Java初始化大量数据到Neo4j中(二)
接Java初始化大量数据到Neo4j中(一)继续探索,之前用create命令导入大量数据发现太过耗时,查阅资料说大量数据初始化到Neo4j需要使用neo4j-admin import
业务数据说明可以参加Java初始化大量数据到Neo4j中(一),这里主要是将处理好的节点数据和关系数据分别导出为csv
在这里插入代码片
入口controller.java
//导出节点数据到csv文件中
@GetMapping("exportNodeData")
public void exportNodeData(HttpServletResponse response) {
service.exportNodeData(response);
}
//导出关系数据到csv文件中
@GetMapping("exportRelationData")
public void exportRelationData(HttpServletResponse response) {
service.exportRelationData(response);
}
service.java
//导出节点数据
@Override
public void exportNodeData(HttpServletResponse response) {
//节点数据,按照自己的实际业务添加,我这里对应的是所有表的数据,因为我业务中所有表结果基本一样,也即节点属性都一样。每个表的数据一个map,key是表名作为节点的标签
Map<String, List<NodeData>> nodeDataMap;
List<Map<String,String>> data = new ArrayList<>();
for(String key:nodeDataMap.keySet()){
List<NodeData> dataList = nodeDataMap.get(key);
if (StringUtils.isEmpty(key) || dataList ==null || dataList .isEmpty()) {
continue;
}
for (NodeData nodeData:dataList ) {
Map<String,String> map = new HashMap<>();
String id = nodeData.getId();
String name = nodeData.getName();
String table = nodeData.getName();
//因为不同表的id会重复,需要一个不重复的值作为节点唯一值(我这里用的是表id拼接表数据id)
String uniqueValue = nodeData.getUniqueValue();
map.put(":LABEL",table );
map.put("id",id);
map.put("name",name);
map.put("uniqueValue:ID",uniqueValue);
data.add(map);
}
}
try {
response.setCharacterEncoding("UTF-8");
response.setHeader("Content-Disposition", "attachment;filename=" + new String("nodeimport.csv".getBytes(StandardCharsets.UTF_8), "ISO8859-1"));
response.setContentType(ContentType.APPLICATION_OCTET_STREAM.toString());
CsvWriter csvWriter = CsvUtil.getWriter(response.getWriter()) ;
csvWriter.writeBeans(data);
csvWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//导出关系数据
@Override
public void exportRelationData(HttpServletResponse response) {
//关系数据,将每一个表数据的关系作为RelationData实体
List<RelationData> relationDatas;
List<Map<String,String>> data = new ArrayList<>();
for (RelationData relation : relationDatas) {
Map<String,String> map = new HashMap<>();
String relationName = relation .getRelationName();
String id = relation .getId();
//因为节点是通过表id拼接数据id,所以关系这里也需要加上拼接后不重复的值
//开始节点唯一的值
String uniqueStartValue = relation .getUniqueStartValue();
//结束节点唯一的值
String uniqueEndValue = relation .getUniqueEndValue();
map.put("relationName",relationName) ;
map.put("id",id) ;
map.put(":START_ID",uniqueStartValue) ;
map.put(":END_ID",uniqueEndValue) ;
map.put(":TYPE",relationName) ;
data.add(map);
}
try {
response.setCharacterEncoding("UTF-8");
response.setHeader("Content-Disposition", "attachment;filename=" + new String("relationimport.csv".getBytes(StandardCharsets.UTF_8), "ISO8859-1"));
response.setContentType(ContentType.APPLICATION_OCTET_STREAM.toString());
CsvWriter csvWriter = CsvUtil.getWriter(response.getWriter()) ;
csvWriter.writeBeans(data);
csvWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
CsvUtil用的是Hutool中的工具类,引入下面依赖即可
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.21</version>
</dependency>
解释:
节点中的,
uniqueValue:ID 冒号前面可以随便写,冒号后端必须是ID,标识全局id,不可重复
:LABEL:这个是标签名,必须这样写
除了这两个以外的字段都是作为节点的属性。
导出的nodeimport.csv文件如下

关系中:
:START_ID:开始节点的唯一值
:END_ID:结束节点的唯一值
:TYPE:关系类型
除这三个外的字段都作为关系
导出的relationimport.csv文件如下:

之后找到Neo4j安装目录,找到import目录,将这个两个导出的文件放到import目录下
删除data\databases目录下的文件(neo4j-admin import要求是空文件 ) ,停掉Neo4j
cmd进入到bin目录,执行下面语句
neo4j-admin import --mode=csv --nodes "E:\work_soft\neo4j-community-3.5.5-windows\neo4j-community-3.5.5\import\nodeimport.csv" --relationships "E:\work_soft\neo4j-community-3.5.5-windows\neo4j-community-3.5.5\import\relationimport.csv" --ignore-extra-columns=true --ignore-missing-nodes=true --ignore-duplicate-nodes=true
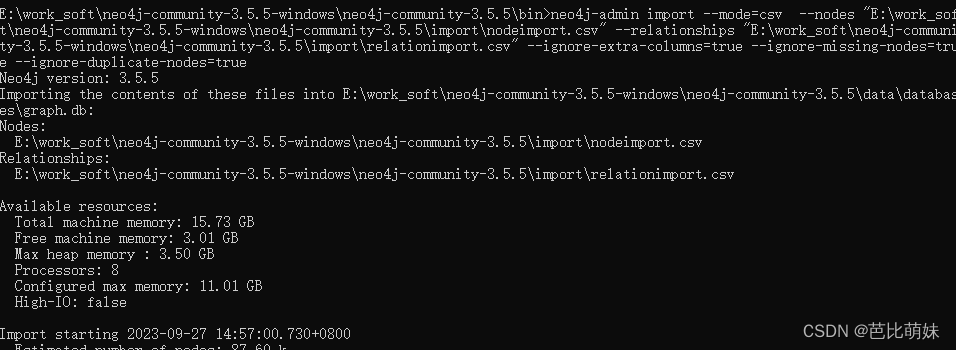
成功之后启动Neo4j,查看数据即可。