Python-pandas-DataFrame取值--.loc[]、.iloc[] 具体的操作及详细语义和语法说明
Python-pandas-DataFrame取值–.loc[]、.iloc[] 具体的操作及详细语义和语法说明
提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是pandas的使用语法。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:每个知识点,都是写出代码和运行结果且前后关联上的去分析和说明(能大量节约您的时间)。
所有文章都不会直接把代码放那里,让您自己去看去理解。我希望我的内容对您有用而努力~
python语法-pandas第三节-附 :本小节是 DataFrame全系列分享(使用.特点.说明.外部文件数据.取值.功能函数.统计函数)的 : 取值额外方法篇:.[] 、.loc[]、.iloc[]
详细的 DataFrame全系列:
DataFrame全系列分享(使用.特点.说明.外部文件数据.取值.功能函数.统计函数)
文章目录
- Python-pandas-DataFrame取值--.loc[]、.iloc[] 具体的操作及详细语义和语法说明
- 前言
- .[]取值
- .loc[]取值
- .iloc[]取值
- .loc[]和.iloc[]总结和切片
- 按条件来取值
- 总结
前言
在工作中,数据量都比较大/比较多。使用pandas读取外部文件,如:Excel、csv的数据时,是一个表格型的数据(有表头有列有行)正好pandas的DataFrame(表格结构)来存储。
然而,日常很多很多时候,并不是每次都把 全部的数据一口气都取出来 做 数据处理。
日常:仅仅需要某列的数据、某几列的数据。某一段(xxx~xxx)的多少行数据 来做处理或可视化。
总结:
在处理这类数据时,往往要根据需求先获取数据中的子集,如某些列、某些行、行列交叉的部分等。
快速整理说明:
df[]:快捷的整行整列选取
df.loc[]:按标签的行列交叉选取
df.iloc[]:按位置序号的行列交叉选取
准备案例变量数据:
此处没有使用外部数据,是手动填写了若干数据,方便大家复制测试
外部数据导入及其他常用方法(声明DataFrame,操作DataFrame等等)。可以查看文章开头 全系列文章。方便理解
import pandas as pd#准备数据
mydata = {#表格数据#列名:[数据]'id':[1,2,3,4,5,6],'name':['bangbangzhi','hello','python','java','pandas','hadoop'],'班级/部门':['行政部','帮帮志','销售部','研发部','售后部','部不部'],'number':[101,102,103,104,105,106],'日期':['2000年1月1日','2000年1月2日','2000年1月3日','2000年1月4日','2000年1月5日','2000年1月6日']
}myDf01 = pd.DataFrame(mydata)#生成DataFrame
print(myDf01)#瞅一眼#模拟了商家 班级 部门等等数据 列可以是姓名 年龄 性别 日期 编号等等等

概念说明:方便理解,比心~
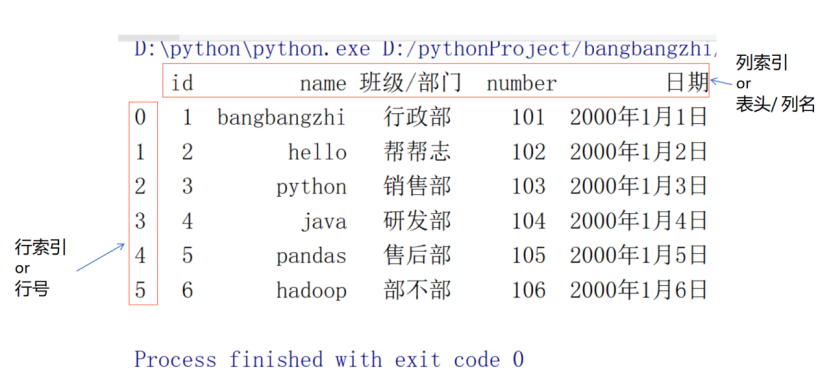
行索引,没有在代理里面指定,是自动生成的。从0开始
列索引 :为了我们在操作数据的时候方便取值/使用。列名一般自己定义(Excel、csv一般也自带表头)。但是,重要!!!
DataFrame给我们生成了一个隐藏的值,从0开始: 第一列 0 第二列 1 第三列 2 (可以直接用的,怕大家看晕 列的0~n。隐藏的~)
.[]取值
语法:
df.[] #用DataFrame数据类型的调用[]
df.[]:方括号内输入列索引/列名,则 选取的是列;而方括号内输入切片、条件选取的是行
df.[]:输入切片选取整行时,如果是按照位置序号的切片,左闭右开;按行标签的切片,左闭右闭。
#按列取出#df.[列名]
print(myDf01['id']) #取id的那一列 #这个没有截屏(不然图片太大)#df.[列名]
print(myDf01[['id','name','日期']]) #取id 和 name 和 日期 的那三列

#切片取出
print(myDf01[1:3])#取第2行(包含) 到 第4行(不包含)

#切片取出
#这步骤很重要 不然报错
df1 = myDf01.set_index("日期") #设置某列为整表的行索引index
print(df1['2000年1月2日':'2000年1月4日'])#取第2行(包含) 到 第4行(包含)

.loc[]取值
df.loc[行选择,列选择]。参数面向的是标签。
#df.loc[行选择,列选择]
#第一个参数是行 第二个参数是列
print(myDf01.loc[2,'name'])#python
print(myDf01.loc[3,'班级/部门'])#研发部
print("隔开一下")#多个数据取出#[[行],[列]]
#想取某几行的就填写几个行索引 想取某几列的就填写几个列索引,相互不影响
# 两行(具体哪两行) 三列(具体哪三列)
#可以去指定set_index 行索引
#直接用数据来取值 如:日期(2000年1月4日这行的某几列)来取值
print(myDf01.loc[[2,4],['name','班级/部门','number']])

.iloc[]取值
df.iloc[行位置序号,列位置序号]。参数面向的是位置序号。
#行从0开始数 2 第三行 列从0开始数 第二列
print(myDf01.iloc[2,1])#python
print(myDf01.iloc[3,2])#研发部
print("隔开一下")#取多个
#2,4 第三行和第5行 1,2,3 第二列 第三列 第四列
print(myDf01.iloc[[2,4],[1,2,3]])
没有偷懒,图是重新截屏的。故意写的这几个数字,就是为了取出和刚刚loc[]一模一样的内容。

.loc[]和.iloc[]总结和切片
df.loc[行选择,列选择]。参数面向的是标签。
df.iloc[行位置序号,列位置序号]。参数面向的是位置序号。
刚刚的案例 , 数据中间填写的 逗号。意味这几个都需要选,如:
print(myDf01.iloc[[2,4],[1,2,3]])
.loc[]和.iloc[]两个数据都可以填写 冒号 。意味切片(从某某位置 到 某某位置)
数据特别多,不可能每个每个都用逗号隔开,写一遍。 用切片
#loc 参数是标签
#很多很多种 不同的排列组合,取出各种各样的不同范围数据
print(myDf01.loc[[起始行:结束行],[起始列:结束列]])
#如
print(myDf01.loc[["2000年1月2日":"2000年1月5日"],["name":"number"]])
#2000年1月2日行开始 包括中间的 一直到 "2000年1月5日"行
#name列 开始 一直到 number列 自然中间包括了中间的列:班级/部门#iloc 参数是位置序号
#很多很多种 不同的排列组合,取出各种各样的不同范围数据
print(myDf01.iloc[[起始行位置:结束行位置],[起始列位置:结束列位置]])
#如
print(myDf01.iloc[[2:10],[3:5]])
按条件来取值
# df.[]的写法
#其他列不管, 只要number列里面 >102 <105 范围里面的,用& 两个条件同时满足
print(myDf01[(myDf01['number']>102) & (myDf01['number']<105)])
# # df.loc[]的写法
print(myDf01.loc[(myDf01['number']>102) & (myDf01['number']<105),:])
# # &与、|或、~非
print(myDf01.loc[(myDf01['number']>102) & ~(myDf01['number']>=105),:])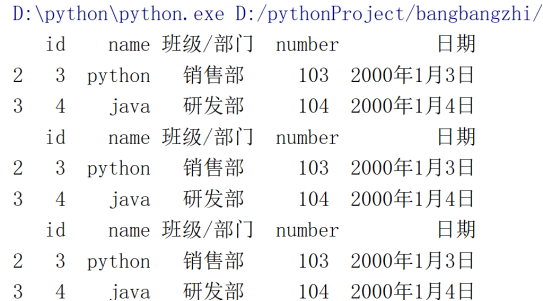
总结
(会陆续更新非常多的IT技术知识及泛IT的电商知识,可以点个关注,共同交流。ღ( ´・ᴗ・` )比心)
(也欢迎评论,提问。 我会依次回答~)