RDMA 高性能通信技术原理
目录
文章目录
- 目录
- DMA 与 RDMA
- RDMA 特性和优势
- 大带宽
- 低延时
- RDMA 协议栈标准
- RDMA 运行原理
- 通信通路
- 通信模型
- 通信方式
- 内存注册
- QP 建链
- 常规流程
- 双向控制 Send-Receive API 流程
- 单向数据 Write API 流程
- 单向数据 Read API 流程
- RDMA Verbs API 编程
- 基础网络连通性
- RDMA C/S 程序
DMA 与 RDMA
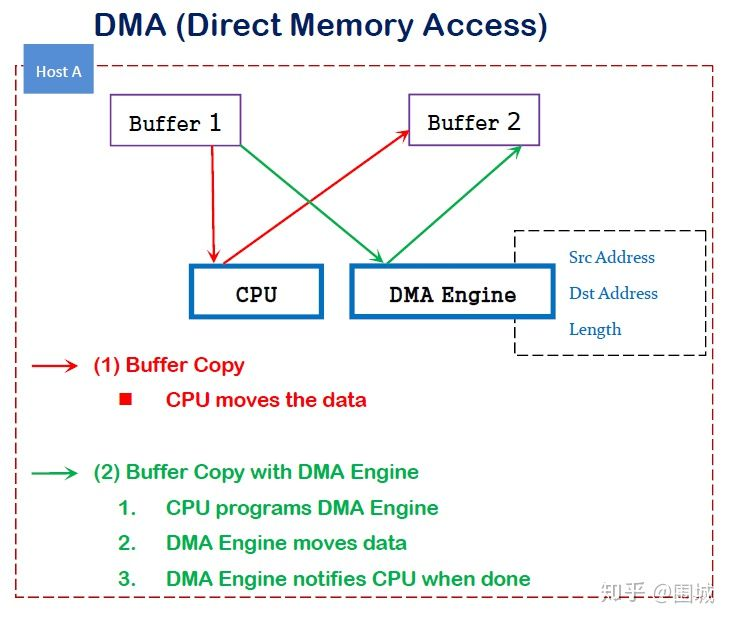
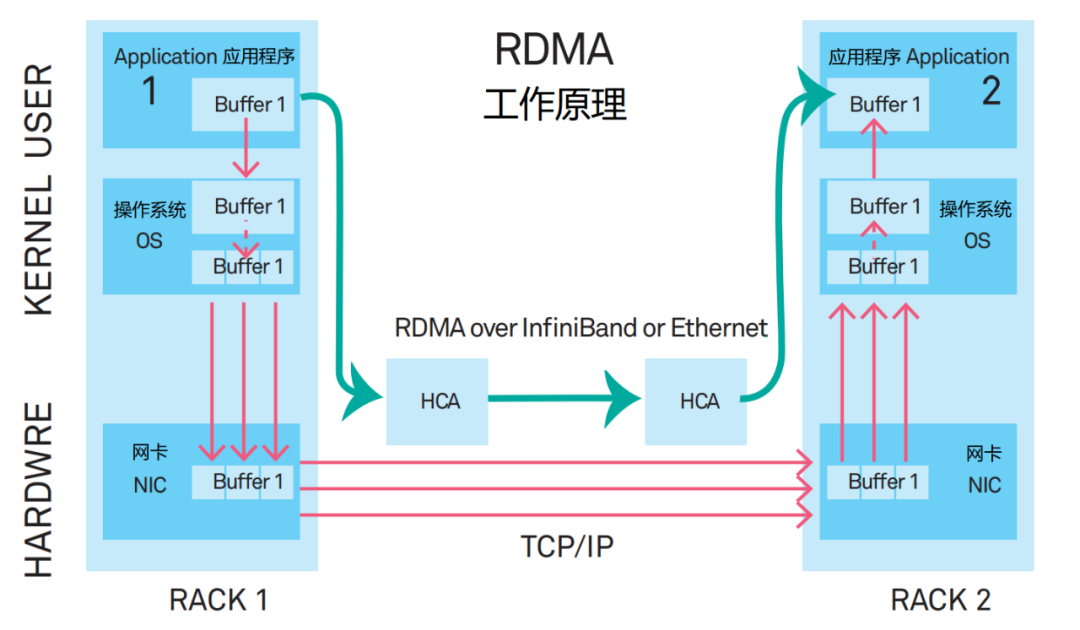
DMA(Direct Memory Access,直接内存访问)让 PCIe I/O 外设可以直接访问 Main Memory。外设跟主存之间的数据交互主要由 DMA Controller/Engine 来完成的,从而避免了 CPU(包括 MMU)的参与。I/O 外设初始化时,DMA Controller 即完成了 Device Address 和 Host Physical Address(ZONE_DMA)之间的直接映射,使得 Kernel 和 User Process 可以直接访问这些外设的存储器。
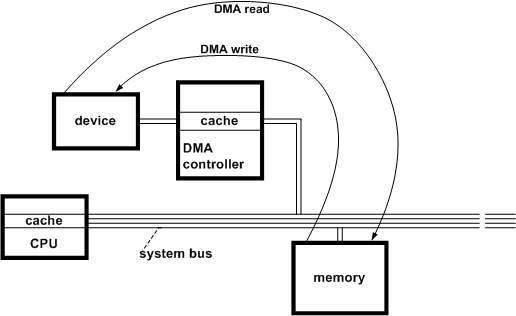
DMA 技术出现之前,NIC 和 CPU 之间的 Frames(二层数据帧)收发依赖 CPU 先从 NIC Rx/Tx Queue 逐个 Copy 到 Kernel Space 内存空间,然后再从 Kernel Space 中 Copy 到 Application 的 User Space 中。每个 Frames 的读/写都需要单向的两次 CPU Copy,非常消耗资源。
DMA 技术出现后,NIC 增加了 DMA Controller(DMA Engine)功能模块,首先将 NIC Rx/Tx Queue 与 Main Memory 中的 ZONE_DMA 建立映射关系,然后当 Frames 进入 NIC Rx/Tx Queue 时,DMA Controller 就会将这些 Frames 通过 DMA Copy 的方式存放到 ZONE_DMA 中,期间完全不需要 CPU 的参与。同时因为 Kernel Space 和 ZONE_DMA 是直接物理映射的关系,所以 Kernel Space 可以直接访问这些 Frames。
通过 DNA Controller 来完成 NIC 和 Main Memory 之间的高速数据传输,在 CPU 读/写报文的单向处理中,减少了一次 CPU Copy 的工作负载。在 32bit Linux 中,ZONE_DMA 默认只有 16MB;而在 64bit Linux 中,ZONE_DMA 默认可以有 4GB,得到了非常大的提升。
RDMA 特性和优势
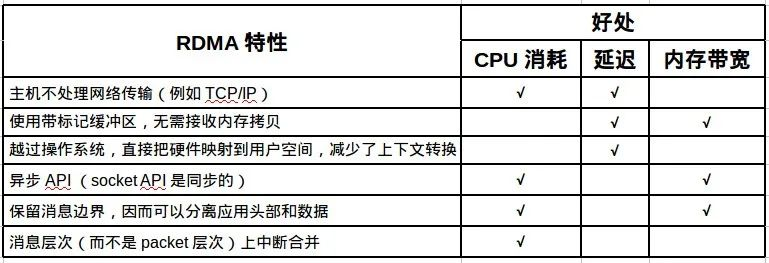
RDMA 的技术特点:
- Remote(远程):数据在 2 台服务器之间进行 P2P 传输。
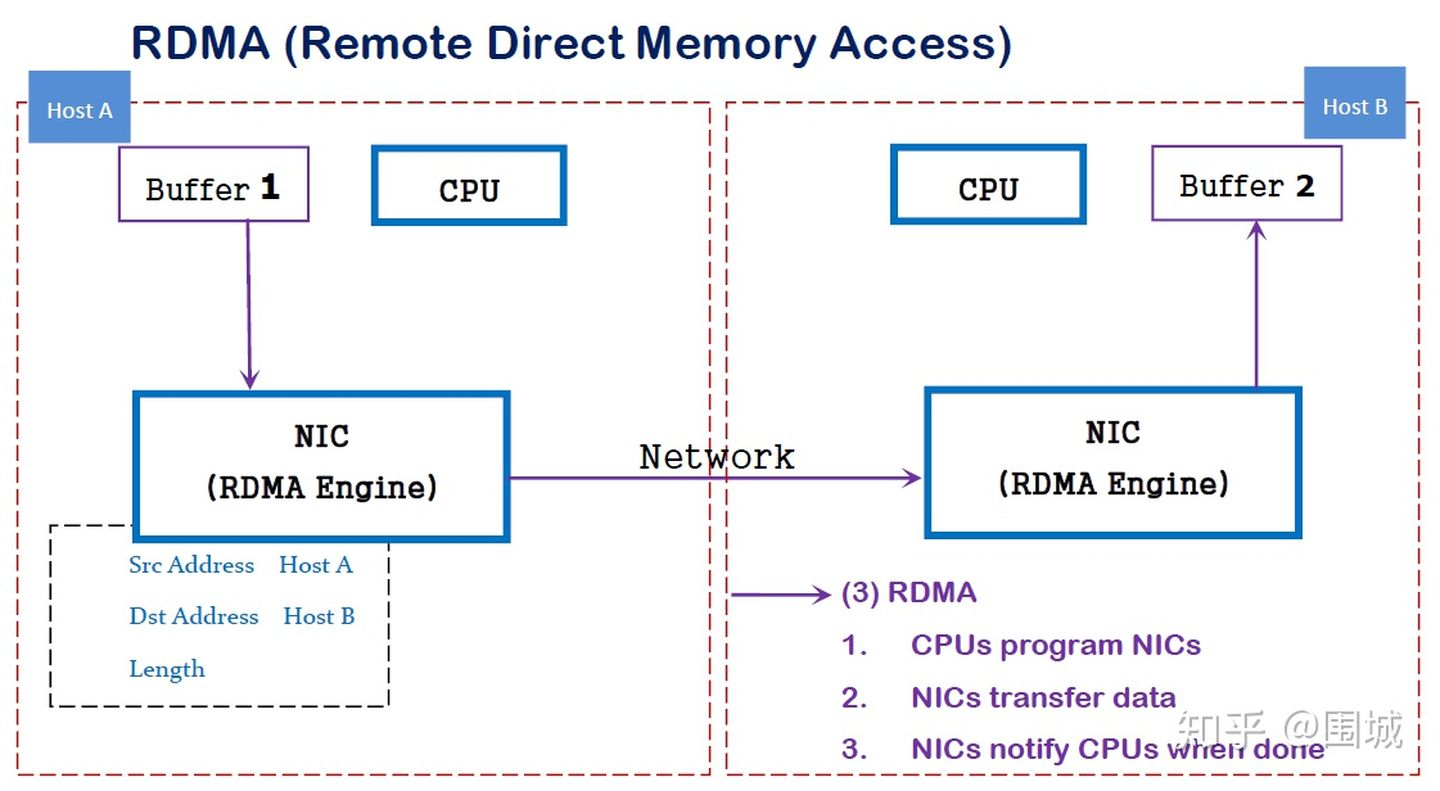
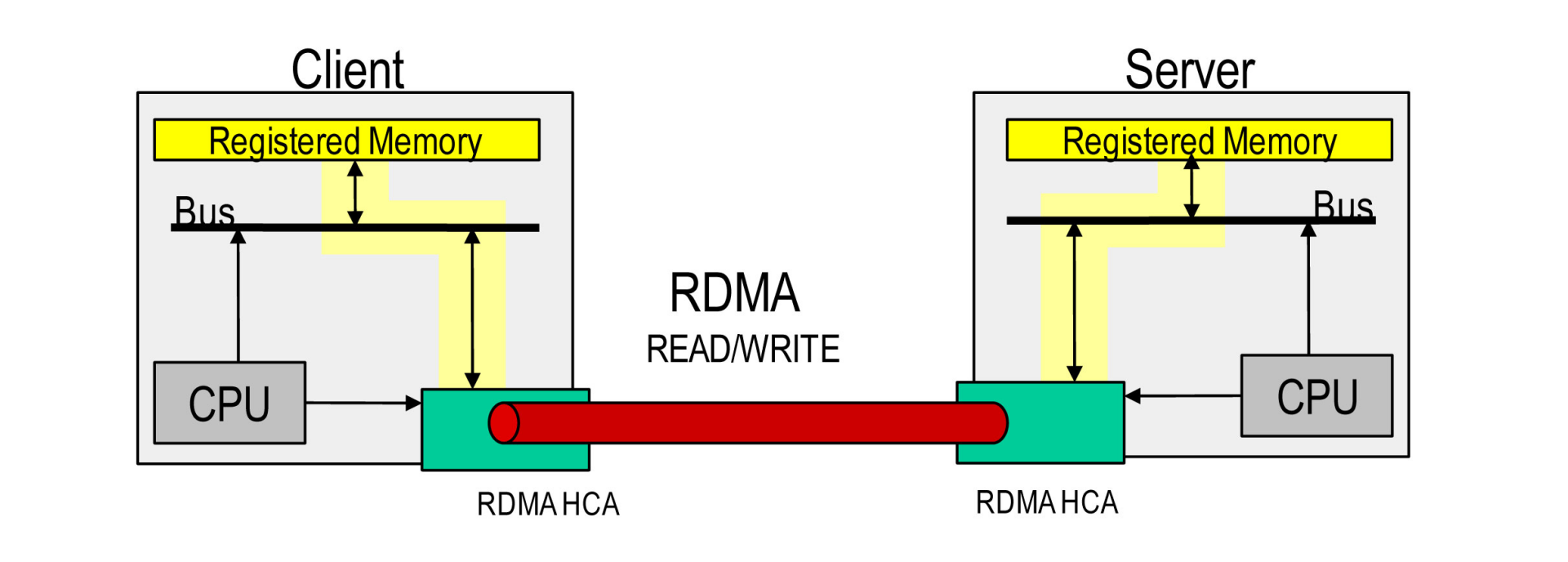
- Direct(直接):不需要 CPU 和 Kernel 的参与,控制信令和数据传输相关的处理都卸载到 RNIC 中完成。
- Memory(内存):2 台服务器上的 Application 之间的内存地址直接传输,延迟最低、带宽最大(服务器内延迟降至 10μs 微秒以下)。
- Access(访问):访问操作有 Send/Receive、Read/Write 等。
大带宽
相对于 TCP,在使用 RDMA 的 100Gbps 场景下,CPU 占用率从 100% 下降到 10%。CPU 处理能力不再是带宽的限制,网卡自身的硬件规格才是。
- TCP 网络中,100Gbps 网络带宽处理需要消耗 64 颗 2.5GHz Core(按 1MHz CPU 处理 1Mbps Net I/O 计算);
- RDMA 网络中,CPU 无需再做收发包中断处理,不仅降低延迟,也节省了 CPU。
低延时
相对于 TCP,网络时延从 ms 级降低到 10μs 以下。
- TCP 网络中,对于一个数据报文,内核协议栈会执行多次内存拷贝、中断处理,上下文切换等会产生数十微秒的固定时延;
- RDMA 网络中,Application 直接操作 RNIC Verbs API,不再经过 System-call 切换到内核态,没有内核切换开销。另外,由于数据报文头都在 RNIC 上处理,不用拷贝到内核态处理,Zero-Copy 延迟会显著减少。
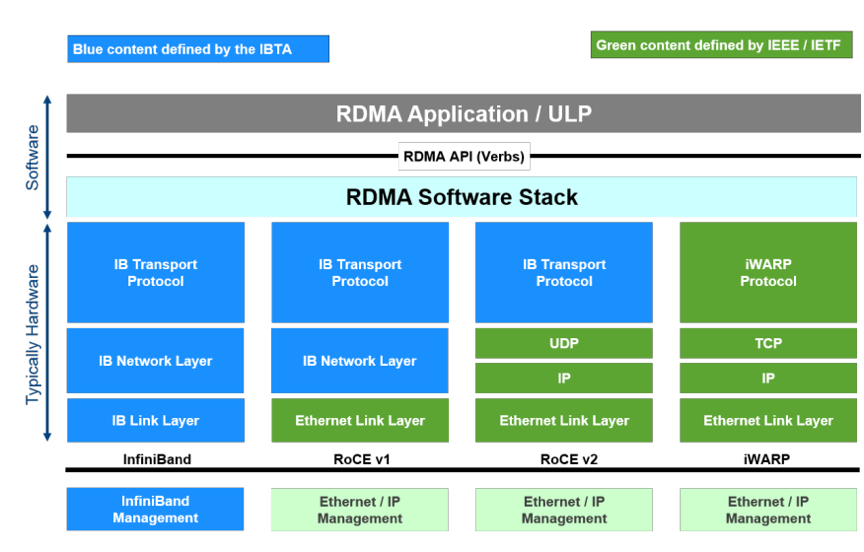
RDMA 协议栈标准
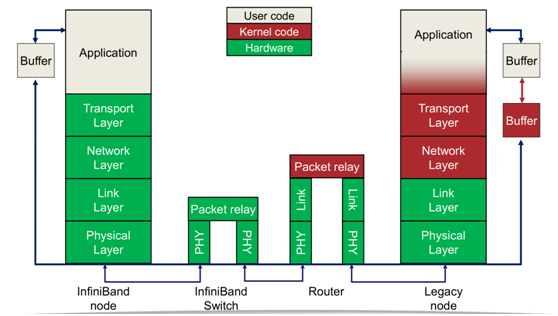
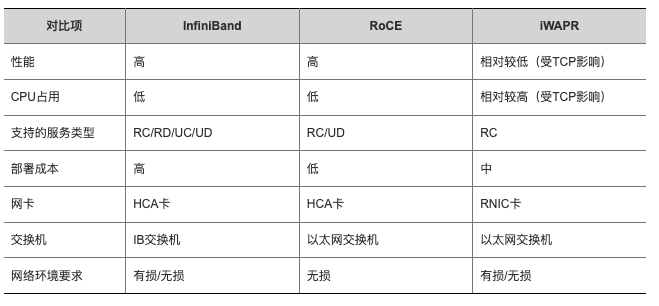
目前主要有 RDMAC和 IBTA(InfiniBand Trade Association)两大组织主导着 RDMA 协议栈标准的发展。
- IBTA(InfiniBand Trade Association):RDMA 协议栈最早由 InfiniBand 实现,InfiniBand 发展的初衷就是把服务器的 DMA 总线网络化,即 RDMA。总线技术中采用的 DMA(Direct Memory Access)技术在 InfiniBand 中以 RDMA(Remote Direct Memory Access)的形式得以实现。最初的 RDMA 是 IBTA 在 2000 年发布的基于 InfiniBand 的 RDMA 规范。由于这是一种闭源的网络技术,因此需要支持该技术的 NIC 和 Switch。
- RDMAC(RDMA Consortium)/ IETF:后来随着复用高性价比 Ethernet 网络架构大趋势下出现的 RoCE 和 iWARP 技术方向。

RDMA 运行原理
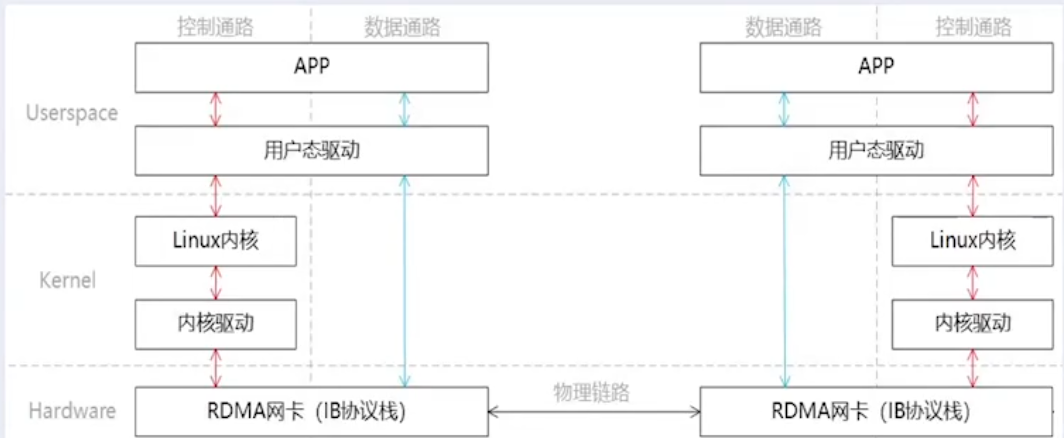
通信通路
RDMA 采用了 “数控分离” 通信通路:
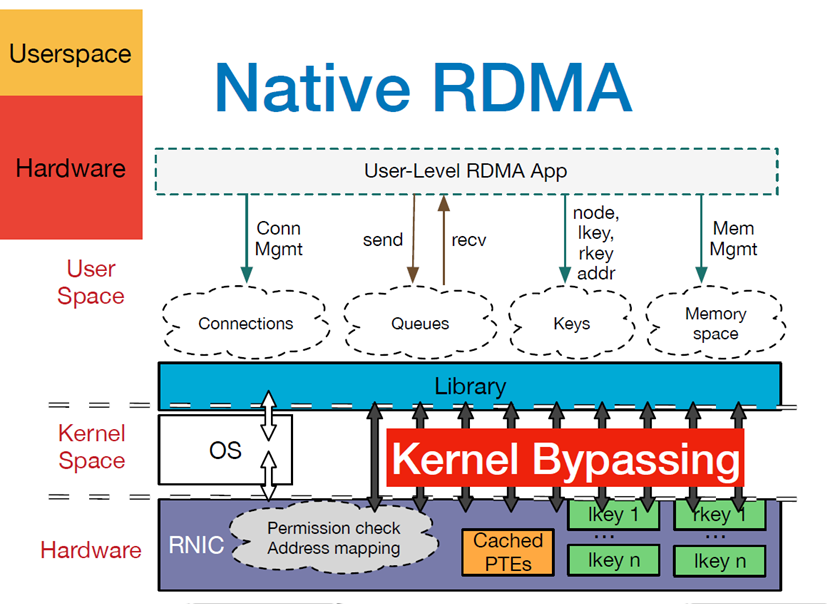
- 控制通路:需要 Kernel 的参与,使用 Socket API 传输控制信令,用于创建和管理 “数据通路” 数据传输时所需要的资源。例如:Channel、QP(Queue Pairs)、MR(Memory Region)等。
- 数据通路:不需要 Kernel 的参与,使用 Verbs API 传输业务数据。
通信模型
RDMA 采用了基于 MQ Channel(消息队列通道)的 P2P 全双工通信模型,定义了 2 大类型的队列:
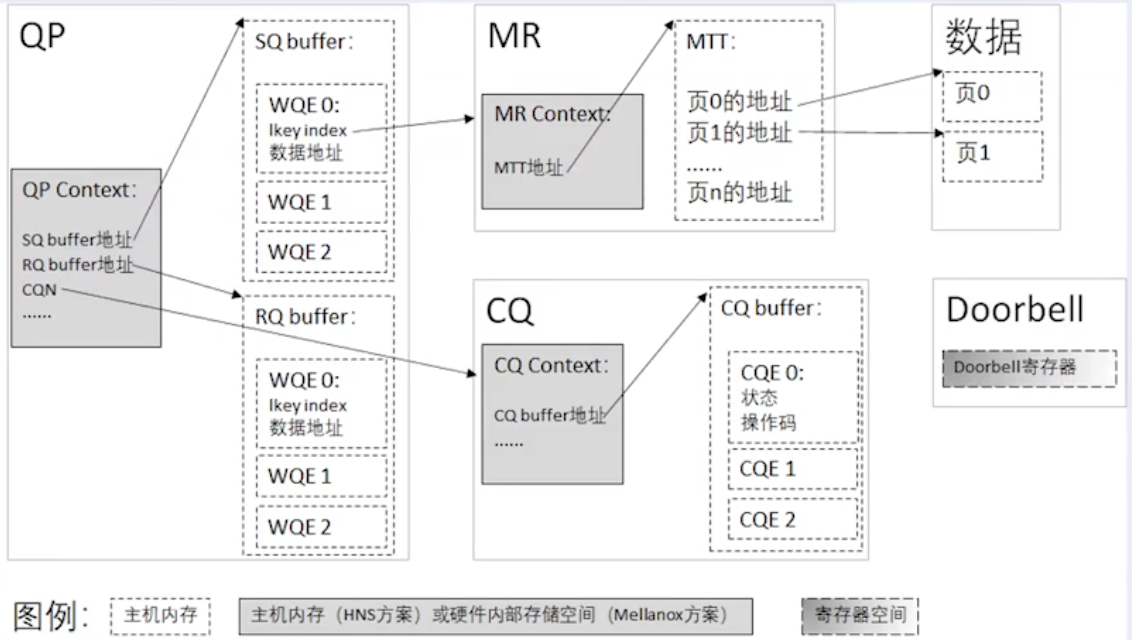
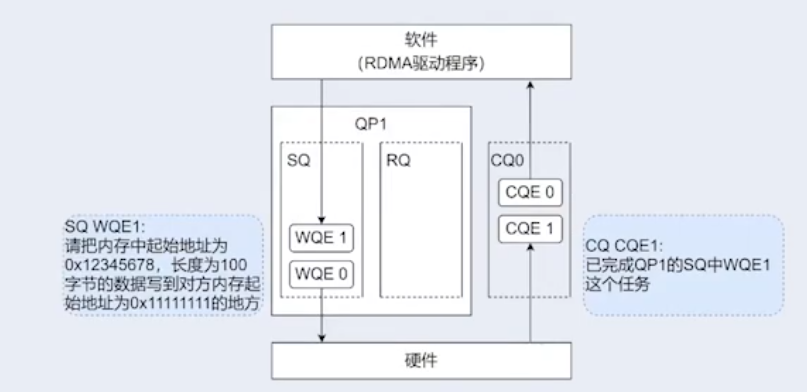
- WQ(Work Queue):App 要收/发数据,就会放置一个 WR(Work Request)到 WQ 作为 WQE(WQ Element)。WQE 是 RNIC 硬件执行任务单元,包含了软件需要硬件执行的动作。RNIC 会获取到 WQE 进行处理。
- CQ(Complete Queue):RNIC 每处理完一个 WQE 之后,就会写入一个 CQE 到 CQ,App 从 CQE 中确认一个 WC(Worker Completion)。
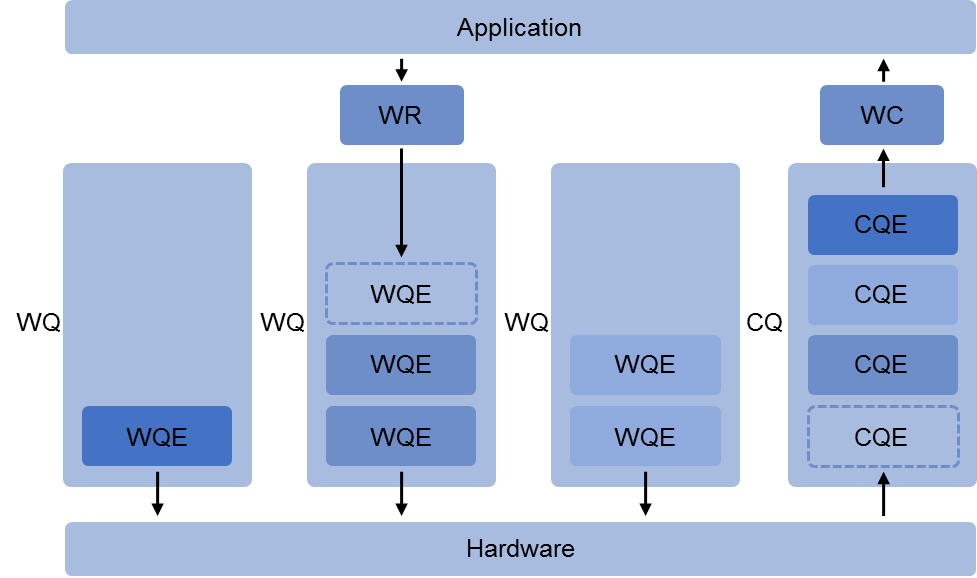
因为 RDMA 支持全双工通信,所以 WQ 进一步细分为 SQ 和 RQ,并称为 QP(Queue Pairs)。通信双方使用一对 QP,通过 BTH QPN 唯一标识,并以此创建 Channel。1 个 RDMA App 可以按需创建多对不同的 QPs 和 Channels。这些 QP 可以用于不同的通信目的,例如:使用不同的服务类型。
- SQ(Send Queue):存放 Send WQE。
- RQ(Receive Queue):存放 Receive WQE。
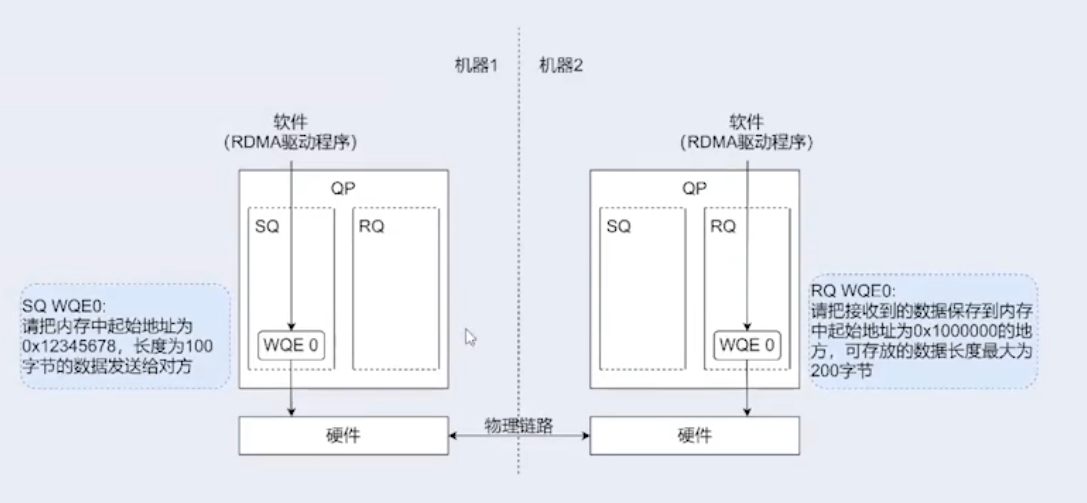
通信方式
RDMA 支持 2 大通信类型:
-
双边通信(Messaging verbs):
- Send-Receive API:双端操作,通过控制通路互相感知,Receiver 需要先下发 Receive WQE,然后 Sender 才会下发 Send WQE。
-
单边通信(Memory verbs):
- Write API:单端操作,Sender 主动执行,只需要本端明确源和目的内存地址,不需要告知 Receiver,Receiver 的 CPU 也不参与,也不会被通知数据的到达。适用于大批量数据传输。
- Read API:同上。
通常在进行 Read / Write API 等单边操作之前,都需要先完成 Send-Receive API 双边操作,交换一些 QP 配置控制信令,包括:
- Local 和 Remote Memory Region 信息
- Local 和 Remote rkey(内存钥匙,控制内存的访问权限)信息
- etc…
内存注册
和内存注册相关的两个重要概念是 PD(Protection Domain,保护域)和 MR(Memory Region,内存区域)。
- MR: 是 RDMA 通信中注册的一块特殊内存区域,需通过 API 显式注册后才能被 RDMA 网卡访问。其主要作用包括:虚拟地址到物理地址的转换、基于 lkey 和 rkey 的访问权限控制、避免换页(锁页)。
- PD:是 RDMA 中用于资源隔离的安全机制,通过将 QP(队列对)和 MR 绑定到同一 PD 中,限制不同 QP 对 MR 的访问权限。其核心作用包括:安全隔离、资源分组管理。同一 PD 内的 QP 只能访问同组的 MR,避免未授权的跨组内存访问。
更详细的,MR 包括以下属性:
- context:上下文
- addr:MR 的 Buffer 首地址
- length:MR 的 Buffer 长度
- lkey:MR 的 local key,唯一标识,在本端执行 RDMA API 操作中用来验证访问权限。
- rkey:MR 的 remote key,唯一标识,在远端执行 RDMA API 操作中用来验证访问权限。
MR 是 Application 的虚拟内存,RNIC 操作的是 Main Memory 的物理内存。所以 Application 创建 MR 时,操作系统的 MMU(内存管理单元)会参与到 MR 的初始化,确保每个虚拟地址都能正确映射到物理地址。
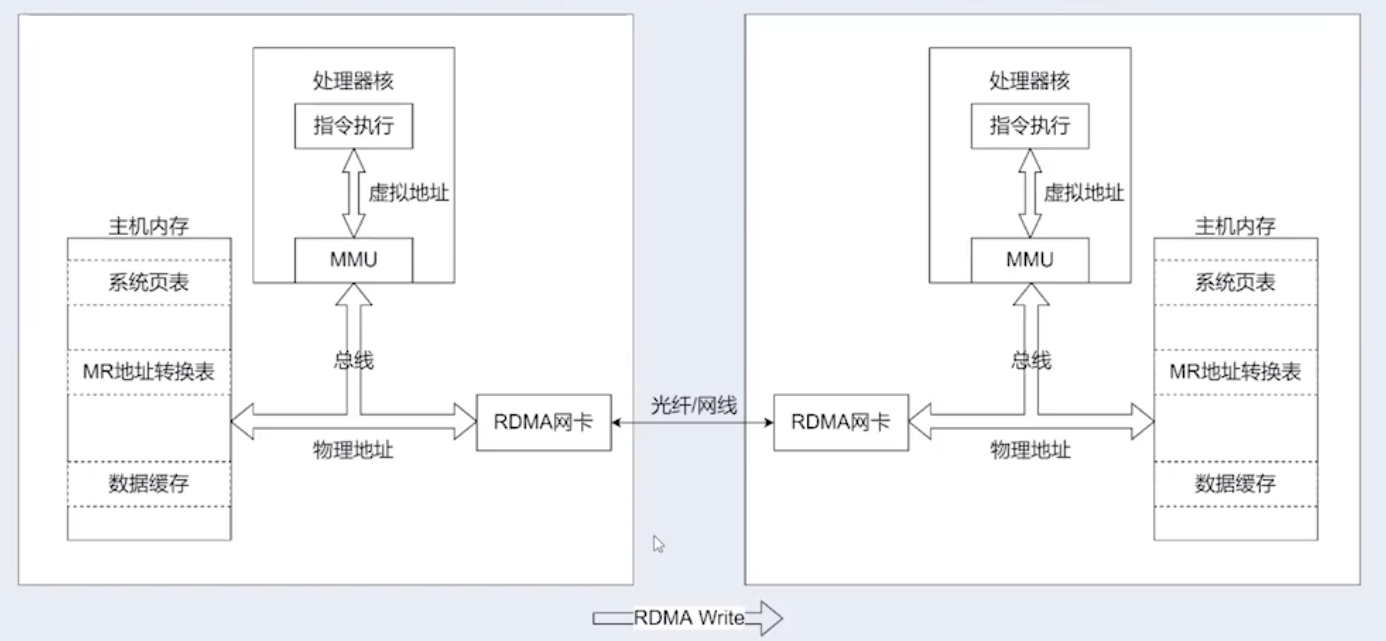
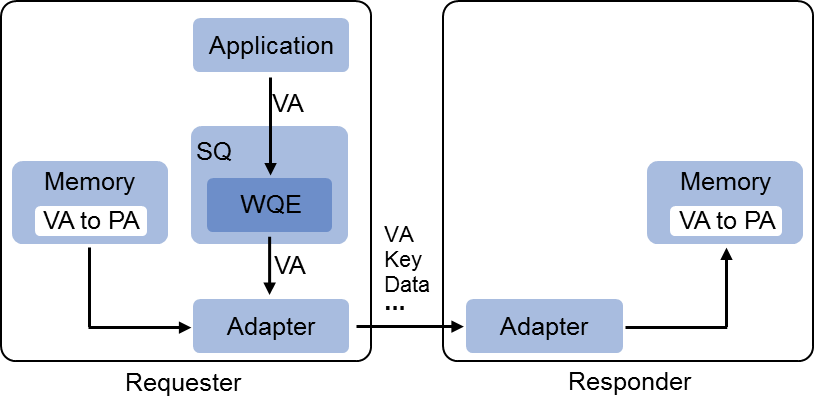
注:
- RNIC 中包含的 MPT(Memory Protection Tables)、MTT(Memory Translation Tables)模块,本质上是一个 Cached Page Table(缓存页表)元件,Page Table Entry 就是用来将 Virtual Address(虚拟内存)映射到相应的 Physical Address(物理内存)。
- RNIC 需要通过 rkey 找到相应的 MPT、然后基于 MPT 的信息再找到相应的 MTT,进而完成 VA 到 PA 的转换。
QP 建链
建立一对 QP 之间的 Channel,过程中协商通信参数。包括:
- GID(Global Identifier,全局 ID):GID 是 IB 网络的唯一标识。IB 网络中用于标识和寻址网络中的节点或端口。
- QPN:QP 的唯一标识,确定建链的对象,GID+QPN 可以在 IB 网络中确定唯一的一个 QP。
- VA(虚拟地址):App 希望访问的虚拟地址。
- rkey:同上。
- qkey:是 UD(不可靠数据报)服务类型中专用的 Key,用于校验数据报的合法性。
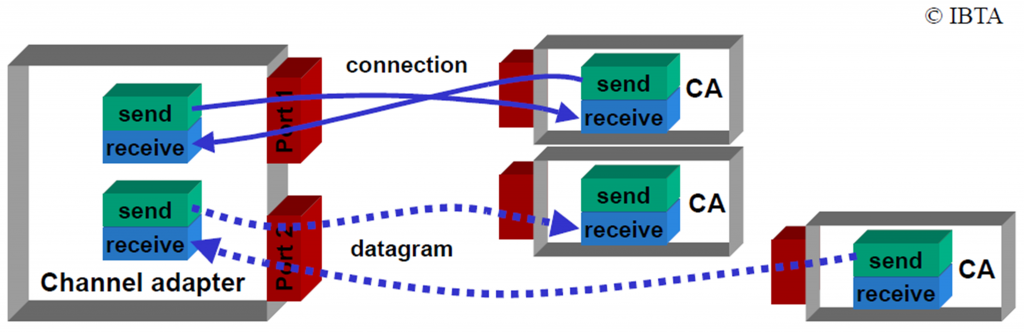
NOTE:QP 建立 “链路(Channel)” 和 “连接(Connection)” 是两个不同的概念,RDMA 支持 4 种基本的服务类型,以满足不同服务对可靠性和传输速率的不同需求。

其中,RC、UC 是存在 Connection 的,而 RD、UD 则不存在 Connection,而是直接传输 Datagram。
RC 服务类型类比 TCP 协议,进行通信的 QP 之间需要建立一对一 Connection。RC 通过 ACK 确认、重传、保序等机制,确保数据能在 QP 间进行有序、可靠的传输,适用于对数据可靠性和完整性较高的场景。但相对的,由于连接机制和可靠性保障机制的存在,导致 RC 的通信开销较大。当节点数增加时,将占用更多的网卡和内存等资源。
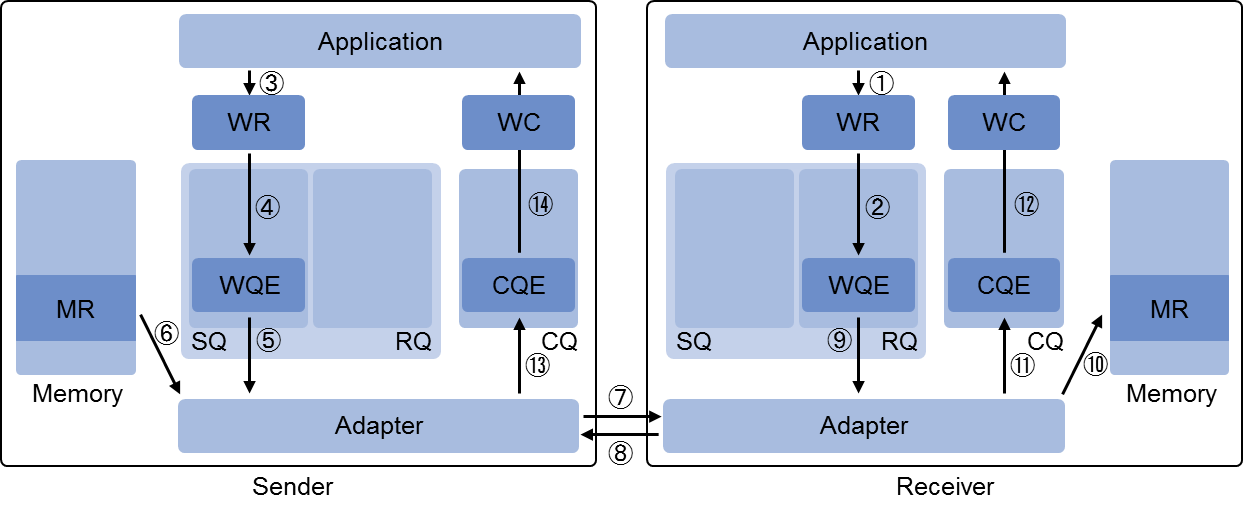
常规流程
- 提交任务:App 通过将 WQE 放入 SQ / RQ 来提交一个任务。
- 完成任务:RNIC 根据 WQE 执行任务,然后生成一个 CQE,包含该任务的完成信息,并放入 CQ。
- 检查结果:App 检查 CQ,确认任务完成情况。如果失败,则可以查看 CQE 信息来了解失败的原因。
双向控制 Send-Receive API 流程
- App B(Receive 端)下发 WQE 到 RQ,描述了一个请求接受任务。
- RNIC B 从 RQ 获取到 WQE 并准备开始接收数据。
- App A(Send 端)下发 WQE 到 SQ,描述了一个请求发送任务。
- RNIC A 从 SQ 获取到 WQE,然后通过 DMA 的方式访问 Main Memory 的指定位置,并获得数据并封装成数据报文。
- RNIC A 将数据报文发送到 RNIC B。
- RNIC B 收到数据报文后进行校验,然后发送 ACK 到 RNIC A。
- RNIC B 解封装数据报文获得数据,然后通过 DMA 的方式将数据存放到指定的 Main Memory 位置。然后生成 CQE 并下发到 CQ 中。
- App B 接收到 CQE 的反馈。
- RNIC A 接受到 ACK 后,生成 CEQ 并下发到 CQ 中。
- App A 接受到 CQE 的反馈。
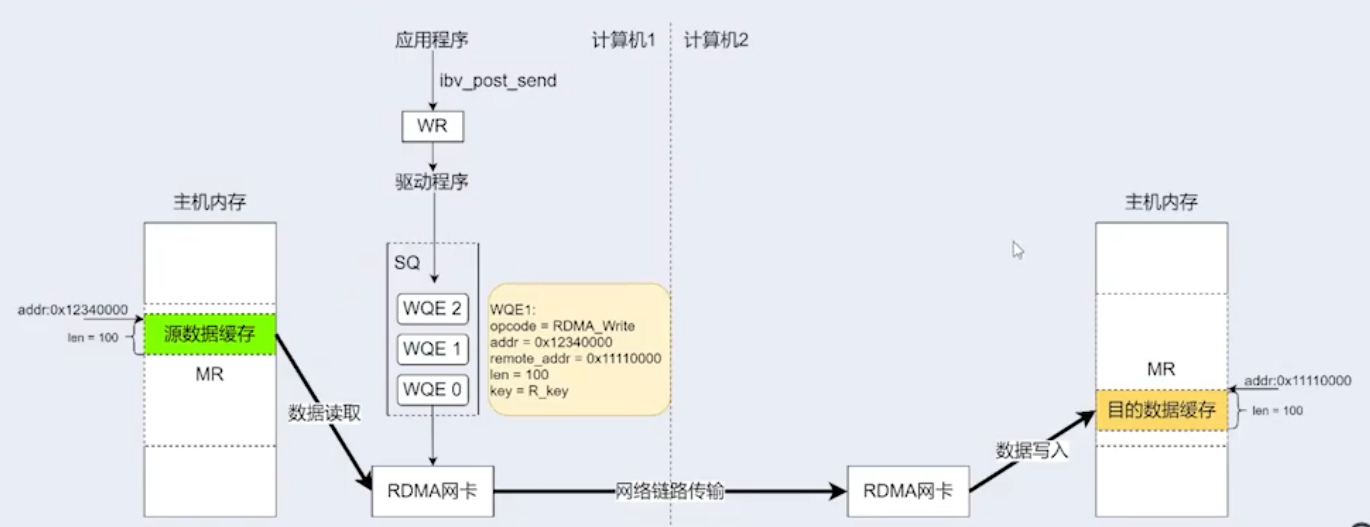
单向数据 Write API 流程
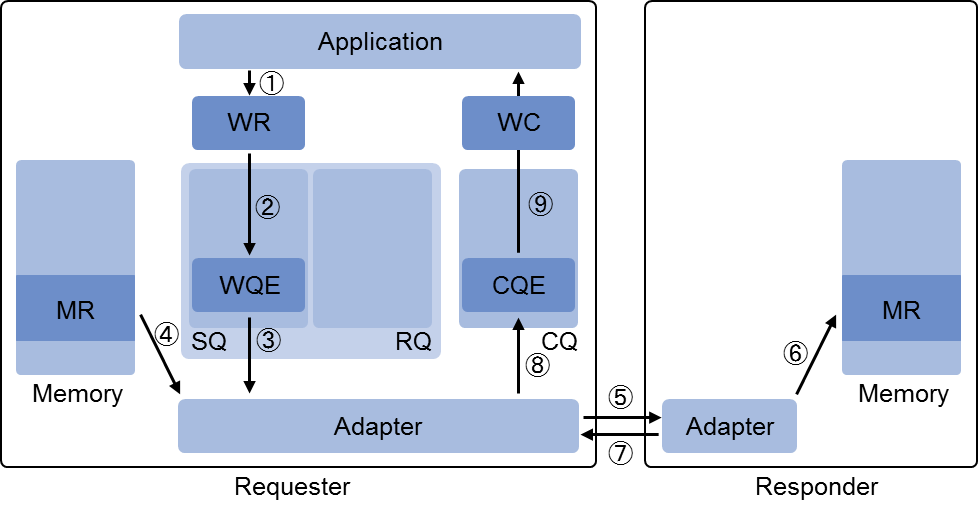
- Local App 将 WQE 下发到 SQ,表示一个请求发送任务。
- Local RNIC 从 SQ 中获取到 WQE。
- Local RNIC 解析出 WQE 中包含的虚拟地址,并通过 RNIC 中的 MPT、MTT 表转换为相应的 Main Memory 物理地址,然后从 Main Memory 中取得数据,封装为数据包。
- Local RNIC 将数据包发送到 Remote RNIC。
- Remote RNIC 接收到数据包,并解析内含的 Payload 数据、虚拟地址、rkey 等信息,并根据 RNIC 的 MPT、MTT 表将虚拟地址转换为 Main Memory 得物理地址,然后通过 DMA 的方式将 Payload 写入到 Main Memory 想要的位置。
- Remote RNIC 返回 ACK 到 Local RNIC。
- Local RNIC 接收到 ACK 后,发送 CEQ 到 CQ。
- Local App 从 CQ 得到任务完成的反馈。
单向数据 Read API 流程
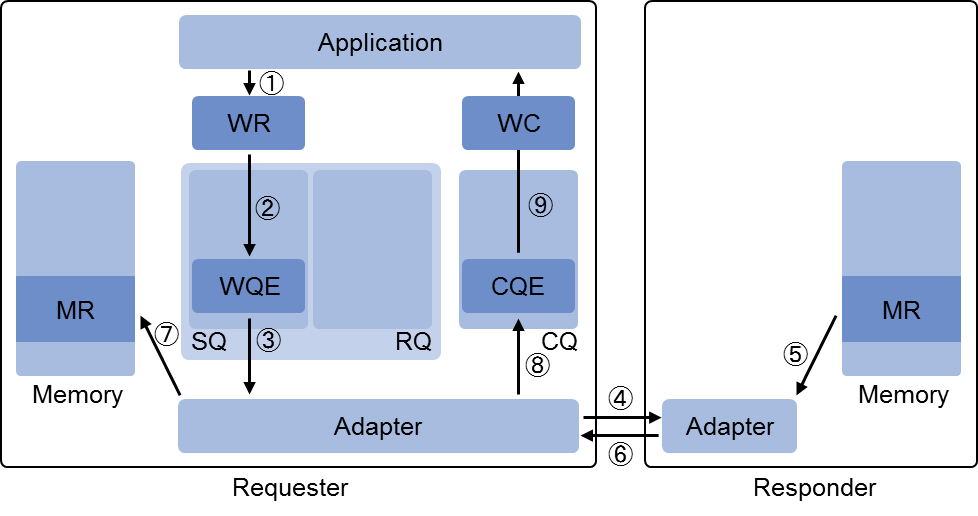
- Local App 将 WQE 下发到 SQ,表示一个请求读取任务。
- Local RNIC 从 SQ 中获取到 WQE。
- Local RNIC 解析 WQE 的内容,并封装成数据包发送到 Remote RNIC。
- Remote RNIC 接收到数据包,并解析内含的虚拟地址,然后将虚拟地址转换为物理地址,并通过 DMA 的方式从 Main Memory 获得相应的数据。
- Remote RNIC 将获取到的数据封装成数据包发送到 Local RNIC。
- Local RNIC 接收到数据包后对其进行解封装,获取到内含的数据之后,根据 WQE 的描述,通过 DMA 将数据放置到指定的 Main Memory 中。
- Local RNIC 发送 CEQ 到 CQ。
- Local App 从 CQ 得到任务完成的反馈。
RDMA Verbs API 编程
基础网络连通性
以 RoCEv2 为例,因为 RoCEv2 的 L2、L3 依旧使用传统以太网,所以可以使用 UDP/IP 进行寻址。
# HostA
$ ifconfig eth2
eth2: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 4200
inet 25.0.0.162 netmask 255.255.255.224 broadcast 25.0.0.191
inet6 fe80::5aa2:e1ff:fe2d:8578 prefixlen 64 scopeid 0x20<link>
ether 58:a2:e1:2d:85:78 txqueuelen 1000 (Ethernet)
RX packets 151 bytes 10282 (10.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 231 bytes 17350 (16.9 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# HostB
$ ifconfig eth2
eth2: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 4200
inet 25.0.0.34 netmask 255.255.255.224 broadcast 25.0.0.63
inet6 fe80::966d:aeff:fefd:1c2c prefixlen 64 scopeid 0x20<link>
ether 94:6d:ae:fd:1c:2c txqueuelen 1000 (Ethernet)
RX packets 130 bytes 9416 (9.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 180 bytes 13688 (13.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# HostA ping B
$ ping -I eth2 25.0.0.34
PING 25.0.0.34 (25.0.0.34) from 25.0.0.162 eth2: 56(84) bytes of data.
64 bytes from 25.0.0.34: icmp_seq=1 ttl=63 time=0.108 ms
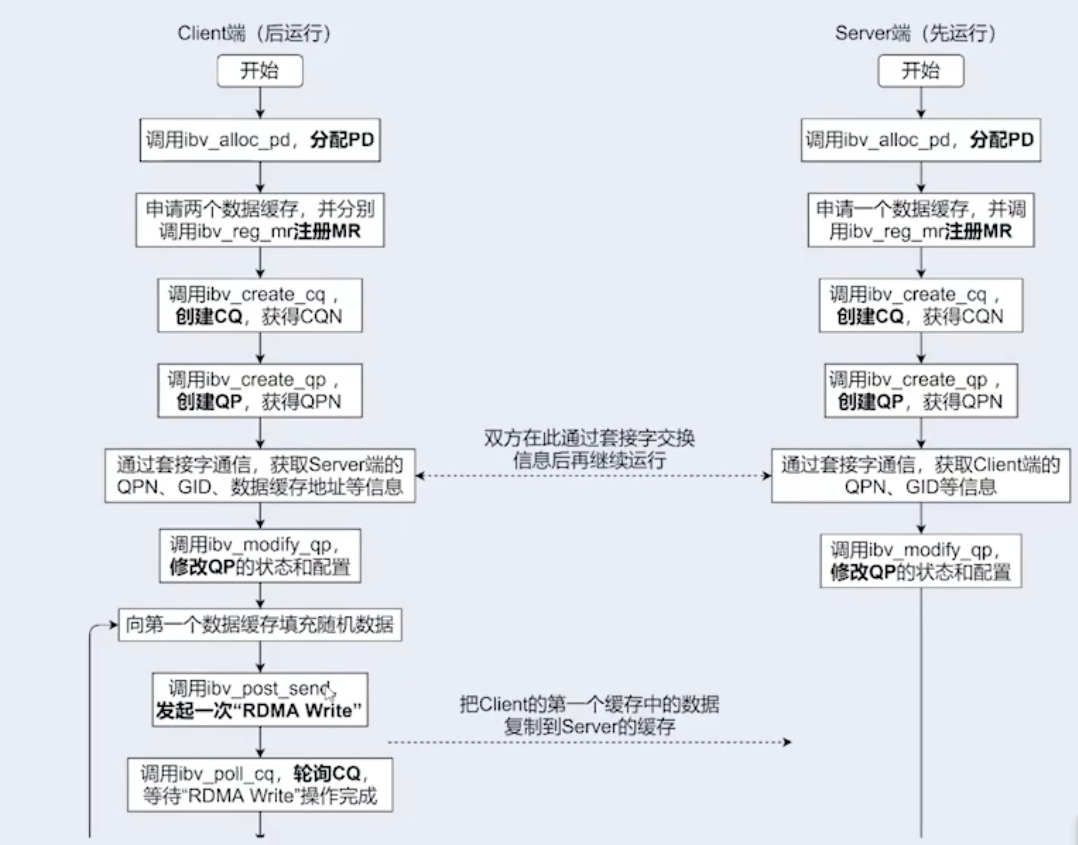
RDMA C/S 程序
- 代码:https://github.com/JmilkFan/rdma-example.git
# RDMA Server
$ ./bin/rdma_server -a 172.16.0.4 -p 20886
RDMA connection management CM event channel is created successfully at 0x22b83a0
A RDMA connection id (36414192) for the server is created
Server RDMA CM id is successfully binded
Server is listening successfully at: 172.16.0.4 , port: 20886
A new RDMA client connection id is stored at 0x22bdda0
A new protection domain is allocated at 0x22bc7f0
An I/O completion event channel is created at 0x22b8380
Completion queue (CQ) is created at 0x22be000 with 31 elements
Client QP created at 0x22be268
Receive buffer pre-posting is successful
Going to wait for : RDMA_CM_EVENT_ESTABLISHED event
A new connection is accepted from 172.16.0.102
Client side buffer information is received...
---------------------------------------------------------
buffer attr, addr: 0x15f43a0 , len: 9 , stag : 0x1ff8b7
---------------------------------------------------------
The client has requested buffer length of : 9 bytes
Local buffer metadata has been sent to the client
Waiting for cm event: RDMA_CM_EVENT_DISCONNECTED
A disconnect event is received from the client...
Server shut-down is complete
# RDMA Client
$ ./rdma_client -a 172.16.0.4 -p 20886 -s rdma_test
Passed string is : rdma_test , with count 9
RDMA CM event channel is created at : 0x15f4500
waiting for cm event: RDMA_CM_EVENT_ADDR_RESOLVED
RDMA address is resolved
waiting for cm event: RDMA_CM_EVENT_ROUTE_RESOLVED
Trying to connect to server at : 172.16.0.4 port: 20886
protection domain allocated at 0x15f48f0
completion event channel created at : 0x15f48b0
CQ created at 0x15f9d30 with 31 elements
QP created at 0x15fb018
Receive buffer pre-posting is successful
waiting for cm event: RDMA_CM_EVENT_ESTABLISHED
The client is connected successfully
Server sent us its buffer location and credentials, showing
---------------------------------------------------------
buffer attr, addr: 0x22bc850 , len: 9 , stag : 0x1ff9b8
---------------------------------------------------------
Client side WRITE is complete
Client side READ is complete
...
SUCCESS, source and destination buffers match
Client resource clean up is complete