谷歌提示词工程白皮书 第一部分
目录
一、引言
二、提示词工程
2.1 LLM 输出配置
2.2 采样控制
本篇文章主要对谷歌《提示词工程》白皮书进行解读。
你不需要是数据科学家或机器学习工程师——每个人都可以写提示词!
一、引言
在考虑大型语言模型的输入和输出时,文本提示(有时会伴随其他模态,例如图像提示)是模型用来预测特定输出的输入。你无需成为数据科学家或机器学习工程师——每个人都可以编写提示词。然而,设计最有效的提示词可能非常复杂。提示词的各个方面都会影响模型输出效果,例如:使用的模型、模型训练数据、模型配置、你的措辞、风格和语气、结构以及上下文都很重要。因此,提示词工程是一个不断迭代的过程。不合适的提示词会导致模糊、不准确的输出,并会阻碍模型产生有意义的输出。
与 Gemini 聊天机器人聊天时,你基本上都需要编写提示词,但本白皮书重点介绍如何在 Vertex AI 中或使用 API 的方式为 Gemini 模型编写提示词,因为通过直接访问模型,你将能够自定义配置温度等模型参数。
本白皮书详细探讨了提示词工程。我们将探讨各种提示词技巧,帮助你入门,并分享一些技巧和最佳实践,助你成为提示词专家。此外,我们还将讨论你在设计提示词时可能遇到的一些挑战。
二、提示词工程
注意 LLM 的工作原理,它是一个预测引擎。该模型将连续的文本作为输入,然后根据训练数据预测下一个输出应该是什么。LLM 会反复执行此操作,将先前预测内容添加到已输出文本的末尾,以预测下一个输出。下一个输出的预测基于先前输出的内容与 LLM 在训练过程中所见内容之间的关系。
当你编写提示词时,你正在尝试设置 LLM 来预测正确的输出。提示词工程是设计高质量提示词的过程,这些提示词可以引导 LLM 生成更精准的输出。这个过程包括不断修改以找到最佳提示词、优化提示词长度,以及根据任务评估提示词的写作风格和结构。在自然语言处理和 LLM 的语境中,提示词是提供给模型以生成响应或预测的输入。
这些提示词可用于实现各种理解和生成任务,例如文本摘要、信息提取、问答、文本分类、语言或代码翻译、代码生成以及代码文档或推理。
请参考 Google 提示词指南,其中包含简单有效的提示词示例。
在进行提示词工程时,首先需要选择一个模型。无论你使用的是 Vertex AI、GPT、Claude 中的 Gemini 语言模型,还是 Gemma 或 LLaMA 等开源模型,提示词可能需要针对你使用的特定模型进行优化。
除了提示词之外,你还需要调整 LLM 的各种参数设置。
2.1 LLM 输出配置
在确定使用的模型后,你需要配置模型参数。大多数 LLM 都带有各种配置选项,用于控制 LLM 的输出。有效的提示词工程需要根据你的任务优化这些配置。
输出长度:
一个重要的参数设置是输出中要生成的令牌(tokens)数量(即:模型输出长度)。生成更多令牌(输出内容)需要 LLM 进行更多计算,从而导致耗费更多的算力、更慢的响应时间和更高的成本。
减少 LLM 的输出长度并不会使 LLM 的输出在风格或文本上更加简洁,而只是会导致 LLM 在达到限制后停止预测更多输出内容。如果您需要较短的输出长度,你可能还需要调整提示词以适应这种情况。
例如:设置最大输出 tokens 为 1,你输入的问题是“请介绍下北京”,模型输出可能是“北京”。如果最大输出 tokens 为 2,模型输出可能是“北京是一个”。当达到最大输出 tokens 时,模型直接截断输出。如果在提示词中设置“请输出不要超过100字”,则不会出现这种问题。
输出长度限制对于某些 LLM 提示技术尤其重要,例如 ReAct,LLM 可能在你想要的输出之后继续输出无用的令牌(token)。
请注意:生成更多令牌需要 LLM 进行更多计算,从而导致更高的算力消耗和更慢的响应时间,最终导致更高的成本。
2.2 采样控制
大模型不会直接预测单个 token(token:大模型的一个输出单位,一个token 约等于2~3个汉字)。相反,大模型会预测下一个 token 的概率,大模型词汇表中的每个 token 都会获得一个概率。然后,这些 token 的概率会被采样,以确定下一个生成的 token 是哪个。Temperature、top-K 和 top-P 参数是最常见的 LLM 配置参数,它们决定了如何处理预测的 token 概率,以选择使用哪个 token 输出作为输出。
温度参数:
温度参数控制 token (输出)选择的随机性程度。较低的温度适合于希望大模型输出更确定性内容,而较高的温度则可能导致更多样化或意想不到的结果。
温度参数为 0 (贪婪解码,是指模型在生成文本的时候,每一步都会直接选择当前概率最高的下一个词,而不是考虑其他可能性)时,输出是确定性的,即始终选择概率最高的令牌(token)(但请注意,如果两个令牌(token)具有相同的最高预测概率,则输出依赖于模型的实现方式。因此,在温度为 0 的情况下,输出结果可能并不总是相同的)。
接近最高温度往往会产生更多随机输出。随着温度越来越高,所有令牌成为下一个预测输出的可能性都会变得均等。
PS:温度是怎么控制 token 概率的?
温度计算公式如下:
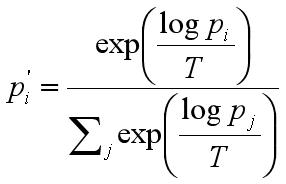
当 T = 1 时,原有的 token 概率不变,当 T 越大,所有 token 的概率值越均等,T 越小,所有 token 的概率差别越大。
Top-K 和 top-P 参数:
Top-K 和 top-P(也称为核采样)是 LLM 中使用的两种采样设置,用于限制预测的下一个 token(输出单元) 仅来自预测概率最高的 token。与温度类似,这些采样设置控制文本生成的随机性和多样性。
Top-K 采样从模型的预测分布中选取最有可能的前 K 个 token。Top-K 值越大,模型的输出就越有创意、越多样化;Top-K 值越低,模型的输出就越呆板、越符合事实。Top-K 值为 1 时相当于贪婪解码。
Top-K 的取值范围:1 ~ 词汇表的大小。
Top-P 采样选择累积概率不超过某个值 (P) 所包含的 token(注意:会先根据词的概率进行排序,然后计算累积)。
P 的取值范围从 0(贪婪解码)到 1(LLM 词汇表中的所有 token)。
例如:假设当前预测的下一个词的概率如下:
| 词 | 概率 |
| 猫 | 0.5 |
| 狗 | 0.3 |
| 鸟 | 0.1 |
| 鱼 | 0.05 |
| 狐狸 | 0.05 |
如果 Top-P = 0.9,那么猫(0.5)+ 狗(0.3)+ 鸟(0.1)= 0.9,这三个词加起来刚好到90%。 于是,只在【猫、狗、鸟】这三个词里面选,不会选鱼或者狐狸了。 然后在这三者之间随机抽一个(当然,猫的概率最高,被抽到的机会也最大)。
如果 Top-P = 0.1,那么 猫(0.5)大于 0.1,所以选择猫。
在 top-K 和 top-P 之间进行选择的最佳方法是分别尝试这两种方法(或同时尝试两种方法),看看哪一种方法能产生你想要的结果。
综合应用:
在 top-K、top-P、温度以及要生成的 token 长度等参数之间进行选择时,取决于具体的应用和期望结果,并且这些参数设置会相互影响。此外,务必了解所选模型如何将不同的采样参数组合在一起。
如果温度、top-K 和 top-P 都可用(例如在 Vertex Studio 中),则同时满足 top-K 和 top-P 标准的 token 将成为下一个预测 token 的候选,然后系统会应用温度参数从符合 top-K 和 top-P 标准的 token 中采样。如果只有 top-K 或 top-P 可用,则采样流程是一样的,但仅使用其中一项 top-K 或 top-P 设置。
如果温度参数不可用,则随机选择满足 top-K 和/或 top-P 标准的 token 来生成下一个预测token。
在某些采样参数值配置的极端情况下,采样参数设置要么抵消其他参数设置,要么变得无关紧要。
- 如果温度参数设为 0,Top-K 和 Top-P 则无关紧要——最高概率的令牌成为下一个预测令牌。如果温度参数极高(超过1,通常到10以上),温度变得无关紧要,Top-K 或 Top-P 过滤后的令牌会随机采样。
- 如果 Top-K 设为1,温度参数和 Top-P 无关紧要。只有一个令牌通过 Top-K 标准,成为下一个预测令牌。如果 Top-K 设为词汇表大小,任何非零概率的令牌都会通过 Top-K 标准。
- 如果 Top-P 设为 0(或很小的值),大多数采样实现只会考虑最高概率的令牌,温度和Top-K无关紧要。如果 Top-P 设为1,任何非零概率的令牌都会通过 Top-P 标准。
在配置参数的时候,温度 0.2、Top-P 0.95、Top-K 30 会生成相对连贯但不过分创意的输出。如果想要特别有创意的结果,可以试温度 0.9、Top-P 0.99、Top-K 40。如果想要更严谨的结果,试温度 0.1、Top-P 0.9、Top-K 20。如果任务有唯一正确答案(比如数学问题),从温度 0 开始。
注意:自由度更高(高温度、Top-K、Top-P 和输出令牌)可能导致模型生成不太相关的文本。
警告:你有没有见过回答末尾堆满无意义的填充词?这是大语言模型常见的 “重复循环错误”,模型陷入循环,反复生成相同的词、短语或句子结构,通常由不合适的温度和 Top-K/Top-P 设置引发。这种问题在低温和高温时都可能出现。低温时,模型过于确定,固守最高概率路径,可能回到之前生成的文本,造成循环。高温时,输出过于随机,随机选择的词可能碰巧回到之前状态,造成循环。解决方法通常需要仔细调整温度和 Top-K/Top-P,找到确定性和随机性的最佳平衡。
参考链接:
[1] https://github.com/08820048/-LLM-Prompt-Engineering-Google/blob/master/%E6%8F%90%E7%A4%BA%E5%B7%A5%E7%A8%8B(%E4%B8%AD%E6%96%87%E7%89%88).md
[2] 谷歌提示词工程白皮书