一种用于从视网膜图像中识别疾病的 BERT 式自监督学习 CNN
大家读完觉得有帮助记得关注和点赞!!!
抽象
在医学成像领域,深度学习的出现,尤其是卷积神经网络 (CNN) 的应用,彻底改变了医学影像的分析和解释。然而,深度学习方法通常依赖于大量的标记数据。在医学成像研究中,获得高质量的标签既昂贵又困难。Vision Transformers (ViT) 和自我监督学习的引入提供了一种利用大量未标记数据的预训练策略,有效缓解了标签采集挑战,同时拓宽了数据利用的广度。然而,ViT 的高计算密度和对计算能力的巨大需求,再加上其对图像补丁的作缺乏本地化特性,限制了它在许多应用场景中的效率和适用性。在这项研究中,我们采用轻量级 CNN 框架 nn-MobileNet 来实现 BERT 风格的自我监督学习方法。我们在来自英国生物样本库的未标记视网膜眼底图像上对网络进行预训练,以提高下游应用程序的性能。我们验证了阿尔茨海默病 (AD)、帕金森病 (PD) 和各种视网膜疾病识别的预训练模型的结果。结果表明,我们的方法可以显著提高下游任务的性能。总之,本研究将 CNN 的优势与高级自我监督学习的能力相结合,在处理大规模未标记数据方面,展示了 CNN 在标签稀缺情况下的潜力。
关键字:
自我监督学习 预训练 卷积神经网络 英国生物样本库1介绍
在过去的几十年里,卷积神经网络 (CNN) 在各种任务中取得了出色的成果,彻底改变了医学成像领域[17,30,29]. CNN 在视网膜疾病检测等任务中取得了优异的成果[24,6,19],这在很大程度上要归功于它们的核心属性,即空间层次结构、定位和平移不变性。这些功能使 CNN 能够捕获局部视觉特征,例如边缘和纹理,并将它们转换为更高级别的抽象特征[24].这种能力至关重要,因为它可以识别对疾病诊断至关重要的细微差异。
深度学习在医学图像分析中显示出巨大的潜力。然而,获得标签的难度和他们要求的成本仍然是该领域一个臭名昭著的问题[26].近年来,自然语言处理 (NLP) 领域在自我监督预训练模型方面取得了重大进展[14],例如来自 transformers 的双向编码器表示的自监督学习模型 (BERT)[2]和生成式预训练转换器 (GPT)[1].从 NLP 的成就中汲取灵感,视觉转换器 (ViT) 的集成催化了许多采用掩蔽策略的自我监督视觉模型的发展。这一转变标志着视觉领域在自我监督模型中从对比学习到生成学习方法的重大转变。
尽管 ViT 带来了解决医学成像领域问题的新方法[23,26],他们的自我注意机制的计算强度高和对大规模数据集的依赖揭示了他们的局限性[23,9].自注意力作的时间和内存复杂度随输入大小呈二次方增长,这使得 ViT 在处理大量数据时特别耗费资源。此外,与传统的 CNN 相比,ViT 在图像处理中表现出较少的定位能力,因为它们的机制主要针对图像的块级,而不是直接关注单个像素。[9].我们在 CNN 中观察到的优势,以及预训练对自我监督学习的显着好处,以及 ViT 的潜在缺点,都激发了进一步的思考:是否有可能将性能良好的 CNN 与 BERT 风格的生成式自我监督学习相结合进行预训练,以结合两者的优势?
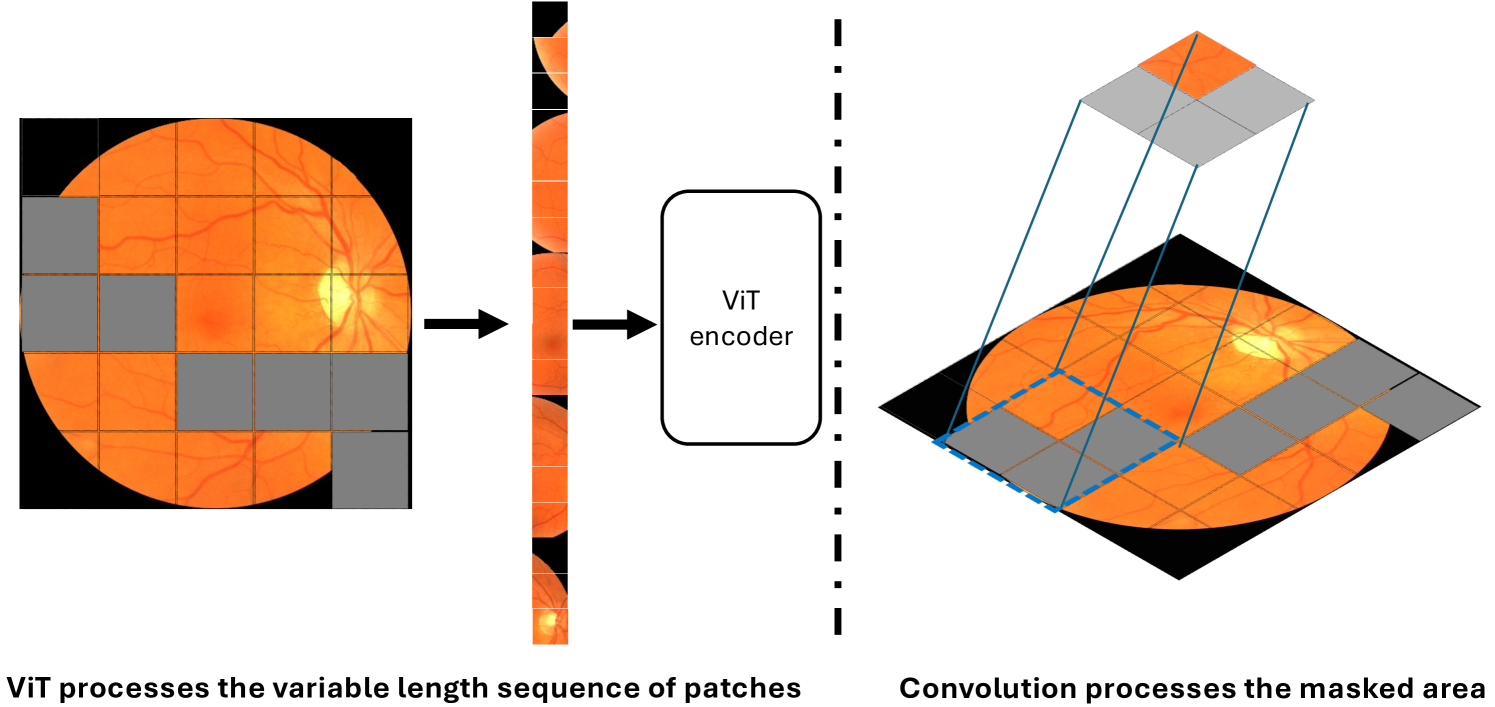
图 1:左侧面板上的 ViT 可以处理非掩码补丁而无需任何更改,因为它可以处理可变长度的序列,而右侧面板上的 CNN 无法跳过卷积的掩码。在 CNN 中简单地采用掩码可能会导致性能下降。这项工作采用了一种新的解决方案来解决这个问题。
我们的研究表明,最初的努力[13,25]使用掩码策略训练 CNN 进行自我监督学习并没有取得有竞争力的结果。 CNN 和 ViT 之间固有的架构差异阻碍了在图像处理任务中用 CNN 直接替代 ViT(图 D)。与 ViT 不同,ViT 擅长处理可变长度的补丁序列,而无需调整遮罩区域,而 CNN 在卷积作期间无法绕过遮罩区域。与 ViT 相比,这种限制导致 CNN 的结果不一致和性能下降。 最近,一些研究人员通过引入稀疏卷积解决了这个掩码问题[10],例如 SparK 的提议[21]和 ConvNextV2[22].通过稀疏卷积,本研究利用 nn-MobileNet 为 CNN 引入了一种 BERT 风格的自我监督学习框架[28]作为 CNN 主干,一种源自 MobileNetV2 的轻量级架构[16].利用来自英国生物样本库的 178,803 张未标记的视网膜图像[20],我们进行自我监督的预培训。然后,在下游任务上评估此预训练模型以评估其性能。我们的研究结果强调了 CNN 的巨大潜力,尤其是在缺乏标记数据的情况下。
本文的主要贡献包括:1). 通过采用稀疏卷积,我们提出了一种新颖的 BERT 式自监督学习 CNN 来丰富自监督方法。它普遍适用于广泛的医学成像研究。2). 我们的方法与 CNN 模型和谐地集成[28],利用其精确定位和较低的数据要求等优势。3). 我们广泛的实验证实了它优于几个领先的监督[24,6]和自我监督[7,27]模型跨一系列基准,包括一个[27]使用超过 1.6M 的眼底图像进行预训练。
2方法
2.1nn-移动网络
我们的骨干是最近开发的 CNN 模型 nn-MobileNet[28](图 .2). 基于 MobileNetV2[16],它进行了以下架构创新。
通道配置。nn-MobileNet 修改了网络中倒置线性残差瓶颈 (ILRB) 的通道配置顺序。此策略旨在通过利用通道配置的重大影响来提高网络性能[11].
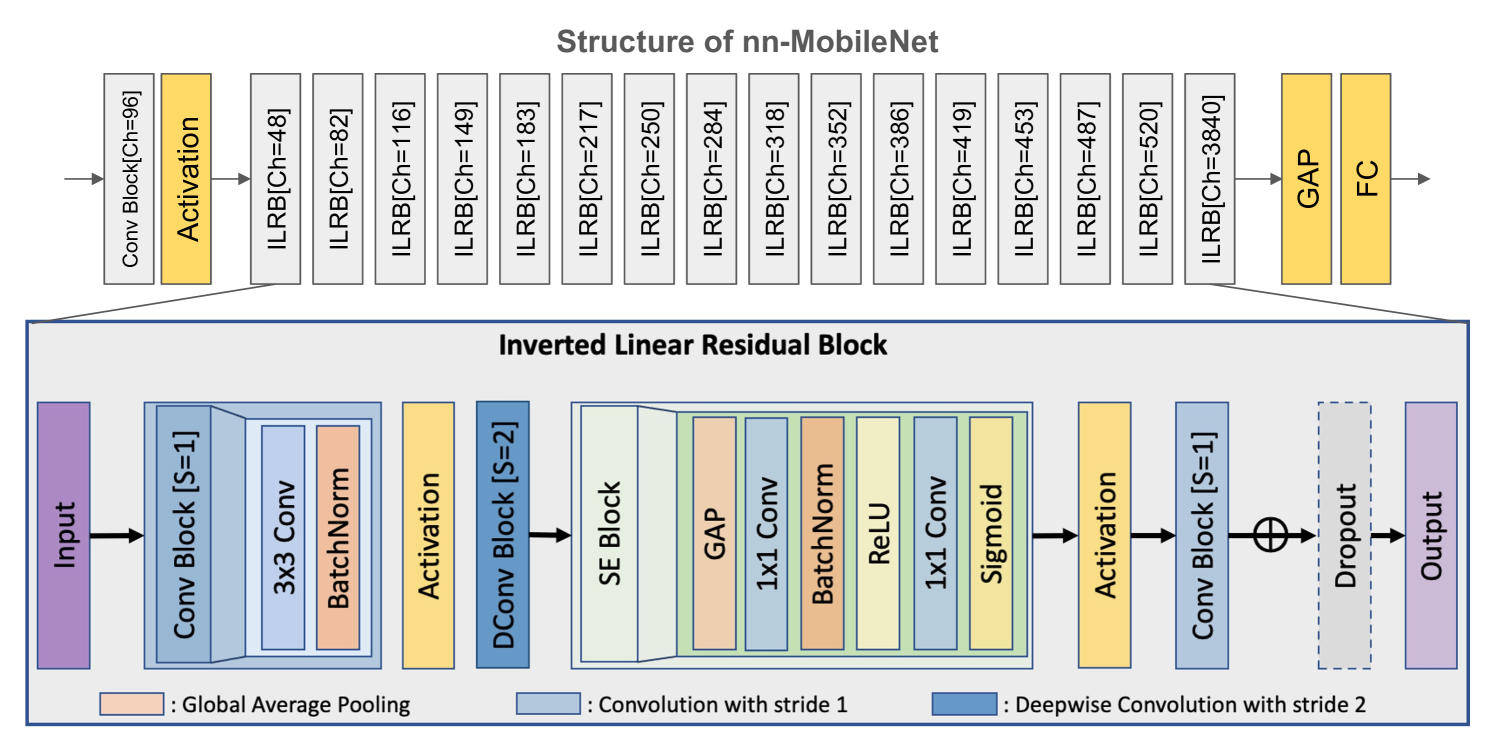
图 2:nn-MobileNet 的详细架构及其 ILRB 设计。nn-MobileNet 在视网膜成像研究中取得了卓越的成果[28].当前的自我监督学习方案进一步增强了其性能。
数据增强。与传统视网膜成像方法相比[24],nn-MobileNet 采用大量数据增强策略,包括图像裁剪、翻转、对比度调整、亮度调整和锐化。实验表明,这种繁重的数据增强对提高系统性能具有显著的好处[28].
辍学。为了解决过拟合问题,nn-MobileNet 尝试在网络内的不同位置添加 Dropout 模块,以确定它们的最佳放置位置,如图 1 所示。2.
激活函数。根据以前的研究,ReLU 激活函数的平滑变体可以提高性能。因此,通过实验比较,ReLU6 因其卓越的性能增强而被选为框架中每个 ILRB 的激活函数。
优化。通过试验和比较当前常见的优化器(包括 Adam、AdamW、AdamP 和 SGD),AdamP[8]是根据经验选择的。
2.2训练前策略
无花果。图 3 说明了预训练策略的工作流程,该策略借鉴了 BERT 架构的基本原则。我们采用图像掩蔽技术(步骤 1)并匹配分层特征图以掩蔽区域(步骤 2)来构建损失函数。我们使用稀疏卷积[10]集成 CNN 架构(步骤 3)。最后,学习到的特征图用于下游应用程序。这种预训练方法的详细信息详细说明如下。
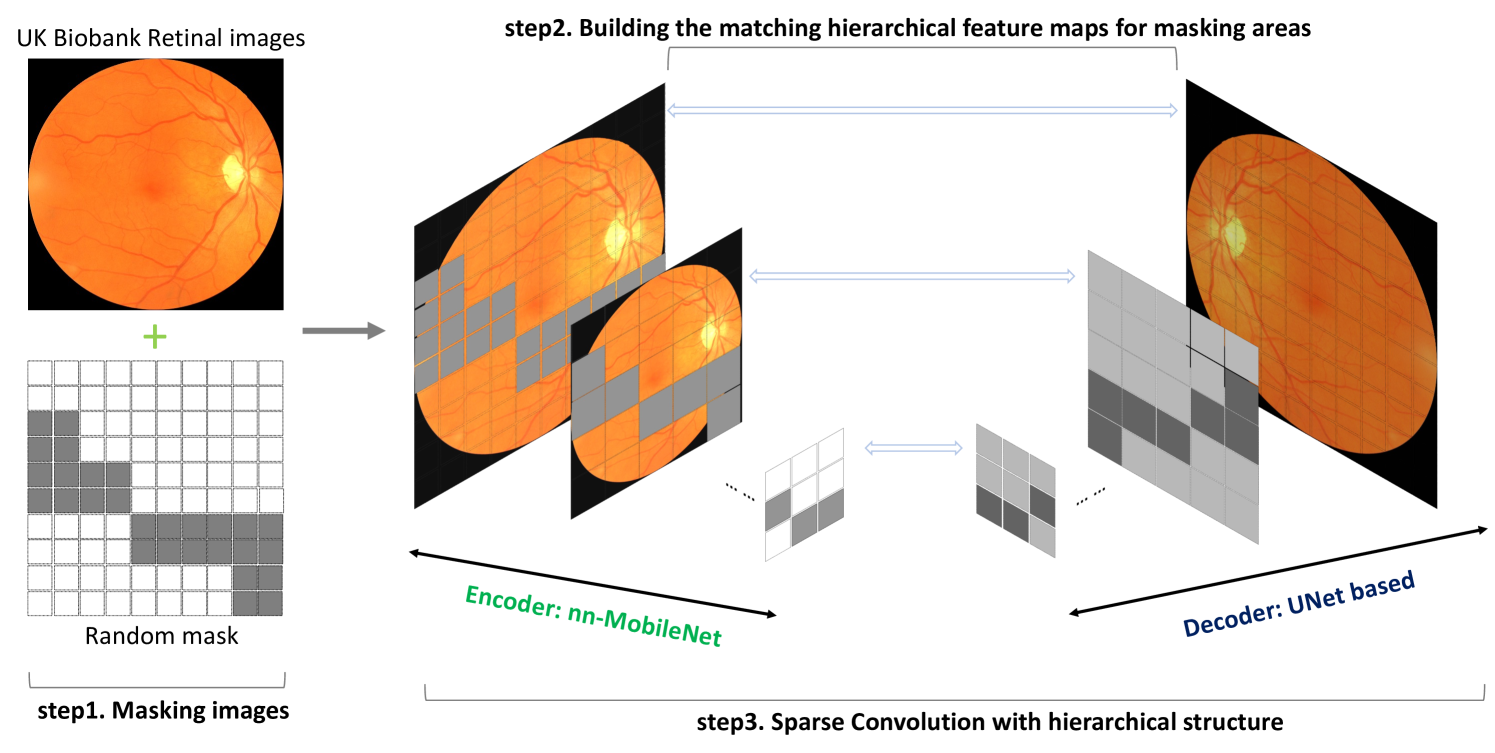
图 3:我们的训练前工作流程图示。我们首先随机屏蔽所有图像(步骤 1)。接下来,我们屏蔽适应 CNN 编码器和解码器不同分辨率的特征图(第 2 步)。最后,我们对被遮罩的图像进行稀疏卷积,并通过解码器恢复图像(第 3 步)。
BERT 风格。在计算机视觉领域,掩码自动编码器 (MAE)[7],类似于 BERT[2]模型,已成为最先进的自我监督学习的预训练策略之一。然而,基于 MAE 方法的研究主要基于 ViTs。如上一节所述,由于 ViT 的固有差异,ViT 的编码器-解码器结构不能直接被 CNN 替代。直到最近,随着 SparK 的连续提议[21]和 ConvNextV2[22],出现了采用 CNN 进行 BERT 式自我监督学习方法的训练前研究的新想法。
层次结构。Hierarchy 被广泛认为是视觉表示系统的黄金标准。在各种 CNN 中实现的分层设计[16,22]显著提高了他们的性能。但是,ViTs 中没有使用这一原理。 在我们的方法中,我们采用 SparK[21]维护 CNN 中固有的层次结构,并确保神经网络可以利用层次结构来改进表示学习。
编码器:在进行卷积作之前,我们根据 CNN 的下采样过程生成不同分辨率的特征图。对于我们的神经网络模型 nn-MobileNet,总共对大小为H∗W,其中 H,W 分别是输入图像的高度和宽度,从而生成特征图集 S 的大小,如下所示:
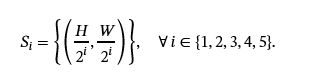
译码器:在解码阶段,我们采用轻量级的 UNet 解码器[15],其特征是包含四个连续的块 {B1,B2,B3,B4} 替换为上采样层。解码器接收S我′从不同分辨率的特征图S我及其掩码嵌入。此外,通过应用投影层φ我,则保证编码器和解码器之间的尺寸一致性。对于最小的特征图,我们定义:D5=φ5(S5′).由此,我们得出其余的特征图D我:
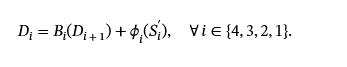
损失功能:我们的损失函数利用一种方法来比较重建图像的掩蔽部分和原始图像中相应的掩蔽区域之间的均方误差 (MSE)。
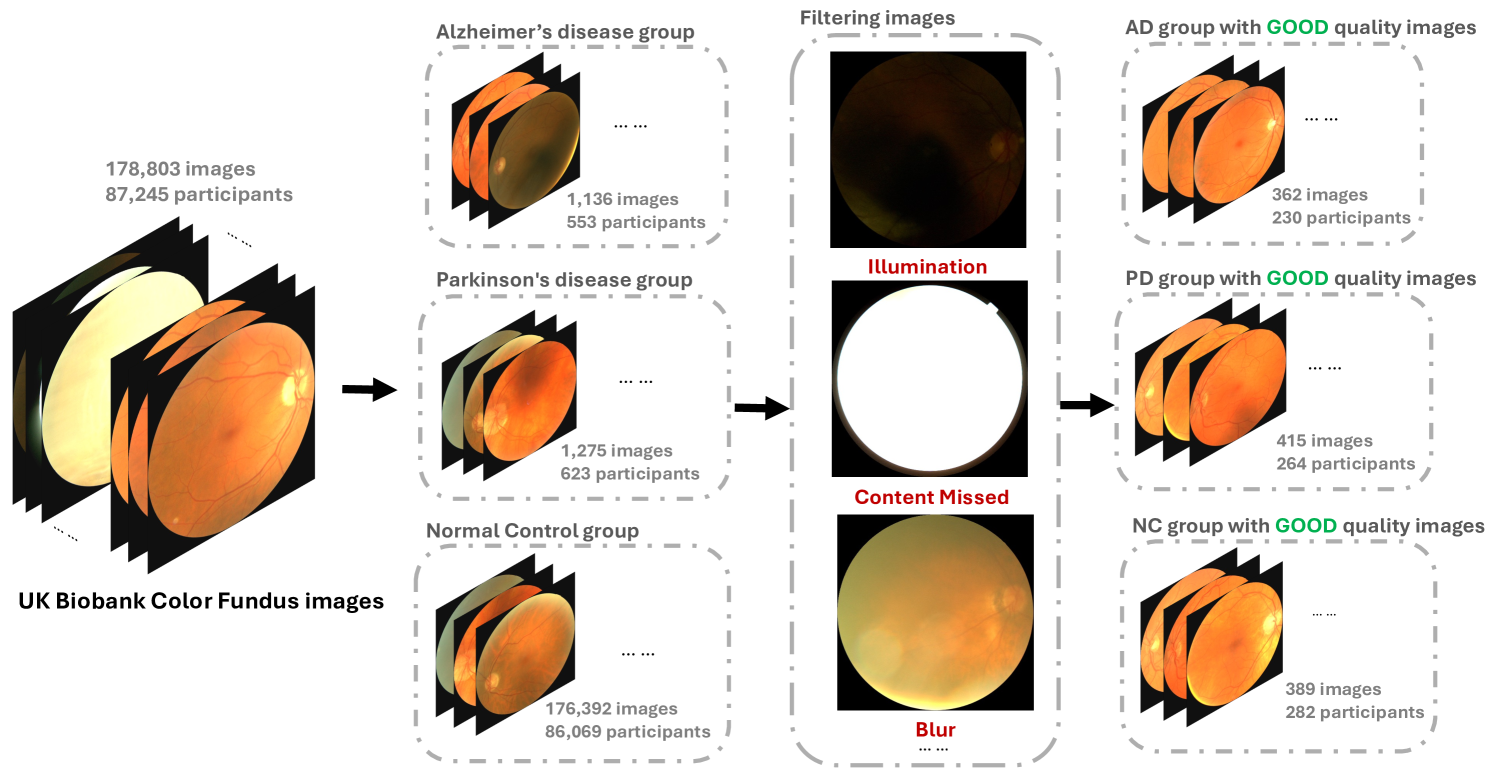
图 4:当我们从英国生物样本库数据集中过滤 AD 患者、PD 患者和正常对照受试者的眼底图像数据时,质量控制管道的图示。
稀疏卷积。卷积广泛用于 2D 计算机视觉研究,其中滑动窗口作通常在像素网格上执行。但是,它在 MAE 研究中是不合适的,因为掩码像素可能会参与卷积并导致结果不一致。稀疏卷积[10]通过省略所有空体素并将卷积运算集中在非零元素上,提高了计算一致性。这项工作通过确保卷积作仅在非掩码像素上进行,将稀疏卷积扩展到自我监督研究。
3实验结果
在英国生物样本库数据集上进行预训练。我们的研究使用了来自英国生物样本库的 178,803 张未标记的彩色视网膜眼底图像[20],涉及 87,245 名参与者,进行自我监督的预培训。在预训练期间,我们首先随机遮罩60%中,其中每个蒙版的大小等于:(HD,WD),其中 D 是网络的下采样率。然后,我们只处理输入图像的未遮罩可见区域。在我们的网络中,输出图像的大小为(224,224),下采样率为32,使我们的蒙版大小为(7,7).我们进一步使用从预训练模块中学到的特征图进行分类研究。
基准。对于实验,我们以 8:2 的比例将数据随机分为训练集和验证集。我们在数据集上采用了 5 倍分层交叉验证。用于评估预训练后网络性能改善情况的评估指标包括二次加权 Kappa (Kappa) 、AUC (接受者作特征下的面积)、F1 评分和准确性。我们的比较方法包括 CANet[24]、VGG11[19]、Rexnet[6]和基于 ViT 的方法,包括 MAE[7]、RETFound[27]和基于英国生物样本库的预训练 MAE 模型。
阿尔茨海默病 (AD) 和帕金森病 (PD) 鉴定。我们的质量控制从英国生物样本库中选择了 362 张 AD 患者的眼底图像,其中包括 230 名患者中的 169 张左眼图像和 193 张右眼图像。此外,我们匹配了 389 张来自无 AD 参与者的图像,包括 282 名参与者的 170 张左眼图像和 219 张右眼图像,作为参考组。同样,我们从英国生物库中选择了 415 张 PD 患者的眼底图像,其中包括 264 名患者中的 197 张左眼图像和 218 张右眼图像。无花果。4 说明了我们的质量控制程序。我们过滤显示任何情况的图像:模糊、低对比度、不良照明和伪像。尽管我们使用了来自英国生物样本库的 AD 和 PD 诊断患者的眼底图像,但我们认为我们的预训练 1) 不使用图像标签,并且 2) 主要侧重于学习掩码区域以构建特征图。我们的实践与常见的自我监督方法一致[27].
MICCAI 近视性黄斑病分析挑战赛 (MMAC) 2023 - 近视性黄斑病的分类[12].该挑战包含 1143 张眼底图像,分为四个近视黄斑病变等级。0 级有 404 张图像,1 级有 412 张图像,2 级有 224 张图像,3 级有 60 张图像,43 级有 43 张图像。nn-MobileNet 在 MICCAI MMAC 中排名第三[12],我们利用它来展示我们的预培训策略的优势。
表 1:所提出的预训练模型与其他监督和自监督网络在 AD/PD 识别研究上的实验结果比较。我们的结果与这些最先进的方法相当或优于这些最先进的方法。
| 广告 | 帕金森 | |||||
|---|---|---|---|---|---|---|
| 方法 | ACC | AUC | 卡帕 | ACC | AUC | 卡帕 |
| CANet[24] | 0.7 | 0.7391 | 0.3981 | 0.6273 | 0.6758 | 0.2557 |
| VGG11的[19] | 0.7467 | 0.8114 | 0.4898 | 0.6211 | 0.589 | 0.2447 |
| 雷克斯内特[6] | 0.9933 | 1.0 | 0.9866 | 0.7640 | 0.8974 | 0.534 |
| 梅[7] | 0.9933 | 1.0 | 0.9866 | 0.8385 | 0.9132 | 0.677 |
| MAE+UK 生物样本库* | 0.9933 | 1.0 | 0.9866 | 0.8696 | 0.9411 | 0.7392 |
| RETFound[27] | 0.9933 | 1.0 | 0.9866 | 0.9193 | 0.9768 | 0.8387 |
| nn-移动网络[28] | 0.9933 | 1.0 | 0.9866 | 0.9876 | 0.9993 | 0.9752 |
| 我们 | 0.9933 | 1.0 | 0.9866 | 0.9938 | 0.9993 | 0.9876 |
*我们根据 MAE 结果继续与英国生物样本库进行预培训。[7].
结果:我们的研究方法在 AD 和 PD 任务上表现出强大的表现(表 1)。在 AD 数据集上,我们取得了良好的结果,正确率为 99.33%,kappa 评分为 0.9866,AUC 为 0.9997。在 PD 数据集上,我们的方法也取得了优异的结果,正确率为 99.38%,kappa 评分为 0.9876,AUC 为 0.9993。我们的结果与其他最先进的方法相当或优于其他最先进的方法[27,7].值得注意的是 RETFound 模型[27]使用超过 1.6M 的视网膜图像进行预训练,而我们的图像使用 176K 眼底图像进行训练。这并不奇怪,因为对于相同的准确率,CNN 通常需要比 ViT 少得多的训练数据[3].
为了分析潜在的生物标志物,我们使用 UNet 进行血管分割,以更好地可视化血管特征[15,31].有了它们,我们使用 Grad-CAM 生成注意力热图[18,5](图 .5). 我们的结果与之前的 AD 研究一致[4],表明具有迂曲变化的视网膜血管分支是 AD 的潜在标识符。
通过在 MMAC 数据集(表.2),我们深入研究了预训练对 nn-MobileNet 性能的影响。实验结果表明,通过对 5 倍交叉验证的结果进行平均,观察到显着改善:Kappa 值提高了 0.232,AUC 提高了 0.0039,Accuracy 提高了 0.0238,加权 F1 分数提高了 0.0412。特别值得注意的是加权 F1 分数的大幅提高,这表明预训练显着提高了模型在多类别分类任务中的性能。
表 2:nn-MobileNet 的结果比较[28]以及在 MMAC 数据集上预训练的 nn-MobileNet。拟议的 pro-training 显著提高了其性能。
| 时代 | 卡帕 | AUC | ACC | F1 系列 | |
|---|---|---|---|---|---|
| nn-移动网络[28] | 300 | 0.8519 | 0.9621 | 0.8105 | 0.7776 |
| 预训练的 nn-MobileNet | 300 | 0.8751 | 0.966 | 0.8313 | 0.8188 |
| 起色 | +0.0232 | +0.0039 | +0.0208 | +0.0412 |
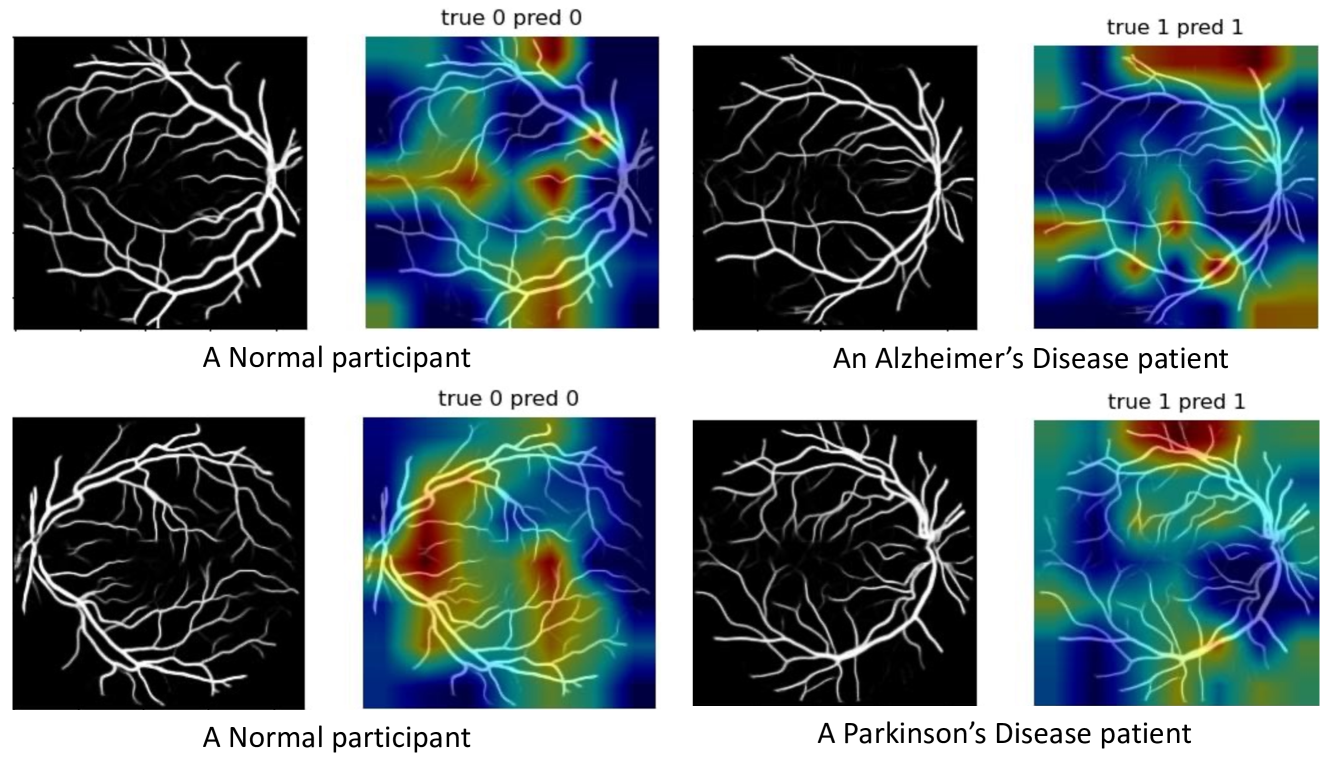
图 5:AD (第一行) 和 PD (第二行) 的热图表明,我们的工作获得了与先前研究一致的有价值的生物标志物[4].
4结论和未来工作
在 NLP 进步的推动下,我们成功地将自监督学习与 CNN 相结合,通过 BERT 风格的自监督训练突破了 ViT 的计算和数据限制,并显著提高了实验性能。在我们未来的工作中,我们的目标是进一步研究 CNN 在自我监督学习领域的优势,将其应用扩展到更广泛的医学成像分析,包括光学相干断层扫描 (OCT) 和磁共振成像 (MRI)。