Linux系统之----程序地址空间
1.程序地址空间
在我们之间的学习中,已经知道空间布局大致是这样的:
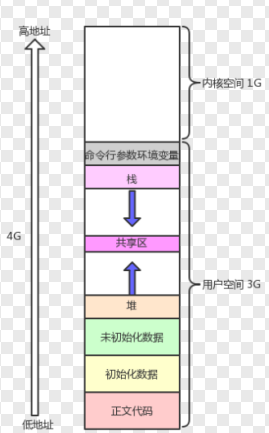
这里说明一点:以后我们在Linux的学习中,高地址就是在高处,低地址就是在低处,就是那个反过来画的我们不提了!
那么我们怎么证明就是这样的空间结构呢?不妨看以下代码!
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>int g_unval;
int g_val = 100;int main(int argc, char *argv[], char *env[])
{const char *str = "helloworld";printf("code addr: %p\n", main);printf("init global addr: %p\n", &g_val);printf("uninit global addr: %p\n", &g_unval);static int test = 10;char *heap_mem = (char*)malloc(10);char *heap_mem1 = (char*)malloc(10);char *heap_mem2 = (char*)malloc(10);char *heap_mem3 = (char*)malloc(10);printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1)printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1)printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1)printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1)printf("test addr: %p\n", &test); //heap_mem(0), &heap_mem(1)printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1)printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1)printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1)printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1)printf("read only string addr: %p\n", str);for(int i = 0 ;i < argc; i++){printf("argv[%d]: %p\n", i, argv[i]);}for(int i = 0; env[i]; i++){printf("env[%d]: %p\n", i, env[i]);}return 0;
}
这里我们调用了栈区堆区上的等等一系列变量,我们可以通过观察其地址,判断其位置!
运行一下:
code addr: 0x561cdc8ad189
init global addr: 0x561cdc8b0010
uninit global addr: 0x561cdc8b001c
heap addr: 0x561cf98ed6b0
heap addr: 0x561cf98ed6d0
heap addr: 0x561cf98ed6f0
heap addr: 0x561cf98ed710
test addr: 0x561cdc8b0014
stack addr: 0x7ffe4c39d7c0
stack addr: 0x7ffe4c39d7c8
stack addr: 0x7ffe4c39d7d0
stack addr: 0x7ffe4c39d7d8
read only string addr: 0x561cdc8ae004
argv[0]: 0x7ffe4c39e711
env[0]: 0x7ffe4c39e719
env[1]: 0x7ffe4c39e729
env[2]: 0x7ffe4c39e737
env[3]: 0x7ffe4c39e74d
env[4]: 0x7ffe4c39e768
env[5]: 0x7ffe4c39e774
env[6]: 0x7ffe4c39e789
env[7]: 0x7ffe4c39e798
env[8]: 0x7ffe4c39e7a7
env[9]: 0x7ffe4c39e7b8
env[10]: 0x7ffe4c39eda7
env[11]: 0x7ffe4c39edcf
env[12]: 0x7ffe4c39edfd
env[13]: 0x7ffe4c39ee1f
env[14]: 0x7ffe4c39ee36
env[15]: 0x7ffe4c39ee41
env[16]: 0x7ffe4c39ee61
env[17]: 0x7ffe4c39ee6a
env[18]: 0x7ffe4c39ee81
env[19]: 0x7ffe4c39ee89
env[20]: 0x7ffe4c39ee9f
env[21]: 0x7ffe4c39eebe
env[22]: 0x7ffe4c39eedf
env[23]: 0x7ffe4c39ef20
env[24]: 0x7ffe4c39ef88
env[25]: 0x7ffe4c39efbe
env[26]: 0x7ffe4c39efd1
env[27]: 0x7ffe4c39efe6
我们把有用的截出来:
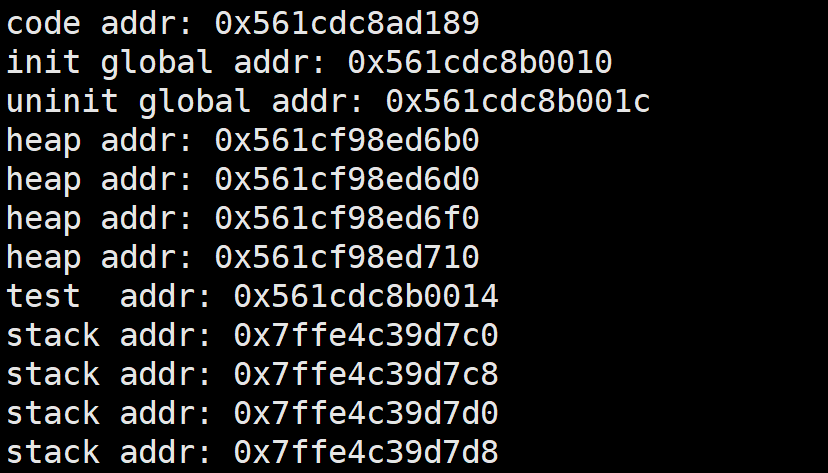
首先,我们发现堆区(heap)整体的地址低,栈区(stack)地址高,其次,在堆区和栈区之间并不是连续的,中间留有一块空白,这个地方便是共享区,恰如图中所示,之后我们仔细观察,栈区是向下发展的,堆区是向上生长的,这与图片是符合的。
这里我们还要明确一点:堆栈和栈一样指的都是栈,堆指的是堆
注意,此种方法只适合在Linux上操作,在Windows上可能会导致出现各种结果,因为Windows上谁都能用,为了保护安全,可能运行的结果不一样。
2.虚拟地址空间
2.1 虚拟地址空间的定义
虚拟地址空间 是操作系统为每个进程创建的一个抽象内存空间。
这个空间中的地址称为 虚拟地址,它与实际的物理内存地址不同。
虚拟地址空间的大小取决于操作系统的位数:
32位系统:虚拟地址范围是 0x00000000 到 0xFFFFFFFF(4GB)。
64位系统:虚拟地址范围是 0x0000000000000000 到 0xFFFFFFFFFFFFFFFF(16EB)。
说明:进程在访问内存的时候,要先进行虚拟地址到物理地址的映射,找到物理内存,然后才可以访问数据,还要就是我们之前C/C++时看到的地址都是虚拟地址!
那么物理地址和虚拟地址是如何进行映射的呢?这里就要提出下一个概念了,页表
2.2页表
2.2.1 概念
页表是操作系统用于实现虚拟地址到物理地址映射的数据结构。它在虚拟内存管理中起到核心作用,使得进程能够通过虚拟地址访问物理内存。每个虚拟地址被分为页号和页内偏移。页号用于查找页表,从而找到对应的物理页号,进而结合页内偏移得到物理地址。
2.2.2 页表结构与内容
页表由多个页表项组成,每个页表项对应一个虚拟页。页表项包含以下关键信息:
物理页号:表示虚拟页在物理内存中的对应位置。
访问权限:如只读、可写、可执行等,确保内存访问的安全性。这也就是为什么我们在C语言中定义一个常量字符串就不能修改,否则就会报错的原因。
char* str="hello world";
str='C'; //程序运行时会崩掉
有效位:标识该页表项是否有效。若无效,表示该虚拟页当前不在内存中,可能在磁盘上,此时访问该页会触发缺页异常,由操作系统处理。
2.2.3 MMU
MMU 是硬件组件,负责将虚拟地址转换为物理地址。
当进程访问虚拟地址时,MMU 查询页表完成映射。
如果页表中没有对应的映射(缺页),MMU 会触发缺页异常,操作系统会处理这个异常,将页面从磁盘加载到内存。
3.父子进程的虚拟地址空间
3.1 代码示例
#include <stdio.h>
#include <unistd.h>int gval = 100;int main() {pid_t id = fork();if (id == 0) {// 子进程while (1) {printf("我是子进程, pid: %d, ppid: %d, gval: %d, &gval: %p\n", getpid(), getppid(), gval, &gval);sleep(1);gval++;}} else {// 父进程while (1) {printf("我是父进程, pid: %d, ppid: %d, gval: %d, &gval: %p\n", getpid(), getppid(), gval, &gval);sleep(1);}}
}3.1.1 父子进程的独立性
当父进程调用 fork() 创建子进程时,子进程会复制父进程的虚拟地址空间。
父子进程的虚拟地址空间是独立的,虚拟地址相同但映射到不同的物理内存。
图中的代码验证了这一点
父进程的 gval: 100, &gval: 0x601054
子进程的 gval: 101, &gval: 0x601054子进程修改 gval 的值后,父进程的值保持不变。
3.1.2 写时拷贝
子进程创建时,父子进程共享相同的物理页面(节省内存)。
当任一进程首次写入某页面时,操作系统会为该进程分配一个新的物理页面,并复制原内容,确保修改互不干扰。
这解释了为什么父子进程在虚拟地址相同的情况下,修改不会互相影响。
说人话就是当子进程想对父进程的共享内容做修改时,操作系统会另外开辟一块空间,并进行内容拷贝,最后再更改页表的映射关系。而这一切都是由操作系统自动去完成的,我们用户不知道!!
3.1.3. 结果解释
子进程创建时,父子进程共享相同的物理页面(写时拷贝机制)。
当子进程首次写入 gval 时,操作系统为子进程分配新的物理页面,复制原内容。
因此,父子进程的虚拟地址相同,但物理内存独立。
结论:
命令行参数和环境变量属于父进程的地址空间内的数据资源,和代码区数据区一样,子进程会继承父进程的地址空间,所以子进程也能看到命令行参数和环境变量!!
4.空间划分
4.1 进程之间是有隔离性的
这里可以打个比喻,假设在大洋彼岸有一个大富翁,他有$10个亿美金,同时还有很多私生子,但是这些私生子都不知道彼此的存在,他对每个私生子都说,百年以后,这10个亿都是你的,给每个人都画了大饼,让他们努力工作,但是随着私生子的增多,他可能就会记错或者记乱了这些大饼,这样是不行的,于是他便拿了一个小本本,把自己画过的饼给纪录了下来,那么同理,我们的虚拟地址空间,就是OS给进程画的饼,本质是一个内核数据结构!
4.2 如何理解空间划分呢?
这里我们还是举个例子,大家小的时候应该都和异性做过同桌吧?小时候特别流行一个叫三八线的东西,桌子上画一条线谁也不能过界,过界了就要被肘击。那么这条三八线的本质就是区域划分啊!!而划分到区域内部的内容,都属于你,由此我们类比操作系统,我们的内存在定义时有一个结构体,里面包含了两个变量,start和end,那么,只要是在这个结构体内部的所有内容,是不是都属于这个结构体呢?因此,区域划分的本质其实只要有线性空间的一段开始地址和结束地址来表明一段范围即可!
5.为什么要有虚拟地址空间
1. 内存隔离
虚拟地址空间为每个进程提供了独立的内存空间,这意味着进程间的内存是隔离的。一个进程的内存修改不会影响到其他进程,这增加了系统的稳定性和安全性。
2. 内存保护
通过虚拟地址空间,操作系统可以为不同的内存区域设置不同的访问权限(如可读、可写、可执行)。这有助于防止恶意或错误的程序访问它们不应该访问的内存区域,从而保护系统免受攻击和崩溃。从另一个角度来看,正因为有了虚拟地址,我们要找其物理地址,访问其内存的时候就必须经过转换,而在这个转换过程中,会进行安全审核,变相的保证了物理内存的安全,维护进程独立性特性。
3. 简化内存管理
虚拟地址空间允许操作系统管理内存的方式更加灵活。例如,操作系统可以使用分页和分段技术来优化内存的使用,即使物理内存不是连续的,也可以通过虚拟地址空间为进程提供一个连续的地址空间。
4. 将无序变为有序
我们实际的物理内存可能是杂乱无章的,可能这个是堆区的,但是跑上面去了,那个是栈区的,有跑下面去了,而有了虚拟地址这个概念,我们可以通过页表,将他们排成有序,因为页表是K=V的形式,所以排完之后页表左边是杂乱无章的,右边是有序的
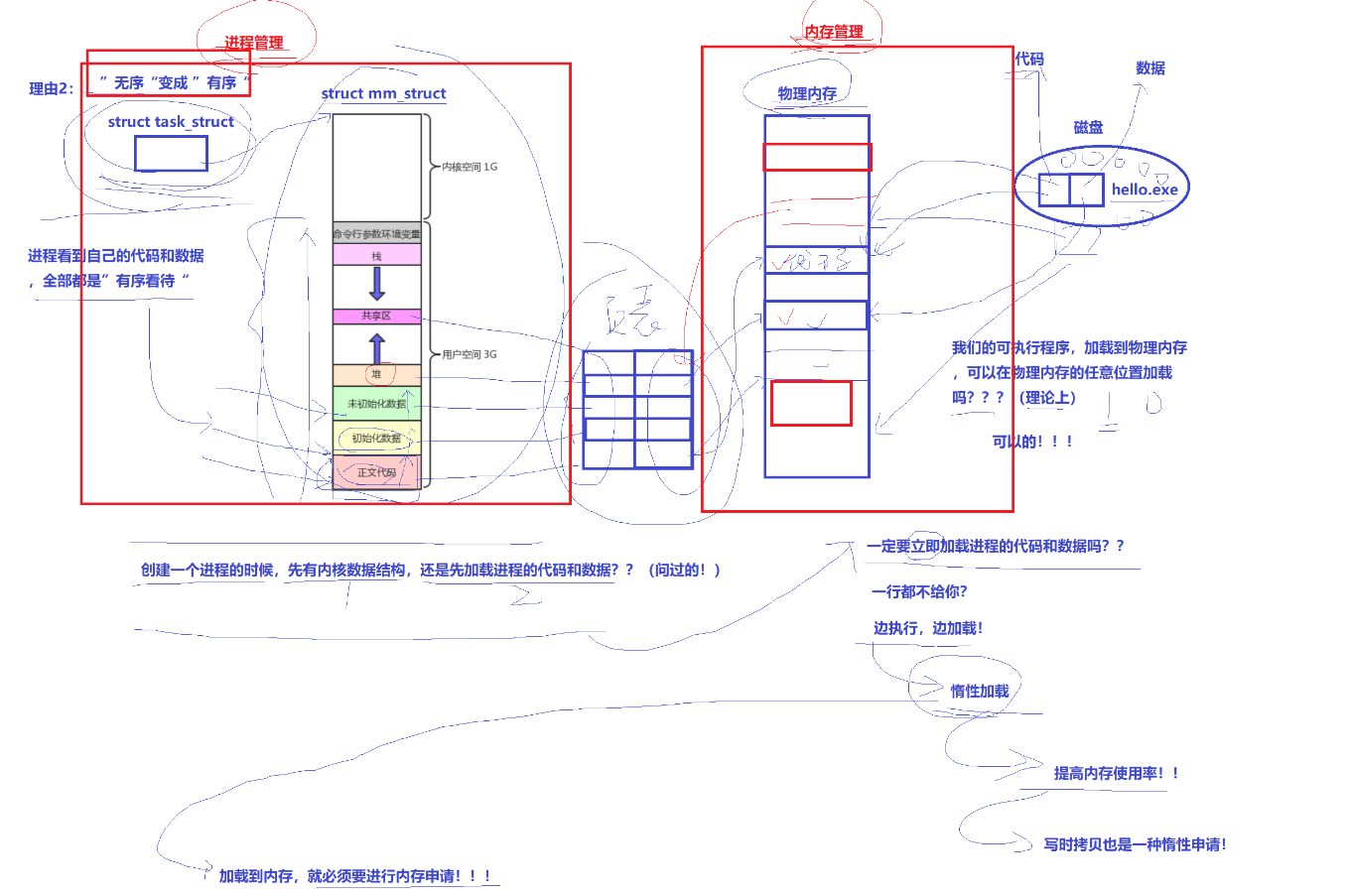
这里再补充说明一点:创建一个进程的时候,是先又内核数据结构,再去加载进程的代码和数据,但是又不是说要立即加载出所有的进程代码和数据,他是边执行边加载的,也就是说,他是惰性加载的,这样做也是为了提高内存的使用率,防止有占着茅坑不拉屎的情况出现。
补充:什么是惰性加载?
惰性加载(Lazy Loading)是一种优化策略,它推迟对象的初始化、数据的加载或资源的获取,直到它们真正被需要时才进行。这种技术可以减少初始页面加载时的资源请求次数,从而加快页面的打开速度在计算机编程中,惰性加载技术在优化应用性能和资源管理中的应用与实现尤为重要。它可以减少初始开销、动态扩展和资源复用,从而显著减少初次访问时的数据传输量和处理时间。此外,惰性加载也用于数据库访问中,通过延迟加载数据,可以减少内存占用,提高程序效率。然而,实现惰性加载需要对程序进行较多的控制,可能会使代码变得更加复杂,且可能会影响程序响应时间,换句话说,写时拷贝也是一种惰性申请!原因如下:
1.进程创建:当通过fork()系统调用创建子进程时,操作系统通常会使用写时拷贝技术。最初,父子进程共享相同的物理内存页,只有当其中一个进程试图修改共享页时,才会创建该页的副本。这意味着在没有写操作之前,不会消耗额外的内存资源来创建物理副本。
2.文件共享:在文件系统中,写时拷贝可以用于实现文件的共享和修改。当多个进程打开同一个文件进行读取时,它们共享文件的相同视图。只有当某个进程需要写入文件时,才会创建文件内容的副本,以便该进程可以独立地修改副本,而不会影响其他进程。
3.内存分配:在内存管理中,写时拷贝可以用于延迟内存分配。例如,当为一个数据结构分配内存时,可能只会分配实际需要的内存量,而不是预分配大量内存。只有在数据结构需要更多内存时,才会进行扩展。也就是说我们malloc或者new的时候,操作系统可能不会立即在物理内存中分配相应的空间。相反,它可能只在虚拟地址空间中标记出这块区域,而实际的物理内存分配则推迟到进程首次访问这块内存时才进行。换句话说,就是给你先占个位置,等你人来了在给你用,你人不来这块位置不是你的!
由于分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。具体来说就是操作系统捕获到这个中断后,会触发一个内存分配请求,将所需的物理内存分配给进程,并更新页表以反映虚拟地址到物理地址的新映射。 但是上述过程,对于我们人来说是完全透明的,也就是说你不知道,也不需要知道。
那么,什么是缺页中断呢?
补充:缺页中断
缺页中断是操作系统内存管理中的一种机制,当程序试图访问一个尚未分配物理内存空间的虚拟地址时,操作系统会检测到这个情况,并触发一个异常,即缺页中断。在C/C++中,使用malloc或new申请内存时,通常涉及惰性空间开辟。
5.对进程管理和内存管理进行解耦合
进程管理和内存管理的解耦合是指操作系统中进程控制信息和内存管理信息的分离,使得这两个模块可以独立操作而互不影响。这种设计提高了系统的灵活性和稳定性,简化了系统设计,并使得操作系统可以更灵活地管理进程和内存。每个内存管理器负责管理该进程的虚拟地址空间和物理内存,这样可以实现进程之间的独立性和隔离性。
通过页表这个结构,很好地将进程管理和内存管理解耦合,互不影响,我们进程所看到的只有虚拟地址,并不在乎物理地址如何如何,而我们的内存也不需要在乎有多少进程,进程的作用是什么,而是只在需要的时候开辟和回收空间就可以了,这样我们在进程出现问题的时候不会影响到内存管理,很好地阻断了可能出现的一系列崩盘的问题。
这种解耦合的设计使得进程管理和内存管理可以独立地发展和优化,提高了操作系统的稳定性和效率。