MySQL的锁(InnoDB)【学习笔记】
MySQL的锁(InnoDB)
知识来源:
- 《MySQL是怎样运行的》--- 小孩子4919
- MySQL 是怎么加锁的? | 小林coding
MySQL实现事务的不同隔离级别,是通过MVCC和锁。锁分为不同的类型,和对应的记录、表还有变量关联。当有事务获取到一把锁后,其他的事务根据锁的类型,选择等待或者直接再次获取到锁。
加锁的本质
-
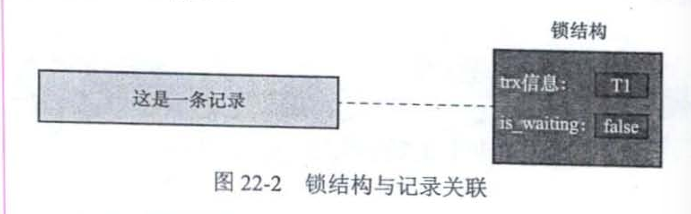
一开始内存中本没有锁
-
当有事务T1想对记录改动时,就会查看内存中有无和记录关联的锁结构
-
没有的话就创造一个锁结构与之关联(成功加锁),记录事务信息、并且将is_waiting设置为false,意为不阻塞。
-
-
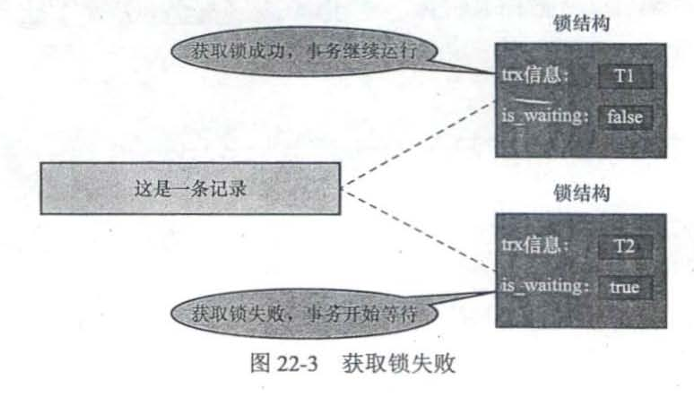
后面事务T2,想修改这条记录,发现已经有锁结构与之相关联,就会再创造一个锁结构,记录事务信息,并且将is_waiting设置为true,意为被阻塞(加锁失败)
-
-
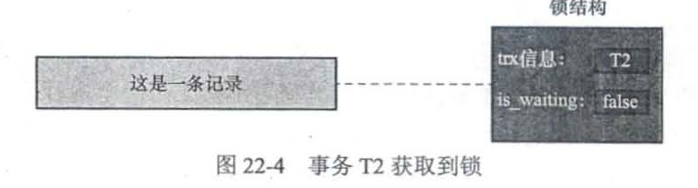
等到事务T1,修改完记录,就会查看内存中是否有其他锁结构与该记录关联,如果有,就唤醒那些阻塞的事务。被唤醒的事务T2会将锁结构的is_waiting设为false(重新加锁)
-
-
TIPS:当然不是每个修改记录的语句都会创造一个锁结构,当满足一些条件之后,那些修改记录的语句就会塞到一个锁结构里面,后面【锁的结构】的一堆比特位就是用来存储的。
锁的分类
-
表级锁
-
元数据锁
-
表级读写锁(S/X),实现对表的锁定
-
S表示读锁,也叫共享锁,一个事务占有了一张表的S锁,其他事务可以占有这张表的S锁,但是获取这张表的X锁时会被阻塞
-
X表示写锁,也叫独占锁、排他锁,一个事务占有了一张表的X锁,其他事务获取这张表的S/X锁时会被阻塞
-
-
AUTO-INC锁,用于给AUTO_INCREMENT修饰的字段自增时加锁,避免字段重复。
-
表级读写意向锁(IS/IX),在获取一张表中记录的S/X锁前,会先对这张表加上对应的IS/IX意向锁。
-
IS表示读意向锁,IX表示写意向锁。IS-IS、IS-IX、IX-IX都互相兼容。
-
因为在对表加上S/X锁前,表中的记录的S/X锁不能被占有(SS互相兼容属于特例)。如果没有意向锁,则需要遍历整张表来查看是否能加上表锁。
-
比如:表中的记录1被加上了S锁、记录1000被加上了X锁,这时我想对这张表加上S锁,会先查看记录1加上了S锁,那么继续遍历记录2、3、4...,直到遍历到记录1000才发现被加上了X锁,这时就会被阻塞。
-
但是我如果在加上加上行级锁,提前加上对应的意向锁。还是上面的例子,我加上表的S锁时,发现这张表有IS和IX锁,就知道表中有记录被加上了S、X锁,那么就立刻被阻塞。
-
-
-
行级锁
-
记录读写锁(I/X),Record Lock,锁定莫一条记录。
-
间隙锁,Gap Lock,加在某一条记录上,锁定这条记录前的一个区间。比如:有记录1(id为20)、记录2(id为30),对记录2加上间隙锁,此时id为(10,20)就被锁定了,就不能插入id为11~19的记录了(id为10、20本就存在,插入就会报错)。
-
Next-Key读写锁,记录读写锁和间隙锁的结合版,还是上面的例子,加在记录2上,就会锁定id为(10,20],注意此时插入id为20的记录就不是报错,而是先阻塞了。
-
插入意向锁,如果有事务对一个区间加上了间隙锁(当然Next-Key锁包含间隙锁),那么另一个事务的对该区间的插入操作就会被阻塞,这时会对加上间隙锁的记录再加上一个插入意向锁。就是一个标记,不能阻止其他事务对这条记录加上任何类型的锁。
-
隐式锁,当事务1在插入操作时(当然插入的区间不能加间隙锁),此时首先不会对任何记录加上任何锁。
-
如果此时事务2使用select ... lock in share mode/select ... for update查看那条聚簇索引记录,由于事务1插入了那条记录,那条记录的trx_id则为事务1,事务2就会查看这个trx_id对应的事务1是否依然活跃,如果是,则会为事务1和自己生成都生成一个锁结构,并且自己阻塞起来。否则,自己加上对应的S/X锁
-
如果事务2查看的是二级索引记录,那么就首先查看记录所在页的PAGE_MAX_TRX_ID属性,观察这个值是否小于系统最小的活跃事务id。如果是,则自己加上对应的S/X锁,否则,回表找到对应的聚簇索引记录再做判断。
-
-
锁的结构
-
在某些情况下,对多条记录的锁结构是可以放到同一个锁结构中的。需要同时满足下面的四个条件:
-
同一个事务加锁
-
被加锁的记录在同一个页面中
-
加锁的类型一致
-
等待状态一致()
-
-
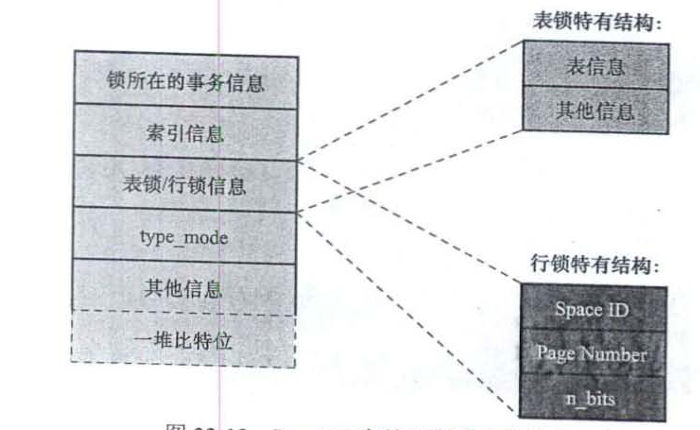
锁所在的事务信息,一个指向事务结构的指针
-
索引信息,指向索引信息的指针
-
表锁/行锁信息
-
表锁:表信息+其他信息
-
行锁:
-
Space ID,记录所在表空间id
-
Page Number,记录所在页号
-
n_bits,表示末尾一堆比特位的数量,大于等于页中记录数量
-
n_bits=(1+((n_recs + LOCK_PAGE_BITMAP_MARGIN)/8))*8
-
n_recs当前页面记录中heap_no最大值的大小(每在表中生成一条记录,就会将当前heap_no的值分配给新记录,heap_no就加1,初始值为2,0和1分别分配给了Infimum记录和Supermum记录)
-
LOCK_PAGE_BITMAP_MARGIN默认值64
-
-
-
一堆比特位:类似一张bitmap,用来记录这锁作用于哪条记录,比特位映射记录的heap_no
-
-
-
-
type_mode,表示锁的类型,32位,分成lock_mode、lock_type和rec_lock_type三部分
-
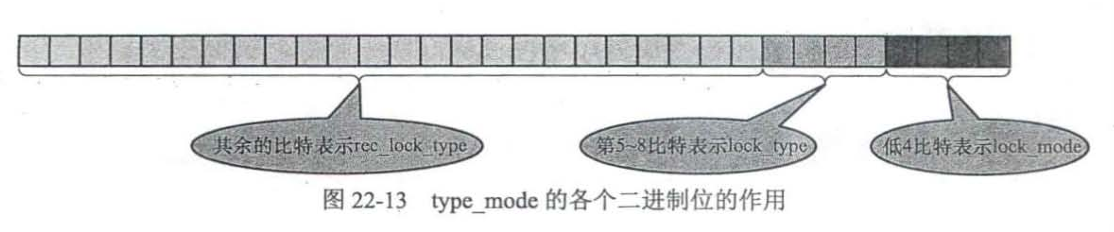
-
lock_mode,锁模式
-
LOCK_IS,共享意向锁
-
LOCK_IX,独占意向锁
-
LCOK_S,共享锁
-
LOCK_X,排他锁
-
LOCK_AUTO_INC,AUTO_INC锁
-
-
lock_type,锁类型
-
LCOK_TABLE,表级锁
-
LCOK_REC,行级锁
-
-
rec_lock_type,当lock_type为行级锁时,该部位有效,表示行锁的具体类型
-
LOCK_ORDINARY,Next-Key锁
-
LOCK_GAP,间隙锁
-
LOCK_REC_NOT_GAP,记录锁
-
LOCK_INSERT_INTENTION,插入意向锁
-
-
LOCK_WAIT,独占整个type_mode的第9位,1表示成功加上锁,0表示等待其他事务释放锁
-

语句执行底层
-
select语句
-
select ... lock in share mode,底层会加上S型锁(具体是记录锁还是Next-Key锁需要具体分析,下面的S/X锁都是如此)
-
select ... for update,底层加上X锁
-
-
delete语句
-
首先对需要删除的记录尝试加上X锁(失败则阻塞),然后执行delete mark操作
-
-
update语句
-
如果未修改主键字段
-
前后记录的字段的值占用空间没有丝毫变化,则首先获取记录的X锁,然后执行原地更新操作
-
否则,获取该记录的X锁,然后彻底删除这条记录,最后根据原纪录和修改字段执行insert语句
-
-
修改主键字段
-
首先对该记录执行delete操作,然后根据原纪录和修改字段执行insert语句
-
-
-
insert语句
-
首先判断新纪录要插入的位置有没有加锁(可能是记录锁、间隙锁、Next-Key锁),如果加了,就给加锁的记录再加上插入意向锁,然后阻塞
-
如果没有被阻塞,则会直接插入记录,对该记录加上隐式锁。
-
语句加锁分析
首先明确锁和MVCC是用来实现事务隔离级别,用来解决事务并发问题的。事务的并发问题有脏写、脏读、不可重复读、幻读。事务的隔离级别分为读未提交、读已提交、可重复读、串行化。MVCC看这篇MySQL的MVCC【学习笔记】-CSDN博客
区分两个读的而概念:
一致性读(Consistent Read),也叫快照读,读取时生成Read View
锁定读(Lock Read),也叫当前读,读取前会尝试获取锁
普通的select语句
-
读未提交,直接读最新记录
-
读已提交,在事务每次执行普通的select语句时都会生成一个Read View
-
可重复读,事务第一次执行普通的select语句时生成一个Read View,可以避免绝大部分的幻读,但是在特殊情况下依旧会有幻读发生。
-
串行化
-
系统变量autocommit为0时,禁止自动提交,普通的select语句会转化成select ... lock in share mode,加锁情况和可重复读一样。
-
系统变量autocommit为1时,开启自动提交,每次执行普通的select语句会生成一个MVCC
-
锁定读
包含以下四种语句:
select ... lock in share mode,主动给记录加行级共享锁
select ... for update,主动给记录加行级排他锁
update ...,首先会查对应的记录,加上行级排他锁,然后再进行更新操作
更新聚簇索引记录,且每个字段前后占用空间不变,则加上记录锁,原地更新
更新聚簇索引记录,并且更新非主键字段,
delete ...,首先会查对应的记录,加上行级排他锁,然后再进行删除操作
下面就以select ... lock in share mode作为案例,演示流程:
普通情况
-
读未提交和读已提交,属于同一种情况
-
首先确定索引扫描区间,找到第一条符合条件的记录,作为当前记录
-
为当前索引(二级索引或者聚簇索引)的记录加记录锁
-
如果是二级索引的话,会多一些步骤
-
判断是否符合索引下推的条件,如果符合,则提前通过索引的其他字段筛选掉一部分记录(二级索引)
-
例如:联合索引(name,age),查询条件为where name like 'zhang%' and age=10,此时根据最左匹配原则,联合索引只用到了name这个字段筛选记录,但是如果开启了索引下推(ICP),那么就会把二级索引记录,再根据age字段,进一步筛选,减少回表次数。(!!!只能用于select语句,update、delete的隐式查询无效!!!)
-
-
则进行回表操作,否则就选择下一条记录作为当前记录,从第一步开始。
-
当然还会判断当前记录是否为扫描区间的边界,如果是,则直接向server层返回查询完毕,此时该记录的锁不会被释放(不论什么事务隔离级别)。
-
回表操作,将记录(聚簇索引)加上记录锁
-
-
当前记录(聚簇索引)是否符合边界条件,符合的话,则释放掉当前记录的锁,否则执行下一步
-
将记录(聚簇索引)返回给server层,判断是否满足where的其他条件,满足的话则返回给客户端,不释放锁,否则释放掉锁。
-
获取下一条记录,作为当前记录(二级索引或者聚簇索引),从头开始
-
-
可重复读和串行化,属于同一种情况
-
和上述类似,只不过
-
记录上加Next-Key锁,而不是记录锁。
-
并且记录加上锁后就不会被释放了。
-
-
-
下面举几个例子:
-
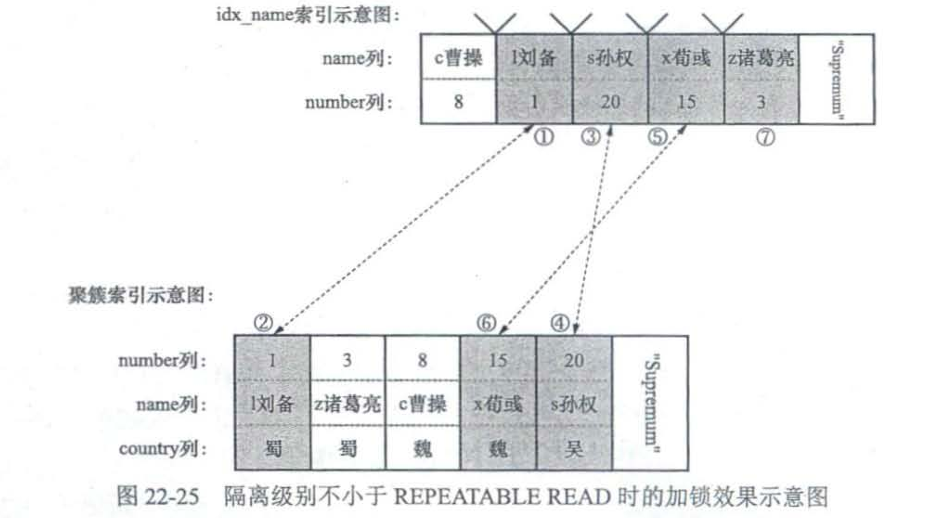
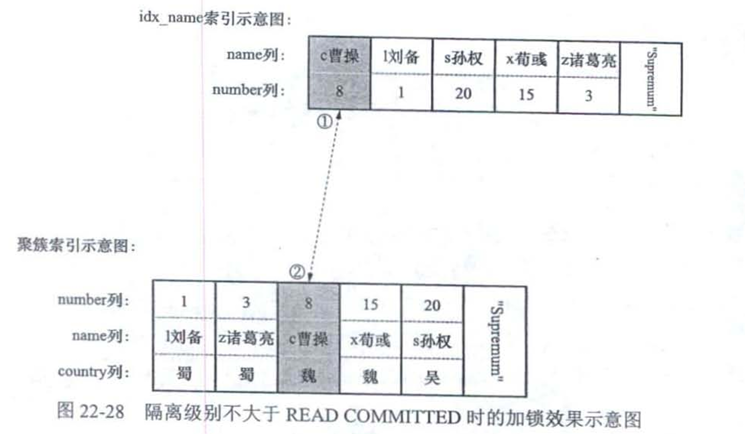
select * from hero where number>1 and number <=15 and country = '魏' lock in share mode;
-
读未提交和读已提交
-
-
可重复读和串行化
-
-
-
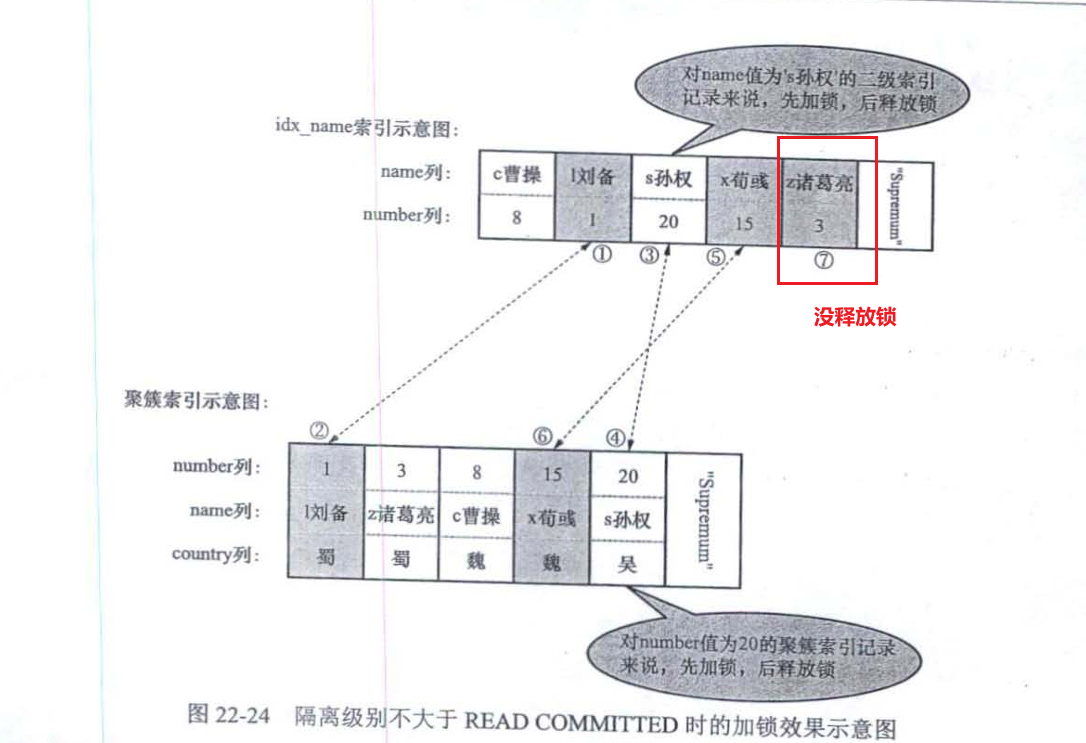
select * from hero force index(idx_name) where name > 'c曹操' and name <= 'x荀彧' and country != '吴' lock in share mode;
-
读未提交和读已提交
-
-
可重复读和串行化
-
-
-
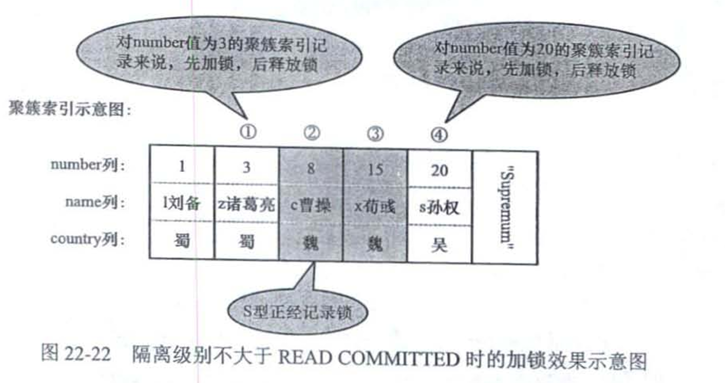
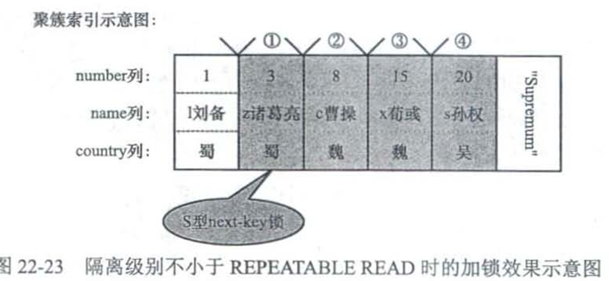
Update hero set name = 'cao曹操' where number > 1 and number <=15 and country = '魏';
-
读未提交和读已提交
-
加锁过程不是锁定读,而是半一致性读(后面会讲)
-
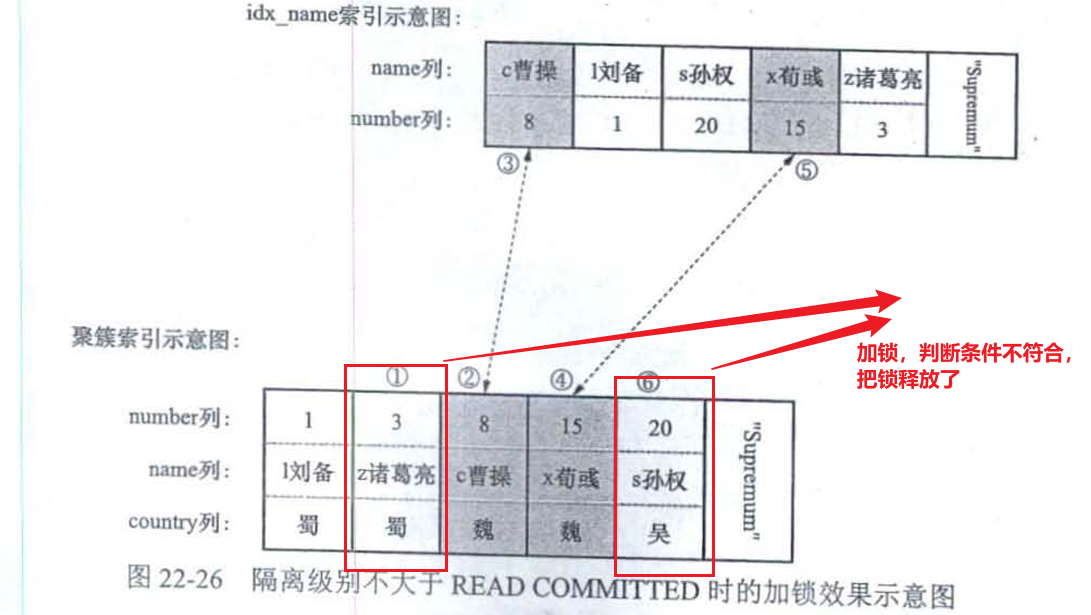
-
-
可重复读和串行化
-
采用锁定读的方式加锁
-
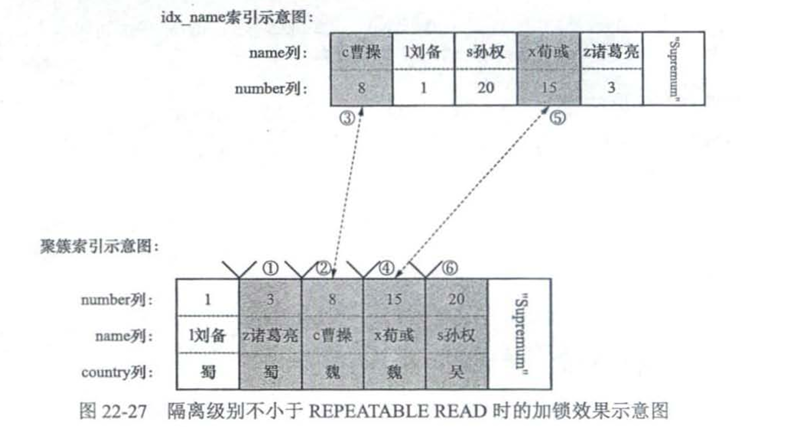
-
-
-
delete语句和select ... for update类似,只不过需要给对应的二级索引也都加上隐式锁,效果和X记录锁类似,update在二级索引加的也是隐式锁。
-
读未提交和读已提交
-
会使用半一致性读方式来加锁,而不是锁定读。
-
-
可重复读和串行化
-
采用锁定读的方式加锁。
-
-
-
特殊情况
-
首先明确精确匹配和唯一性匹配的概念
-
精确匹配:扫描区间的左右开区间都是同一个值,例如:[1,1]、[(1,1),(1,1)]
-
唯一性搜索(unique search):可以确定扫描区间中有且仅有一条记录,需要满足以下条件
-
首先是精确匹配
-
并且索引需要是聚簇索引或者唯一二级索引(搜索条件的值不能等于NULL)
-
如果索引包含多个列,生成扫描区间的时候,每个列都要用到
-
-
-
精确匹配的情况
-
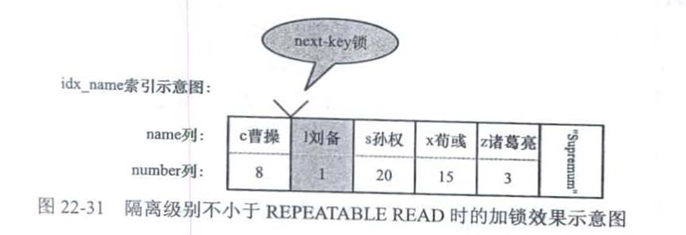
select * from hero where name='c曹操' for update;
-
读未提交和读已提交,不会为不符合区间的第一条数据加锁
-
-
可重复读和串行化,为不符合区间的第一条数据加间隙锁而不是Next-Key锁
-
-
-
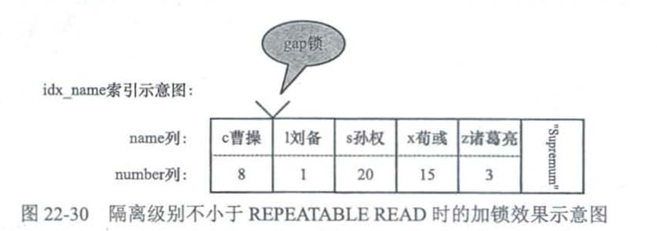
select * from hero where name='g关羽' for update;
-
读未提交和读已提交
-
不会加任何锁
-
-
可重复读和串行化
-
会加上间隙锁
-
-
-
-
-
不是精确匹配的情况
-
select * from hero where name>'d' and name <'1' for update;
-
可重复读和串行化
-
会为下一条记录加上Next-Key锁
-
-
-
-
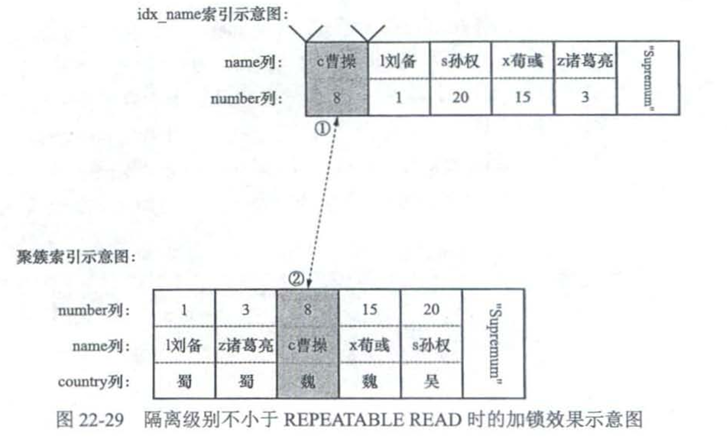
select * from hero where number>=8 for update;
-
可重复读和串行化
-
会为第一条记录符合区间的记录加上记录锁,而不是Next-Key锁
-
-
-
-
-
唯一性搜索的情况
-
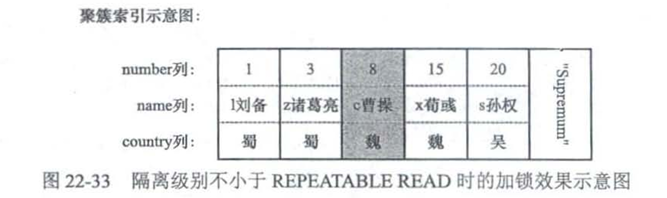
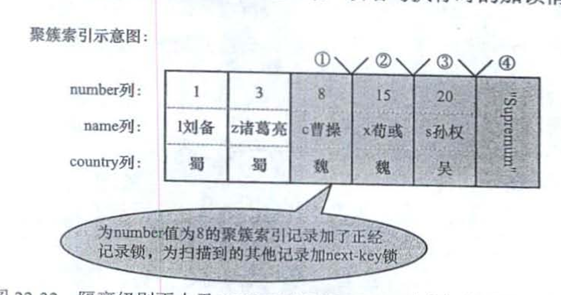
select * from hero where number=8 for update;
-
-
无论什么隔离级别,都加上X记录锁(不会是Next-Key锁)
-
-
-
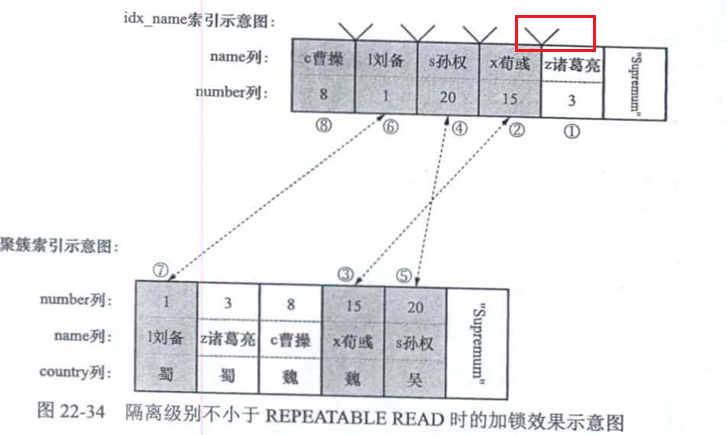
从右往左扫描的情况(一般都是从左往右)
-
select * from hero force index(idx_name) where name>'c曹操' and name<= 'x荀彧' and country != '吴' order by name desc for update;
-
可重复读和串行化
-
-
会为合法区间外的后一条记录,加上间隙锁
-
-
-
半一致性读
读未提交、读已提交隔离级别在执行update语句时会使用半一致性读(Semi-Consistent Read)。介于一致性读和锁定读之间的读取方式。
-
当update语句读到被其他事务加上X锁的记录时,就会将该记录的最新版本读出来。
-
判断该记录是否满足where的匹配条件,如果不满足,就会跳过这条记录,读取下一条记录。
-
如果满足,就会对该记录加锁。
-
例如(隔离级别为读已提交):
-
事务1执行:select * from hero where number=8 for update;
-
-
事务2执行:update hero set name='cao曹操' where number>=8 and number <20 and country!='魏';
-
依次读取number为8、15、20的记录
-
如果是锁定读的话,就会阻塞在读取number为8的记录,但此时是本一致性读,
-
存储引擎就会先将记录返回给server层,判断不符合country!='魏的条件,直接掠过这条记录,server层让存储引擎继续读取后续记录
-
-
insert语句
-
正常情况前面已经说明了
-
但是插入过程如果报错了,那么就会报错,在报错前还会有一些操作:
-
遇到重复键(主键或者唯一键冲突)
-
读未提交、读已提交,会给重复键冲突的记录加上S型记录锁
-
可重复读、串行化,会给重复键冲突的记录加上S型Next-Key锁
-
如果insert语句是,insert ... on duplicate key ...,则上述S型都变成X型
-
-
外键检查
-
如果外键能在对应的表找到,那么无论什么隔离级别,都会给外键的表对应的记录加上S型记录所。
-
如果找不到
-
读未提交、读已提交,不加锁
-
可重复读、串行化,外键的表对应的记录加上间隙锁(外键对应的下一条记录,原本有2、4两条记录,外键为3,那么给4加上间隙锁)
-
-
-
查看事务加锁情况
-
MySQL5.7
-
show engine innodb status\G;
-
TRACSACTION段落存在
-
-
select * from information_schema.innodb_trx;
-
该表存储了 lnnoDB存储引擎当前正在执行的事务信息,包括事务 id(如果没有为该事务分配唯一的事务id,则会输出该事务对应的内存结构的指针)、事务状态(比如事务是正在运行还是在等待获取某个锁、事务正在执行的语句、事务是何时开启的)
-
-
select * from information_schema.innodb_locks;
-
记录锁的信息,但是只有在以下两种情况才会记录:
-
如果一个事务想要获取某个锁但未获取到, 则记录该锁信息
-
如果一个事务获取到了某个锁,但是这个锁阻塞了别的事务,则记录该锁信息.
-
-
-
select * from information_schema.innodb_lock_waits;
-
表明每个阻塞的事务是因为获取不到哪个事务持有的锁而阻塞
-
-
-
MySQL8.0
-
select * from performance_schema.data_locks;
-
LOCK_TYPE:锁的类型(RECORD行级锁,TABLE表级锁)
-
LOCK_MODE:锁的模式
-
X,REC_NOT_GAP ---X型记录锁
-
X,GAP ---X型间隙锁
-
X ---X型Next-Key锁
-
-
-
死锁
-
两个事务互相获取对方的锁就会发生死锁。
-
MySQL自己会自动将事务id较小的那个事务回滚,解除死锁。
-
可以通过show engine innodb status\G;查看死锁日志
-
LATEST DETECTED DEADLOCK 段落(最近一次死锁日志)
-
innodb_print_all_deadlocks设置为on,可以查看所有死锁日志
-