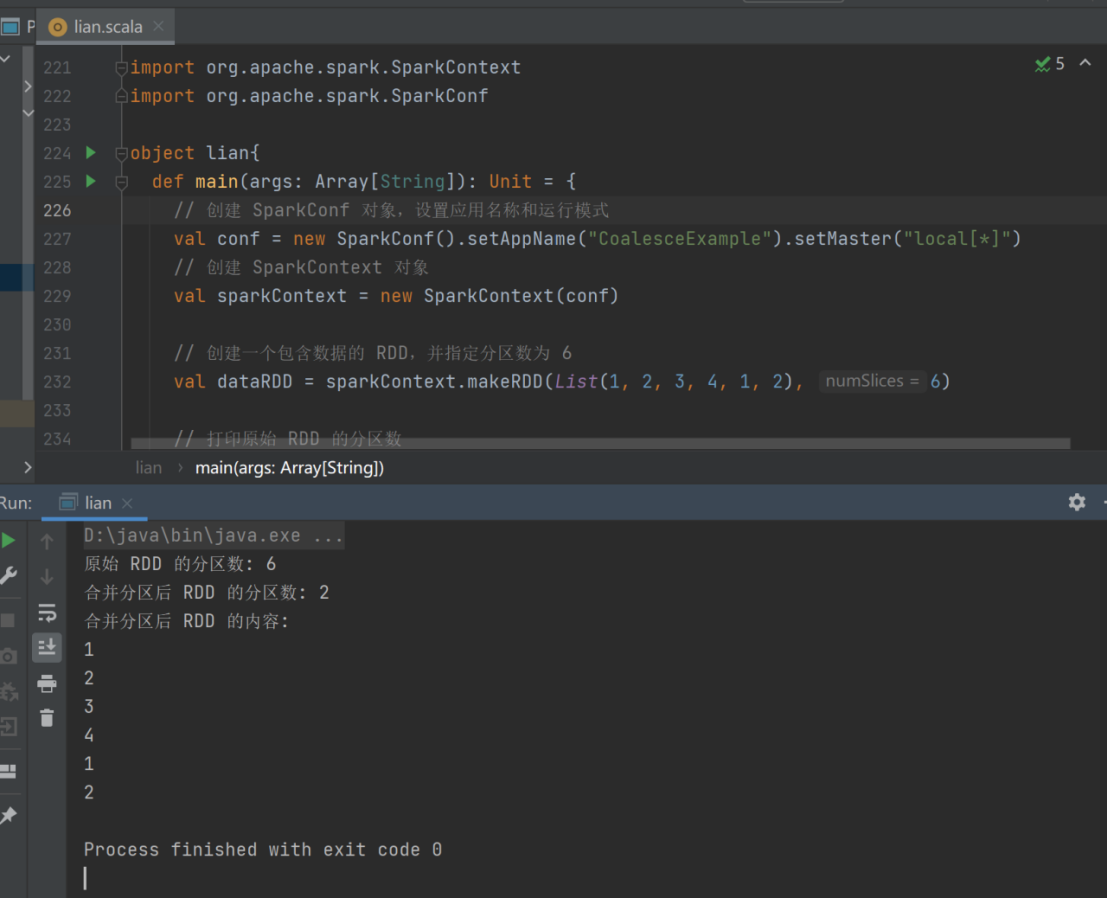
10) coalesce
➢ 函数签名
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T]
➢ 函数说明
根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率
当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少分区的个数,减小任务调度成本
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4,1,2
),6)
val dataRDD1 = dataRDD.coalesce(2)
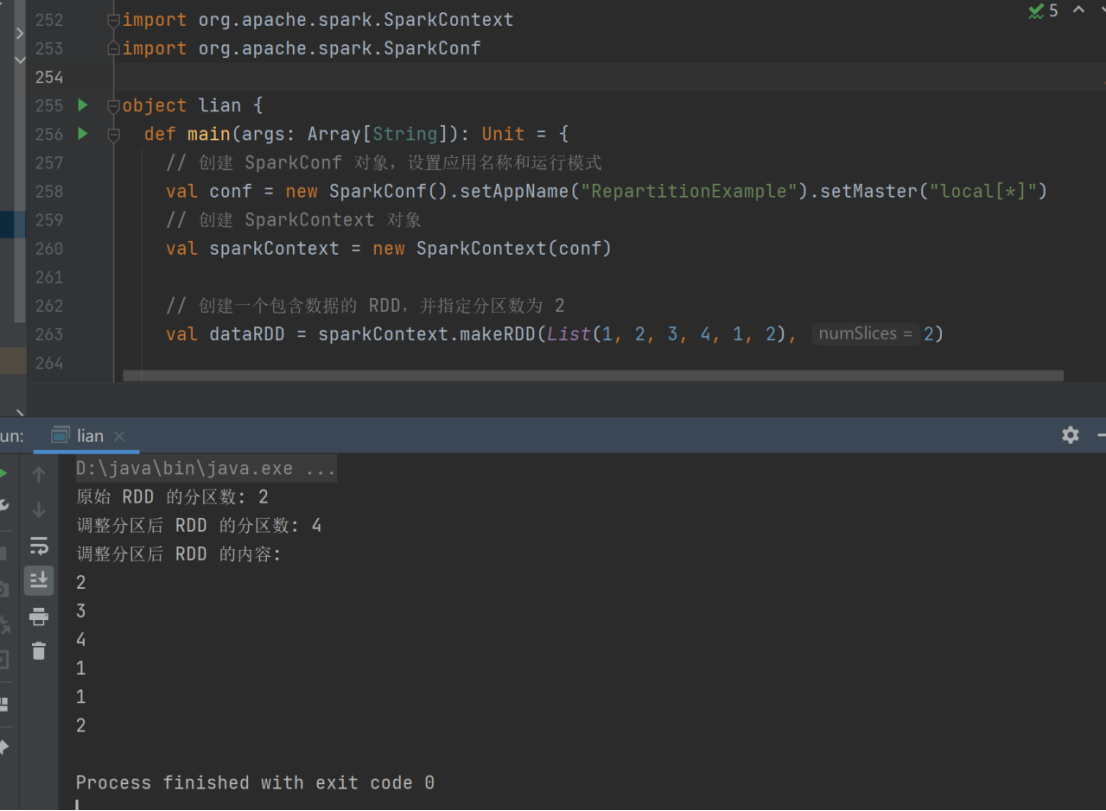
11) repartition
➢ 函数签名
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
➢ 函数说明
该操作内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true。无论是将分区数多的RDD 转换为分区数少的 RDD,还是将分区数少的 RDD 转换为分区数多的 RDD,repartition操作都可以完成,因为无论如何都会经 shuffle 过程。
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4,1,2
),2)
val dataRDD1 = dataRDD.repartition(4)
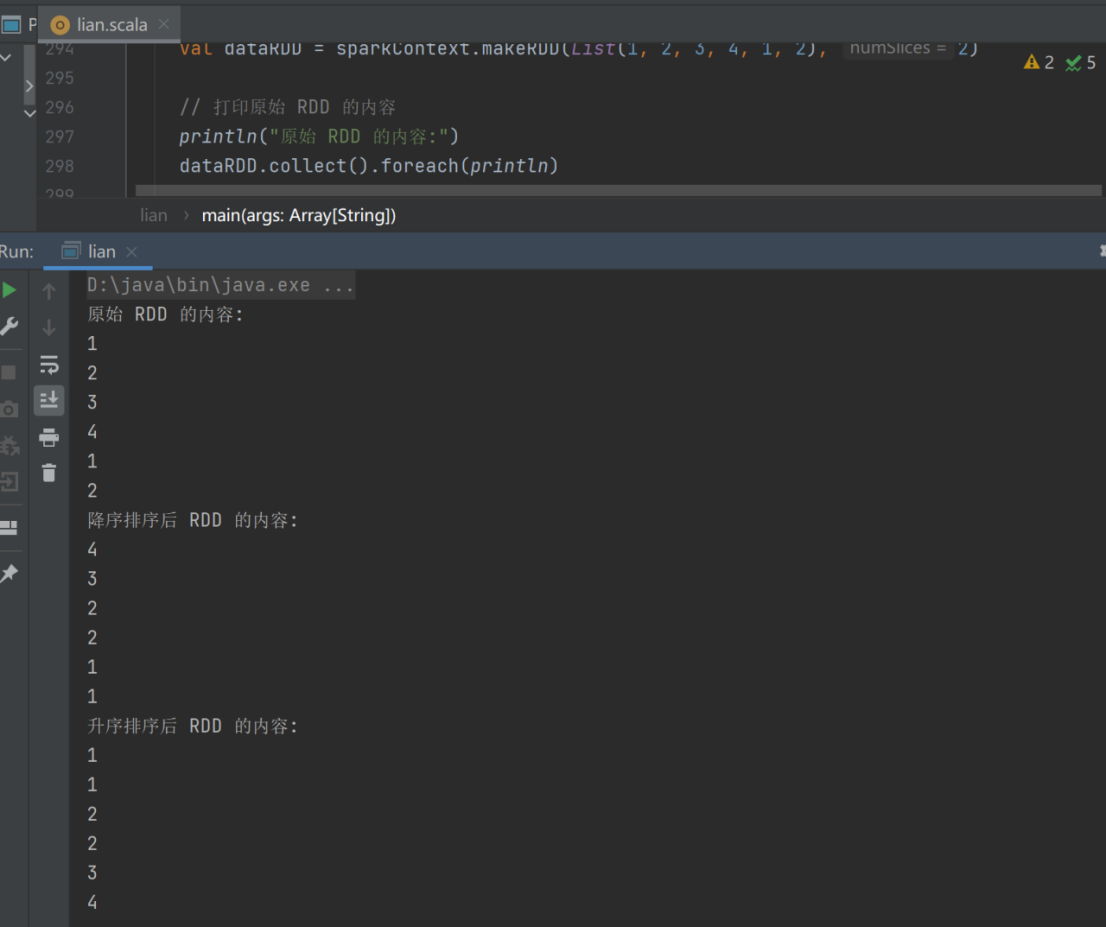
12) sortBy
➢ 函数签名
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
➢ 函数说明
该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序,默认为升序排列。排序后新产生的 RDD 的分区数与原 RDD 的分区数一致。中间存在 shuffle 的过程。
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4,1,2
),2)
val dataRDD1 = dataRDD.sortBy(num=>num, false, 4)
val dataRDD2 = dataRDD.sortBy(num=>num, true, 4)
双Value类型:
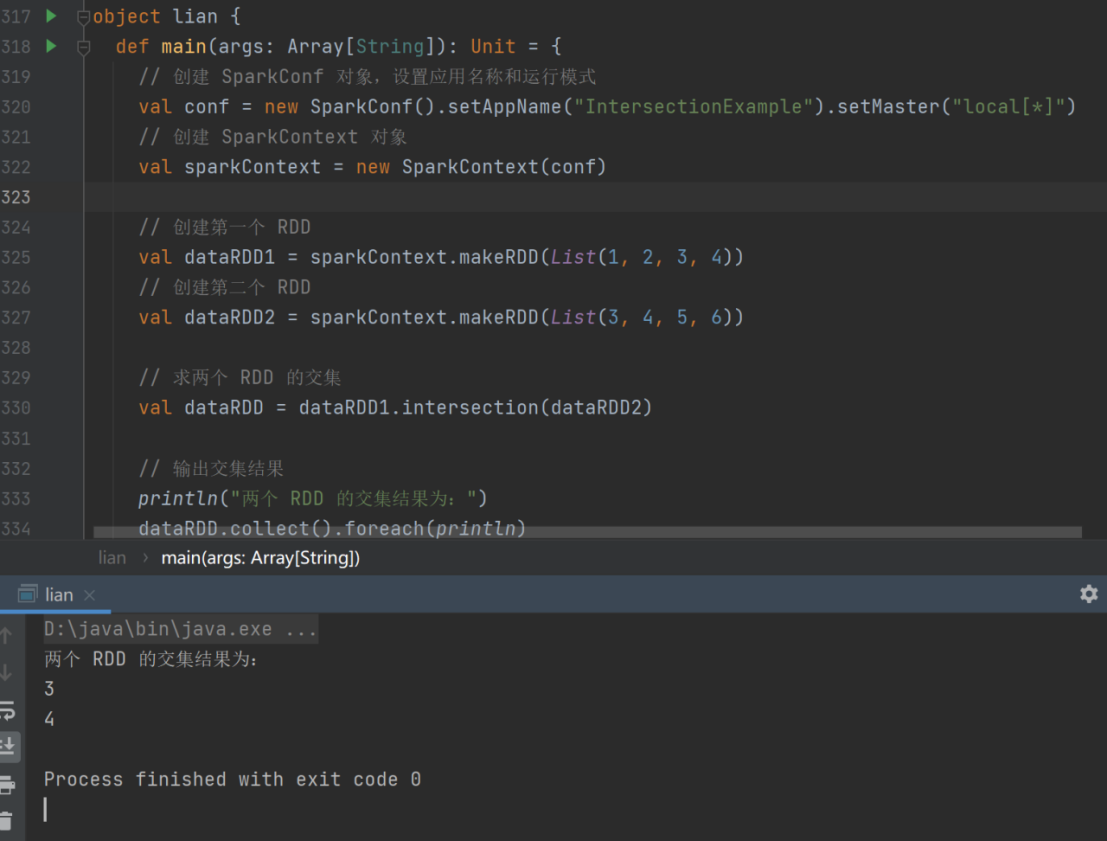
13) intersection
➢ 函数签名
def intersection(other: RDD[T]): RDD[T]
➢ 函数说明
对源 RDD 和参数 RDD 求交集后返回一个新的 RDD
val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4))
val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.intersection(dataRDD2)
14) union
➢ 函数签名
def union(other: RDD[T]): RDD[T]
➢ 函数说明
对源 RDD 和参数 RDD 求并集后返回一个新的 RDD(重复数据不会去重)
val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4))
val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.union(dataRDD2)
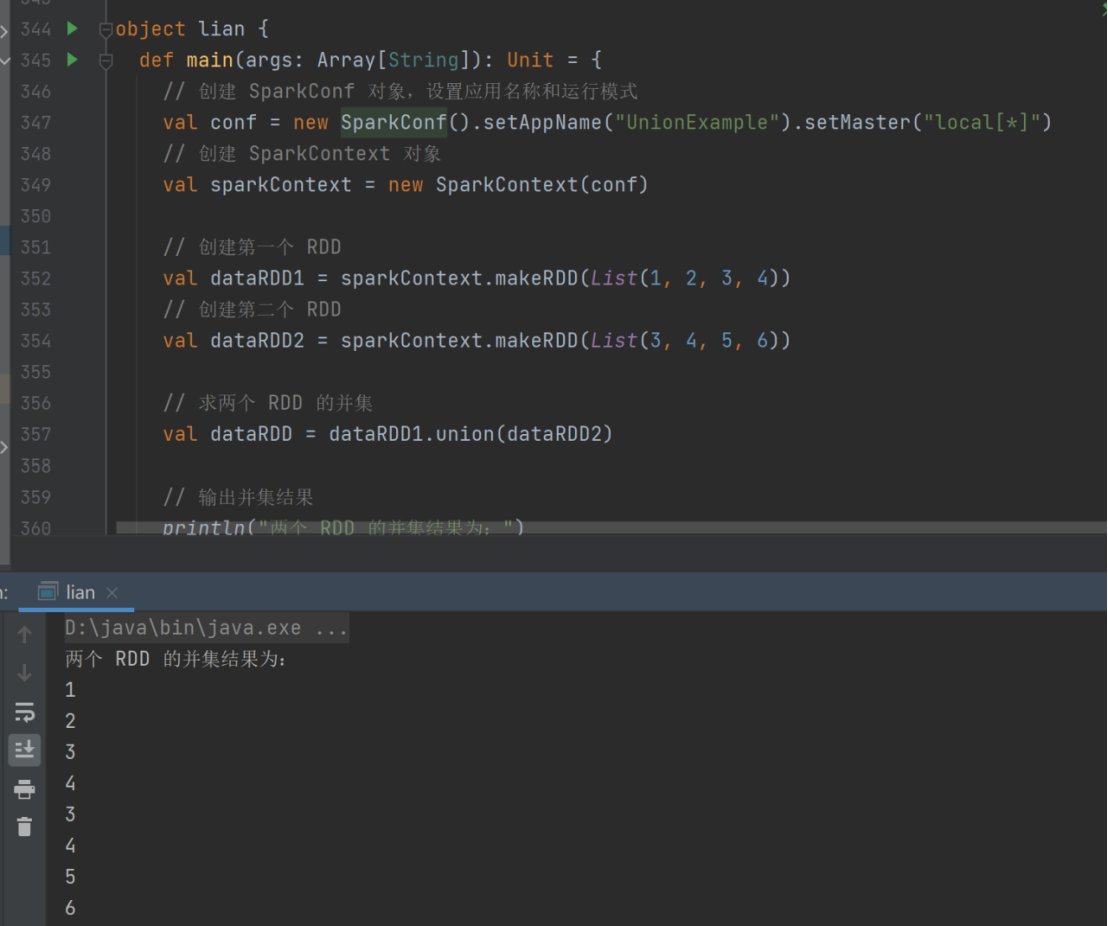
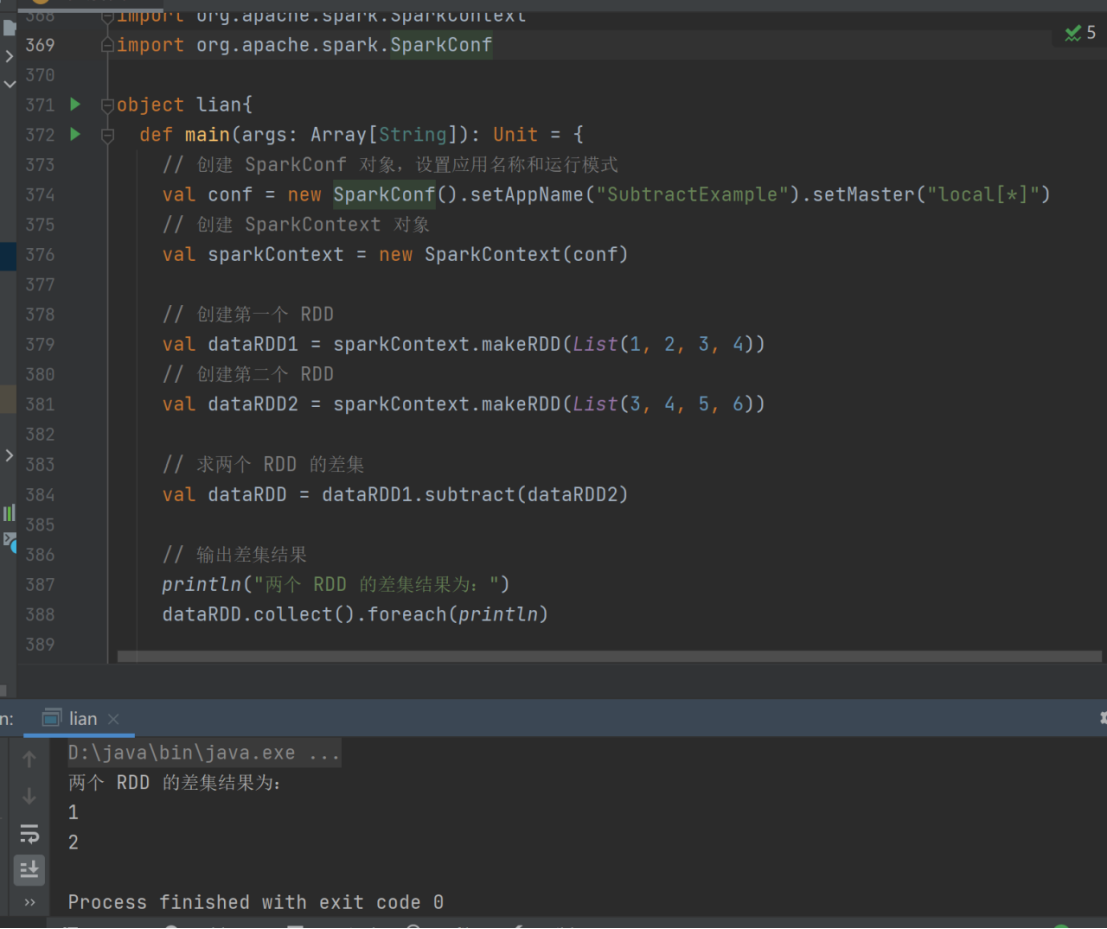
15) subtract
➢ 函数签名
def subtract(other: RDD[T]): RDD[T]
➢ 函数说明
以源 RDD 元素为主,去除两个 RDD 中重复元素,将源RDD的其他元素保留下来。(求差集)
val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4))
val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.subtract(dataRDD2)
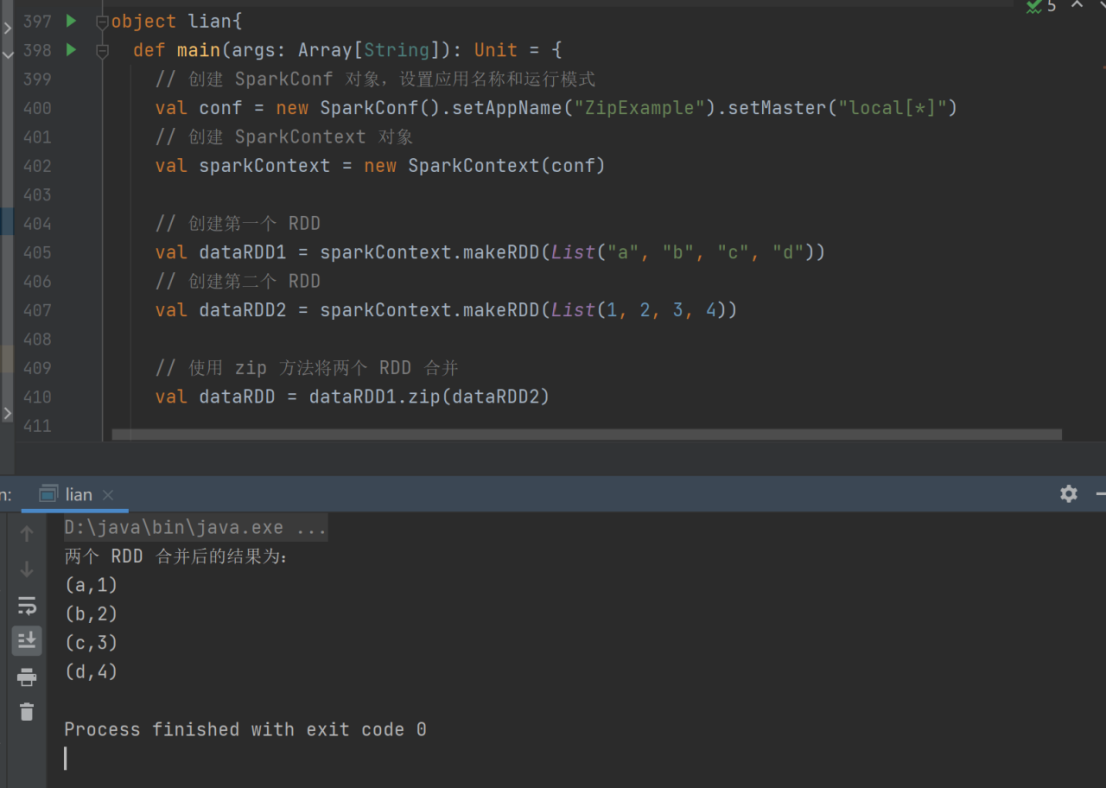
16) zip
➢ 函数签名
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
➢ 函数说明
将两个 RDD 中的元素,以键值对的形式进行合并。其中,键值对中的 Key 为第 1 个 RDD
中的元素,Value 为第 2 个 RDD 中的相同位置的元素。
val dataRDD1 = sparkContext.makeRDD(List("a","b","c","d"))
val dataRDD2 = sparkContext.makeRDD(List(1,2,3,4))
val dataRDD = dataRDD1.zip(dataRDD2)
Spark Core
Spark-Core编程(四)
Key-Value类型:
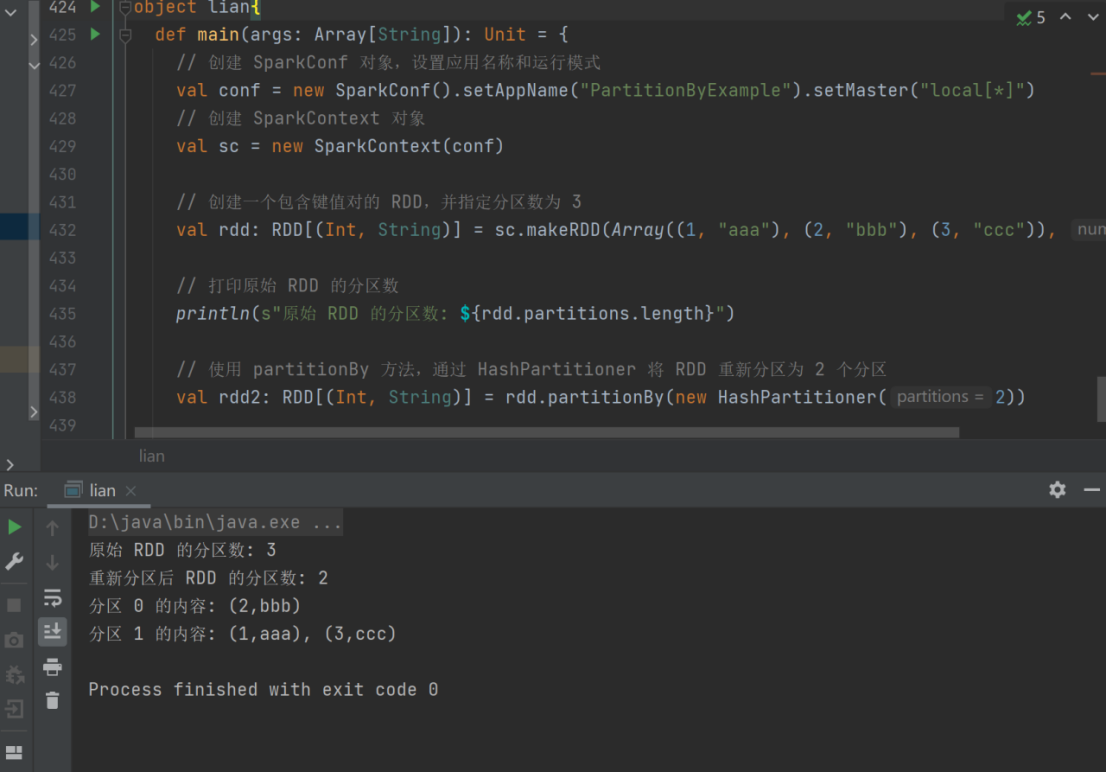
17) partitionBy
➢ 函数签名
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
➢ 函数说明
将数据按照指定 Partitioner 重新进行分区。Spark 默认的分区器是 HashPartitioner
val rdd: RDD[(Int, String)] =
sc.makeRDD(Array((1,"aaa"),(2,"bbb"),(3,"ccc")),3)
val rdd2: RDD[(Int, String)] =
rdd.partitionBy(new HashPartitioner(2))
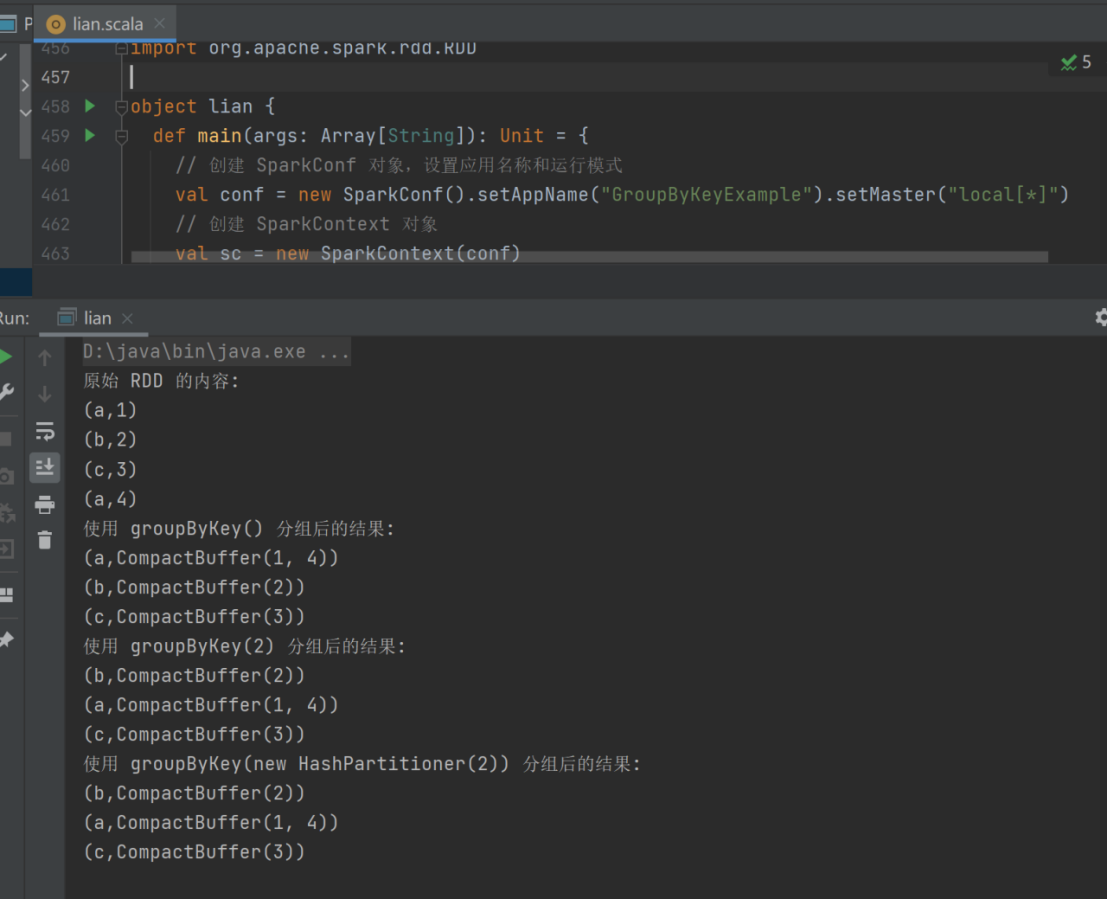
18) groupByKey
➢ 函数签名
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
➢ 函数说明
将数据源的数据根据 key 对 value 进行分组
val dataRDD1 =
sc.makeRDD(List(("a",1),("b",2),("c",3),("a",4)))
val dataRDD2 = dataRDD1.groupByKey()
val dataRDD3 = dataRDD1.groupByKey(2)
val dataRDD4 = dataRDD1.groupByKey(new HashPartitioner(2))
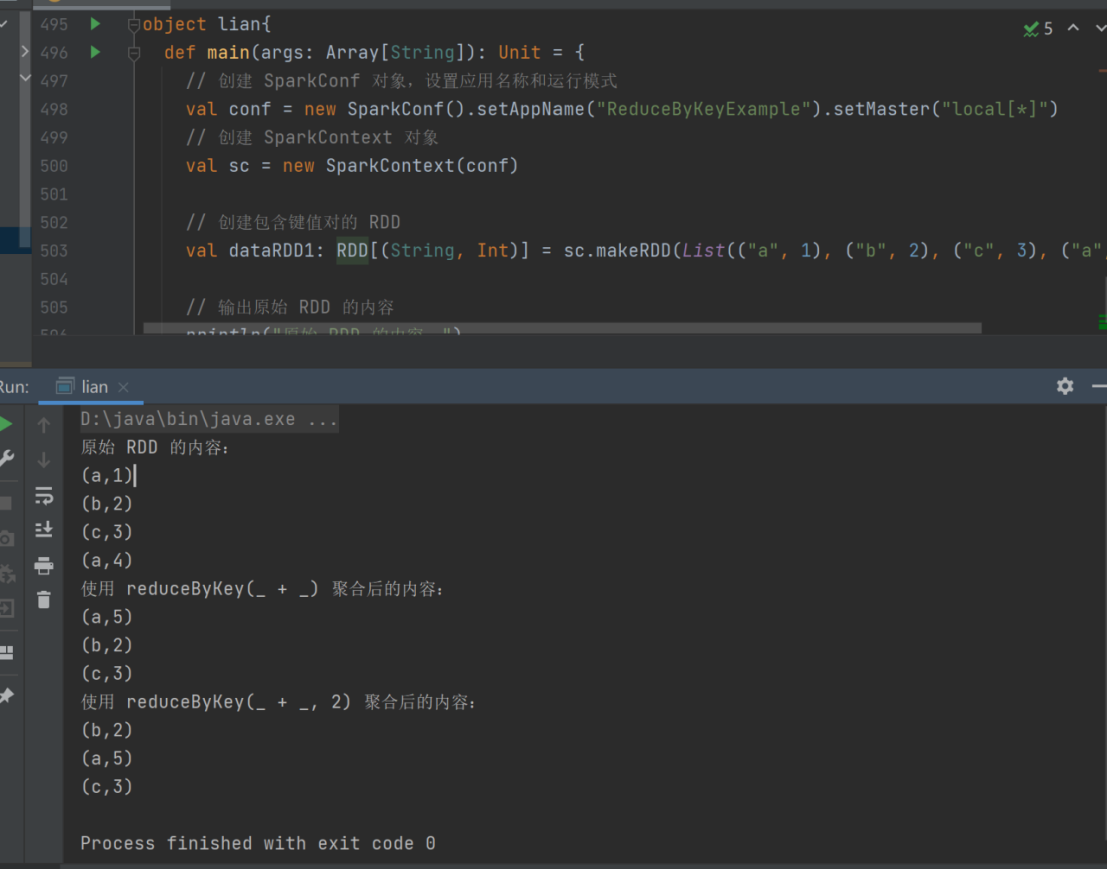
19) reduceByKey
➢ 函数签名
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
➢ 函数说明
可以将数据按照相同的 Key 对 Value 进行聚合
val dataRDD1 = sc.makeRDD(List(("a",1),("b",2),("c",3),("a",4)))
val dataRDD2 = dataRDD1.reduceByKey(_+_)
val dataRDD3 = dataRDD1.reduceByKey(_+_, 2)
reduceByKey 和 groupByKey 的区别:
从 shuffle 的角度:reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的数据量,而 groupByKey 只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较高。
从功能的角度:reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚
合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那
么还是只能使用 groupByKey
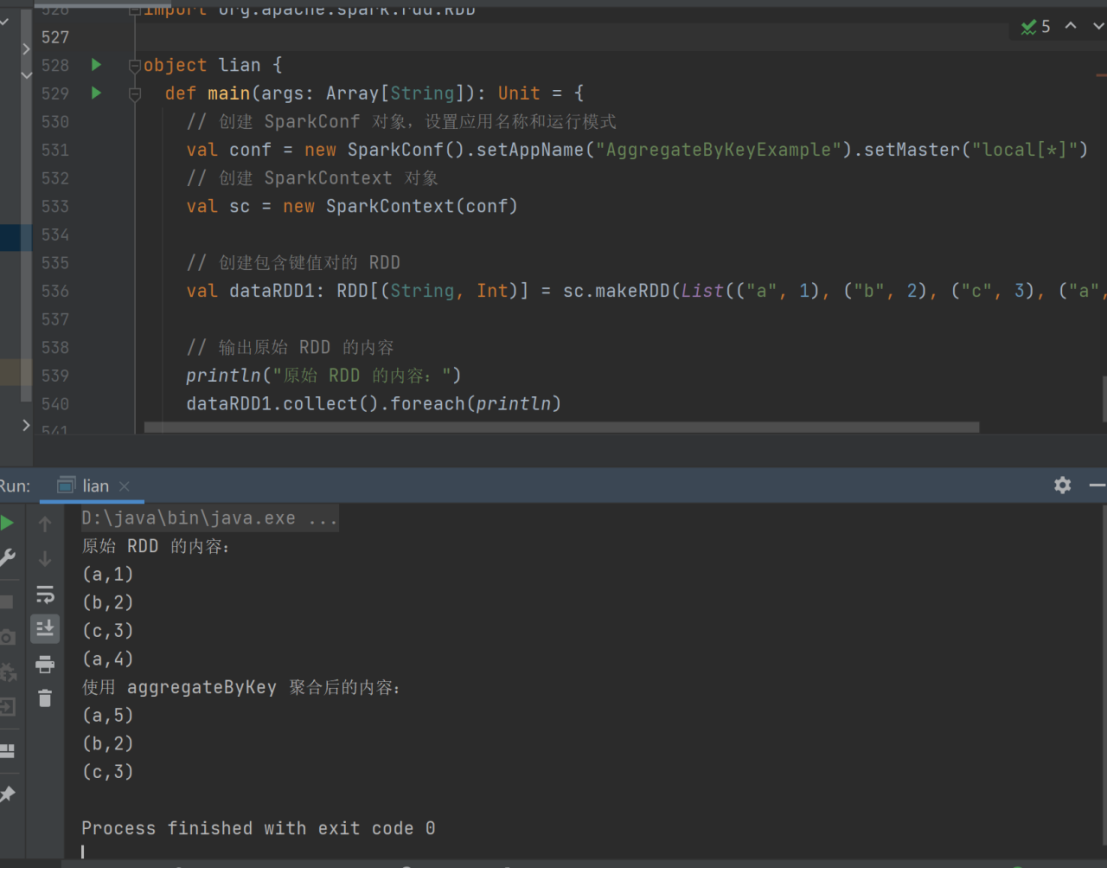
20) aggregateByKey
➢ 函数签名
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)]
➢ 函数说明
将数据根据不同的规则进行分区内计算和分区间计算val dataRDD1 =
sc.makeRDD(List(("a",1),("b",2),("c",3),("a",4)))
val dataRDD2 =
dataRDD1.aggregateByKey(0)(_+_,_+_)
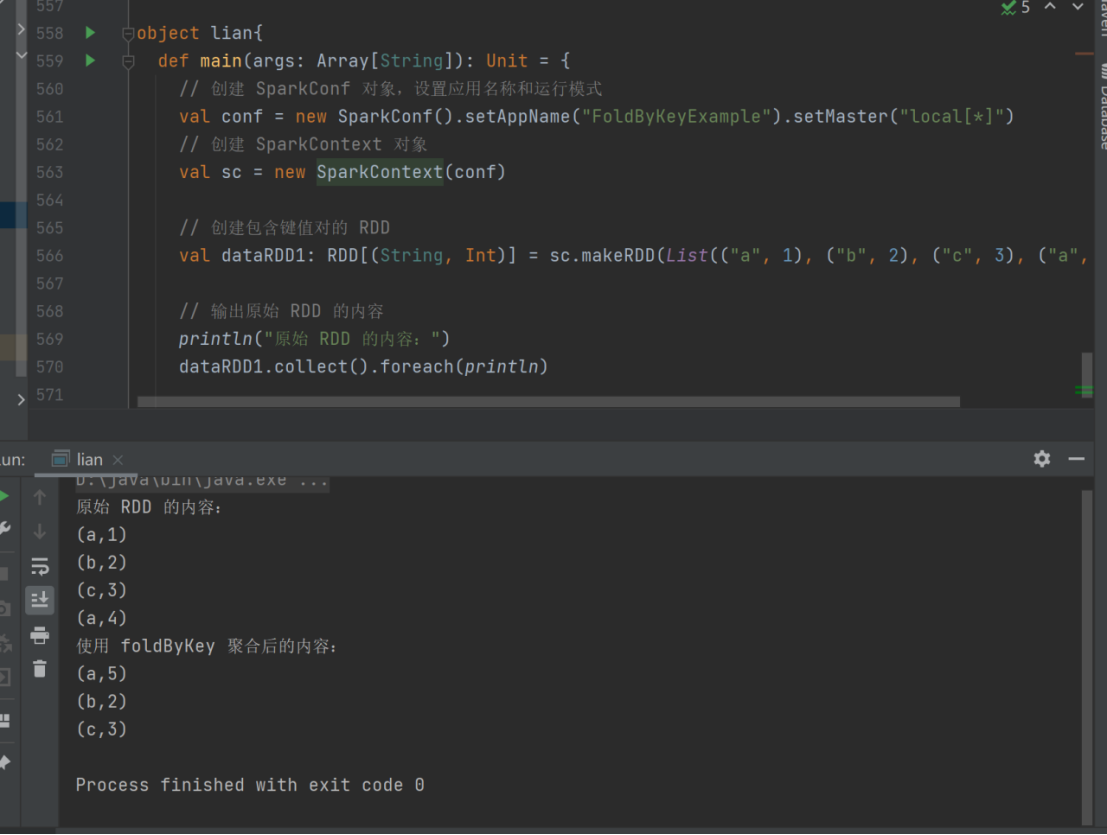
21) foldByKey
➢ 函数签名
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
➢ 函数说明
当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey
val dataRDD1 =
sc.makeRDD(List(("a",1),("b",2),("c",3),("a",4)))
val dataRDD2 = dataRDD1.foldByKey(0)(_+_)
22) combineByKey
➢ 函数签名
def combineByKey[C](
createCombiner: V => C,//将当前值作为参数进行附加操作并返回
mergeValue: (C, V) => C,// 在分区内部进行,将新元素V合并到第一步操作得到的C中
mergeCombiners: (C, C) => C): RDD[(K, C)]//将第二步操作得到的C进行分区间计算
➢ 函数说明
最通用的对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。类似于
aggregate(),combineByKey()允许用户返回值的类型与输入不一致。
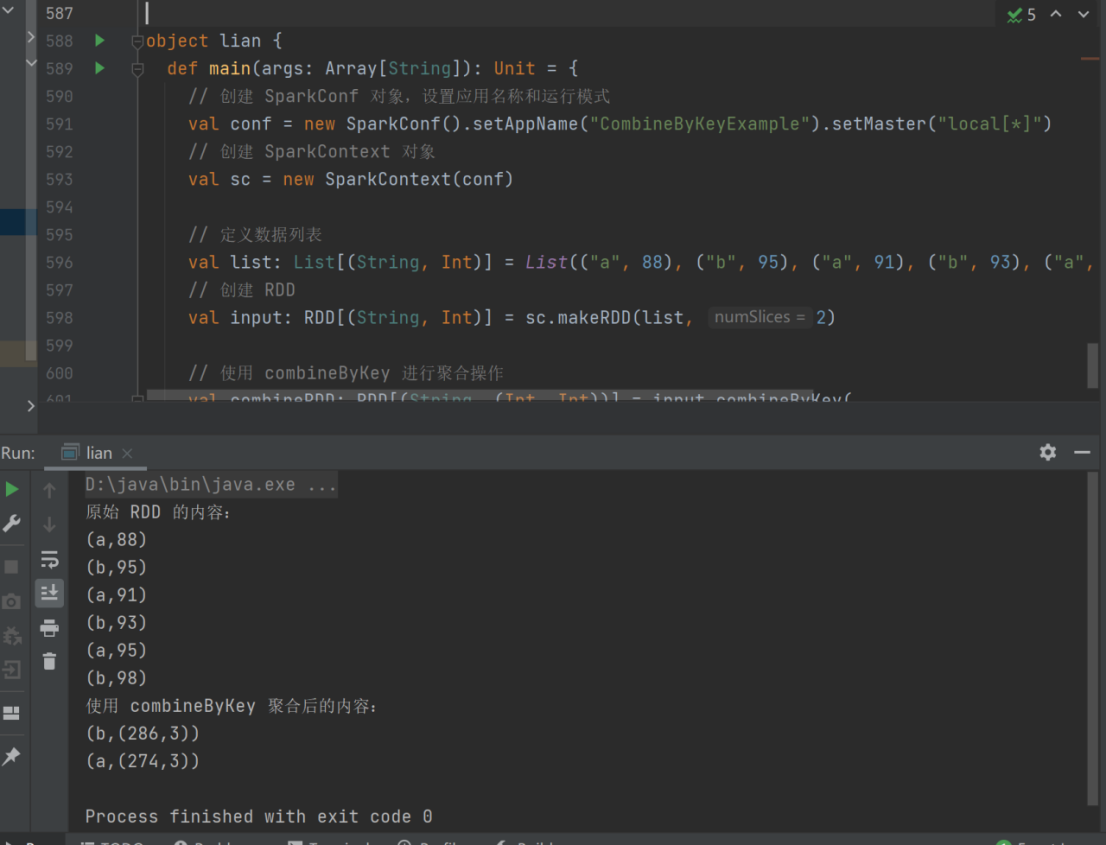
示例:现有数据 List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)),求每个key的总值及每个key对应键值对的个数
val list: List[(String, Int)] = List(("a", 88), ("b", 95), ("a", 91), ("b", 93),("a", 95), ("b", 98))
val input: RDD[(String, Int)] = sc.makeRDD(list, 2)
val combineRDD: RDD[(String, (Int, Int))] = input.combineByKey(
(_, 1), //a=>(a,1)
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1), //acc_1为数据源的value,acc_2为key出现的次数,二者进行分区内部的计算
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) //将分区内部计算的结果进行分区间的汇总计算,得到每个key的总值以及每个key出现的次数
)
reduceByKey、foldByKey、aggregateByKey、combineByKey 的区别:
reduceByKey: 相同 key 的第一个数据不进行任何计算,分区内和分区间计算规则相同
FoldByKey: 每一个key 对应的数据和初始值进行分区内计算,分区内和分区间计算规则相
同
AggregateByKey:每一个 key 对应的数据和初始值进行分区内计算,分区内和分区间计算规则可以不相同
CombineByKey:当计算时,发现数据结构不满足要求时,可以让第一个数据转换结构。分区
内和分区间计算规则不相同。
Spark Core
Spark-Core编程(四)
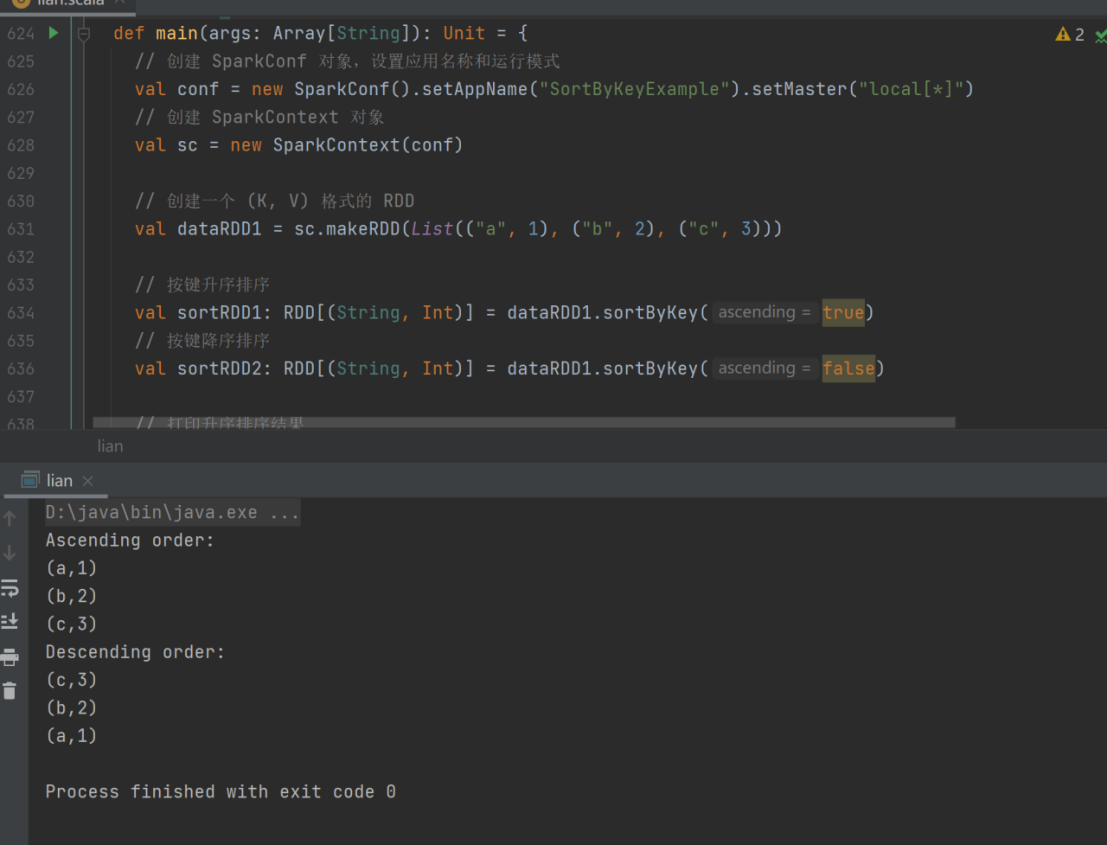
23) sortByKey
➢ 函数签名
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]
➢ 函数说明
在一个(K,V)的 RDD 上调用,K 必须实现 Ordered 接口(特质),返回一个按照 key 进行排序
val dataRDD1 = sc.makeRDD(List(("a",1),("b",2),("c",3)))
val sortRDD1: RDD[(String, Int)] = dataRDD1.sortByKey(true)
val sortRDD2: RDD[(String, Int)] = dataRDD1.sortByKey(false)
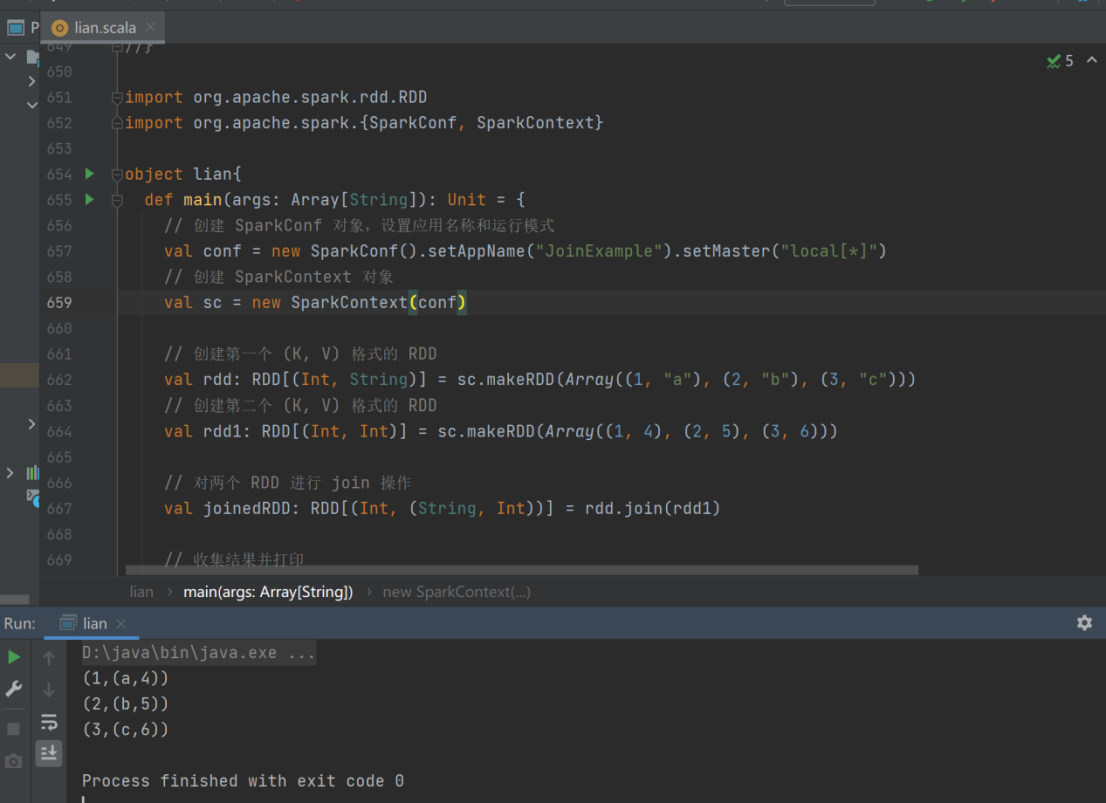
24) join
➢ 函数签名
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
➢ 函数说明
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的
(K,(V,W))的 RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (3, 6)))
rdd.join(rdd1).collect().foreach(println)
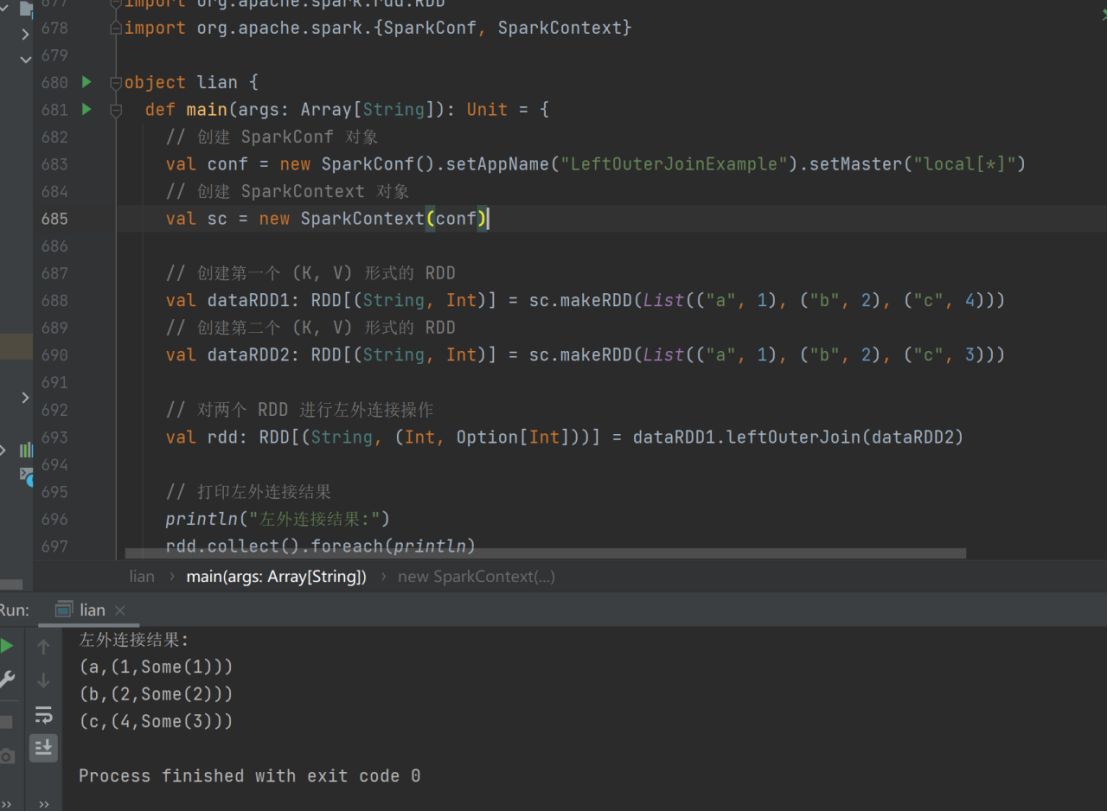
25) leftOuterJoin
➢ 函数签名
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
➢ 函数说明
类似于 SQL 语句的左外连接
val dataRDD1 = sc.makeRDD(List(("a",1),("b",2),("c",4)))
val dataRDD2 = sc.makeRDD(List(("a",1),("b",2),("c",3)))
val rdd: RDD[(String, (Int, Option[Int]))] = dataRDD1.leftOuterJoin(dataRDD2)
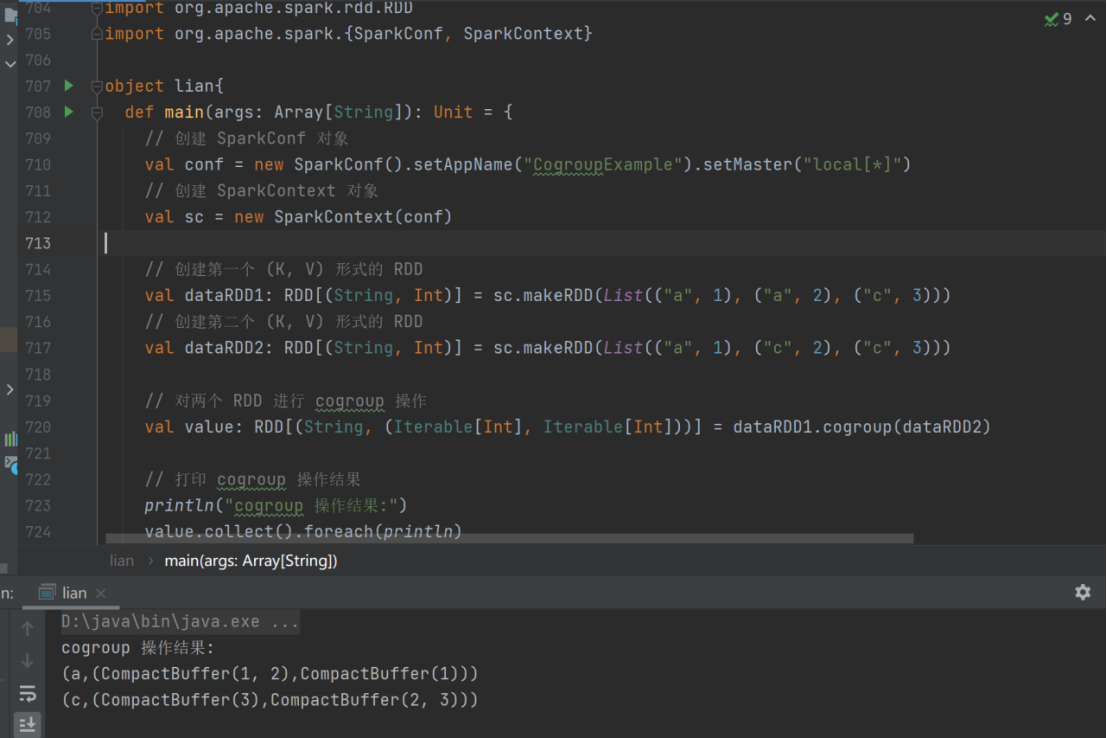
26) cogroup
➢ 函数签名
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
➢ 函数说明
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的 RDD
val dataRDD1 = sc.makeRDD(List(("a",1),("a",2),("c",3)))
val dataRDD2 = sc.makeRDD(List(("a",1),("c",2),("c",3)))
val value: RDD[(String, (Iterable[Int], Iterable[Int]))] =
dataRDD1.cogroup(dataRDD2)
Spark Core
Spark-Core编程(五)
RDD行动算子:
行动算子就是会触发action的算子,触发action的含义就是真正的计算数据。
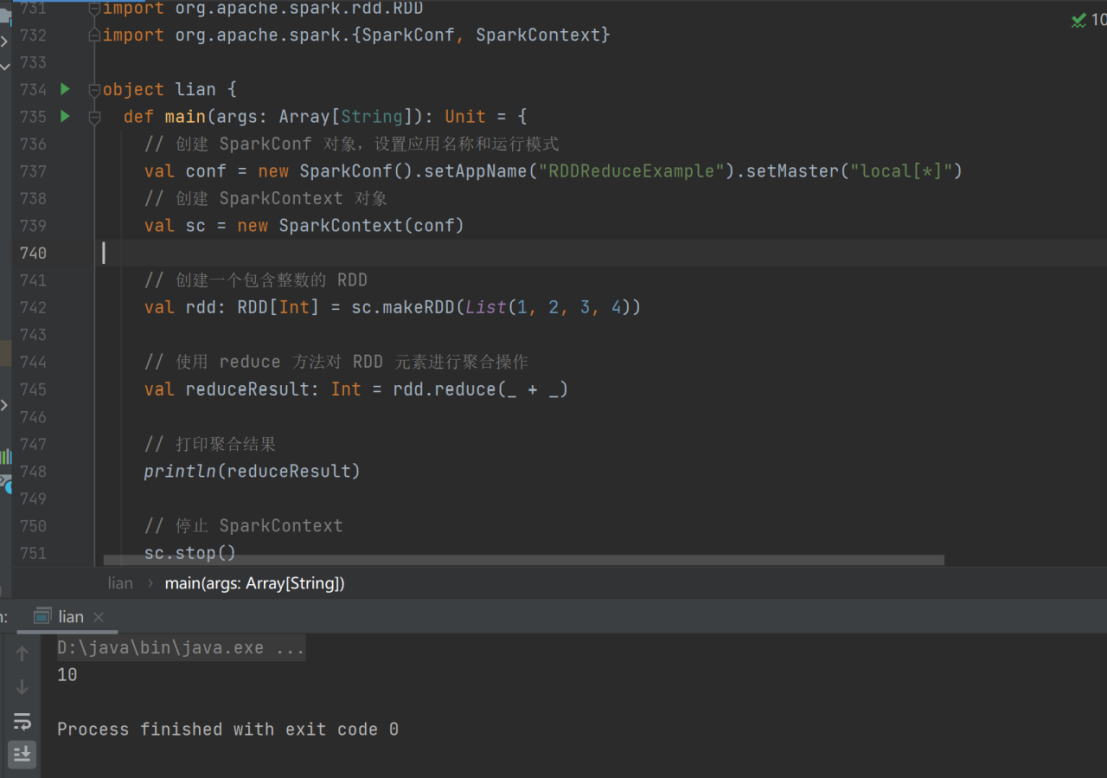
1) reduce
➢ 函数签名
def reduce(f: (T, T) => T): T
➢ 函数说明
聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val reduceResult: Int = rdd.reduce(_+_)
println(reduceResult)
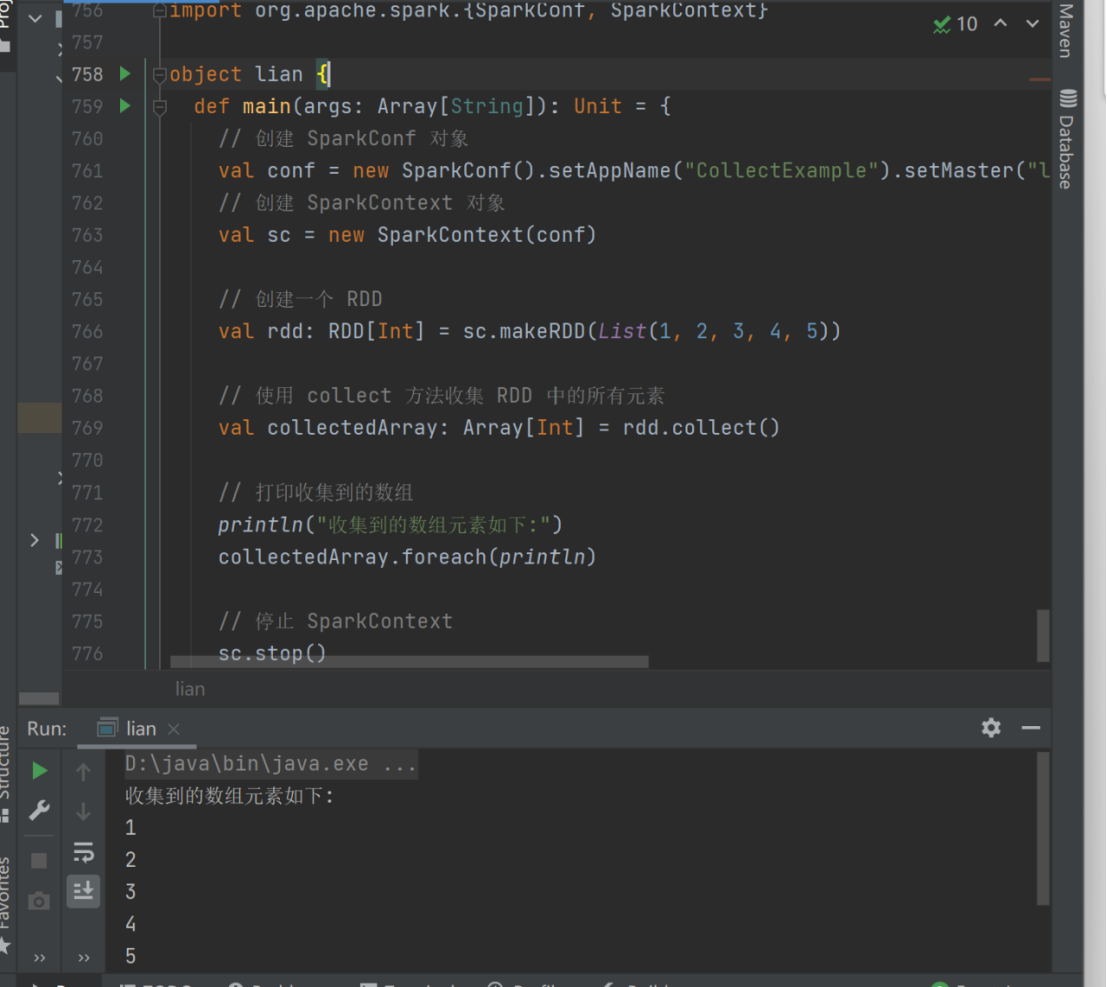
2) collect
➢ 函数签名
def collect(): Array[T]
➢ 函数说明
在驱动程序中,以数组 Array 的形式返回数据集的所有元素
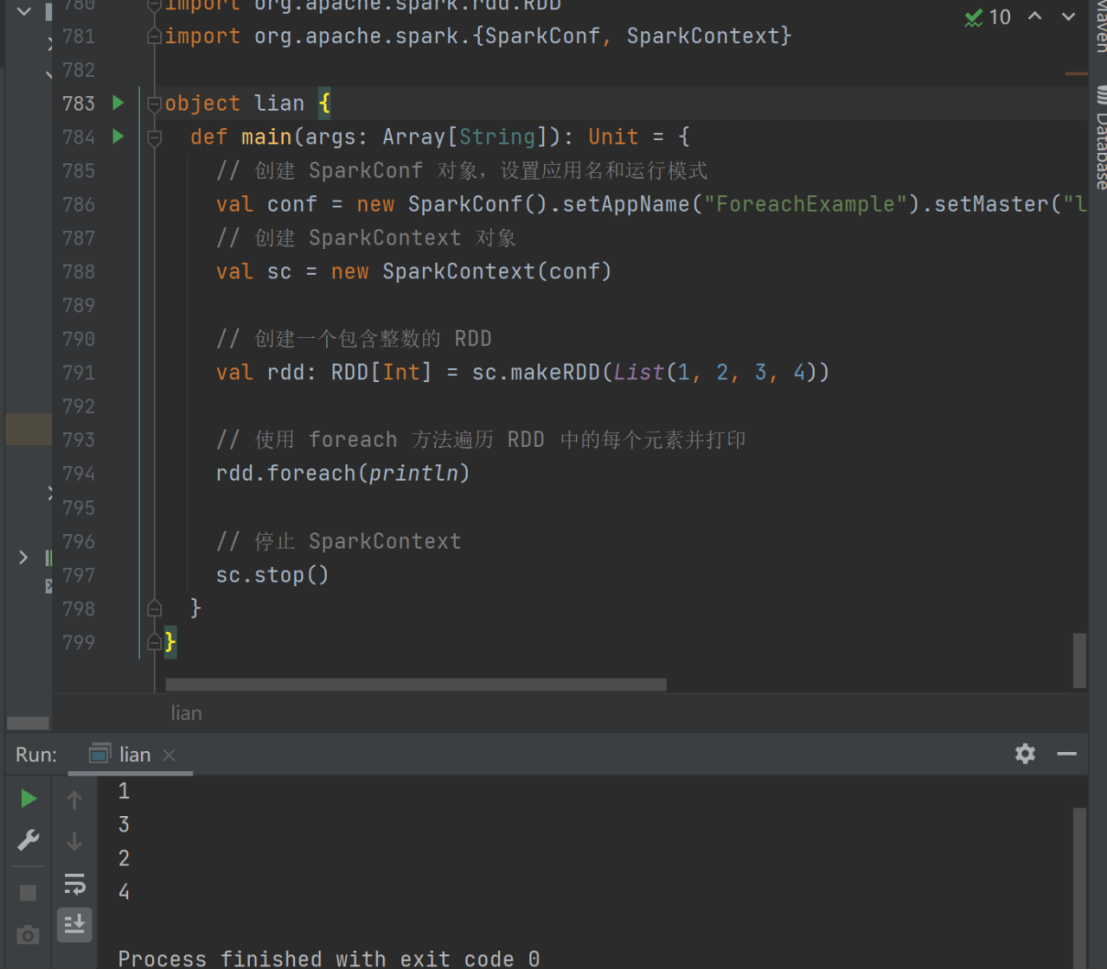
3) foreach
➢ 函数签名
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
➢ 函数说明
分布式遍历 RDD 中的每一个元素,调用指定函数
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
rdd.collect().foreach(println)
4) count
➢ 函数签名
def count(): Long
➢ 函数说明
返回 RDD 中元素的个数
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val countResult: Long = rdd.count()
println(countResult)
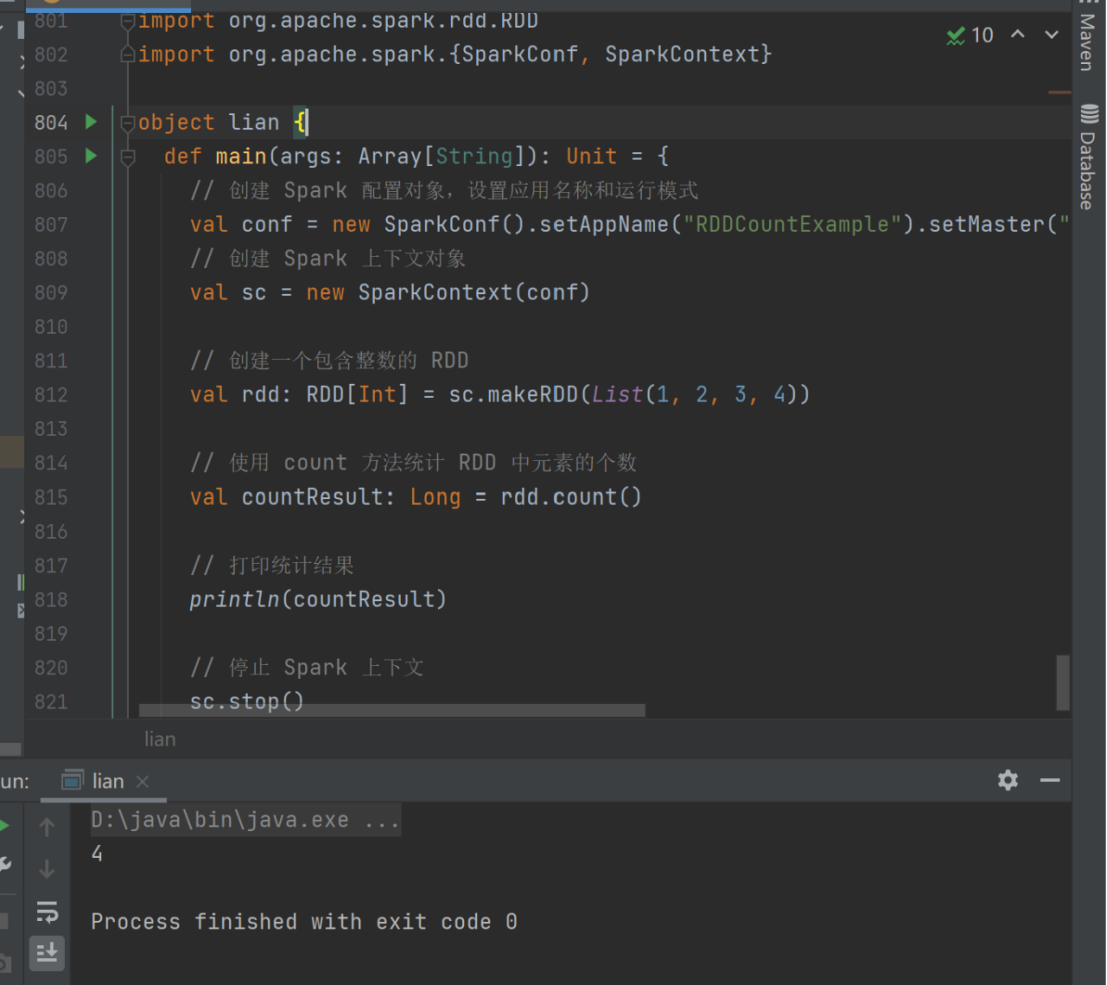
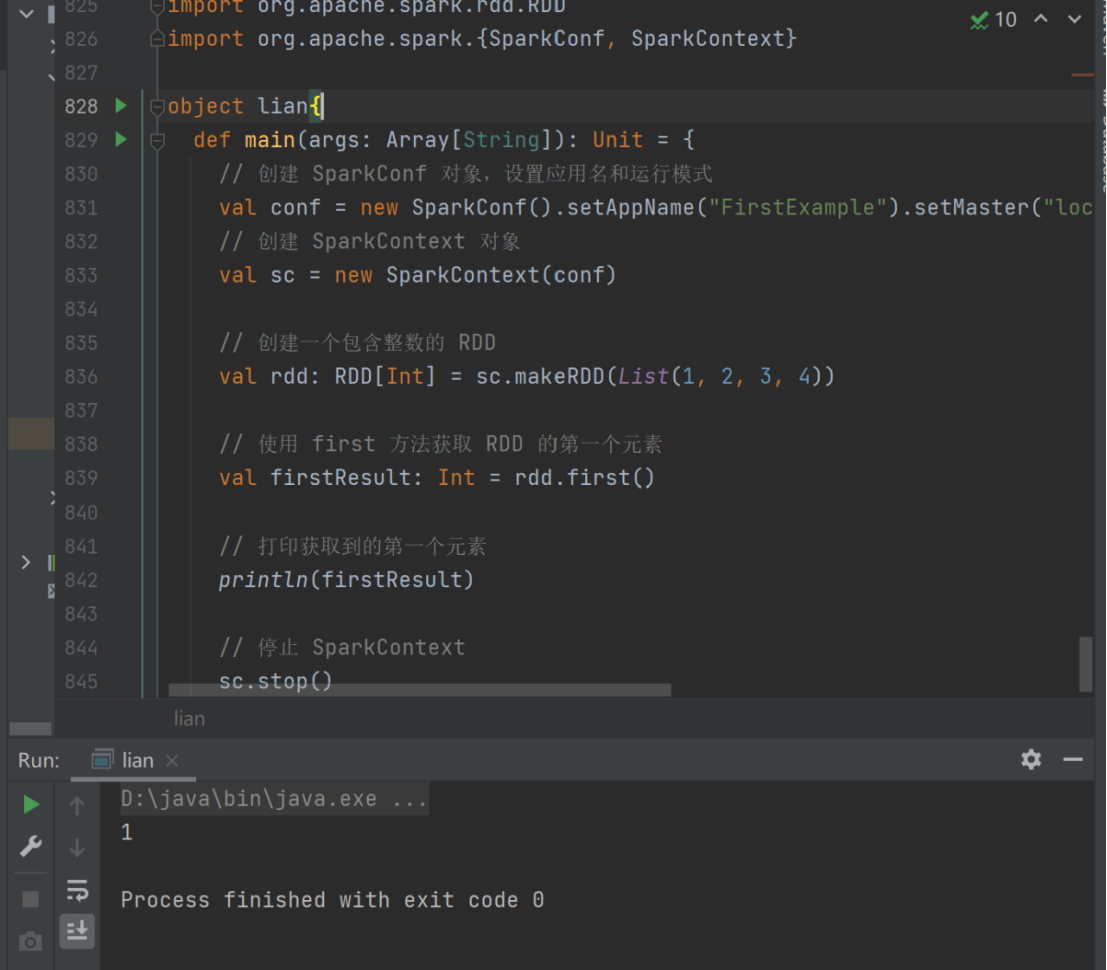
5) first
➢ 函数签名
def first(): T
➢ 函数说明
返回 RDD 中的第一个元素
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val firstResult: Int = rdd.first()
println(firstResult)
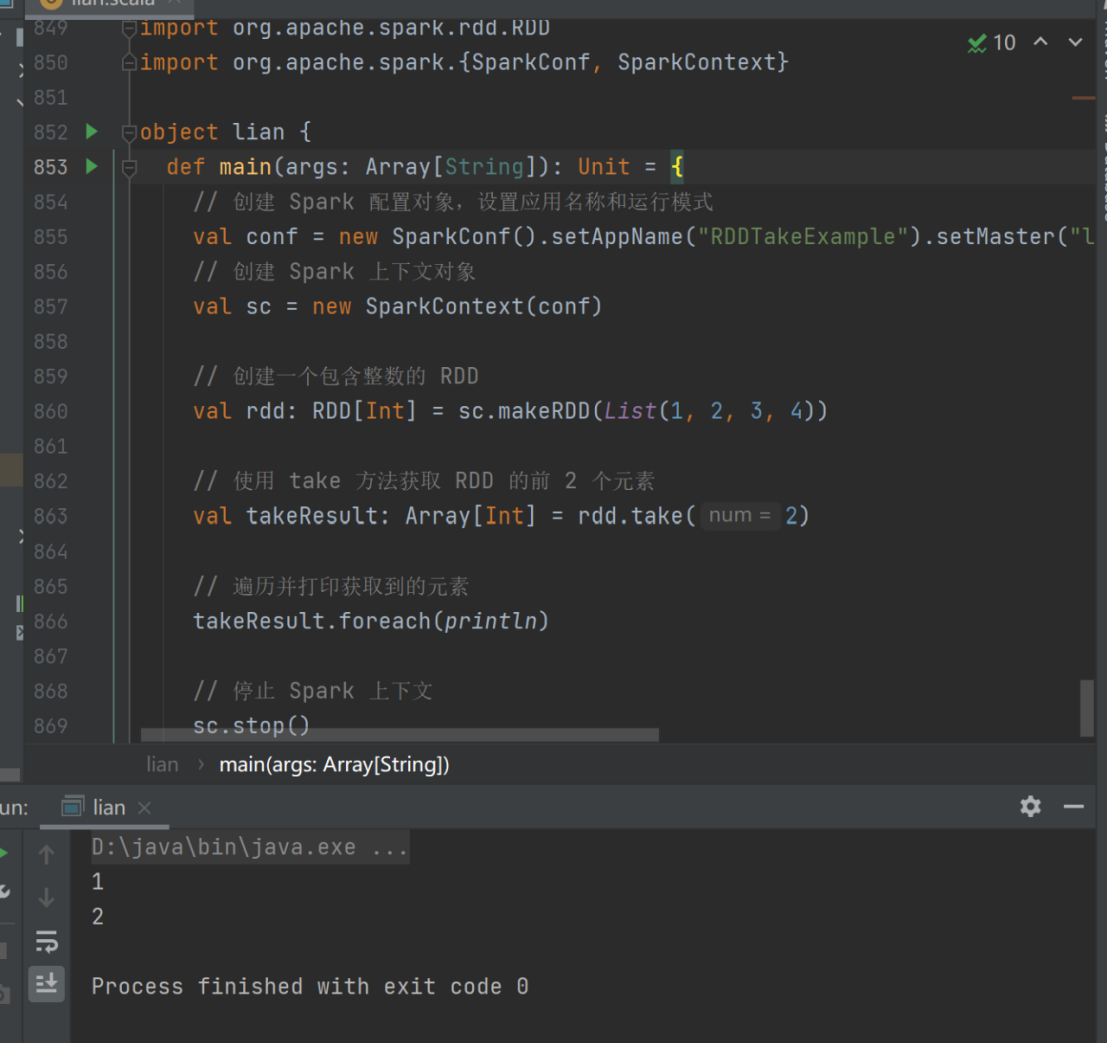
6) take
➢ 函数签名
def take(num: Int): Array[T]
➢ 函数说明
返回一个由 RDD 的前 n 个元素组成的数组
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
val takeResult: Array[Int] = rdd.take(2)
takeResult.foreach(println)
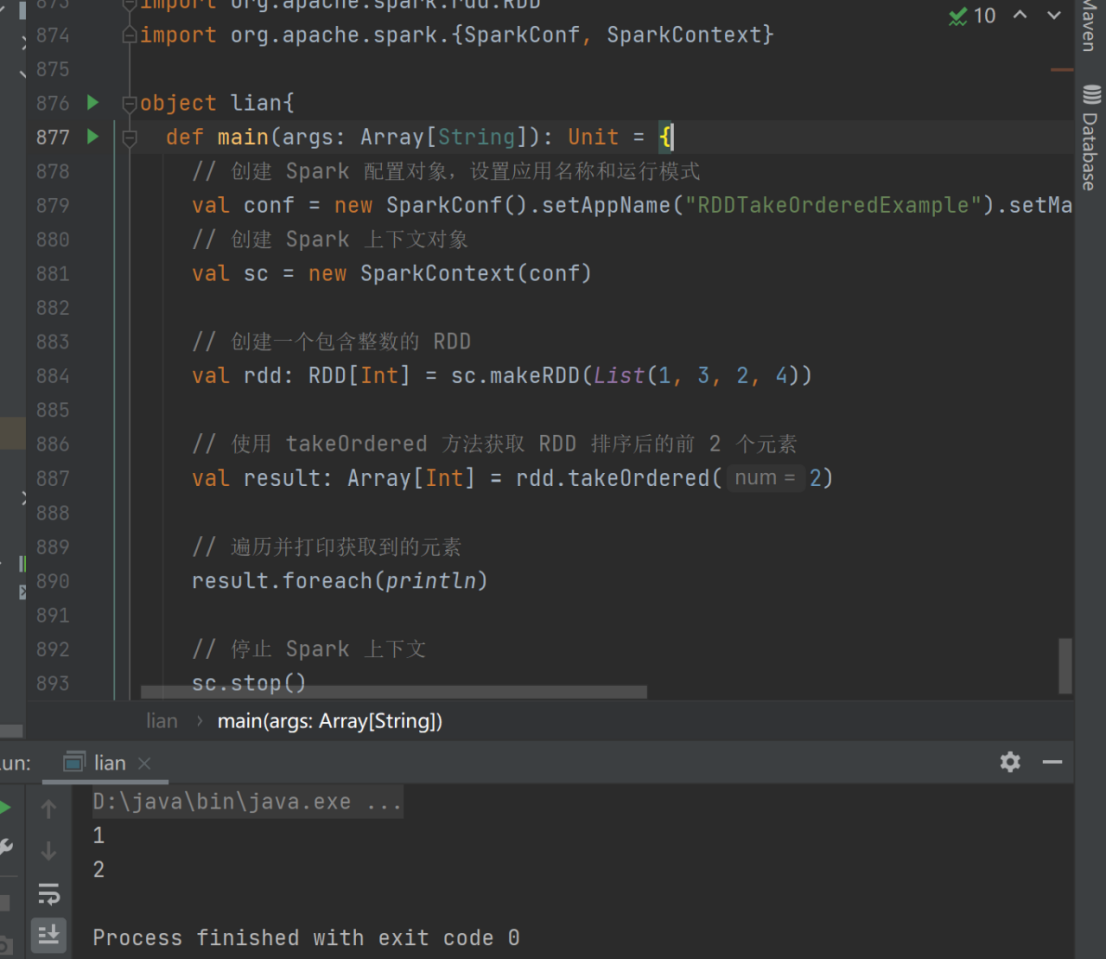
7) takeOrdered
➢ 函数签名
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
➢ 函数说明
返回该 RDD 排序后的前 n 个元素组成的数组
val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4))
val result: Array[Int] = rdd.takeOrdered(2)
result.foreach(println)
8) aggregate
➢ 函数签名
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
➢ 函数说明
分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),8)
// 将该 RDD 所有元素相加得到结果
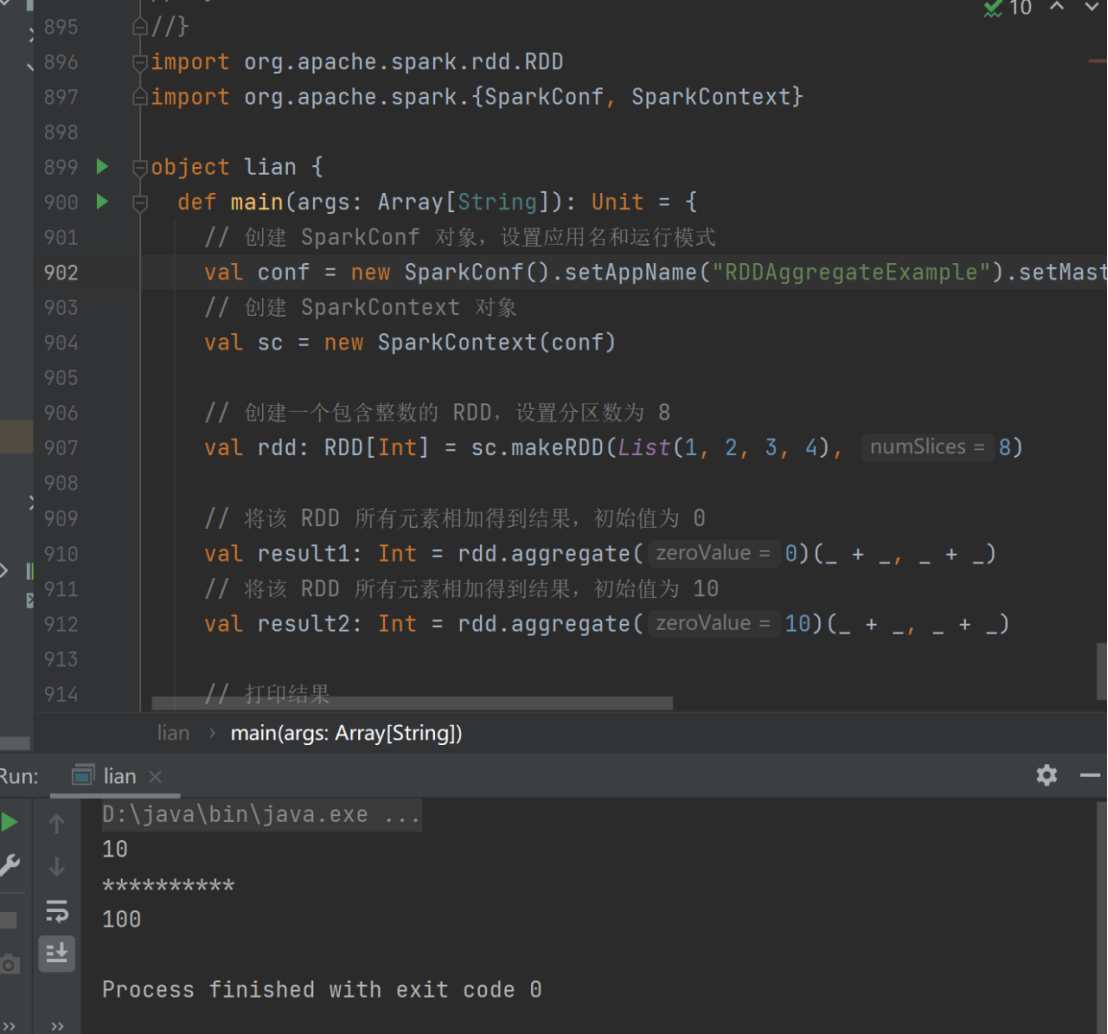
val result1: Int = rdd.aggregate(0)(_+_, _+_)
val result2: Int = rdd.aggregate(10)(_+_,_+_)
println(result1)
println("**********")
9) fold
➢ 函数签名
def fold(zeroValue: T)(op: (T, T) => T): T
➢ 函数说明
折叠操作,aggregate 的简化版操作
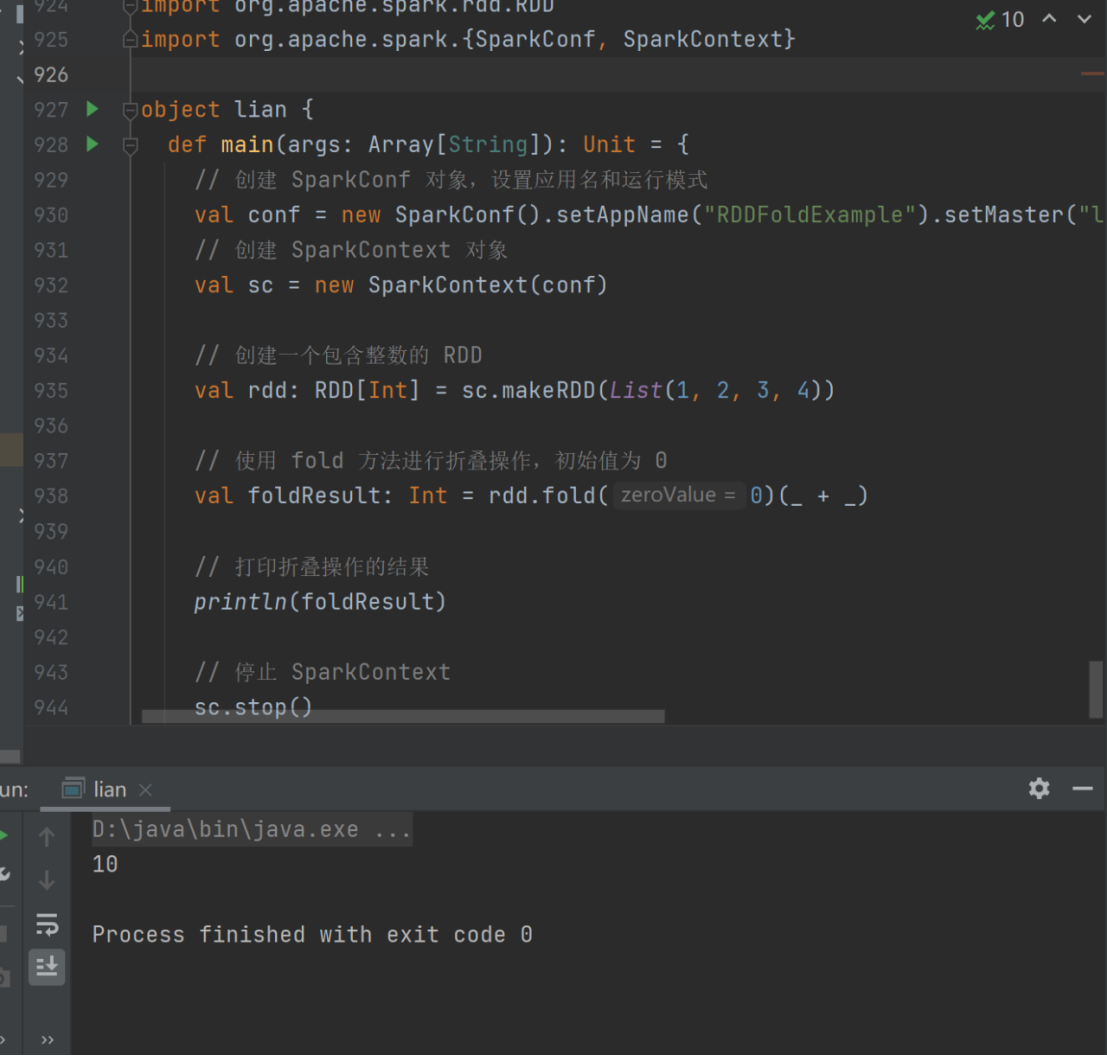
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val foldResult: Int = rdd.fold(0)(_+_)
println(foldResult)
10) countByKey
➢ 函数签名
def countByKey(): Map[K, Long]
➢ 函数说明
统计每种 key 的个数
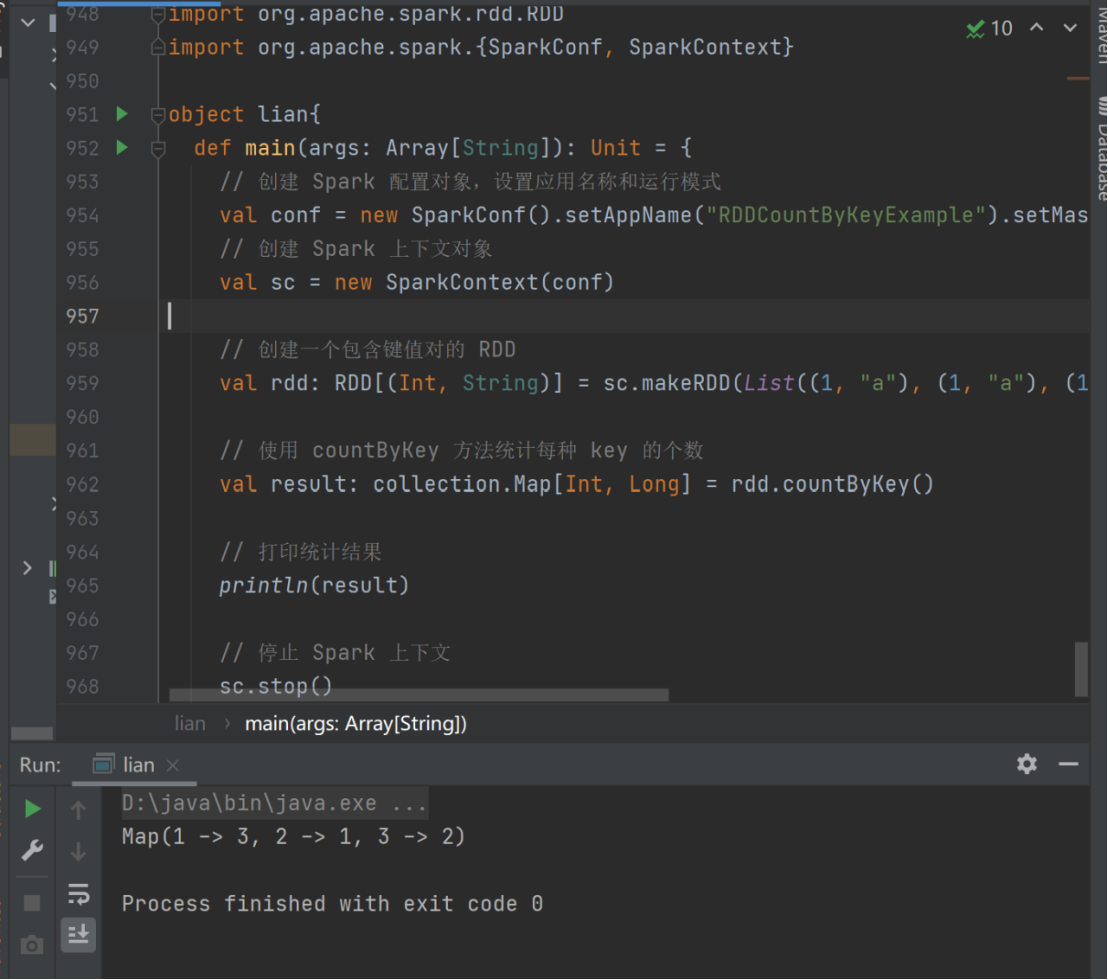
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2,"b"), (3, "c"), (3, "c")))
val result: collection.Map[Int, Long] = rdd.countByKey()
print(result)
11) save 相关算子
➢ 函数签名
def saveAsTextFile(path: String): Unit
def saveAsObjectFile(path: String): Unit
def saveAsSequenceFile(
path: String,
codec: Option[Class[_ <: CompressionCodec]] = None): Unit //了解即可
➢ 函数说明
将数据保存到不同格式的文件中
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
// 保存成 Text 文件
rdd.saveAsTextFile("Spark-core/output/output")
// 序列化成对象保存到文件
rdd.saveAsObjectFile("Spark-core/output/output1")
Spark Core
Spark-Core编程(六)
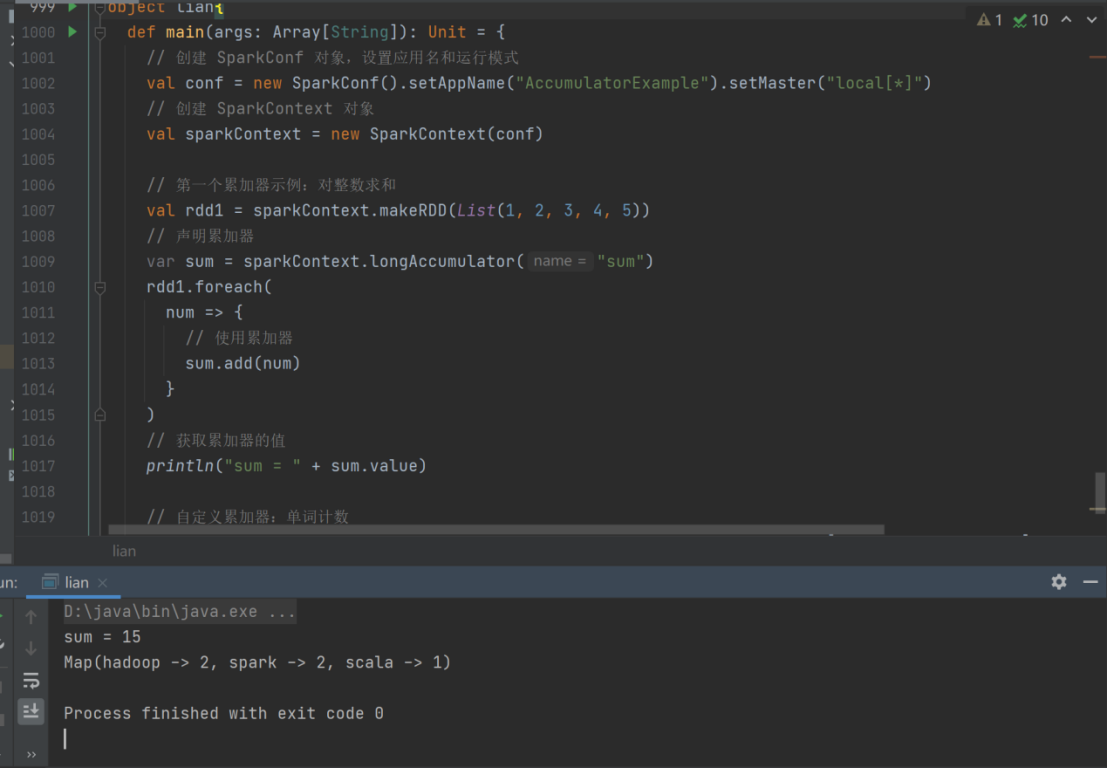
累加器
实现原理
累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在
Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 Driver 端进行 merge。
val rdd = sparkContext.makeRDD(List(1,2,3,4,5))
// 声明累加器
var sum = sparkContext.longAccumulator("sum");
rdd.foreach(
num => {
// 使用累加器
sum.add(num)
}
)
// 获取累加器的值
println("sum = " + sum.value)
自定义累加器实现wordcount:
创建自定义累加器:
class WordCountAccumulator extends AccumulatorV2[String,mutable.Map[String,Long]] {
var map:mutable.Map[String,Long] = mutable.Map()
override def isZero: Boolean = map.isEmpty
override def copy(): AccumulatorV2[String, mutable.Map[String,Long]] = new WordCountAccumulator
override def reset(): Unit = map.clear()
override def add(v: String): Unit = {
map(v) = map.getOrElse(v,0L)+1L
}
override def merge(other: AccumulatorV2[String, mutable.Map[String,Long]
]): Unit = {
val map1 = map
val map2 = other.value
map = map1.foldLeft(map2)(
(innerMap,kv)=>{
innerMap(kv._1) = innerMap.getOrElse(kv._1,0L)+kv._2
innerMap
}
)
}
override def value: mutable.Map[String,Long] = map
}
调用自定义累加器:
val rdd = sparkContext.makeRDD(
List("spark","scala","spark hadoop","hadoop")
)
val acc = new WordCountAccumulator
sparkContext.register(acc)
rdd.flatMap(_.split(" ")).foreach(
word=>acc.add(word)
)
println(acc.value)
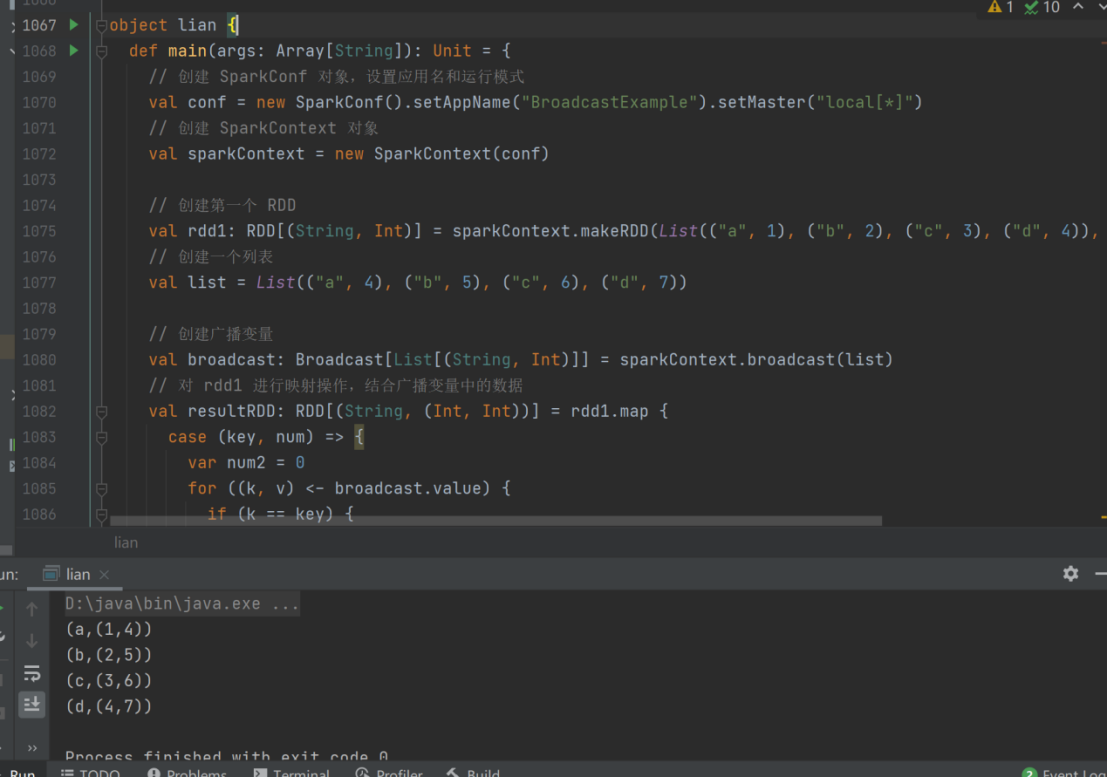
广播变量
实现原理
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个
或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,
广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark 会为每个任务
分别发送。
val rdd1 = sparkContext.makeRDD(List( ("a",1), ("b", 2), ("c", 3), ("d", 4) ),4)
val list = List( ("a",4), ("b", 5), ("c", 6), ("d", 7))
val broadcast :Broadcast[List[(String,Int)]] = sparkContext.broadcast(list)
val resultRDD :RDD[(String,(Int,Int))] = rdd1.map{
case (key,num)=> {
var num2 = 0
for((k,v)<-broadcast.value){
if(k == key) {
num2 = v
}
}
(key,(num,num2))
}
}
resultRDD.collect().foreach(println)
sparkContext.stop()
}
第三章第一节 Spark-SQL简介
Spark-SQL 概述
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。
Spark-SQL 特点
易整合。无缝的整合了 SQL 查询和 Spark 编程
统一的数据访问。使用相同的方式连接不同的数据源
兼容 Hive。在已有的仓库上直接运行 SQL 或者 HQL
标准数据连接。通过 JDBC 或者 ODBC 来连接
DataFrame 是什么
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中 的二维表格。DataFrame 与 RDD 的主要区别在于,前者带有 schema 元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型。
DataSet 是什么
DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame 的一个扩展。它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换(操作 map,flatMap,filter 等等)
DataSet 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象
用户友好的 API 风格,既具有类型安全检查也具有 DataFrame 的查询优化特性;
用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到 DataSet 中的字段名称;
DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person]。
DataFrame 是 DataSet 的特列,DataFrame=DataSet[Row] ,所以可以通过 as 方法将 DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。
第三章第二节 Spark-SQL核心编程(一)
DataFrame
Spark SQL 的 DataFrame API 允许我们使用 DataFrame 而不用必须去注册临时表或者生成 SQL 表达式。DataFrame API 既有 transformation 操作也有 action 操作。
创建 DataFrame
在 Spark SQL 中 SparkSession 是创建 DataFrame 和执行 SQL 的入口,创建 DataFrame
有三种方式:通过 Spark 的数据源进行创建;从一个存在的 RDD 进行转换;还可以从 Hive
Table 进行查询返回。
从 Spark 数据源进行创建
Spark-SQL支持的数据类型:

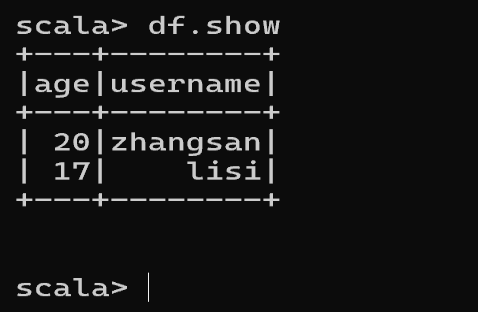
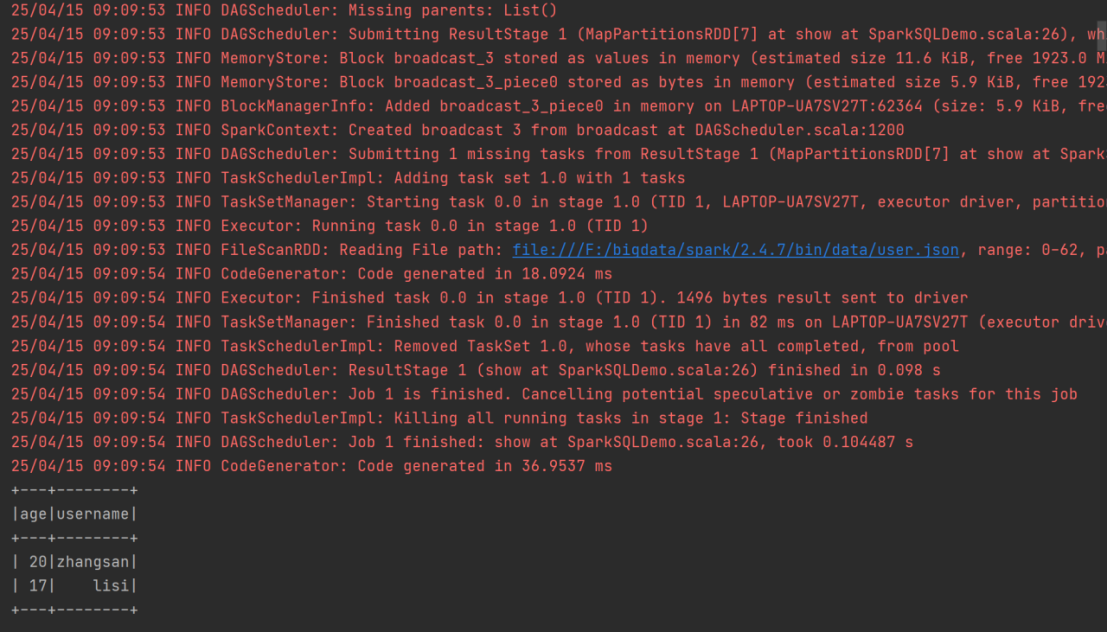
➢ 在 spark 的 bin/data 目录中创建 user.json 文件
{"username":"zhangsan","age":20}
{"username":"lisi","age":17}
➢ 读取 json 文件创建 DataFrame
val df = spark.read.json("F:\\bigdata\\spark\\2.4.7\\bin\\data\\user.json")

展示数据:
df.show
SQL 语法
SQL 语法风格是指我们查询数据的时候使用 SQL 语句来查询,这种风格的查询必须要
有临时视图或者全局视图来辅助
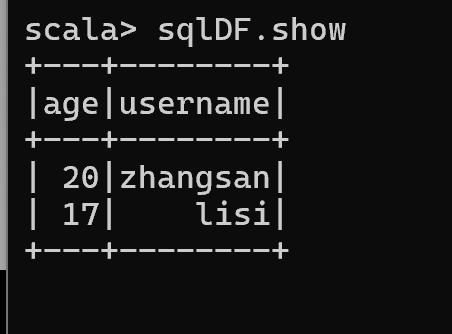
- 读取 JSON 文件创建 DataFrame
val df1 = spark.read.json("F:\\bigdata\\spark\\2.4.7\\bin\\data\\user.json")

- 对 DataFrame 创建一个临时表
df1.createOrReplaceTempView("people")

- 通过 SQL 语句实现查询全表
val sqlDF = spark.sql("select * from people")

- 结果展示
sqlDF.show
第三章第三节 Spark-SQL核心编程(二)
DataFrame
DSL 语法
DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。 可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图了。
- 创建一个 DataFrame
val df = spark.read.json("F:\\bigdata\\spark\\2.4.7\\bin\\data\\user.json")

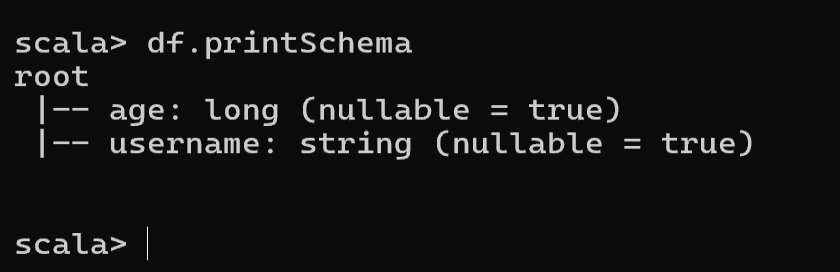
- 查看 DataFrame 的 Schema 信息
df.printSchema
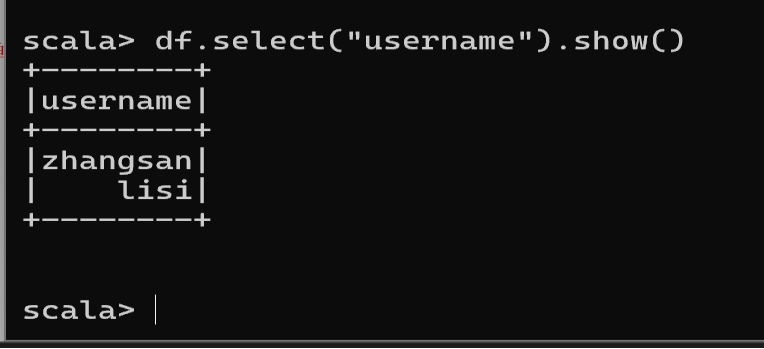
- 只查看"username"列数据
df.select("username").show()
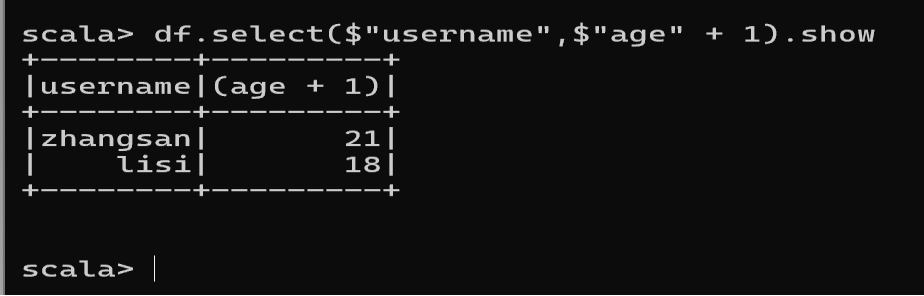
- 查看"username"列数据以及"age+1"数据
注意:涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
df.select($"username",$"age" + 1).show
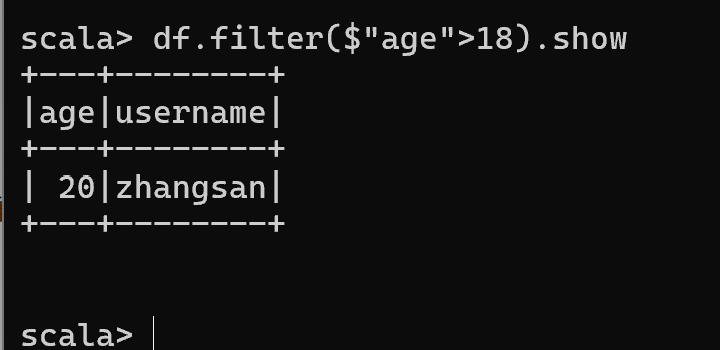
- 查看"age"大于"18"的数据
df.filter($"age">18).show
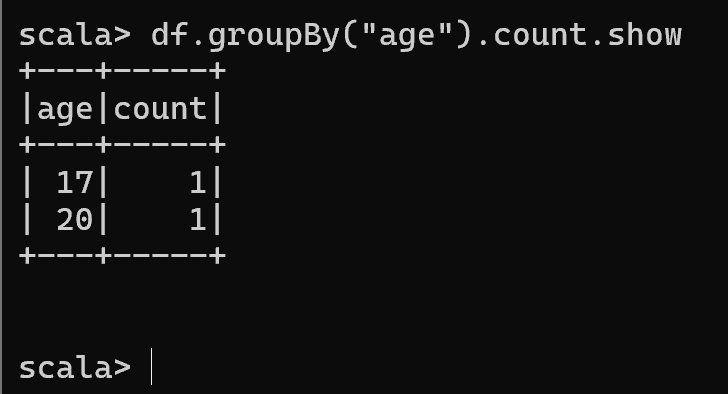
- 按照"age"分组,查看数据条数
df.groupBy("age").count.show
RDD 转换为 DataFrame
在 IDEA 中开发程序时,如果需要 RDD 与 DF 或者 DS 之间互相操作,那么需要引入 import spark.implicits._ 这里的 spark 不是 Scala 中的包名,而是创建的 sparkSession 对象的变量名称,所以必 须先创建 SparkSession 对象再导入。这里的 spark 对象不能使用 var 声明,因为 Scala 只支持 val 修饰的对象的引入。
spark-shell 中无需导入,自动完成此操作。
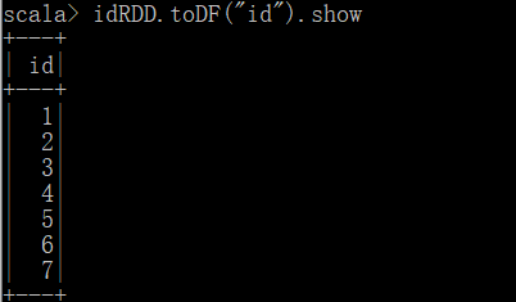
val idRDD = sc.textFile("F:\\bigdata\\spark\\2.4.7\\bin\\data\\id.txt")

idRDD.toDF("id").show
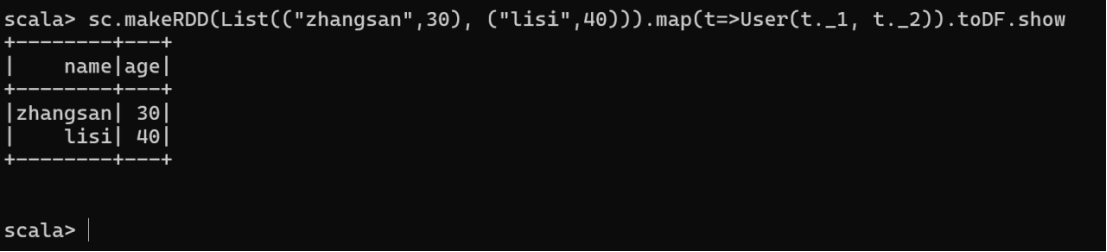
实际开发中,一般通过样例类将 RDD 转换为 DataFrame
case class User(name:String, age:Int)

sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF.show
DataFrame 转换为 RDD
DataFrame 其实就是对 RDD 的封装,所以可以直接获取内部的 RDD
val df = sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF

val rdd = df.rdd

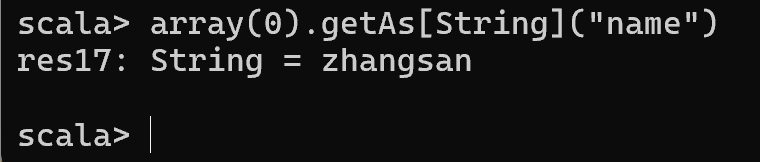
val array = rdd.collect

注意:此时得到的 RDD 存储类型为 Row
array(0)

array(0)(0)

array(0).getAs[String]("name")
第三章第四节 Spark-SQL核心编程(三)
DataSet
DataSet 是具有强类型的数据集合,需要提供对应的类型信息。
创建 DataSet
1) 使用样例类序列创建 DataSet
case class Person(name: String, age: Long)

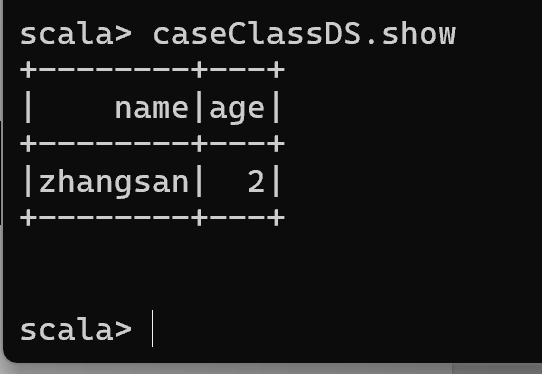
val caseClassDS = Seq(Person("zhangsan",2)).toDS()

caseClassDS.show
2) 使用基本类型的序列创建 DataSet
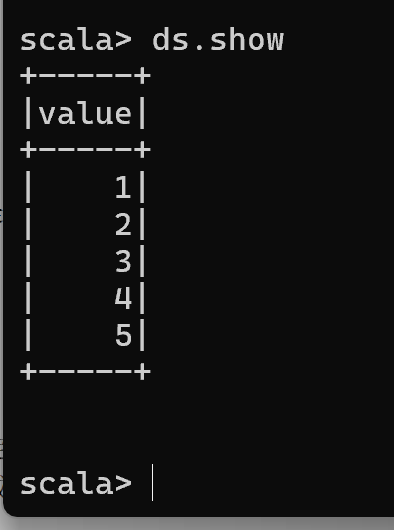
val ds = Seq(1,2,3,4,5).toDS

ds.show
注意:在实际使用的时候,很少用到把序列转换成DataSet,更多的是通过RDD来得到DataSet
RDD 转换为 DataSet
SparkSQL 能够自动将包含有 case 类的 RDD 转换成 DataSet,case 类定义了 table 的结 构,case 类属性通过反射变成了表的列名。Case 类可以包含诸如 Seq 或者 Array 等复杂的结构。
case class User(name:String, age:Int)
sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDS

DataSet 转换为 RDD
DataSet 其实也是对 RDD 的封装,所以可以直接获取内部的 RDD
case class User(name:String, age:Int)

sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1, t._2)).toDS

val rdd = res3.rdd

rdd.collect

DataFrame 和 DataSet 转换
DataFrame 其实是 DataSet 的特例,所以它们之间是可以互相转换的。
DataFrame 转换为 DataSet
case class User(name:String, age:Int)
val df = sc.makeRDD(List(("zhangsan",30), ("lisi",49))).toDF("name","age")

val ds = df.as[User]

DataSet 转换为 DataFrame
val ds = df.as[User]

val df = ds.toDF

Spark-SQL核心编程(四)
实验内容:
利用IDEA开发Spark-SQL。
实验步骤:
利用IDEA开发Spark-SQL
- 创建子模块Spark-SQL,并添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
- 创建Spark-SQL的测试代码:
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SparkSession, DataFrame, Dataset}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.Row
case class User(id:Int, name:String, age:Int)
object SparkSQLDemo {
def main(args: Array[String]): Unit = {
// 创建上下文环境配置对象
val sparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("SQLDemo")
.set("spark.some.config.option", "some-value") // 可选配置
// 创建SparkSession对象
val spark: SparkSession = SparkSession.builder()
.config(sparkConf)
.getOrCreate()
import spark.implicits._
// 1. 读取json文件
val df: DataFrame = spark.read.json("F:\\bigdata\\spark\\2.4.7\\bin\\data\\user.json")
println("原始数据:")
df.show()
// 2. SQL风格语法
df.createOrReplaceTempView("user")
println("SQL查询所有数据:")
spark.sql("SELECT * FROM user").show()
println("SQL计算平均年龄:")
spark.sql("SELECT avg(age) as avg_age FROM user").show()
// 3. DSL风格语法
println("DSL查询部分字段:")
df.select($"username", $"age").show()
println("DSL过滤查询:")
df.filter($"age" > 25).show()
// 4. RDD <=> DataFrame <=> DataSet 转换
// 4.1 RDD => DataFrame => DataSet
println("RDD => DataFrame => DataSet 转换:")
val rdd1: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(
List((1, "zhangsan", 30), (2, "lisi", 40), (3, "wangwu", 25))
)
// RDD转DataFrame
val df1: DataFrame = rdd1.toDF("id", "name", "age")
println("RDD转DataFrame:")
df1.show()
// DataFrame转DataSet
val ds1: Dataset[User] = df1.as[User]
println("DataFrame转DataSet:")
ds1.show()
// 4.2 DataSet => DataFrame => RDD
println("DataSet => DataFrame => RDD 转换:")
val df2 = ds1.toDF()
println("DataSet转DataFrame:")
df2.show()
val rdd2: RDD[Row] = df2.rdd
println("DataFrame转RDD并打印:")
rdd2.foreach(row => println(s"Row: id=${row.getInt(0)}, name=${row.getString(1)}, age=${row.getInt(2)}"))
// 4.3 直接RDD转DataSet
println("直接RDD转DataSet:")
rdd1.map {
case (id, name,age) => User(id, name, age)
}.toDS().show()
// 4.4 DataSet转RDD
val rdd3 = ds1.rdd
println("DataSet转RDD并打印字段:")
rdd3.foreach(user => println(s"User: id=${user.id}, name=${user.name}, age=${user.age}"))
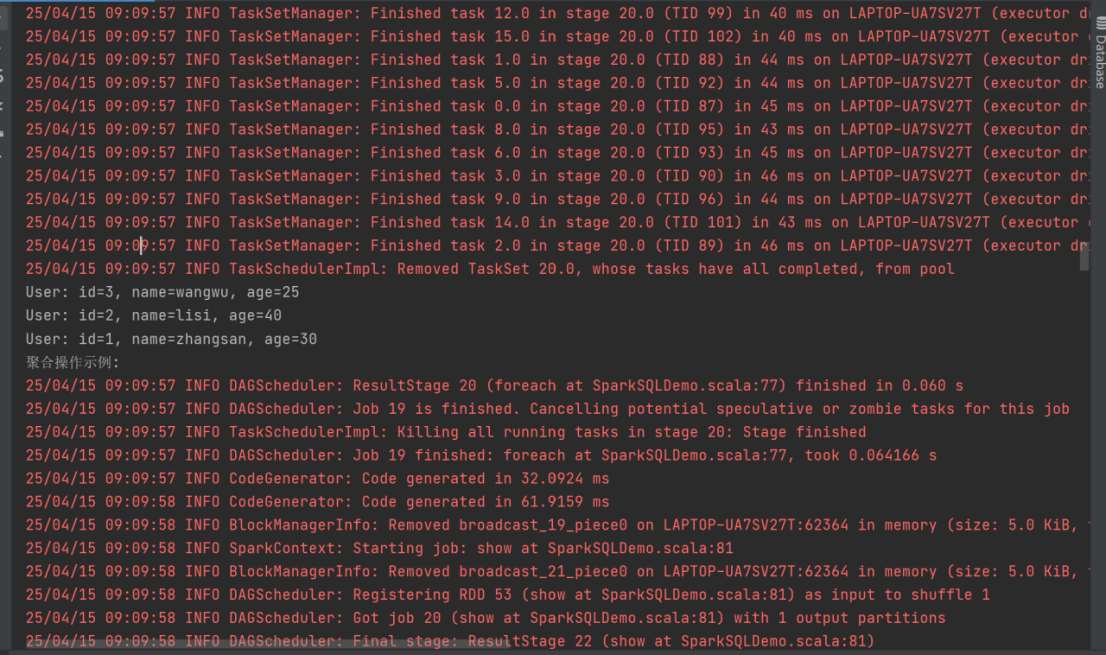
// 5. 聚合操作示例
println("聚合操作示例:")
ds1.groupBy("age").count().show()
// 6. 类型安全的DataSet操作
println("类型安全的DataSet操作:")
ds1.filter(_.age > 30).show()
// 关闭SparkSession
spark.stop()
}
}
第三章第六节 Spark-SQL核心编程(五)
自定义函数:
UDF:
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SQLDemo")
//创建SparkSession对象
val spark :SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
//读取json文件
val df : DataFrame = spark.read.json("Spark-SQL/input/user.json")
spark.udf.register("addName",(x:String)=>"Name:"+x)
df.createOrReplaceTempView("people")
spark.sql("select addName(username),age from people").show()
spark.stop()
UDAF(自定义聚合函数)
强类型的 Dataset 和弱类型的 DataFrame 都提供了相关的聚合函数, 如 count(),
countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。Spark3.0之前我们使用的是UserDefinedAggregateFunction作为自定义聚合函数,从 Spark3.0 版本后可以统一采用强类型聚合函数 Aggregator
实验需求:计算平均工资
实现方式一:RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDD{
def main(args: Array[String]): Unit = {
// 1. 创建Spark配置和上下文
val sparkConf: SparkConf = new SparkConf()
.setAppName("SalaryAverageCalculation")
.setMaster("local[*]") // 使用本地所有可用核
val sc: SparkContext = new SparkContext(sparkConf)
try {
// 2. 创建RDD并计算平均工资
val resRDD: (Int, Int) = sc.makeRDD(List(("zhangsan", 20), ("lisi", 30), ("wangwu", 40)))
.map {
case (name, salary) => {
(salary, 1) // 转换为(工资, 计数)的元组
}
}
.reduce {
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2) // 累加工资总和和人数
}
}
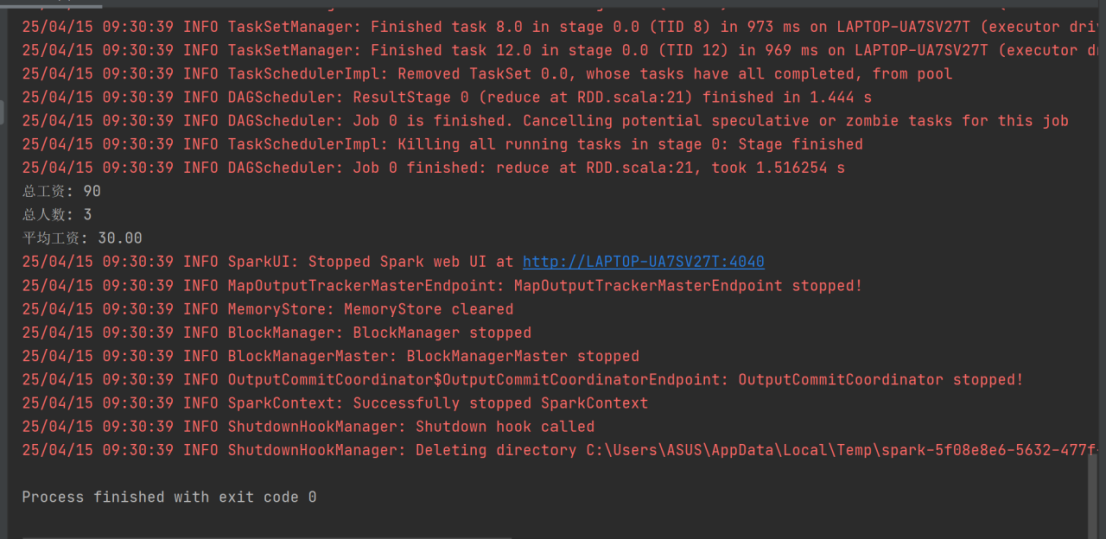
// 3. 计算并打印平均工资
if (resRDD._2 != 0) {
val averageSalary = resRDD._1.toDouble / resRDD._2
println(f"总工资: ${resRDD._1}")
println(f"总人数: ${resRDD._2}")
println(f"平均工资: $averageSalary%.2f") // 保留两位小数
} else {
println("警告:没有有效数据计算平均工资")
}
} finally {
// 4. 确保无论如何都关闭SparkContext
sc.stop()
}
}
}
实现方式二:强类型UDAF
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.Encoder
import org.apache.spark.sql.Encoders
import org.apache.spark.sql.functions
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.DataFrame
// 定义一个用于存储总和和计数的缓冲区类
case class Buff(var sum: Long, var cnt: Long)
// 自定义聚合函数类,继承自 Aggregator
class MyAverageUDAF extends org.apache.spark.sql.expressions.Aggregator[Long, Buff, Double] {
// 初始化缓冲区
override def zero: Buff = Buff(0, 0)
// 合并输入值到缓冲区
override def reduce(b: Buff, a: Long): Buff = {
b.sum += a
b.cnt += 1
b
}
// 合并两个缓冲区
override def merge(b1: Buff, b2: Buff): Buff = {
b1.sum += b2.sum
b1.cnt += b2.cnt
b1
}
// 完成聚合操作,计算最终结果
override def finish(reduction: Buff): Double = {
reduction.sum.toDouble / reduction.cnt
}
// 定义缓冲区的编码器
override def bufferEncoder: Encoder[Buff] = Encoders.product
// 定义输出结果的编码器
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
object Cyy {
def main(args: Array[String]): Unit = {
// 创建 SparkConf 对象,设置应用名称和运行模式
val sparkconf: SparkConf = new SparkConf().setAppName("app").setMaster("local[*]")
// 创建 SparkSession 对象
val spark: SparkSession = SparkSession.builder().config(sparkconf).getOrCreate()
import spark.implicits._
// 创建 RDD 并存储人员姓名和工资信息
val res: RDD[(String, Int)] = spark.sparkContext.makeRDD(List(("zhangsan", 20), ("lisi", 30), ("wangwu", 40)))
// 将 RDD 转换为 DataFrame
val df: DataFrame = res.toDF("name", "salary")
// 在 Spark 中注册临时视图
df.createOrReplaceTempView("user")
// 创建自定义聚合函数实例
var myAverage = new MyAverageUDAF
// 在 Spark 中注册聚合函数
spark.udf.register("avgSalary", functions.udaf(myAverage))
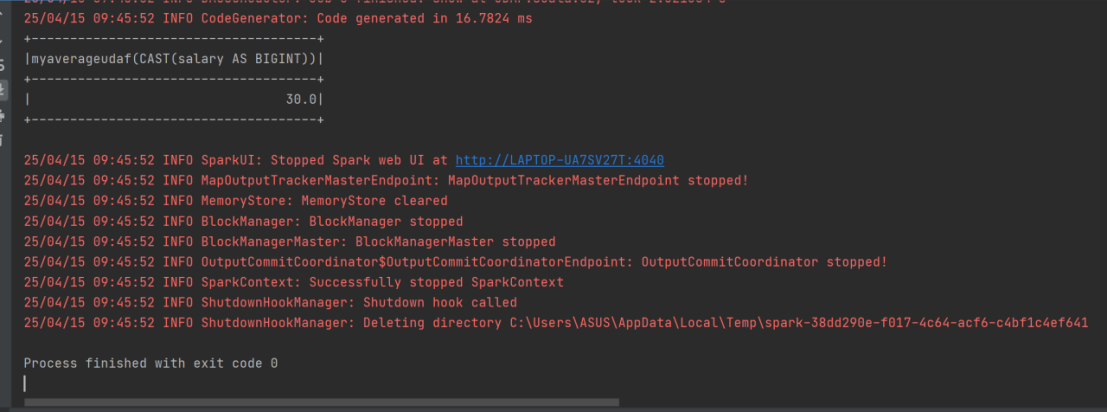
// 执行 SQL 查询,计算平均工资并显示结果
spark.sql("select avgSalary(salary) from user").show()
// 关闭 SparkSession 连接
spark.stop()
}
}
第七节 Spark-SQL核心编程(六)
MySQL
Spark SQL 可以通过 JDBC 从关系型数据库中读取数据的方式创建 DataFrame,通过对
DataFrame 一系列的计算后,还可以将数据再写回关系型数据库中。
IDEA通过JDBC对MySQL进行操作:
- 导入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
MySQL8 <version>8.0.11</version>
- 读取数据
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SQL")
val spark:SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
//通用的load方式读取
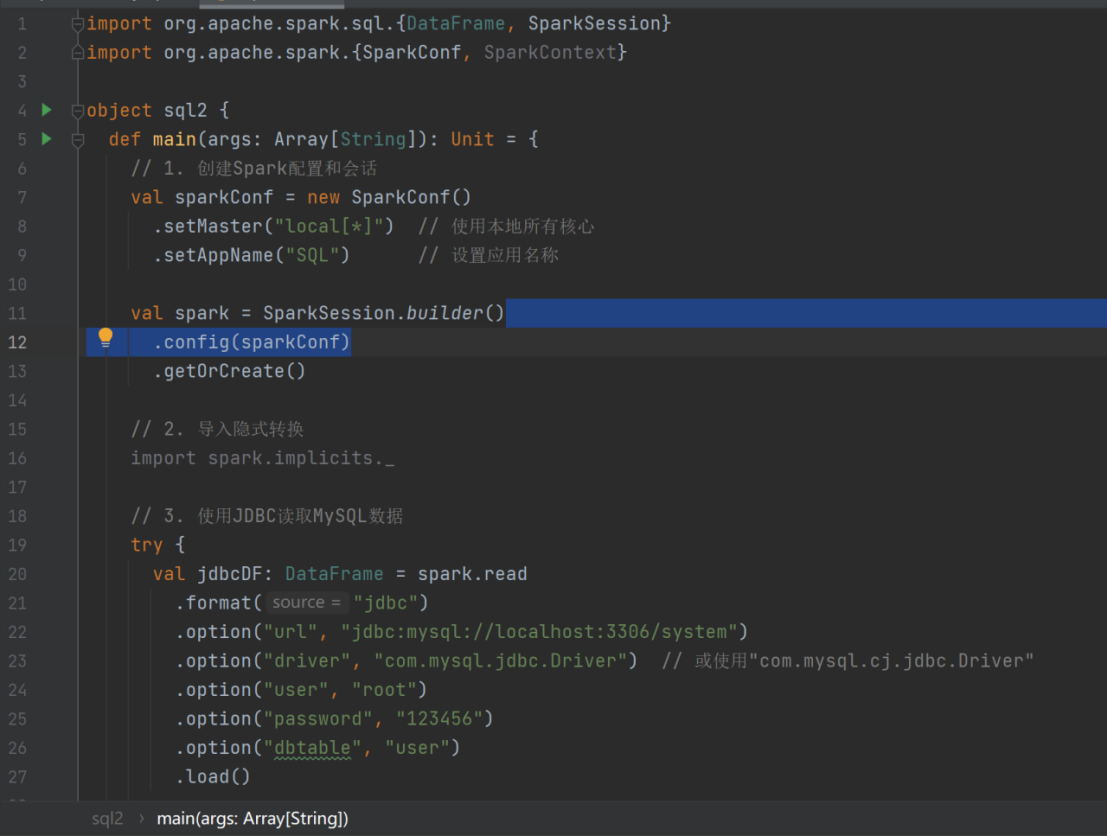
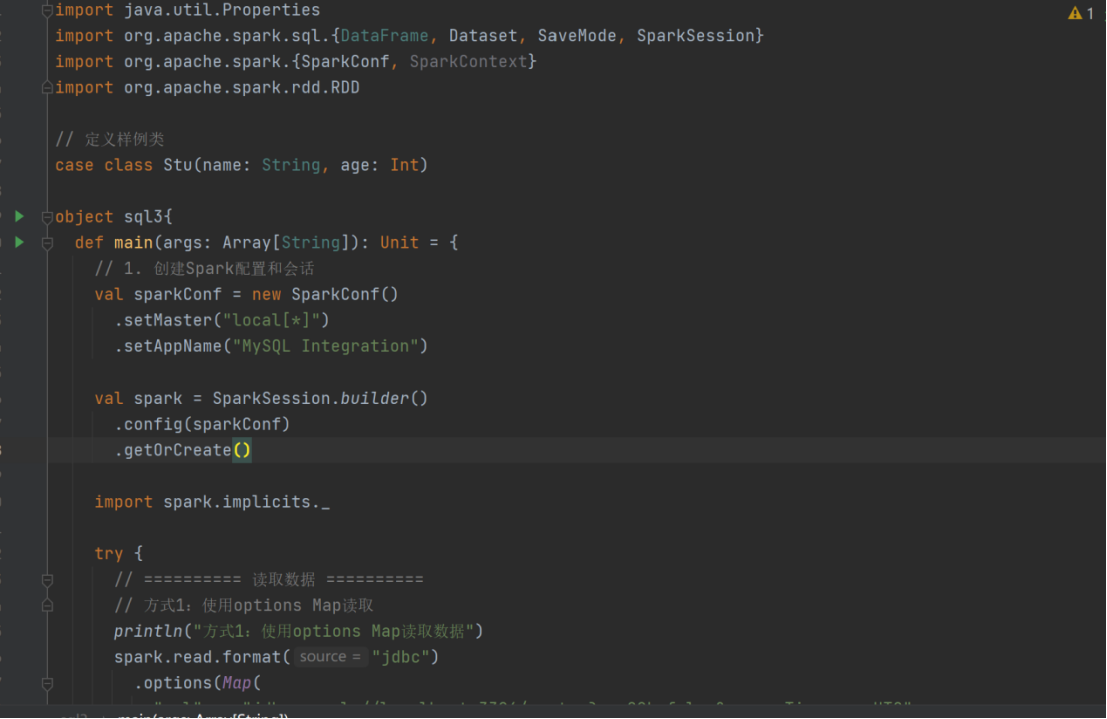
spark.read.format("jdbc")
.option("url","jdbc:mysql://localhost:3306/system")
.option("driver","com.mysql.jdbc.Driver")//com.mysql.cj.jdbc.Driver
.option("user","root")
.option("password","123456")
.option("dbtable","user")
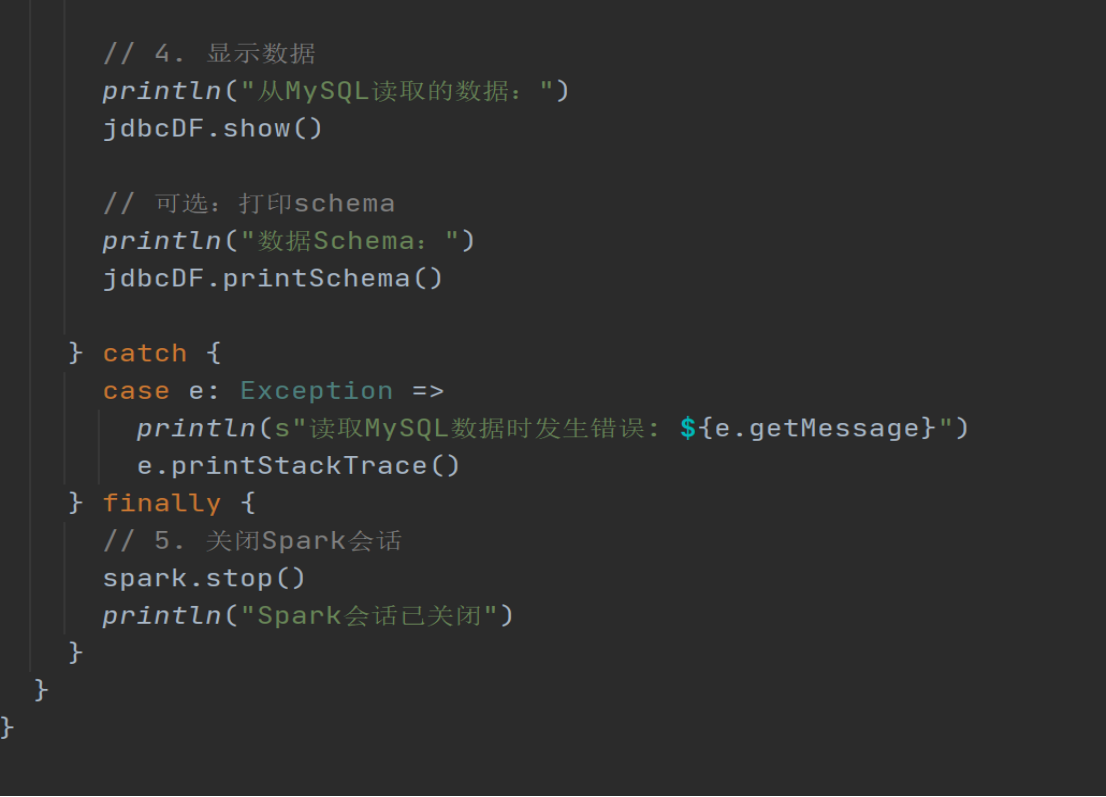
.load().show()
spark.stop()
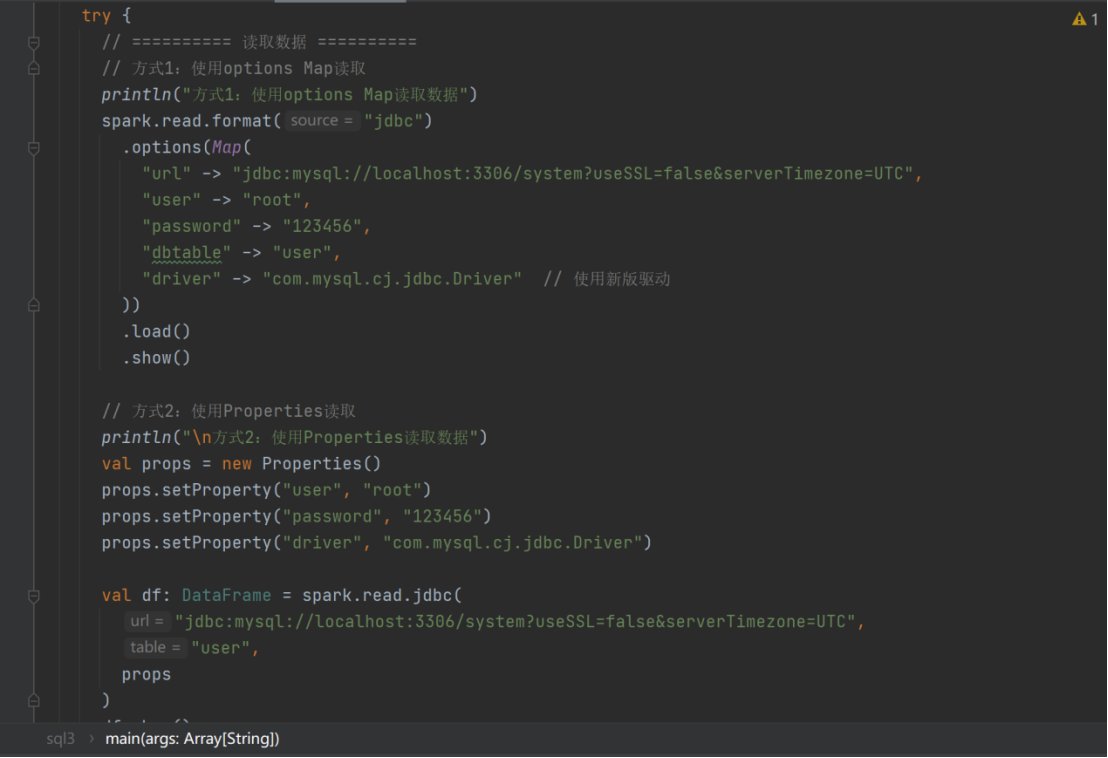
//通用的load方法的另一种形式
spark.read.format("jdbc")
.options(
Map("url"->"jdbc:mysql://localhost:3306/system?user=root&password=123456","dbtable"->"user","driver"->"com.mysql.jdbc.Driver"))
.load().show()
//通过JDBC
val pros :Properties = new Properties()
pros.setProperty("user","root")
pros.setProperty("password","123456")
val df :DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/system","user",pros)
df.show()
- 写入数据
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SQL")
val spark:SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
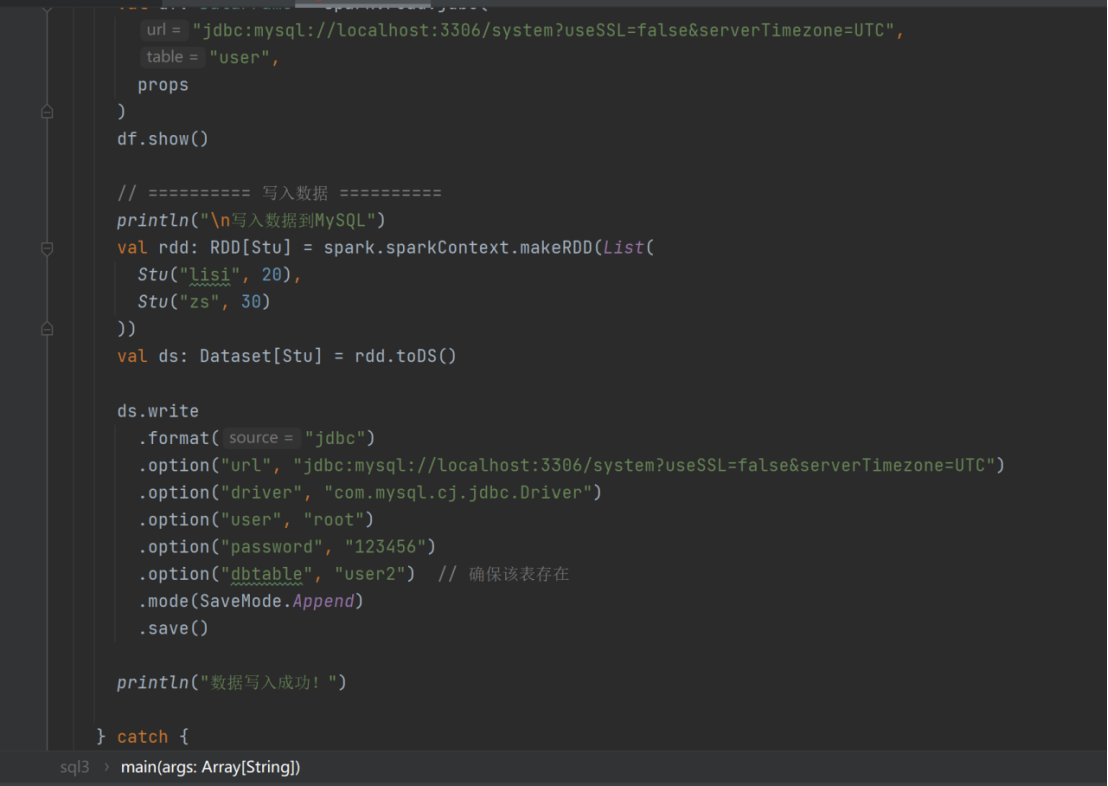
val rdd: RDD[Stu] = spark.sparkContext.makeRDD(List(Stu("lisi", 20),
Stu("zs", 30)))
val ds:Dataset[Stu] = rdd.toDS()
ds.write.format("jdbc")
.option("url","jdbc:mysql://localhost:3306/system")
.option("driver","com.mysql.jdbc.Driver")
.option("user","root")
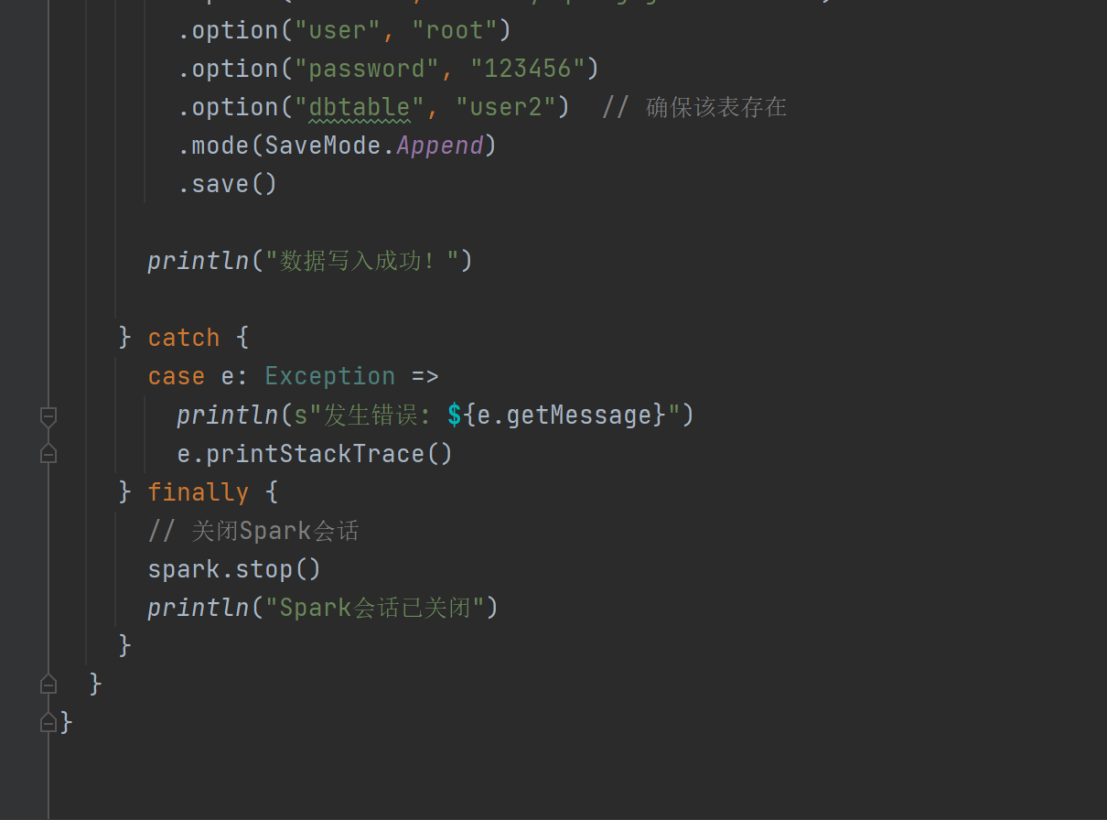
.option("password","123456")
.option("dbtable","user2")
.mode(SaveMode.Append)
.save()
spark.stop()
Spark-SQL核心编程(七)
代码操作Hive
1. 导入依赖。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.3</version>
</dependency>
可能出现下载jar包的问题:
D:\maven\repository\org\pentaho\pentaho-aggdesigner-algorithm\5.1.5-jhyde
2. 将hive-site.xml 文件拷贝到项目的 resources 目录中。
3. 代码实现。
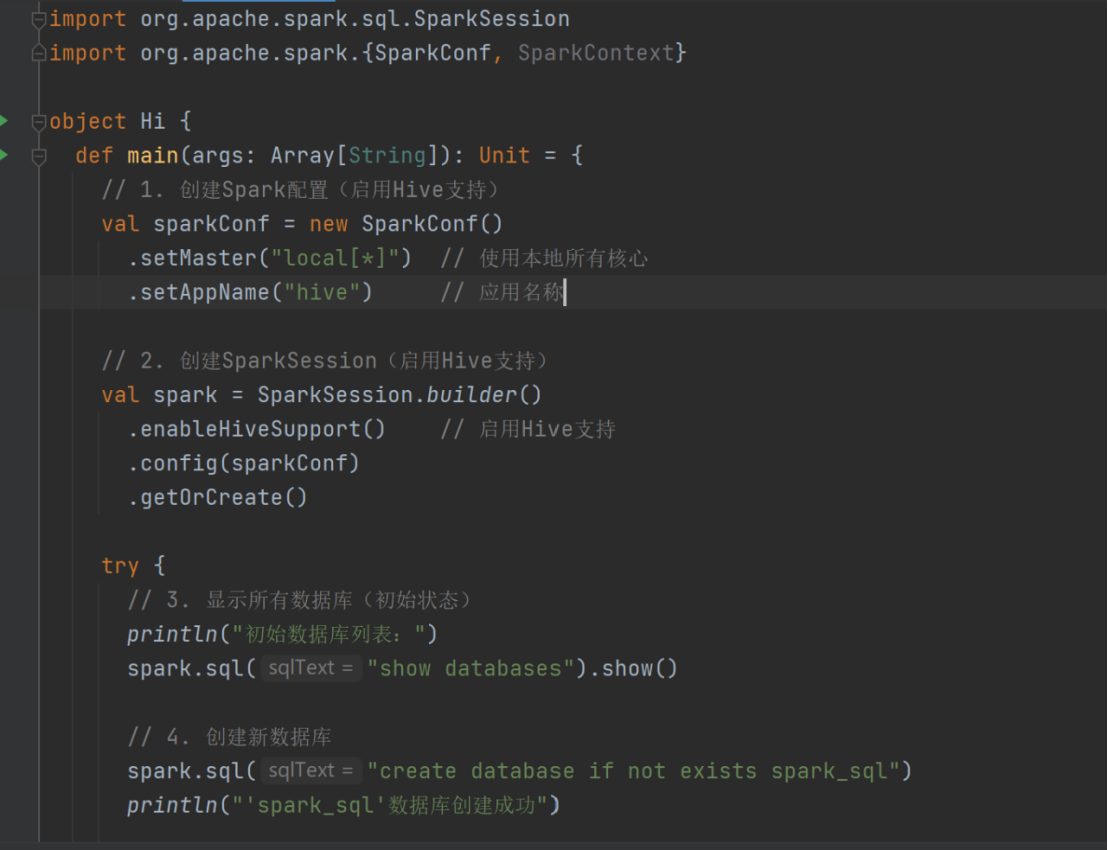
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("hive")
val spark:SparkSession = SparkSession.builder()
.enableHiveSupport()
.config(sparkConf)
.getOrCreate()
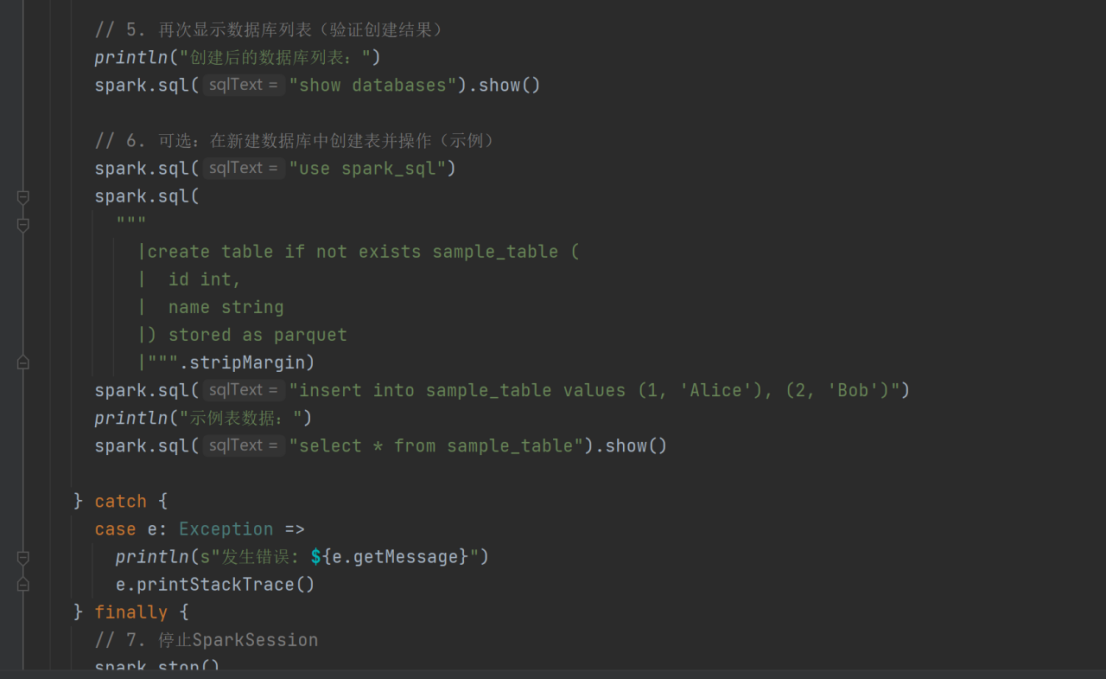
spark.sql("show databases").show()
spark.sql("create database spark_sql")
spark.sql("show databases").show()
注意:
- 如果在执行操作时,出现如下错误:

可以在代码最前面增加如下代码解决:
System.setProperty("HADOOP_USER_NAME", "node01")
此处的 node01 改为自己的 hadoop 用户名称
- 在开发工具中创建数据库默认是在本地仓库,通过参数修改数据库仓库的地址: config("spark.sql.warehouse.dir", "hdfs://node01:9000/user/hive/warehouse")

Spark-Streaming
DStream实操
案例一:WordCount案例
需求:使用 netcat 工具向 9999 端口不断的发送数据,通过 SparkStreaming 读取端口数据并统计不同单词出现的次数
实验步骤:
- 添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
- 编写代码
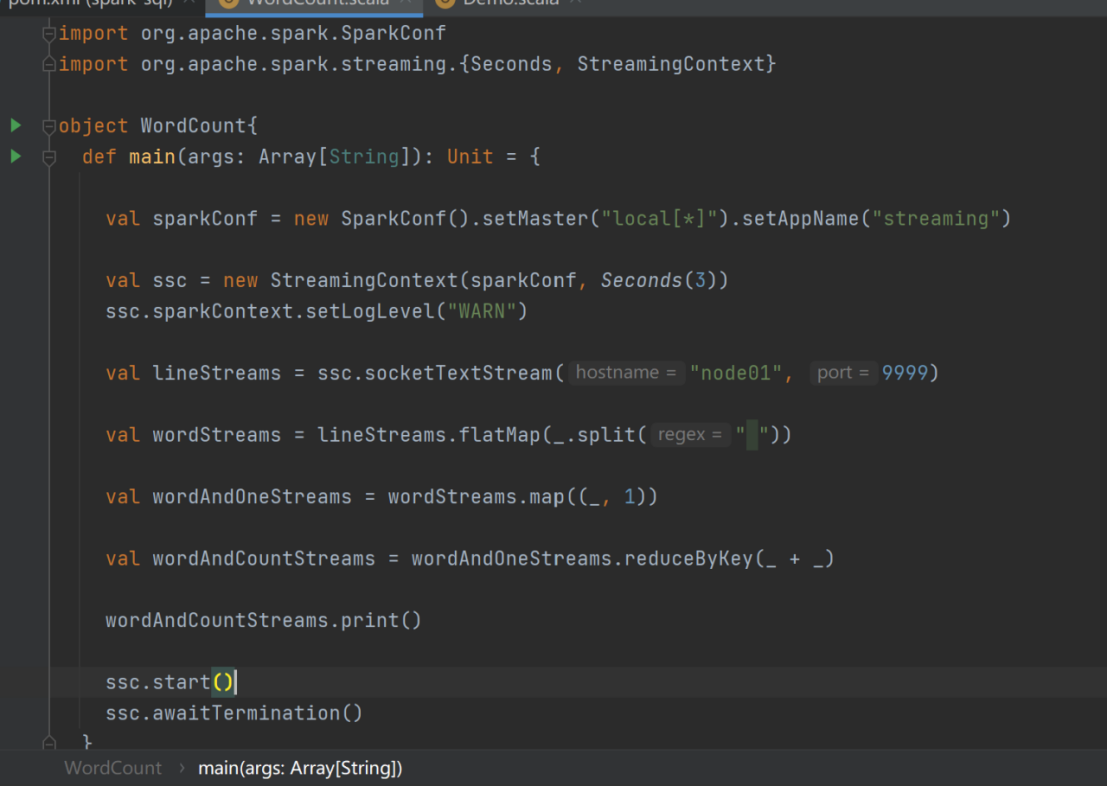
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("streaming")
val ssc = new StreamingContext(sparkConf,Seconds(3))
val lineStreams = ssc.socketTextStream("node01",9999)
val wordStreams = lineStreams.flatMap(_.split(" "))
val wordAndOneStreams = wordStreams.map((_,1))
val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_)
wordAndCountStreams.print()
ssc.start()
ssc.awaitTermination()
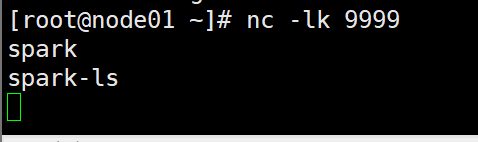
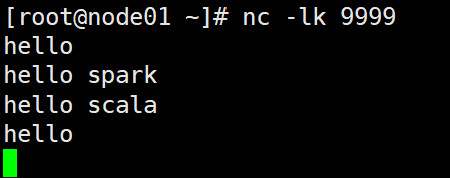
- 启动netcat发送数据
nc -lk 9999
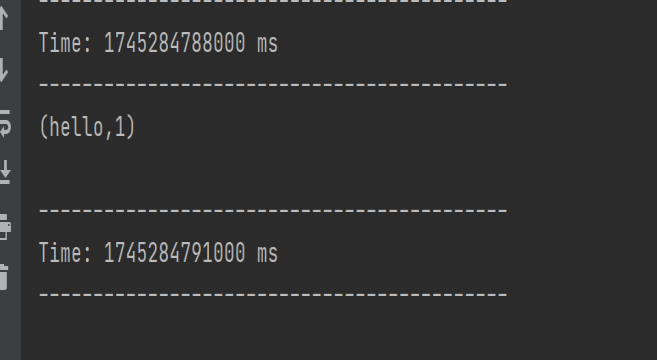
Spark-Streaming核心编程(一)
DStream 创建
创建DStream的三种方式:RDD队列、自定义数据源、kafka数据源
RDD队列
可以通过使用 ssc.queueStream(queueOfRDDs)来创建 DStream,每一个推送到这个队列中的 RDD,都会作为一个DStream 处理。
案例:
需求:循环创建几个 RDD,将 RDD 放入队列。通过 SparkStream 创建 Dstream,计算 WordCount
代码:
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDDStream")
val ssc = new StreamingContext(sparkConf, Seconds(4))
val rddQueue = new mutable.Queue[RDD[Int]]()
val inputStream = ssc.queueStream(rddQueue,oneAtATime = false)
val mappedStream = inputStream.map((_,1))
val reducedStream = mappedStream.reduceByKey(_ + _)
reducedStream.print()
ssc.start()
for (i <- 1 to 5) {
rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)
Thread.sleep(2000)
}
ssc.awaitTermination()
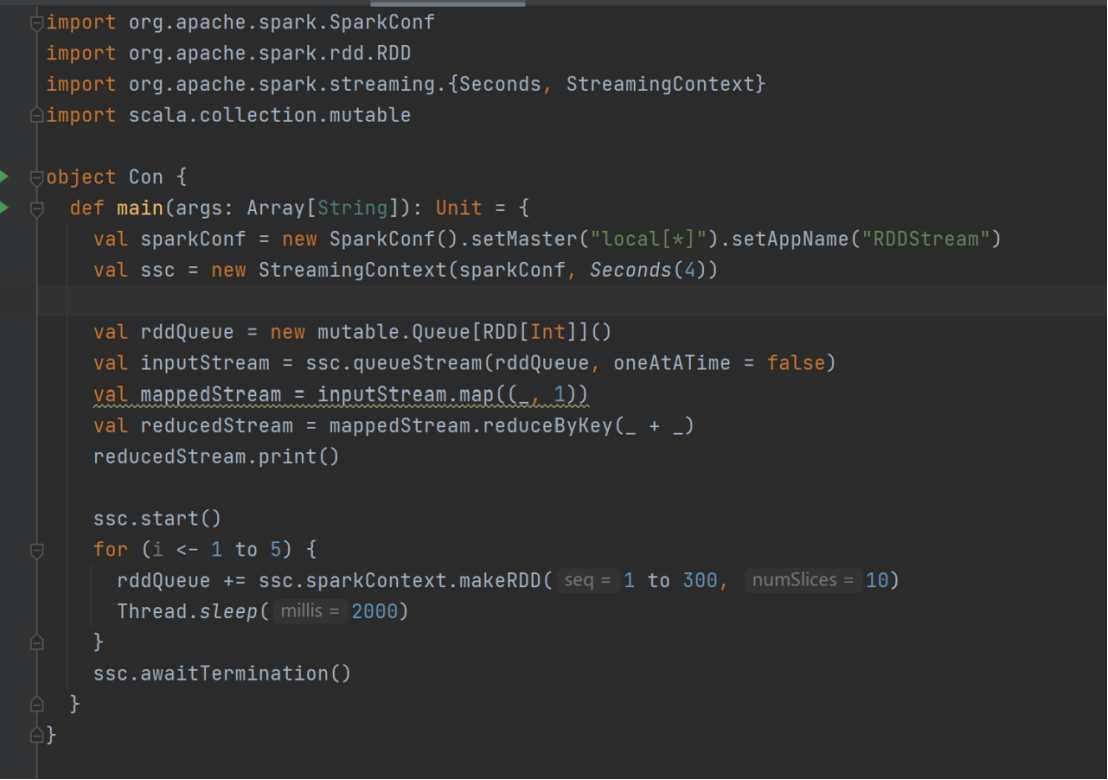
结果展示:
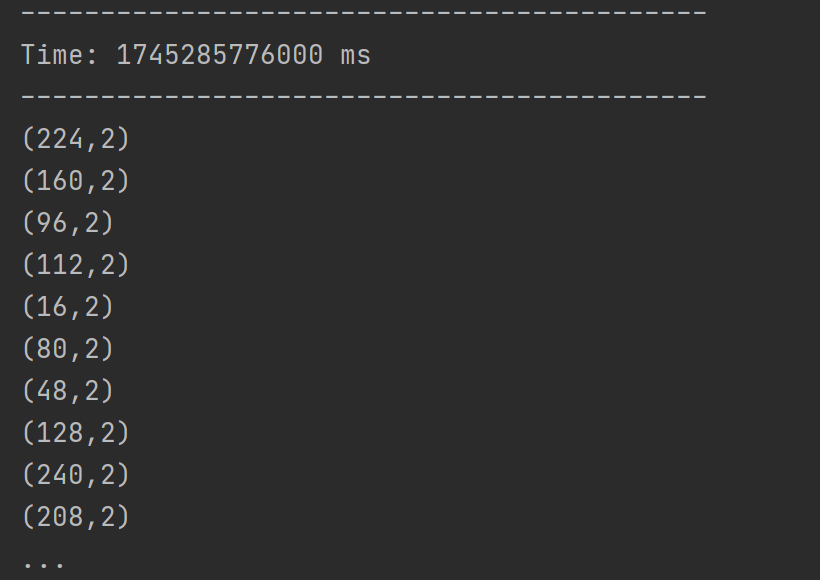
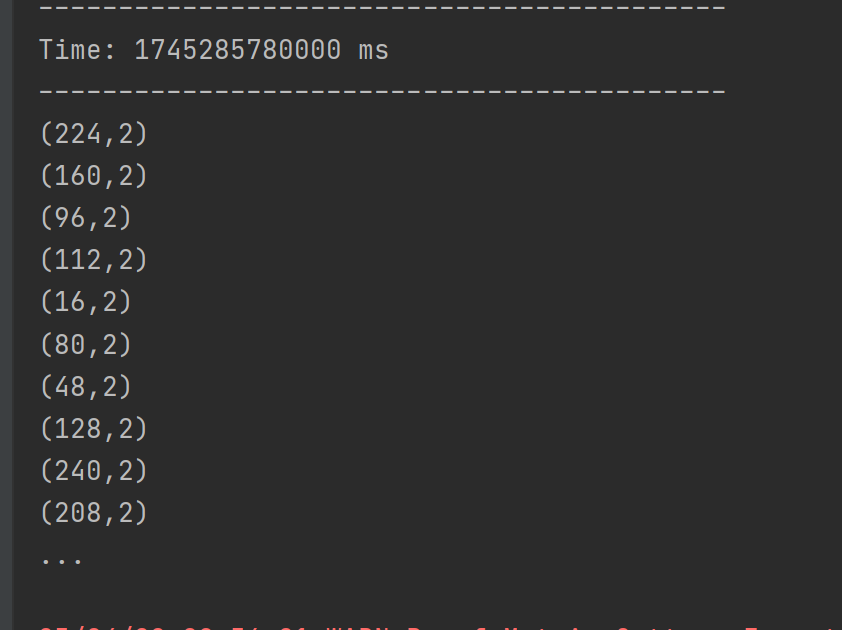
自定义数据源
自定义数据源需要继承 Receiver,并实现 onStart、onStop 方法来自定义数据源采集。
案例:自定义数据源,实现监控某个端口号,获取该端口号内容。
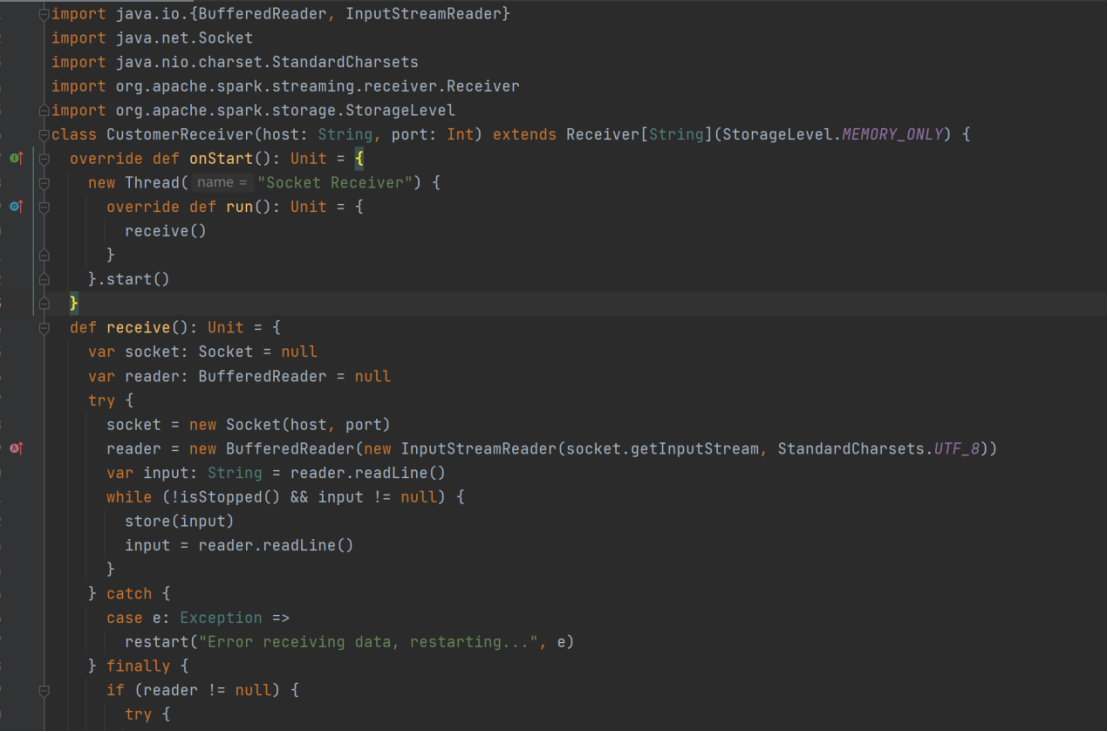
- 自定义数据源
class CustomerReceiver(host:String,port:Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {
override def onStart(): Unit = {
new Thread("Socket Receiver"){
override def run(): Unit ={
receive()
}
}.start()
}
def receive(): Unit ={
var socket:Socket = new Socket(host,port)
var input :String = null
var reader = new BufferedReader(new InputStreamReader(socket.getInputStream,StandardCharsets.UTF_8))
input = reader.readLine()
while(!isStopped() && input != null){
store(input)
input = reader.readLine()
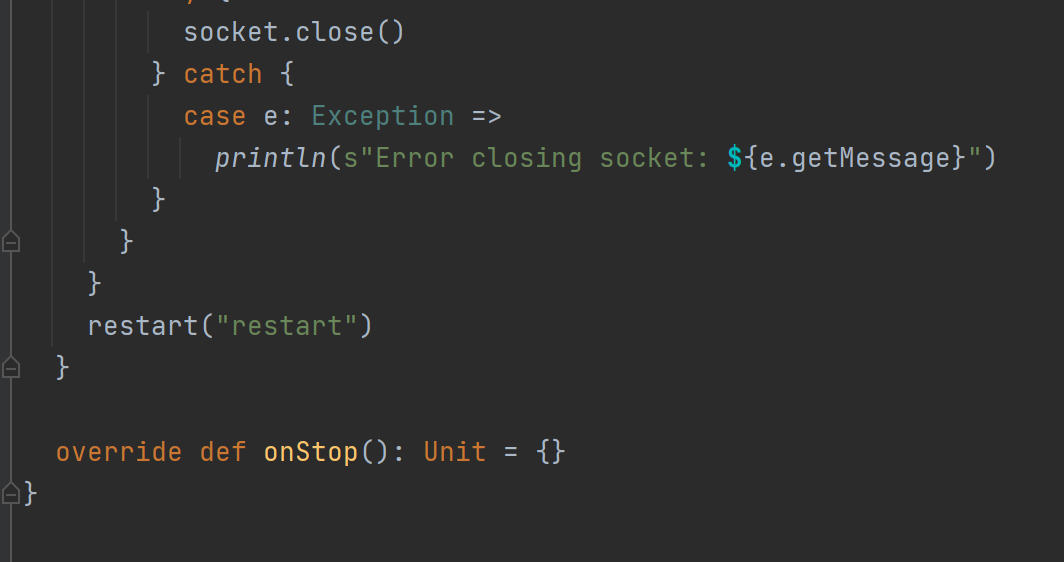
}
reader.close()
socket.close()
restart("restart")
}
override def onStop(): Unit = {}
}
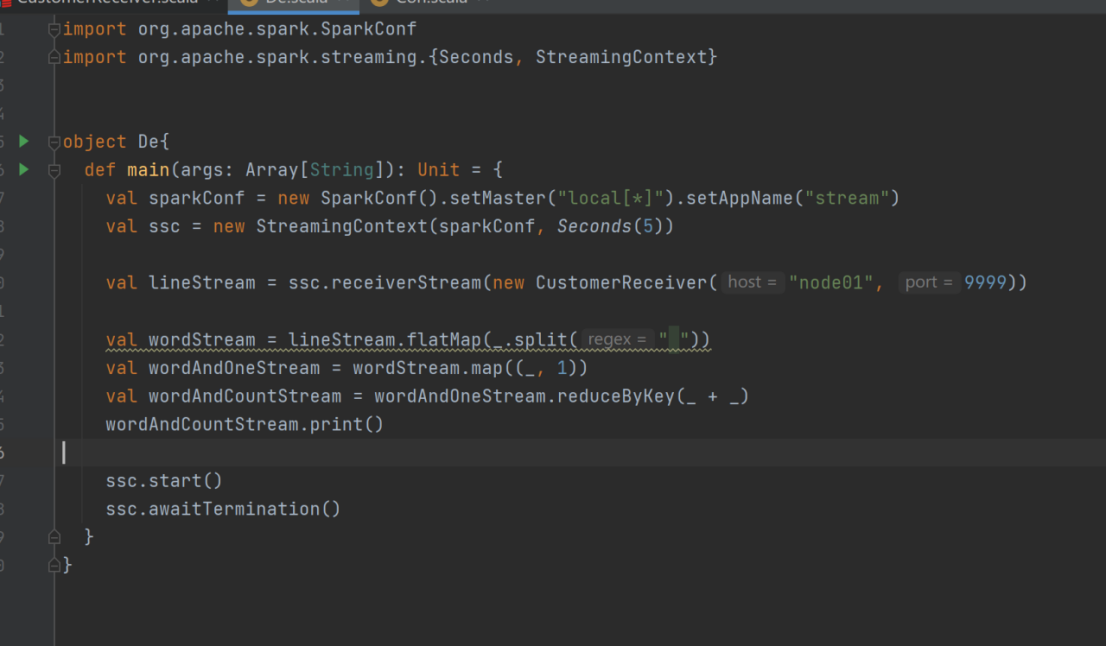
- 使用自定义的数据源采集数据
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("stream")
val ssc = new StreamingContext(sparkConf,Seconds(5))
val lineStream = ssc.receiverStream(new CustomerReceiver("node01",9999))
val wordStream = lineStream.flatMap(_.split(" "))
val wordAndOneStream = wordStream.map((_,1))
val wordAndCountStream = wordAndOneStream.reduceByKey(_+_)
wordAndCountStream.print()
ssc.start()
ssc.awaitTermination()

Spark-Streaming核心编程(四)
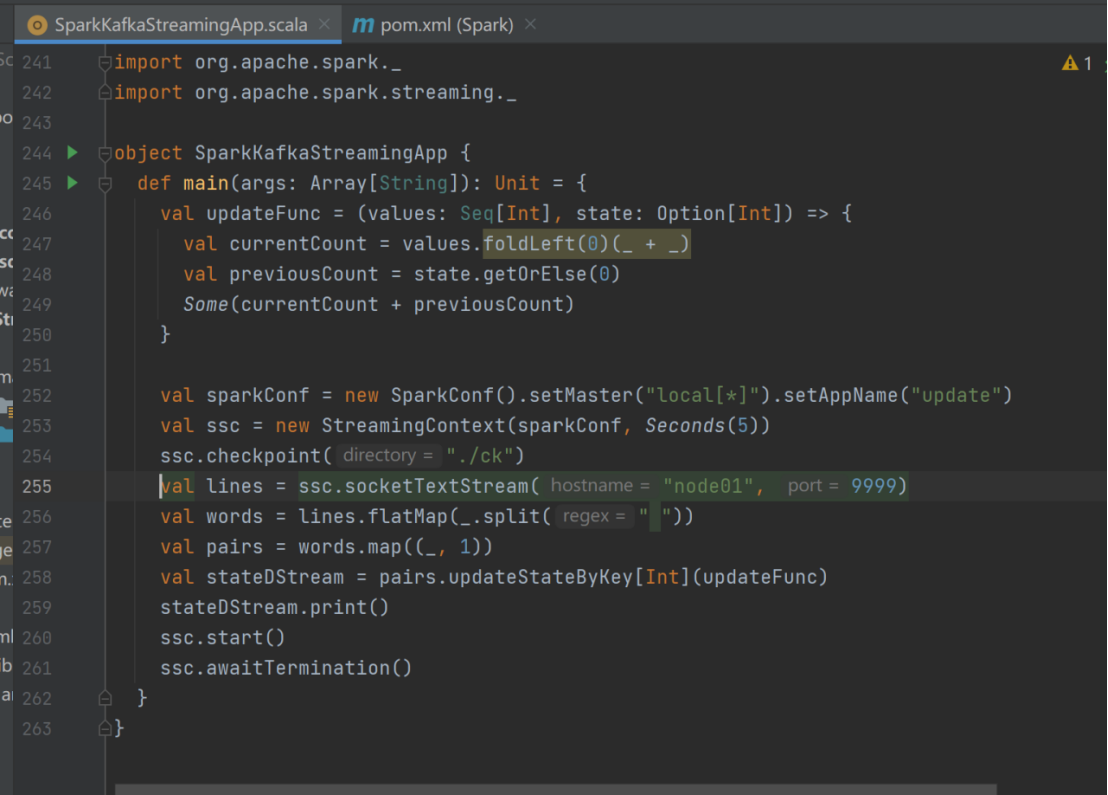
有状态转化操作
val updateFunc = (values:Seq[Int],state:Option[Int])=>{
val currentCount = values.foldLeft(0)(_+_)
val previousCount = state.getOrElse(0)
Some(currentCount+previousCount)
}
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("update")
val ssc = new StreamingContext(sparkConf,Seconds(5))
ssc.checkpoint("./ck")
val lines = ssc.socketTextStream("node01",9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map((_,1))
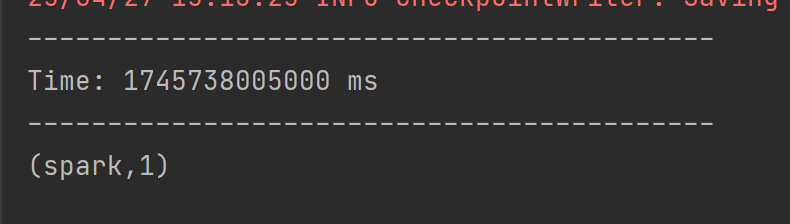
val stateDStream = pairs.updateStateByKey[Int](updateFunc)
stateDStream.print()
ssc.start()
ssc.awaitTermination()
WindowOperations
Window Operations 可以设置窗口的大小和滑动窗口的间隔来动态的获取当前 Steaming 的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
- 窗口时长:计算内容的时间范围;
- 滑动步长:隔多久触发一次计算。
注意:这两者都必须为采集周期大小的整数倍。
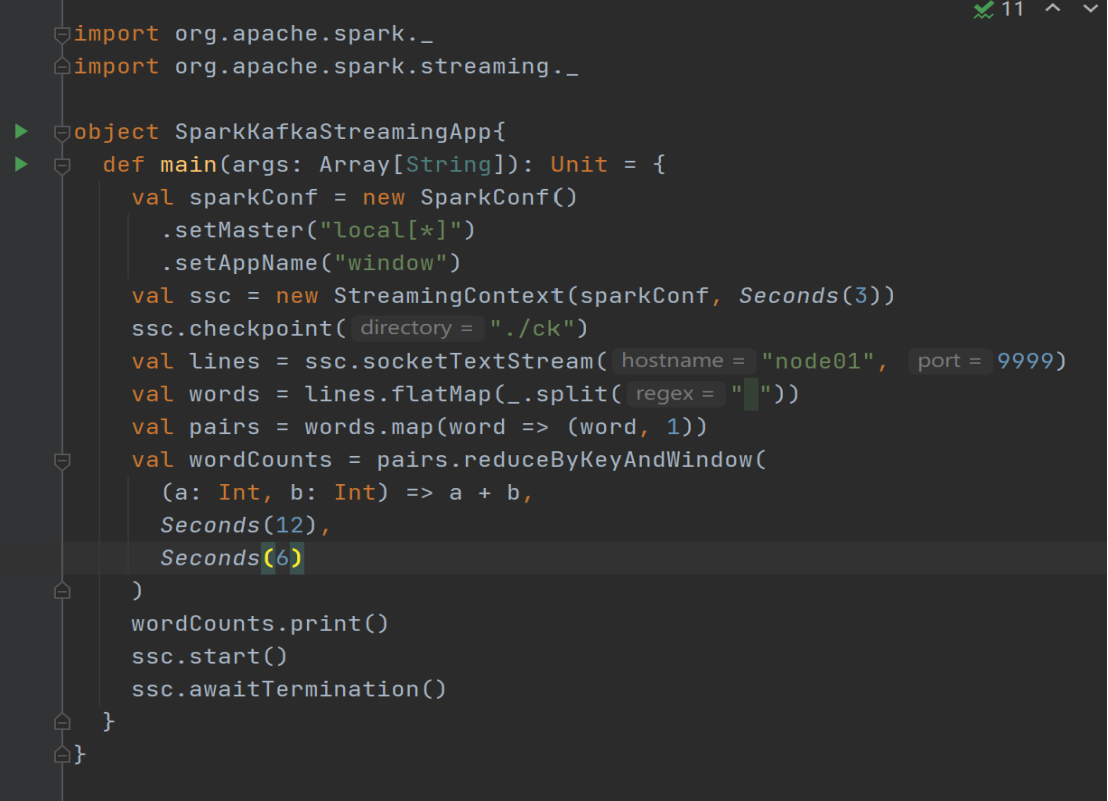
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("window")
val ssc = new StreamingContext(sparkConf,Seconds(3))
ssc.checkpoint("./ck")
val lines = ssc.socketTextStream("node01",9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map((_,1))
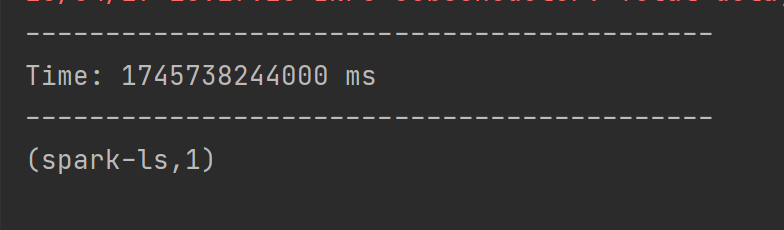
val wordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int)=>(a+b),Seconds(12),Seconds(6))
wordCounts.print()
ssc.start()
ssc.awaitTermination()