Improving Deep Learning For Airbnb Search
解决问题
问题1:
解决推荐酒店与用户实际预定酒店价格存在偏差问题,实际预定比推荐要更便宜:
所以问题为是否更低价格的list更倾向于用户偏好,应该被优先推荐?
1. 该文通过数据分析与模型演进,将模型改造为item score与价格成单调递减的关系,发现预订量下降。发现价格与其他特征存在交互作用,不能单纯改造为优先推荐低价item。而随着数据分析的深入,对地区进行分桶,发现价格与质量的权衡机制过度适配预订量占主导的热门地区,而将这些权衡逻辑泛化到长尾查询时效果欠佳,模型未能适应地域特性。由于该网络采用成对损失函数进行训练,那些在配对房源间存在差异的特征对模型影响最大;所以为了强化查询特征对排序决策的影响,系统可以更灵活地适应不同地域市场的价格敏感度与消费预期。构建了双塔模型(item塔+用户塔)来建模。有效的提升了总体收益。
问题2:
冷启动问题:新item得不到有效推荐:若仅优化短期预订量,排名策略会偏向已积累历史数据的成熟房源;但从平台长期生态健康出发,必须付出一定成本探索新上线房源。而如果通过冷启动方法来强制rerank的话,会存在一些问题:
-
相关性悖论:强制提升可能导致与用户搜索意图无关的新房源混入前排结果,损害用户体验;
-
动态校准困境:提升幅度需随房源生命周期动态调整,过早衰减会削弱冷启动效果,过晚则造成资源浪费;
-
个性化冲突:全局统一的提升策略无法适配不同用户对新房源的接受度差异,可能干扰个性化排序逻辑。
所以为了防止用户体验下降并为了提升长期增益体验,本文设计了一种预测器,基于旧item得到有效推荐主要来源于交互特征的假设(并通过指标验证)。来对新item与用户交互相关特征进行预测,从而填充冷启动item交互特征,使得新item得到有效推荐。使得整体预订量增长+0.38%,印证了用户体验的全域提升。
方法演进
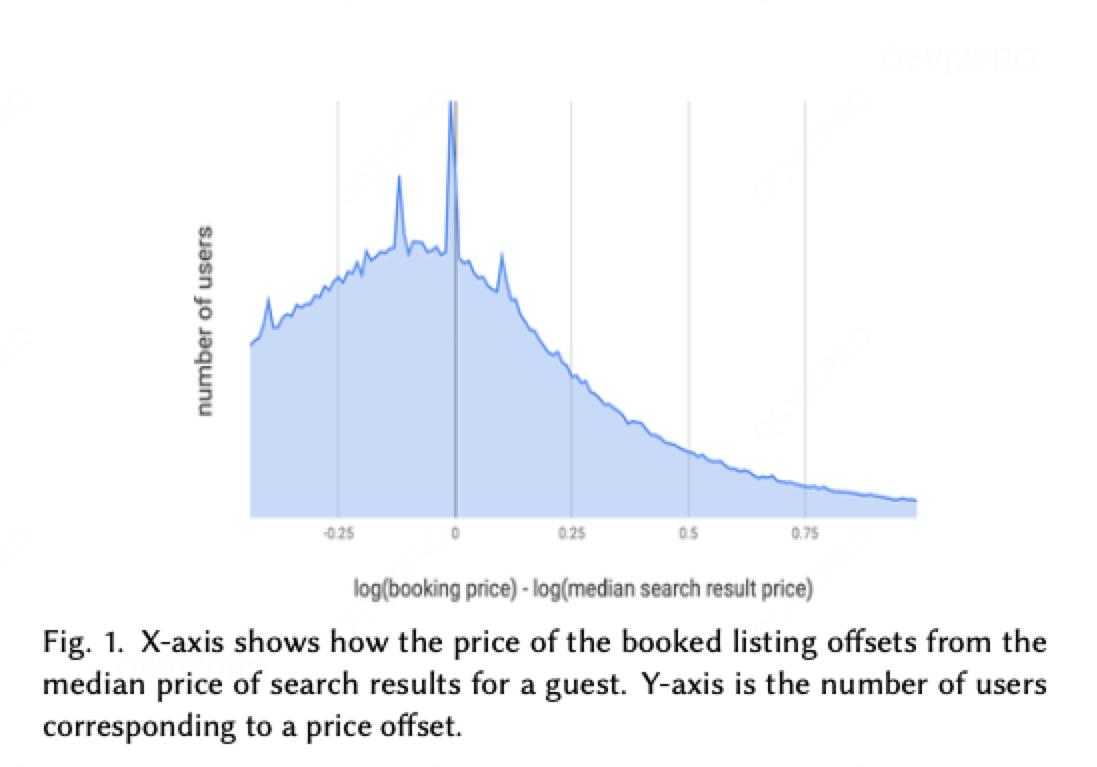
如图,价格偏差分布(预定-推荐)左偏,而期望为正太分布。
方法1:
为了保证模型的可解释性,将价格特征单独拿出来:
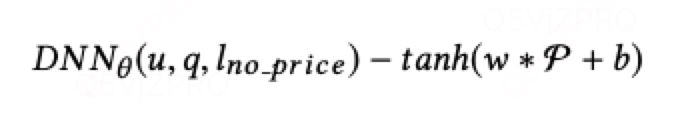
其中:
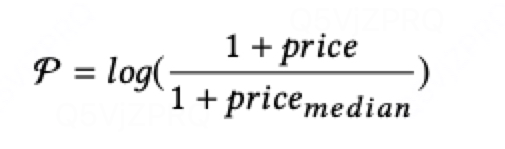
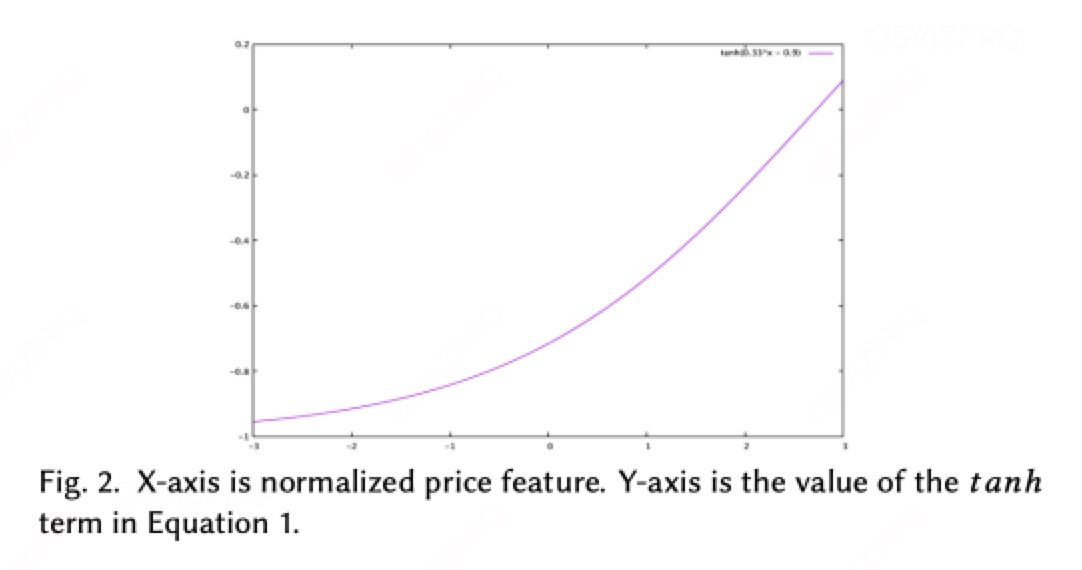
这样随着价格上升,dnn输出score会单调递减;
实验结果:搜索的平均价格下降5.7%,但是预定量也降低了1.5%。实验结果表明价格与其他特征是有交互关系的,简单从模型中溢出会导致under-fitting。
方法2:
拆分为两个部分:
一个部分将作为输入(-P与价格是单调递减的关系),对输入进行
计算(保证单调递减)。hidden_layers也使用tanh函数保证单调递减。在第二个hidden layer使用
![]() 。
。
其中一个部分为价格无关特征,也没有单调递减约束允许特征之间进行交互;
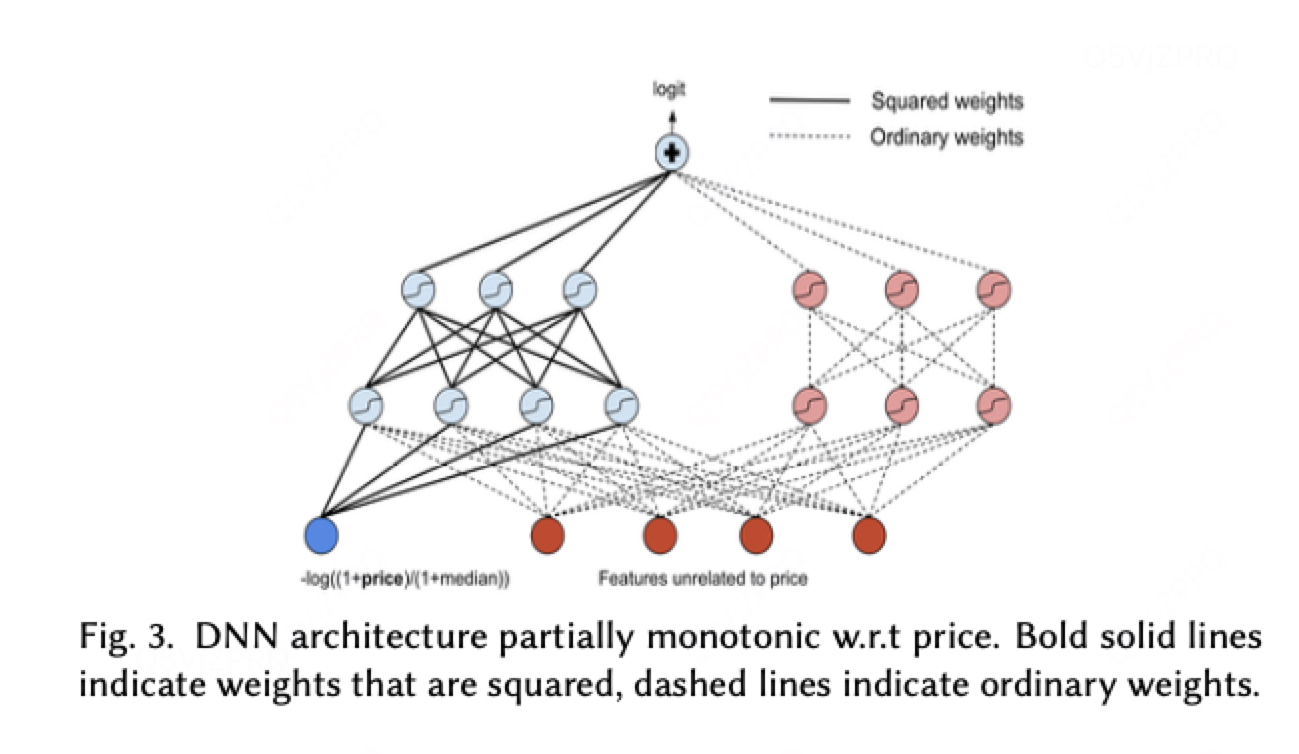
实验结果预定量也降低了1.6%。这种结构的失败表明根据价格单调递减的约束过于严格。
方法3:Soft Monotonicity
不使用单调递减的限制,而是使用一个soft hint来提示cheaper is better。除了正负样本的label之外(预定or未预定),增加了另外一个label,标注pair样本中哪个是更便宜的。实验结果3.3%的价格均值下降,同时0.67%的预订量下降。

方法4: Putting Some ICE
降价实验带来的灾难让我们陷入了一种矛盾的状态:搜索结果中的挂牌价格似乎高于客人的偏好,但降价让客人不高兴。为了了解新模型的不足之处,有必要比较基线模型如何利用价格特征,但这被完全连接的DNN缺乏可解释性所掩盖。
如前所述,部分依赖图等概念没有用,因为它们依赖于给定特征对模型的影响独立于其他特征的假设。在DNN的情况下,这根本不是真的。试图绘制价格的部分依赖性产生了平缓的直线,这表明DNN对价格有一些温和的线性依赖,这与我们所知道的一切相矛盾。
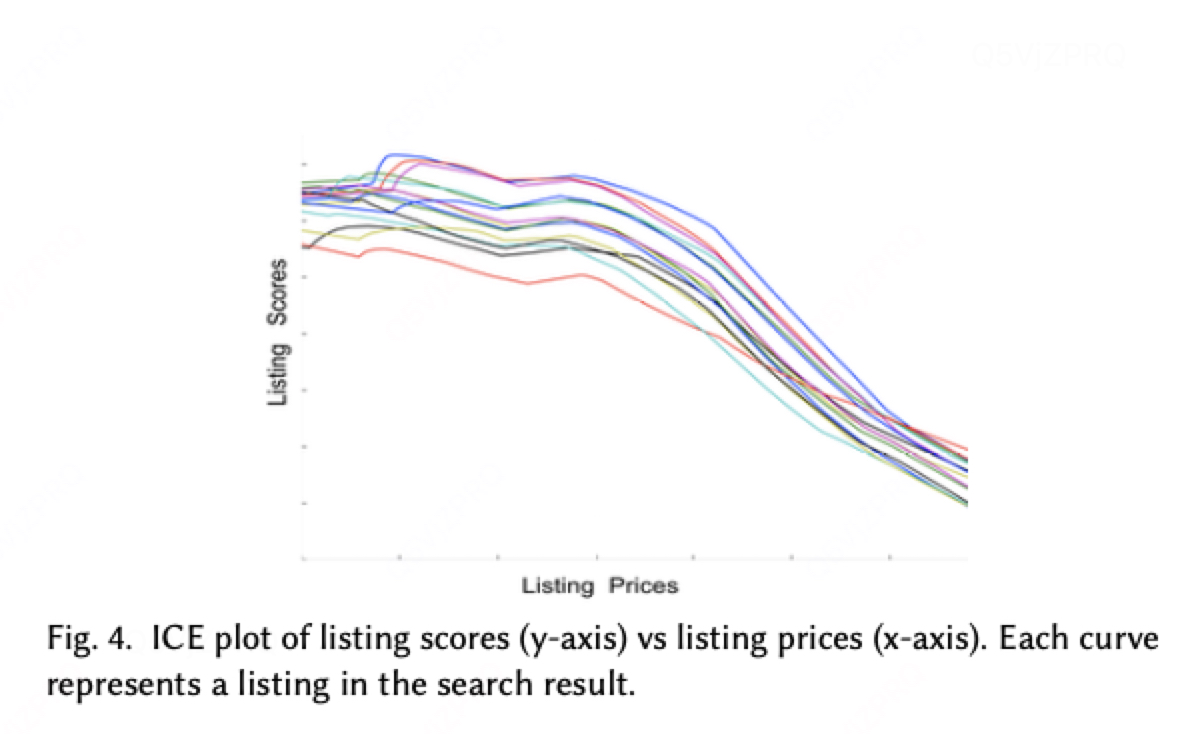
为了取得进展,我们缩小了DNN可解释性的问题。我们没有试图对价格如何影响DNN做出一般性陈述,而是专注于一次解释一个搜索结果。借鉴[5]中的个体条件期望(ICE)图的思想,我们从单个搜索结果中提取列表,在保持所有其他特征不变的情况下浏览价格范围,并构建模型得分图。图4显示了一个示例图。这些图表明,完全连接的两层DNN完全理解更便宜更好。
对日志中随机选择的搜索集合重复ICE分析,进一步强化了这一结论。通过试图进一步压低价格,失败的模型架构在质量上做了妥协。
方法5:Two Tower Architecture
回到图1,客人们显然通过该图表传递了一个明确的信息。但那些执着于用相关性换取价格的系统架构却误读了这个信息。我们需要对图1进行重新诠释——这种诠释必须同时兼顾价格与相关性之间的平衡。
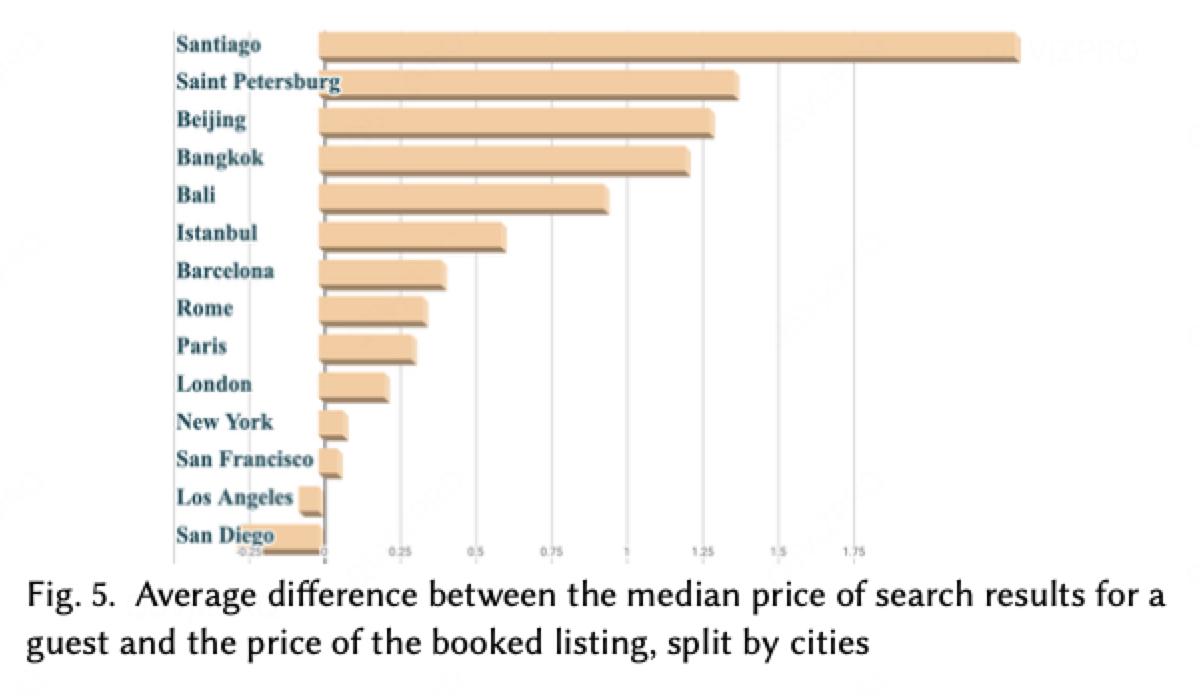
当我们计算每位客人搜索结果中位数价格与其实际预订价格的差值,并按城市分组求平均值时,一个全新的解释浮现出来。正如预期,不同城市之间存在差异,但与头部城市相比,尾部城市(通常位于新兴市场)的价差明显更大。图5展示了部分精选城市的搜索结果中位数价格与预订价格的平均差值。这引出一个重要假设:图1背后的深度神经网络正遭受"多数群体暴政"的影响——其价格与质量的权衡机制过度适配预订量占主导的热门地区,而将这些权衡逻辑泛化到长尾查询时效果欠佳,模型未能适应地域特性。
这一假设与另一个关于DNN特征输入的观察相印证:由于该网络采用成对损失函数进行训练,那些在配对房源间存在差异的特征对模型影响最大;而查询特征(配对房源共有的特征)影响力微乎其微,即使剔除这些特征对NDCG指标也几乎无影响。
新的观点认为,模型虽然深刻理解了"低价优先"的逻辑,却未能捕捉到"旅行合理价位"这一核心概念。要掌握这一概念,需更细致地关注如地理位置等查询特征,而非单纯依赖房源特征的差异进行判别。
这种思路将价格相关性从房源层面的绝对比较,提升到搜索上下文中的动态评估——模型需要理解不同目的地(如巴黎商务区与巴厘岛度假村)自然存在差异化的合理价格区间,而非一味追逐绝对低价。通过强化查询特征对排序决策的影响,系统可以更灵活地适应不同地域市场的价格敏感度与消费预期。
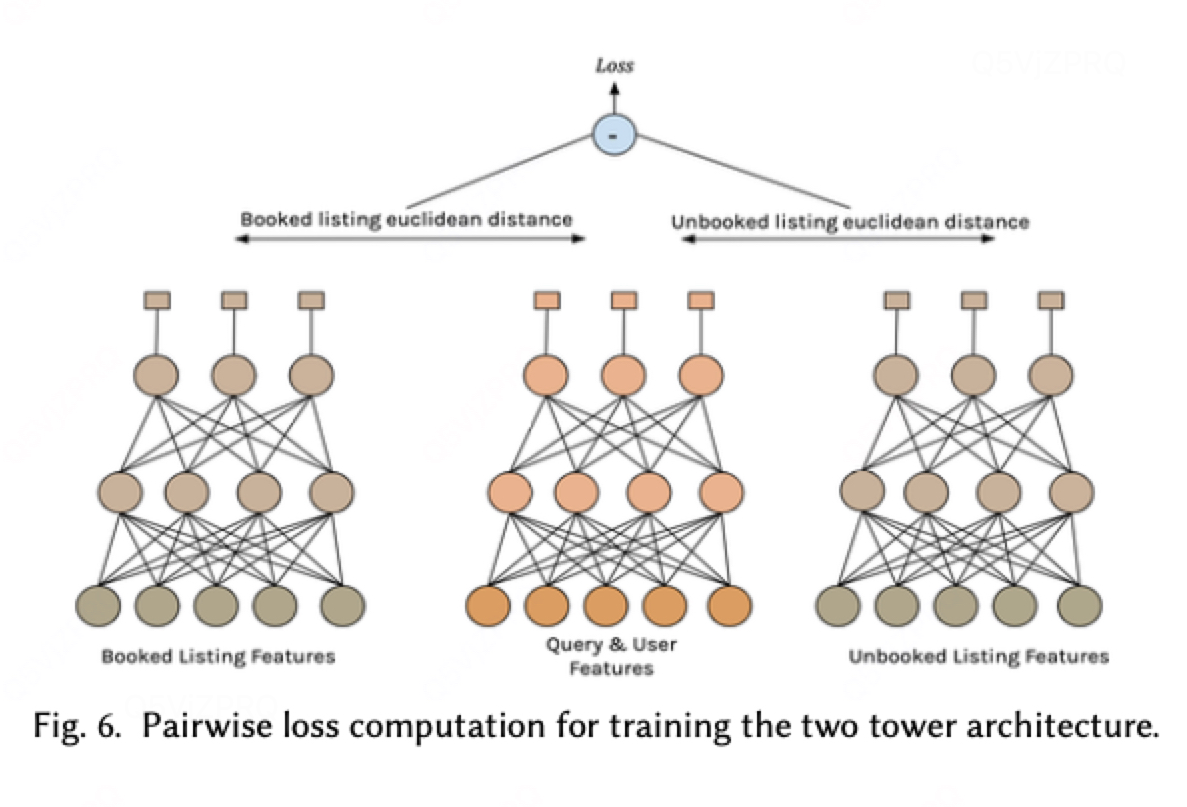
所以构建一个双塔模型:系统由两个并行的深度神经网络构成:
-
查询用户塔:输入查询特征(如目的地、出行日期)与用户画像,输出表征"理想房源"的100维语义向量;
-
房源特征塔:输入房源属性(价格、设施、历史评分等),输出房源本身的100维表征向量。
两个向量间的欧氏距离,则量化为该房源与当前搜索上下文下理想房源的匹配偏离度。训练时采用对比学习策略:每对训练样本包含一个被预订房源与一个未被预订房源,通过最小化损失函数(被预订房源与理想向量的距离应小于未被预订房源的距离),驱动双塔网络参数更新。
这种设计巧妙地将文献[12]的三元组损失简化为二元组形式——查询用户塔自动学习生成隐含的"锚点"(即理想房源向量),而非显式构造三元组。表3的抽象代码展示了该架构在TensorFlow™中的核心实现逻辑(实际工程部署时对计算图进行了速度优化)。
推理时如何实现?

实验结果预定量增加了0.6%。我们观察到,作为相关性增加的副作用,搜索结果的平均价格下降了-2.3%。预订量的增加抵消了价格下跌对收入的影响,整体增长了0.75%。
结构分析:
尽管我们为模型成功上线欢欣鼓舞,但伴随DNN迭代而来的疑虑仍悄然浮现:这套架构是否真的如设计预期般运行?还是神经网络偶然习得了其他无关模式?过去,DNN的黑箱特性使此类问题极难解答。但得益于双塔架构的改进本就源于对用户痛点的直接回应,我们可借助初始设计思路逆向解析模型行为。
重新审视价格变量的ICE(个体条件期望)曲线时,我们观察到显著变化:原先单调递减的曲线(印证"越便宜越好"的排序逻辑)被打破,取而代之的是在特定价格区间出现评分峰值(如图7所示)——这与"旅行合理价位"的理论解释高度契合。
两个ICE曲线为不同模型得出的不同结果;
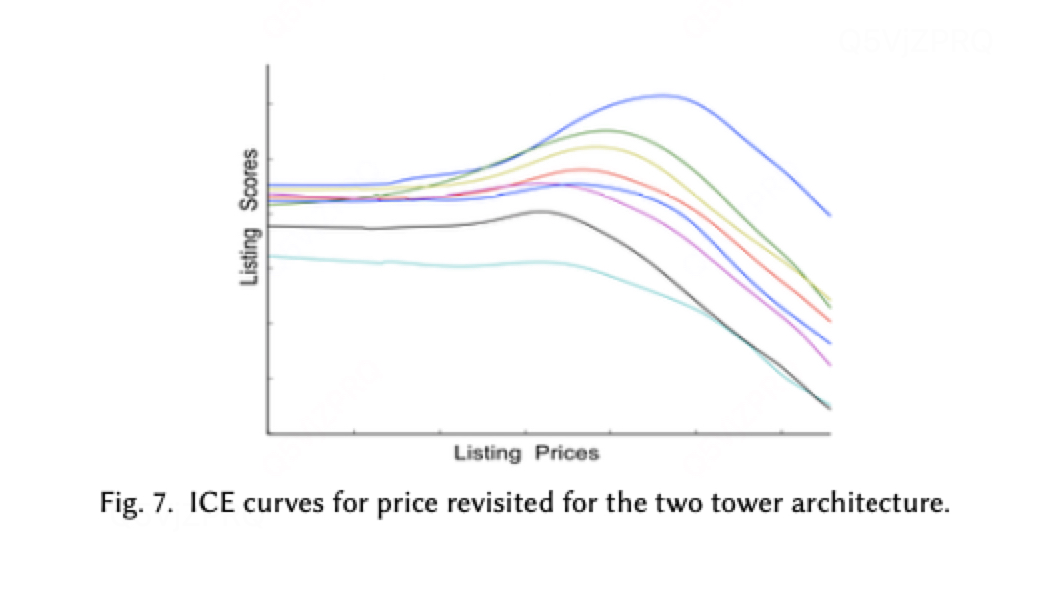
针对"低质房源是否可能通过定价策略操纵新模型排名"的质疑,我们深入分析ICE曲线发现:评分峰值仅出现在本身质量优异、原本排名靠前的房源中;而绝大多数普通房源的价格-评分曲线仍保持单调递减趋势。这表明模型在捕捉合理价格区间时,已自发将房源质量纳入综合评估体系。
要理解"合理价格"与"理想房源"的定义,关键在于分析查询塔生成的向量表征。为此,我们随机抽取搜索样本输入双塔DNN,捕获查询塔输出的100维嵌入向量。由于100维向量本身不具备可解释性,我们采用t-SNE降维技术[17]将其投影至二维空间,可视化结果如图8所示——值得注意的是,图5中的部分城市对应查询在语义空间中的分布呈现显著的区域聚集性。
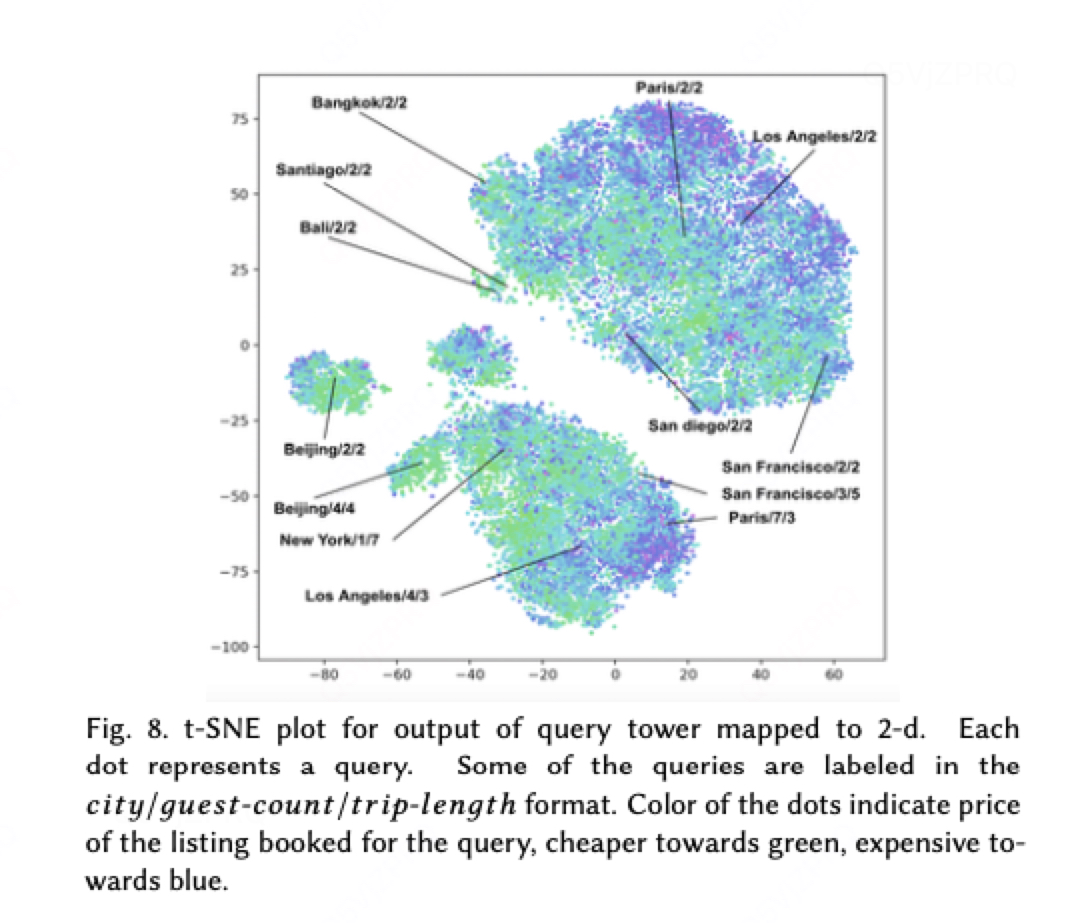
这一发现暗示:虽然查询特征在原始排序模型中影响力薄弱,但深度网络实际上已经隐式捕捉到地域属性等上下文信息。问题在于,这种地理语义的编码未能有效传导至最终的排序决策层,导致模型无法将价格评估置于地域消费水平的坐标系中进行校准。
需要重点指出的是,这些聚类并非单纯的价格分组。图8中点的颜色代表对应查询的实际预订价格,可见同一聚类内颜色(价格)分布广泛。虽然莫斯科通常比巴黎价格低廉,但根据入住人数、住宿时长、景点距离、周末/工作日差异等多重因素,莫斯科的预订价完全可能高于巴黎。价格与其他属性维度深度交织,要准确判断旅行的合理价格,必须同步把握所有关联因素。
尽管我们的分析方法无法为"双塔架构已全面掌握这种综合判断能力"提供确凿证据,但价格ICE曲线的形态转变、查询塔向量的t-SNE可视化以及跨城市价格波动分析形成的证据链,足以支撑我们对模型运行机制符合预期的信心。
冷启动问题:
对我们而言,使用NDCG(归一化折损累积增益)量化被预订房源在搜索结果中的排名位置,始终是评估模型性能最可靠的指标。因此,分析用户痛点的自然切入点便是寻找NDCG显著低于整体水平的细分房源群体。
通过拆解平台新上线房源(无历史预订记录)的NDCG并与成熟房源对比,我们观测到两者存在-6%的差距。作为参考,过往经验表明,当模型间NDCG差异达0.7%时,线上预订量便会产生统计显著性变化。这一巨大差距意味着,现有模型迫使房客付出额外精力才能发现优质新房源。为深入剖析成因,我们从DNN输入特征中剔除了所有基于历史用户互动的信号(如房源过往预订量)。移除这些互动特征后,NDCG指标下降-4.5%,证明模型高度依赖此类特征进行排序决策。对于缺乏用户互动数据的新房源,DNN只能基于剩余特征做出粗粒度评估,导致其排序结果趋近于新房源的平均表现水平。
冷启动问题可被重新定义为探索(explore)与利用(exploit)的权衡。若仅优化短期预订量,排名策略会偏向已积累历史数据的成熟房源;但从平台长期生态健康出发,必须付出一定成本探索新上线房源。一种典型解决方案是对新房源施加显式排名提升——即使其DNN预测分数较低,仍通过规则干预提升其展示位次,以较低预订损失为代价收集用户反馈。此类方法在电商排序中广泛应用(如文献[15]),并可通过曝光量上限、时间衰减因子等进一步优化。我们的首次实验即测试该机制:通过在线A/B测试,在保持整体预订量中性的前提下,使新房源首屏曝光量增加8.5%。
然而,探索-利用框架的引入引发严峻挑战:
-
相关性悖论:强制提升可能导致与用户搜索意图无关的新房源混入前排结果,损害用户体验;
-
动态校准困境:提升幅度需随房源生命周期动态调整,过早衰减会削弱冷启动效果,过晚则造成资源浪费;
-
个性化冲突:全局统一的提升策略无法适配不同用户对新房源的接受度差异,可能干扰个性化排序逻辑。
新房源排名提升机制受到两股对立力量的拉扯:
-
短期用户体验下降:因搜索结果相关性降低导致的可量化负面影响;
-
长期体验增益:通过扩充优质库存带来的隐性长期收益(难以精确量化)。
由于缺乏对"最优提升幅度"的客观定义,团队内部爆发激烈争论,难以达成多方满意的平衡方案。
即使人为设定全局探索成本预算后,新问题随之浮现:预算的合理分配高度依赖地域供需动态。例如:
-
高需求地区:用户对新房源探索容忍度较高;
-
低需求地区:过度探索可能加剧预订量下滑风险;
-
供给受限地区:急需通过探索扩大有效库存;
-
供给过剩地区:优质房源闲置时,探索成本效益比低下。
而供需状态本身又受地理位置、季节周期、客群规模等多维参数调控。这意味着,要优化使用全局探索预算,需建立包含数千个地域化参数的动态调控体系——这显然无法通过人工规则实现。
预测未来用户互动特征
为构建可管理的冷启动系统,我们重新审视问题核心:新房源的本质差异何在?答案在于缺乏用户互动特征(如预订量、点击量、评论数等),而其价格、位置、设施等固有属性与其他房源无异。理论上,若存在能100%精准预测新房源互动特征的神谕模型,即可完美解决冷启动问题。
基于此洞见,我们将冷启动问题重新定义为"预估新房源未来互动特征"的预测任务——这一视角转变带来关键突破:它允许我们设定明确优化目标并通过迭代逐步逼近。为此,我们向DNN引入新模块,该模块在训练与预测阶段均生成新房源的互动特征预测值。
预测器精度评估方法
我们采用以下四步验证框架:
-
数据采样:从日志中抽取约1亿次搜索结果的top 100房源构成样本集,确保所选房源已积累充分用户互动数据;
-
基准排序计算:基于真实互动特征,计算每个样本房源的折损排名得分DR_real = log(2.0)/log(2.0 + R_real),其中R_real为日志中的实际排名;
-
预测排序模拟:移除样本房源的真实互动特征,替换为待测预测器的估计值,重新计算其预测排名得分DR_predicted;
-
误差度量:以(DR_real - DR_predicted)²作为单个样本预测误差,最终误差取全体样本均值。
总之就是:通过排名误差来对真实互动特征进行预测。从而得到冷启动item的互动特征。
理想预测器的误差应为零,实践中通过比较不同预测器的误差值选择更优方案。
预测器对比验证
我们对比两种方案:
-
基线系统:生产环境原有方案,对缺失特征(含新房源互动特征)赋予人工设定的固定默认值;
-
地理邻近预测器:基于时空滑动窗口策略,仅聚合与新房源地理位置相邻(半径限定)、容量匹配的房源历史互动特征均值。例如,预测某新房源(双人容量)的预订量时,取周边同类房源在相同时段(考虑季节性)的平均预订量。该方法概念上类似文献[11]的朴素贝叶斯推荐器,通过生成式方法填补缺失信息。
离线分析表明,相较于使用默认值的基线系统,上述地理邻近预测器将互动特征估计误差降低42%。在线A/B测试中,新上线房源的预订量提升+14%,首屏曝光占比同步增长+14%。值得注意的是,该优化不仅助力新房源冷启动,还推动整体预订量增长+0.38%,印证了用户体验的全域提升。
启发
参考:
ICE: https://www.tandfonline.com/doi/full/10.1080/10618600.2014.907095
Methods and metrics for cold-start recommendations