Java二分查找——数据结构篇

二分查找算法也称折半查找,是一种非常高效的工作于有序数组的查找算法,是算法入门的不二选择。本文使用java编程语言,逐步讲解二分查找的原理、基础版实现、改进版实现、平衡版实现以及java源代码中是怎么实现的。
算法描述
严格描述:
| 前提 | 给定一个内含 n 个元素的有序数组 A,满足 A{0}\leq A{1}\leq A{2}\leq \cdots \leq A{n-1},一个待查值target |
| 1 | 设置 i=0,j=n-1 |
| 2 | 如果 i \gt j,结束查找,没找到 |
| 3 | 设置 m = floor(\frac {i+j}{2}) ,m 为中间索引,floor 是向下取整(\leq \frac {i+j}{2} 的最小整数) |
| 4 | 如果 target < A_{m} 设置 j = m - 1,跳到第2步 |
| 5 | 如果 A_{m} < target 设置 i = m + 1,跳到第2步 |
| 6 | 如果 A_{m} = target,结束查找,找到了 |
说白了,就是给你一个有序数组 a 和一个目标值 target,让你在数组中找索引对应值为 target 的索引。文字解释比较晦涩难懂,下面我使用黑马程序员中的算法可视化界面为大家展示一下这个算法:
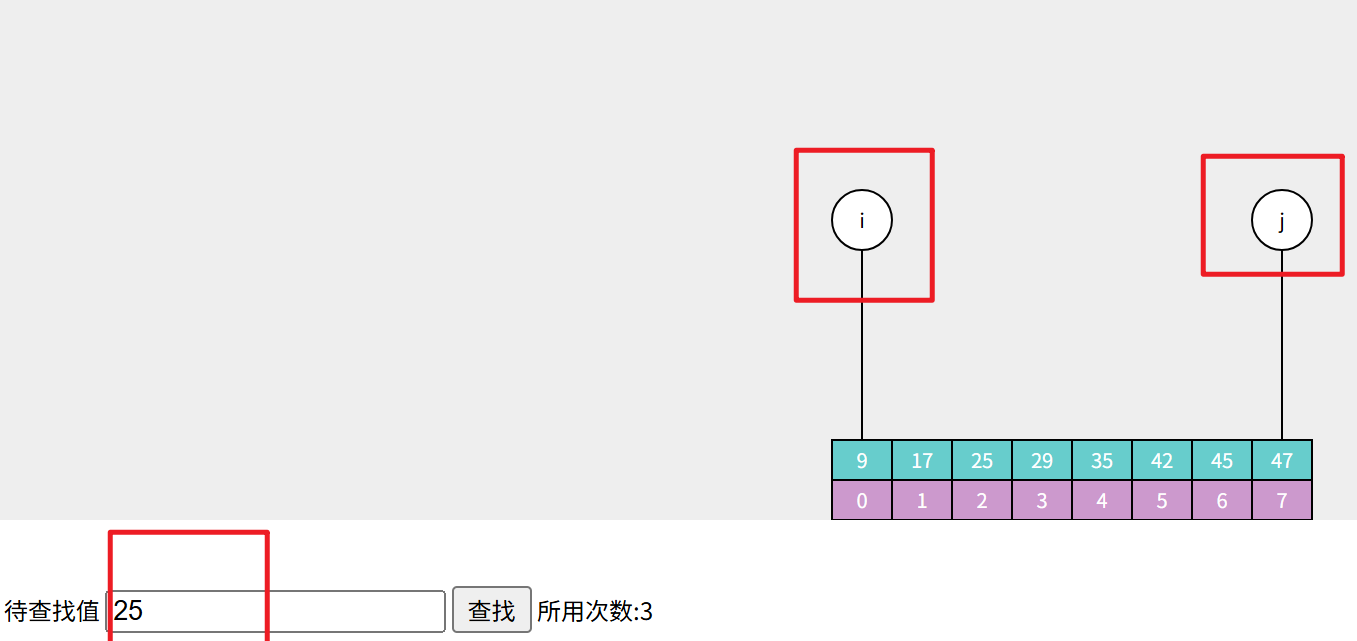
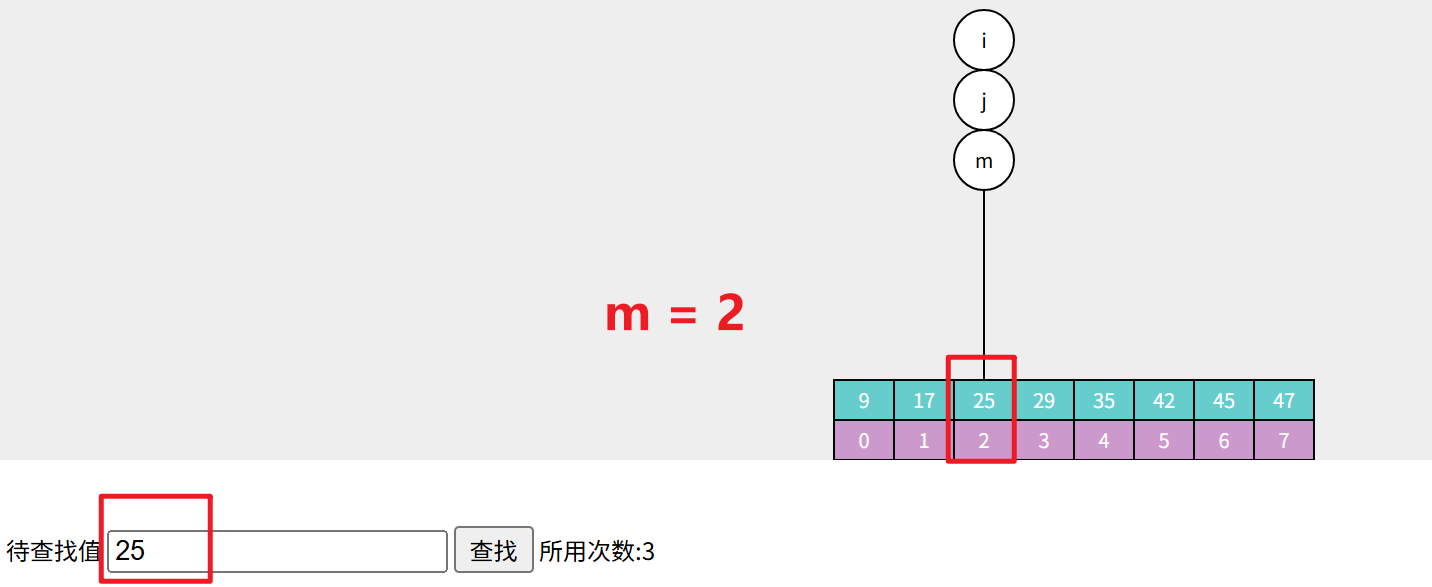
1. 首先准备一个有序数组,再输入一个目标值 25。
在算法开始执行之前,创建一前一后两个指针,分别指向数组的首位元素(索引 index = 0;)和数组的最后一位元素(索引 index = a.length -1;):
2. 循环执行:
取两个索引的中间值,得到中间索引m,用a[m]和目标值 target 进行对比
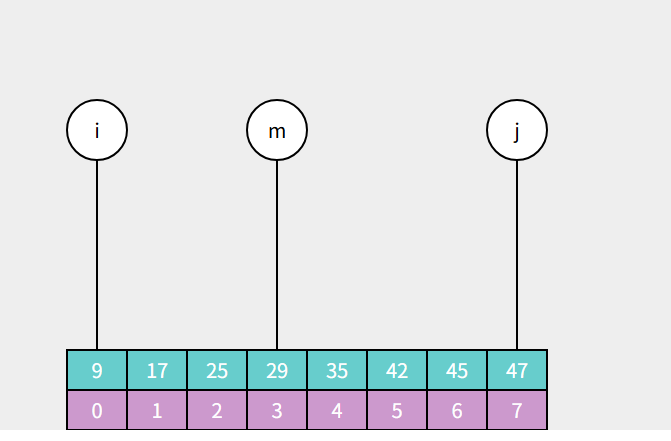
你一定注意到了如果中间值有可能出现小数的问题,所以二分查找的中间值如果不是整数就向下取整,简单说就是去掉小数点后面的数,取一个整数(如3.5取3、6.5取6)。
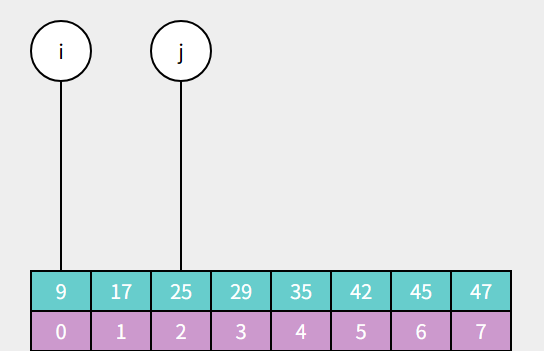
如果a[m] > target 说明目标值在中间索引对应值a[m]的左边,那么指针 j 需要向左移动到 j = m-1 的位置,接着进行下一轮循环:
如果反过来 a[m] < target 说明目标值在中间索引对应值a[m]的右边,那么指针 i 需要向左移动到 i = m+1 的位置,接着进行下一轮循环:
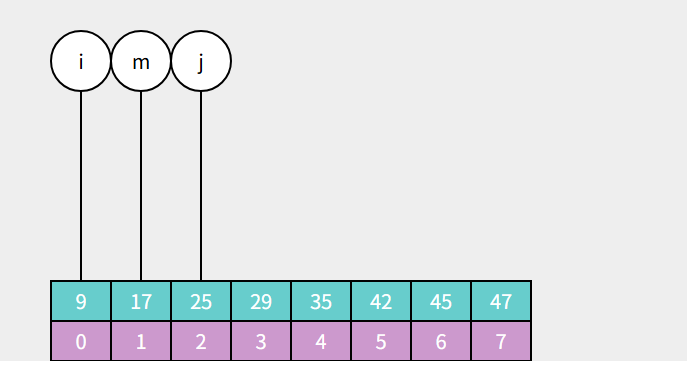
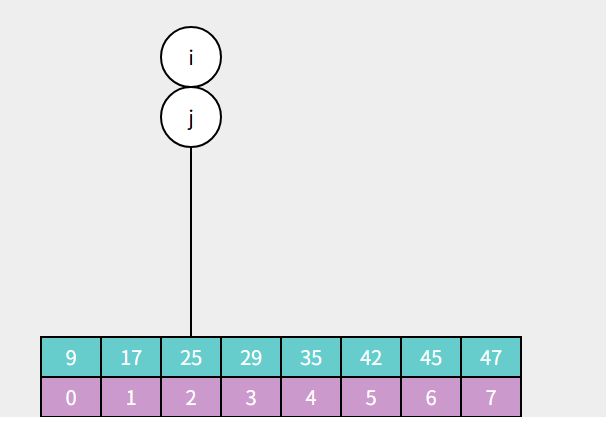
那么如果遇到a[m]等于 target 的情况呢?那恭喜你,成功找到了目标值对应的索引,索引值为m,可以直接退出循环返回 m:
最后,如果目标值在数组中不存在怎么办?那我们就需要为循环设置一个退出条件,当前面的指针 i > j 的时候说明所有可能的值都比对了一遍,即可直接退出循环。
为什么要用二分查找?
传统的寻找目标值方式一般是从左到右,或者从右到左依次遍历数组中的值进行对比是否等于目标值,直到遍历出结果为止,数据量大的时候往往会导致性能很差。比如数组中有一万个元素,如果目标值在数组的尾部或者目标值根本不存在,那么就需要程序遍历对比大几千到一万次。
但是二分查找会省事很多,因为二分查找不会一一遍历数组元素,取中间值进行对比的方式可以排除很多不可能的选项。文字还是不够直观地让你深刻体会到二分查找的优势,下面一张图可以让你感受到其带来的效率到底有多高:
红色的为二分查找的数据量和执行时间分析曲线,蓝色的为传统方法的数据量和执行时间分析曲线,x轴为数据量,y轴为单位执行时间。
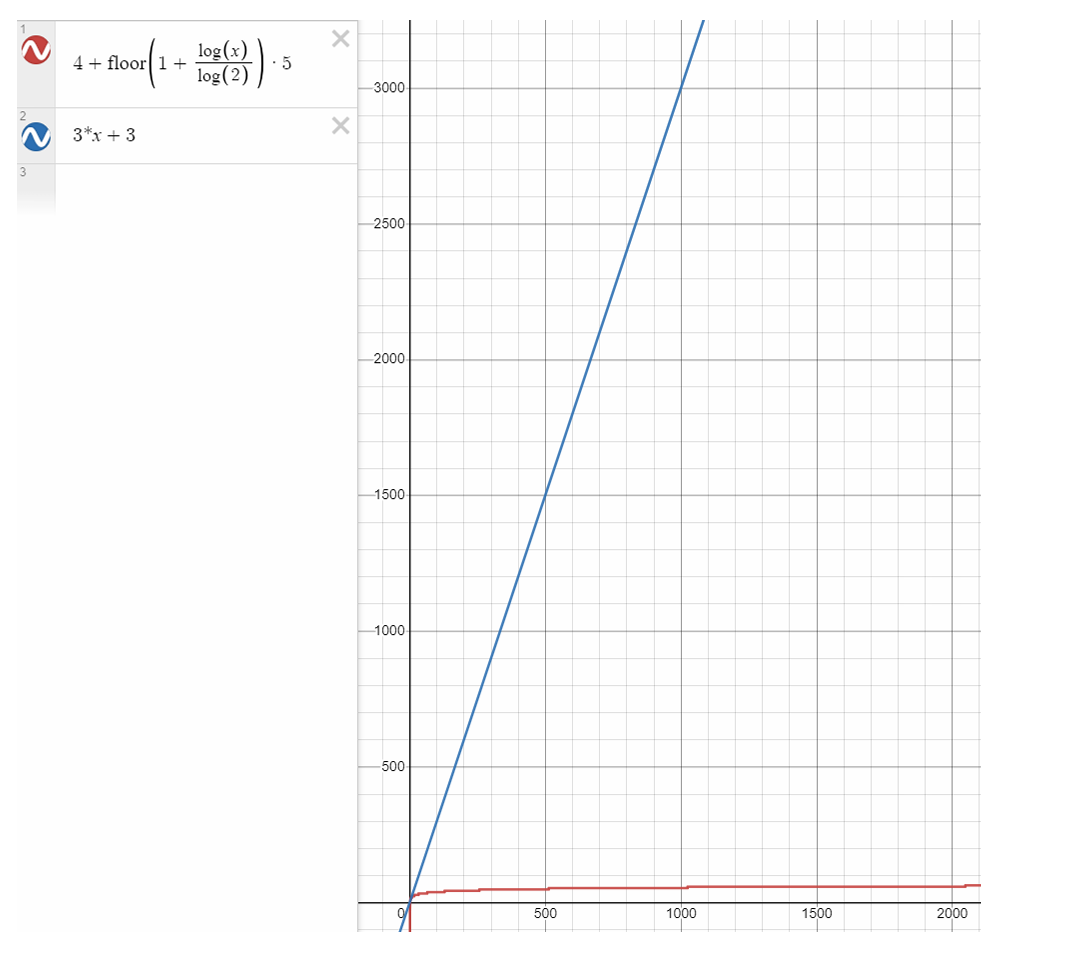
从时间复杂度分析:
传统的方法时间复杂度为O(N)
二分查找的时间复杂度为O(logN),二分查找更优。
为什么数组可以用二分查找?
因为数组内的元素是连续存储的,这就是根据索引查询元素的天然优势,因为只要得到一个数组,所有数组中的元素地址,都可以通过一个简单的索引公式计算出来,从而获取对应的值。时间复杂度达到惊人的 O(1) !
公式——BaseAddress为数组的起始地址,i为索引,size为每个元素占用的字节(如int[]数组,size = 4):
索引 i 所在元素地址 = BaseAddress + i * size
能高效地获取索引对应的值就可以将其与二分查找的目标值进行高效地对比。
java代码实现
基础版
public static int binarySearch(int[] a, int target) {int i = 0, j = a.length - 1;while (i <= j) {int m = (i + j) >>> 1;if (target < a[m]) { // 在左边j = m - 1;} else if (a[m] < target) { // 在右边i = m + 1;} else {return m;}}return -1;
}最后没找到返回不存在的索引-1。
当然除了上述写法,你还可以看到这种写法:
public static int binarySearch(int[] a, int target) {int i = 0, j = a.length;while (i < j) {int m = (i + j) >>> 1;if (target < a[m]) { // 在左边j = m;} else if (a[m] < target) { // 在右边i = m + 1;} else {return m;}}return -1;
}这种方法让 j 指向右边一个不存在的索引 a.length 的位置,同时也意味着 j 指向的一定不是查找的目标,所以不存在 i = j 的情况。
平衡版
这是一种性能更优的二分查找版本,但是最好的情况性能不及基础版本的二分查找(可以忽略):
public static int binarySearchBalance(int[] a, int target) {int i = 0, j = a.length;while (1 < j - i) {int m = (i + j) >>> 1;if (target < a[m]) {j = m;} else {i = m;}}return (a[i] == target) ? i : -1;
}这个代码之所以这么写,它的核心就是 else 中的判断包含是了 a[m] = target 的情况,
一旦 a[m] = target,后面 i+j >>> 1 的索引一定会大于m,其值也一定会大于m。
也就是说如果目标值存在,算法会先得到一个正确的m赋值给i,然后一直缩小j直到 1 < j - i 不成立
为什么条件是 1 < j - i ?
这是因为这里的 j 也不是一个指向真正索引的值(j的初始化为 j = a.length)
而且 i = m 的赋值方法会让对比过的索引直接赋值给i,因此 j 走到 i+1的位置就不需要再执行下一次循环了。这里的理解文字可能不太好懂,但是使用一个例子可以比较清晰地推敲出来为什么这样设计。只要记住核心思想——对比过的索引所在值就不需要对比了。
java源代码版本
二分查找在Java中的实现代码:
private static int binarySearch0(long[] a, int fromIndex, int toIndex,long key) {int low = fromIndex;int high = toIndex - 1;while (low <= high) {int mid = (low + high) >>> 1;long midVal = a[mid];if (midVal < key)low = mid + 1;else if (midVal > key)high = mid - 1;elsereturn mid; // key found}return -(low + 1); // key not found.
}从代码中可以看出来,这就是一个二分查找的基础版本。但是没有找到的时候,返回的值却不是我上述基础版的-1,而是一个更有利用价值的值。
这里的low其实指的是待插入索引——数组中没有对应的目标值,但是如果要插入这个目标值的话,应该插入到low的位置。
返回-(low+1)则更多的是为了避免索引冲突的考量,确保没有找到的时候返回的索引是一个负数。