AlexNet神经网络详解及VGGNet模型和
AlexNet模型细节
一共8层,5个卷积层,3个全连接层
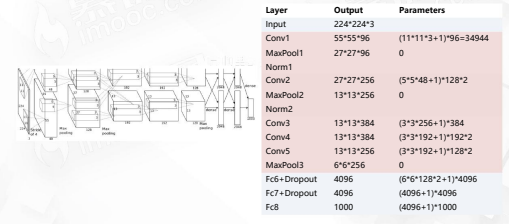
AlexNet工程技巧
多GPU训练,ReLU激活函数,LRN归一化,Dropout,重叠池化,数据增强等
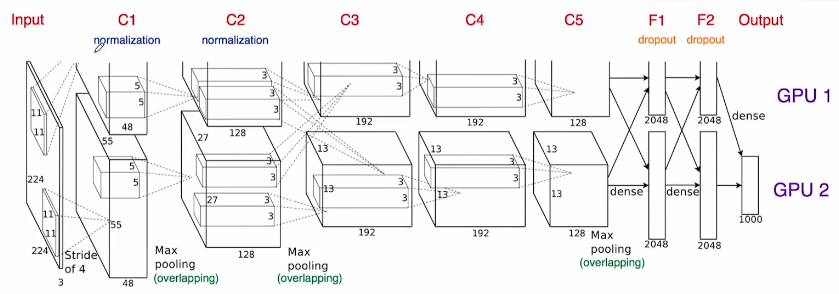
多GPU训练
除了将模型的神经元进行了并行,还使得通信被限制在了某些网络层。第三层卷积要使用第二层所有的特征图,但是第四层却只需要同一块GPU中的第三层的特征图。
LRN归一化
作用于ReLU层之后,抑制反馈较小的神经元,放大反馈较大的神经元,增强模型泛化能力。
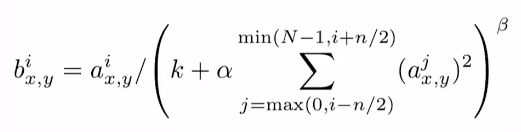
取n个最近邻的特征通道计算,k=2,n=5,α=10-4,β=0.75
数据增强
使用裁剪翻转,PCA颜色扰动等方法,提高模型泛化能力
Dropout层
正则化方法,提高模型泛化
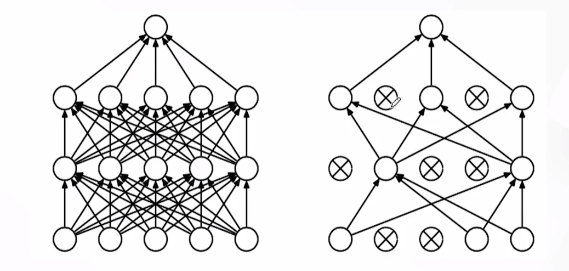
Dropout可以看成是一种模型集成方法,每次生成的网络结构都不一样,通过集成多个模型的方式能够有效地减少过拟合
重叠池化
相邻池化区域的窗口有重叠,可提高模型泛化能力
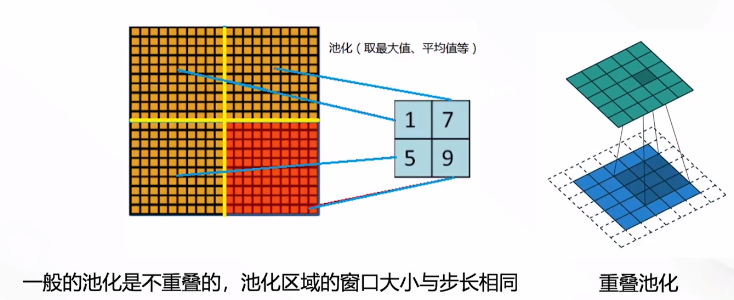
一般的池化是不重叠的,池化区域的窗口大小与步长相同,重叠池化
ReLU激活函数
简单而有效的激活函数,可加速模型收敛
测试时数据增强
将原始图片进行水平翻转、垂直翻转、对角线翻转、旋转角度等数据增强操作,得到多张图,分别进行推理,再融合得到最终输出结果。
VGGNet模型
小卷积的使用
DC Ciresan等人研究表明使用更小的卷积是有利的。
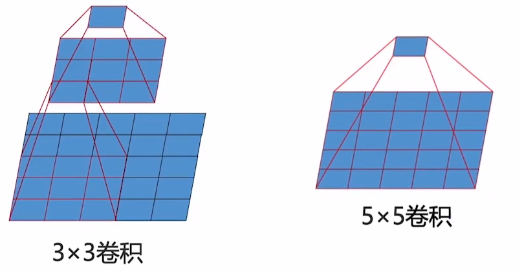
- 网络层数增加(非线性表达能力增加)
- 网络参数数量减少
不同版本的VGGNet
根据深度不同,由VGG11,VGG13,VGG16,VGG19
VGGNet测试
将全连接层替换为卷积,从而适应不同输入大小的图

VGGNet总体特点
与AlexNet同为链式结构,而且更加简单
- 结构非常简洁,整个网络使用了同样大小的卷积核尺寸(3×3)和最大池化尺寸(2×2)
- 几个小滤波器(3×3)卷积层的组合比一个大滤波器(5×5或7×7)卷积层好
- 层数更深更宽(11层、13层、16层、19层)
- 池化核变小且为偶数
- 验证了通过不断加深网络结构可以提升性能
从零搭建VGGNet网络
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.conv1_1 = nn.Conv2d(3, 64, 3, 1, 1)
self.conv1_2 = nn.Conv2d(64, 64, 3, 1, 1)
self.pool1 = nn.MaxPool2d(2)
self.conv2_1 = nn.Conv2d(64, 128, 3, 1, 1)
self.conv2_2 = nn.Conv2d(128, 128, 3, 1, 1)
self.pool2 = nn.MaxPool2d(2)
self.conv3_1 = nn.Conv2d(128, 256, 3, 1, 1)
self.conv3_2 = nn.Conv2d(256, 256, 3, 1, 1)
self.conv3_3 = nn.Conv2d(256, 256, 3, 1, 1)
self.pool3 = nn.MaxPool2d(2)
self.conv4_1 = nn.Conv2d(256, 512, 3, 1, 1)
self.conv4_2 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv4_3 = nn.Conv2d(512, 512, 3, 1, 1)
self.pool4 = nn.MaxPool2d(2)
self.conv5_1 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv5_2 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv5_3 = nn.Conv2d(512, 512, 3, 1, 1)
self.pool5 = nn.MaxPool2d(2)
# 全连接层
self.fc1 = nn.Linear(7 * 7 * 512, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.classifier = nn.Linear(4096, 1000)
def forward(self, x):
x = F.relu(self.conv1_1(x))
x = F.relu(self.conv1_2(x))
x = self.pool1(x)
x = F.relu(self.conv2_1(x))
x = F.relu(self.conv2_2(x))
x = self.pool2(x)
x = F.relu(self.conv3_1(x))
x = F.relu(self.conv3_2(x))
x = self.pool3(x)
x = F.relu(self.conv4_1(x))
x = F.relu(self.conv4_2(x))
x = self.pool4(x)
x = F.relu(self.conv5_1(x))
x = F.relu(self.conv5_2(x))
x = self.pool5(x)
x = x.reshape(-1, 7 * 7 * 512)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.classifier(x)
return x
if __name__ == '__main__':
x = torch.randn((1, 3, 224, 224))
vgg = VGG()
y = vgg(x)
print(y.shape)
torch.save(vgg, 'vgg.pth')
torch.onnx.export(vgg, x, 'vgg,onnx')