【Java ee初阶】多线程(4)
一、java是怎么做到可重入的
java中,通过synchronized进行加锁,指定一个()包含了一个锁对象。(锁对象本身是一个啥样的对象,这并不重要,重点关注锁对象是不是同一个对象)
后面搭配{}.进入遇到{就触发加锁操作 遇到 } 就触发解锁操作 防止解锁操作被遗忘
如果一个线程加锁,一个线程不加锁;一个线程针对locker1加锁,一个线程针对locker2加锁......
锁相当于都不会产生冲突,不会产生阻塞。
二、synchronized的特性
1.互斥
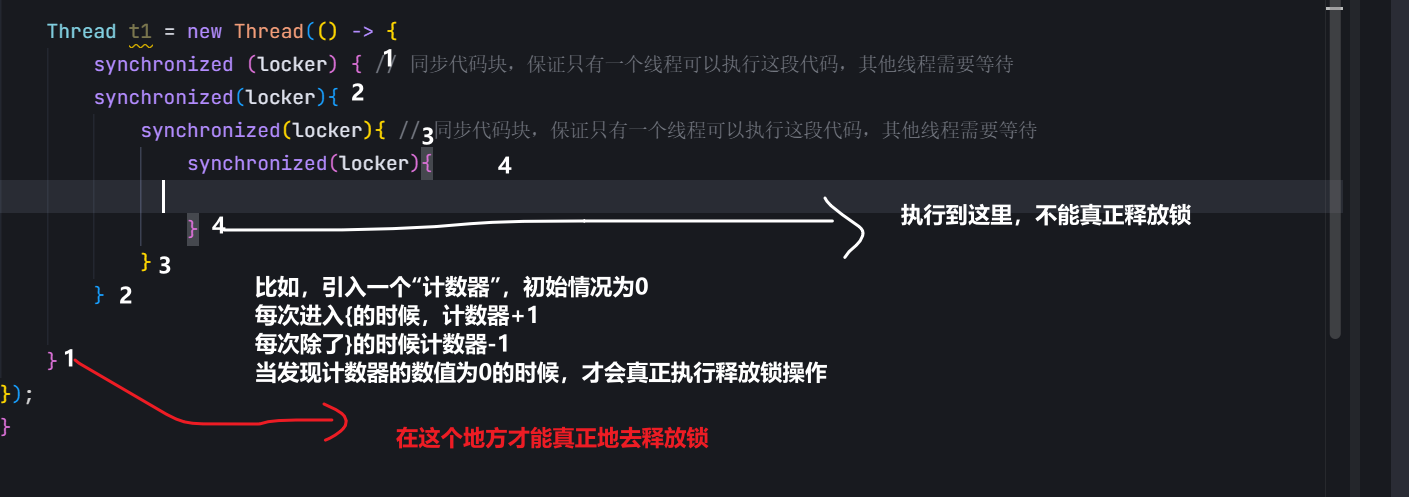
2.可重入 一个线程,一把锁,这个线程针对这个锁,连续加锁两次
synchronized(locker){
synchronized(locker)
}
locker已经是被加锁的状态了.尝试对一个已经上了锁进行加锁,就会产生阻塞
此处阻塞的接触,需要先释放第一次锁
要想释放第一次加锁,需要先加上第二次的锁
一个线程针对一把锁,连续加锁多次,不会触发死锁——>可重入
可重入这个现象是如何做到的呢?
让锁对象本身,记录下来拥有者是哪个线程(把线程id给保存下来了)
Object...Java的对象,除了又一个内存区域,保存程序员自定义的成员之外,还有一个隐藏区域,用来保存“对象头”。
对象头是JVM去维护的,保存了这个对象的一些其他运行信息,例如,加锁状态,哪个线程加了锁等等。
当我们已经给一个对象加锁了,后序再去针对这个对象加锁,那么就会先判定,当前尝试加锁的线程,是不是已经持有这个锁的线程。如果没有,才触发阻塞,如果有,不触发阻塞,直接放行。
二、死锁的情况
可重入锁,只能处理死锁的其中一种情况,没办法处理其他情况
1.一个线程一把锁,连续加锁两次
2.两个线程两把锁,每个线程先获得一把锁,再尝试获取对方的锁
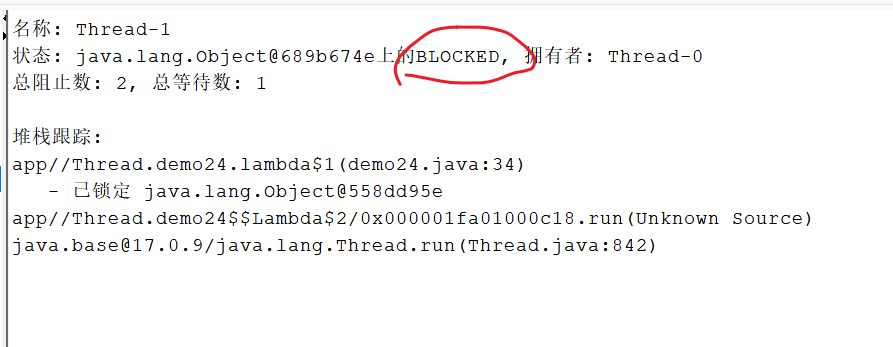
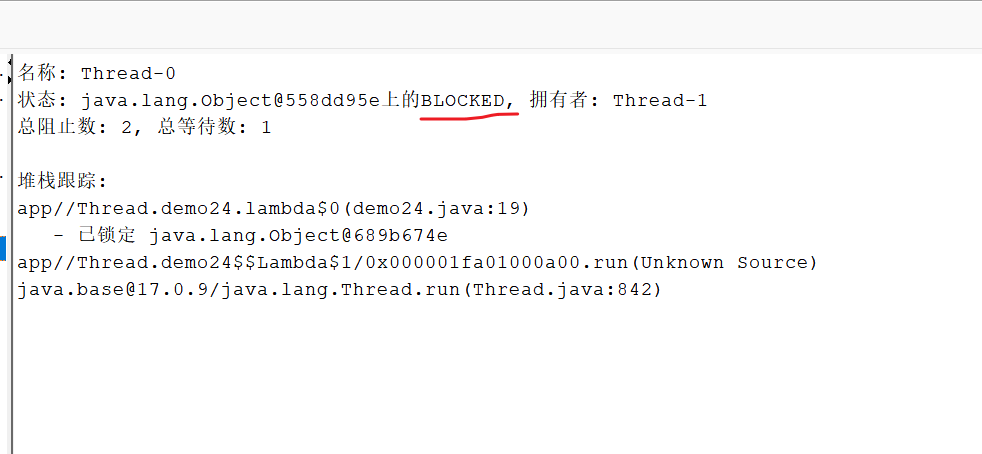
package Thread;public class demo24 {private static Object locker1 = new Object(); private static Object locker2 = new Object(); public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> { synchronized (locker1) { System.out.println("t1拿到了locker1");try {Thread.sleep(1000);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}synchronized (locker2) { System.out.println("t1拿到了locker2"); }}
});Thread t2 = new Thread(() -> {synchronized (locker2) { System.out.println("t2拿到了locker2");try {Thread.sleep(1000);} catch (InterruptedException e) {}synchronized (locker1) { System.out.println("t2拿到了locker1");} } });t1.start();t2.start();t1.join(); // 等待t1线程执行完毕,才能继续执行后面的代码t2.join(); // 等待t2线程执行完毕,才能继续执行后面的代码}}输出:

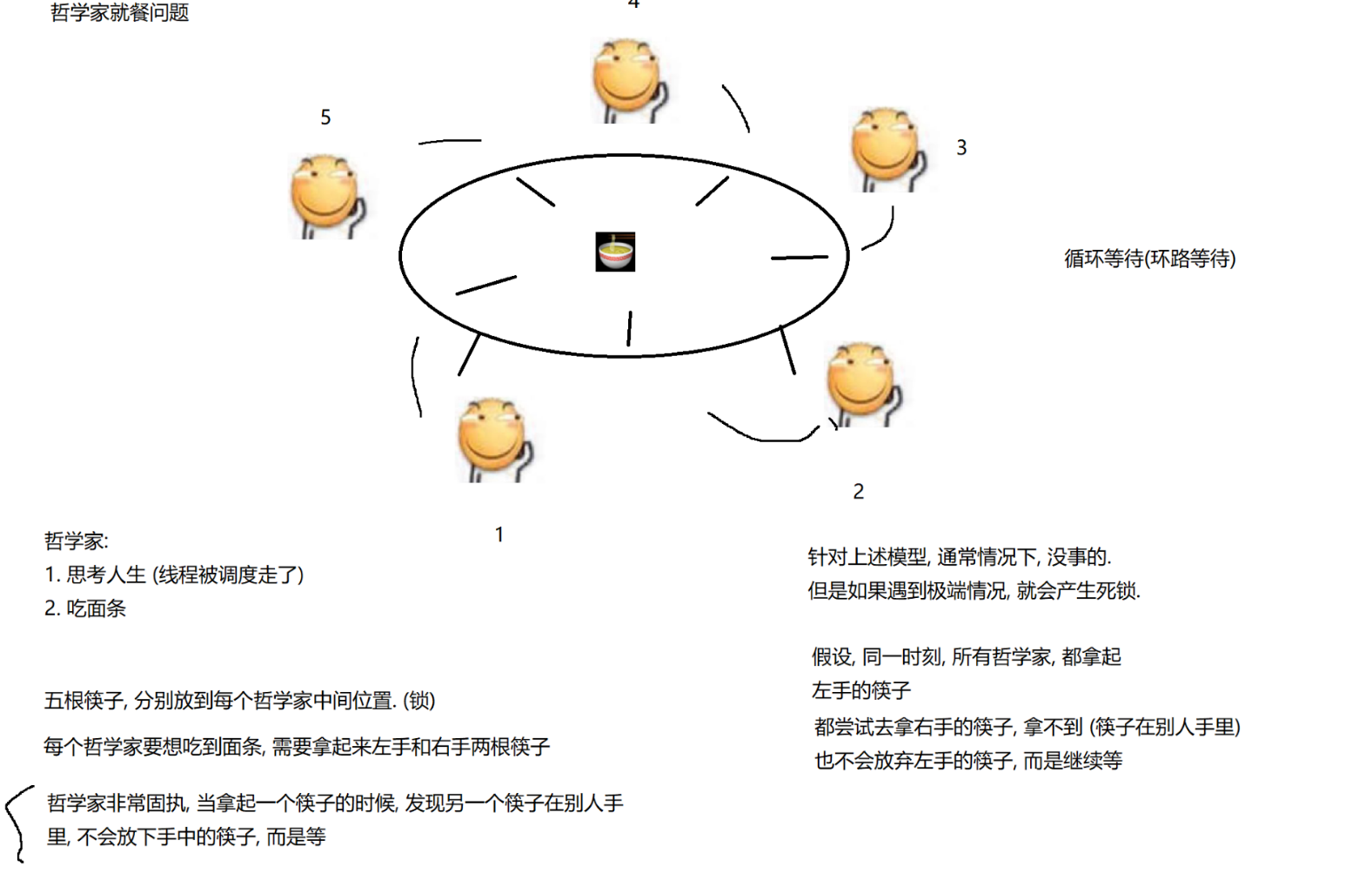
3.N个线程M把锁,也会构成死锁
“哲学家就餐问题”
三、如何避免死锁的出现
死锁这样的情况就是会客观发生的,线程一旦出现死锁,线程就卡死了,不动了,后序的逻辑就无法正常执行了,这是bug
如何避免代码中出现死锁呢?
关键在于理解死锁的“四个必要条件”
1.锁是互斥的——我们现在正在学习的synchronized是互斥的
2.锁不可被抢占——线程1拿到锁之后,线程2也想要这个锁,线程2会阻塞等待,而不是直接把锁抢过来
(对于synchronized来说,条件1和条件2 都是synchronized的基本特点)
3.请求和保持——拿到第一把锁的情况下,不去释放第一把锁,再尝试请求第二把锁(*确实有一定的场景是需要拿到锁1 的前提下再尝试去拿锁2)
4.循环等待——等待锁释放,等待的关系(顺序)构成了循环
(*也就是不要让等待关系构成循环 针对锁进行编号
;约定,加多个锁的时候,必须按照一定的顺序来加锁,比如按照编号从小到大的顺序)
上述两种是开发中比较实用的方法,还有一些其他的方案,也能解决死锁问题。
package Thread;public class demo24 {private static Object locker1 = new Object(); private static Object locker2 = new Object(); public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> { synchronized (locker1) { System.out.println("t1拿到了locker1");try {Thread.sleep(1000);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}synchronized (locker2) { System.out.println("t1拿到了locker2"); }
});Thread t2 = new Thread(() -> {synchronized (locker2) { System.out.println("t2拿到了locker2");try {Thread.sleep(1000);} catch (InterruptedException e) {}} //把第二把锁的加锁操作放到第一把锁的外面,先释放第一把锁,再获取第二把锁,这样就不会出现死锁的情况了。synchronized (locker1) { System.out.println("t2拿到了locker1");} });t1.start();t2.start();t1.join(); // 等待t1线程执行完毕,才能继续执行后面的代码t2.join(); // 等待t2线程执行完毕,才能继续执行后面的代码}}四、Java 标准库中的线程安全类
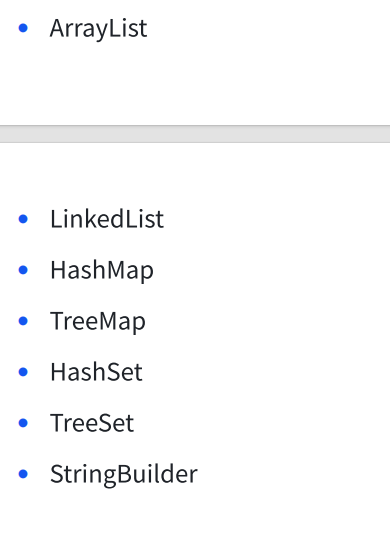
这些常用的集合类,大多是线程不安全的,把加锁策略交给程序员
但是还有⼀些是线程安全的. 使用了一些锁机制来进行控制

其中 Vector 和 HashTable 是Java早年间起,各位java大佬还不够成熟的时候引入的设定
现在的话这些设定已经被推翻,不建议再使用
有的虽然没有加锁, 但是不涉及 "修改", 仍然是线程安全的

*解决线程安全问题,我们使用加锁的方式。但是加锁是有代价的,加锁会非常明显地影响到程序的执行效率。加锁意味着可能触发锁竞争,一旦触发竞争就会产生阻塞。某个线程一旦因为加锁阻塞,能回来继续执行任务的时间就不确定了。写代码的时候需要考虑清楚某个地方是否要加锁。
五、内存可见性引起的线程安全问题
package Thread;public class Demo15 {public static int count = 0; // 共享变量,多个线程共同修改的变量,称为共享变量public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> { // 线程t1for (int i = 0; i < 5000; i++) { // 循环5000次count++; // 自增操作,相当于count = count + 1}});Thread t2 = new Thread(() -> { // 线程t2for (int i = 0; i < 5000; i++) { // 循环5000次count++; // 自增操作,相当于count = count + 1}});t1.start(); // 启动线程t1t2.start(); // 启动线程t2// 等待线程t1和线程t2执行完毕t1.join(); // 等待线程t1执行完毕t2.join(); // 等待线程t2执行完毕System.out.println(count); // 打印count的值,应该是10000,因为每个线程都自增了5000次}}
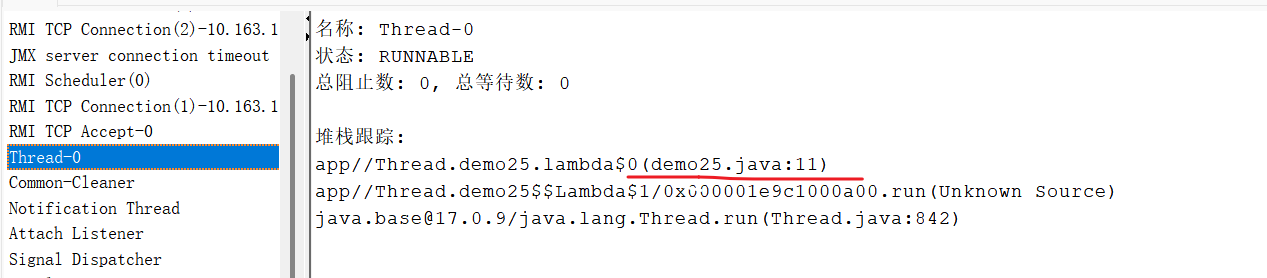
这个问题产生的原因,就是“内存可见性”
flag变量的修改,对于t1线程“不可见了”,t2修改了flag,但是t1看不见
编译器优化
主流编程语言,编译器的设计者(对于Java来说,谈到的编译器包括javac和jvm)考虑到一个问题:实际上写代码的程序员,水平是参差不齐的(具有一定的差距)
虽然有的程序员水平不高,写的代码效率比较低,编译器在编译执行的时候,分析理解现有代码的意图和效果,然后自动对这个代码进行调整和优化,在确保程序执行逻辑不变的前提下,提高程序的效率。
编译器优化的效果是很明显,但是大前提是“程序的逻辑不变”
大多数情况下,编译器优化,都可以做到“逻辑不变的前提”
但是在有些特定场景下,编译器优化可能出现“误判”,导致逻辑发生改变。
“多线程代码”
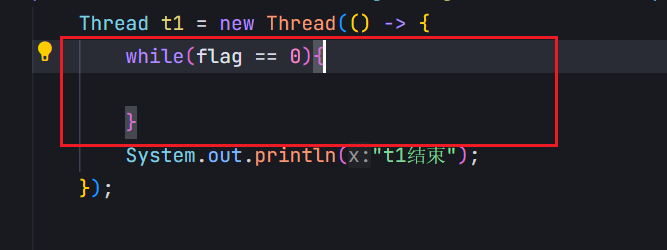
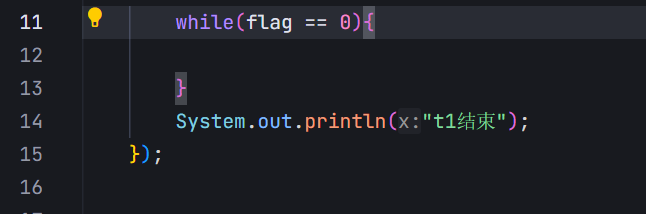
对于这个程序来说,编译器看到的效果是:有一个变量flag,会快速地,反复地读取整个内存的值(反复执行load\cmp\load\cmp);同时,反复执行的过程中,每次拿到的flag的值还都是一样的,上述的load操作相比cmp,耗时会多很多,读取内存,比读取寄存器,效率会慢很多(几百倍,几千倍)
既然load读取的值都是一样的,而且load开销这么多,于是编译器直接把从内存读取flag这个操作给优化掉了。上述操作只是前几次读内存,后面发现一样,就干脆从读好的寄存器中直接获取这个flag的值,此时,循环的侠侣就大幅度地提升了。
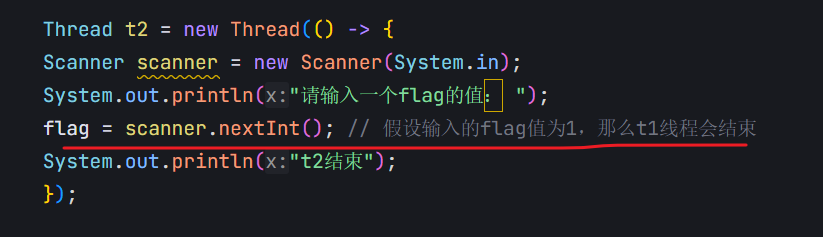
编译器不确定这里的flag修改代码到底能不能执行,以及啥时候执行。
上述内存可见性问题,是编译器优化机制,自身出现的bug。
六、volatile关键字
通过这个关键字,提醒编译器,某个变量是“易变”的,此时就不要针对这个易变的变量进行上述优化。
给变量添加了volatile关键字,编译器在看到volatile的时候,就会提醒JVM运行的时候不进行上述的优化。
在读写volatile变量的指令前后添加“内存屏障相关的指令”
JMM Java Memory Model
Java的内存模型
首先一个Java进程,会有一个“主内存”存储空间,每个Java线程又会有自己的“工作内存”存储空间
形如上述的代码,t1进行flag变量的判定时,就会把flag的值从主内存,先读取到工作内存,再用工作内存中的值进行判定。同时,t2对flag进行修改,修改的则是主内存的值,主内存的值的修改不会影响到t1的工作内存。
上述解释,出自于Java的官方文档
main memory(主内存)就是内存
work memory (工作内存)相当于是打了个比方,本质上这一块区域并不是内存,而是CPU的寄存器和CPU的缓存构成的统称
Java自身是希望做成“跨平台”,Java用户不需要了解系统底层和硬件差异。Java的设计者是不希望用户了解这些底层细节的。另一方面,不同的CPU底层结构也不一定相同。
抛开Java上下文不谈,只关注操作系统和硬件,没有上面“主内存”“工作内存”的说法的。
存储数据,不只是有内存,还有外存(硬盘),还有cpu寄存器,cpu上还有缓存。
现代CPU都引入了缓存,CPU的缓存空间比寄存器要大,速度要比寄存器要慢,但是比起内存还是要快。
CPU的寄存器和缓存,就统称为work memory
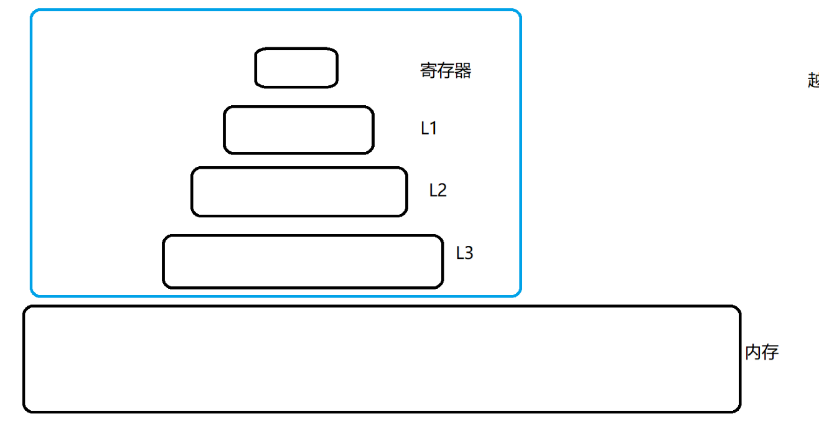
越往上,速度就越快,空间就越小,成本就越高。
编译器优化,就是把本来要从内存中读取的值,优化成从寄存器中读取。
可能是优化成从寄存器上读取,也可能是优化成从L1缓存上读取,也可能是优化成从L2缓存上读取,也可能是优化成从L3缓存上读取……(都没有从内存上重新读取,因此读不到最新的修改之后的数值)
编译器优化,并非是100%触发,根据不同的代码结构,可能产生出不同的优化效果(有优化/无优化/优化方式)
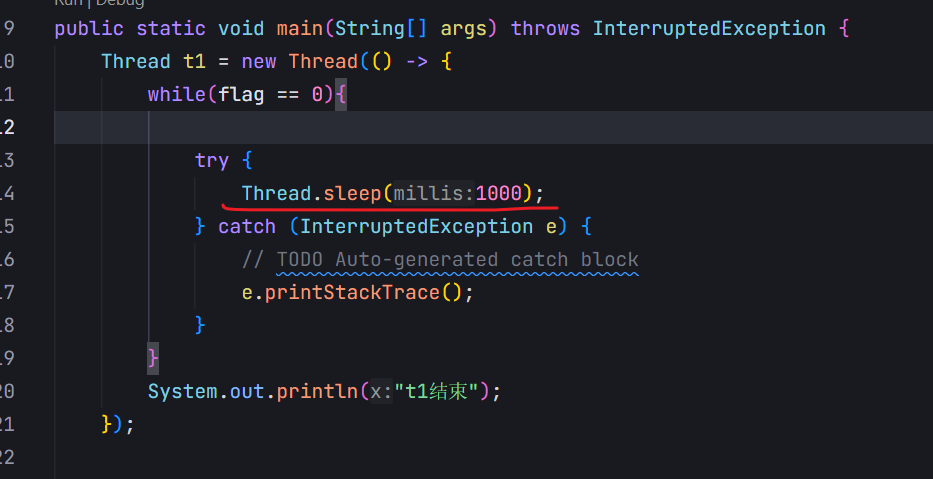
此处虽然没有写volatile,但是加了sleep也会使得上述程序不在优化。
因为:
1.循环速度大幅度降低了
2.有了sleep一次循环的瓶颈,就不是load,此时再优化load,就没有什么用了。
3.sleep本身会触发线程调度,调度过程触发上下文切换。
volatile这个关键字,能够解决内存可见性引起的线程安全问题,但是不具备原子性这样的特点。
synchronized和volatile是两个不同的维度,前者是两个线程都修改,volatile是一个线程读,另一个线程修改。
六、wait/notify
这两个关键字是用来协调线程之间的执行顺序的
两个线程在运行的时候,都是希望持续运行下去的(不涉及结束)。但是两个线程中的某些环节,我们希望能够有一定的先后顺序。
*线程执行本身是随即调度的(顺序不确定),join控制线程的结束顺序
例如线程1 ,线程2
希望线程1 先执行完某个逻辑之后,再让线程2去执行。
此时就可以让线程2通过wait主动进行阻塞,让线程1先参与调度,等线程1把对应的逻辑执行完了,就可以通过notify唤醒线程2.
另外,wait / notify 也能解决“线程饿死”的问题。
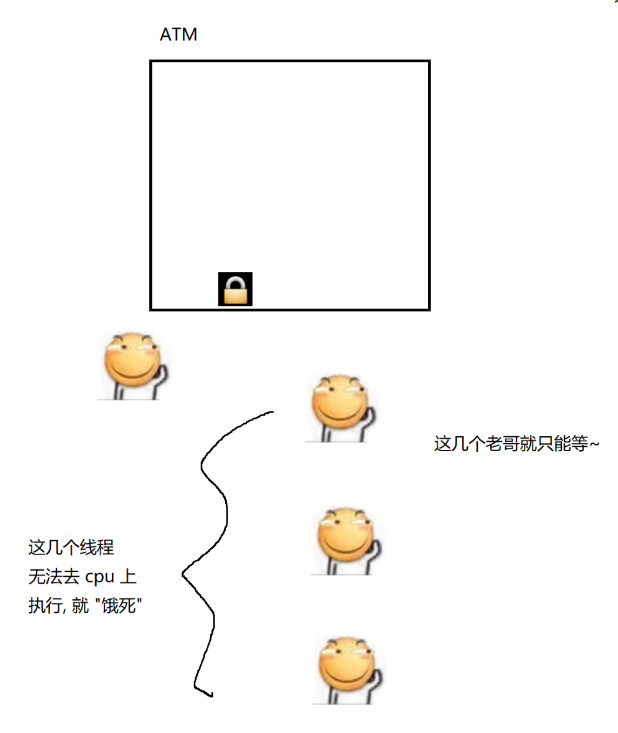
当线程1释放锁之后,其他线程就要竞争这个锁(线程1 自身也可以重复参与到竞争中)
由于其他线程还要等待操作系统唤醒,此时线程1就是在cpu上执行,就有很大的可能性,“捷足先登”
不像死锁,死锁发生,就僵硬住,除非程序启动,否则就会一直僵持。
线程饿死,没那么严重,在线程1反复获取几次锁之后,其他线程也是有机会拿到锁的,但是其他线程拿到锁的时间会延长,降低了程序的效率。