黑马点评redis改 part 6
GEO数据结构
GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
GEODIST:计算指定的两个点之间的距离并返回
GEOHASH:将指定member的坐标转为hash字符串形式并返回
哈希降维:先将经纬度坐标值 转换成 二进制的数字,然后再利用特殊的编码 转换成 对应的字符串[1.转换成字符串后,占用的空间就会小一点,节省内存。
GEOPOS:返回指定member的坐标
GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.2以后已废弃
GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。6.2.新功能
在首页中点击某个频道,即可看到频道下的商户:Request URL:http://localhost:8080/api/shop/of/type?&typeId=1¤t=1&x=120.149993&y=30.334229
请求方式GET
请求路径/shop/of/type
typeId:商户类型
请求参数current:页码,滚动查询;x:经度;y:纬度
返回值List<Shop>:符合要求的商户信息
我们可以看到这个请求,它的请求方式是GET,路径叫`/shop/tap`。我们在这个地方其实暗含了一个条件,就是要根据类型搜索啊,他点美食,你搜出来肯定是美食,点KTV出来的就是KTV。要求根据类型做搜索。传了第一个参数叫`typeId`商户的类型。然后第二个参数呢叫`count`,页码这里要做滚动查询啊,注意这个滚动查询就是说这个地方可能一页展示不完嘛,那我就滚动一次,你就多查一页,滚动一次查一页。而在分页的时候呢,他这里有页码,那肯定就会有每一页的大小,所以他不就是一个传统分页吗?所以这块呢我们不用太担心,实现起来也不复杂。然后呢,既然要去实现附近商户搜索,那你是不是得有一个圆心。所以呢,这里接下来的两个参数x y,那大家一看就知道了啊,看这个值是经纬度的,那这个经纬度啊就是当前登录这个用户他的一个坐标,将来我们要搜的呢就是它附近的这些商户,按照距离去做个排序。那这个用户的坐标哪儿来的呢?如果是在真实的案例当中,肯定是由咱们的app从后台获取,当前的这个手机所在的位置啊,咱们这儿呢就直接在前台写死了好。
那么我们拿到这些信息了以后传到后台了,那后台就可以根据`typeId`做过滤,去搜索到相同类型的这些商家,然后再利用current页码去做分页,再利用这种经纬度去做一个排序就行了。最后呢返回的自然就是查询到的所有商家,形成的一个集合了啊。那到这里呢,这个接口的分析就完成了。但是我们别着急啊,去实现这个接口啊,同学们想想看,现在我们的商家的信息都保存在哪里?哎,是不是保存在数据库啊?那我们可以来看一下,我们打开数据库,在这里啊,`tb_shop`,就是我们的商户表了。那这张表里面呢有很多的字段啊,其中有一个就是`typeId`代表的是店铺的类型。在这里边呢我们现在数据量并不多啊,其中呢他把id为一的,就是所有的美食有关的店铺啊,他把id为二的就是所有KTV有关的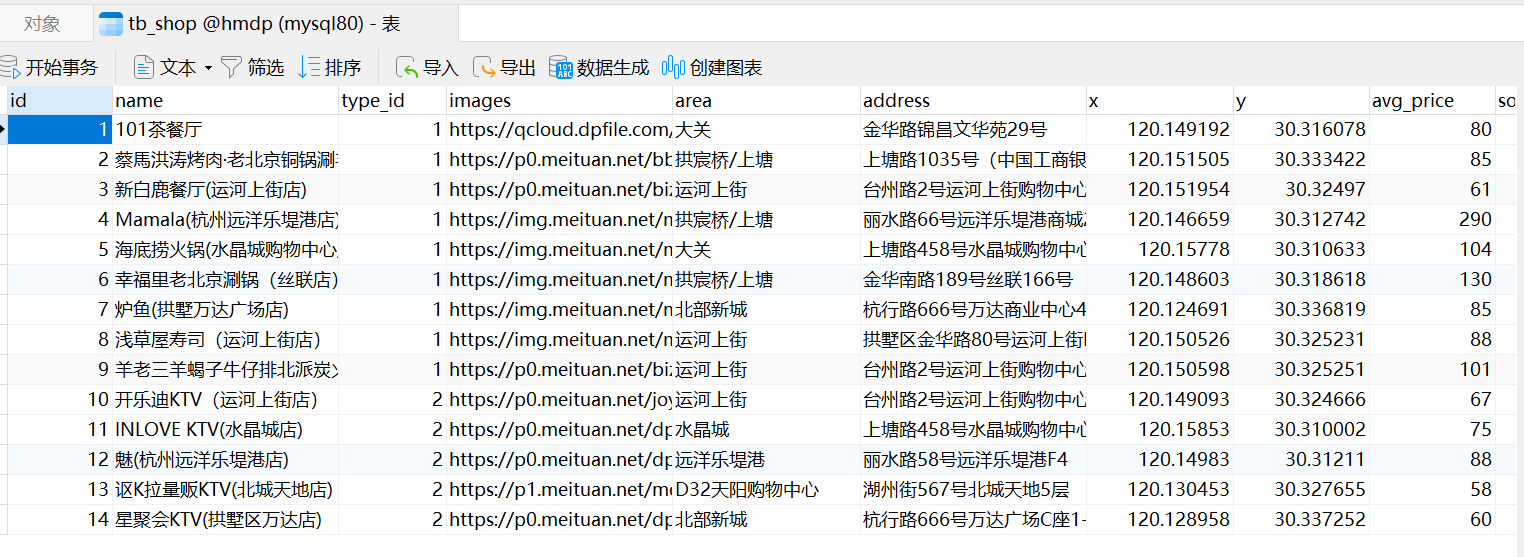
那现在这个接口怎么是验证的,就是前端发过来的`typeId`,他会来这基于`typeId`做过滤,然后呢找到对应的店铺,然后做分页返回到前端。不过我们将来要实现的呀,除了根据`typeId`过滤以外,是不是还要按照地理坐标去搜索附近的商家呀,唉还要按距离排序。那这样的功能在我们的数据库里能实现吗?唉显然不能啊。那要想实现我们必须干嘛,我们必须要把店铺当中的这些经纬度坐标啊等等信息导入到Redis当中的Geo类型的数据结构当中。不过呀这里有一点需要注意啊,我们的Geo类型他在存储的时候,不知道大家记不记得它里边的参数呢,其实主要就是一个member,一个经度和一个纬度。经纬度对应到我们数据库表里就是xy,而member我们存什么呢,是不是把整个店铺的信息都塞到那个member里去呢,显然不合适吧。那Redis毕竟是内存存储啊,它的空间占用了太多了也不太好。所以说呢在这个地方我的建议是啊,这个member啊,我们直接存一个店铺的id就可以了。也就是说我们将来把这些数据导入list的时候,存店铺id和经纬度坐标,将来我们要去搜索附近店铺的时候,根据经纬度坐标去进行筛选,筛选以后得到的是什么,然后我们再拿id来数据库里,根据id查我们的数据库效率上还是可以接受的,对不对?唉这是我们将来实现的一个思路啊。但是事情到这还没完啊,这里啊还有一个问题需要我们去分析,我们回到PPT看一下,大家别忘了这里我们的搜索有一个限制条件,就是要根据类型id做过滤,你要知道我们刚才商量了,我们存到Redis里面的仅仅是坐标,还有店铺的id,根本就没有类型id,所以你能过滤吗?过滤不了。
附近商户搜索
按照商户类型做分组,类型相同的商户作为同一组,以typeld为key存入同一个GEO集合中即可
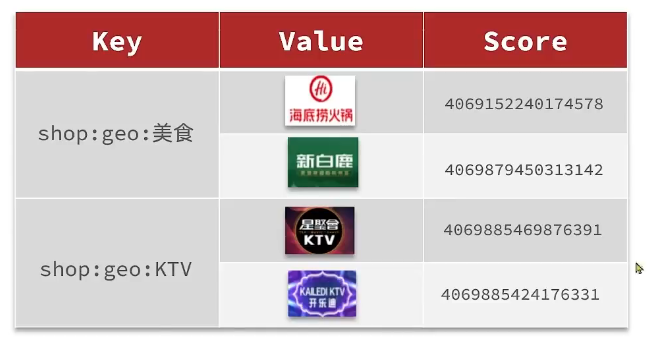
@Test
void loadShopData(){// 1. 查询所有店铺信息(若数据量大可分批查询,此处因数据量小直接查询全部)List<Shop> list = shopService.list();// 2. 按类型ID分组,使用Stream API优雅实现分组逻辑// key: 店铺类型ID,value: 同类型店铺集合Map<Long, List<Shop>> map = list.stream().collect(Collectors.groupingBy(Shop::getTypeId));// 3. 分批写入Redis GEO,优化网络延迟map.forEach((typeId, shops) -> {// 3.1 创建Redis GEO键,格式:shop:geo:{typeId}String key = "shop:geo:" + typeId;// 3.2 构建地理位置集合,批量操作提升效率List<RedisGeoCommands.GeoLocation<String>> locations = new ArrayList<>(shops.size());shops.forEach(shop -> {// 将店铺ID作为member,经纬度封装为Point对象locations.add(new RedisGeoCommands.GeoLocation<>(shop.getId().toString(), new Point(shop.getX(), shop.getY())));});// 3.3 批量写入Redis,单次请求完成所有同类型店铺的地理位置存储// 对比单条插入,批量操作显著减少网络往返时延stringRedisTemplate.opsForGeo().add(key, locations);});
}运行test,可以看到geo中存在1和2,对应的类型是餐厅和ktv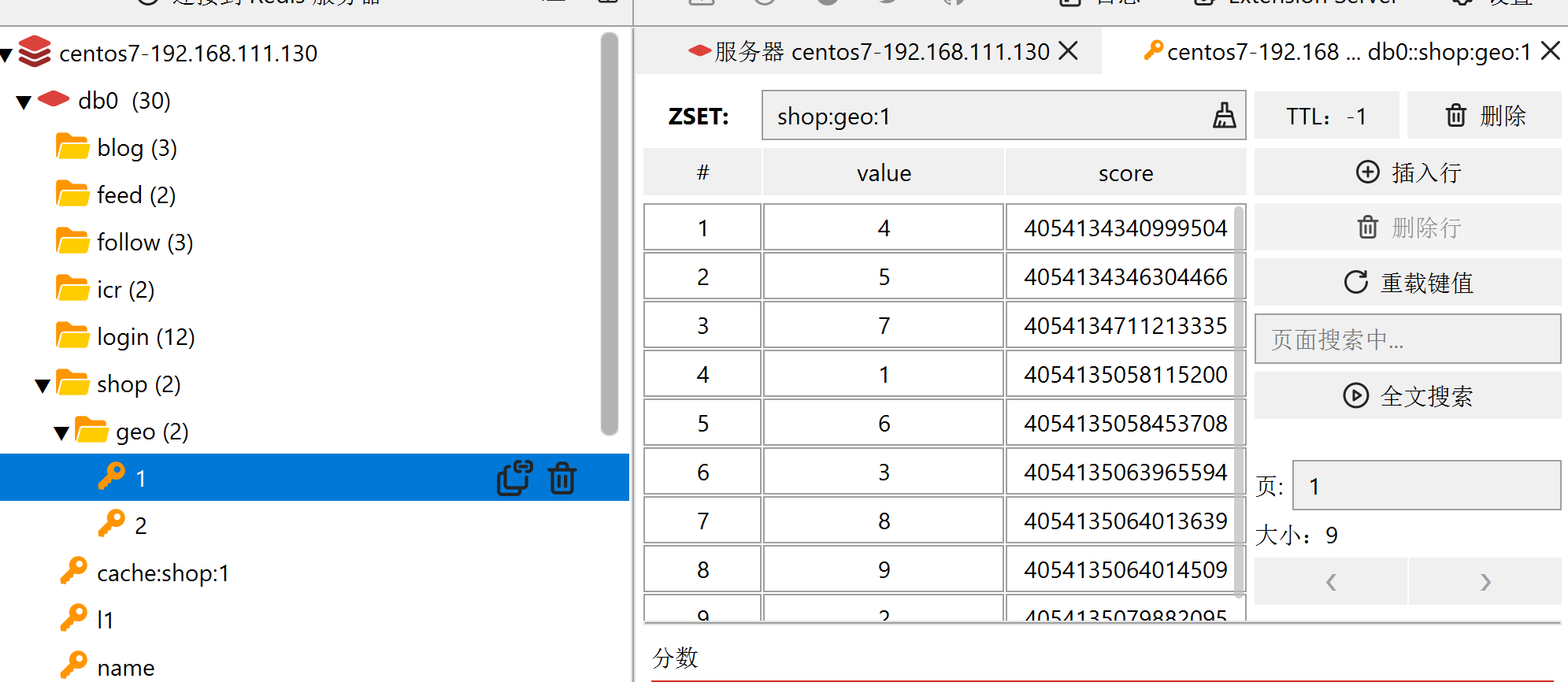
SpringDataRedis的2.3.9版本并不支持Redis6.2提供的GEOSEARCH命令,因此我们需要提示其版本,修改自己的POM文件,内容如下: 按照老师视频中可以按照mavenhelper插件,
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><exclusions><exclusion><artifactId>lettuce-core</artifactId><groupId>io.lettuce</groupId></exclusion><exclusion><artifactId>spring-data-redis</artifactId><groupId>org.springframework.data</groupId></exclusion></exclusions></dependency><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-redis</artifactId><version>2.6.2</version></dependency><dependency><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId><version>6.1.6.RELEASE</version></dependency>修改shopcontroller,service和impl
@GetMapping("/of/type")public Result queryShopByType(@RequestParam("typeId") Integer typeId,@RequestParam(value = "current", defaultValue = "1") Integer current,@RequestParam(value = "x",required = false) Double x,@RequestParam(value = "y",required = false) Double y) {return shopService.queryShopByType(typeId,current,x,y);}
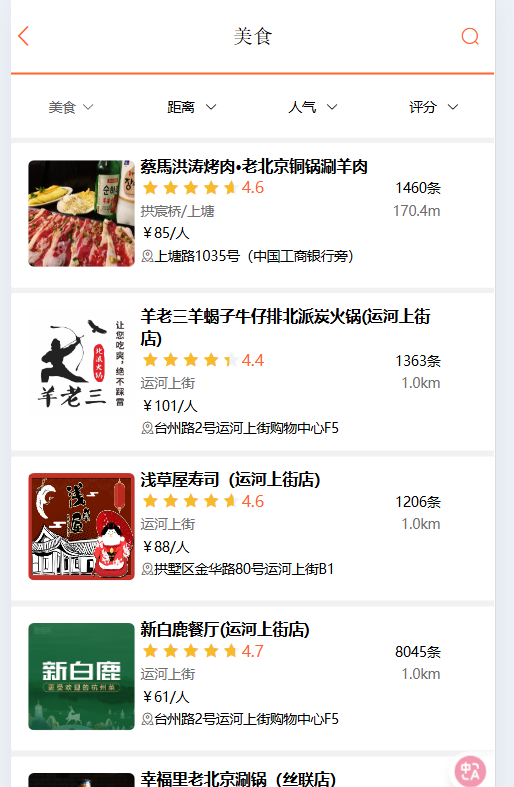
@Overridepublic Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {// 1. 判断是否需要根据坐标查询if (x == null || y == null) {// 不需要坐标查询,按数据库查询Page<Shop> page = query().eq("type_id", typeId).page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));// 返回数据return Result.ok(page.getRecords());}// 2. 计算分页参数int from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE;int end = current * SystemConstants.DEFAULT_PAGE_SIZE;// 3. 查询redis,按照距离排序,分页。结果:shopId.distanceString key = SHOP_GEO_KEY + typeId;GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo() // GEOSEARCH key BYLONLAT x y BYRADIUS 10 WITHDISTANCE.search(key,GeoReference.fromCoordinate(x, y),new Distance(5000),RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end));// 4. 解析出idif (results == null) {return Result.ok(Collections.emptyList());}List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent();if (list.size() <= from) {//没有下一页了,结束return Result.ok(Collections.emptyList());}// 4.1. 截取 from ~ end 的部分Map<String, Distance> distanceMap = new HashMap<>(list.size());List<Long> ids = new ArrayList<>(list.size());list.stream().skip(from).forEach(result -> {// 4.2. 获取店铺idString shopIdStr = result.getContent().getName();ids.add(Long.valueOf(shopIdStr));// 4.3. 获取距离Distance distance = result.getDistance();distanceMap.put(shopIdStr, distance);});// 5. 根据id查询ShopString idStr = StrUtil.join(",", ids);List<Shop> shops = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();for(Shop shop:shops){shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());}return Result.ok(shops);}不再像原来那样第一个是101茶餐厅了, 第一个是烤肉了,距离170m,往下滑也会出现其他的餐厅
-
判断是否需要地理查询
首先检查用户是否提供了经纬度参数x和y。如果任意一个为空,说明不需要地理范围查询,直接按传统方式从数据库分页查询。根据类型ID(typeId)筛选记录,使用MyBatis-Plus的分页功能,每页大小采用系统常量默认值(如5条),返回当前页的店铺数据。 -
计算分页范围
当需要地理查询时,根据当前页码(current)和固定每页大小(如5条),计算需要获取的数据区间。例如第1页取0-5条,第2页取5-10条。通过(current-1)*pageSize确定起始位置,current*pageSize确定结束位置。 -
Redis地理搜索
构建Redis的Geo查询:- 使用固定前缀(如
shop:geo:)拼接类型ID作为Redis键 - 以用户提供的经纬度(x,y)作为圆心
- 设置半径范围(如5000米)
- 要求返回结果包含距离信息
- 通过limit参数限制返回数量(取结束位置的值,如第2页取10条)
- 使用固定前缀(如
-
解析搜索结果
检查Redis返回结果是否为空。若结果不足一个完整分页(如第3页只有2条数据但请求5条),直接返回空列表。否则遍历结果,提取店铺ID并记录对应的距离值,同时截取当前分页区间的数据(如第2页取索引5到10的条目)。 -
数据库精准查询
根据提取的店铺ID集合,使用SQL的IN语句批量查询数据库。特别添加ORDER BY FIELD语句,确保返回顺序与Redis地理搜索结果的顺序一致,避免数据错位。 -
补充距离信息
将Redis获取的距离值回填到店铺对象中。遍历数据库查询结果,根据每个店铺的ID从距离映射表中查找对应值,设置到对象的distance属性。
关键注意事项:
- Redis的limit参数需要取分页结束位置的值(如第2页取10),因为Redis会返回从第1条到第10条的数据,后续需自行截取5-10条部分
- 数据库查询必须使用
ORDER BY FIELD保持与Redis结果顺序一致 - 距离单位需与Redis存储时的单位(米)保持一致
- 需要处理边界情况(如最后一页数据不足、无搜索结果等)
if (list.size() <= from) { //没有下一页了,结束return Result.ok(Collections.emptyList()); }
用户签到
BitMap用法
假如我们用一张表来存储用户签到信息,其结构应该如下:
CREATE TABLE `tb_sign` (`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',`user_id` bigint unsigned NOT NULL COMMENT '用户id',`year` year NOT NULL COMMENT '签到的年',`month` tinyint NOT NULL COMMENT '签到的月',`date` date NOT NULL COMMENT '签到的日期',`is_backup` tinyint unsigned DEFAULT NULL COMMENT '是否补签',PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=COMPACT;假如有1000万用户,平均每人每年签到次数为10次,则这张表一年的数据量为1亿条
每签到一次需要使用(8+8+1+1+3+1)共22字节的内存,一个月则最多需要600多字节
因此模拟签到卡,BitMap用法,我们按月来统计用户签到信息,签到记录为1,未签到则记录为0. 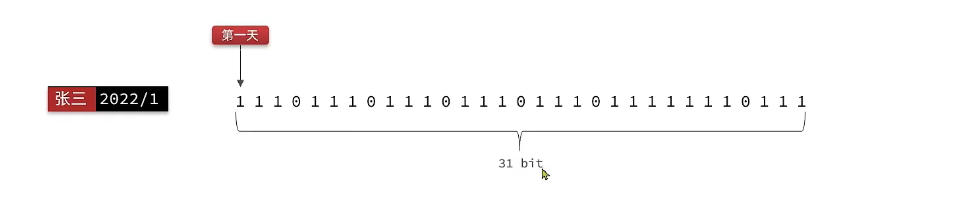
把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路就称为位图(BitMap)。Redis中是利用string类型数据结构实现BitMap,因此最大上限是512M,转换为bit则是2^32个bit位。(有点像牛逼的状态压缩dp)
Redis中是利用string类型数据结构实现BitMap,因此最大上限是512M,转换为bit则是2^32个bit位。
BitMap的操作命令有:
SETBIT:向指定位置(offset)存入一个0或1
GETBIT:获取指定位置(offset)的bit值
BITCOUNT:统计BitMap中值为1的bit位的数量
BITFIELD:操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
BITFIELD_RO:获取BitMap中bit数组,并以十进制形式返回
BITOP:将多个BitMap的结果做位运算(与、或、异或)
BITPOS:查找bit数组中指定范围内第一个0或1出现的位置

好同学们,在刚才我们已经熟悉了`bitmap`的基本用法,下面呢我们就利用它来实现一下签到的功能啊。在这儿我已经把需求给罗列出来了,需求说让我们实现签到的接口,将当前用户当天的签到信息保存到Redis当中。而这里请求的方式呢用了POST代表新增,请求的路径呢是`/user/sign`,那代表就是签到了啊。请求的参数是没有返回值,什么参数都没有,让我去签到。大家应该还记得吧,我们之前讲过实验签到,最终格式是不是这样子的,我们会与用户结合这个年和月作为key,因为呢签到往往是以月为统计单位的,所以我们希望每个用户每个月的签到情况,放到一个bitmap里,方便我们将来去做统计了。所以呢我们的key呢就有用户和日期啊两部分组成,那这样一来要想实现这样的功能,是不是至少要知道用户信息,还有年和月的信息,还有你让我签到签的是第几个比特位啊,是不是还得知道对应的日期信息啊,年月日都得知道,结果呢你现在啥都不给我,那我怎么去实现这个签到唉,他说了,是将当前用户,是我们登录的这个用户,当天,就是现在,所以让他现在时间,可以用代码直接获取,因此这几个东西都不需要前端,是直接就搞定了。
所以啊签到功能是无参的,那将来如果你要实现什么补签之类的,你再让他传日期是不是就ok了。好,这是我们整个接口的一些要求啊,那我们之前讲的时候,bitmap讲的是命令啊,那现在咱们用java代码实现了呀,这里呢有一个提示告诉我们了,说bitmap底层是spring类型实现的啊,是我们redis里面的spring实现的啊,所以说呢我们的spring在做api封装的时候,把对于bitmap的操作一起封装到字符串里面去了,那我们知道在redis templating,它是不是有open for value ops for hash哈,希set呀,哎但是他没有opposable bitmap啊,因为呢相关的都封装到了字符串操作了,叫a value,因此这里拿的是value operation,所以我们将来操作并web的时候一定要记住啊,拿的是value相关操作字符串操作,然后里面提供了set bit get bit field的三个函数,那set bit是不是就可以实现签到功能,然后这里的三个参数分别就是我们的key,然后我们的offset,然后就是true和false代表零和一啊,就是k是谁给哪一天签到啊,签的是true还是false。
UserController和service还有impl
@PostMapping("/sign")
public Result sign(){return userService.sign();
}
@Overridepublic Result sign() {// 1. 获取当前登录用户Long userId = UserHolder.getUser().getId();// 2. 获取日期LocalDateTime now = LocalDateTime.now();// 3. 拼接keyString keySuffix = now.format(DateTimeFormatter.ofPattern("yyyyMM"));String key = USER_SIGN_KEY + userId + keySuffix;// 4. 获取今天是本月的第几天int dayOfMonth = now.getDayOfMonth();// 5. 写入Redis SETBIT key offset 1stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);return Result.ok();}数据库应该存一份,迟到功能,签到时间还没实现 
我们在redis中检验一下, 正好今天是4.27号,一个字节8位,因此为了存储一共32个,所以后面还有5个0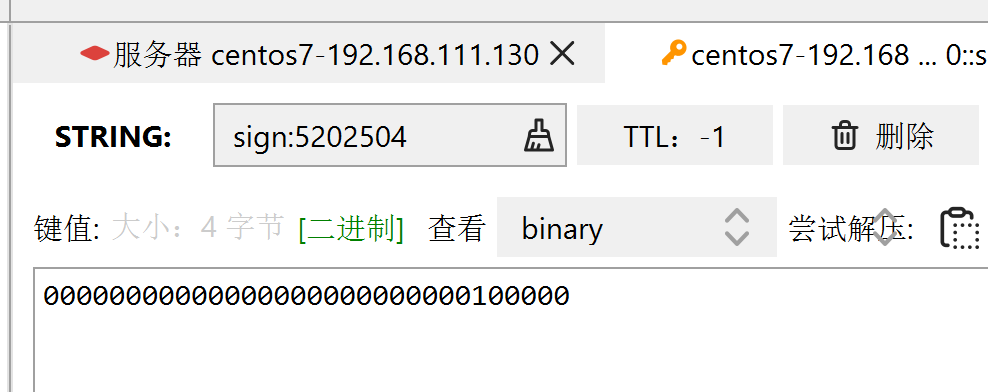
问题1:什么叫做连续签到天数?
从最后一次签到开始向前统计,直到遇到第一次未签到为止,计算总的签到次数,就是连续签到天数。
111000110110001011101111101111
问题2:如何得到本月到今天为止的所有签到数据?
BITFIELD key GET u[dayOfMonth] 0
问题3:如何从后向前遍历每个bit位?
与1做与运算,就能得到最后一个bit位。随后右移1位,下一个bit位就成为了最后一个bit位。
需求:实现下面接口,统计当前用户截止当前时间在本月的连续签到天数
| 说明 | |
| 请求方式 | GET |
| 请求路径 | /user/sign/count |
| 请求参数 | 无 |
| 返回值 | 连续签到天数 |
在本节中,我们将实现一个签到功能,该功能将当前用户当天的签到信息保存到Redis中。请求方式使用POST,代表新增,请求路径是/user/sign,代表签到操作。请求参数没有,返回值也没有,意味着这个接口是无参的。我们可以通过获取当前登录用户的信息以及当前日期来实现这个功能。
首先,我们需要了解bitmap的基本用法。在Redis中,bitmap可以用来存储签到信息。我们将用户ID和年月作为key,因为签到通常以月为统计单位,所以我们希望每个用户每个月的签到情况都放在一个bitmap里,方便将来进行统计。
要实现签到功能,我们需要知道用户信息、年和月的信息,以及对应的日期信息。这些信息都不需要前端传递,我们可以直接在后端获取。签到功能是无参的,但如果未来需要实现补签之类的功能,可以让用户传递日期参数。
在Redis中,我们可以使用SETBIT命令来实现签到功能,其中三个参数分别是key、offset和value。这里的key是我们的bitmap key,offset是偏移量,value是签到状态(0或1)。
接下来,我们将使用Java代码来实现这个统计连续签到次数的功能。我们需要从最后一次签到开始向前统计,直到遇到第一次未签到为止,然后计算总的签到次数,即连续签到次数。
我们可以通过以下步骤实现这个功能:
- 获取当前月份所有签到数据。
- 从最后一次签到开始向前统计,直到遇到第一次未签到为止。
- 计算总的签到次数,即连续签到次数。
在Java代码中,我们可以使用for循环和if语句来实现这个逻辑。首先,我们需要获取当前用户当月的签到记录,然后从最后一个签到记录开始向前遍历,直到遇到未签到的记录。在遍历过程中,我们需要一个计数器来记录签到次数,每遇到一个签到记录,计数器加一,直到遇到未签到的记录为止。
最后,我们将这个计数器的值返回,它就代表了用户在本月的连续签到天数。
@GetMapping("/sign/count")public Result signCount(){return userService.signCount();}UserControl修改如下,连带service,impl一起
@Overridepublic Result signCount() {Long userId = UserHolder.getUser().getId();LocalDateTime now = LocalDateTime.now();String keySuffix = now.format(DateTimeFormatter.ofPattern("yyyyMM"));String key = USER_SIGN_KEY + userId + keySuffix;int dayOfMonth = now.getDayOfMonth();//5,获取本月截止今天为止的所有的签到记录,返回的是一个十进制的数字 BITFIELD sign:5:202504 GET u14 0List<Long>result =stringRedisTemplate.opsForValue().bitField(key,BitFieldSubCommands.create().get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0));Long num =result.get(0);if(result.isEmpty() || result ==null){//没有任何签到return Result.ok(0);}//6.循环遍历int count=0;while(true){//6.1.让这个数字与1做与运算,得到数字的最后一个bit位if((num&1) == 0){//如果为0,说明未签到,结束//如果不为0,说明已签到,计数器+1break;}else{count++;}//把数字右移一位,抛弃最后一个bit位,继续下一个bit位num >>>= 1;}return Result.ok(count);}- 可在Redis客户端使用
BITFIELD sign:5:202504 GET u14 0验证数据 - 使用
SETBIT sign:5:202504 0 1模拟签到数据 - 注意月份切换时的键变化(如4月->5月会生成新键)
@Override
public Result signCount() {// 获取当前用户ID(从线程上下文获取登录用户信息)Long userId = UserHolder.getUser().getId();// 获取当前日期时间LocalDateTime now = LocalDateTime.now();// 生成Redis键的后缀(格式:yyyyMM,例如"202504")String keySuffix = now.format(DateTimeFormatter.ofPattern("yyyyMM"));// 构建完整的Redis键(格式:sign:用户ID:yyyyMM)String key = USER_SIGN_KEY + userId + keySuffix;// 获取当前日期是本月的第几天(用于确定查询的bit位数)int dayOfMonth = now.getDayOfMonth();// 使用Redis BitField命令获取本月截止今天的签到记录 [[7]]List<Long> result = stringRedisTemplate.opsForValue().bitField(key,BitFieldSubCommands.create()// 定义BITFIELD GET子命令:无符号整数,长度为当前日期天数,从第0位开始读取.get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0));// 处理Redis返回结果的边界情况if (result.isEmpty() || result.get(0) == null) {return Result.ok(0); // 无签到记录时返回0}// 将结果转换为二进制处理(每位代表一天的签到状态)Long num = result.get(0);int count = 0; // 计数器:连续签到天数// 通过位运算遍历每个bit位(从低位到高位对应从当月1号到当前日期)while (true) {// 1. 检查最低位是否为1(已签到) [[7]]if ((num & 1) == 0) {break; // 遇到未签到天(0)终止循环}count++; // 累计连续签到天数// 2. 右移一位继续检查下一天(高位->低位移动)[[7]]num >>>= 1;}return Result.ok(count); // 返回连续签到天数
}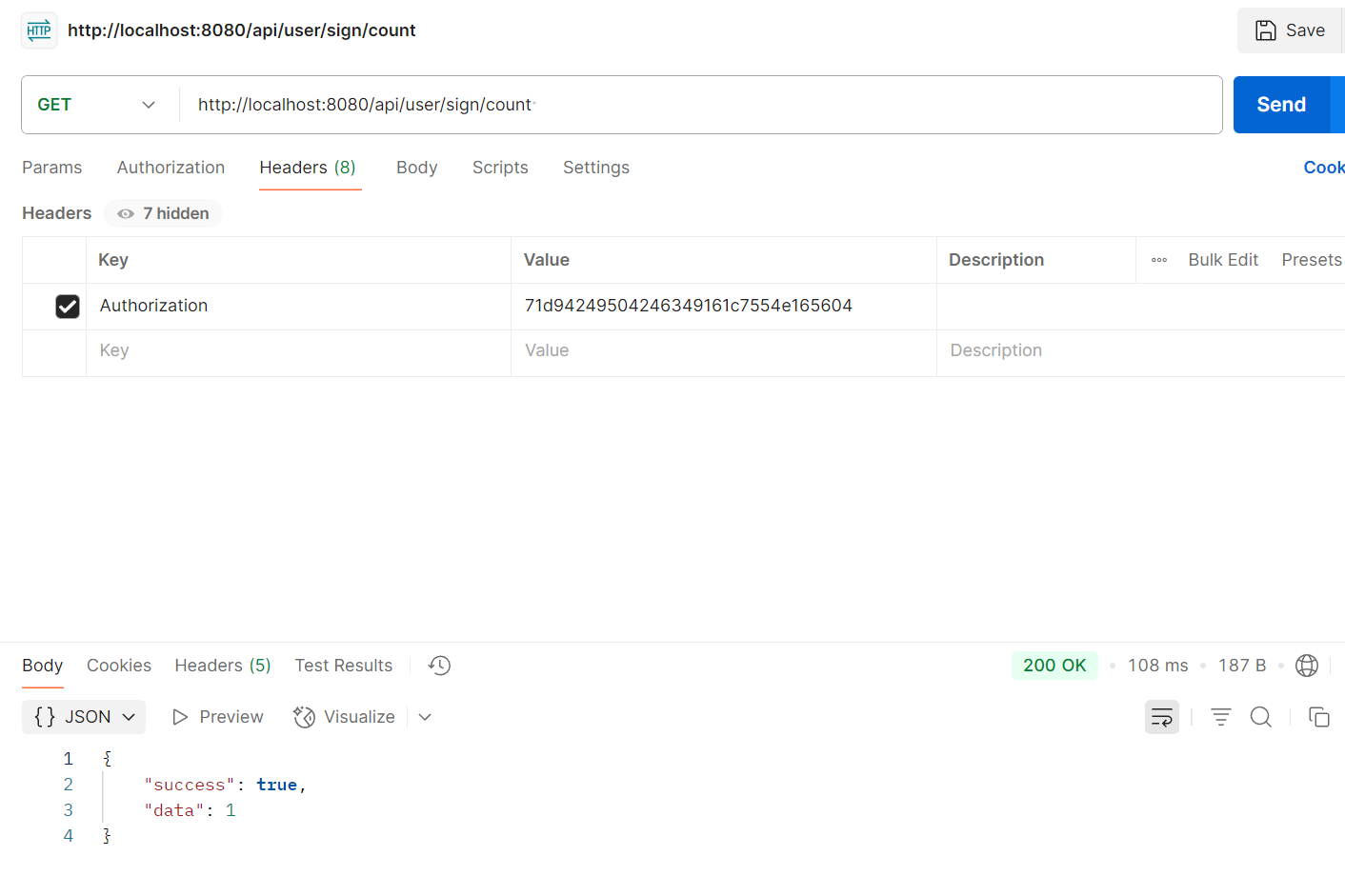
签到一天,那么return 1,你可以改改redis,自行测试是否可以5天,15天
UV统计
HyperLogLog用法
首先我们搞懂两个概念:
●UV:全称UniqueVisitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
●PV:全称PageView,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖。
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。相关算法原理大家可以参考:https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结果 是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。
PFADD key element [element ...]
summary: Adds the specified elements to the specified HyperLogLog.
since: 2.8.9PFCOUNT key [key ...]
summary: Return the approximated cardinality of the set(s) observed by
since: 2.8.9PFMERGE destkey sourcekey [sourcekey ...]
summary: Merge N different HyperLogLogs into a single one.
since: 2.8.9127.0.0.1:6379> PFADD hl1 e1 e2 e3 e4 e5
(integer) 1
127.0.0.1:6379> PFCOUNT hl1
(integer) 5
127.0.0.1:6379> PFADD hl1 e1 e2 e3 e4 e5
(integer) 0
127.0.0.1:6379> PFADD hl1 e1 e2 e3 e4 e5
(integer) 0
127.0.0.1:6379> PFCOUNT hl1
(integer) 5
127.0.0.1:6379>test一下
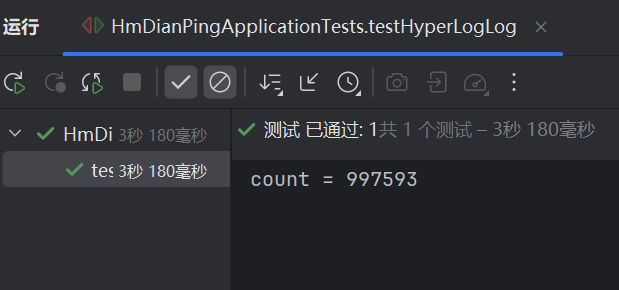
@Testvoid testHyperLogLog(){String[] values = new String[1000];int j = 0;for (int i = 0; i < 1000000; i++) {j = i % 1000;values[j] = "user_" + i;if (j == 999) {// 发送到RedisstringRedisTemplate.opsForHyperLogLog().add("hl2", values);}}
// 统计数量Long count = stringRedisTemplate.opsForHyperLogLog().size("hl2");System.out.println("count = " + count);}
黑马点评完整代码(RabbitMQ优化)+简历编写+面试重点 ⭐_黑马点评简历-CSDN博客