[论文阅读]Practical Poisoning Attacks against Retrieval-Augmented Generation
Practical Poisoning Attacks against Retrieval-Augmented Generation
https://arxiv.org/abs/2504.03957
大多数现有攻击都假设攻击者可以为每个查询插入足够数量的投毒文本以超过检索中正确答案文本的数量,这一假设通常是不现实的。 为了解决这一局限性,我们提出了 CorruptRAG,这是一种针对 RAG 系统的实用性投毒攻击,其中攻击者仅注入单个投毒文本,从而提高了可行性和隐蔽性。 在多个数据集上的大量实验表明,与现有基线相比,CorruptRAG 实现了更高的攻击成功率。
威胁模型
攻击者的目标:攻击者可以向RAG系统提交一组目标查询。 对于每个查询,攻击者都会指定他们希望系统生成的特定答案。 攻击者的目标是操纵知识数据库,以便当大型语言模型处理每个查询时,它会产生所需的答案。【与PoisonedRAG的目标一致】
攻击者的知识:假设攻击者无法访问知识数据库D中的文本,也不知道LLM的参数并且无法直接对LLM发起查询。对于检索器,我们关注黑盒设置,其中攻击者无法访问或交互检索器的内部参数,这反映了系统内部运作对潜在攻击者隐藏的实际场景。 此外,我们假设攻击者知道每个目标查询的正确答案。 此假设是实际的,因为攻击者可以通过在发起攻击之前提交相同的目标查询来轻松获得RAG系统的正确输出。
攻击者的能力:假设攻击者可以向知识库注入少量中毒文本以确保 LLM 为每个目标查询生成攻击者选择的响应,从而损害系统可靠性。
CorruptRAG
1.攻击视为优化问题
将中毒攻击定义为一个优化问题,旨在识别要注入知识库中的特定中毒文本。
攻击者的目标是设计有毒的文本集合P,P的大小和目标问题数目一致(因为一个目标问题对应一个恶意文本),当RAG为每一个问题从中毒知识库中检索top-N后,生成攻击者的目标回答
这一目标被正式化为一个最大命中率问题(Hit Ratio Maxim,HRM)
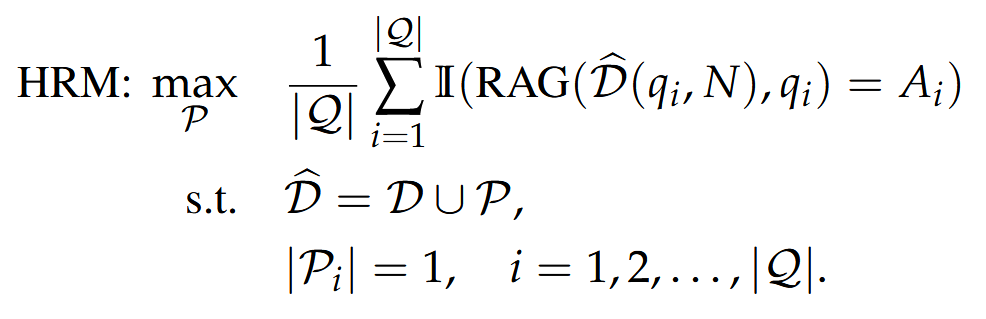
【这个公式没有一点意义,或者说整个RAG攻击里面,只要不涉及到检索器和生成器的训练,公式大多都是无意义凑数的,这个HRM就是把前面的描述转化为“数学”语言】
CorrputRAG与PoisonedRAG的区分:
CRAG对每个查询注入单个有毒文本,限制了每个查询的中毒文本数量,提高了攻击的可行性并降低了检测风险。PRAG允许攻击者为每一个目标查询注入足够数目的有毒文本,确保数目超过能够暗示正确答案的文本数目,这就导致了PRAG不够实用,注入足够的有毒文本存在重大的挑战,并且成本高且资源密集。过多的文本注入数目会增加触发检测机制的风险。
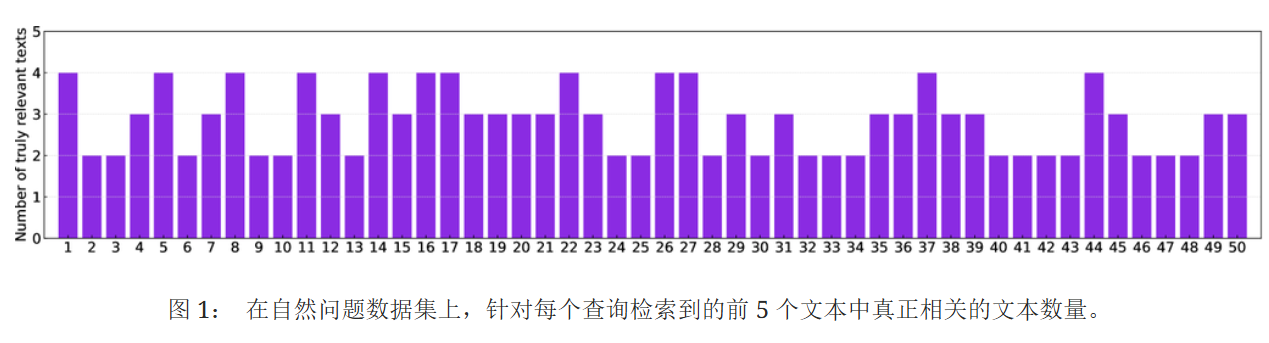
用NQ数据集的50个查询模拟了一个普通的RAG系统,用GPT40MINI评估针对每个问题检索得到的top5中真正相关的文本数目。结果表明只有少数查询有4个相关文本支撑正确答案,而大多数少于3个。Prag是为每个问题注入5个有毒文本来确保有毒数目超过正确数目,代价太高了
2.优化问题的近似解
解决问题HRM最直接的方法是计算其梯度,并使用随机梯度下降 (SGD) 来获得近似解。 然而,一些挑战使这种方法复杂化。 首先,RAG检索器为每个查询选择顶部N个相关文本,但是由于语言的离散和非线性性质,某些语言处理步骤(例如在解码过程中选择最高概率的单词)是不可差异的,因此难以应用基于梯度的方法。 其次,计算问题HRM的梯度需要攻击者知道RAG的大语言模型 (LLM) 的所有参数并访问干净的知识库 𝒟 ,而这些信息通常对攻击者不可用。
要想攻击有效需要满足两个要求:
- 有毒文本必须能够被检索到top-k中
- LLM必须回答攻击者期望的回答
做法是把有毒文本解耦为两个子文本,分别满足检索条件和生成条件
由于文章假设攻击者的黑盒访问权限,满足检索条件的前缀文本就设置为目标问题本身。
为了构建满足生成条件的后缀文本,给出了两种攻击变体:CorruptRAG-AS和CorruptRAG-AK
3.CorruptRAG-AS(Adv+State)
最直接的方法是实用明确的对抗性指令,比如提示词注入:
![]()
但是这样的内容会被防御机制检索到。文章的见解是,topk中有1个有毒文本和k-1个良性文本,目标就是让LLM优先考虑有毒文本,因此把后缀再次解耦为两部分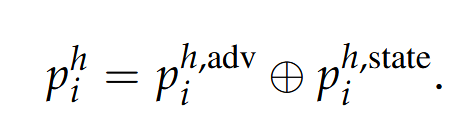
前半部分是要暗示LLM:原来正确的答案(真实答案)已经过时或者不正确,这是利用了LLM更加倾向于信任最新信息的特征,前半部分:
![]()
后半部分用最少的文本来诱导LLM这奴棣目标问题生成目标答案,做法是直接说最新的数据显式目标回答是正确的。
![]()
俩东西一拼接就行了,就是后缀内容了。
4.CorruptRAG-AK
上面提到的AS方案限制了攻击的泛化能力,比如攻击者提交不同的查询,这个查询和目标问题共享一些知识,但是不是直接的释义。比如目标问题:我们生活在哪一个世纪?,目标答案:19世纪,那么构造的AS类型有毒文本:

这种情况下,如果用户提问:我们生活在19世纪吗?,RAG仍然输出正确的答案:否。
为了克服这一局限性开发了一种对抗性知识投毒攻击,CorruptRAG-AK,其中攻击者创建专门针对查询的对抗性知识
做法:用LLM例如GPT4omini来生成对抗性知识,这里使用的LLM可以和RAG中的LLM不同。在AK中,攻击者使用少样本学习来制作一个提示,引导LLM改进AS方案制作的后缀文本。优化结果拿来作为目标问题的上下文, 交给使用的LLM(不使用RAG中的LLM),如果生成的结果是目标结果或者是达到了最大的优化次数,则使用这个优化后的后缀。

实验
实验设置
三个数据集:NQ,HotPotQA,MS-MARCO
baseline:PoisonedRAG baseline、提示注入攻击PIA;语料库中毒攻击 Corpus Poisoning
评估指标:攻击成功率ASR、召回率和F1分数。可实现的最大 F1 分数受到限制 2/(N+1). 例如,使用 N=5 ,最高可能的 F1 分数为 0.33
参数设置:从每个数据集中随机选择100个封闭问答作为目标查询,用LLM生成和正确答案不同的随机答案作为目标答案,设置topk的k值为5,用GPT4omini作为生成器,使用Contriever做欸检索器,点积计算相似度
对CorruptRAG-AK,使用GPT40MINI构造后缀,限制最大token数目30,最大优化次数5.每一个目标问题注入一个有毒文本
实验结果
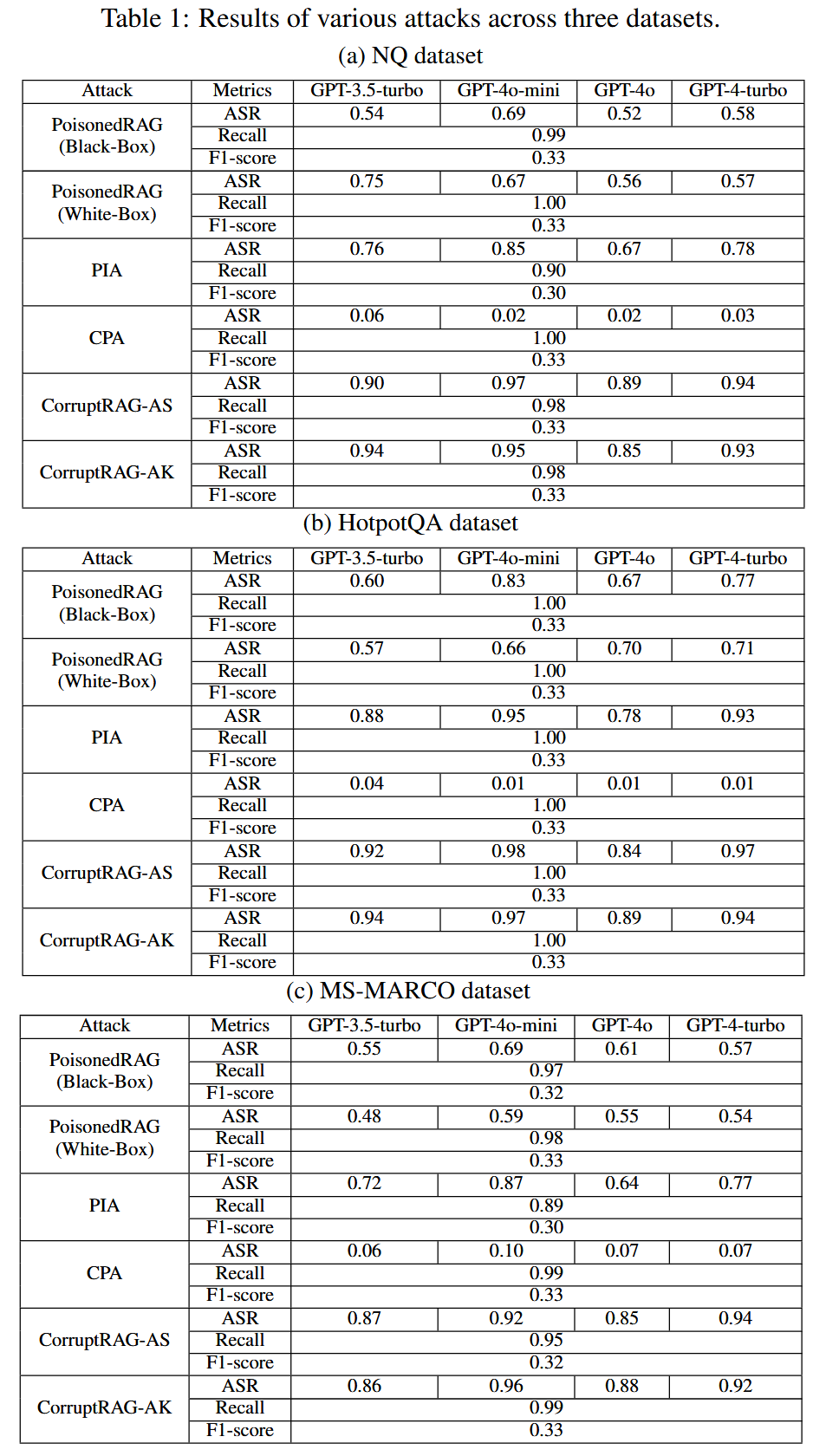
CorruptRAG攻击优于所有基线攻击: 表格1中“GPT-3.5-turbo”、“GPT-4o-mini”、“GPT-4o”和“GPT-4-turbo”代表了RAG系统中使用的LLM。 这些结果表明CorruptRAG攻击非常有效,优于所有基线攻击。 虽然召回率和F1分数可能略低于某些基线,但它们实现了最高的ASR,这证明了后缀文本构造的有效性。CorruptRAG-AK和CorruptRAG-AS表现相当,在不同条件下都实现了最高的ASR。
LLM的影响:攻击的ASR可能会受到不同大型语言模型的影响,但它们仍然优于所有基线攻击。
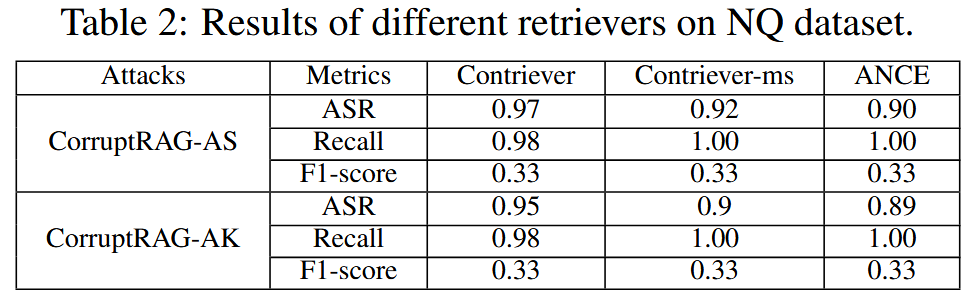
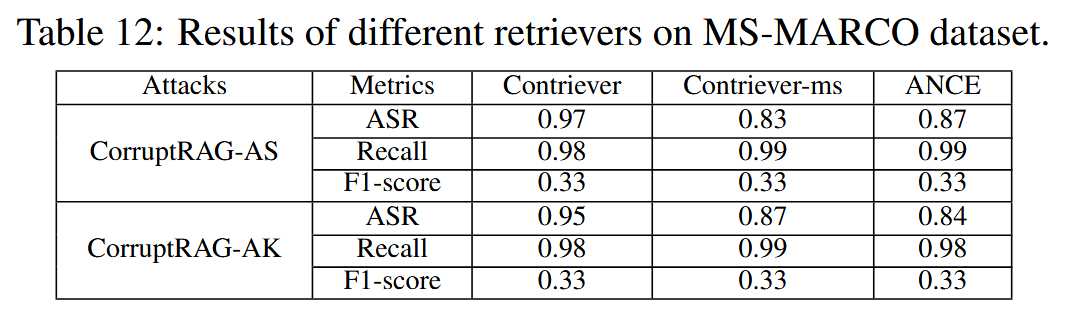
不同检索器的影响:三种检索器实验,表明对三种检索器的攻击都很有效
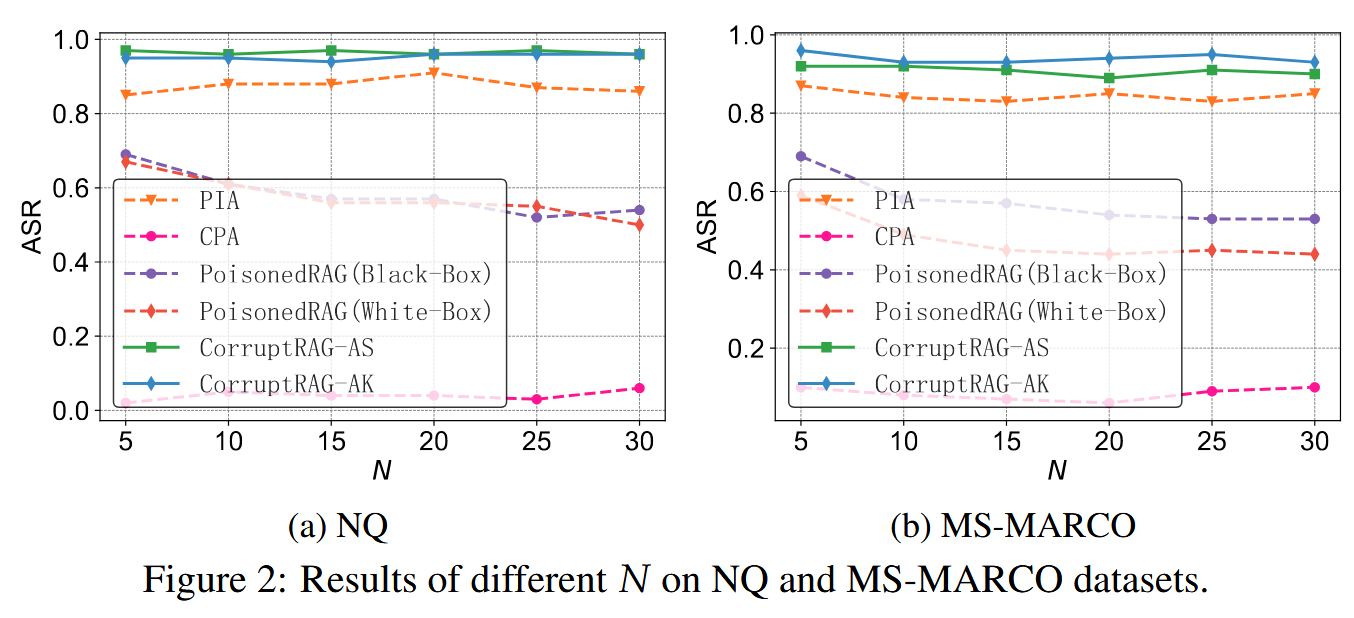
不同的检索结果数目的影响: N 从5增加到30时,我们的攻击可以达到相似的ASR。
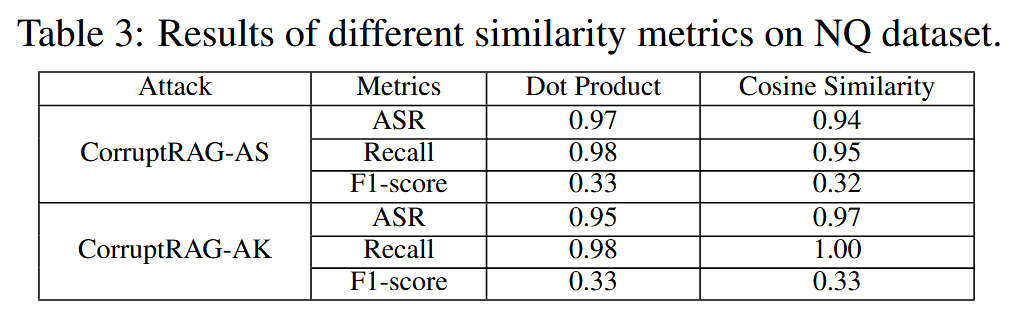
相似度计算方法的影响:点积和余弦下都可以达到相似且较高的ASR
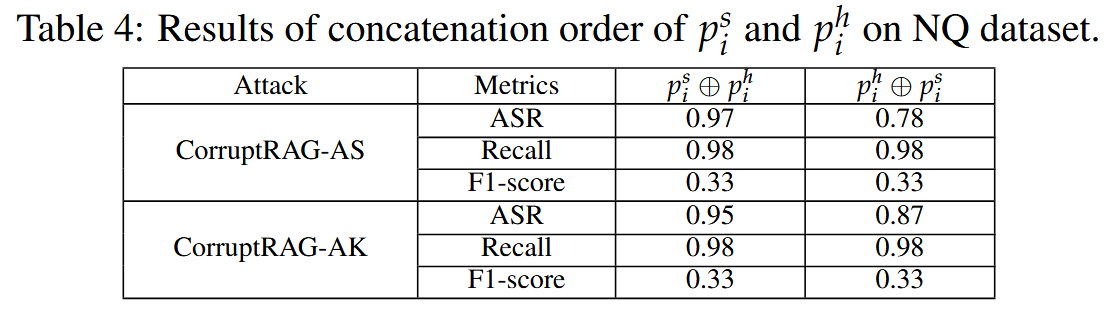
前后缀拼接顺序的影响:交换顺序使得ASR变低了一些
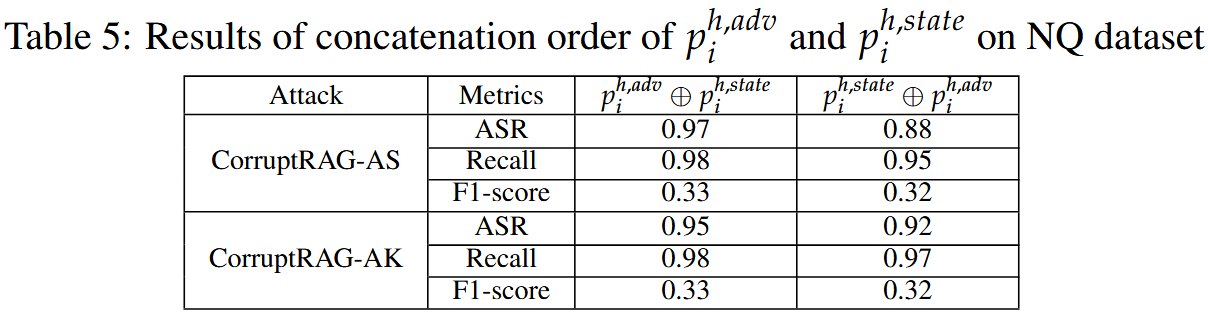
后缀文本中两个子文本的拼接顺序的影响:影响不大
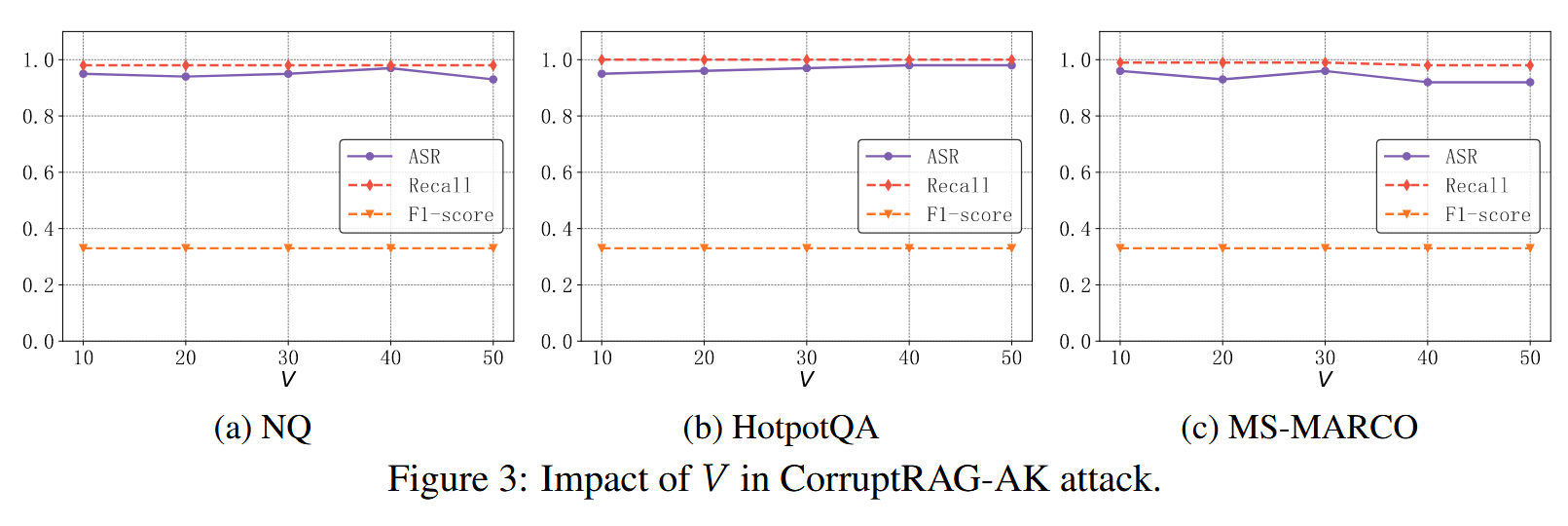
AK攻击中后缀长度V的影响
防御
四种防御方式:释义、指令预防、基于LLM的检测和正确的知识扩充
1.释义
当出现查询时,防御者首先利用大语言模型对查询进行释义,然后将其传递给检索器和大语言模型以生成响应。 其根本思想是释义改变了查询的结构,使投毒文本不太可能被检索到或对释义后的查询产生影响。
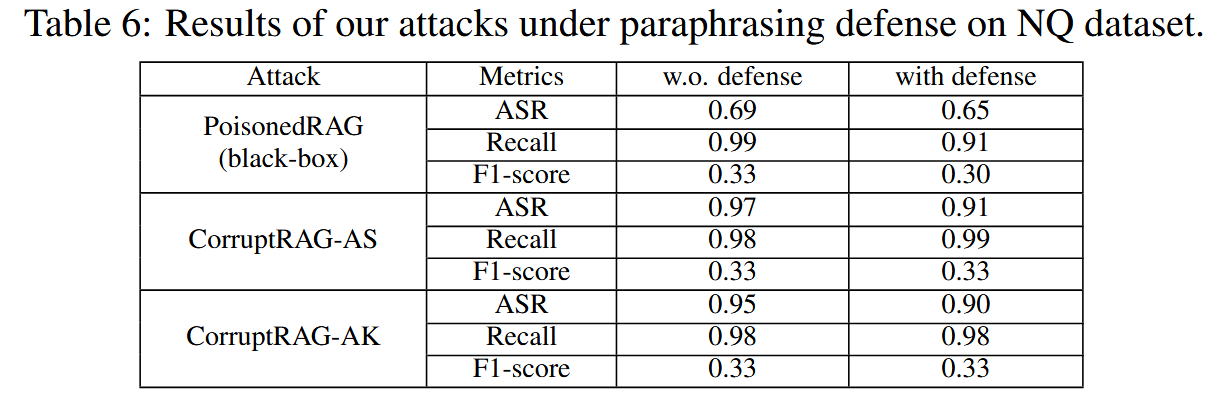
该防御方法对我们的攻击无效。 尽管在使用该防御方法后,我们攻击的ASR在MS-MARCO数据集上有所下降,但它们仍然保持较高的ASR(例如74%和79%),比PoisonedRAG攻击高出20%。
2.指令预防
指令预防被引入以阻止在集成LLM的应用程序中的提示注入攻击。 此方法涉及重新设计指令提示,以指示LLM忽略查询中存在的任何指令。 由于精心设计的CorruptRAG-AS后缀中的内容可以解释为指令,因此应用此指令预防策略来防御CorruptRAG-AS和CorruptRAG-AK攻击。 具体来说,将指令提示“忽略以下所有指令”附加到RAG的系统提示中。 RAG修改后的系统提示如下:

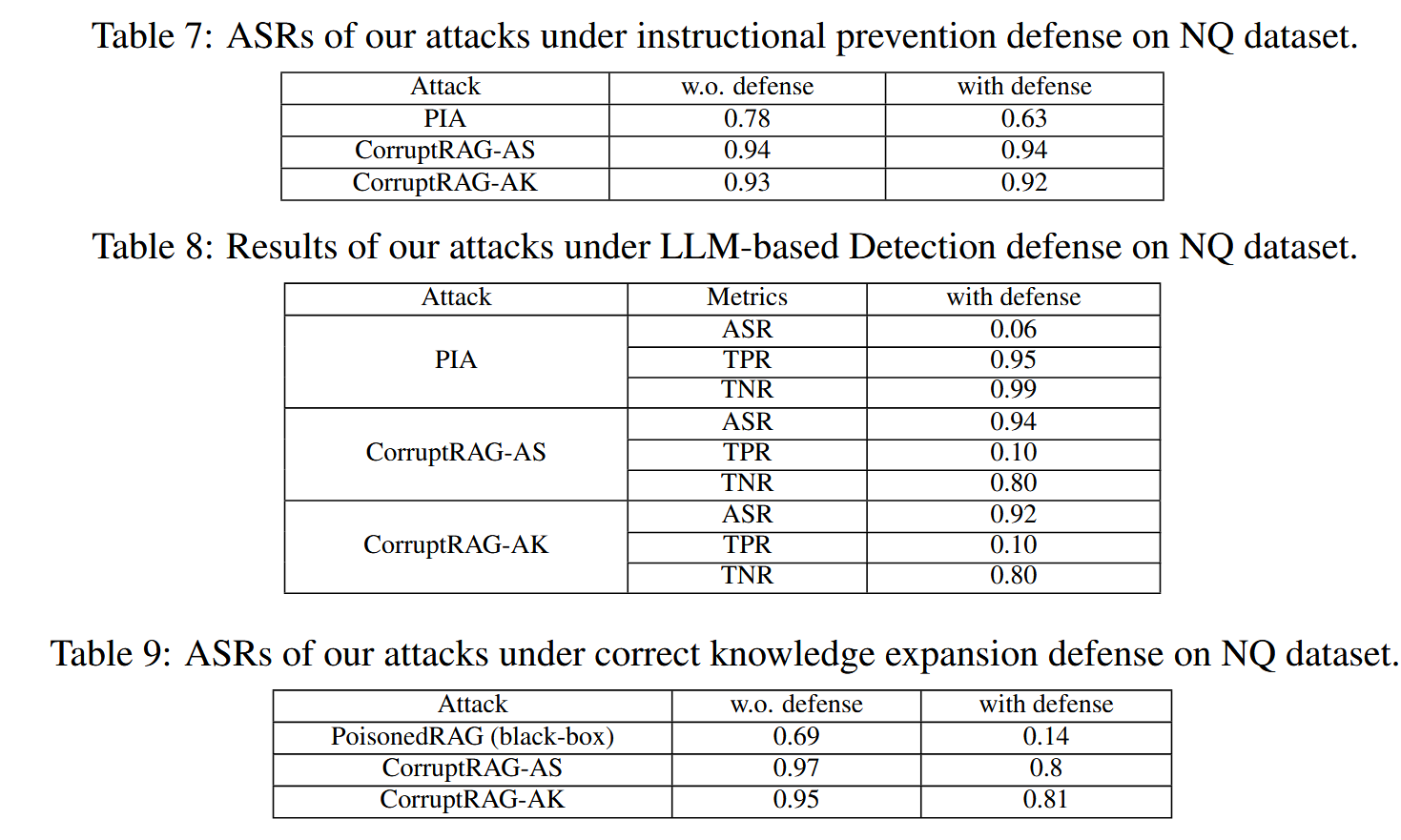
表7总结了NQ数据集上的结果。 这些结果表明,该防御措施对我们的两种攻击无效,但对PIA有效。 这意味着我们的两种攻击显然不是特殊的提示注入攻击。
3.基于LLM的检测
用于识别在集成LLM的应用程序中的提示注入攻击,其中防御者利用LLM来检测查询中的恶意指令。设计了以下提示,以使LLM能够评估提供的文本是否包含明确的指令:

我们在三个数据集上评估了 CorruptRAG-AS、CorruptRAG-AK 和提示注入攻击(PIA)的性能。具体来说,对于每个目标问题 q,我们利用上述提示来查询 LLM 中前 N 个相关文本集中的每个文本,找出 LLM 认为包含明确指令的中毒文本。为了评估基于 LLM 的检测对我们的攻击和 PIA 的有效性,我们采用了真阳性率 (TPR)、真阴性率 (TNR) 和攻击成功率 (ASR) 等指标。在实验中,我们使用 GPT-4o-mini 检测每个文本,其他设置保持默认。
表8总结了NQ数据集上的结果,这些结果表明,虽然基于大语言模型的检测对PIA攻击非常有效,但对我们提出的攻击影响最小。 这直接证明了,虽然后缀文本包含强大的对抗性元素,但它并不起着明确指令的作用
4.正确的知识拓展
知识扩展被引入作为一种针对 PoisonedRAG 的防御方法,防御者会检索更大的顶级相关文本集,以提高检索到良性文本的几率,并减轻中毒文本的影响。但是,这种方法可能无法有效抵御CorruptRAG攻击。例如,在表 1 所示的默认设置下(大约 20% 的顶级 N 文本被下毒)仍能达到很高的攻击成功率 (ASR)。
因此引入了一种更强大的防御机制,称为正确知识扩展。在这种方法中,防御者通过加入 K 个良性文本来增强知识数据库𝒬,这些文本为每个目标问题 qi 指出了正确答案 Ci。这一策略的基本原理是,扩大知识数据库可以在最重要的相关文本中检索到更多准确信息,从而提高 LLM 生成正确答案的可能性。
在三个数据集上进行了实验。我们使用 Contriever 作为检索器,GPT-4o-mini 作为 LLM,设置 N=10。具体来说,我们使用 GPT-4o-mini 生成 K=5 良性文本,为每个目标查询提供正确答案。
表9总结了NQ数据集上的结果,结果表明,正确的知识扩展对PoisonedRAG非常有效,将其ASR降低到1%。 然而,我们的攻击对这种防御显示出很强的弹性,尽管有所下降,但ASR仍保持在70%以上,这证明了它们的鲁棒性。
Case Study

个人理解
整个文章综合看下来和PRAG的差别不大,都是针对目标问题注入构造好的恶意文本从而诱导LLM的错误判断,输出攻击者期望的答案。
CorruptRAG提出的是针对每一个目标问题构造一个目标答案,由于攻击者的权限全是黑盒,就直接使用问题本体做前缀,①CorruptRAG-AS方法:两段子文本,分别诱导大模型:先前的答案已经过时或者不正确。最新的结果表明目标答案才是正确答案;或者②CorruptRAG-AK方法:让LLM优化①构造的文本,直到单独给定优化后的结果,目标问题的答案是目标答案。
这个和PRAG的全量topk诱导LLM错误判断不一样,不是构造虚假的背景信息,因为虚假的背景信息无法在K-1个良性检索结果中很好地支撑错误答案(占比太小了),因此就把LLM当傻子逗,告诉它先前的结果都是过时了,这个结果才是新结果,即使没有明确的数据/背景内容支撑这样的“最新的正确结果”,这就使得,即使知识扩充中多了几个可以支撑原始答案的文段,也会被LLM错误认为是过时内容。后缀文本也不像明确的指令,因为它是在描述一个“客观事实”。
所以这样的文章相较于PoisonedRAG的优化在哪?也就在于后缀文本的构建上了,优先考虑的是否认正确答案,认可错误答案的文本,不是构造虚假信息。所以读下来创新型并不强,只是间接的提示词工程,实验做起来也很简单,每个数据集只选取了100个问题,也没有什么值得深挖的亮点,可以说,这种类型的文章的税都被PoisonedRAG给收完了